SQL数据库如何压缩
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL数据库如何压缩相关的知识,希望对你有一定的参考价值。
我客户的SQL数据库
其中MDF文件是二百多M
LDF只有一M
清理过日记了
我想问一下怎么把那二百M的MDF文件再压缩一下
最好压缩在五十M左右
如果你要复制的话就不用了
1、首先从开始菜单着手,打开开始菜单栏,在菜单栏上找到我们已经安装的SQL server 2008,单击打开它。

2、打开SQL server 2008数据库,来到登录界面,在这里我们只需要输入登录服务器名(电脑IP地址)、登录身份、账号、密码,然后单击登录。
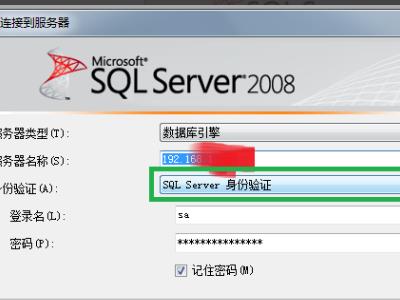
3、成功登录进入SQL 数据库,可以看到连接的数据库基本信息,展开数据库节点,单击数据库然后使用鼠标右键,在弹出的菜单中选择附加。
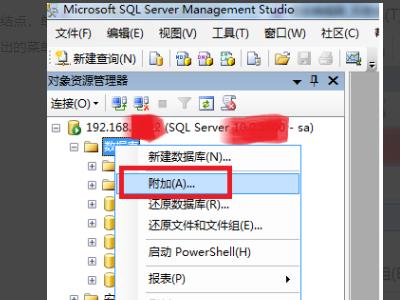
4、接着弹出附加数据库的界面,这里我们只需要单击界面上的添加按钮就可以了。
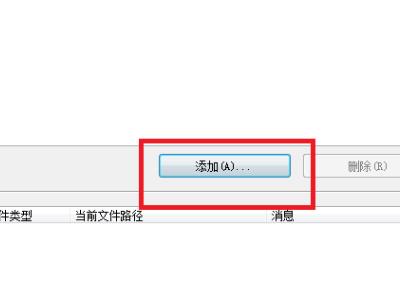
5、单击添加按钮后,新弹出来一个框,让你选择你要附加的数据文件路径,选择到我们要附加的数据库文件,单击确定按钮。
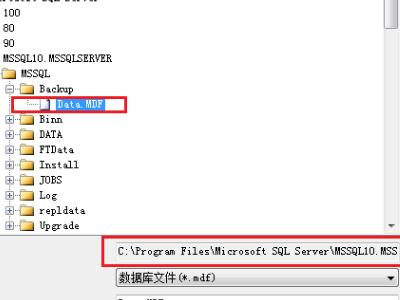
6、返回到附加数据库的界面,这是我们可以从界面上看到选择的附加数据库文件信息,然后在上方可以修改要附加的数据库名称。
/*--特别注意
请按步骤进行,未进行前面的步骤,请不要做后面的步骤
否则可能损坏你的数据库.
一般不建议做第4,6两步
第4步不安全,有可能损坏数据库或丢失数据
第6步如果日志达到上限,则以后的数据库处理会失败,在清理日志后才能恢复.
--*/
--下面的所有库名都指你要处理的数据库的库名
1.清空日志
DUMP TRANSACTION 库名 WITH NO_LOG
2.截断事务日志:
BACKUP LOG 库名 WITH NO_LOG
3.收缩数据库文件(如果不压缩,数据库的文件不会减小
企业管理器--右键你要压缩的数据库--所有任务--收缩数据库--收缩文件
--选择日志文件--在收缩方式里选择收缩至XXM,这里会给出一个允许收缩到的最小M数,直接输入这个数,确定就可以了
--选择数据文件--在收缩方式里选择收缩至XXM,这里会给出一个允许收缩到的最小M数,直接输入这个数,确定就可以了
也可以用SQL语句来完成
--收缩数据库
DBCC SHRINKDATABASE(库名)
--收缩指定数据文件,1是文件号,可以通过这个语句查询到:select * from sysfiles
DBCC SHRINKFILE(1)
4.为了最大化的缩小日志文件(如果是sql 7.0,这步只能在查询分析器中进行)
a.分离数据库:
企业管理器--服务器--数据库--右键--分离数据库
b.在我的电脑中删除LOG文件
c.附加数据库:
企业管理器--服务器--数据库--右键--附加数据库
此法将生成新的LOG,大小只有500多K
或用代码:
下面的示例分离 pubs,然后将 pubs 中的一个文件附加到当前服务器。
a.分离
EXEC sp_detach_db @dbname = '库名'
b.删除日志文件
c.再附加
EXEC sp_attach_single_file_db @dbname = '库名',
@physname = 'c:\Program Files\Microsoft SQL Server\MSSQL\Data\库名.mdf'
5.为了以后能自动收缩,做如下设置:
企业管理器--服务器--右键数据库--属性--选项--选择"自动收缩"
--SQL语句设置方式:
EXEC sp_dboption '库名', 'autoshrink', 'TRUE'
6.如果想以后不让它日志增长得太大
企业管理器--服务器--右键数据库--属性--事务日志
--将文件增长限制为xM(x是你允许的最大数据文件大小)
--SQL语句的设置方式:
alter database 库名 modify file(name=逻辑文件名,maxsize=20)本回答被提问者采纳 参考技术B 可以使用DBCC SHRINKDATABASE 和DBCC SHRINKFILE 命令来压缩数据库。
其中DBCC SHRINKDATABASE 命令对数据库进行压缩,DBCC SHRINKFILE 命令对数据库中指定的文件进行压缩。
DBCC SHRINKDATABASE 命令语法如下:
DBCC SHRINKDATABASE (database_name [, target_percent]
[, NOTRUNCATE | TRUNCATEONLY] )
各参数说明如下:
target_percent:
指定将数据库压缩后,未使用的空间占数据库大小的百分之几。如果指定的百分比过大,超过了压缩前未使用空间所占的比例,则数据库不会被压缩。并且压缩后的数据库不能比数据库初始设定的容量小。
NOTRUECATE:
将数据库缩减后剩余的空间保留在数据库,中不返还给操作系统 ,如果不选择此选项,则剩余的空间返还给操作系统。
TRUNCATEONLY :
将数据库缩减后剩余的空间返还给操作系统。使用此命令时SQL Server 将文件缩减到最后一个文件分配,区域但不移动任何数据文件。选择此项后,target_percent 选项就无效了。
SQL Server 2008如何创建分区表,并压缩数据库空间
1、什么是分区表
分区表在逻辑上是一个表,而物理上是多个表。从用户角度来看,分区表和普通表是一样的。使用分区表的主要目的是为改善大型表以及具有多个访问模式的表的可伸缩性和可管理性。分区表是把数据按设定的标准划分成区域存储在不同的文件组中,使用分区可以快速而有效管理和访问数据子集。
适合做分区表的情况
? 数据库中某个表的数据很多,在查询数据时会明显感觉到速度很慢,这个时候需要考虑分区表;
? 数据是分段的,如以年份为分隔的数据,对于当年的数据经常进行增删改查操作,而对于往年的数据几乎不做操作或只做查询操作,这种情况可以使用分区表。对数据的操作如果只涉及一部分数据而不是全部数据的情况可以考虑分区表,如果一张表的数据经常使用且不管年份之类的因素经常对其增删改查操作则最好不要分区。
? 对于具有多个CPU的系统,分区可以对表的操作通过并行的方式进行,可以提升访问性能。
创建分区表的步骤分为5步:
(1)创建数据库文件组
(2)创建数据库文件
(3)创建分区函数
(4)创建分区方案
(5)创建分区表
3.1、创建数据库文件组
注:数据库:ZMQGL_TEST;表:dbo.ENTRY_HEAD、dbo.ENTRY_LIST为例
创建文件组:alter database ZMQGL_TEST add filegroup Group1
语法:alter database <数据名称> add filegroup <文件组名称>
3.2、创建数据库文件
创建文件并添加到文件组中:
alter database ZMQGL_TEST add file
(name=N‘ById1‘,filename=N‘E:\DB\ZMQGL_test\ById1.ndf‘,size=5Mb,filegrowth=5mb)to filegroup Group1语法:alter database <数据库名称> add file <数据标识> to filegroup <文件组名称>--<数据标识> (name:文件名,fliename:物理路径文件名,size:文件初始大小kb/mb/gb/tb,filegrowth:文件自动增量kb/mb/gb/tb/%,maxsize:文件可以增加到的最大大小kb/mb/gb/tb/unlimited)
3.3、创建分区函数、创建分区方案、创建分区表
右键到要分区的表--- >> 存储 --- >> 创建分区 --- >>显示向导视图 --- >> 下一步 --- >> 下一步。。




点击“下一步”,最后点击完成会生成分区函数和分区方案的脚本,如下:USE [ZMQGL_TEST]GOBEGIN TRANSACTIONCREATE PARTITION FUNCTION [FQ_HS](datetime2(3)) AS RANGE LEFT FOR VALUES (N‘2015-12-31T23:59:59.999‘, N‘2016-12-31T23:59:59.999‘)CREATE PARTITION SCHEME [FQ_FA] AS PARTITION [FQ_HS] TO ([PRIMARY], [Group1], [Group2])CREATE CLUSTERED INDEX [ClusteredIndex_on_FQ_FA_636040955802353043] ON [dbo].[ENTRY_HEAD]([D_DATE])WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF) ON [FQ_FA]([D_DATE])DROP INDEX [ClusteredIndex_on_FQ_FA_636040955802353043] ON [dbo].[ENTRY_HEAD] WITH ( ONLINE = OFF )COMMIT TRANSACTION直接F5运行即可。
ALTER PARTITION SCHEME FQ_FA NEXT USED [Group3]‘
ALTER PARTITION SCHEME <分区方案> NEXT USED <文件组>ALTER PARTITION FUNCTION <分区函数> SPLIT RANGE(<边界值>)
删除边界值为‘2017-12-31 23:59:59.999‘的分区
ALTER PARTITION FUNCTION FQ_HS() MERGE RANGE (‘2017-12-31 23:59:59.999‘)
与之対应的分区方案也发生了变化。
以上是关于SQL数据库如何压缩的主要内容,如果未能解决你的问题,请参考以下文章