云原生可观测性之Grafana Loki介绍
Posted GottdesKrieges
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生可观测性之Grafana Loki介绍相关的知识,希望对你有一定的参考价值。
云原生可观测性之Grafana Loki介绍
云原生计算基金会(CNCF)提出了一套云原生可观测性标准协议,称为OpenTelemetry Protocol。OpenTelemetry定义了云原生可观测性的三个重要支柱:Log、Metrics、以及Trace。
-
Log:基于日志的监控
日志是以应用程序运行事件为基础的记录。基于日志的监控产品有Elastic Stack、Flume、Graylog、以及Grafana Loki。 -
Metrics:基于指标的监控
指标是可聚合的数据。这些数据可以来自于基础系统、主机、第三方源等等。基于指标的监控产品有Prometheus、Elastic Stack、Zabbix、Skywalking、以及Grafana Mimir。 -
Trace:基于调用链的监控
调用链是从头至尾跟踪某一过程的一种行为。这个过程可以是一次 API 调用,也可以是系统内的一个动作。基于调用链的监控产品有Skywalking、Zipkin、PinPoint、以及Grafana Tempo。
Loki是Grafana Labs推出的日志聚合工具。Loki本身不存储日志数据,而是将采集的日志写入到第三方对象存储中(例如Amazon S3、MinIO、BoltDB)。与Elasticsearch不同,Loki只会对标签进行索引,而不会对日志数据进行索引,因而能够大大节省存储空间。
Loki架构
版本:v2.7
Loki部署模式
Loki的部署模式可以通过命令行参数-target来指定。
单进程模式
默认的部署模式(-target=all)。Loki的所有组件都将以二进制形式或容器镜像形式统一运行在一个单独的进程里。
😄 优点:快速部署,适用于小体量的读写场景(每天不超过100GB)。
😢 缺点:横向扩展只能通过新增实例来实现,无法针对读或写场景单独扩容。
简单可扩展模式
简单可扩展模式支持读写分离(-target=read和-target=write),可以针对读写场景有针对性的扩容。
😄 优点:读写节点分离,可以单独按需扩展读写能力,最高可以支持每天TB级别日志量的场景。
😢 缺点:需要在Loki前面部署LB,将对/loki/api/v1/push的请求流量以轮询方式(round-robin)定向到写节点。
微服务模式
微服务部署模式中,Loki的每个组件都将以单独的进程运行。通过target命令行标志指定以下组件:
- ingester
- distributor
- query-frontend
- query-scheduler
- querier
- index-gateway
- ruler
- compactor
😄 优点:以微服务集群形式部署的扩展性好、可观测性高、运行效率高,与Kubernetes搭配使用最佳。
😢 缺点:部署和运维最为复杂。
Loki组件
Distributor
Distributor负责处理客户端以stream形式发来的写请求。Distributor对接收到的日志流数据进行简单的检查后,将它们拆分为多个批量(batch),发送给多个Ingester并行处理。
Distributor本身是无状态的。多个distributor组件前面最好部署LB来合理地分配写请求流量。
Distributor的主要功能包括:日志流检查、标签预处理、日志流限速、日志流转发、哈希运算、多数派一致性。
-
Distributor会检查日志流使用的标签(label)是否为有效的Prometheus标签,还会检查日志的时间戳、以及确保日志单行不会过长。
-
Distributor不会修改日志流数据,仅仅对日志流的标签做正则化处理,以及对标签进行排序。这里的正则化处理,是使得
foo="bar",app="game"等价于app='game',foo="bar"。正则化和排序处理使得Loki能够确定地对等价的标签进行缓存和哈希运算。 -
Distributor支持针对租户对日志流写入进行限速。同一个租户在每个distributor的写入速度上限等于租户写入速度上限除以distributor的数量。租户在单个distributor的写入速度上限会随着distributor的横向扩缩容自动调整。
-
对日志流做完检查后,distributor会将其转发给ingester。为了避免数据丢失,distributor会将日志流定向给3个ingester(由参数
replication_factor决定,默认为3)。Distributor通过哈希运算来获取要转发的多个目标ingester。目标ingester中的多数派(floor(replication/2)+1)写入成功,日志流才算写入成功。除了多副本写入以外,ingester还通过WAL(write ahead log)机制来持久化日志流写入,防止数据丢失。 -
一个日志流关联一个确定的租户ID和唯一的标签集合(labelset)。Distributor利用日志流对应的租户ID和labelset来进行哈希运算,以确定要转发的目标ingester。Loki利用存储在Consul中的哈希环(hash ring)来实现一致性哈希。每个ingester都会向哈希环注册自己的状态、以及拥有的token集合。如果ingester拥有的token大于日志流的哈希值,就可以作为目标ingester接受写入。
-
所有的distributor都访问同一个哈希环。为了保证查询的一致性,只有ingester中的多数节点返回确认后,distributor才会向客户端返回成功。
🌻Loki中的Hash Ring:https://grafana.com/docs/loki/latest/fundamentals/architecture/rings/
🌻Loki中使用标签:https://grafana.com/docs/loki/latest/fundamentals/labels/
Ingester
Ingester组件主要负责将日志数据写入后端长期存储,例如DynamoDB、AWS S3、Cassandra等,同时还负责向读请求返回日志数据到内存中。
Ingester内置一个lifecycler来管理其生命周期。Ingester生命周期中包含以下几种状态:PENDING、JOINING、ACTIVE、LEAVING、UNHEALTHY。Lifecycler特性在较新的版本中已被WAL机制取代。
Ingester对接的每个日志流都会被转化为内存中的多个Chunk,在经过一定的interval(可配置参数)后,这些Chunk结构会被落盘持久化。Chunk在以下情况下会被压缩并被标记为只读:
-
Chunk达到了容量上限(可配置参数);
-
距离上次修改Chunk经过了很长的时间;
-
Chunk落盘持久化时。
每当有一个Chunk被标记为只读时,就会产生一个可写的新chunk来取代它。如果ingester进程崩溃或者突然退出,还没有落盘的日志数据就会丢失。Loki通过为每个日志流配置多个副本(replication_factor)来缓解该风险。
当一个Chunk被持久化到后端存储时,Loki会根据它的租户、标签、以及内容进行哈希运算。正常情况下,这样可以保证同一个日志流的多个ingester副本中只有一个副本的Chunk会被写入到后端存储,避免了空间浪费。但是如果某个副本发生了数据写入失败,导致Chunk的内容不完全一致,就可能导致相同的日志数据被重复落盘。这时就需要用到Querier的去重功能。
Loki可以配置为接受乱序写入。当没有配置接受乱序写入时,Ingester会验证采集的日志行是否有序。每个日志行都包含一个时间戳信息。Ingester会丢弃不满足时间戳递增顺序的日志行,并向客户端返回错误信息。如果两条日志具有相同的时间戳,会分为以下两种情况来处理:
-
两条日志的时间戳相同,内容也相同:后接收的日志会被认为是重复内容,直接忽略;
-
两条日志的时间戳相同,但内容不同:后接收的日志会被保留。也就是说此时会存在两条时间戳相同但内容不同的日志。
Query Frontend
Query前端是一个可选部署的服务,可用于提供Querier的API endpoint,以及加速读操作。部署了Query前端时,所有的读请求应该被重定向到Query前端,而不是直接转发到Querier组件。
Query前端将接收的读请求放入一个内置的队列中。Querier组件则担任类似worker的角色,从队列中拉取任务执行,并将执行结果返回给Query前端。Querier通过配置querier.frontend-address来连接到Query前端。
Query前端是无状态的。一般情况下,建议部署两个Query前端来实现较好的调度效果。
Query前端的队列机制主要有以下好处:
-
确保因为OOM失败的大查询可以自动重试。
-
支持将大查询拆分为多个并行的小查询,在不同Querier执行后将执行结果汇总。
-
通过队列的FIFO机制,避免多个大查询被分配给同一个Querier处理。
-
利用公平的租户间调度算法,阻止单个租户通过DOS(denial-of-service)攻击其他租户。
Querier
Querier组件使用Loki的LogQL查询语言来处理请求,负责从ingester获取日志、以及从后端长期存储读取日志。
Querier在处理读请求时,会先向ingester查询内存中的日志数据,如果内存中没有,才会去后端存储中查找。由于replication_factor配置,Querier可能查到重复的日志数据。此时Querier会对时间戳、labelset、以及日志内容都相同的数据进行去重。
客户端
Loki可接受以下官方客户端agent来采集日志,并将日志流通过HTTP API发送给Loki distributor:
-
Promtail
适用于K8S集群和裸金属服务器的日志采集。K8S集群中可以使用Promtail来采集同一worker节点上的Pod日志。裸金属服务器上可以配置Promtail来采集指定路径的文件日志,例如/var/log/*.log。 -
Docker Driver
适用于非K8S编排的docker容器场景。 -
Fluentd和Fluent Bit
如果已经部署了Fluentd并且配置了Parser和Filter插件,也可以结合使用Fluentd和Loki。 -
Logstash
如果已经部署了Logstash和Beats,也可以结合Logstash的Loki输出插件使用。 -
Lambda Promtail
适用于Amazon CloudWatch和Load Balancer日志的采集传送场景。
References
[1] https://grafana.com/docs/loki/latest/fundamentals/architecture/
[2] https://grafana.com/docs/loki/latest/clients/
[3] https://cloud.tencent.com/developer/article/2096468
[4] https://github.com/open-telemetry
企业实践|分布式系统可观测性之应用业务指标监控
简介:本文主要讲述如何建立应用业务指标Metrics监控和如何实现精准告警。Metrics 可以翻译为度量或者指标,指的是对于一些关键信息以可聚合的、数值的形式做定期统计,并绘制出各种趋势图表。透过它,我们可以观察系统的状态与趋势。
作者简介:
赵君|南京爱福路汽车科技有限公司基础设施部云原生工程师,过去一直从事 java 相关的架构和研发工作。目前主要负责公司的云原生落地相关工作,负责 F6 基础设施和业务核心应用全面上云和云原生化改造。
徐航|南京爱福路汽车科技有限公司基础设施部云原生工程师,过去一直负责数据库高可用以及相关运维和调优工作。目前主要负责研发效能 DevOps 的落地以及业务系统云原生可观测性的改造。
随着分布式架构逐渐成为了架构设计的主流,可观测性(Observability)一词也日益被人频繁地提起。
2017 年的分布式追踪峰会(2017 Distributed Tracing Summit)结束后,Peter Bourgon 撰写了总结文章《Metrics, Tracing, and Logging》系统地阐述了这三者的定义、特征,以及它们之间的关系与差异。文中将可观测性问题映射到了如何处理指标(metrics)、追踪(tracing)、日志(logging)三类数据上。
其后,Cindy Sridharan 在其著作《Distributed Systems Observability》中,进一步讲到指标、追踪、日志是可观测性的三大支柱(three pillars)。
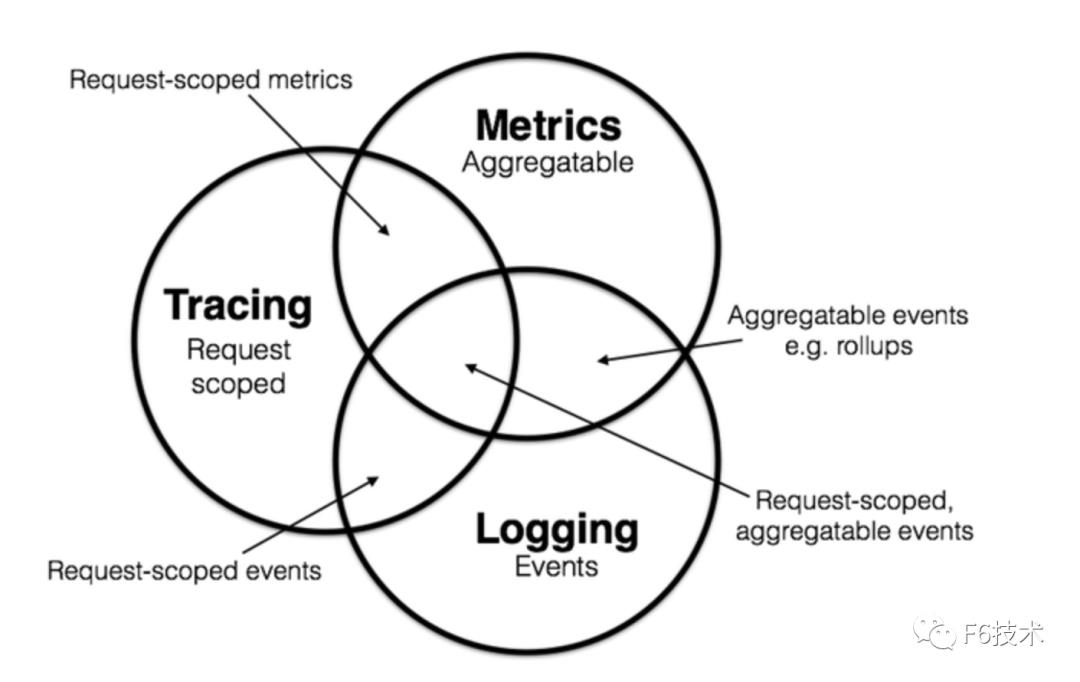
到了 2018 年, CNCF Landscape 率先出现了 Observability 的概念,将可观测性( Observability )从控制论( Cybernetics )中引入到 IT 领域。在控制论中,可观测性是指系统可以由其外部输出,来推断其内部状态的程度,系统的可观察性越强,我们对系统的可控制性就越强。
可观测性可以解决什么问题?Google SRE Book 第十二章给出了简洁明快的答案:快速排障。
There are many ways to simplify and speed troubleshooting. Perhaps the most fundamental are:
- Building observability—with both white-box metrics and structured logs—into each component from the ground up
- Designing systems with well-understood and observable interfaces between components.
Google SRE Book, Chapter 12
而在云原生时代,分布式系统越来越复杂,分布式系统的变更是非常频繁的,每次变更都可能导致新类型的故障。应用上线之后,如果缺少有效的监控,很可能导致遇到问题我们自己都不知道,需要依靠用户反馈才知道应用出了问题。
本文主要讲述如何建立应用业务指标Metrics监控和如何实现精准告警。Metrics 可以翻译为度量或者指标,指的是对于一些关键信息以可聚合的、数值的形式做定期统计,并绘制出各种趋势图表。透过它,我们可以观察系统的状态与趋势。
技术栈选择
我们的应用都是 Spring Boot 应用,并且使用 Spring Boot Actuator 实现应用的健康检查。从 Spring Boot 2.0 开始,Actuator 将底层改为 Micrometer,提供了更强、更灵活的监测能力。Micrometer 支持对接各种监控系统,包括 Prometheus。
所以我们选择 Micrometer 收集业务指标,Prometheus 进行指标的存储和查询,通过 Grafana 进行展示,通过阿里云的告警中心实现精准告警。
指标收集
对于整个研发部门来说,应该聚焦在能够实时体现公司业务状态的最核心的指标上。例如 Amazon 和 eBay 会跟踪销售量, Google 和 Facebook 会跟踪广告曝光次数等与收入直接相关的实时指标。
Prometheus 默认采用一种名为 OpenMetrics 的指标协议。OpenMetrics 是一种基于文本的格式。下面是一个基于 OpenMetrics 格式的指标表示格式样例。
# HELP http_requests_total The total number of HTTP requests. # TYPE http_requests_total counter http_requests_totalmethod="post",code="200" 1027 http_requests_totalmethod="post",code="400" 3 # Escaping in label values: msdos_file_access_time_secondspath="C:\\\\DIR\\\\FILE.TXT",error="Cannot find file:\\n\\"FILE.TXT\\"" 1.458255915e9 # Minimalistic line: metric_without_timestamp_and_labels 12.47 # A weird metric from before the epoch: something_weirdproblem="division by zero" +Inf -3982045 # A histogram, which has a pretty complex representation in the text format: # HELP http_request_duration_seconds A histogram of the request duration. # TYPE http_request_duration_seconds histogram http_request_duration_seconds_bucketle="0.05" 24054 http_request_duration_seconds_bucketle="0.1" 33444 http_request_duration_seconds_bucketle="0.2" 100392 http_request_duration_seconds_bucketle="0.5" 129389 http_request_duration_seconds_bucketle="1" 133988 http_request_duration_seconds_bucketle="+Inf" 144320 http_request_duration_seconds_sum 53423 http_request_duration_seconds_count 144320 # Finally a summary, which has a complex representation, too: # HELP rpc_duration_seconds A summary of the RPC duration in seconds. # TYPE rpc_duration_seconds summary rpc_duration_secondsquantile="0.01" 3102 rpc_duration_secondsquantile="0.05" 3272 rpc_duration_secondsquantile="0.5" 4773 rpc_duration_secondsquantile="0.9" 9001 rpc_duration_secondsquantile="0.99" 76656 rpc_duration_seconds_sum 1.7560473e+07 rpc_duration_seconds_count 2693
指标的数据由指标名(metric_name),一组 key/value 标签(label_name=label_value),数字类型的指标值(value),时间戳组成。
metric_name [ "" label_name "=" `"` label_value `"` "," label_name "=" `"` label_value `"` [ "," ] "" ] value [ timestamp ]
Meter
Micrometer 提供了多种度量类库(Meter),Meter 是指一组用于收集应用中的度量数据的接口。Micrometer 中,Meter 的具体类型包括:Timer, Counter, Gauge, DistributionSummary, LongTaskTimer, FunctionCounter, FunctionTimer, and TimeGauge
- Counter 用来描述一个单调递增的变量,如某个方法的调用次数,缓存命中/访问总次数等。支持配置 recordFailuresOnly,即只记录方法调用失败的次数。Counter 的指标数据,默认有四个 label:class, method, exception, result。
- Timer 会同时记录 totalcount, sumtime, maxtime 三种数据,有一个默认的 label: exception。
- Gauge 用来描述在一个范围内持续波动的变量。Gauge 通常用于变动的测量值,比如队列中的消息数量,线程池任务队列数等。
- DistributionSummary 用于统计数据分布。
应用接入流程
为了方便微服务应用接入,我们封装了 micrometer-spring-boot-starter。micrometer-spring-boot-starter 的具体实现如下。
1.引入 Spring Boot Actuator 依赖
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <dependency> <groupId>io.micrometer</groupId> <artifactId>micrometer-registry-prometheus</artifactId> <version>$micrometer.version</version> </dependency>
2.进行初始配置
Actuator 默认开启了一些指标的收集,比如 system, jvm, http,可以通过配置关闭它们。其实仅仅是我们需要关闭,因为我们已经接了 jmx exporter 了。
management.metrics.enable.jvm=false management.metrics.enable.process=false management.metrics.enable.system=false
如果不希望 Web 应用的 Actuator 管理端口和应用端口重合的话,可以使用 management.server.port 设置独立的端口。这是好的实践,可以看到黑客针对 actuator 的攻击,但是换了端口号,不暴露公网问题会少很多。
1management.server.port=xxxx
3.配置 spring bean
TimedAspect 的 Tags.empty() 是故意的,防止产生太长的 class 名称对 prometheus 造成压力。
@PropertySource(value = "classpath:/micrometer.properties")
@Configuration
public class MetricsConfig
@Bean
public TimedAspect timedAspect(MeterRegistry registry)
return new TimedAspect(registry, (pjp) -> Tags.empty());
@Bean
public CountedAspect countedAspect(MeterRegistry registry)
return new CountedAspect(registry);
@Bean
public PrometheusMetricScrapeEndpoint prometheusMetricScrapeEndpoint(CollectorRegistry collectorRegistry)
return new PrometheusMetricScrapeEndpoint(collectorRegistry);
@Bean
public PrometheusMetricScrapeMvcEndpoint prometheusMvcEndpoint(PrometheusMetricScrapeEndpoint delegate)
return new PrometheusMetricScrapeMvcEndpoint(delegate);
应用接入时,引入 micrometer-spring-boot-starter 依赖
<dependency> <groupId>xxx</groupId> <artifactId>micrometer-spring-boot-starter</artifactId> </dependency>
现在,就可以通过访问 http://ip:port/actuator/prometheus,来查看 Micrometer 记录的数据。
自定义业务指标
Micrometer 内置了 Counted 和 Timed 两个 annotation。可以通过在对应的方法上加上 @Timed 和 @Counted 注解,来收集方法的调用次数,时间和是否发生异常等信息。
@Timed
如果想要记录打印方法的调用次数和时间,需要给 print 方法加上 @Timed 注解,并给指标定义一个名称。
@Timed(value = "biz.print", percentiles = 0.95, 0.99, description = "metrics of print") public String print(PrintData printData)
在 print 方法上加上 @Timed 注解之后,Micrometer 会记录 print 方法的调用次数(count),方法调用最大耗时(max),方法调用总耗时(sum)三个指标。percentiles = 0.95, 0.99 表示计算 p95,p99 的请求时间。记录的指标数据如下。
biz_print_seconds_countexception="none" 4.0 biz_print_seconds_sumexception="none" 7.783213927 biz_print_seconds_maxexception="none" 6.14639717 biz_print_secondsexception="NullPointerException" 0.318767104 biz_print_secondsexception="none",quantile="0.95", 0.58720256 biz_print_secondsexception="none",quantile="0.99", 6.157238272
@Timed 注解支持配置一些属性:
- value:必填,指标名
- extraTags:给指标定义标签,支持多个,格式 "key", "value", "key", "value"
- percentiles:小于等于 1 的数,计算时间的百分比分布,比如 p95,p99
- histogram:记录方法耗时的 histogram 直方图类型指标
@Timed 会记录方法抛出的异常。不同的异常会被记录为独立的数据。代码逻辑是先 catch 方法抛出的异常,记录下异常名称,然后再抛出方法本身的异常:
try
return pjp.proceed();
catch (Exception ex)
exceptionClass = ex.getClass().getSimpleName();
throw ex;
finally
try
sample.stop(Timer.builder(metricName)
.description(timed.description().isEmpty() ? null : timed.description())
.tags(timed.extraTags())
.tags(EXCEPTION_TAG, exceptionClass)
.tags(tagsBasedOnJoinPoint.apply(pjp))
.publishPercentileHistogram(timed.histogram())
.publishPercentiles(timed.percentiles().length == 0 ? null : timed.percentiles())
.register(registry));
catch (Exception e)
// ignoring on purpose
@Counted
如果不关心方法执行的时间,只关心方法调用的次数,甚至只关心方法调用发生异常的次数,使用 @Counted 注解是更好的选择。recordFailuresOnly = true 表示只记录异常的方法调用次数。
@Timed(value = "biz.print", recordFailuresOnly = true, description = "metrics of print") public String print(PrintData printData)
记录的指标数据如下。
biz_print_failure_totalclass="com.xxx.print.service.impl.PrintServiceImpl",exception="NullPointerException",method="print",result="failure", 4.0 counter 是一个递增的数值,每次方法调用后,会自增 1。
private void record(ProceedingJoinPoint pjp, Counted counted, String exception, String result)
counter(pjp, counted)
.tag(EXCEPTION_TAG, exception)
.tag(RESULT_TAG, result)
.register(meterRegistry)
.increment();
private Counter.Builder counter(ProceedingJoinPoint pjp, Counted counted)
Counter.Builder builder = Counter.builder(counted.value()).tags(tagsBasedOnJoinPoint.apply(pjp));
String description = counted.description();
if (!description.isEmpty())
builder.description(description);
return builder;
Gauge
Gauge 用来描述在一个范围内持续波动的变量。Gauge 通常用于变动的测量值,例如雪花算法的 workId,打印的模板 id,线程池任务队列数等。
- 注入 PrometheusMeterRegistry
- 构造 Gauge。给指标命名并赋值。
@Autowired
private PrometheusMeterRegistry meterRegistry;
public void buildGauge(Long workId)
Gauge.builder("biz.alphard.snowFlakeIdGenerator.workId", workId, Long::longValue)
.description("alphard snowFlakeIdGenerator workId")
.tag("workId", workId.toString())
.register(meterRegistry).measure();
记录的指标数据如下。
biz_alphard_snowFlakeIdGenerator_workIdworkId="2" 2
配置 SLA 指标
如果想要记录指标时间数据的 sla 分布,Micrometer 提供了对应的配置:
management.metrics.distribution.sla[biz.print]=300ms,400ms,500ms,1s,10s
记录的指标数据如下。
biz_print_seconds_bucketexception="none",le="0.3", 1.0 biz_print_seconds_bucketexception="none",le="0.4", 3.0 biz_print_seconds_bucketexception="none",le="0.5", 10.0 biz_print_seconds_bucketexception="none",le="0.6", 11.0 biz_print_seconds_bucketexception="none",le="1.0", 11.0 biz_print_seconds_bucketexception="none",le="10.0", 12.0 biz_print_seconds_bucketexception="none",le="+Inf", 12.0
存储查询
我们使用 Prometheus 进行指标数据的存储和查询。Prometheus 采用拉取式采集(Pull-Based Metrics Collection)。Pull 就是 Prometheus 主动从目标系统中拉取指标,相对地,Push 就是由目标系统主动推送指标。Prometheus 官方解释选择 Pull 的原因。
Pulling over HTTP offers a number of advantages:
- You can run your monitoring on your laptop when developing changes.
- You can more easily tell if a target is down.
- You can manually go to a target and inspect its health with a web browser.
Prometheus 也支持 Push 的采集方式,就是 Pushgateway。
For cases where you must push, we offer the Pushgateway.
为了让 Prometheus 采集应用的指标数据,我们需要做两件事:
1.应用通过 service 暴露出 actuator 端口,并添加 label: monitor/metrics
apiVersion: v1
kind: Service
metadata:
name: print-svc
labels:
monitor/metrics: ""
spec:
ports:
- name: custom-metrics
port: xxxx
targetPort: xxxx
protocol: TCP
type: ClusterIP
selector:
app: print-test
2.添加 ServiceMonitor
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: metrics
labels:
app: metric-monitor
spec:
namespaceSelector:
any: true
endpoints:
- interval: 15s
port: custom-metrics
path: "/manage/prometheusMetric"
selector:
matchLabels:
monitor/metrics: ""
Prometheus 会定时访问 service 的 endpoints (http://podip:port/manage/prometheusMetric),拉取应用的 metrics,保存到自己的时序数据库。
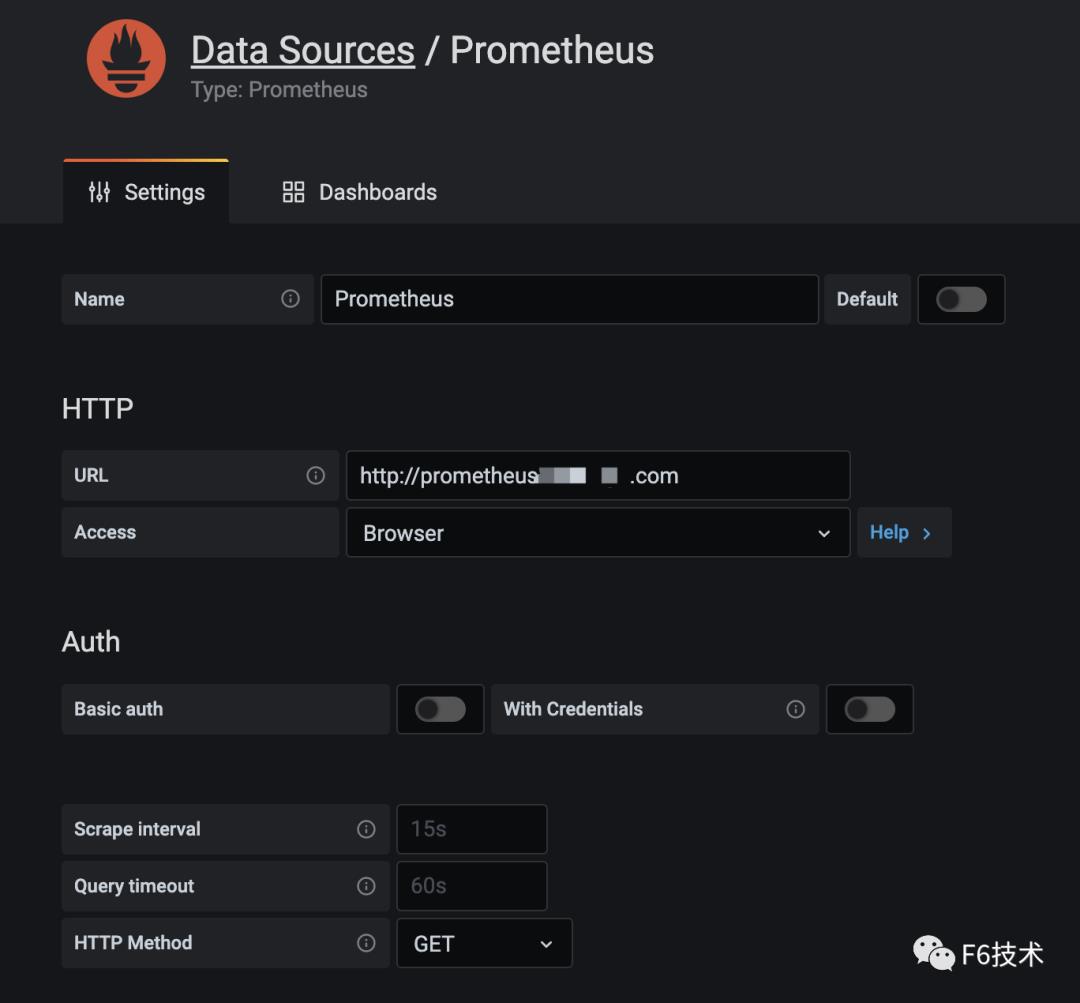
Prometheus 存储的数据是文本格式,虽然 Prometheus 也有 Graph,但是不够炫酷,而且功能有限。还需要有一些可视化工具去展示数据,通过标准易用的可视化大盘去获知当前系统的运行状态。比较常见的解决方案就是 Grafana。Prometheus 内置了强大的时序数据库,并提供了 PromQL 的数据查询语言,能对时序数据进行丰富的查询、聚合以及逻辑运算。通过在 Grafana 配置 Prometheus 数据源和 PromQL,让 Grafana 去查询 Prometheus 的指标数据,以图表的形式展示出来。
1. grafana 配置 Prometheus 数据源
2. 添加看板,配置数据源,query 语句,图表样式

3. 可以在一个 dasborad 添加多个看板,构成监控大盘。
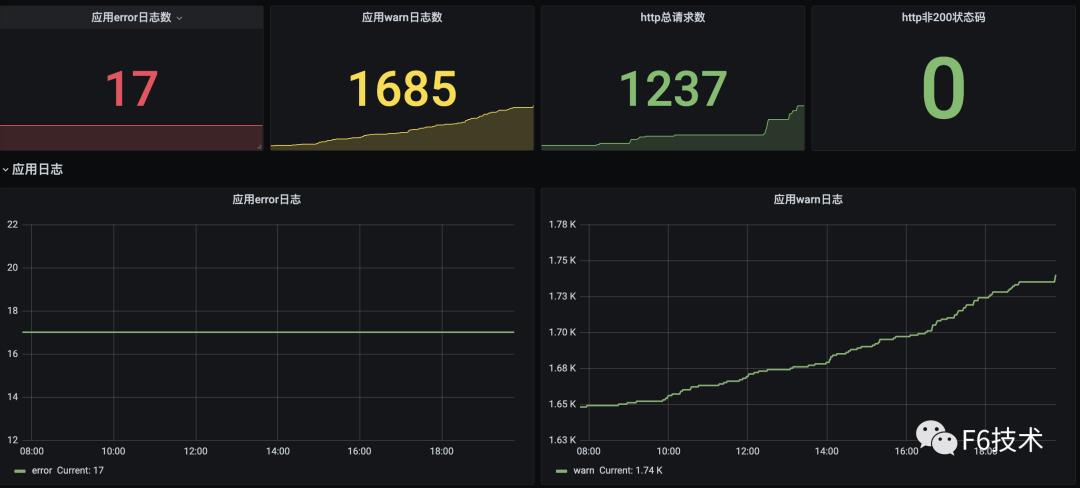
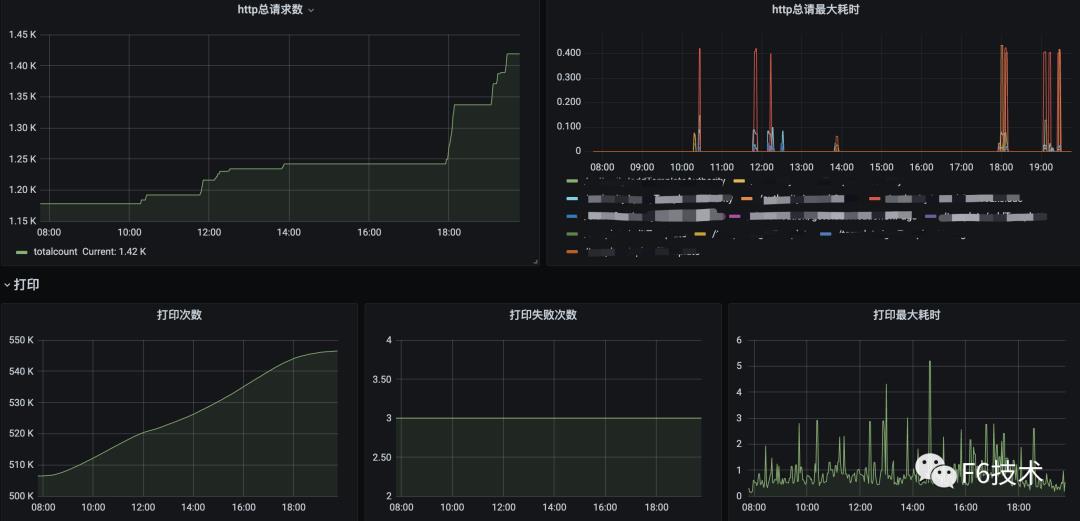
精准告警
任何系统都不是完美的,当出现异常和故障时,能在第一时间发现问题且快速定位问题原因就尤为重要。但要想做到以上这两点,只有数据收集是不够的,需要依赖完善的监控和告警体系,迅速反应并发出告警。
我们最初的方案是,基于 Prometheus operator 的 PrometheusRule 创建告警规则, Prometheus servers 把告警发送给 Alertmanager,Alertmanager 负责把告警发到钉钉群机器人。但是这样运行一段时间之后,我们发现这种方式存在一些问题。SRE 团队和研发团队负责人收到的告警太多,所有的告警都发到一个群里,打开群消息,满屏的告警标题,告警级别,告警值。其中有需要运维处理的系统告警,有需要研发处理的应用告警,信息太多,很难快速筛选出高优先级的告警,很难快速转派告警到对应的处理人。所以我们希望应用告警可以精准发送到应用归属的研发团队。
经过一段时间的调研,我们最终选择阿里云的《ARMS 告警运维中心》来负责告警的管理。ARMS 告警运维中心支持接入 Prometheus 数据源,支持添加钉钉群机器人作为联系人。
1. 收集研发团队的钉钉群机器人的 webhook 地址,创建机器人作为联系人。
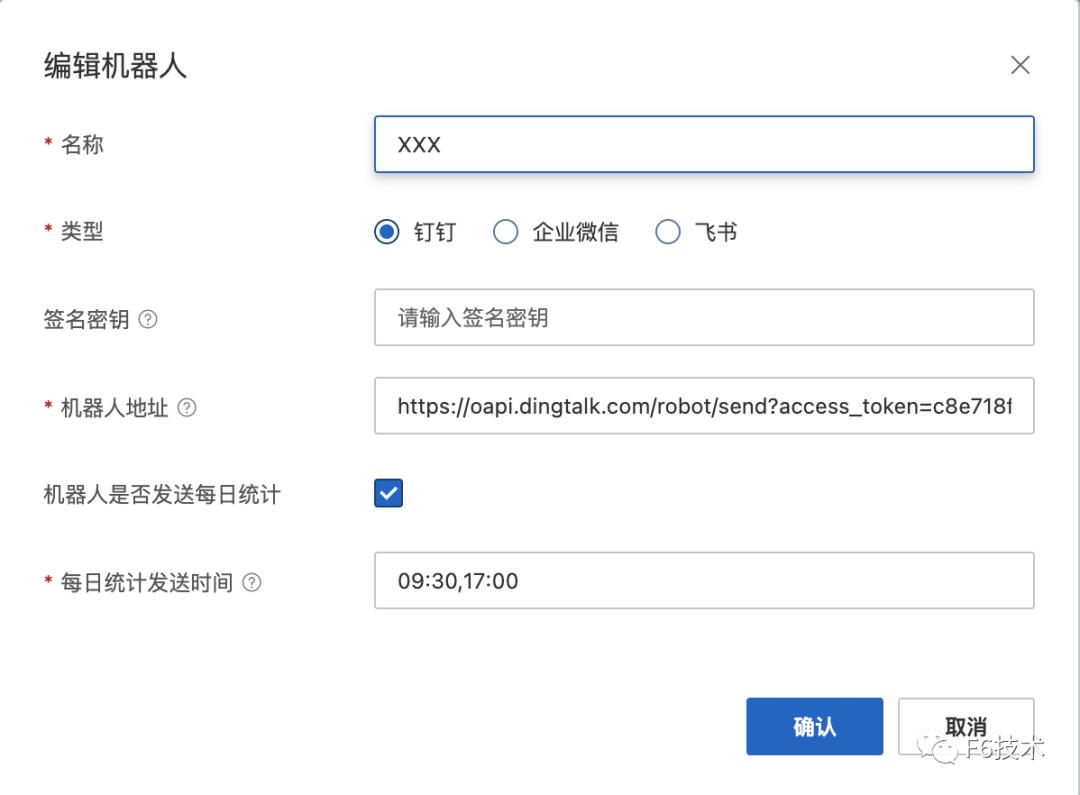
2. 给每个研发团队分别配置通知策略,通知策略筛选告警信息里的 team 字段,并绑定对应的钉钉群机器人联系人。
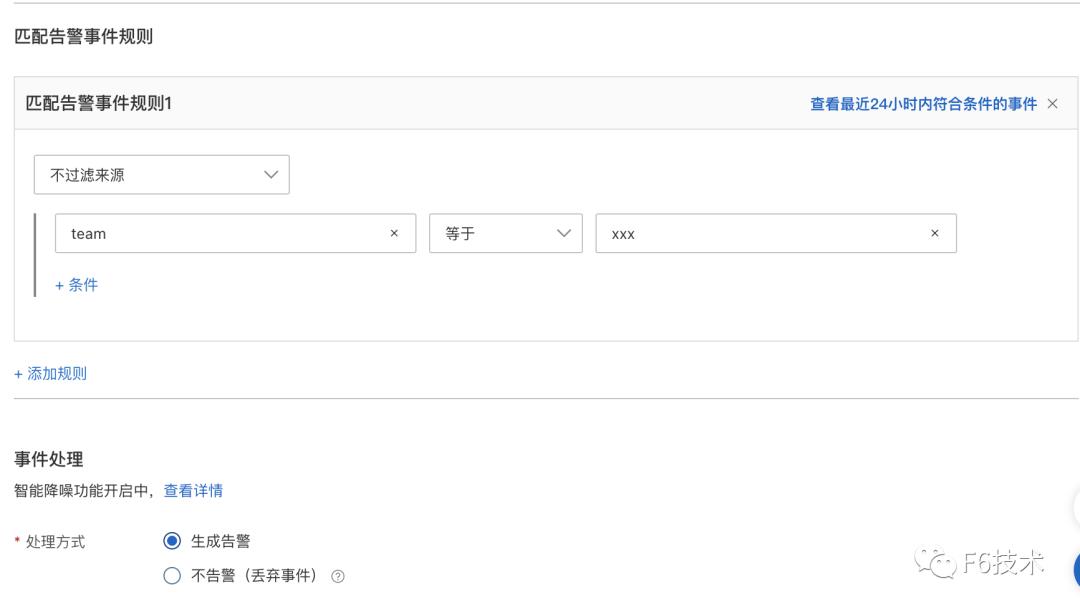
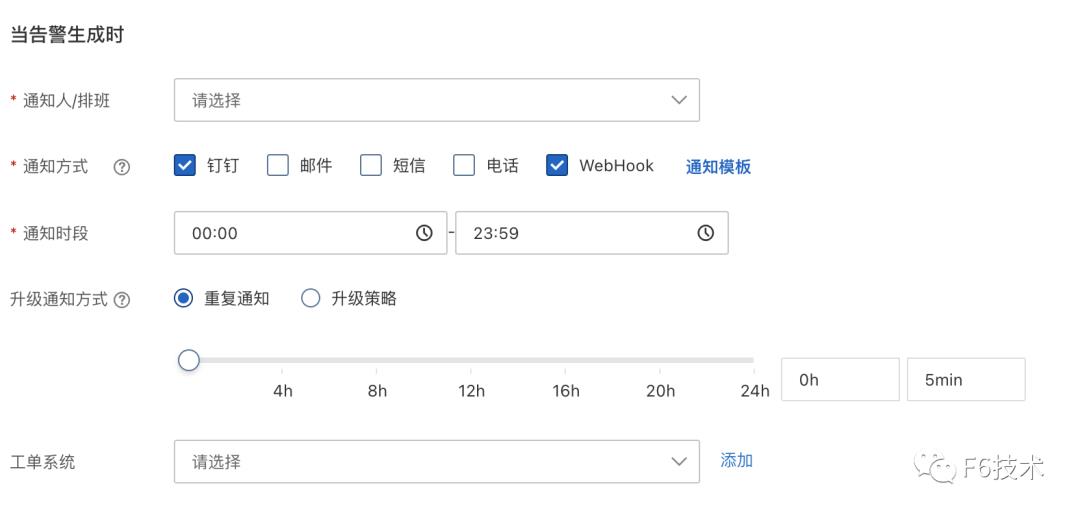
通过这个方式,实现了应用的告警直接发送到对应的研发团队,节省了信息筛选和二次转派的时间,提高了告警处理效率。
效果如下:
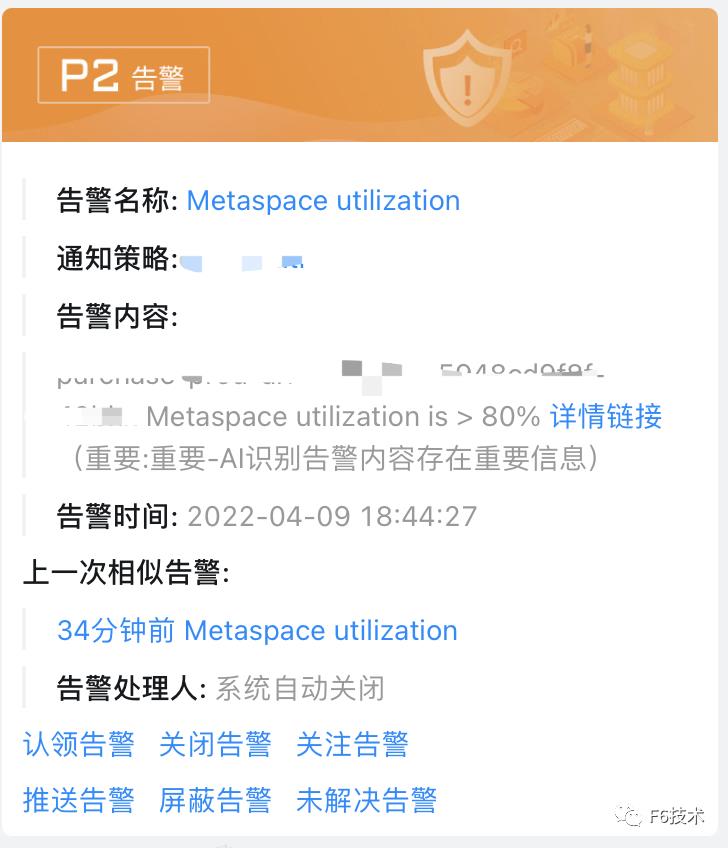
ARMS 告警运维中心支持接入 grafana,zabbix,arms 等多种数据源,具有告警分派和认领,告警汇总去重,通过升级通知方式对长时间没有处理的告警进行多次提醒,或升级通知到领导,保证告警及时解决。
本文为阿里云原创内容,未经允许不得转载。
以上是关于云原生可观测性之Grafana Loki介绍的主要内容,如果未能解决你的问题,请参考以下文章