RabbitMQ集群架构笔记
Posted AbtYee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RabbitMQ集群架构笔记相关的知识,希望对你有一定的参考价值。
RabbitMQ集群架构笔记
RabbitMQ 四种集群架构
主备模式
-
warren(兔子窝),一个主/备方案(主节点如果挂了,从节点提供服务,和ActiveMQ利用Zookeeper做主/备一样)
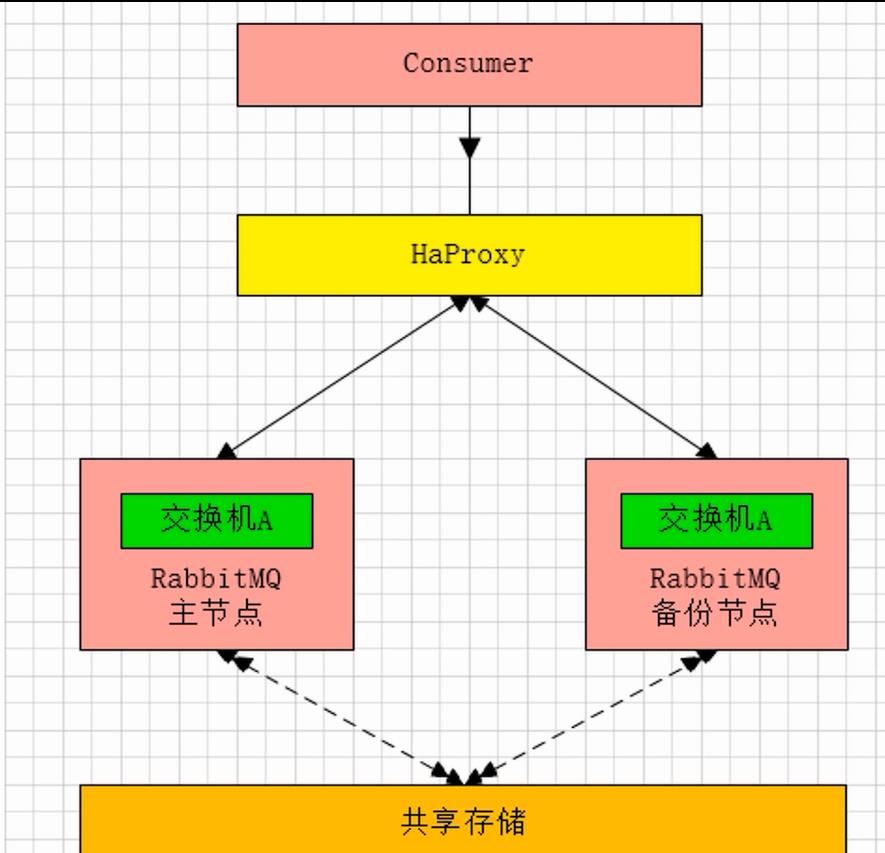
图中的consumer不仅仅是消费者,可以理解为需求方,通过HaProxy默认路由到主节点,默认也是master提供服务,而当master出现故障之后,下一次路由在HaProxy里配置了一些规则后,它会帮我们路由到备份节点,备份节点就会升级为主节点,而当原主节点修复完成后便会加入该集群,成为新主节点的备份节点
-
HaProxy配置
listen rabbitma_cluster bind 0.0.0.0:5672 # 配置TCP模式 mode tcp # 简单的轮询 balance roundrobin # 主节点 server bhz76 192.168.11.76:5672 check inter 5000 rise 2 fall 2 server bhz77 192.168.11.77:5672 backup check inter 5000 rise 2 fall 2 # 备用节点
远程模式
-
远距离通信和复制,可以实现双活的一种模式,简称Shovel模式,并不常用,因为可靠性还有待提高,并且配置也比较麻烦
-
所谓Shovel就是我们可以把消息进行不同数据中心的复制工作,可以跨地域的让两个mq集群互联
-
架构模型
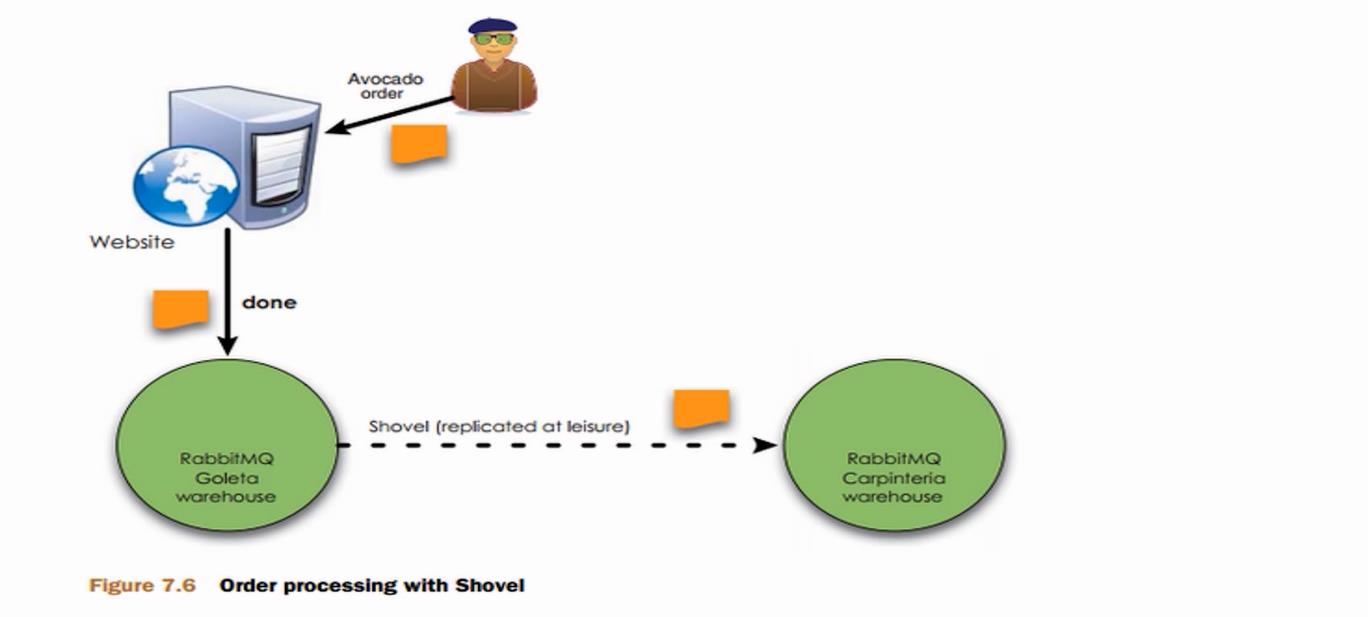
-
Shovel集群的拓扑图
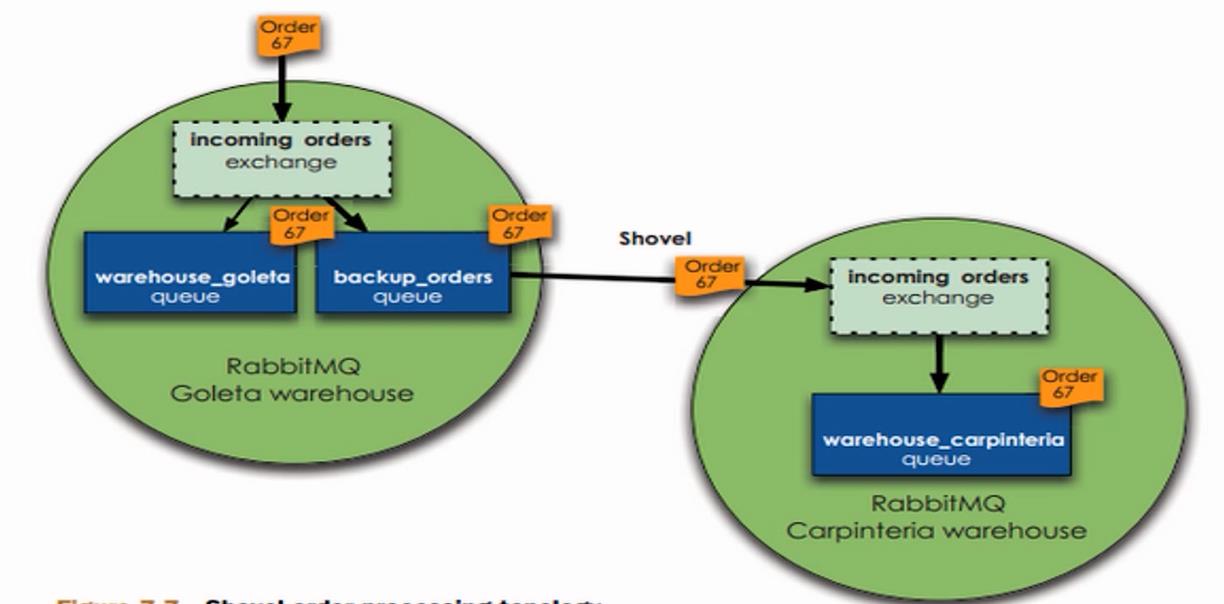
这种集群可以帮我们做路由转换,也就是说当第一个集群消费不过来的时候,可以转到第二个,当第一个出现问题的时候也可以转到第二个
-
配置步骤:
-
1、启动RabbitMQ插件:
rabbitmq-plugins enable amqp_client rabbitmq-plugins enable rabbitmq_shovel -
2、创建rabbitmq.config文件
touch /etc/rabbitmq/rabbitmq.config -
3、添加配置进rabbitmq.config

-
4、源与目的地服务器使用相同的配置文件(rabbitmq.config)
-
镜像模式(最主流)
- 集群模式非常经典的就是Mirror镜像模式,保证100%数据不丢失
- 在实际工作中用的最多,并且实现集群非常的简单,一般互联网大厂都会构建这种镜像集群模式
Mirror镜像队列
-
高可靠
当数据发送过来时,会同步到队中的镜像集群中所有的节点,都会做一个数据备份存储
-
数据同步
由于底层是erlang写的,天然就用交换机的方式,与原生socket一样低的延迟,所以在同步的时候性能是非常好的
-
奇数个节点
如果发生脑裂,更快的能够在选举的时候将master选举出来
-
架构图
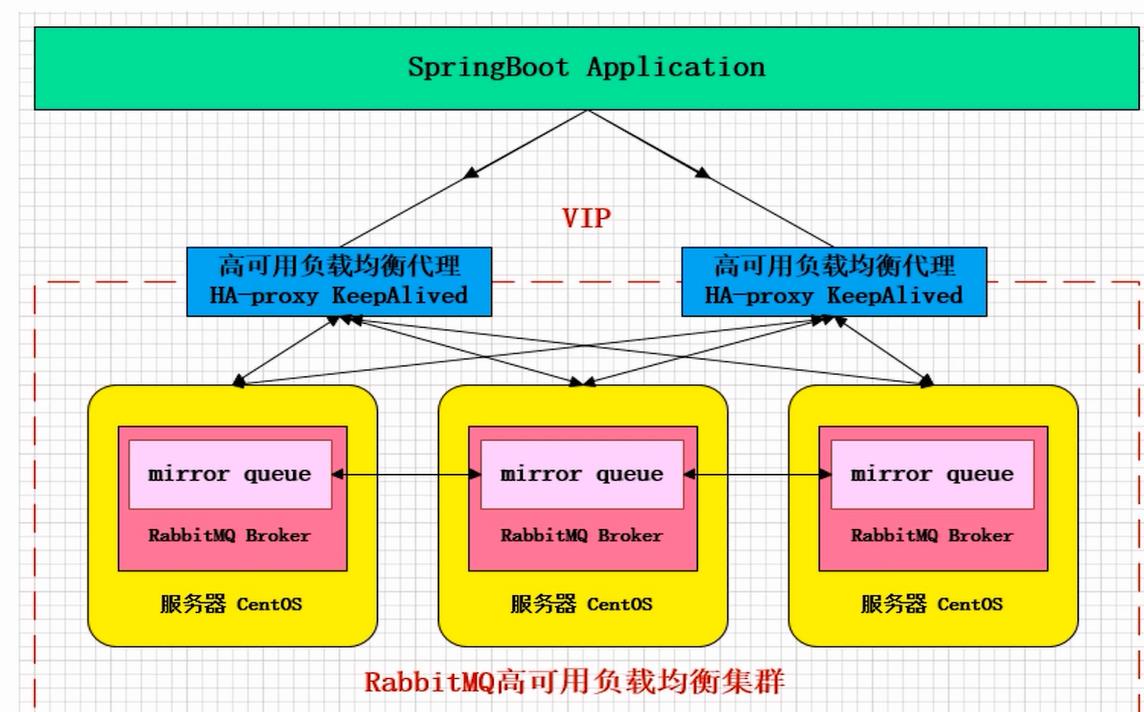
这种架构的缺陷是不能支持横向的扩展,因为其数据存储是有限的,当在高峰期时,流量非常大,而消费者消费的速度并没有这么快时,消息就会堆积到镜像队列上,而此时横向扩容是无意义的,横向再扩展一份反倒增加了rabbitmq的负担
多活模式
-
这种模式也是实现异地数据复制的主流模式,因为Shovel模式配置比较复杂,所以一般来说实现异地集群都是使用这种双活,或者多活模型来实现的
-
这种模型需要依赖RabbitMQ的federation插件,可以实现持续的可靠的AMQP数据通信,多活模式实际配置与应用非常简单
-
RabbitMQ部署架构采用双中心模式(多中心),那么在两套(或多套)数据中心各部署一套RabbitMQ集群,各中心的RabbitMQ服务除了需要为业务提供正常的消息服务外,中心之间还需要实现部分队列消息共享
-
架构图
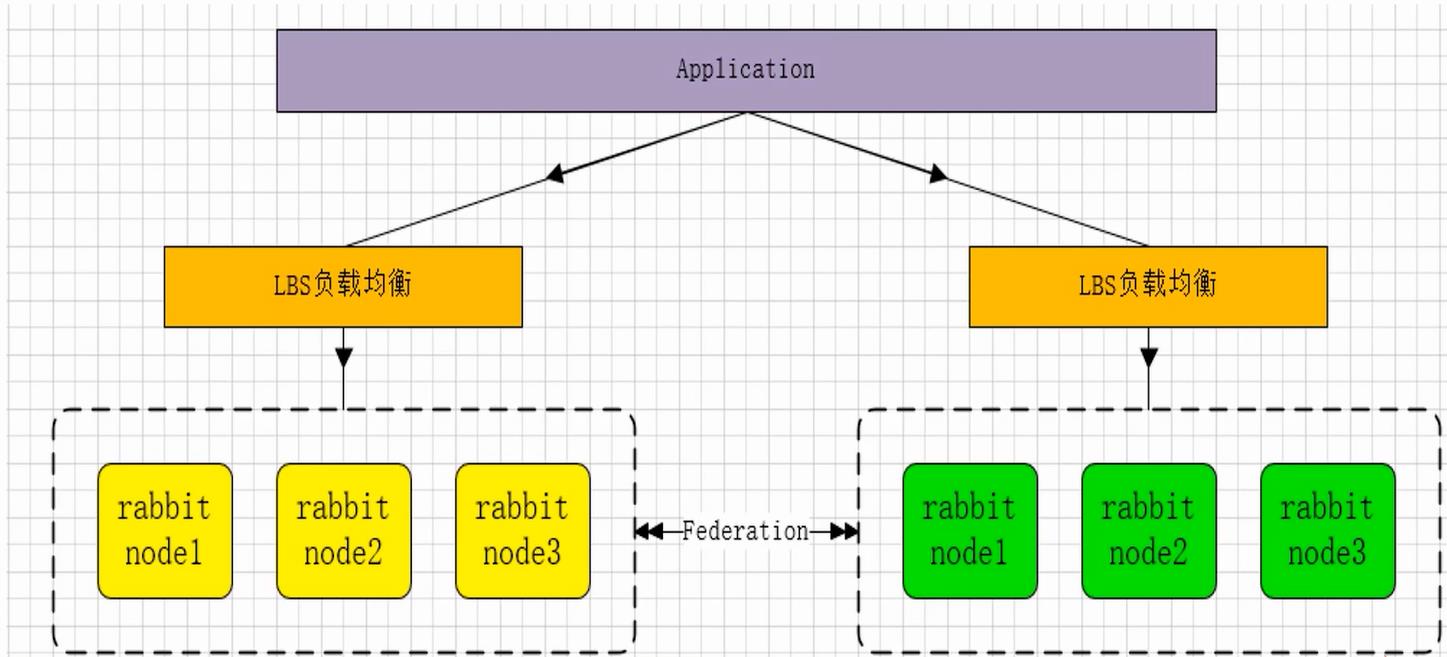
-
Federation插件
Federation插件是一个不需要构建Cluster,而在Brokers之间传输消息的高性能插件,Federation插件可以在Brokers或者Cluster之间传输消息,连接的双方可以使用不同的users和virtual hosts,双方也可以使用版本不同的RabbitMQ和Erlang。Federation插件使用AMQP协议通讯,可以接受不连续的传输
Federation Exchanges,可以看出Downstream从Upstream主动拉取消息,但并不是拉取所有消息,必须是在Downstream上已经明确定义Bindings关系的Exchange,也就是有实际的物理Queue来接收消息,才会从Upstream拉取消息到Downstream。使用AMQP协议实施代理间通信,Downstream会将绑定关系组合在一起,绑定/解除绑定命令将发送到Upstream交换机。因此,Federation Exchange只接收具有订阅的消息:
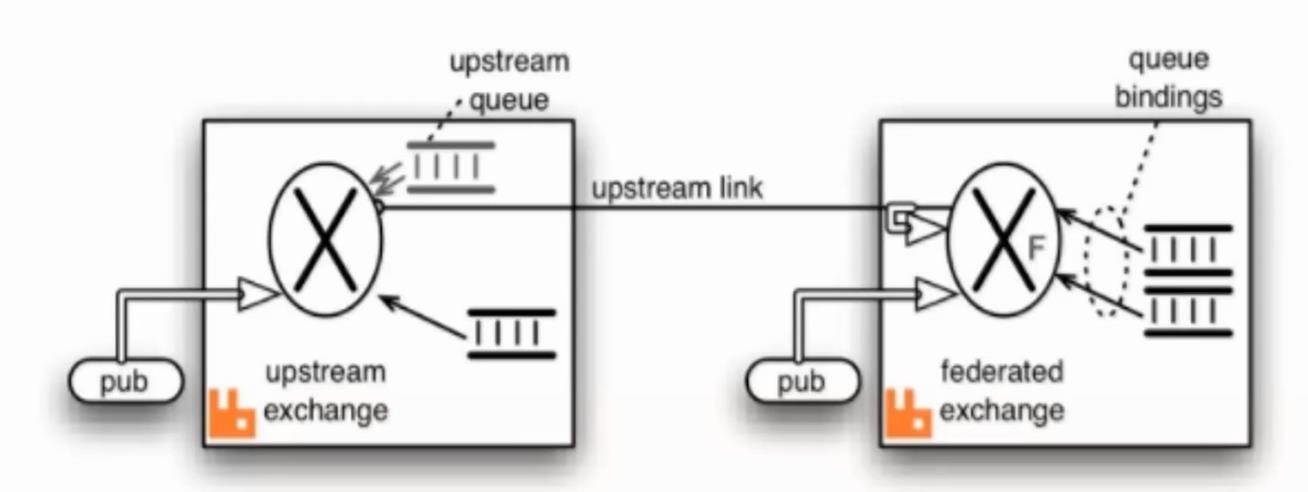
rabbitmq系统学习集群架构
RabbitMQ集群架构模式
主备模式
- 实现RabbitMQ的高可用集群,一般在并发和数据量不高的情况下,这种模型非常的好用且简单。主备模式也称为Warren模式
- HaProxy配置
listen rabbitmq_cluster
bind 0.0.0.0:5672 # 配置TCP模式
mode tcp #简单的轮询
balance roundrobin #主节点
server bhz76 192.168.11.76:5672 check inter 5000 rise 2 fall 3
server bhz77 192.168.11.77:5672 backup check inter 5000 rise 2 fall 3 # 备用节点
# 备注: rabbitmq集群节点配置 #inter 每隔五秒对mq集群做健康检查,2次正确证明服务器可用,3次失败证明服务器不可用,并且配置主备机制远程模式
- 远程模式可以实现双活的一种模式,简称Shovel模式,所谓Shovel就是我们可以把消息进行不同数据中心的复制工作,我们可以跨地域的让两个mq集群互联
镜像模式(用的最多)
- 集群模式非常经典的就是Mirror镜像模式,保证100%数据不丢失,在实际工作中用的最多。并且实现集群非常的简单
异地多活模式
- 实现异地数据复制的主流模式,需要依赖rabbitmq的federation插件
- 采用双中心模式,需要在两套或多套数据中心各部署一套RabbitMQ集群,各中心RabbitMQ服务除了需要为业务提供正常的消息服务外,中心之间还需要实现部分队列消息共享
安装
- /etc/hostname 取名
- 复制/var/lib/rabbitmq/.erlang.cookie 文件到每台服务器
- rabbitmq-server -detached
- rabbitmqctl stop_app
- rabbitmqctl join_cluster --ram [email protected] #主机名,ram内存方式存储,模式磁盘方式
- rabbitmqctl start_app
- 移除节点 rabbitmqctl forget_cluster_node [email protected]
- 修改集群名称 rabbitmqctl set_cluster_name rabbitmq_cluster1
- 查看集群状态 rabbitmqctl cluster_status
Haproxy
- 高可用负载均衡以及基于TCP(第四层)和HTTP(第七层)应用的代理软件,支持虚拟主机。
- 单进程,时间驱动模型显著降低了上下文切换的开销以及内存占用
- 在任何可用的情况下,单缓冲机制能以不复制任何数据的方式完成读写操作,这会节约大量的CPU时钟周期及内存宽带
KeepAlived
- 通过VRRP协议实现高可用功能,VRRP是Virtual Router RedundancyProtocol(虚拟路由器冗余协议)的缩写,它的出现目的是为了解决静态路由单点故障问题,它能够保证党个别节点宕机时,整个网络可以不间断地运行,所以,Keepalived一方面具有配置管理LVS负载均衡的功能,同时还具有对LVS下面节点进行健康检查的功能,另一方面也可以实现系统网络服务的高可用功能
延迟插件
消息的延迟推送、定时任务(消息)的执行。包括一些消息重试策略的配置使用,以及用于业务削峰限流、降级的异步延迟消息机制,都是延迟队列的实际应用场景
rabbitmq插件库地址
www.rabbitmq.com/community-plugins.html
下载插件rabbitmq_delayed_message_exchange
互联网大厂SET架构
BAT/TMD大厂单元化架构设计衍变
- 单个大型分布式体系的集群,通过加机器+集群内部拆分(kv/mq、Mysql等),虽然具备一定的可扩展性,但是随着业务量的进一步增长,整个集群规模逐渐变得巨大,从而会在某个点上达到瓶颈,无法满足扩展性需求,并且大集群内核心服务出现问题,会影响全网所有用户
- 如滴滴打车、美团外卖,订单量巨大,每天上2000w,会面临以下问题
- 容灾问题
- 资源扩展问题
- 大集群拆分问题
- 同城“双活”架构
- 两地三中心架构
- SET化方案目标
- 业务:解决业务遇到的扩展性和容灾等需求,支撑业务的高速发展
- 通用性:架构侧形成统一通用的解决方案,方便各业务接入使用
SET化架构策略
- SET化架构设计
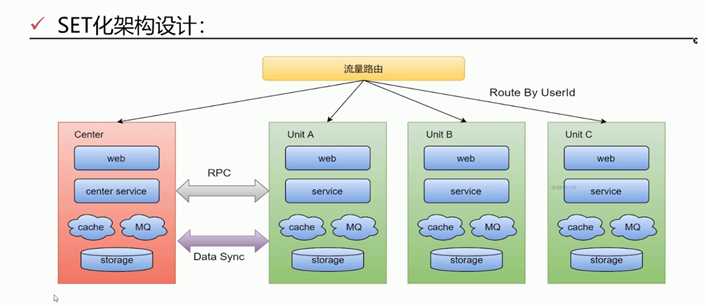
- 流量路由
- 按照特殊的key(通常为userid)进行路由,判断某次请求该路由到中心集群还是单元化集群;
- 中心集群:
- 未进行单元化改造的服务(通常不在核心交易链路,比如供应链系统)称为中心集群,跟当前架构保持一致
- 单元化集群:
- 每个单元化集群只负责本单元内的流量处理,以实现流量拆分以及故障隔离
- 每个单元化集群,前期只储存本单元产生的交易数据,后续会做双向数据同步,实现容灾切换需求
- 中间件(RPC、KV、MQ等):
- RPC:对于SET服务,调用封闭在SET内;对于非SET服务,沿用现有路由逻辑
- KV:支持分SET的数据生产和查询
- MQ:支持分SET的消息生产和消费
- 数据同步:
- 全局数据(数据量小且变化不大,比如商家的菜品数据)部署在中心集群,其他单元化集群同步全局数据到本单元化内
- 未来演变为异地多活架构时,各单元化集群数据需要进行双向同步来实现容灾需要
- 集装箱式扩展
- SET的封装性支持更灵活的部署扩展性,比如SET一键创建/下线,SET一键发布等
- SET化架构图
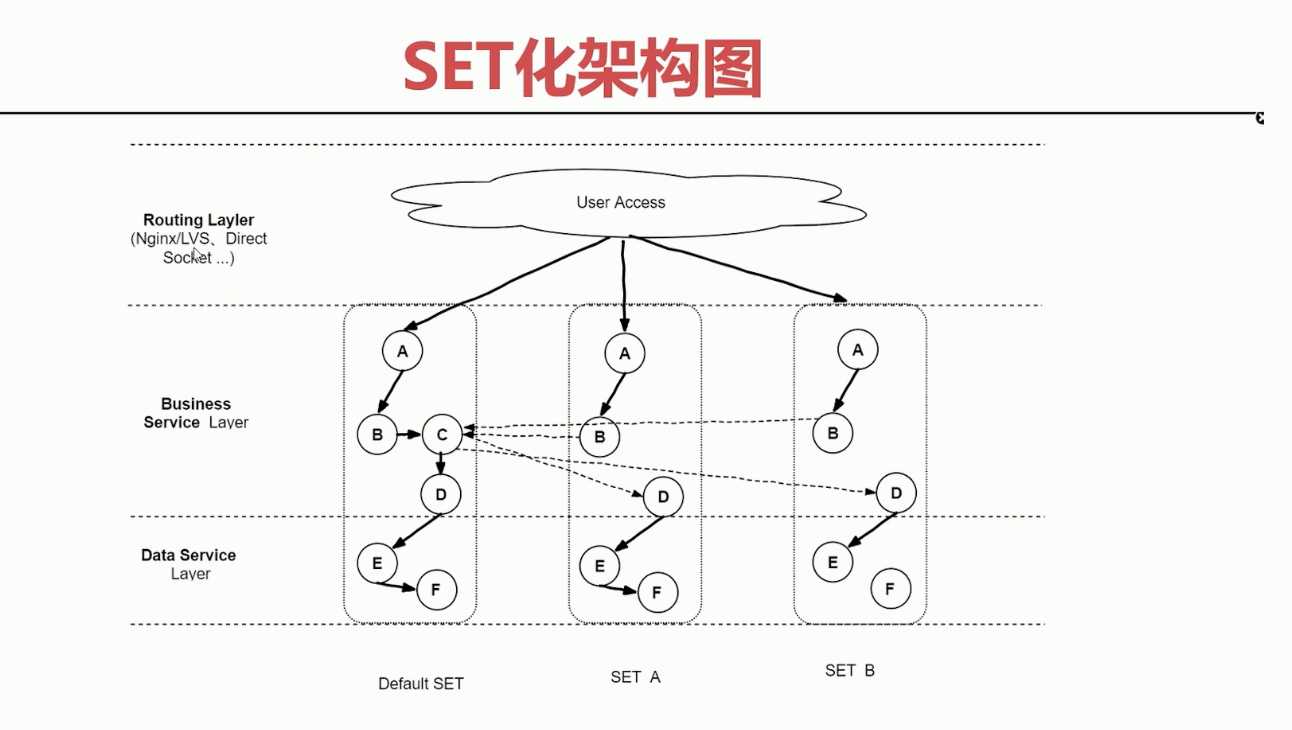
未完待续...
以上是关于RabbitMQ集群架构笔记的主要内容,如果未能解决你的问题,请参考以下文章