HadoopHDFS高可用与高扩展原理分析(HA架构与Federation机制)
Posted ccql
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HadoopHDFS高可用与高扩展原理分析(HA架构与Federation机制)相关的知识,希望对你有一定的参考价值。
文章目录
一、HDFS的高可用性(HA架构)
为保证HDFS的高可用性,即当NameNode节点机器出现故障而导致宕机时整个系统依旧可以维持运转,那么只需要存在多个NameNode节点即可,当前节点(Active NameNode)宕机的时候就立即切换到另外的备用节点(Standby NameNode)。这就所谓的HA(High Available)结构的基础架构和想法,那么为了保证这一点则需要Standby NameNode随时做好准备,使其与Active NameNode的节点状态保持同步(元数据保持一致)。
HA架构中存在两个NameNode,一个是Active NameNode,是当前正在使用的NameNode;另一个是Standby NameNode,是备用的NameNode。在HA架构中不存在Secondary NameNode,因为Standby NameNode会代替它的功能,将edits文件整合为fsimage文件。
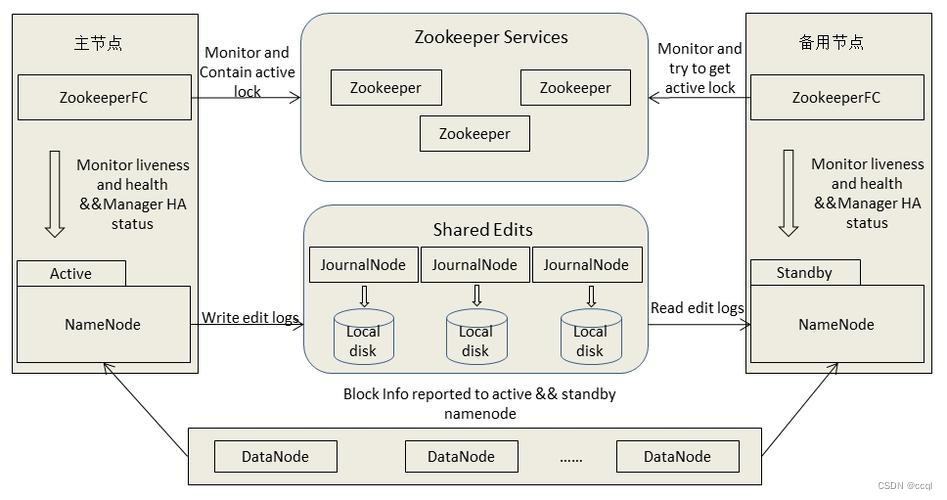
如上图所示,DataNode需要向Active NameNode和Standby NameNode分别发送block块的位置信息,且HA结构中还构建了一组Journal Nodes用以同步Active NameNode和Standby NameNode的edits文件信息,由于fsimage文件是由edits文件合并生成的,因此保证两者edits文件的同步即可。
图中的Zookeeper是为了实现自动切换NameNode功能,当多个NameNode启动的时候会分别向Zookeeper中注册一个临时节点,当它挂掉的时候,这个临时节点也就消失了,这是Zookeeper的特性。如果Zookeeper的监视器注意到当前的Active NameNode出现故障,就会立即将Standby NameNode转换为Active NameNode,将原本故障的Active NameNode转换为Standby NameNode,即使后续该节点故障被排除,也不会再切换回来,直到当前节点也出现故障才会切换回原来那个节点。
二、HDFS的高扩展性(Federation机制)
HDFS的Federation机制可以解决单一NameNode存在的问题,当集群中数据增长到一定规模后,NameNode 进程占用的内存可能会达到成百上千 GB,此时NameNode成了集群的性能瓶颈。通俗的讲,集群启动时DataNode会向NameNode上报所有的Block块信息,每个块(无论大小)对象约占150byte,而NameNode的内存是有限的,当HDFS文件愈来愈多的时候,NameNode就会成为集群的短板(这也是为什么HDFS不适合存储小文件的原因)。使用多个NameNode,每个NameNode负责一个命令空间,这种设计可提供以下特性:
- HDFS集群扩展性。多个NameNode分管一部分目录,使得一个集群可以扩展到更多节点,不再因内存的限制制约文件存储数目。
- 性能更高效。多个NameNode管理不同的数据,且同时对外提供服务,将为用户提供更高的读写吞吐率。
- 良好的隔离性。用户可根据需要将不同业务数据交由不同NameNode管理,这样不同业务之间影响很小。
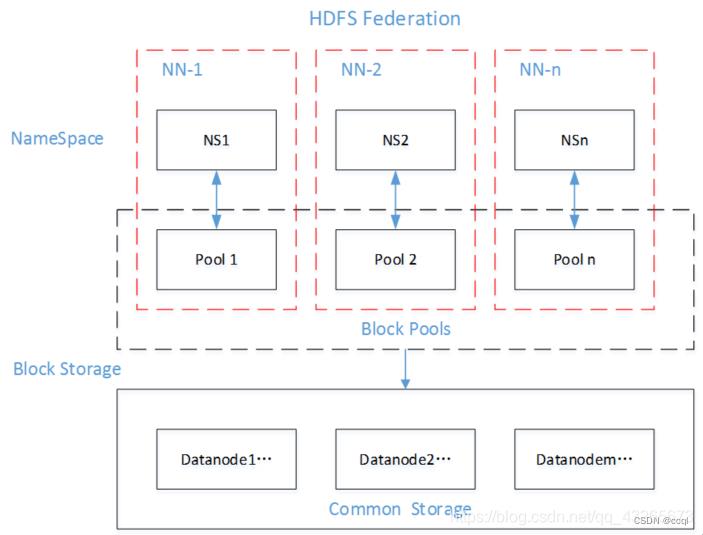
HDFS的Federation机制下存在多个NameNode,也就意味着存在多个NameSpace(命名空间),不同的NameNode分管不同的NameSpace。被同一个NameNode所管理的数据都在同一个NameSpace下,一个NameSpace对应一个Block Pool(所有数据块的集合),但每个NameNode又共用全部的DataNode资源(不同的块存储分别在不同的DataNode中)。
三、HA架构 + Federation机制
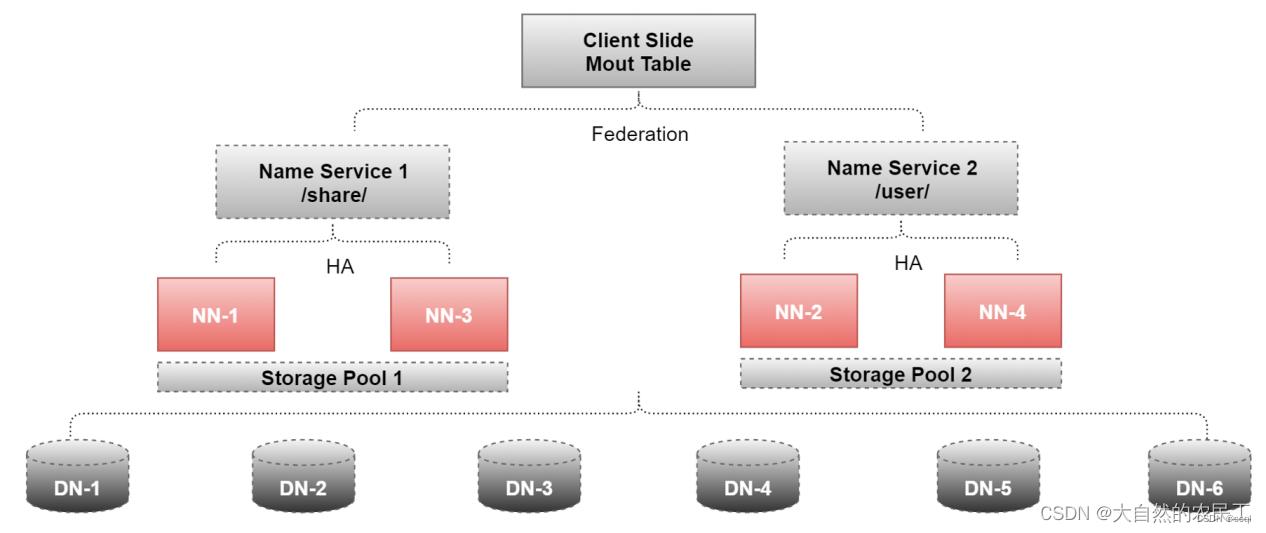
为了同时解决NameNode的单点故障问题和横向扩容问题,超大规模的集群一般都会采用HA+Federation的部署方案。从图中可以看到每个Federation机制下的NameNode都是由一个Active NameNode和一个Standby NameNode一起构成的HA架构,这样既考虑到了HDFS的高扩展性,又顾及了HDFS的高可用性。
MySQLMySQL复制与高可用水平扩展架构实战
本文导读
本文简单介绍几种复制方式复制在生产中解决的实际问题,MySQL复制的配置流程和MySQL复制类型,不会深入到 MTBF、MTTR平均故障间隔、平均修复时间等等以及MMM 集群架构、MHA 集群架构等等产线实际应用的架构,也不会深入复制的原理,本文主要是带读者建立完整的MySQL 复制的知识体系,后续会通过单独的文章讲解:
MySQL 复制工作原理(待补充)、MySQL 高可用架构与企业级实战(待补充)。
一、什么是MySQL复制
1、什么是复制
MySQL的复制是构建大规模、高性能应用程序的基础,称为“水平扩展”架构。生产环境通常为服务器配置一个或多个备用数据库以同步数据。
复制是将一台服务器(即MySQL数据库)的数据与其他服务器同步。
一个主数据库的数据可以同步到多个备用数据库,备用数据库本身也可以配置为另一个服务器的主数据库。主数据库和备用数据库之间有许多不同的组合。
可以通过复制将读取操作指向备用数据库,以获得更好的读取扩展。
但是,对于写操作,复制不适合扩展写操作。在一个主数据库和多个从数据库的架构中,写入操作将被多次执行。此时,整个系统的性能取决于写入操作的最慢部分。

注:本文为了追求正确 master 改为 main,slave 改为 secondary。
2、MySQL数据库的复制方式
MySQL支持两种复制方法:基于行的复制和基于语句的复制。
基于语句的复制(也称为逻辑复制)自 MySQL 3.23 以来就已经存在,基于行的复制是在 MySQL 5.1 中增加的新特性
两种方法都通过在主数据库上记录二进制日志并在备用数据库上同步写日志来实现异步数据复制
这意味着备用数据库上的数据可能在同一时间点与主数据库不一致,主数据库和备用数据库之间的延迟无法保证。一些大型语句可能会导致备用数据库延迟几秒钟、几分钟甚至几小时。
3、复制可以解决的问题
3.1、数据分布
MySQL 引入的基于行的复制后,比传统的基于语句的复制模式带来更大的带宽压力。这种情况对于复制操作可以随时停止或开始,并在不同的地理位置(如两地三中心)分发数据备份。
3.2、负载均衡
MySQL复制可以将读取操作分发到多个服务器,以优化读取密集型应用程序。实施方便,可以通过简单的代码修改来实现负载平衡。
3.3、备份
对于备份,复制是一项重要的技术补充(但是不能代替redo log、bin log等)。
3.4、高可用性和故障切换
复制可以帮助应用程序避免MySQL单点故障(例如两地三中心:生产中心、同城容灾中心、异地容灾中心),故障切换系统可以显著减少停机时间。
3.5、MySQL版本切换
使用更高版本的MySQL作为备用数据库,以确保在升级所有实例之前可以在备用数据库中按预期执行查询,最后逐步切换主库。
这里面一般使用的方法分为4步,1、首先主备都使用低版本库,2、切换备库的时候,双写主备库,查还是低版本,3、切换备库的时候,双写主备库,查使用高版本备库,4、完全使用没问题的主备高版本库。
二、MySQL 复制的配置实战
MySQL复制实现非常简单。基本步骤如下:
1、创建复制所需的帐户和权限;
在 main(MASTER )数据库中创建一个用户,并给予其适当的权限。备用数据库I/O线程使用此用户名连接到主数据库,并读取其二进制日志。
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO repl@192.168.0.% IDENTIFIED BY password,;
复制代码
2、要从主库 main 复制数据副本,可以使用逻辑备份工具mysqldump、mysqlpump或物理备份工具克隆插件;(配置主库和备库一般是DBA的工作)
3、使用命令 CHANGE MASTER TO 建立复制关系(启动复制)
4、使用命令 SHOW SLAVE STATUS 观察复制状态(当执行完 CHANGE MASTER TO ,需要通过 SHOW SLAVE STATUS 检查复制是否正确)
三、如何避免单点数据库服务器失效
MySQL 复制一般分为以下几种类型:异步复制、半同步复制、多源复制、延迟复制。

本文简单介绍几种复制方式,不会深入到 MTBF/(MTBF+MTTR),平均故障间隔、平均修复时间以及MMM 集群架构、MHA 集群架构等等产线实际应用的架构,也不会深入复制的原理,本文主要是带读者建立完整的MySQL 复制的知识体系,后续会通过单独的文章讲解:
MySQL 复制工作原理(待补充)、MySQL 高可用架构与企业级实战(待补充)。
1、异步复制(async replication)
在异步复制中,主库 main 不关心从库 secondary 是否接收二进制日志,因此主库 main不依赖从库 secondary 。您可以认为 main 和 secondary 是两个独立工作的服务器,数据最终将通过二进制日志保持一致。
异步复制性能最好,因为对数据库本身几乎没有开销,除非主从延迟非常大,并且转储线程需要读取大量二进制日志文件。
如果企业对数据一致性的要求较低,则可以在发生故障时容忍数据丢失。推荐异步复制,它具有最好的性能(例如微博业务,虽然它对性能要求很高,但通常可以容忍数据丢失)。而核心交易业务系统通常最关心数据安全,如监控业务和报警系统。

2、半同步复制(semi-synchronous replication)
半同步复制分为有损和无损,有损半同步一般没有使用场景。半同步复制要求在主事务提交过程中至少有 N 个从库 secondary 接收二进制日志,这样当主库 main 停机时,至少有 N 台从库 secondary 中的数据是完整的。

无损半同步复制 WAIT ACK 发生在事务提交之前。即使从库 secondary 没有收到二进制日志,主库 main 也已关闭,由于异常尚未提交,因此数据本身对外界不可见,也不存在丢失的问题。
因此,对于任何有数据一致性要求的业务,如核心订单业务、银行、保险、证券等与资金密切相关的业务,必须使用无损半同步复制。通过这种方式,数据是安全和有保障的,并且即使发生故障,从库 secondary 也拥有完整的数据副本。
3、多源复制(multisource replication)
异步复制与半同步复制都是一个主库 main 都对应于 N 个从库 secondary 。MySQL还支持N个主机对应1个从库。这种架构称为多源复制。
多源复制允许将不同MySQL实例上的数据同步到一个MySQL实例,便于在一个从库 secondary 上进行一些统计查询,例如常见的OLAP业务查询。

4、延迟复制(delayed replication)
延迟复制允许从库 secondary 延迟接收的二进制日志,为了避免主服务器上的错误操作,它会立即同步到从库 secondary ,导致数据完全丢失。
-- 设置了 Slave 落后 Master 服务器3小时
CHANGE MASTER TO master_delay = 10800
例如,您可以设置延迟一天的待机机器,如果出现在线错误操作,如DROP TABLE和DROP DATABASE,用户可以获得一天的快照,快速恢复数据。
对于金融行业来说,延迟复制是备份设计中必须考虑的一个体系结构部分(博主就是使用多源复制+延迟复制+无损半同步复制的)。
总结
本文简单介绍几种复制方式复制在生产中解决的实际问题,MySQL复制的配置流程和MySQL复制类型,不会深入到 MTBF、MTTR平均故障间隔、平均修复时间等等以及MMM 集群架构、MHA 集群架构等等产线实际应用的架构,也不会深入复制的原理,本文主要是带读者建立完整的MySQL 复制的知识体系,后续会通过单独的文章讲解:
MySQL 复制工作原理(待补充)、MySQL 高可用架构与企业级实战(待补充)。
以上是关于HadoopHDFS高可用与高扩展原理分析(HA架构与Federation机制)的主要内容,如果未能解决你的问题,请参考以下文章
Apache hadoop namenode ha和yarn ha ---HDFS高可用性