Hadoop大数据原理 - 架构演进
Posted 小爱玄策
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop大数据原理 - 架构演进相关的知识,希望对你有一定的参考价值。
文章目录
1. 软件的发展
传统的软件开发已经经历了非常久的时间,从C/S到B/S架构的演进是过去20年以来感受比较强的一个变化。逐渐开始“轻”客户端,“重”服务端,使得软件服务的升级和维护变得越来越便利,当然这样的便利性也带来了一些问题,那就是当客户端访问数据量大的时候,服务端可能无法承受而崩溃,导致服务无法使用,数据库异常等问题。
当然,随着互联网的发展,B/S架构能够面向未知的用户群体,实现用户量的疯狂扩张,用户只需要操作系统和浏览器就能够进行服务访问。
近10年还有一个明显的改变就是,大家开始从PC向手机端迁移,根据摩尔定律,手机能够进行越来越强大的计算,现在几乎人手1部手机,我们进入了移动互联网时代。
社会发展越来越科技化,视频监控等信息采集这些基础设施越来越完善,运营商/软件企业能够获取到越来越多的数据(不讨论脱敏与否,也不讨论大数据分析和画像能够对脱敏数据的某些数据进行恢复和精确搜索到具体的人或事物),数据开始呈指数增长。
数据越来越多,对我们分析数据的要求也越来越高了,以前我们传统的软件,都是主要考虑进行纵向提高服务器的配置,商业级的服务器不够用,就升级小型机,小型机不够用,就升级中型机,还不够,升级大型机,升级超级计算机。虽然根据摩尔定律,硬件的处理能力每18个月翻一倍,总能造出更强大的计算机。但是这些年,软件的增长速度目前比硬件更快,大多数软件工程师接到需求后,并没有那么多合适的硬件来支撑自己的服务要求,所以这种思路并不适合互联网的技术要求。Google、Facebook、阿里巴巴这些网站每天需要处理数十亿次的用户请求、产生上百 PB 的数据,不可能有一台计算机能够支撑起这么大的计算需求。
互联网公司开始换一种思路来解决问题,从过去的纵向提高计算机处理能力,变为横向扩展计算机,目前的互联网巨头们,都经历了这样的成长过程。
2. 大数据技术的出现
两台计算机要想合作构成一个系统,必须重新进行架构设计。就是现在互联网企业广泛使用的:负载均衡、分布式缓存、分布式数据库、分布式服务等各种分布式系统。
当这些分布式技术满足互联网的日常业务需求时,对离线数据和存量数据的处理就被提了出来,当时这些分布式技术并不能满足要求,于是大数据技术就出现了。
大数据技术更为关注数据,所以相关的架构设计也围绕数据展开,如何存储、计算、传输大规模的数据是要考虑的核心要素。
3. 移动计算
在大数据行业,有一句耳熟能详的话,移动计算比移动数据更划算。
下面介绍移动计算程序到数据所在位置进行计算是如何实现的:
-
将待处理的大规模数据存储在服务器集群的所有服务器上,主要使用 HDFS 分布式文件存储系统,将文件分成很多块(Block),以块为单位存储在集群的服务器上;
-
大数据引擎根据集群里不同服务器的计算能力,在每台服务器上启动若干分布式任务执行进程,这些进程会等待给它们分配执行任务;
-
使用大数据计算框架支持的编程模型进行编程,例如 Hadoop 的 MapReduce 编程模型,或者 Spark 的 RDD 编程模型;
-
应用程序编写好以后,进行打包,MapReduce 和 Spark 都是在 JVM 环境中运行,所以打包出来的是一个 Java 的 JAR 包;
-
用 Hadoop 或者 Spark 的启动命令执行这个应用程序的 JAR 包,首先执行引擎会解析程序要处理的数据输入路径,根据输入数据量的大小,将数据分成若干片(Split),每一个数据片都分配给一个任务执行进程去处理;
-
任务执行进程收到分配的任务后,检查自己是否有任务对应的程序包,如果没有就去下载程序包,下载以后通过反射的方式加载程序。到这里,最重要的一步,也就是移动计算就完成了。
-
加载程序后,任务执行进程根据分配的数据片的文件地址和数据在文件内的偏移量读取数据,并把数据输入给应用程序相应的方法去执行,从而实现在分布式服务器集群中移动计算程序,对大规模数据进行并行处理的计算目标。
4. 编程框架Hadoop
大数据技术将移动计算这一编程技巧上升到编程模型的高度,并开发了相应的编程框架,使开发人员只需关注大数据的算法实现,不必关注如何将这个算法在分布式的环境中执行,极大地简化了大数据的开发难度,统一了大数据的开发方式,使大数据的开发门槛直线下降,这也让更多的大数据工程师将精力集中到业务和分析中去,全力去挖掘数据的价值。
Hadoop是一个开源框架,允许使用简单的编程模型在跨计算机集群的分布式环境中存储和处理大数据。它的设计是从单个服务器扩展到数千个机器,每个都提供本地计算和存储。它由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统,其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
Hadoop 依赖于社区服务,生态很好,任何人都可以使用。
Hadoop主要有以下几个优点:
-
高可靠性:按位存储和处理数据能力的高可靠性;
-
高扩展性:在可用的计算机集群间分配数据并完成计算任务的,这些集群可方便灵活的方式扩展到数以千计的节点;
-
高效性:能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快;
-
高容错性:自动保存数据的多个副本,并且能够自动将失败的任务重新分配;
-
低成本:集群允许通过部署普通廉价的机器组成集群来处理大数据,以至于成本很低。看重的是集群整体能力;
Hadoop带有用Java语言编写的框架,因此运行在Linux生产平台上是非常理想的。Hadoop上的应用程序也可以使用C++语言编写。
大数据学习:HDFS架构演进之路
Hadoop的核心三大组件之一,HDFS主要负责分布式文件存储,将大规模的数据存储任务拆分成小块,分布到不同的机器上,从而以低成本的方式解决大数据存储问题。今天的大数据学习分享,我们就主要来讲讲伴随着Hadoop的迭代更新,HDFS架构是如何演进的。
众所周知,Hadoop的诞生源于Google三篇论文,也就是我们经常说的“三辆马车”,2006年Hadoop出了第一个发行版本,Hadoop到目前为止发展已经有10余年,版本经过了无数次的更新迭代,业内把Hadoop大的版本分为Hadoop1,hadoop2,Hadoop3三个版本。
而HDFS,也随着Hadoop的更新迭代,在不断完善和优化。
HDFS架构演进
(1)HDFS 1.0架构
一般来说,架构我们分两种,一种就是主从架构,另一种是对等架构。在大数据生态中,常用的对等架构有Zookeeper、Kafka,而HDFS是主从式(master/slave)结构,由NameNode和DataNode以及SecondaryNamenode组成,如下图所示:
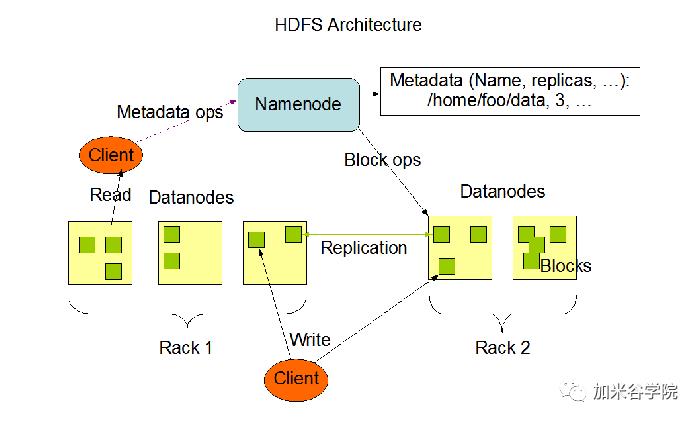
Namenode:属于集群中的中心服务器,管理节点,主要负责管理文件系统的命名空间(namespace)以及客户端对文件的访问,比如打开、关闭、重命名文件或目录,同时管理集群元数据的存储,记录文件中数据块(block)的映射关系。
Datanode:主要负责存储用户数据,处理来自文件系统客户端的请求,保持与namenode的通信,执行namenode的调度指令。
SeconddaryNameNode:主要是合并NameNode的edit logs到fsimage文件。
HDFS 1.0当中,分布式文件系统由一个Namenode和多个Datanode共同组成,这样的组织架构,导致了HDFS 1.0在运行当中出现单点故障以及内存受限的问题。
在实际运行当中,一旦NameNode出现了故障或者宕机,会导致数据丢失。因此在之后的HDFS 2.0架构当中,就对此作了改进。
(2)HDFS 2.0架构
HDFS 2.0采用HA(高可用)的方案,相对于HDFS 1.0来说,Namenode会区分两种状态,active和standby,正常工作的时候时候由active Namenode对外提供服务,standby Namenode则会从journalnode同步元数据,保证和active保持元数据一致。
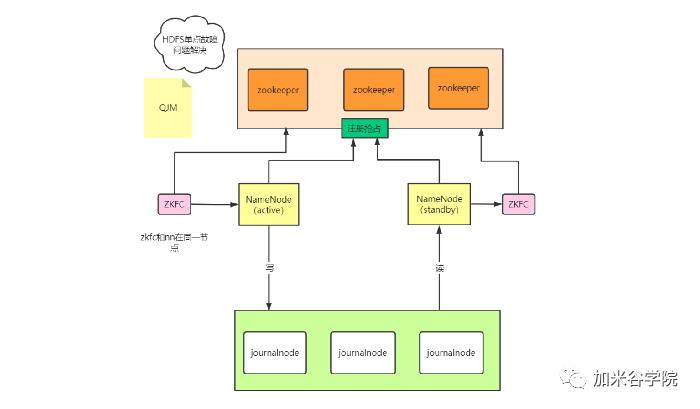
当active Namenode出现故障或者宕机的时候,standby会自动切换为新的active Namenode对外提供服务,并且HA对外提供了统一的访问名称,对于用户来说,不管访问的Namenode是active状态还是standby状态都是无感知的。
此外HDFS 2.0通过federation(联邦)机制解决了内存受限的问题。HDFS 2.0采用了建仓库的办法,也就是federation机制,但是一般适用于1000+规模的集群,小公司基本是用不上。
(3)HDFS 3.0架构
HDFS 3.0在架构上相对于HDFS 2.0没什么大的调整,HDFS 2.0只支持至多两个Namenode,而HDFS 3.0在2.0的基础上增加了多个Namenode的支持,提供集群可用性。
HDFS 3.0主要聚焦提升底层数据存储优化,降低数据开销的成本,采用纠错码技术提高集群的容错性。
关于大数据学习,HDFS架构演进之路,以上就为大家做了简单的介绍了。作为大数据主流基础架构的Hadoop,在实际发展当中历经多次更新和迭代,而其中的HDFS架构,也是在不断完善和优化的。
成都加米谷学院
个人技能提升 丨 企业内训提升
成都高新区吉泰一街国际科技节能大厦B座23层
以上是关于Hadoop大数据原理 - 架构演进的主要内容,如果未能解决你的问题,请参考以下文章