音频信号特征
Posted 香菜烤面包
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了音频信号特征相关的知识,希望对你有一定的参考价值。
1.声音
音信号是由空气压力的变化而产生的,可以测量压力变化的强度,并绘制这些测量值随时间的变化。
声音信号经常在规律的、固定的区间内重复,每个波都具有相同形状,高度表示声音的强度,称之为振幅。
信号完成一个完整波所花费的时间为周期,信号在一秒钟内发出的波数为频率。频率是周期的倒数,单位是赫兹。
2.怎么以数字表示声音
每隔相同的时间段对声音的振幅进行测量,然后把信号转换为数字。每一次这样的测量就是一个样本,采样率是每秒的样本数。 例如,采样率通常约为每秒 44,100 个样本,也就是说一个 10 秒的音乐片段有 441,000 个样本。
使用深度学习时实际上并没有处理原始格式的音频数据,是把音频数据转换为图像,然后使用标准的CNN架构处理这些图像,通常会从音频中生成声谱图。
3.时域与频域
频谱是表示相同信号的另一种方式,它显示了振幅与频率之间的关系。
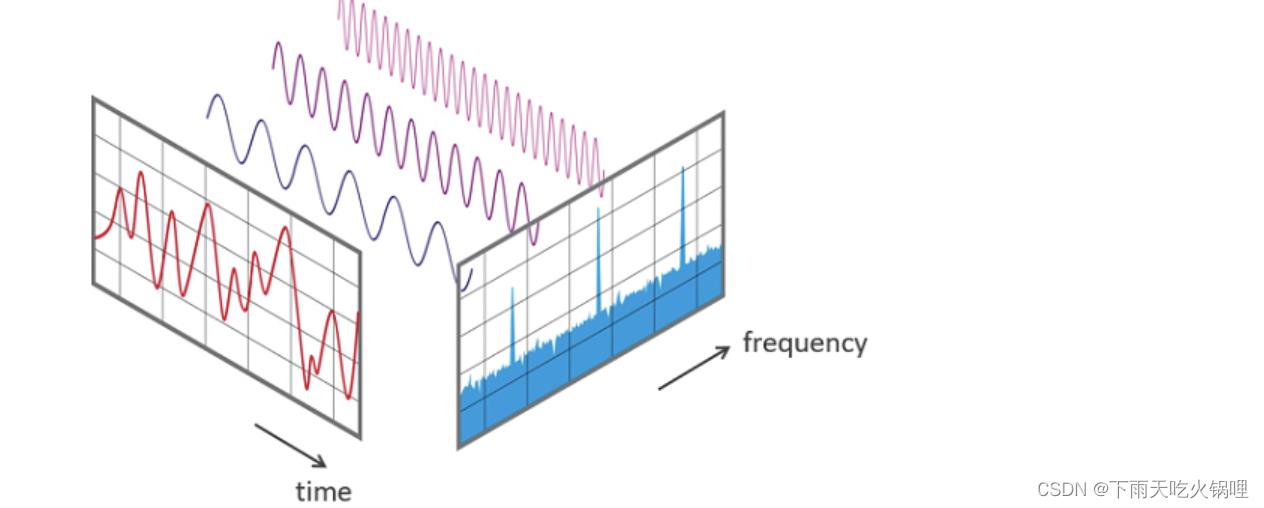
4.频谱图
频谱图是组合在一起产生信号的一组频率,频谱图绘制了信号中的所有频率以及每个频率的强度或振幅,信号中的最低频率叫作基频,基频的整数倍的频率叫作谐波。
5.声谱图
信号随时间变化会产生不同的声音,因此其组成频率也会随时间而变化。
声谱图是使用 Fourier Transforms 从声音信号中生成的,Fourier Transforms 将信号分解成其组成频率,并显示信号里的每个频率的振幅。声谱图将声音信号的持续时间缩短为小的时间段,然后将 Fourier Transform 应用于每个时间段来确定该段中所含的频率,然后把所有时间段的 Fourier Transform 合为一个图。
信号的声谱图绘制了它频谱随时间的变化,就像信号的“照片”一样。它在 X 轴上绘制时间,在 Y 轴上绘制频率,就好像我们在不同的时间点一次又一次地拍摄频谱,然后将它们全部合并为一个图。声谱图是声波的“快照”,因为它是图像,所以非常适合输入处理图像的基于 CNN 的架构中。
它使用不同的颜色表示每个频率的振幅或强度。颜色越亮,信号越好。频谱图的每个垂直“切片”本质上是信号在该时间点的频谱,显示了在该时间点信号中发现的每个频率中的信号强度是如何分布的。
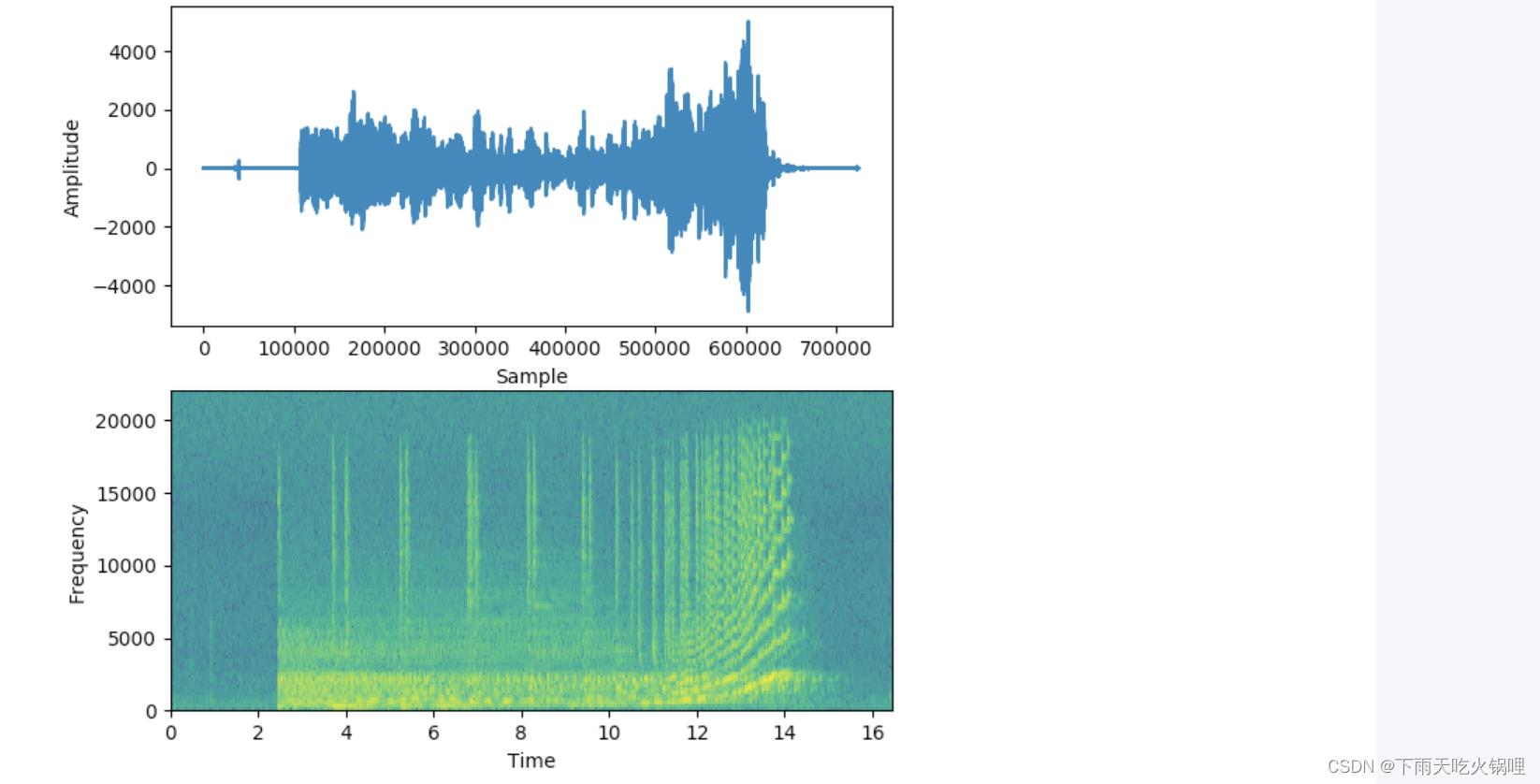
第一张图片显示是时域中的信号,即振幅与时间,可以从图中看出来一个片段在每个时间点的音量,但是没有告诉我们存在哪些频率。
6.音频深度学习模型
声谱图,它是音频信号的等价紧凑表示,就像是信号的“指纹”,是音频数据的基本特征捕获并转换为图像的一个好方法。音频深度模型使用的典型pipeline:
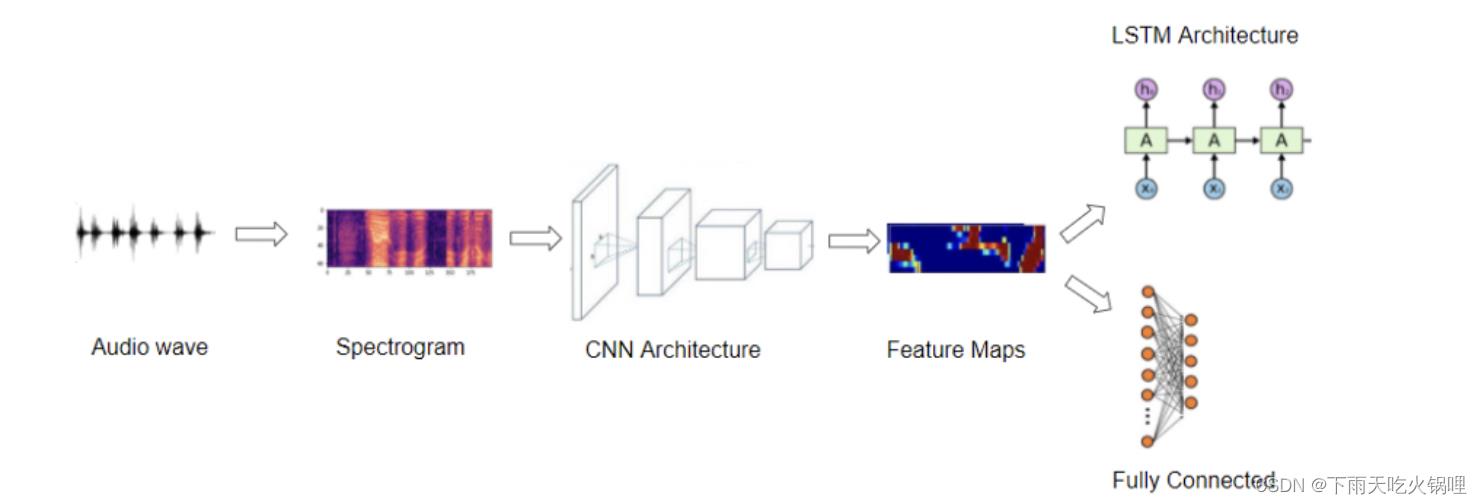
特征图,这是声谱图像的编码表示,从这个编码表示中生成输出预测:
- 对于音频分类问题,我将音频传入分类器,分类器通常由一些完全连接的线性层组成
- 对于语音转文本问题,我们可以将其传递给一些 RNN 层来从这个编码表示中提取文本句子
应用:音频分类 / 音频分离与分割 / 音乐流派分类和标记 / 音乐生成和转录 / 语音识别 / 语音转文本和文本转语音
7.音频文件格式和 Python 库
音频文件格式包括 .wav、.mp3、.wma、.aac、和 .flac 等
Python音频处理库,Librosa 、scipy。Pytorch有一个配套库torchaudio,该库与 Pytorch 紧密结合。Pytorch 没有 Librosa 的功能多,但它是专门为深度学习开发的。
音频是以压缩格式保存在文件中的,加载完成后,文件会被解压并转换为Numpy数组,无论文件的原始格式是什么,最后获得的数组看起来都是一样的。
音频在存储器中表现为数字时间序列,代表着每个 timestep 的振幅。例如,如果采样率为16800,则一秒钟的音频片段就包含 16800 个数字。由于测量是在固定的时间间隔下进行的,因此该数据只包含振幅值,不包含时间值。在给定采样率的情况下,可以计算出每个振幅值是在什么特定时间点测量的。
比特位深:每个样本的振幅测量可以取多少个可能的值 。例如,比特位深为 16 表示振幅值可以在 0 到 65535 (2 ¹⁶ -1)之间。比特位深会影响音频测量的分辨率,比特位深越高,音频保真度越好。
8.人类感知声音
人类感知声音的方式比较独特,我们能够听到的大多数声音都集中在狭窄的频率和振幅范围内,声音频率叫作“音调”,人类不会线性感知频率,对低频之间的差异比高频更为敏感。人类对声音振幅的感知就是声音的响度,与频率相似,我们听到的音量增大,一般都是对数的,不是线性的。
9.梅尔声谱图
为了真实地处理声音,我们在处理数据的频率和幅度时,必须通过梅尔刻度和分贝刻度来使用对数刻度,Y 轴为梅尔刻度而不是频率,使用分贝刻度代替振幅来指示颜色。深度学习模型通常使用梅尔声谱图而不是简单的声谱图。
普通声谱图:

使用梅尔刻度代替频率:
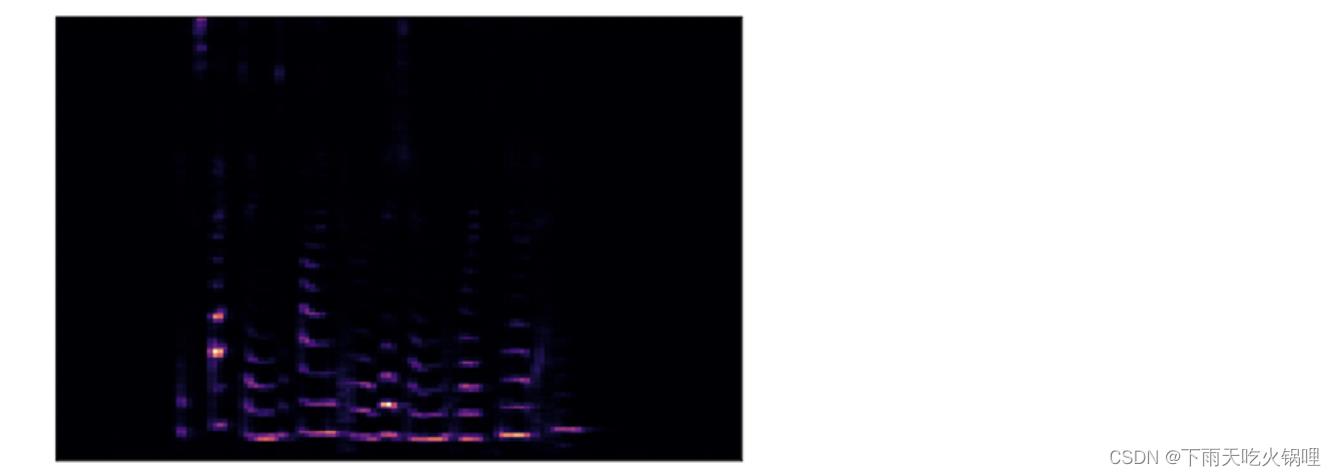 使用分贝刻度来代替振幅:
使用分贝刻度来代替振幅: 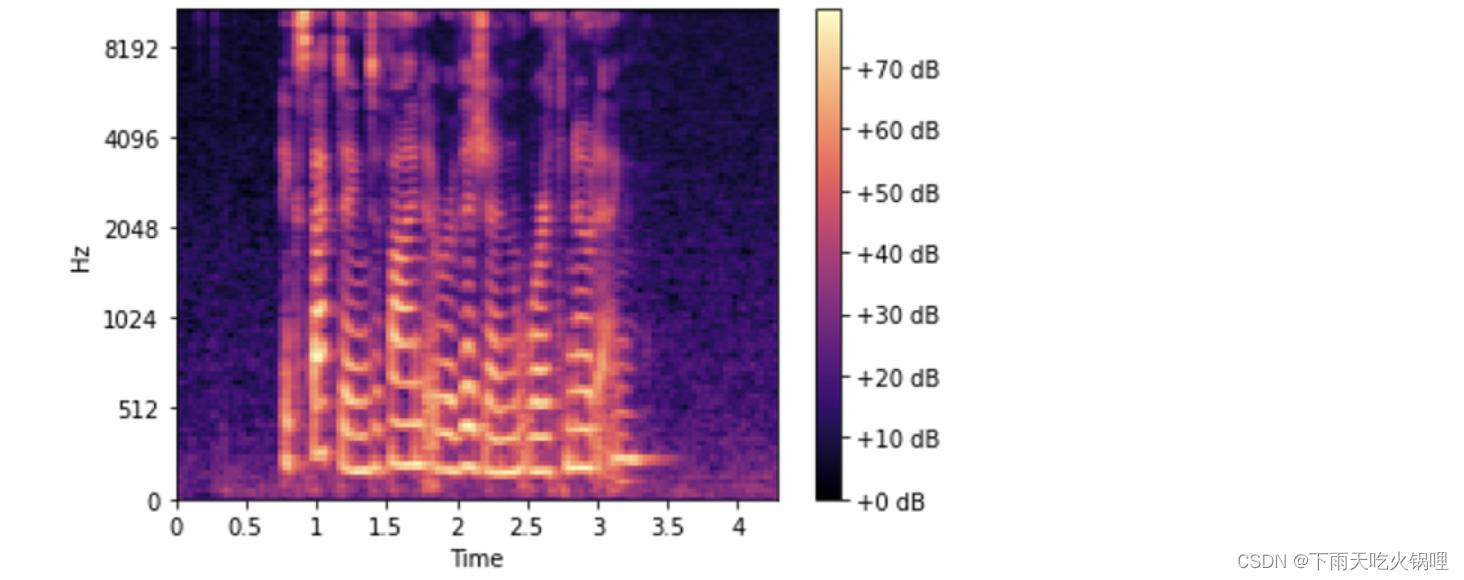
使用 Python 根据其特征相似性将音频信号分组
【中文标题】使用 Python 根据其特征相似性将音频信号分组【英文标题】:sort audio signals into groups based on its feature similarity using Python 【发布时间】:2021-05-20 06:54:46 【问题描述】:我已将包含所有英文字母(A、B、C、D 等)的音频文件拆分为单独的音频 .wav 文件块。我想将每个字母归为一组。例如,我希望将字母 A 的所有音频文件分组到一个文件夹中。那么我将有 26 个文件夹由相同字母的不同发音组成。
我已经搜索过这个,我发现了一些关于 K-mean 聚类的工作,但我无法达到我的要求。
【问题讨论】:
【参考方案1】:首先,您需要将声音转换为适合进一步处理的表示,因此您可以应用分类或聚类算法的一些特征向量。
对于音频,典型的选择是基于频谱的特征。要处理声音,librosa 会很有帮助。
由于声音具有不同的持续时间,并且您可能希望每次录音都有一个固定大小的特征向量,因此您需要一种在一系列数据之上构建单个特征向量的方法。在这里,可以使用不同的方法,具体取决于您的数据量和标签的可用性。假设您的录音数量有限且没有标签,您可以从简单地将几个向量堆叠在一起开始。平均是另一种可能性,但它会破坏时间信息(在这种情况下可能没问题)。训练某种 RNN 来学习作为隐藏状态的表示是最强大的方法。
看看这个相关的答案:How to classify continuous audio
【讨论】:
以上是关于音频信号特征的主要内容,如果未能解决你的问题,请参考以下文章