在Python中逐行读取多行字符串
Posted 迹忆客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在Python中逐行读取多行字符串相关的知识,希望对你有一定的参考价值。
使用 str.splitlines() 方法逐行读取多行字符串,例如 for line in multiline_str.splitlines():。str.splitlines() 方法在每个换行符处拆分字符串并返回字符串中的行列表。
multiline_str = """\\
First line
Second line
Third line"""
# First line
# Second line
# Third line
for line in multiline_str.splitlines():
print(line)

str.splitlines() 方法将字符串拆分为换行符,并返回一个包含字符串中行的列表。
multiline_str = """\\
First line
Second line
Third line"""
lines = multiline_str.splitlines()
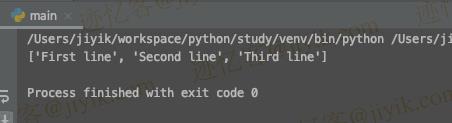
print(lines) # 👉️ ['First line', 'Second line', 'Third line']
除非 keepends 参数设置为 True,否则该方法不包括换行符。
multiline_str = """\\
First line
Second line
Third line"""
lines = multiline_str.splitlines(True)
print(lines) # 👉️ ['First line\\n', 'Second line\\n', 'Third line']
str.splitlines()方法在不同的行边界上拆分,例如\\n、\\r、\\r\\n等
my_str = "one\\rtwo\\r\\nthree\\n"
lines = my_str.splitlines()
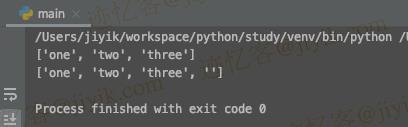
print(lines) # 👉️ ['one', 'two', 'three']
如果字符串以换行符结尾,则 splitlines() 方法将其删除,而不是 str.split() 方法。
my_str = "one\\ntwo\\nthree\\n"
lines = my_str.splitlines()
print(lines) # 👉️ ['one', 'two', 'three']
lines = my_str.split('\\n')
print(lines) # 👉️ ['one', 'two', 'three', '']
请注意,str.split()方法返回的列表中的最后一项是空字符串。
使用
str.splitlines()获取字符串中的行列表后,使用 for 循环遍历列表并逐行读取。
再看下面的例子。
multiline_str = """\\
First line
Second line
Third line"""
# First line
# Second line
# Third line
for line in multiline_str.splitlines():
print(line)
如果文本和换行符之间有空格,请使用 str.strip() 方法将其删除。
my_str = 'one \\ntwo \\n three \\n'
# 👇️ ['one ', 'two ', ' three ']
print(my_str.splitlines())
lines = [line.strip() for line in my_str.splitlines()]
print(lines) # 👉️ ['one', 'two', 'three']
我们使用列表推导来迭代列表。
列表推导用于对每个元素执行一些操作,或者选择满足条件的元素子集。
在每次迭代中,我们调用
str.strip()方法从字符串中删除任何前导和尾随空格。
如果我们在结果中得到空字符串并想要过滤掉它们,请使用 filter() 函数。
my_str = '\\rone\\r\\ntwo\\nthree\\n'
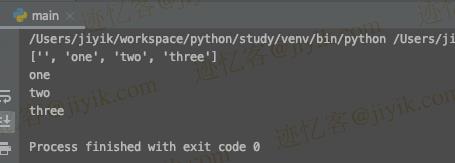
# 👇️ ['', 'one', 'two', 'three']
print(my_str.splitlines())
lines = list(filter(None, my_str.splitlines()))
# one
# two
# three
for line in lines:
print(line)
filter() 函数将一个函数和一个迭代器作为参数,并从迭代器的元素构造一个迭代器,函数为其返回一个真值。
如果为函数参数传递
None,则可迭代的所有虚假元素都将被删除。
空字符串是虚假值,因此空字符串列表项已从列表中删除。
Python:如何在 numpy 数组中逐行读取?
【中文标题】Python:如何在 numpy 数组中逐行读取?【英文标题】:Python: How to read line by line in a numpy array? 【发布时间】:2016-06-05 08:11:13 【问题描述】:我想知道我们可以在数组中逐行读取。例如:
array([[ 0.28, 0.22, 0.23, 0.27],
[ 0.12, 0.29, 0.34, 0.21],
[ 0.44, 0.56, 0.51, 0.65]])
以数组形式读取第一行以执行一些操作,然后继续第二行数组:
array([0.28,0.22,0.23,0.27])
产生上述数组的原因是这两行代码:
from numpy import genfromtxt
single=genfromtxt('single.csv',delimiter=',')
single.csv
0.28, 0.22, 0.23, 0.27
0.12, 0.29, 0.34, 0.21
0.44, 0.56, 0.51, 0.65
使用readlines() 似乎生成列表而不是数组。就我而言,我使用的是 csv 文件。我试图逐行使用值行,而不是一起使用它们以避免内存错误。谁能帮帮我?
with open('single.csv') as single:
single=single.readlines()
【问题讨论】:
你的csv 里面有array([0.28,0.22,0.23,0.27]) 吗?这不是csv 格式。
readlines 产生一个字符串列表。解析每一行以获取数字
【参考方案1】:
你可以使用np.fromstring
import numpy as np
with open('single.csv') as f:
lines=f.readlines()
for line in lines:
myarray = np.fromstring(line, dtype=float, sep=',')
print(myarray)
见http://docs.scipy.org/doc/numpy-1.10.1/reference/generated/numpy.fromstring.html 和How to read csv into record array in numpy?
【讨论】:
对不起,我不熟悉 np.fromstring。它返回了这个错误:NameError: name 'double' is not defined【参考方案2】:您似乎没有在 Python 中读取文件的经验。让我在 Ipython 迭代会话中详细介绍一个示例
创建多行文本来模拟您的文件
In [23]: txt="""0.28, 0.22, 0.23, 0.27
0.12, 0.29, 0.34, 0.21
0.44, 0.56, 0.51, 0.65"""
将其分成几行来模拟readlines的结果
In [24]: txt=txt.splitlines(True)
In [25]: txt
Out[25]:
['0.28, 0.22, 0.23, 0.27\n',
'0.12, 0.29, 0.34, 0.21\n',
'0.44, 0.56, 0.51, 0.65']
我可以使用genfromtxt 将其转换为数组(您可以像这样将结果传递给readlines 到genfromtxt。
In [26]: np.genfromtxt(txt, delimiter=',')
Out[26]:
array([[ 0.28, 0.22, 0.23, 0.27],
[ 0.12, 0.29, 0.34, 0.21],
[ 0.44, 0.56, 0.51, 0.65]])
我可以遍历这些行,去掉 \n 并在 ',' 上拆分
In [27]: for line in txt:
print line.strip().split(',')
....:
['0.28', ' 0.22', ' 0.23', ' 0.27']
['0.12', ' 0.29', ' 0.34', ' 0.21']
['0.44', ' 0.56', ' 0.51', ' 0.65']
我可以通过列表理解将每个字符串转换为浮点数:
In [28]: for line in txt:
print [float(x) for x in line.strip().split(',')]
....:
[0.28, 0.22, 0.23, 0.27]
[0.12, 0.29, 0.34, 0.21]
[0.44, 0.56, 0.51, 0.65]
或者通过将迭代放在另一个列表推导中,我可以获得一个数字列表列表:
In [29]: data=[[float(x) for x in line.strip().split(',')] for line in txt]
In [30]: data
Out[30]: [[0.28, 0.22, 0.23, 0.27], [0.12, 0.29, 0.34, 0.21], [0.44, 0.56, 0.51, 0.65]]
我可以把它变成一个数组
In [31]: np.array(data)
Out[31]:
array([[ 0.28, 0.22, 0.23, 0.27],
[ 0.12, 0.29, 0.34, 0.21],
[ 0.44, 0.56, 0.51, 0.65]])
genfromtxt 本质上是在经历这个序列——读取行,拆分它们,将字符串转换为值,最后从列表中创建一个数组。
有捷径,但我认为你会从详细完成这些步骤中受益。它既是关于基本 Python 字符串和列表操作的练习,也是关于数组的练习。
【讨论】:
谢谢 :) 很有帮助。【参考方案3】:for list in array:
print(list)
for item in list:
print(item)
给出输出:
[0.28, 0.22, 0.23, 0.27]
0.28
0.22
0.23
0.27
[0.12, 0.29, 0.34, 0.21]
0.12
0.29
0.34
0.21
[0.44, 0.56, 0.51, 0.65]
0.44
0.56
0.51
0.65
【讨论】:
以上是关于在Python中逐行读取多行字符串的主要内容,如果未能解决你的问题,请参考以下文章