数据结构-串数组和广义表
Posted L、fly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构-串数组和广义表相关的知识,希望对你有一定的参考价值。
串、数组和广义表
串
串的定义
串(String)——零个或多个任意字符组成的有限序列
-
子串:串中任意个连续字符组成的子序列称为该串的子串
真子串是指不包含自身的所有子串
-
主串:包含子串的串相应地称为主串
-
字符位置:字符在序列中的序号为该字符在串中的位置
-
子串位置:子串第一个字符在主串中的位置
-
空格串:由一个或多个空格组成的串,与空串不同
串相等:当且仅当两个串的长度相等并且各个对应位置上的字符都相同时,这两个串才是相等的。
- 所有空串是相等的。
串的类型定义、存储结构及运算
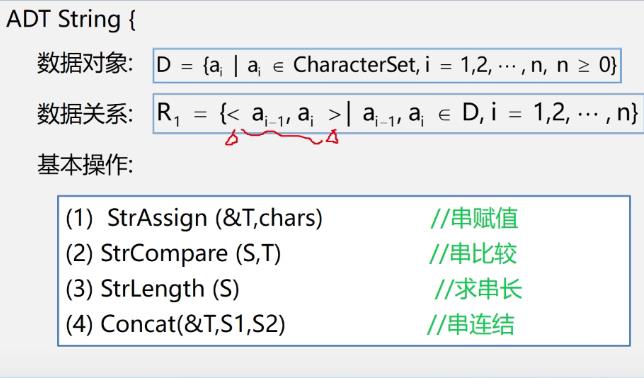
ADT String
数据对象:D=a_i|a_i∈CharacterSet,i=1,2,...,n,n≥0
数据关系:R_1=<a_i-1,a_i>|a_i-1,a_i∈D,i=1,2,...,n
基本操作:
StrAssign(&T,chars) //串赋值
StrCompara(S,T) //串比较
StrLength(S) //求串长
Concat(&T,S1,S2) //串连结
SubString(&Sub,S,pos,len) //求子串
StrCopy(&T,S) //串拷贝
StrEmpty(S) //串判空
ClearString(&S) //清空串
Index(S,T,pos) //子串的位置
Replace(&S,T,V) //串替换
StrInsert(&S,pos,T) //子串插入
StrDelete(&S,pos,len) //子串删除
DestroyString(&S) //串销毁
ADT String
-
串的顺序存储结构
#define MAXLEN 255 typedef struct char ch[MAXLEN+1]; //存储串的一维数组 int length; //串的当前长度 SString; -
串的链式存储结构——块链结构
优点:操作方便 缺点:存储密度较低(存储密度=串值所占的存储/实际分配的存储)
可将多个字符存放在一个结点中,以克服其缺点
#define CHUNKSIZE 80 //块的大小可由用户定义 typedef struct Chunk char ch[CHUNKSIZE]; struct Chunk *next; Chunk; typedef struct Chunk *head,*tail; //串的头指针和尾指针 int curlen; //串的当前长度 LString; //字符串的块链结构 -
串的模式匹配算法
算法目的:
确定主串中所含**子串(模式串)**第一次出现的位置(定位)
算法应用:
搜索引擎、拼写检查、语言翻译、数据压缩
算法种类:
-
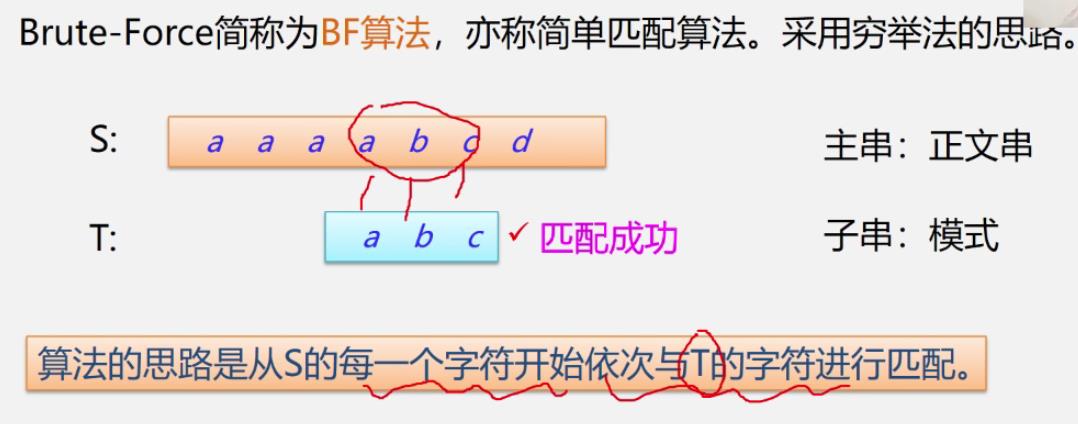
BF算法(Brute-Force,又称古典的、经典的、朴素的、穷举的)
简单匹配算法,采用穷举法的思路,从S的每一个字符开始依次与T的字符进行匹配
int Index_BF(SString S,SString T) int i=1,j=1; while(i<=S.length&&j<=T.length) if(s.ch[i]==t.ch[j])++i;++j;//主串和子串依次匹配下一个字符 elsei=i-j+2;j=1;//主串、子串指针回溯重新开始下一次匹配 if(j>=T.length) return i-T.length;//返回匹配的第一个字符的下标 else return 0;//模式匹配不成功若n为主串长度,m为子串长度,最坏情况是总次数为:(n-m)*m+n=(b-m+1) * m,若m<<n,则算法复杂度O(n * m)
-
KMP算法(特点:速度快)
利用已经部分匹配的结果而加快模式串的滑动速度?
且主串S的指针i不必回溯!可提速到O(n+m)!
为此,定义**next[j]**函数,表明当模式中第j个字符与主串中相应字符“失配”时,在模式中需重新和主串中该字符进行比较的字符的位置。
n e x t [ j ] = m a x k ∣ 1 < k < j , 且 " p 1 . . . p k − 1 " ( 从头开始的 k − 1 个元素 ) = " p j − k + 1 . . . p j − 1 " ( j 前面的 k − 1 个元素 ) 当此集合非空时 0 当 j = 1 时 1 其他情况 next[j]= \\begincases max\\k|1<k<j,且"p_1...p_k-1"(从头开始的k-1个元素)="p_j-k+1...p_j-1"(j前面的k-1个元素)\\\\\\ \\quad \\quad \\quad \\quad 当此集合非空时\\\\ 0\\quad 当j=1时\\\\ 1\\quad 其他情况 \\endcases next[j]=⎩ ⎨ ⎧maxk∣1<k<j,且"p1...pk−1"(从头开始的k−1个元素)="pj−k+1...pj−1"(j前面的k−1个元素)当此集合非空时0当j=1时1其他情况
int Index KMP(SString S,SString T,int pos) i=pos;j=1; while(i<S.length&&j<T.length) if(j==0||S.ch[i]==T.ch[j])i++;j++; else j=next[j];/*i不变,j后退*/ if(j>T.length) return i-T.length;/*匹配成功*/ else return 0;/*返回不匹配标志*/ void get_next(SString T,int &next[]) i=1;next[1]=0;j=0; while(i<T.length) if(j==0|T.ch[i]==T.ch[j]) ++i;++j; next[i]=j; else j=next[j]; //next改进 void get_nextval(SString T,int &nextval[]) i=1;nextval[1]=0;j=0; while(i<T.length) if(j==0|T.ch[i]==T.ch[j]) ++i;++j; if(T,ch[i]!=T.ch[j])nextval[i]=j; else nextval[i]=nextval[j]; else j=nextval[j];
-
数组
数组:按一定格式排列起来的、具有相同类型的数据元素的集合。
一维数组:若线性表中的数据元素为非结构的简单元素,则称为一维数组。
一维数组的逻辑结构:线性结构。定长的线性表。
声明格式:数据类型 变量名称[长度];
二维数组:若一维数组中的数据元素又是一维数组结构,则称为二维数组。
二维数组的逻辑结构:
-
非线性结构
每一个数据元素既在一个行表中,又在一个列表中。
-
线性结构、定长的线性表
该线性表的每个数据元素也是一个定长的线性表。
声明格式:数据类型 变量名称[行数] [列数];
在C语言中,一个二维数组类型也可以定义为一维数组类型(其分量类型为一维数组类型),即:
typedef elemtype array2[m][n];
//等价于
typedef elemtype array1[n];
typedef array1 array2[m];
三维数组:若二维数组中的元素又是一个一维数组,则称作三维数组。
n维数组:若n-1维数组中的元素又是一个一维数组结构,则称作n维数组。
结论:线性表结构是数组结构的一个特例,而数组结构又是线性表结构的扩展。
数组特点:结构固定——定义后,维数和维界不再改变。
数组基本操作:除了结构的初始化和销毁之外,只有取元素和修改元素值的操作。
特殊矩阵的压缩存储
矩阵:一个由mxn个元素排成的m行n列的表。
矩阵的常规存储:将矩阵描述为一个二维数组。
矩阵的常规存储的特点:可以对其元素进行随机存取;矩阵运算非常简单;存储的密度为1。
不适宜常规存储的矩阵:值相同的元素很多且呈某种规律分布;零元素多。
矩阵的压缩存储:为多个相同的非零元素只分配一个存储空间;对零元素不分配空间。
-
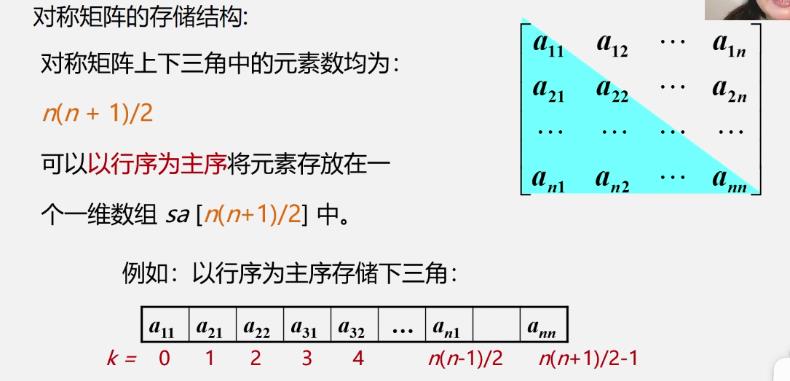
对称矩阵
特点:在n×n的矩阵a中,满足如下性质:aij=aji(1≤i,j≤n)
存储方法:只存储下(或者上)三角(包括主对角线)的数据元素。共占用n(n+1)/2个元素空间。
-
三角矩阵
特点:对角线以下(或者以上)的数据元素(不包括对角线)全部为常数c。
存储方法:重复元素c共享一个元素存储空间,共占用n(n+1)/2+1个元素空间:sa[1…n(n+1)/2+1]
存储下标 上三角矩阵: k = ( i − 1 ) × ( 2 n − i + 2 ) / 2 + j − i + 1 i ≤ j n ( n + 1 ) / 2 + 1 i > j 下三角矩阵: k = i × ( i − 1 ) / 2 + j i ≥ j n ( n + 1 ) / 2 + 1 i < j 存储下标\\\\ 上三角矩阵:k= \\begincases (i-1)×(2n-i+2)/2+j-i+1\\quad i≤j \\\\ n(n+1)/2+1\\quad i>j \\endcases\\\\ 下三角矩阵:k= \\begincases i×(i-1)/2+j\\quad i≥j \\\\ n(n+1)/2+1\\quad i<j \\endcases 存储下标上三角矩阵:k=(i−1)×(2n−i+2)/2+j−i+1i≤jn(n+1)/2+1i>j下三角矩阵:k=i×(i−1)/2+ji≥jn(n+1)/2+1i<j -
对角矩阵(带状矩阵)
特点:在n×n的方阵中,所有非零元素都集中在以主对角线为中心的带状区域中,区域外的值全为0,则称为对角矩阵。常见的有三对角矩阵、五对角矩阵、七对角矩阵等。
存储方法:以对角线的顺序存储
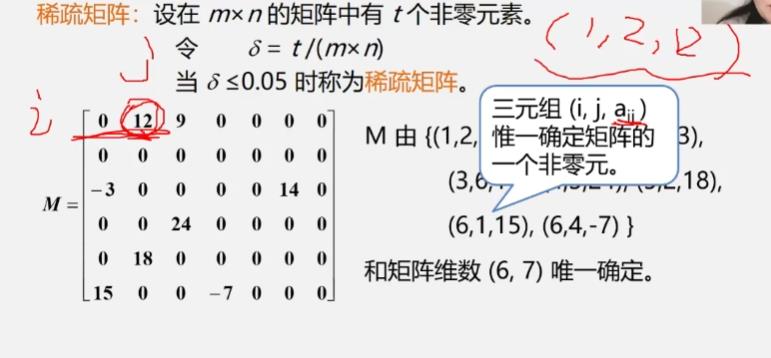
稀疏矩阵:设在m×n的矩阵中有t个非零元素。令δ=t/(m×n),当δ≤0.05时称为稀疏矩阵。
压缩存储原则:存各非零元的值、行列位置和矩阵的行列数。
注意:为更可靠描述,通常再加一个“总体”信息:即总行数、总列数、非零元素总个数。
三元组顺序表又称有序的双下标法。
三元组顺序表的优点:非零元在表中按行有序存储,因此便于进行依行顺序处理的矩阵运算。
三元组顺序表的缺点:不能随机存取。若按行号存取某一行中的非零元,则需从头开始进行查找。
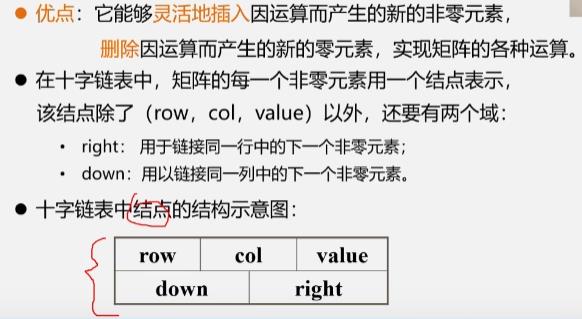
稀疏矩阵的链式存储结构:十字链表
优点:它能够灵活地插入因运算而产生的新的非零元素,删除因运算而产生的新的零元素,实现矩阵的各种运算。
在十字链表中,矩阵的每一个非零元素用一个结点表示,该结点除了(row,col,value)以外,还要有两个域:
- right:用于链接同一行中的下一个非零元素;
- down:用以链接同一列中的下一个非零元素。
广义表
广义表(又称列表Lists)是n≥0个元素a0,a1,…,a_n-1的有限序列,其中每一个ai或者是原子,或者是一个广义表。
广义表通常记作:LS=(a1,a2,…,an) 其中:LS为表名,n为表的长度,每一个ai为表的元素。
习惯上,一般用大写字母表示广义表,小写字母表示原子。
表头:若LS非空(n≥1),则其第一个元素a1就是表头。记作head(LS)=a1。 注:表头可以是原子,也可以是子表。
表尾:除表头之外的其它元素组成的表。记作tail(LS)=(a2,…,an)。 注:表尾不是最后一个元素,而是一个子表。
广义表的性质
-
广义表中的数据元素有相对次序;一个直接前驱和一个直接后继
-
广义表的长度定义为最外层所包含元素的个数
-
广义表的深度定义为该广义表展开后所含括号的重数
A=(b,c)的深度为1,B=(A,d)的深度为2,C=(f,B,h)的深度为3
注意:“原子”的深度为0;“空表”的深度为1。
-
广义表可以为其他广义表共享;如:广义表B就共享表A。在B中不必列出A的值,而是通过名称来引用,B=(A)
-
广义表可以是一个递归的表。如:F=(a,F)
注意:递归表的深度是无穷值,长度是有限值。
-
广义表是多层次结构,广义表的元素可以是单元素,也可以是子表,而子表的元素还可以是子表,…。
广义表可以看成是线性表的推广,线性表是广义表的特例。
广义表的结构相当灵活,在某种前提下,它可以兼容线性表、数组、树和有向图等各种常用的数据结构。
当二维数组的每行(或每列)作为子表处理时,二维数组即为一个广义表。
广义表的基本运算
- 求表头GetHead(L):非空广义表的第一个元素,可以是一个单一的元素,也可以是一个子表
- 求表尾GetTail(L):非空广义表除去表头元素以外其它元素所构成的表。表尾一定是一个表
数据结构与算法学习笔记 串,数组和广义表
数据结构与算法学习笔记(6) 串、数组和广义表
截图、笔记来自: 王卓 数据结构与算法

文章目录
一.串
1.串的定义
-
串:零个或多个任意字符组成的有限序列
-

-
几个术语
- 子串:串中任意个连续字符组成的子序列称为该串的子串
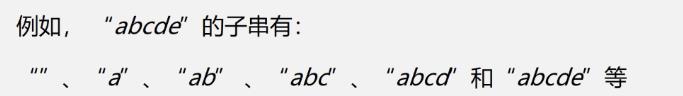
- 真子串是不包含自身的所有子串
- 主串: 包含子串的串相应地称为主串
- 字符位置:字符在序列中的序号为该字符在串中的位置
- 子串位置: 子串第一个字符在主串中的位置
- 空格串:由一个或多个空格组成的串,与空串不同

- 串相等: 当且仅当两个串的长度相等且在各对应位置上字符都相同时,这两个串才相等
- 注意所有空串都相等
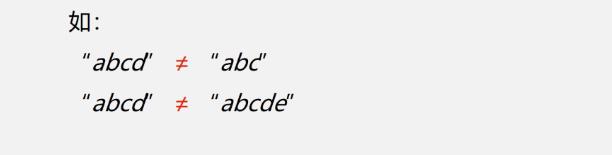
- 子串:串中任意个连续字符组成的子序列称为该串的子串
2.串的类型定义、存储结构及其运算
串的类型定义

串的存储
串的顺序存储结构
#define MAXLEN 255
typedef struct{
char ch[MAXLEN+1]; //存储串的一维数组
// 0号单元存放串的长度
int length; //串的当前长度
}SString;
串的链式存储结构

根据需要选择单链表/双向链表/循环链表等
-
优点:操作方便
-
缺点:存储密度低
-

-
解决办法
将多个字符放在一个结点中,以克服其缺点


块链结构
上述解决办法就是块链结构
#define CHUNKSIZE 80 //块的大小可自定义
typedef struct Chunk{
char ch[CHUNKSIZE];
struct Chunk *next;
}Chunk;
typedef struct{
Chunk *head,*tail; //串的头尾指针
int curlen; //串的当前长度
}LString; //字符串的块链结构
顺序存储结构用的更多,因为匹配查找运算用的多,删除插入用的少
3.串的模式匹配算法
-
算法目的:
确定主串中所含子串(模式串)第一次出现的位置(定位)
-
算法应用
搜索引擎、拼写检查、语言翻译、数据压缩
-
算法种类
- BF算法(Brute-force,古典的、经典的、朴素的、穷举的)
- KMP算法(速度快)
①BF算法
-
例子引入

-
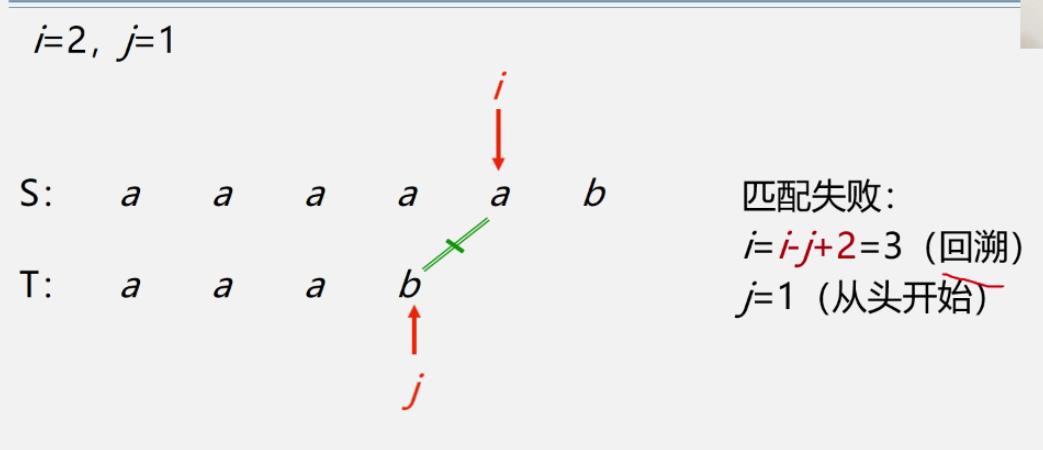
对i-j+2的理解
T从1位置移动到j,移动了j-1个长度,则S也移动了j-1
S现在的位置是i,移动的长度也是j-1,用现在的位置i减去移动的长度i-(j-1),再加1就是下一个位置,所以是i-j+2

-
-
算法思想

-
算法描述
int Index_BF(SString S,SString T){ int i=1,j=1; while(i<=S.length && j<=T.length){ //j>T.length时说明j的每个字符都匹配成功了,就不用继续匹配了 if(S.ch[i]==t.ch[j]) { ++i; ++j; //主串和子串依次匹配下一个字符 } else { i=i-j+2; j=1; //主串、子串指针回溯重新开始下一次匹配 } } if(j>T.length) return i-T.length; //返回匹配的第一个字符的下标 else return 0; //模式匹配不成功 }or
int Index(SString S, SString T, int pos) { i = pos; j = 1; while (i <= S[0] && j <= T[0]) { if (S[i] == T[j]) { ++i; ++j; } // 继续比较后继字符 else { i = i-j+2; j = 1; } // 指针后退重新开始匹配 } if (j > T[0]) return i-T[0]; else return 0; } // Index -
算法时间复杂度分析
-
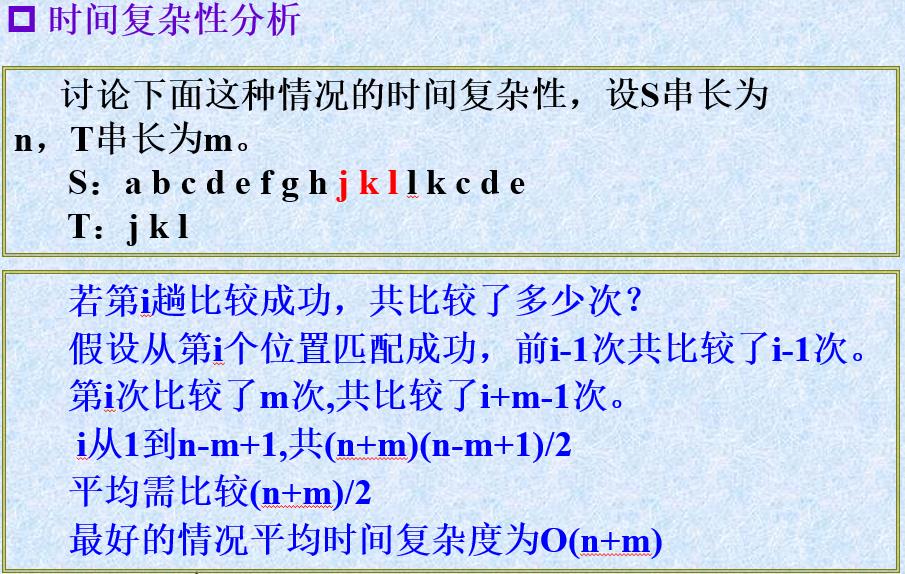
最坏时间复杂度:
在最坏情况下,每趟不成功的匹配都发生在模式串T的最后一个字符
那么前n-m趟不成功的匹配比较了(n-m)*m次,最后一趟匹配成功比较了m次,则总共匹配了
(n-m)*m+m次


-
②KMP算法
这里听了一遍没理解,去搜了搜别的教程,推荐几个:
👉有个哈工大师兄在B站发的视频讲的挺好


-
小例
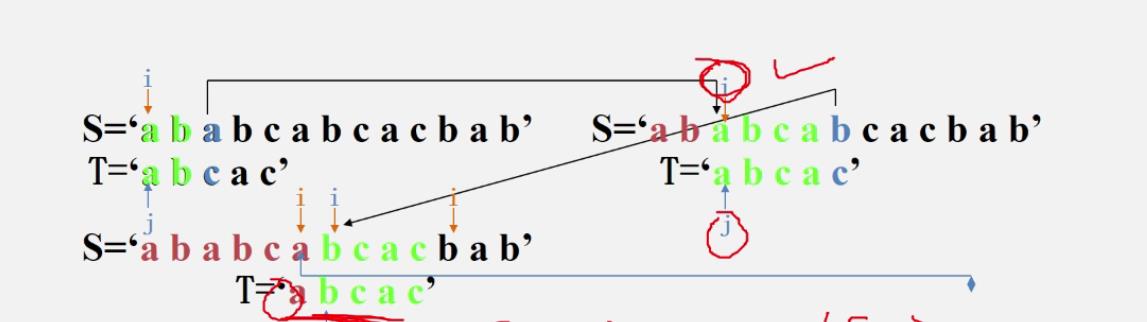
-
算法思想

- 例
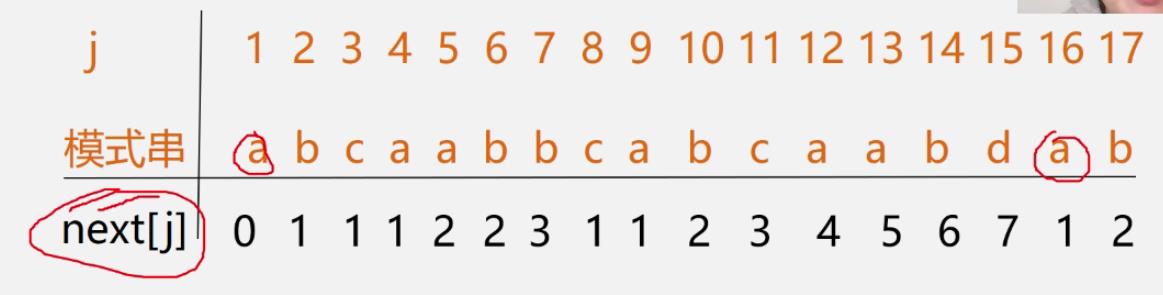
-
算法描述
int index_KMP(SString S,SString T,int pos){ i = pos, j = 1; while(i<S.length && j<T.length){ if(j==0 || S.ch[i]==T.ch[j]){ i++; j++;} else j=next[j]; // i不变,j后退 } if(j>T.length) return i - T.length; //匹配成功 else return 0; //返回不匹配标志 } -
求next数组的函数
void get_next(SString T,int &next[]){ i = 1; next[1]=0; j=0; while(i<T.length){ if(j==0||T.ch[i]==T.ch[j]){ ++i;++j; next[i]=j; } else j = next[j]; } }
二.数组
1.数组的定义及特点
-
数组:按一定格式排列起来的具有相同类型的数据元素的集合
-
一维数组:线性表中的数据元素为非结构的简单元素,则称为一维数组
- 一维数组的逻辑结构:线性结构
- 是定长的线性表
- 声明格式
数据类型 变量名称[长度]; - 一维数组的逻辑结构:线性结构
-
二维数组


二维数组既可以看成线性结构,也可以看成非线性结构
-
声明格式
数据类型 变量名称[行数][列数]; -

array1是有n个元素的一维数组
-
-
三维数组

-
数组特点:结构固定
定义后,维数和维界不再改变
-
数组基本操作

插入删除等操作会破坏数组结构
2.数组的抽象数据类型定义
-
n维数组的抽象数据类型

n n n为数组的维数, b i b_i bi为数组第i维的长度, j i j_i ji为数组元素第i维的下标

3.数组的顺序存储结构

-
一维数组
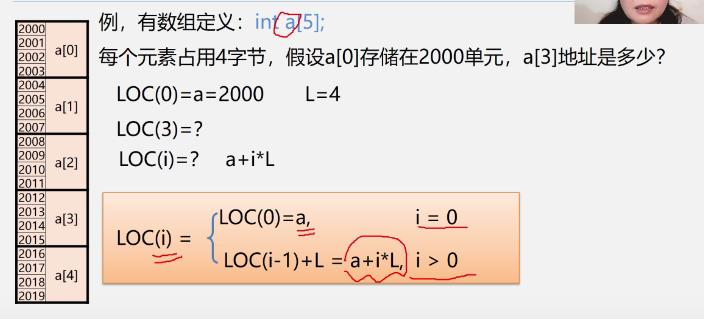
-
二维数组
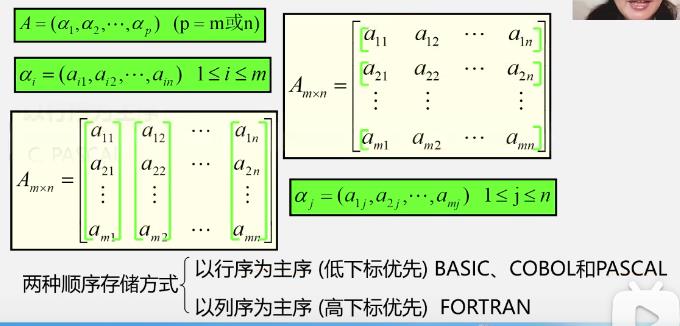

-
以行序为主序
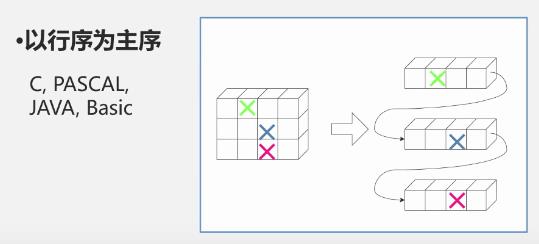
-
以列序为主序
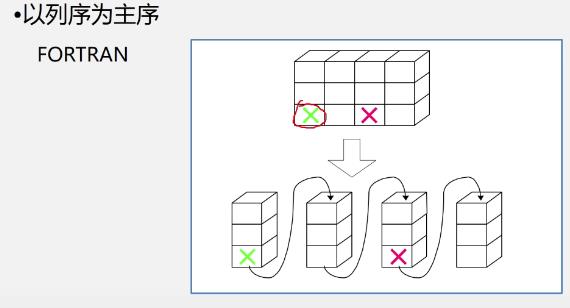

-
二维数组的行序优先表示

-
-
-
三维数组
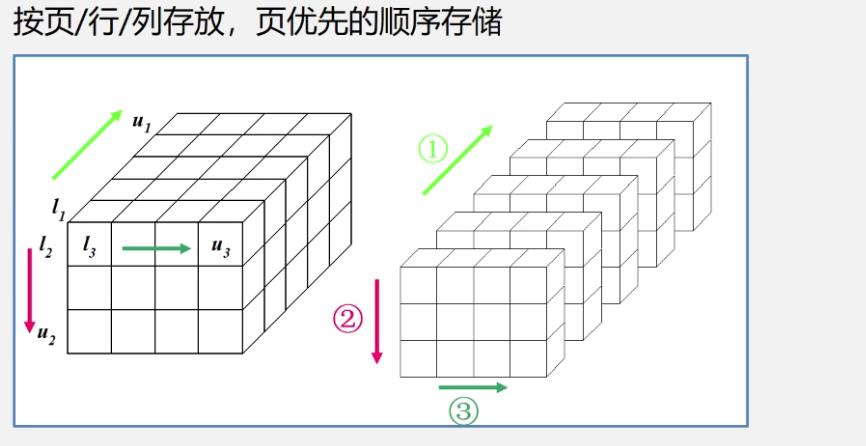

-
n维数组

-
例

4.特殊矩阵的压缩存储


①对称矩阵的压缩存储

②三角矩阵、对角矩阵的压缩存储
- 三角矩阵

空间里面那个+1是用来存储常数c
- 对角矩阵

③稀疏矩阵的压缩存储
-
压缩存储原则: 存各非零元的值、行列位置和矩阵的行列数
- 三元组的不同表示方法可决定稀疏矩阵不同的压缩存储方法
三元组顺序表
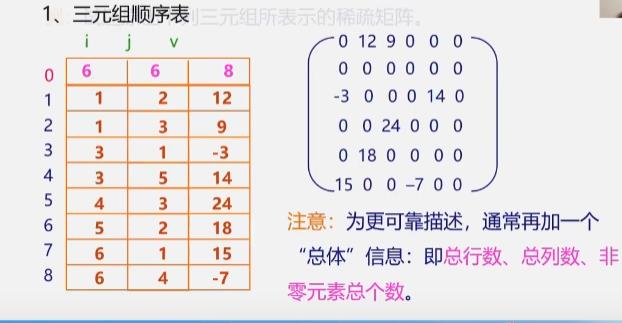

-
优缺点

下面的十字链表可以克服三元组顺序表的缺点
稀疏矩阵的链式存储结构:十字链表

三.广义表
广义表也是递归定义

线性表中的元素是同类型的单一元素
上面说的原子就是指单一元素
-
广义表的一些基本概念


-
广义表的性质

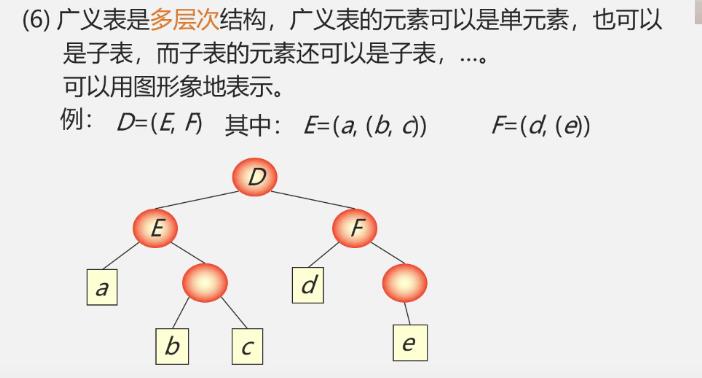
-
广义表和线性表的区别

-
广义表的基本运算

以上是关于数据结构-串数组和广义表的主要内容,如果未能解决你的问题,请参考以下文章