js-正则表达式ES6--正则的扩展
Posted Marvin_Tang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了js-正则表达式ES6--正则的扩展相关的知识,希望对你有一定的参考价值。
2019-10-27
学习内容:
两大部分:js正则匹配、es6正则扩展
补充:
1、什么叫先行断言?
“先行断言”指的是,x只有在y前面才匹配,必须写成/x(?=y)/。比如,只匹配百分号之前的数字,要写成/\\d+(?=%)/。“先行否定断言”指的是,x只有不在y前面才匹配,必须写成/x(?!y)/。比如,只匹配不在百分号之前的数字,要写成/\\d+(?!%)/。
2、什么叫后行断言?
“后行断言”正好与“先行断言”相反,x只有在y后面才匹配,必须写成/(?<=y)x/。比如,只匹配美元符号之后的数字,要写成/(?<=\\$)\\d+/。“后行否定断言”则与“先行否定断言”相反,x只有不在y后面才匹配,必须写成/(?<!y)x/。比如,只匹配不在美元符号后面的数字,要写成/(?<!\\$)\\d+/。
3、日期格式的替换:(非常实用的例子)
let re = /(?<year>\\d{4})-(?<month>\\d{2})-(?<day>\\d{2})/u;
\'2015-01-02\'.replace(re, \'$<day>/$<month>/$<year>\')
// \'02/01/2015\'
图形化解析正则表达式的工具:http://regexper.com
()括号括住的是分组
【】里的内容任选其一
一、REGEXP 对象:
有两种方法实例化regexp对象的方法:字面两和构造函数
字面量:var reg = /\\bis\\b/;
var = reg = /\\bis\\b/g; //全局匹配
使用: ‘xxx\'.replace(reg, \'0\') //‘0’是替换匹配文本的内容
构造函数: var reg = new REGEXP(\'\\\\bis\\\\b\', \'g\')
两个斜线的是因为\'\\\'在js是特殊字符,需要转义。
修饰符:类似于g这种用于给限定条件的字符:

二、Re:
元字符:
re中由两种基本字符类型组成:原义文本字符、元字符
元字符是在re中有特殊含义的非字母字符:如b . * /

字符类:

- 字符类取反:

范围类:

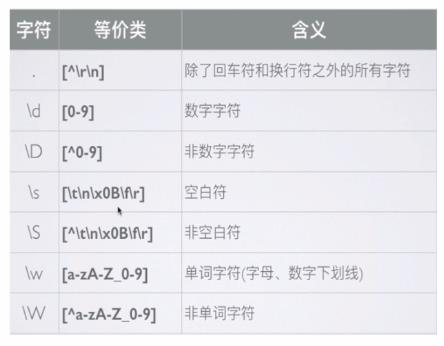
预定义类:
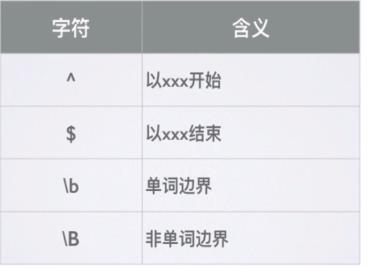
- 边界:
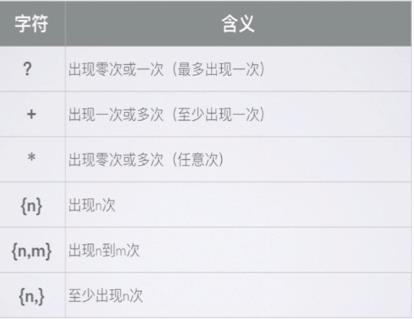
量词:
贪婪模式:
尽量的多匹配,同样满足的次数,取最多,通常匹配的字符串长度最长
非贪婪模式:
让re尽可能少的匹配,也就是说一旦成功匹配就不再继续尝试。操作:量词后加?
\'123456789\'.match(/\\d{3,5}?\\/g)
// 匹配结果: ["123", "456", "789"]
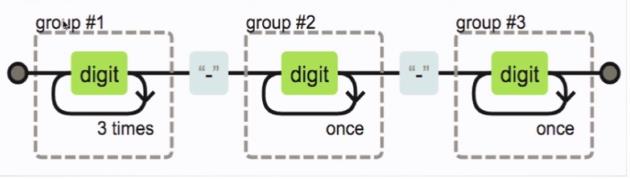
分组:搭配捕获使用更为常见
反例:Byron{3} 只会匹配3次的“n”
使用( )可以达到分组的效果,使量词作用于整个组
或: | 指两种可能满足一种就能匹配
结合分组可以圈定范围:Byr(on|ca)sper
反向引用(分组并且捕获):2015-12-05 => 12/05/2015 实现:‘2015-12-05’.replace(/(\\d{4})-(\\d{2})-(\\d{2})/g, \'$2/$3/$1\')
忽略分组:(不捕获,不占用分组顺序)

前瞻或后顾:就是先行断言,和后行断言。正向和负向就是肯定和否定匹配
(详见文章头部的补充)
正则对象属性:

(lastIndex在ES6可用y修饰符)
这些属性都无法直接赋值为true,只能使用修饰符做修改
test和exec方法:
(1)test(str): 用于测试字符串参数重是否存在匹配re模式的字符串,返回布尔值
g和y修饰符会带来一下test的问题:解决方法就是test不要和g和y搭配使用
var reg = /\\w/g reg.test(\'ab) // true reg.test(\'ab) // true reg.test(\'ab) // False。因为lastIndex属性指向了b的下一个是无值,需要经过一次false才会回到起点 reg.test(\'ab) // true
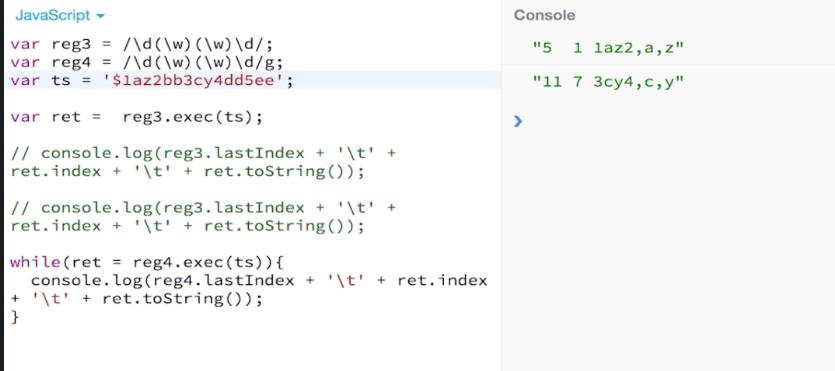
(2)exec(str):使用re模式对字符串执行搜索,并将更新全局RegExp对象的属性以反映匹配结果。匹配到的返回结果数组(index:声明匹配文本的第一个字符的位置, input:存放被检索的字符串string),否则返回null
非全局调用:


ps:ret是结果数组
全局调用:
非全局调用是没有lastindex的(常为0),但是全局执行一次是有lastindex
字符串对象方法:
(1)search(reg):用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串。有的话(无论几个)只返回第一个匹配结果index(位置),找不到就返回 -1。g标志将无意义,总是从字符串开始进行检索。

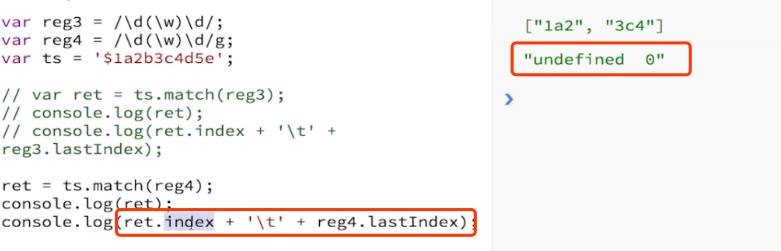
(2)match(reg):检索字符串,以找到一个或多个与regexp匹配的文本,此时g修饰符有意义。
非全局时:只执行一次,有的话返回一个数组,存放相关信息,没有就返回null。
相关信息指的是:(类似exec,只是string和reg换了个位置)

全局时:(此时不再类似exec,比exec展示弱,但不需要写while就能拿到全部匹配结果)

(3)split(reg)结合正则做切割:

(4)replace(reg,replacestr/function):匹配替换。第一个参数会被转成正则表达式
看看function怎么做(替换结果跟匹配结果有关系)



ES6 —— 正则的扩展:
一、RegExp 构造函数:
ES5中,构造函数的参数有两种情况:
// 情况一: var regex = new RegExp(\'xyz\', \'i\'); // 等价于 var regex = /xyz/I; // 情况二: var regex = new RegExp(/xyz/i); // 等价于 var regex = /xyz/i;
注意到情况二中, ‘i’不能隔开写,ES6中允许了:
new RegExp(/abc/ig, \'i\').flags // "I" // 上面代码中,原有正则对象的修饰符是ig,它会被第二个参数i覆盖。
二、字符串的正则方法:
字符串对象共有 4 个方法,可以使用正则表达式:match()、replace()、search()和split()。
ES6 将这 4 个方法,在语言内部全部调用RegExp的实例方法,从而做到所有与正则相关的方法,全都定义在RegExp对象上。
String.prototype.match调用RegExp.prototype[Symbol.match]String.prototype.replace调用RegExp.prototype[Symbol.replace]String.prototype.search调用RegExp.prototype[Symbol.search]String.prototype.split调用RegExp.prototype[Symbol.split]
三、u修饰符:
这个是为了修正大于\\uFFFF的 Unicode 字符。也就是说,会正确处理四个字节的 UTF-16 编码。
/^\\uD83D/u.test(\'\\uD83D\\uDC2A\') // false /^\\uD83D/.test(\'\\uD83D\\uDC2A\') // true
这样会引起一系列行为的改变:
(1)点字符:
点(.)字符在正则表达式中,含义是除了换行符以外的任意单个字符。对于码点大于0xFFFF的 Unicode 字符,点字符不能识别,必须加上u修饰符。
更加正确认识“单个字符”。
(2)新的Unicode 字符表示法
ES6 新增了使用大括号表示 Unicode 字符,这种表示法在正则表达式中必须加上u修饰符,才能识别当中的大括号,否则会被解读为量词。正则表达式无法识别\\u{61}这种表示法,只会认为这匹配 61 个连续的u。
/\\u{61}/u.test(\'a\') // true
(3)转义
没有u修饰符的情况下,正则中没有定义的转义(如逗号的转义\\,)无效,而在u模式会报错。
四、RegExp.prototype.unicode 属性:
正则实例对象新增unicode属性,表示是否设置了u修饰符。
const r1 = /hello/; const r2 = /hello/u; r1.unicode // false r2.unicode // true
五、y修饰符:
以上是关于js-正则表达式ES6--正则的扩展的主要内容,如果未能解决你的问题,请参考以下文章