ThreadPool线程池源码解析
Posted 浮生_半日闲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ThreadPool线程池源码解析相关的知识,希望对你有一定的参考价值。
ThreadPool线程池源码解析
文章目录
前言
- 如何实现线程复用的?
- 先提交的任务一定会先执行吗?
- 线程池中的线程如何做到空闲一定时间退出的?
- 没有任务时候超过最大存活时间被销毁的是非核心线程?
- 在调用shutdown方法关闭线程池的时候,如何判断线程有没有在执行任务?
- shutdown和shutdownNow两个方法区别?
- 如何处理执行失败的任务?
本觉得自己已经懂线程池了,看到以上几个问题能否都能答上来,还是又觉得自己不懂了,一脸懵逼?如果你能回答上来那么你可以绕过了。
上面前几个问题都是原理概念问题,最后一个是实际使用中必须要面对的问题,当然你可以不面对,我相信这也是觉大多数人的做法,直接忽略,才不管有没有执行成功,我把任务提交到线程池有么有最终执行成功关我毛事。本篇中先对线程池源码进行分析,逐个解答如上问题,并以实际工作案例给出常用的任务失败处理方案。
一、基本使用
如上是我们再熟悉不过的代码了。
二、执行流程
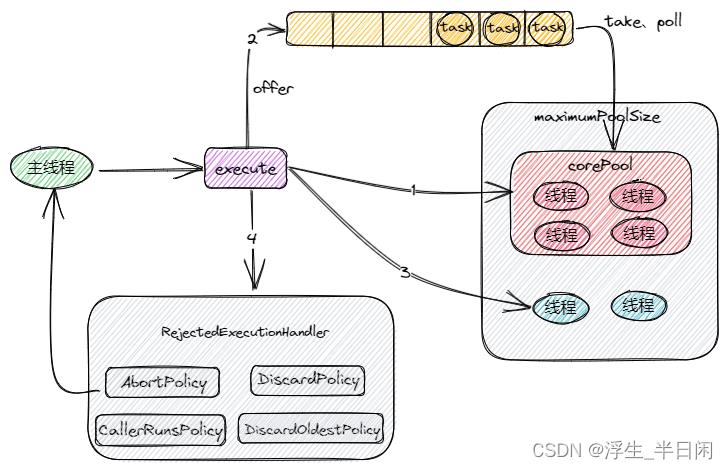
如上执行流程我们已经背诵的滚瓜烂熟了。
三、源码分析

首先看下最基本的类继承关系,我们本篇以方法execute(Runnable)作为切入分析,submit(Runnable)是对这个方法做了下封装,所以我们还是从最基本的开始。
在开始分析前execute(Runnable)方法之前先看下ThreadPoolExecutor相关重要的属性,有个大概印象就行了,遇到不清楚的再回过头来看。
ThreadPoolExecutor 中重要属性
public class ThreadPoolExecutor extends AbstractExecutorService
... ...
//高3位:表示当前线程池运行状态 除去高3位之后的低位:表示当前线程池所拥有的线程数量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 表示在ctl中,低COUNT_BITS位 用于存放当前线程数量的位
private static final int COUNT_BITS = Integer.SIZE - 3;
//低COUNT_BITS位 所能表达的最大数值
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
//线程池状态:
//表示可接受新任务,且可执行队列中的任务;
private static final int RUNNING = -1 << COUNT_BITS;
//表示不接受新任务,但可执行队列中的任务;
private static final int SHUTDOWN = 0 << COUNT_BITS;
//表示不接受新任务,且不再执行队列中的任务,且中断正在执行的任务;
private static final int STOP = 1 << COUNT_BITS;
// 所有任务已经中止,且工作线程数量为0,最后变迁到这个状态的线程将要执行terminated()钩子方法,只会有一个线程执行这个方法;
private static final int TIDYING = 2 << COUNT_BITS;
//中止状态,已经执行完terminated()钩子方法;
private static final int TERMINATED = 3 << COUNT_BITS;
private static int runStateOf(int c) return c & ~CAPACITY;
private static int workerCountOf(int c) return c & CAPACITY;
private static int ctlOf(int rs, int wc) return rs | wc;
//任务队列,当线程池中的线程达到核心线程数量时,再提交任务 就会直接提交到 workQueue
private final BlockingQueue<Runnable> workQueue;
//线程池全局锁,增加worker 减少 worker 时需要持有mainLock , 修改线程池运行状态时,也需要。
private final ReentrantLock mainLock = new ReentrantLock();
//线程池中真正存放 worker->thread 的地方。
private final HashSet<Worker> workers = new HashSet<Worker>();
// 记录线程池生命周期内 线程数最大值
private int largestPoolSize;
// 记录线程池所完成任务总数
private long completedTaskCount;
// 创建线程会使用线程工厂
private volatile ThreadFactory threadFactory;
//拒绝策略
private volatile RejectedExecutionHandler handler;
//空闲线程存活时间,当allowCoreThreadTimeOut == false 时,会维护核心线程数量内的线程存活,超出部分会被超时。
private volatile long keepAliveTime;
//控制核心线程数量内的线程 是否可以被回收。true 可以,false不可以。
private volatile boolean allowCoreThreadTimeOut;
// 核心线程池数量
private volatile int corePoolSize;
// 线程池最大数量
private volatile int maximumPoolSize;
// 默认拒绝策略
private static final RejectedExecutionHandler defaultHandler =
new AbortPolicy();
... ...
关键代码解析:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
线程池状态具体是存在ctl成员变量中,ctl中不仅存储了线程池的状态还存储了当前线程池中线程数的大小。
//表示可接受新任务,且可执行队列中的任务;
private static final int RUNNING = -1 << COUNT_BITS;
//表示不接受新任务,但可执行队列中的任务;
private static final int SHUTDOWN = 0 << COUNT_BITS;
//表示不接受新任务,且不再执行队列中的任务,且中断正在执行的任务;
private static final int STOP = 1 << COUNT_BITS;
// 所有任务已经中止,且工作线程数量为0,最后变迁到这个状态的线程将要执行terminated()钩子方法,只会有一个线程执行这个方法;
private static final int TIDYING = 2 << COUNT_BITS;
//中止状态,已经执行完terminated()钩子方法;
private static final int TERMINATED = 3 << COUNT_BITS;
线程池内部有5个常量来代表线程池的五种状态:
- RUNNING:线程池创建时就是这个状态,能够接收新任务,以及对已添加的任务进行处理。
- SHUTDOWN:调用shutdown方法线程池就会转换成SHUTDOWN状态,此时线程池不再接收新任务,但能继续处理已添加的任务到队列中任务。
- STOP:调用shutdownNow方法线程池就会转换成STOP状态,不接收新任务,也不能继续处理已添加的任务到队列中任务,并且会尝试中断正在处理的任务的线程。
- TIDYING:SHUTDOWN 状态下,任务数为 0, 其他所有任务已终止,线程池会变为 TIDYING 状态。线程池在 SHUTDOWN 状态,任务队列为空且执行中任务为空,线程池会变为 TIDYING 状态。线程池在 STOP 状态,线程池中执行中任务为空时,线程池会变为 TIDYING 状态。
- TERMINATED:线程池彻底终止。线程池在 TIDYING 状态执行完 terminated() 方法就会转变为 TERMINATED 状态。
ThreadPoolExecutor 内部类Worker
线程池中的工作线程以Worker作为体现,Worker也就是线程池中的线程,只是给线程包装了下,Worker中包含工作线程和要执行的任务。
private final class Worker extends AbstractQueuedSynchronizer implements Runnable
private static final long serialVersionUID = 6138294804551838833L;
// worker内部封装的工作线程
final Thread thread;
//当worker启动后thread线程会优先执行firstTask,当执行完firstTask后,会到queue中去获取下一个任务。
Runnable firstTask;
// 记录当前worker所完成的任务数量
volatile long completedTasks;
Worker(Runnable firstTask)
setState(-1);
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
public void run()
runWorker(this);
protected boolean isHeldExclusively()
return getState() != 0;
protected boolean tryAcquire(int unused)
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
return true;
return false;
protected boolean tryRelease(int unused)
setExclusiveOwnerThread(null);
setState(0);
return true;
public void lock() acquire(1);
public boolean tryLock() return tryAcquire(1);
public void unlock() release(1);
public boolean isLocked() return isHeldExclusively();
void interruptIfStarted()
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted())
try
t.interrupt();
catch (SecurityException ignore)
其中构造函数很重要,firstTask即为我们提交的任务,newThread(this)将自身传入,我们从上面的代码中可以看到Worker implements Runnable,即线程会执行Worker类的run()方法,
Worker(Runnable firstTask)
setState(-1);
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
run()中会执行外部类的runWorker方法。
public void run()
runWorker(this);
execute()方法
public class ThreadPoolExecutor extends AbstractExecutorService
... ...
public void execute(Runnable command)
if (command == null)
throw new NullPointerException();
// 获取ctl的值
int c = ctl.get();
// 当前线程数小于核心线程池数量,此次提交任务,直接创建一个新的worker
if (workerCountOf(c) < corePoolSize)
// addWorker 即为创建线程的过程,会创建worker对象,并且将command作为firstTask
// core==true 表示创建的线程为核心线程,false非核心线程
if (addWorker(command, true))
return;
c = ctl.get();
// 执行到这里有几种情况?
// 1.当前线程池数量已经达到corePoolSize
// 2. addWorker失败
// 当前线程池处于running状态,尝试将task放入到workQueue中
if (isRunning(c) && workQueue.offer(command))
// 获取当前ctl
int recheck = ctl.get();
// !isRunning()成功,代表当你提交到任务队列后,线程池状态被外部线程给修改,例如调用了shutDown(),shutDownNow()
// remove成功,提交之后,线程池中的线程还没消费
// remove 失败,说明在shutDown或者shutDown之前,就被线程池的线程给处理了
if (! isRunning(recheck) && remove(command))
reject(command);
// 当前线程池是running状态,
else if (workerCountOf(recheck) == 0)
// 如果当前没有线程,就添加一个线程保证当前至少有一个线程存在
addWorker(null, false);
//执行到这里,有几种情况?
//1.offer失败:offer失败,需要做什么? 说明当前queue 满了!这个时候如果当前线程数量尚未达到maximumPoolSize的话,会创建新的worker直接执行command
//2.当前线程池是非running状态:线程池状态为非running状态,这个时候因为 command != null addWorker 一定是返回false。
else if (!addWorker(command, false))
reject(command);
... ...
execute方法的执行流程大致可以分为以下几步:
- 工作线程数量小于核心数量,创建核心线程;
- 达到核心数量,进入任务队列;
- 任务队列满了,创建非核心线程;
- 达到最大数量,执行拒绝策略;
execute方法中逻辑还是很清晰的。
首先我们看第一个场景,当前线程数小于核心线程数,直接创建一个新的worker。
也就是execute()方法中的这块逻辑。
if (workerCountOf(c) < corePoolSize)
if (addWorker(command, true))
return;
c = ctl.get();
addWorker(command, true)方法
//firstTask 可以为null,如线程池刚启动初始化核心线程,worker自动到queue中获取任务,如果不是null,则worker优先执行firstTask
//core 如果为true表示创建的为核心线程 false表示为非核心线程
private boolean addWorker(Runnable firstTask, boolean core)
// 自旋:判断当前线程池状态是否允许创建线程的事情
retry:
for (;;)
// 获取当前ctl值
int c = ctl.get();
// 获取当前线程池运行状态
int rs = runStateOf(c);
// 判断当前线程池是否允许添加线程
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
// 内部自旋:获取创建线程令牌的过程
for (;;)
//判断当前线程是否超过限制,超过限制就无法创建线程
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// 通过cas将线程数量加1,能够成功加1相当于申请到创建线程的令牌
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get();
// 判断当前线程状态是否发生变化
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try
// 创建work
w = new Worker(firstTask);
//将新创建的work节点的线程 赋值给t
final Thread t = w.thread;
if (t != null)
final ReentrantLock mainLock = this.mainLock;
//持有全局锁,可能会阻塞,直到获取成功为止,同一时刻操纵 线程池内部相关的操作,都必须持锁。
mainLock.lock();
try
//获取最新线程池运行状态保存到rs中
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null))
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
// 将创建的work添加到线程池中
workers.add(w);
// 获取最新当前线程池线程数量
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
finally
// 释放锁
mainLock.unlock();
if (workerAdded)
// 添加work成功后,将创建的线程启动
t.start();
workerStarted = true;
finally
// 启动失败
if (! workerStarted)
// 释放令牌
// 将当前worker清理出workers集合
addWorkerFailed(w);
return workerStarted;
runWorker(worker )方法
从上面的addWorker方法可以看到创建了一个work添加到线程池中,然后调用start()方法,也就是调用Worker中的run方法,run方法中调用runWorker方法。
final void runWorker(Worker w)
// 工作线程
Thread wt = Thread.currentThread();
// 任务
Runnable task = w.firstTask;
w.firstTask = null;
// 释放锁
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try
// 取任务,如果有第一个任务,这里先执行第一个任务
// getTask:取任务
while (task != null || (task = getTask()) != null)
// 加锁,是因为当调用shutDown方法它会判断当前是否加锁,加锁就会跳过它接着执行下一个任务
w.lock();
// 检查线程池状态
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try
// 钩子方法,方便子类在任务执行前做一些处理
beforeExecute(wt, task);
Throwable thrown = null;
try
//真正任务执行的地方,task可能是FutureTask 也可能是 普通的Runnable接口实现类。
//如果前面是通过submit()提交的 runnable/callable 会被封装成 FutureTask。
task.run();
catch (RuntimeException x)
thrown = x; throw x;
catch (Error x)
thrown = x; throw x;
catch (Throwable x)
thrown = x; throw new Error(x);
finally
// 钩子方法,方便子类在任务执行后做一些处理
afterExecute(task, thrown);
finally
task = null;
w.completedTasks++;
w.unlock();
completedAbruptly = false;
finally
processWorkerExit(w, completedAbruptly);
关键代码解析:
while (task != null || (task = getTask()) != null)
在我们线程池刚启动还没有创建核心线程时候,提交任务到进来就会创建核心线程,创建完核心线程,调用run方法,执行提交进来的任务,这时候task也就是我们提交过来的任务,所以不为空进入循环体内,执行任务。执行完成之后又会进入上面的判断逻辑,这时候task==null了,所以进入getTask()方法从任务队列中获取任务来执行,此处也就是实现了线程复用。
w.lock();
在执行任务前要加锁,此处要结合shutDown方法来分析了,在shutDown中尝试w.tryLock()获取锁来判断线程是否在执行任务,
getTask()方法
private Runnable getTask()
// 是否超时
boolean timedOut = false;
// 自旋
for (;;)
int c = ctl.get();
// 线程池状态
int rs = runStateOf(c);
//当前程池状态是SHUTDOWN的时候会把队列中的任务执行完直到队列为空
// 线程池状态是stop时退出
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty()))
《Elasticsearch 源码解析与优化实战》第16章:ThreadPool模块分析
一、简介
每个节点都会创建一系列的线程池来执行任务,许多线程池都有与其相关任务队列,用来允许挂起请求,而不是丢弃它。 下面列出目前ES版本中的线程池。
官网: https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-threadpool.html
generic:用于通用的操作(例如,节点发现),线程池类型为 scaling。index:用于index/delete操作,线程池类型为fixed,大小为处理器的数量,队列大小为200,允许设置的最大线程数为1+处理器数量。search:用于count/search/suggest操作。线程池类型为fixed, 大小为int((处理器数量3)/2)+1,队列大小为1000。get:用于get操作。线程池类型为fixed, 大小为处理器的数量,队列大小为1000。bulk:用于bulk操作,线程池类型为fixed,大小为处理器的数量,队列大小为200,该线程池允许设置的最大线程数为1+处理器数量。snapshot:用于snaphostrestore操作。线程池类型为scaling,线程保持存活时间为5min,最大线程数为min(5, (处理器数量)/2)。warme:用于segment warm-up操作。线程池类型为scaling, 线程保持存活时间为5min,最大线程数为min(5, (处理器数量)/2)。refresh:用于refresh 操作。线程池类型为scaling, 线程空闲保持存活时间为5min,最大线程数为min(10, (处理器数量)/2)。listener:主要用于Java客户端线程监听器被设置为true时执行动作。线程池类型为scaling,最大线程数为min(10, (处理器数量)/2)。same:在调用者线程执行,不转移到新的线程池。management:管理工作的线程池,例如,Node info、Node tats、 List tasks等。flush:用于索引数据的flush操作。force_merge:顾名思义,用于Lucene分段的force merge。fetch_shard_started :用于TransportNodesAction.fetch_shard_store :用于TransportNodesListShardStoreMetaData。thread_pool.search.size: 30:线程池和队列的大小可以通过配置文件进行调整,例如,为search增加线程数和队列大小:
二、线程池类型
如同任何要并发处理任务的服务程序一样,线程池要处理的任务类型大致可以分为两类:CPU计算密集型和I/O密集型。对于两种不同的任务类型,需要为线程池设置不同的线程数量。
一般说来,线程池的大小可以参考如下设置,其中N为CPU的个数:
- 对于CPU密集型任务,线程池大小设置为N+1;
- 对于I/O密集型任务,线程池大小设置为2N+1;
对于计算密集型任务,线程池的线程数量 一 般不应该超过N+1。如果线程数量太多,则会导致更高的线程间上下文切换的代价。加1是为了当计算线程出现偶尔的故障,或者偶尔的I/O、发送数据、写日志等情况时,这个额外的线程可以保证CPU时钟周期不被浪费。
I/O密集型任务的线程数可以稍大一些,因为I/O密集型任务大部分时间阻塞在I/O过程,适当增加线程数可以增加并发处理能力。而上下文切换的代价相对来说已经不那么敏感。但是线程数量不一定设置为2N+1,具体需要看I/O等待时间有多长。等待时间越长,需要越多的线程,等待时间越少,需要越少的线程。因此也可以参考下面的公式:
最佳线程数= ((线程等待时间 + 线程CPU时间) /线程CPU时间) * CPU数
为了应对这两种类型的任务,ES封装了以下类型的线程池。
2.1、fixed
线程池拥有固定数量的线程来处理请求,当线程空闲时不会销毁,当所有线程都繁忙时,请求被添加到队列中。
size参数用来控制线程的数量。queue_size 参数用来控制线程池相关的任务队列大小。设置为-1表示无限制。当请求到达时,如果队列已满,则请求将被拒绝。
例如:
thread_pool.search.size: 30
thread_pool.search.queue_size: 1500
2.2、scaling
scaling 线程池的线程数量是动态的,介于core和max参数之间变化。线程池的最小线程数为配置的core大小,随着请求的增加,当core数量的线程全都繁忙时,线程数逐渐增大到max数量。max是线程池可拥有的线程数.上限。当线程空闲时,线程数从max大小逐渐降低到core大小。
keep_alive参数用来控制线程在线程池中的最长空闲时间。
例如:
thread_pool.warmer.core: 1
thread_pool.warmer.max:8
thread_pool.warmer.keep_alive: 2m
2.3、direct
这种线程池对用户并不可见,当某个任务不需要在独立的线程执行,又想被线程池管理时,于是诞生了这种特殊类型的线程池:在调用者线程中执行任务。
2.4、fixed_auto_queue_size
与fixed类型的线程池相似,该线程池的线程数量为固定值,但是队列类型不一样。 其队列大小根据利特尔法则( Little’s Law) 自动调整大小。该法则的详细信息可以参考https://en.wikipedia.org/wiki/Little%27s_law。 该线程池有以下参数可以调整:
size:用于指定线程数量;queue_size,:指定初始队列大小; .min_queue_size:最小队列大小;max_queue_size:最大队列大小;auto_gueue_frame_size: 调整队列之前进行测量的操作数;target_response_time:一个时间值设置,用来指示任务的平均响应时间,如果任务经常高于这个时间,则线程池队列将被调小,以便拒绝任务。
该线程类型为实验性质,未来可能会移除。目前只有search线程池使用这种类型。(
Deprecated in 7.7.0 and will be removed in 8.0. )
三、处理器设置
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-threadpool.html#node.processors
默认情况下,ES自动探测处理器数量。各个线程池的大小基于这个数量进行初始化。在某些情况下,如果想手工指定处理器数量,则可以通过设置 processors 参数实现:
processors: 2
有以下几种场景是需要明确设置processors数量的:
(1)、在同一台主机上运行多个ES实例,但希望每个实例的线程池只根据一部分CPU来设置,此时可以通过processors参数来设置处理器数量。例如,在16核的服务器上运行2个实例,可以将processors设置为8。请注意,在单台主机上运行多个实例,除了设置processors数量,还有许多更复杂的参数需要设置。例如,修改GC线程数,绑定进程到CPU等。
(2)、有时候自动探测出的处理器数量是错误的,在这种情况下,需要明确设置处理器数量。要检查自动探测的处理器数量,可以使用节点信息API中的os字段来查看。
四、查看线程池
ES提供了丰富的API查看线程池状态,在监控节点健康、排查问题时非常有用。
4.1、cat thread pool
该命令显示每个节点的线程池统计信息。默认情况下,所有线程池都返回活动、队列和被拒绝的统计信息。我们需要特别留意被拒接的信息,例如,bulk 请求被拒绝意味着客户端写入失败。在正常情况下客户端应该捕获这种错误(错误码429)并延迟重试,但有时客户端不一定对这种错误做了处理,导致写入集群的数据量低于预期值。
curl -X GET "localhost:9200/_cat/thread_pool"
返回信息如下:
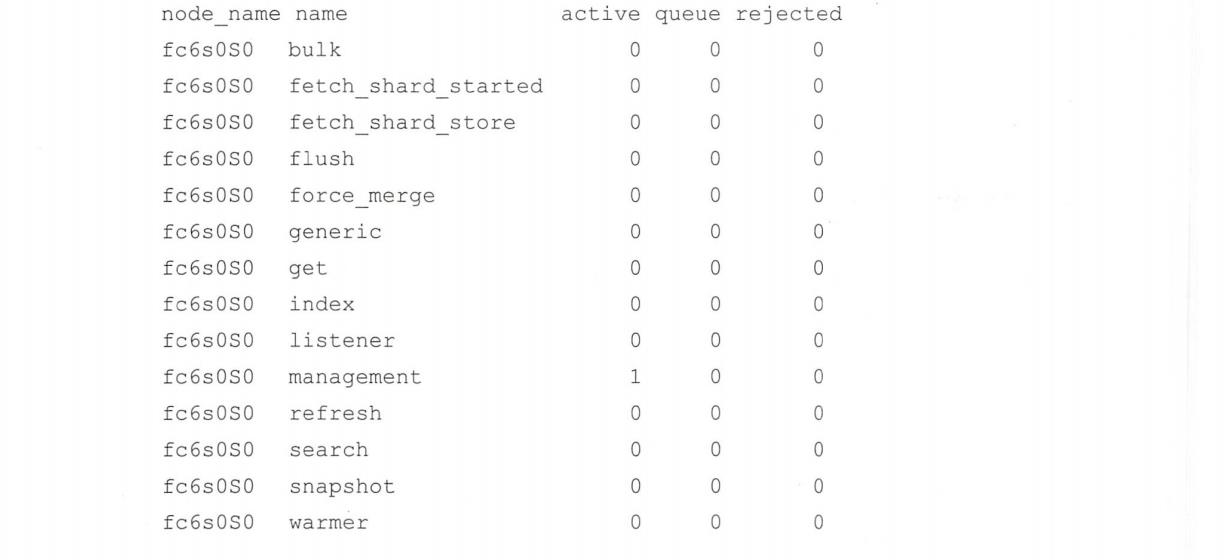
- active 表示当前正在执行任务的线程数量
- queue 表示队列中等待处理的请求数量
- rejected 表示由于队列已满,请求被拒绝的次数。
对返回结果进行过滤等更多用法可参考官方手册: https://www.elastic.co/guide/en/elasticsearch/reference/6.1/cat-thread-pool.html。
4.2、nodes info
节点信息API可以返回每个线程池的类型和配置信息,例如,线程数量、队列大小等。下面的第一条命令返回所有节点的信息,第二条命令返回特定节点的信息。.
curl -X GET "localhost:9200/_nodes"
curl -X GET "localhost:9200/_nodes/nodeId1, nodeId2"
节点信息API返回的信息非常大,其中与线程池相关信息在thread_ pool 字段中,选取部分信息如下:
"thread_pool" : {
"force_merge" : {
"type" : "fixed",
"min" : 1,
"max" : 1,
"queue_size" : - 1
},
"fetch_shard started" : {
"type" : "scaling",
"min" : 1,
"max" : 16,
"keep_alive" : "5m",
"queue_size" : -1
}
}
该命令的完整信息可参考官方手册: https://www.elastic.co/guide/en/elasticsearch/reference/6.1/cluster-nodes-info.html
4.3、nodes stats
statsAPI返回集群中一个或全部节点的统计数据。
下面的第一条命令返回所有节点的统计数据,第二条命令返回特定节点的统计数据。
curl -X GET “localhost:9200/_nodes/stats”
curl -X GET “localhost:9200/_nodes/nodeId1, nodeId2/stats”
默认情况下,该API返回全部 indices、oS、process、jvm、transport、http、fs、breaker 和thread_pool 方面的统计数据。其中线程池相关的返回结果摘要如下:
"thread_pool" : {
"bulk" : {
"threads" : 0,
"queue" : 0,
"active" : 0,
"rejected" : 0,
"largest" : 0,
"completed" : 0
}
}
该命令的完整使用方式可参考官方手册: https://www.elastic.co/guide/en/elasticsearch/reference/6.1/cluster-nodes-stats.html。
4.4、nodes hot threads
该API返回集群中一个或全部节点的热点线程。
当发现节点进程占用CPU非常高时,想知道是哪些线程导致的,这些线程具体在执行什么操作,常规做法是通过top命令配合jstack来定位线程,现在ES提供了更便捷的方式,通过hot threads API可以直接返回这些信息。
下面的第一条命令返回所有节点的热点线程,第二条命令返回特定节点的热点线程。
curl -X GET "localhost:9200/_nodes/hot_threads"
curl -X GET "localhost:9200/nodes/nodeId1, nodeId2/hot_threads"
该命令支持以下参数:
threads:返回的热点线程数,默认为3。interval:ES对线程做两次检查,来计算某个操作.上花费时间的百分比,此参数定义这个间隔时间。默认为500 ms。type:定义要检查的线程状态类型,默认为CPU.API可以检查线程的CPU占用时间、阻塞(block)时间和等待(wait) 时间。ignore_idle_threads:如果设置为true, 则空闲线程(例如,在套接字中等待,或者从空队列中获取任务)将被过滤。默认值为true。
其返回信息的样例如下图所示。

返回信息中的第一行表明这个是哪个节点的信息,以及这个节点的IP地址等。
::: {node1} {un- 9UZ4PS8-K6hF59x1MWA} {bjk2C_ _6USh0YgMYKcBWKLQ} {node1.eshost}
{10.10.13.15:9300}
接下来列出哪个线程占用较多的CPU,以及CPU的占用比:
82.2% (411.2ms out of 500ms) cpu usage by thread 'elasticsearch [node1]
[bulk] [T#1] '
最后是该线程的堆栈信息。
ES中的线程池是基于对Java线程池的封装和扩展。我们先看一下Java线程池的结构和使用方式,这些是ES内部线程原理的基础知识。
4.5、Java 的线程池结构
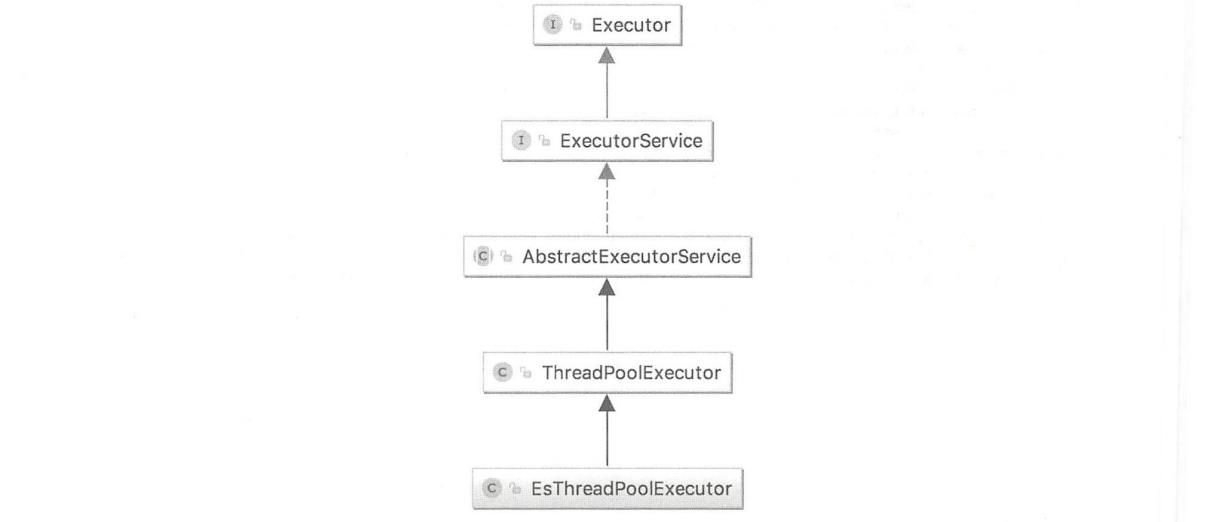
Java内部的线程池称为Executor框架,几个基本的类概念如下:
- Runable定义一个要执行的任务。
- Executor提供了execute 方法,接受一个Runable实例,用来执行一个任务。
- ExecutorService是线程池的虚基类,继承自Executor, 提供了shutdown, shutdownNow等关闭线程池接口。
- ThreadPoolExecutor线程池的具体实现。继承自ExecutorService,维护线程创建、线程生命周期、任务队列等。
- EsThreadPoolExecutor是ES对ThreadPoolExecutor的扩展实现。未来会增加一些统计信息。
这几个类的继承结构如下图所示。
我们以一个简单的例子来看看Java 线程池的用法,ExecutorService 类用于保存创建的线程池实例,后续调用execute方法执行任务。在下面的例子中,任务类TestRunnable只是打印当前线程名称。
import java. util.concurrent.ExecutorService;
import java. util.concurrent.Executors;
public class ThreadPoolDemo {
public static void main(String[] args) {
//通过Executors构建一个固定大小的线程池,线程数量为2,返回线程池实例
ExecutorService executorService = Executors.newFixedThreadPool (2) ;
//调用 线程池的execute方法执行一个任务
executorService.execute(new TestRunnable());
}
}
class TestRunnable implements Runnable {
public void run() {
System.out.println (Thread.currentThread().getName()) ;
}
}
ES内部创建线程池时,返回类型同样是ExecutorService类。接下来我们通过构建过程来看看ThreadPoolExecutor的结构,其构造函数如下:
public ThreadPoolExecutor (int corePoolSize,
int maximumPoolSize,
long keepAl iveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 || max.imumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException() ;
if (workQueue == null || threadFactory == null || handler == null)
throw new Nul lPointerException() ;
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue ;
this.keepAliveTime = unit.toNanos (keepAliveTime) ;
this.threadFactory = threadFactory;
this.handler = handler;
}
几个重要参数的含义如下:
corePoolSize:线程池大小;maximumPoolSize:最大线程数量;keepAliveTime:线程空闲回收时间;BlockingQueue:任务队列;handler: 队列满,拒绝请求时的回调函数。
ThreadPoolExecutor类是Java线程池的具体实现,是整个线程池中最重要的类,ES 基于这个类进行了一些扩展。
五、ES的线程池实现
**ES中使用的线程池绝大部分封装在ThreadPool类中,**个别独立线程池的实现在本章末尾讨论。除了个别情况,在ThreadPool类中,会创建各个模块要使用的全部线程池。本章开始所讨论的几种线程池就是在ThreadPool类中创建的。
ThreadPool类创建各个线程池,要使用线程池的各个内部模块会引用ThreadPool类对象,通过其对外提供executor方法,根据线程池名称获取对应的线程池引用,进而执行某个任务。
ThreadPool对外提供的重要方法如下表所示。
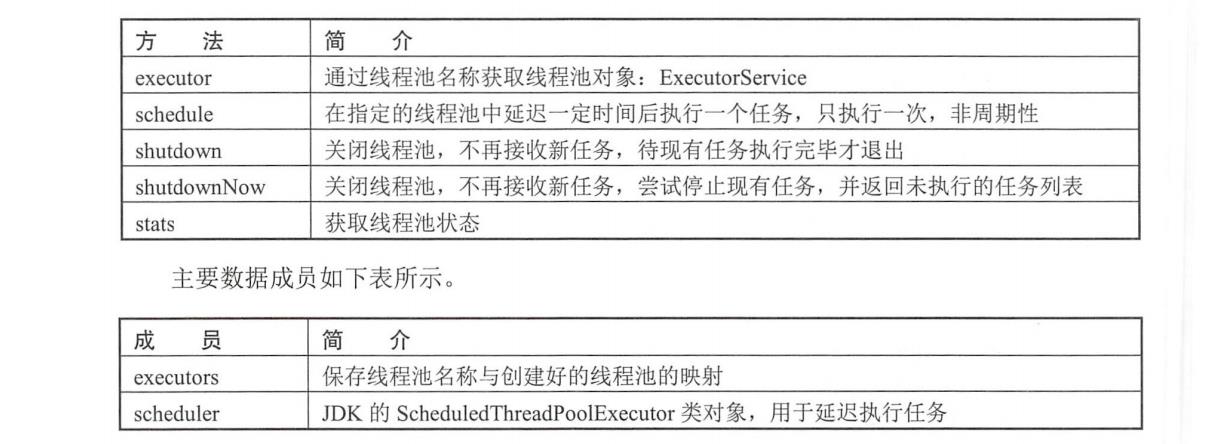
当某个模块要在新的线程中启动任务时,典型的使用方式如下:
threadPool.executor(ThreadPool.Names.SNAPSHOT).execute(() ->
beginSnapshot (newState, newSnapshot, request.partial(), listener));
threadPool.executor方法返回snapshot线程池( ExecutorService类)的引用,通过线程池的execute方法执行任务,在本例中,任务的Runnable是Lambda表达式定义的。
5.1、ThreadPool 类结构与初始化
ThreadPool类对象在节点启动时初始化,在Node类的构造函数中初始化ThreadPool类:
final ThreadPool threadPool = new ThreadPool (settings, executorBuilders.toArray (new ExecutorBuilder[0]));
线程池对象构建完毕,将这个类的引用传递给其他要使用线程池的模块:
final ResourcewatcherService resourceWatcherService = new ResourceWatcherService (settings, threadPool);
线程池的名称在内部类Names中,最好记住它们的名字,有时需要通过jstack查看堆栈,ES的堆栈非常长,这就需要通过线程池的名称去查找关注的内容。
public static class Names {
public static final String SAME = "same";
public static final String GENERIC = "generic";
public static final String LISTENER = "listener";
public static final String GET = "get";
public static final String INDEX = "index" ;
public static final String BULK = "bulk";
public static final String SEARCH = "search";
public static final String MANAGEMENT = "management" ;
public static final String FLUSH = "flush";
public static final String REFRESH = "refresh";
public static final String WARMER = "warmer" ;
public static final String SNAPSHOT = "snapshot";
public static final String FORCE MERGE = "force_merge";
public static final String FETCH\\_SHARD\\_STARTED = "fetch\\_shard\\_started";
public static final String FETCH\\_SHARD\\_STORE = "fetch\\_shard\\_store";
}
线程池类型由枚举类型ThreadPoolType 定义:
enum ThreadPoolType {
DIRECT ("direct") ,
FIXED ("fixed") ,
FIXED_AUTO_QUEUE_SIZE("fixed_auto_queue_size") ,
SCALING ("scaling") ;
}
在ThreadPool类构造函数中,全部的线程池被初始化:
public ThreadPool (final Settings settings, final ExecutorBuilder<?> ... customBuilders) {
final Map<String, ExecutorBuilder> builders = new HashMap<> () ;
builders.put(Names.GENERIC, new ScalingExecutorBuilder(Names.GENERIC, 4, genericThreadPoolMax, TimeValue. timeValueSeconds (30))) ;
builders.put (Names. INDEX, new FixedExecutorBuilder (settings, Names.INDEX, availableProcessors, 200)) ;
//index/delete操作与bulk使用同一个线程池
builders.put(Names.BULK, new FixedExecutorBuilder(settings, Names.BULK, availableProcessors, 200));
builders.put(Names.GET, new FixedExecutorBuilder(settings, Names.GET, availableProcessors, 1000)) ;
builders.put (Names.SEARCH, new AutoQueueAdjustingExecutorBuilder(settings, Names.SEARCH, searchThreadPoolSiz (availableProcessors), 1000, 1000, 1000, 2000));
builders.put (Names.MANAGEMENT, new Scal ingExecutorBuilder(Names.MANAGEMENT, 1, 5, TimeValue.timeValueMinutes(5))) ;
builders.put (Names.LISTENER, new FixedExecutorBuilder (settings, Names.LISTENER, halfProcMaxAt10, -1));
builders.put (Names.FLUSH, new ScalingExecutorBuilder (Names.FLUSH, 1, halfProcMaxAt5, TimeValue.timeValueMinutes(5))) ;
builders.put (Names . REFRESH, new ScalingExecutorBuilder(Names.REFRESH, 1, halfProcMaxAt10, TimeValue.timeValueMinutes(5))) ;
builders.put (Names.WARMER, new Scal ingExecutorBuilder (Names.WARMER, 1, halfProcMaxAt5, TimeValue.timeValueMinutes(5))) ;
builders.put (Names.SNAPSHOT, new ScalingExecutorBuilder(Names.SNAPSHOT, 1, halfProcMaxAt5, TimeValue.timeValueMinutes(5))) ;
builders.put (Names.FETCH_SHARD_STARTED, new ScalingExecutorBuilder(Names.FETCH_SHARD_STARTED, 1, 2 * availableProcessors, TimeValue.timeValueMinutes(5))) ;
builders.put (Names.FORCE_MERGE, new FixedExecutorBuilder (settings, Names.FORCE_MERGE, 1, -1) ) ;
builders.put (Names.FETCH_SHARD_STORE, new Scal ingExecutorBuilder(Names.FETCH_SHARD_STORE, 1, 2 * availableProcessors, TimeValue.timeValueMinutes(5))) ;
}
这些线程池构建成功后,最终保存到一个map结构中,map 列表根据builders信息构建, 将SAME线程池单独添加进去。
Map<String, ExecutorHolder> executors
当某个模块使用线程池时,通过线程池名称从这个map中获取对应的线程池。
public ExecutorService executor (String name) {
final ExecutorHolder holder = executors.get(name);
return holder.executor() ;
}
map 中的值: ExecutorHolder 是 ThreadPool 内部类,它只是简单封装了一下ExecutorService。
class ExecutorHolder {
private final ExecutorService executor ;
//Info类主要是线程池名称、类型、队列大小、线程数量的max和min、keepAlive时间
public final Info info;
}
5.2、fixed类型线程池构建过程
FіхеdЕхесutоrВuіldеr 类用于fixed类型的线程池构建,它的主要实现是通过 ЕѕЕхесutоrѕ.newFixed 方法构建一个ExecutorService。由于是fixed类型的线程池,因此EsThreadPoolExecutor传入的corePoolSize 和 maximumPoolSize 的大小相同。
public static EsThreadPoolExecutor newFixed (String name, int size, int queueCapacity, ThreadFactory threadFactory, ThreadContext contextHolder) {
//使用有限或无限大小的阻塞队列初始化线程池队列
BlockingQueue<Runnable> queue;
if (queueCapacity < 0) f
queue = Concur rentCollections . newBlockingQueue () ;
} else {
queue =new SizeBlockingQueue<> (ConcurrentCollections.<Runnable> newBlockingQueue(), queueCapacity) ;
}
//创建线程池
return new EsThreadPoolExecutor (name, size, size, 0, TimeUnit.MILLISECONDS, queue, threadFactory, new EsAbortPolicy(), contextHolder) ;
}
5.3、scaling类型线程池构建过程
ScalingExecutorBuilder用于 scaling类型线程池的构建,它的主要实现是通过EsExecutors.newScaling方法创建一个ExecutorService, min 和 max 分别对应corePoolSize 和 maximumPoolSize。
public static EsThreadPoolExecutor newScaling (String name, int min, int max, long keepAliveTime, TimeUnit unit, ThreadFactory threadFactory, ThreadContext contextHolder) {
//创建线程队列
ExecutorScal ingQueue<Runnable> queue = new ExecutorScalingQueue<>() ;
//min corePoolSize, max maximumPoolSize
EsThreadPoolExecutor executor = new EsThreadPoolExecutor (name, min, max, keepAliveTime, unit, queue, threadFactory, new ForceQueuePolicy(), contextHolder) ;
queue.executor = executor;
return executor ;
}
5.4、direct类型线程池构建过程
direct类型的线程池没有通过*ExecutorBuilder类创建,而是通过EsExecutors.newDirectExecutorService方法直接创建的,该方法中直接返回一个定义好的简单的线程池DIRECT_EXECUTOR_SERVICE。该线程池的实现如下,在execute方法中直接运行这个任务,因此任务在调用者所执行。
private static final ExecutorService DIRECT\\_EXECUTOR\\_SERVICE = new AbstractExecutorService《Elasticsearch 源码解析与优化实战》第16章:ThreadPool模块分析