Half-UNet:用于医学图像分割的简化U-Net架构
Posted deephub
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Half-UNet:用于医学图像分割的简化U-Net架构相关的知识,希望对你有一定的参考价值。
Half-UNet简化了编码器和解码器,还使用了Ghost模块(GhostNet)。并重新设计的体系结构,把通道数进行统一。
论文动机
编码器的不同类型的架构图,编码器(A-C)的结构分别来源于U-Net的编码器、解码器和全的Unet结构。

下面是上图的一些结果指标
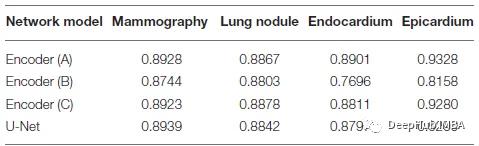
将U-Net 的编码器和解码器都视为编码器。通过设计单个解码器来聚合 C1 到 C16 的特征,其结构与 UNet 3+ 中的全尺寸特征聚合相同。编码器(A)可以达到与编码器(C)相当的性能,而编码器(B)的性能明显下降。也就是说U-Net的解码器(图中的B部分)是可以被简化的并且不影响性能。
Half-UNet
1、统一通道数
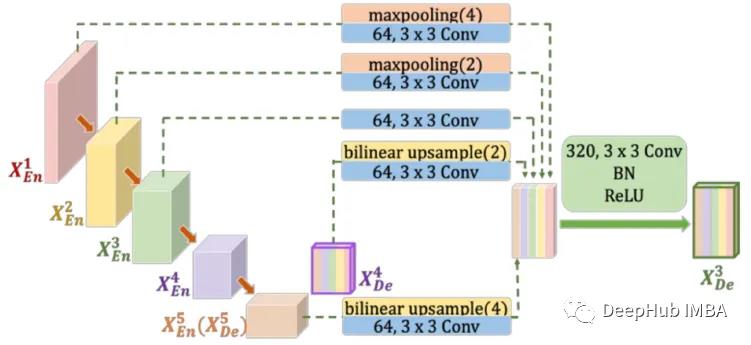
上图说明了如何在UNet3+的第三解码器层中构造全尺寸聚合特征映射。
在U-Net和UNet 3+的每一个下采样步骤中,特征通道的数量都增加了一倍,增强了特征表达的多样性。但是这增加了模型的复杂性。在 Half-UNet 中,所有特征图的通道数是统一的,也就是减少了卷积运算中的过滤器数量。
2、全尺寸特征融合

U-Net和UNet 3+都使用串联操作进行特征融合,这需要更多的内存和计算量。而加法操作不需要额外的参数和计算复杂度。将不同比例尺的特征图上采样到原始图像的大小,然后通过加操作进行特征融合。
从上图可以看到,他只用了unet的编码器部分,也就是一半的unet,所以这就是Half-UNet的由来
3、Ghost 模块

与标准卷积相比,Half-UNet 使用 Ghost 模块来减少所需的参数和 FLOP。与 GhostNet 中一样,Ghost 模块使用廉价操作的同时生成更多的特征图。
使用 s=2,其中 s 表示固有特征图比例的倒数。一半的特征图由卷积生成,另一半由深度可分离卷积生成。最后将特征图的两部分连接起来形成输出。
结果
论文使用3个数据集

定量结果
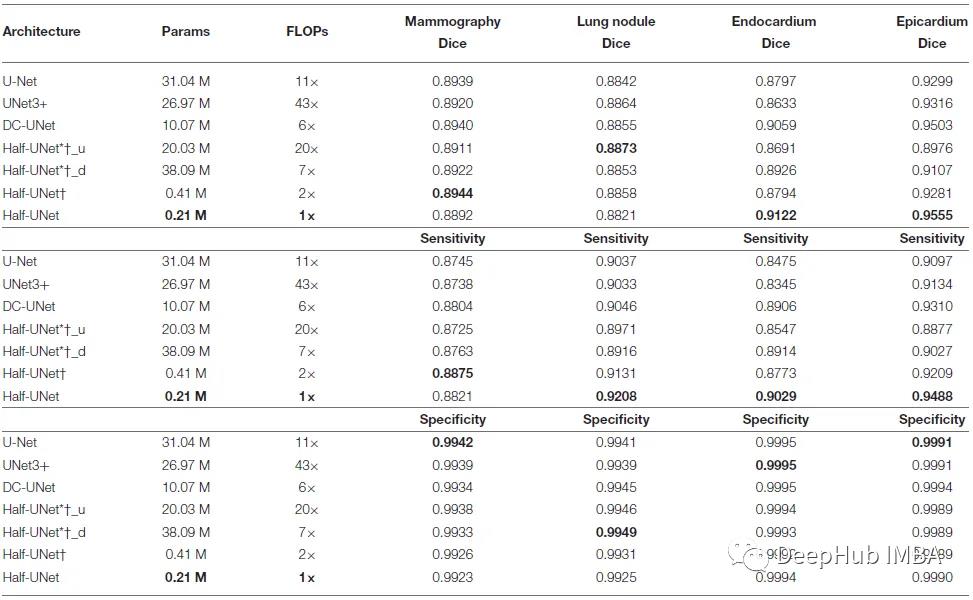
Half-UNet†:删除 Half-UNet 中的 Ghost 模块,在乳房 X 光图像方面优于 U-Net 及其变体,在肺结节图像方面比 Half-UNet 更接近U-Net。Half-UNet† 在左心室 MRI 图像方面的表现不如 Half-UNet。
与U-Net及其变体相比,Half-UNet(有无Ghost模块)具有相似的分割精度,而参数和flop分别降低了98.6%和81.8%。
Half-UNet†u 和 Half-UNet †d 的通道数在下采样后翻倍。解码器中的特征融合有两种策略:
1、Upsampling2D + 3×3 convolution,Half-UNet†u和UNet 3+是这样做的;
2、反卷积,也就是Half-UNet†_d和U-Net所做的。
可以看到Half-UNet†u和Half-UNet†d与Half-UNet†相比,增加了所需的flop和参数。
定性结果

Half-UNet、U-Net 和 UNet 3+ 在左心室 MRI 中的定性比较。Half-UNet 可以更完整地分割心内膜和心外膜边界。
进一步的研究
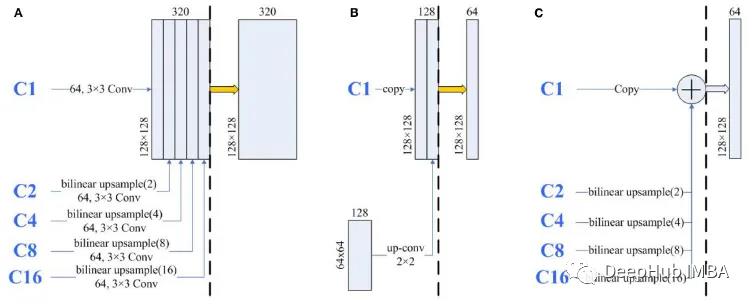
在Half-UNet子网络的左侧,由于双线性上采样和加法都是线性运算,因此几乎不产生参数和计算。在Half-UNet子网络的右侧部分,由于输入通道数量较少(只有64个),并且使用了Ghost模块,卷积的代价明显小于其他结构。

Half-UNet避免了上述三种网络的问题,大大降低了所需的参数和FLOPs。
总结
根据论文表述U-Net 在医学图像分割中的成功主要归功于其分而治之的解决方案,而不是特征融合。所以作者提出了Half-UNet,简化了特征融合部分。
根据我个人的理解,Half-UNet 除了大大减少了参数和FLOPs以外,应该会在分割界限不尖锐的情况表现的比unet更好。
论文地址:Half-UNet: A Simplified U-Net Architecture for Medical Image Segmentation
https://avoid.overfit.cn/post/b6a976d524644102bec313b1a28e0375
自然和医学图像的深度语义分割:网络结构
参考技术A 原文链接: https://www.yanxishe.com/blogDetail/18223?from=jianshu0312一、写在前面:
网络架构的设计主要是基于 CNN 结构延伸出来的。主要的改进方式有两点:新神经架构的设计(不同深度,宽度,连接性或者拓扑结构)或设计新的组件(或者层)。下面我们逐个去分析了解。
本文涉及到的论文范围如下图:
二、网络架构的改进
2.1.1 FCN
传统的 CNN 分割,为了对一个像素分类,使用该像素周围的一个图像块作为 CNN 的输入用于训练和预测。缺点很多:比如存储开销大,计算效率低,像素块大小也限制了感知域的大小。基于存在的这些问题,由 Long 等人在 2015 年提出的 FCN 结构,第一个全卷积神经网络的语义分割模型。我们要了解到的是,FCN 是基于 VGG 和 AlexNet 网络上进行预训练,然后将最后两层全连接层改为的卷积层。
FCN 具体处理过程是怎么样的?从 pool1 开始,每个 pool 后图像都会变为上个池化后图像的 1/2。Pool1 为原图的 1/2,以此类推,pool5 后为原图的 1/2^5,conv6,和 conv7 之后的图像保持不变,进行 stride=32 的反卷积,得到 FCN-32s。也就是直接对 pool5 进行 32 倍上采样获得 32 upsampled feature,再对 32 upsampled feature 每个点做 softmax prediction,就可以获得 32*upsampled prediction(分割图)。
FCN 这三个创新点有哪些? 全卷积 :用于解决逐像素的预测问题。通过将基础网络最后面几个全连接层换成卷积层,可实现任意大小的图像输入,并且输入图像大小与输入相对应。 反卷积 :端到端的像素级语义分割需要输出大小和输入图像大小一致。但是传统的 conv+pooling 结构会缩小图片尺寸。基于此作者引入反卷积(deconvolution)操作,对缩小后的特征进行上采样,恢复原始图像大小。 跳跃结构 :语义分割包括语义识别和目标定位。卷积网络的高层特征图可以有效的反应语义信息,而低层特征图可以有效反应目标的位置信息。语义分割任务同时进行语义识别和目标定位。作者提出的跨层连接结构(skip architecture),将低层的目标位置信息和高层语义信息进行融合,以此来提升语义分割性能。在此基础上进行 2 倍采样,2 倍 upsample 之后与 pool4 的像素点相加,进行 stride=16 的 upsample,为此 FCN-16s,重复上面类似的步骤,得到 FCN-8s。
了解到以上信息,应该对 FCN 有个整体的认识了。还有一些细节部分,比如 FCN 采用的简单的 softmax 分类损失函数,采用双线性差值 + 反卷积进行上采样,在微调的时候没有采用类别平衡策略。分割结果来看,FCN-8s>FCN-16s>FCN-32s。也就是说使用多层特征融合有利于提高分割准确性。
2.1.2 SegNet
SegNet 主要动机是在场景理解 。它在设计的时候考虑的是预测期间保证内存和计算时间上的效率。其中,SegNet 和 FCN 有很多相似之处,编码网络使用 VGG16 的前 13 层卷积;移除全连接;解码器使用从相应的编码器的 max-pooling indices 进行 upsampling。
对比 SegNet 和 FCN 实现 Decoder 的过程。FCN 是利用双线性插值初始化的反卷积进行上采样。而 SegNet 则是在每次 pooling 时,都存下最大值的位置,在 upsample 时将 input 值直接赋给相应的位置,其他位置的值置零。
2.1.3 U-Net
接下来,我们需要了解的是 U-Net。U-net 网络架构,由收缩路径(contracting path)和扩展路径(expanding path)组成。每一层使用两个 3 乘 3 的 conv kernel,每次卷积都进行 Relu 和 stride=2 的 maxpooling 进行下采样。四次操作后输出结果称之为 feature map。
2 乘 2 的反卷积,上采样,通道数减半,并将左边对称位置的 feature map copy 到右边进行 concate 操作,来融合下采样的浅层位置信息和高层语义信息。合并后在进行 3*3 的卷积操作。最后 output 之前,通道数表示分类的类别产生 N 类分割结果,最后选择出概率值最大的分割结果,作为最后的分割图。
U-Net 中常常会问为什么适用于医学图像这个问题.。首先分析医学影像数据特点:图像语义较为简单,结构较为固定:都是一个固定的器官的成像。而且器官本身结构固定,语义信息没有特别丰富,所以高级语义信息和低级特征都非常重要。(U-net 的 skip connection 可以解决这个问题);数据量少:医学影像的数据较难获取,为了防止过拟合,设计的模型不宜过大;多模态:医学影像是具有多种模态的;可解释性:医生需要进一步指导病灶在哪一层,哪一层的哪个位置,分割结果能求体积么?而且 U-Net 在自然图像分割也取得了不错的效果。
需要注意的一点:Unet 融合浅层信息是 maxpooling 之前还是之后的结果?是 maxpooling 之前的结果。因为 Maxpooling 之后会丢失准确的位置信息。
2.1.4 V-Net
V-Net 也就是 3D 的 U-net 的一种版本,3D 卷积,引入残差模块和 U-Net 的框架。整个网络分为压缩路径和非压缩路径,也就是缩小和扩大 feature maps,每个 stage 将特征缩小一半,也就是 128-128-64-32-16-8,通道上为 1-16-32-64-128-256。每个 stage 加入残差学习以加速收敛。 图中的圆圈加交叉代表卷积核为 5 乘 5 乘 5,stride 为 1 的卷积,可知 padding 为 2 乘 2 乘 2 就可以保持特征大小不变。每个 stage 的末尾使用卷积核为 2 乘 2 乘 2,stride 为 2 的卷积,特征大小减小一半(把 2x2 max-pooling 替换成了 2x2 conv.)。整个网络都是使用 keiming 等人提出的 PReLU 非线性单元。网络末尾加一个 1 乘 1 乘 1 的卷积,处理成与输入一样大小的数据,然后接一个 softmax。
而且 V-Net 采用 Dice coefficient 损失函数,如下:
Pi 为预测的前景,Gi 为标记的前景,使用这个函数能有效避免类别不平衡的问题。
2.1.5 Dense-UNet
Dense U-net(原名:one-hundred layers Tiramisu Network)该架构是由密集连接块(dense block)构建的。该架构由向下过度的两个下采样路径和向上过度的两个上采样路径组成。且同样包含两个水平跳跃连接,下采样 Dense 模块的输出与同水平的上采样 Dense 模块输入的相应特征图拼接在一起。上采样路径和下采样路径的连接模式并不完全相同:下采样路径中,每个密集块外有一条跳跃性连接,从而导致 feature map 数量线性增长,上采样中没有此操作。
主要创新点是融合了 Dense-Net 和 U-Net 网络。
2.1.6 DeepLab 系列网络
DeepLabV1:首次把空洞卷积(dilated convolution) 引入图形分割领域, 融合卷积神经网络和概率图模型:CNN + CRF,提高了分割定位精度。
DeepLabV2:ASPP (扩张空间金字塔池化):CNN+CRF。
DeepLabV3:改进 ASPP,多了 1 乘 1 卷积和全局平均池化(global avg pool);对比了级联和并联空洞卷积的效果。
DeepLabV3+:加入编解码架构思想,添加一个解码器模块来扩展 DeepLabv3;将深度可分离卷积应用于 ASPP 和解码器模块;将改进的 Xception 作为 Backbone。
2.1.7 PSPNet
PSPNet 全名是 Pyramid Scene Parsing Network(金字塔场景解析网络)。提出了金字塔池化模块(pyramid pooling module)能够聚合不同区域的上下文信息,从而提高获取全局信息的能力。
输入图像后,使用预训练的带空洞卷积 ResNet 提取特征图。最终的特征映射大小是输入图像的 1/8;在特征图上,我们使用 C 中的金字塔池化模块收集上下文信息。使用 4 层金字塔结构,池化内核覆盖了图像的全部、一半和小部分。他们被融合为全局先验信息;在 c 的最后部分将之前的金字塔特征映射与原始特征映射 concate 起来;在进行卷积,生成 d 中的最终预测图。
总结
基于深度学习的图像语义分割模型大多遵循编码器-解码器体系结构,如 U-Net。近几年的研究成果表明,膨胀卷积和特征金字塔池可以改善 U-Net 风格的网络性能。
参考文献:
Deep Semantic Segmentation of Natural and Medical Images: A Review
以上是关于Half-UNet:用于医学图像分割的简化U-Net架构的主要内容,如果未能解决你的问题,请参考以下文章