HashMap初始容量如何设置
Posted 如风之夏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap初始容量如何设置相关的知识,希望对你有一定的参考价值。
集合初始化的时候,建议指定集合初始化值大小。
说明:HashMap使用HashMap(int initialCapacity) 初始化。
正例:initialCapacity=(需要存储的元素个数/负载因子)+1 。
initialCapacity = (int) ((float) expectedSize / 0.75F + 1.0F)
注意负载因子(即loaderfactor) 默认为0.75,如果暂时无法确定初始值大小,请设置为16(即默认值)。
反例:HashMap需要放置1024个元素,由于没有设置容量初始大小,随着元素不断增加,容量7次被迫扩大,resize需要重建hash表,严重影响性能。
在jdk中,当我们new HashMap并且指定初始化容量capacity时,jdk会帮我们取第一个大于capacity的2次幂。
具体的实现是:
-
先把capacity - 1
-
进行多次无符号右移和或运算
-
最后 + 1
其中1,2,3步作用是将初始容量变成2次幂,比如初始容量是3将变成4,初始容量为5将变成8,也就是得到最近且大于初始容量的2次幂的值,其中得到的2次幂就是Map对象实际容量大小,
实际容量大小一定是2次幂。
比如:
- 新建一个Map,事先知道只存储一个元素,那么它的初始容量可以设置为2,put一个元素不会扩容,如果设置为1,put一个元素将会扩容一次。
- 如果事先知道只存储2个元素,那么它的初始容量可以为3,也可以为4,因为3,4初始容量会转化为最近的2次幂,也就是4.
- 如果事先知道只存储3个元素,那么它的初始容量可以设置为5,6,7,8
综上可知:
初始容量可以设置为:(int) ((float) expectedSize / 0.75F + 1.0F) 到最近2次幂之间的数值。
注意点:
HashMap 中更为危险的是,HashMap 在并发执行扩容操作时会引起死循环,导致 CPU 利用率接近100%。因为多线程会导致 HashMap 的 Entry 链表形成环形数据结构,一旦形成环形数据结构,Entry 的 next 节点永远不为空,就会在获取 Entry 时产生死循环。形成环形链表的原因主要跟 JDK1.7 下 HashMap 发生碰撞后,链表是前序插入有关。
应如何设置HashMap容量的初始值?
应如何设置HashMap容量的初始值?
Java中的集合框架是每一个java程序员使用很多的,其中hashMap的使用也是很多的,我之前也写过一篇对hashMap源码进行比较详细分析的博客:链接,读者可以参考学习。然后有看过阿里编程规范的应该知道,规范里指出在使用hashMap时候是可以指定一个初始化的容量的,然后具体原因是什么?
ok,我们还是找到崇山版的编程规范,这是最新的文档,在阿里的《阿里编程规范崇山版》#(六) 集合处理 # 17里找到阿里规范对hashMap初始化容量的建议:
【推荐】集合初始化时,指定集合初始值大小。
说明:HashMap 使用 HashMap(int initialCapacity) 初始化,如果暂时无法确定集合大小,那么指定默
认值(16)即可。
正例:initialCapacity = (需要存储的元素个数 / 负载因子) + 1。注意负载因子(即 loader factor)默认
为 0.75,如果暂时无法确定初始值大小,请设置为 16(即默认值)。
反例: HashMap 需要放置 1024 个元素,由于没有设置容量初始大小,随着元素增加而被迫不断扩容,
resize()方法总共会调用 8 次,反复重建哈希表和数据迁移。当放置的集合元素个数达千万级时会影响程序
性能。
从上面信息可以知道几个知识点:
- HashMap默认的初始化容量是16,也就是不指定的情况,就是16
- 规范里建议我们设置 initialCapacity = (需要存储的元素个数 / 负载因子) + 1
- 规范里指出没有指定容量的情况,可能会进行扩容resize,需要重建hash表,比较耗性能
ok,从规范里知道,不指定的情况可能会导致hashMap的扩容问题,什么情况会进行扩容?从HashMap源码里知道大于 initialCapacity * 负载因子(默认0.75f)的时候就会进行扩容
下面给出一个例子,在指定了容量,性能就会好?
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
import java.util.HashMap;
import java.util.Map;
public class HashMapExample
public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException
Map<String, Object> map = new HashMap<>(4);
map.put("name" , "tom");
printHashMapInfo(map);
map.put("address" , "hangzhou");
printHashMapInfo(map);
map.put("tel" , "15522299988");
printHashMapInfo(map);
map.put("email", "22999888@qq.com");
printHashMapInfo(map);
protected static void printHashMapInfo(Map<String , Object> map) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException
Class<?> mapCls = map.getClass();
Method capacityMethod = mapCls.getDeclaredMethod("capacity");
capacityMethod.setAccessible(true);
System.out.println(String.format("capacity:%s , size :%d" , capacityMethod.invoke(map) , map.size()));
在新增到4的时候,进行了扩容,为什么?因为hashMap里达到阈值,容量*0.75之后,就会进行扩容resize,然后容量从4变成了8
capacity:4 , size :1
capacity:4 , size :2
capacity:4 , size :3
capacity:8 , size :4
然后我们对初始容量进行修改,比如改为6,按照阿里的规范initialCapacity = (需要存储的元素个数 / 负载因子) + 1,再次打印:
capacity:8 , size :1
capacity:8 , size :2
capacity:8 , size :3
capacity:8 , size :4
这次打印处理的结果,可以看出没有进行扩容了,所以这个容量指定不能随便指定
ok,跟到这里,读者是否会有一个疑问?我们刚才传入的初始容量,明明是6,然后打印时候,怎么打印出8了?其实这个是hashMap源码对我们传入的数据进行重新计算,重新找出最近的一个2的n次方的值,比如传入6,距离最近的值就是2的3次方8
具体的源码,可以在hashMap源码里找到
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap)
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
ok,然后又有一个问题了,hashMap的开发者为什么要将初始容量转变为2的n次方?
这个问题,还是要先看一下源码,比较关键的put逻辑里,可以找到如下代码,hashMap里有计算数组下标的代码逻辑(n-1) & hash
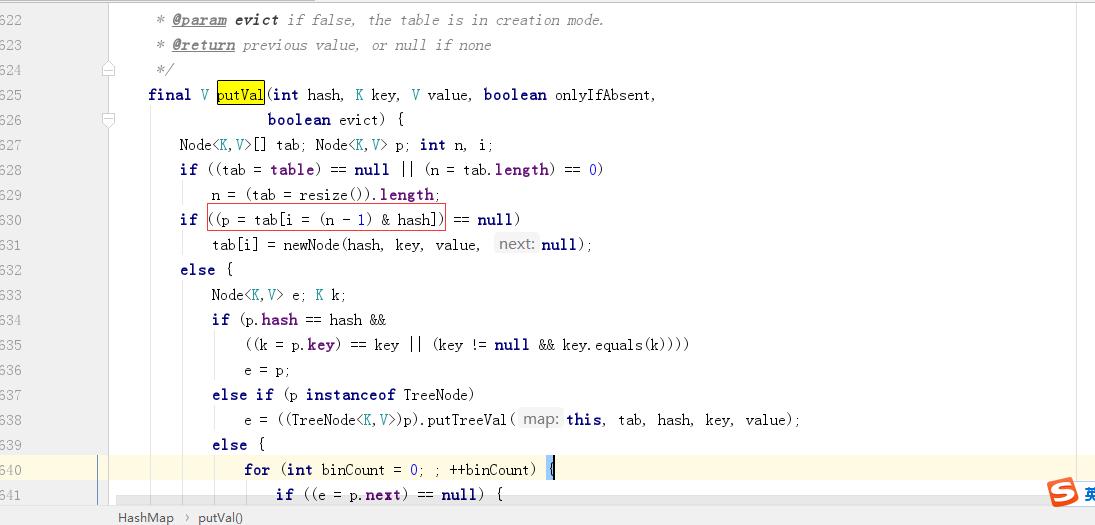
resize扩容的源码:

既然是计算hashMap里数组的下标,所以就不需要特别大,我们可能会想到用取余计算 hash % n,没错,hashMap源码的作者也是考虑到这个,因为在n,也即容量为2的n次方的时候 hash & (n-1) = hash % n,然后为什么不用取余的方法,因为效率没有与运算高,与运算直接是二进制的运算,直接对内存数据进行计算,取余的还是用十进制数据计算,所以效率没有与运算高
然后为什么要使用n-1?,举个例子,默认hashMap初始容量是16,n-1就是15,二进制是1111,然后试试其它的数据,其实发现n为2的n次方的情况,n-1其实都是1111…,然后为什么?因为都是1的情况,和hashcode进行与计算,数据是比较均匀的,比较少有hash冲突的情况
1111和其它二进制数据进行与运算,顺便计算,没有发现相同的数据

找其它非1111…的数据进行与计算,发现,里面都要3个数据是1001,所以这种情况就会出现hash冲突

ok,归纳一下,设置为2的n次方的原因:
- hash & (n-1) 和 hash % n 在2的n次方的情况,会相等,而且与运算效率更高,所以计算数组下标使用hash & (n-1)
n-1,在n为2的n次方的情况,结果都是1111…,所以进行与运算,hash冲突的情况是很少的
本博客需要有一定的hashMap源码阅读经验,所以读者可以阅读我之前博客,链接,然后再来学习这篇博客
以上是关于HashMap初始容量如何设置的主要内容,如果未能解决你的问题,请参考以下文章