微服务常见面试题总结(2022最新)
Posted 程序员大彬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微服务常见面试题总结(2022最新)相关的知识,希望对你有一定的参考价值。
什么是微服务?
微服务是将一个原本独立的系统拆分成多个小型服务,这些小型服务都在各自独立的进程中运行,服务和服务之间采用轻量级的通信机制进行协作。每个服务可以被独立的部署到生产环境。
单体系统的缺点:
- 修改一个小功能,就需要将整个系统重新部署上线,影响其他功能的运行;
- 功能模块互相依赖,强耦合,扩展困难。如果出现性能瓶颈,需要对整体应用进行升级,虽然影响性能的可能只是其中一个小模块;
单体系统的优点:
- 容易部署,程序单一,不存在分布式集群的复杂部署环境;
- 容易测试,没有复杂的服务调用关系。
微服务的优点:
- 不同的服务可以使用不同的技术;
- 隔离性。一个服务不可用不会导致其他服务不可用;
- 可扩展性。某个服务出现性能瓶颈,只需对此服务进行升级即可;
- 简化部署。服务的部署是独立的,哪个服务出现问题,只需对此服务进行修改重新部署;
微服务的缺点:
- 网络调用频繁。性能相对函数调用较差。
- 运维成本增加。系统由多个独立运行的微服务构成,需要设计一个良好的监控系统对各个微服务的运行状态进行监控。
分布式和微服务的区别
从概念理解,分布式服务架构强调的是服务化以及服务的分散化,微服务则更强调服务的专业化和精细分工;
从实践的角度来看,微服务架构通常是分布式服务架构,反之则未必成立。
一句话概括:分布式:分散部署;微服务:分散能力。
服务怎么划分?
横向拆分:按照不同的业务域进行拆分,例如订单、营销、风控、积分资源等。形成独立的业务领域微服务集群。
纵向拆分:把一个业务功能里的不同模块或者组件进行拆分。例如把公共组件拆分成独立的原子服务,下沉到底层,形成相对独立的原子服务层。这样一纵一横,就可以实现业务的服务化拆分。
要做好微服务的分层:梳理和抽取核心应用、公共应用,作为独立的服务下沉到核心和公共能力层,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求
总之,微服务的设计一定要 渐进式 的,总的原则是 服务内部高内聚,服务之间低耦合。
微服务设计原则
单一职责原则
意思是每个微服务只需要实现自己的业务逻辑就可以了,比如订单管理模块,它只需要处理订单的业务逻辑就可以了,其它的不必考虑。
服务自治原则
意思是每个微服务从开发、测试、运维等都是独立的,包括存储的数据库也都是独立的,自己就有一套完整的流程,我们完全可以把它当成一个项目来对待。不必依赖于其它模块。
轻量级通信原则
首先是通信的语言非常的轻量,第二,该通信方式需要是跨语言、跨平台的,之所以要跨平台、跨语言就是为了让每个微服务都有足够的独立性,可以不受技术的钳制。
接口明确原则
由于微服务之间可能存在着调用关系,为了尽量避免以后由于某个微服务的接口变化而导致其它微服务都做调整,在设计之初就要考虑到所有情况,让接口尽量做的更通用,更灵活,从而尽量避免其它模块也做调整。
微服务之间是如何通讯的?
1、RPC
优点:简单,常见。因为没有中间件代理,系统更简单
缺点:
- 只支持请求/响应的模式,不支持别的,比如通知、发布/订阅
- 降低了可用性,因为客户端和服务端在请求过程中必须都是可用的
2、消息队列
除了标准的基于RPC通信的微服务架构,还有基于消息队列通信的微服务架构,这种架构下的微服务采用发送消息(Publish Message)与监听消息(Subscribe Message)的方式来实现彼此之间的交互。
网易的蜂巢平台就采用了基于消息队列的微服务架构设计思路,如下图所示,微服务之间通过RabbitMQ传递消息,实现通信。
与上面几种微服务架构相比,基于消息队列的微服务架构并不多,案例也相对较少,更多地体现为一种与业务相关的设计经验,各家有各家的实现方式,缺乏公认的设计思路与参考架构,也没有形成一个知名的开源平台。因此,如果需要实施这种微服务架构,则基本上需要项目组自己从零开始去设计实现一个微服务架构基础平台,其代价是成本高、风险大。
优点:
- 把客户端和服务端解耦,更松耦合提高可用性,因为消息中间件缓存了消息,直到消费者可以消费
- 支持很多通信机制比如通知、发布/订阅等
缺点:
- 缺乏公认的设计思路与参考架构,也没有形成一个知名的开源平台
- 成本高、风险大
熔断器
雪崩效应:假如存在这样的调用链路,a服务->b服务->c服务,当c服务挂了的时候,b服务调用c服务会等待超时,a服务调用b服务也会等待超时,调用方长时间等不到相应而占用线程,如果有大量的请求过来,就会造成线程池打满,导致整个链路的服务奔溃。
为了解决分布式系统的雪崩效应,分布式系统引进了熔断器机制 。
当一个服务的处理用户请求的失败次数在一定时间内小于设定的阀值时,熔断器出于关闭状态,服务正常。
当服务处理用户请求失败次数在一定时间内大于设定的阀值时,说明服务出现故障,打开熔断器,这时所有的请求会快速返回失败的错误信息,不执行业务逻辑,从而防止故障的蔓延。
当处于打开状态的熔断器时,一段时间后出于半打开状态,并执行一定数量的请求,剩余的请求会执行快速失败,若执行请求失败了,则继续打开熔断器,若成功了,则将熔断器关闭。
服务网关
何为网关?
通俗一点的讲:网关就是要去别的网络的时候,把报文首先发送到的那台设备。稍微专业一点的术语,网关就是当前主机的默认路由。
网关一般就是一台路由器,有点像“一个小区中的一个邮局”,小区里面的住户互相是知道怎么走,但是要向外地投递东西就不知道了,怎么办?把地址写好送到本小区的邮局就好了。
那么,怎么区分是“本小区”和“外地小区”的呢?根据IP地址 + 掩码。如果是在一个范围内的,就是本小区(局域网内部),如果掩不住的,就是外地的。
例如,你的机器的IP地址是:192.168.0.2/24,网关是192.168.0.1
如果机器访问的IP地址范围是:192.168.0.1~192.168.0.254的,说明是一个小区的邻居,你的机器就直接发送了(和网关没任何关系)。如果你访问的IP地址不是这个范围的,则就投递到192.168.0.1上,让这台设备来转发。
参考:https://www.zhihu.com/question/362842680/answer/951412213
何为API网关
假设你正在开发一个电商网站,那么这里会涉及到很多后端的微服务,比如会员、商品、推荐服务等等。
那么这里就会遇到一个问题,APP/Browser怎么去访问这些后端的服务? 如果业务比较简单的话,可以给每个业务都分配一个独立的域名(https://service.api.company.com),但这种方式会有几个问题:
- 每个业务都会需要鉴权、限流、权限校验等逻辑,如果每个业务都各自为战,自己造轮子实现一遍,会很蛋疼,完全可以抽出来,放到一个统一的地方去做。
- 如果业务量比较简单的话,这种方式前期不会有什么问题,但随着业务越来越复杂,比如淘宝、亚马逊打开一个页面可能会涉及到数百个微服务协同工作,如果每一个微服务都分配一个域名的话,一方面客户端代码会很难维护,涉及到数百个域名
- 每上线一个新的服务,都需要运维参与,申请域名、配置nginx等,当上线、下线服务器时,同样也需要运维参与,另外采用域名这种方式,对于环境的隔离也不太友好,调用者需要自己根据域名自己进行判断。
- 另外还有一个问题,后端每个微服务可能采用了不同的协议,比如HTTP、AMQP、自定义TCP协议等,但是你不可能要求客户端去适配这么多种协议,这是一项非常有挑战的工作,项目会变的非常复杂且很难维护。
更好的方式是采用API网关(也叫做服务网关),实现一个API网关接管所有的入口流量,类似Nginx的作用,将所有用户的请求转发给后端的服务器,但网关做的不仅仅只是简单的转发,也会针对流量做一些扩展,比如鉴权、限流、权限、熔断、协议转换、错误码统一、缓存、日志、监控、告警等,这样将通用的逻辑抽出来,由网关统一去做,业务方也能够更专注于业务逻辑,提升迭代的效率。
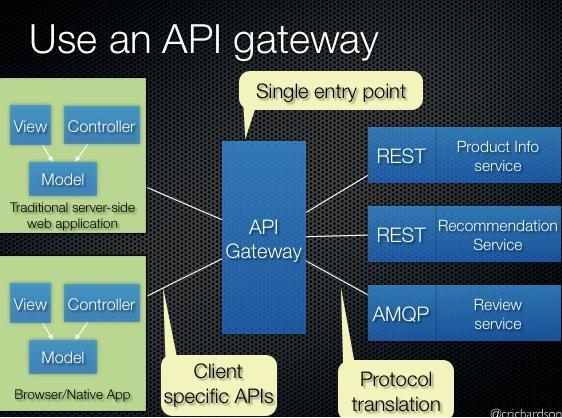
通过引入API网关,客户端只需要与API网关交互,而不用与各个业务方的接口分别通讯,但多引入一个组件就多引入了一个潜在的故障点,因此要实现一个高性能、稳定的网关,也会涉及到很多点。
网关层通常以集群的形式存在。并在服务网关层前通常会加上Nginx 用来负载均衡。
服务网关基本功能:
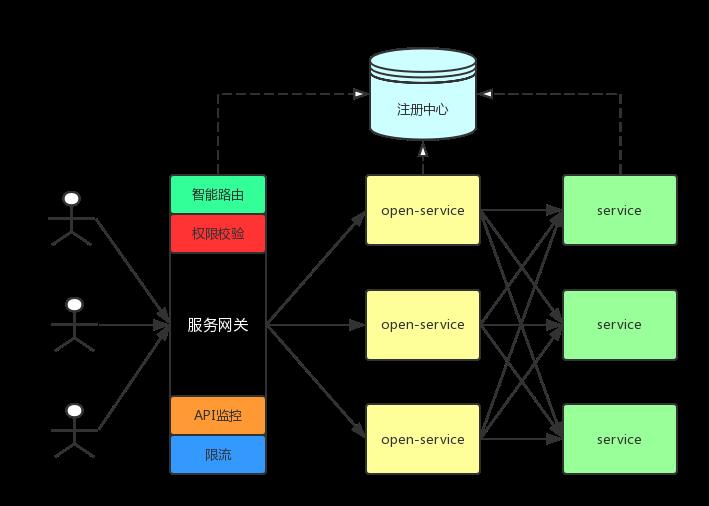
- 智能路由:接收外部一切请求,并转发到后端的对外服务。注意:我们只转发外部请求,服务之间的请求不走网关,这就表示全链路追踪、内部服务API监控、内部服务之间调用的容错、智能路由不能在网关完成;当然,也可以将所有的服务调用都走网关,那么几乎所有的功能都可以集成到网关中,但是这样的话,网关的压力会很大,不堪重负。
- 权限校验:网关可以做一些用户身份认证,权限认证,防止非法请求操作API 接口,对内部服务起到保护作用
- API监控:监控经过网关的请求,以及网关本身的一些性能指标(gc等)
- 限流:与监控配合,进行限流操作
- API日志统一收集:类似于一个aspect切面,记录接口的进入和出去时的相关日志
当然,网关实现这些功能,需要做高可用,否则网关很可能成为架构的瓶颈,最常用的网关组件Zuul、Nginx
服务配置统一管理
在微服务架构中,需要有统一管理配置文件的组件,例如:SpringCloud Config组件、阿里的Diamond、百度的Disconf、携程的Apollo等
服务链路追踪
在微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与、参与顺序,是每个请求链路清晰可见,便于问题快速定位。
常用链路追踪组件有Google的Dapper、Twitter 的Zipkin,以及阿里Eagleeye。
微服务框架
市面常用微服务框架有:Spring Cloud 、Dubbo 、kubernetes
- 从功能模块上考虑,Dubbo缺少很多功能模块,例如网关、链路追踪等
- 从学习成本上考虑,Dubbo 版本趋于稳定,稳定完善、可以即学即用,难度简单,Spring cloud 基于Spring Boot,需要先掌握Spring Boot ,例外Spring cloud 大多为英文文档,要求学习者有一定的英文阅读能力
- 从开发风格考虑,Dubbo倾向于xml的配置方式,Spring cloud 基于Spring Boot ,采用基于注解和JavaBean配置方式的敏捷开发
- 从开发速度上考虑,Spring cloud 具有更高的开发和部署速度
- 从通信方式上考虑,Spring cloud 基于HTTP Restful 风格,服务于服务之间完全无关、无耦合。Dubbo 基于远程调用,对接口、平台和语言有强依赖性,如果需要实现跨平台,需要有额外的中间件。
所以Dubbo专注于服务治理;Spring Cloud关注于微服务架构生态。
其他
Spring Cloud基础知识
什么是Service Mesh?
Service Mesh 是微服务时代的 TCP/IP 协议。
参考:https://zhuanlan.zhihu.com/p/61901608
常见面试题总结
微服务
1. Springboot加载配置文件顺序?
2. SpringBoot启动时都做了那些事
3. Mybatis的sql执行过程
4.SpringMVC的执行流程
5. Spring容器启动的执行过程
6. SpringIOC的过程
7. 微服务整体架构图
8. 如何拆分微服务
DDD领域驱动
9. 几个注册中心的比较?Eureka、Zookeeper、Nacos、Consul
10. 链路追踪和监控(如何实现全链路的业务监控?)
11. 说说springBean的一个加载流程吧,如何解决循环依赖问题
JVM
1. jvm内存结构
- 线程共享
- 方法区 MetaSpace
- 运行时常量池
- 类的信息,包括类名、参数、方法等
- 类的常量
- 类的静态变量
- 堆 Heap
- 老年代 Old Space
- 新生代 Young Space
- Eden -8
- S1-1
- S2-1
- 方法区 MetaSpace
- 线程私有的
- 虚拟机栈
- 本地变量表
- 操作数栈
- 动态链接 一些动态生成的链接地址等,类似于符号引用变直接引用
- 返回地址(包括正常的和异常的)
- 本地方法栈
- 程序计数器
- 虚拟机栈
2. JVM垃圾回收算法,垃圾回收器,G1,CMS回收过程,虚拟机怎么保证分配内存时的线程安全
- 标记清除
- 标记整理
- 标记复制
3. JVM类加载
类加载是指把.class 文件加载到jvm虚拟机的过程,主要包括以下几个步骤
-
加载 Loading 根据类的全限定名从磁盘或者网络上加载二进制流(十六进制编码)
此处主要是使用Java的ClassLoader 即类加载器进行加载,常用的类加载器分为以下几个部分
- BootStrap ClassLoader 即根加载器,主要加载rt.jar的类
- Extention ClassLoader 即扩展类加载器, 主要加载.ext下的jar
- Application ClassLoader 即应用类加载器,加载当前classpath下的类
- Custom ClassLoader 即自定义类加载器
-
链接 Linking
- 验证 Verification 验证类文件的格式,比如开头是否是cafebabe等 包括有对应的词法语法解析器
- 准备 Preparing 给类的静态变量初始化空间并赋值初始值
- 解析 Resovling 把一些符号引用转化为内存中的直接引用
-
初始化 Initialization
给类的静态变量赋值
MethodNotFoundException、ClassNotFoundException、ClassDefNotFoundException分别发生在哪个步骤?
4. 垃圾收集器
-
Serial 新生代 使用标记复制 单线程
-
Serial Old 老年代 使用标记整理 单线程
-
ParNew 新生代 使用标记复制,基于Serial 多线程收集
-
Parallel Scavenge 新生代 使用标记复制,更关注吞吐量
-
Parallel Old 老年代 标记整理,关注吞吐量
-
CMS收集器 老年代 使用标记清楚算法 关注停顿时间,整个过程stw 两次
-
先初始标记 stw (每一步具体做了什么???)
-
然后并发标记
-
重新标记 stw
-
并发清除
并发:用户线程和垃圾回收线程可以并行执行 成为并发
-
-
G1 并发收集器 1.9默认 可以设置具体的停顿时间,会更改jvm的内存区域,划分成大小相等的独立区域
相比cms 是在cms 并发清楚的时候这一步进行筛选回收,主要是因为用户设置了停顿时间,所以只能选择性的回收。
- 堆内存的存活率超过了50%
- 对象的分配和晋升速度变化大
- 垃圾回收时间长
5. JVM调优(你是怎么去做jvm调优的)
-
GC收集器:停顿时间和吞吐量
- 停顿时间: 垃圾回收所使用的的时间
- CMS G1 停顿时间较小 适用于web应用 并发类的收集器
- 吞吐量: 吞吐量 = 运行用户代码的时间/(运行用户代码的时间+垃圾回收时间)
- Parallel Scavenge Parallel Old 并行类的收集器
- 停顿时间: 垃圾回收所使用的的时间
-
内存的使用维度
6.如何设置JVM堆的大小
正常来说默认JVM堆的大小=老年代的大小+新生代的大小,默认比例为2:1, 老年代的大小可以设置成老年代FULL GC后存活对象总大小的3到4倍,元数据区域的大小可以设置为老年代存活对象总大小的1.2倍到1.5倍左右,可以通过JVM启动参数 加入GC日志来观察每次FULL GC后的对象总大小,或者通过JMAP -dump命令下载内存快照强制触发full gc 并通过快照分析。
7. 如果jsp的CPU占用过高如何去分析?
8. Jvm内存溢出怎么分析?
9. Happens Before
- Volatile 规则
- a happens before b , b happens before c 则 a happens before c
- 单线程的程序顺序规则
- 线程的start规则,线程start前面的程序一定对线程内部是可见的
- 线程的join规则,
- 锁规则,synchronize规则
10. 对象在堆中的组成结构

Java基础和JUC
1. valotile关键字
原因:之所以出现是因为cpu级别的缓存和总线锁导致的数据可见性问题以及指令重排序问题
作用:valotile的作用是可以禁止指令重排序以及实现可见性,但并不是线程安全的,因为不具有原子性
可见性是如何实现的了?
操作系统层面提供了三种内存屏障,即读屏障 写屏障 和全屏障,JVM基于操作系统层面的内存屏障实现了4种屏障类型,分别是读读屏障,读写屏障、写写屏障和写读屏障。volitile正是在代码执行之后加了一个storeLoad屏障,保证了此写入对后续读是可见的。
为什么存在指令重排序?举例说明
2. 线程池的使用,各参数的作用,拒绝策略的执行
- corePoolSize 核心线程数
- maximumPoolSize 最大线程数
- keepAliveTime 最大线程数持续时间
- unit 持续单位
- workQueue 线程队列
- threadFacory 线程工厂
- refectedHandler 拒绝策略(默认有几种拒绝策略?)
有时候会从源码级别考察,一个线程执行的过程
3. ThreadLocal原理,会出现什么问题?
主要说明实现原理,可以顺带说他的哈希碰撞解决方案用了线性寻址法,以及内存泄露的原因和应该怎么去处理
4. 锁升级的过程
对象在内存中包括 对象头 实例数据 填充数据
对象头包括mark word 对象指针 数组长度
markword 32位或者64位 分别包括线程Id hashcode值 分代年龄 是否偏向锁标识 锁标识等epoch
偏向锁 cas 把当前线程的ThreadId存储在对象头中
轻量级锁 自旋 把锁对象的指针指向当前栈帧中的lockRecord,
重量级锁 锁 monitor monitorenter monitorexit
5. 线程的一些方法wait,notify,condition await() signal()
wait, notify 是属于Object类的方法 基于monitor 监视器锁实现等待和唤醒,后台维护了一个等待队列和一个阻塞队列
await signal是condition接口的方法,是基于ReentrantLock锁实现的 基于AQS等待和唤醒
6.讲讲为什么ConcurrentHashMap是并发安全的吧,既然有锁怎么去统计size呢
7. ArrayList和LinkedList的区别
- arrayList是数组
- LinkedList是链表
8. HashMap的底层数据结构
数组加链表+红黑树
9. hashmap容量为什么是2的幂次?
因为计算数组下标的时候是hashcode & (n-1) 如果n是2的幂次方 转换成二进制后 后面的全是1,做&运算的时候能保证散落的更加均匀
10. 你重写过hashcode和equals么,要注意什么?
11. ConcurrentHashMap怎么解决HashMap的并发问题(源码)
主要是通过unsafe类的cas操作
12. CAS缺点和解决方案
cas 第一个缺点是大多数使用在自选中,但最后只有一个线程可以运行成功,效率较低
第二个是ABA问题,即第一个线程要修改的值是A,然后第二个线程先把值修改成B 然后在修改成A, 这时候cas依然可以成功。
13. Synchronize锁和ReetranLock锁的区别?
把你所知道的可以有逻辑的讲出来,mic的课程很清晰
14. CountDownLatch和CycleBarrier使用场景?
15. JDK动态代理和CGLIB动态代理
jdk动态代理基于接口,因为代理类本身已经继承了Proxy类, 实现Invocationhandler
Proxy.newInstance(ClassLoader, Class<?>[], Invocationhandler)
CGLIB动态代理是基于可继承的父类,通过Enhancer类加强器创建子类实现动态代理 实现MethodIntecetpor
16. 哈希冲突的四种解决办法
- 开放寻址法 如果可以预知哈希的大小,可以完美散列 ThreadLocalMap
- 线性探测
- 二次探测
- 随机数探测
- 拉链法
- 再哈希法
- 建立公共溢出区
17. 一致性Hash算法
- 常规哈希取模
- 不带虚拟节点的哈希 通过服务器的信息(比如 host、port、name等)通过hash算法形成一个圈,每个服务器负责一段范围的请求,如果超过了这个返回就重新回到第一个服务器。这中算法的缺点是其中一个服务挂了之后,所有的请求会转发到下一个服务,容易导致雪崩
- 带虚拟节点的哈希 跟上一个不同点是,把每一个服务器分布在环的不同位置,从而避免雪崩。
中间件
redis如何主从同步?
- 全量复制 通过rdb文件当slave机器连接的时候 master服务器 fork一个子线程 子线程生成一个快照,同步给slave去同步数据
- 增量复制 通过心跳命令去增量同步数据,服务器会维护一个log的内存文件和已经同步的偏移量信息
- 无磁盘复制 通过内存生成文件去复制,不通过磁盘
redis分布式锁注意事项?
redis的哨兵和集群模式?
redis的基本数据结构和底层实现
redis的持久化方案
分布式事务的解决方案?
分布式下redis如何保证线程安全?
单点登录怎么实现?
秒杀系统怎么来实现?
多路复用 IO NIO BIO
布隆过滤器 Bitmap
kafka的架构,如何用kafka保证消息的有序性
kafka和redis的区别
MQ
-
交换机类型
-
消息怎么删除
-
消息队列的使用场景
- 削峰
- 解耦
- 异步
- 广播
- 削峰
-
消息队列什么时候变成死信
- 消息消费的时候被拒绝,没有设置重新进入队列
- 消息过期
- 超过队列长度的时候 第一条消息会变成死信
- 消息消费的时候被拒绝,没有设置重新进入队列
-
多个消费者监听同一个队列,消息怎么分发
- 轮询
- 公平分发
- 比如有的消费时间比较久,占用时长高,这时候可以设置参数 大于多少个的时候不在分发消息
- 轮询
-
无法路由的消息去了哪里?一般被丢弃
-
延迟队列如何实现
-
3.7+ 有一个延迟队列插件
-
TTL + 死信队列 可以通过消息的存活时间和死信队列来实现,指定死信交换机
-
-
-
消息的顺序执行
-
一个队列一个消费者
-
一个队列,然后使用内存队列排队,根据订单id哈希去把同一个订单的发送到同一个队列,然后使用多个线程去消费不同的队列
-
MYSQL
1. 事务的四大特性 ACID
-
原子性 Atomicity
我们对数据库的一系列操作要么都成功 要么都失败,如果转账场景,一个账户增加 另一个失败,要么都成功或者都失败
-
一致性 Consistent
一种是指数据库的完整性月数没有被破坏,比如主键唯一,事务的合法等,另一种是业务的一致性,比如转账场景,A账户余额减少1000,B账户余额增加500,这时候虽然两个操作都成功了,符合了原子性协议,但没有符合一致性
-
隔离性 Isolation
数据库中有很多事务同时去访问同一个表或者同一行数据,必然会产生一些并发的影响,这时候就要定义不同的事务让他们之间互不干扰,也是通过这种方式保证数据的一致性
-
持久性 Durable
对数据库的任意操作,只要成功了就应该是持久的
数据库的持久性是如何实现的?
通过redo log 和 double write双写缓冲来实现的,我们操作数据的时候,会先写道内存的buffer pool中,同时记录redo log,如果在刷盘之前出现异常,再重启后就可以读取redo log的内容,写入磁盘,保证数据的持久性,当然恢复成功的前提是数据页本身没有被破坏,是完整的 这个是通过双写缓冲来保证的
2. 性能优化
-
通过开启slow query log 可以把慢查询日志记录下来,并用mysqlDumpSlow分析并导出对应需要的格式
mysqlDumpSlow -s t -t 20 -g 'select' /usr/local/mysql/data/slow-query.log
-
通过开启select @@profile 开关 可以查看sql执行所用时间 cpu占用信息等情况,
select * from information_schema.profiling 表中存储了所有信息
-
通过show processlist 或者select * from information_schema.processlist 查看所有正在执行的sql线程,看看是否有死锁线程或者等待队列已满等情况
3. EXPLAIN
-
id 笛卡尔积,2 * 3 * 4 = 6 * 4 会优于 3 * 4 * 2 = 12 * 2 因为中间产生的笛卡尔积临时表空间更少
如果id大小不一样 查询顺序是从大到小进行,如果id大小是一样的,查询顺序是自上而下
-
select_type
- PRIMARY
- SUBQUERY
- DERIVED
- UNNION ALL
-
table
-
type
- System 系统只有一行数据
- const 只查询到一行数据
- eq_ref 唯一性索引 是对于多表join查询,并且对于前表的每一条结果刚好能匹配到后表的每一条结果
- ref 非唯一性索引,
- range 范围查找
- index full index scan 查询的字段是在索引上的字段
- all
- null
-
possible_keys 可能使用到的索引
-
key 实际使用到的索引,如果查询的字段存在于某个索引上,虽然这个索引不符合最左匹配原则,但实际还是会用到索引,此时 possible_keys为null key不为null,
-
rows 扫描到的大概行数
-
filtered 过滤的百分比 越接近100越好
-
extra 附加条件
-
using where 如果存储引擎层返回的数据不是我们最终需要的数据,需要经过server端过滤的时候
需要索引查询到的数据回表查询,
-
using index 只是用了索引数据,不需要回表去查询数据
-
using index condition 索引下推 查询的条件语句经过索引进一步过滤之后 再返回给server端
-
using filesort 没有使用到对应的索引排序, 用了额外的排序规则
-
using temporary 临时表
-
4. 一个SQL语句的执行过程
连接--》分析器(词法分析器(把一个sql语句拆分成单个的单词去校验)和语法分析器(按照语法树去分析))--》预处理器--》优化器(query optimizer,会生成所有可能的执行计划,然后基于开销时间获取一个最佳的执行计划) --》执行计划(可以通过explain查看)-》执行引擎
5. mysql 存储文件
- innodb:
- .frm文件 表结构文件
- ibd文件索引文件
- myisam
- frm文件 表结构文件
- myi 索引文件
- myd 数据文件
6. 存储引擎
-
MYISAM
-
支持表级别的锁,不支持事务 ,所以插入和更显会锁表
-
拥有较高的插入和查询速度,适合读多写少的情况
-
存储了表的count行数,所以count速度更快
怎么快速向数据库插入100万条数据了,可以先用MYISAM引擎插入数据,然后在修改为INNODB
-
-
INNODB
- 支持事务,支持外键,
- 支持航级别的锁和表级别的锁
- 支持读写并发,写不阻塞读(MVCC)
- 特殊的索引存放 可以减少IO
7. INNODB的内存结构和磁盘结构
1. 内存结构(Buffer Pool) 默认128M 可以缓存索引页和数据页
-
Buffer Pool 内存的缓冲池数据写满了怎么办?Innodb使用LRU算法,有一个Buffer Pool List分成Old (3/8)和young(5/8)代,如果查询的数据在缓冲池中已存在,则提升到连表头,如果不存在则放到中间,后面的数据进行末尾淘汰
-
Change Buffer 写缓冲,如果要写入的数据不是唯一索引,也就是说不存在数据重复的情况下,就不需要先从磁盘加载判断唯一性,直接先在缓冲池中更改,从而提升增删改的执行速度,5.5之前的版本叫Insert Buffer 现在可以支持更新和删除,所以更改为Change Buffer
然后把change Buffer的数据merge,在访问这个数据页的时候merge,通过后台线程、或者数据库发生 shutdown的时候,以及 redo log 写满时触发
如果数据库的大部分索引都是非唯一索引,并且业务是写多读少,不会在写后立刻读取数据,就可以调大change buffer的值,默认占用 Buffer Pool的25%空间
-
Adaptive Hash index
-
(redo)log buffer 为防止Change Buffer里的数据未同步到磁盘发生宕机,innodb 把所有的写操作都记录在 redo log 中,redo log在表空间中 默认有2个文件,每个文件默认48M,默认都是先写日志 在写磁盘,因为写入磁盘是随机IO,写入日志文件是顺序IO,所以速度更快。默认是每次事务提交的时候 都会把log buffer 写入到磁盘。
redo log的文件大小是固定的,默认16M,里边有两个指针,一个写指针,一个check指针,如果两个指针重叠,说明文件满了,这个时候需要同步数据到磁盘中
2. 磁盘结构
- 系统表空间 system tablespace
- 独占表空间
- segment 段 数据段 索引段
- extent 区(簇) 大小是1M 包括64个页
- page 页 每个页大小是16K
- 通用表空间
8. 日志文件
- redo log 记录修改后的数据,用来更新数据日志 是在存储引擎层完成的
- undo log 记录之前的数据,用来恢复数据
- bin log 记录逻辑日志,只记录操作,不记录数据,主要用来做主从复制和数据恢复 是在server层完成的
一个更新语句的执行流程是:先经过server层,然后交给存储引擎层执行更新,将更新结果写入到Buffer Pool,记录redo log的记录并且设置状态为prepare的,然后返回给server层,server层写入bin log日志,此时再通知存储引擎层更改redo log的状态为commit,保持数据一致性
Innodb 辅助索引只存储索引和主键值 ,主键索引即聚簇索引是和数据放在一起的
Myisam 索引和数据是分开存储的
mysql innodb如果没有主键:第一个不为空唯一索引 --》row_id
9. 事务的几种数据特性 / 事务并发带来的几个问题
-
脏读
A事务读到了B事务更改后但未提交的值,导致两次读取到的数据不一样
-
不可重复读
A事务读到了B事务更改(特指修改或者删除)后提交的值,导致两次读取的数据不一样,
-
幻读
A事务读到了B事务更改(特指新增)后提交的值,导致两次读取的数据不一样
10. 事务的4个隔离级别
-
RU (Read Uncommitted)未提交读
-
RC (Read Committed) 已提交读
通过MVCC实现读一致性 通过Record lock 实现写一致性,存在幻读问题
-
RR (Repeatable Read)可重复读 同一个事务里多次读取同样的数据结果是一样的,解决了不可重复读问题,并在INNODB中解决了幻读的问题,通过临键锁,
通过MVCC实现读一致性,通过Record Lock,Gap Lock, Next-Key Lock实现写一致性
-
Serializable 串行化 所有的事务都是串行执行的,解决了所有问题,但效率降低
11. Mysql默认添加的几个字段
- DB_TRX_ID 事务id
- DB_ROLL_PTR 回滚id 指向undo log
- DB_ROW_ID 行id
12. mysql锁
包括有排它锁 即Exclusive Lock 即X锁 写锁 和 共享锁 Share Mode Lock 即S锁 读锁
-
record lock 记录锁
如果查询的数据正好是唯一索引或者主键索引的数据,就是记录锁,只锁当前这一行数据
-
gap lock 间隙锁
间隙所是记录锁的n+1个,是指记录不错的区间锁,左开右开的,如果查询的记录不存在,则用间隙锁
-
Next-key Lock 临键锁 默认
临键锁是INNODB默认的行锁,并通过此解决了在RR事务级别下的数据幻读问题,如果查询的是区间数据并且命中了某一个索引的值,则用间隙锁,锁住当前记录的前一个间隙锁和后一个间隙锁。
13. mysql几种日志文件格式及作用
- redo log 重做日志 。是存储引擎层记录的,在数据更新到Buffer Pool之后记录在redo log中,用于记录数据的更新值
- undo log 回滚日志,也是存储引擎层记录的,用于记录数据更新前的值,
- bin log server层记录的,只记录增删改的这些sql日志,并不记录实际的值,用于主从同步和数据恢复的
14. MySQL多版本控制MVCC
Multi Version Concurrency, 基于快照实现, 通过数据库隐藏的字段 事务id和 回滚指针来完成,回滚指针指向undo log里的数据
15. 如何解决数据库读一致性的问题
-
LBCC (Lock Based Conconrrency Control)
在读取数据前,对其加锁,阻止其他事务对数据进行修改
-
MVCC( Muti Version Concurrency Control )
生成一个数据请求时间点的快照,并用这个快照来提供一定级别的一致性读取
16. 二叉搜索树 二叉平衡树(AVL)B树 B+树
-
二叉搜索树:左子树小于根节点 右子树大于根节点 按照中序排列的话是一个有序的队列,缺点是树的深度太大
-
二叉平衡树:基于二叉搜索树的一个平衡树 树的深度绝对值差不超过1
-
B树 :多路平衡树,度是关键字n的n+1个,叶子节点都存储数据和索引,度数多
-
B+树:非叶子节点只存储关键字,不存储索引和值,所以可以存储更多关键字,叶子节点中有一个指向下一个节点的指针,排序和范围查询更快,而且树的深度是固定的,所以IO次数是固定的
17. 死锁的四大必要条件(举例说明,如何发生一个死锁)
- 互斥条件
- 持有且等待
- 不可剥夺
- 循环依赖
18. 哪些情况不走索引
1、查询条件中使用了计算 比如 age+=20
2、查询条件中使用了函数
3、第三是like %
4、or操作
其他
1. tcp为什么断开连接时是四次挥手而建立连接时是三次握手
2. 设计模式7大原则
-
开闭原则
-
单一职责原则
-
接口隔离原则 接口不要太大 尽可能暴露给客户端的都是需要的
-
里氏替换原则 子类可以继承父类,但不能更改父类原有的功能
-
依赖倒置原则 应该是下层依赖上层 细节依赖抽象
-
迪米特法则 也即最少知道原则
-
合成复用原则 尽量多远组合而不是继承
3. 常见的设计模式(举例说明你在项目中的实际使用场景)
必问话题
个人提前准备好对应的措辞,反复自问自答,多做练习
- 自我介绍
- 找一个你做过最复杂的项目说说
- 找一个你解决过项目中最困难的问题说说
- 找一个你解决的记忆最深刻的线上问题说说
- 在上家公司个人成长
- 为什么离开上家公司
- 个人未来的职业规划
- 对我们公司,你还有什么想要了解的吗(可以多问问岗位工作内容、技术栈方向)
- 你期望的薪资、你目前的薪资
- 你对我们公司的职级了解么?你期望达到什么职级
开发性话题
-
设计一个系统你会考虑哪些方面?
-
了解CAP、Base、Tcc吗?
-
如何拆分微服务?DDD了解过吗?
-
怎么去设计一个单点登录系统?
-
如何去设计一个秒杀系统?
-
如何去设计一个短连接处理系统?
中间件主要以MQ、REDIS、ZOOKEPER和KAFKA为主
以上是关于微服务常见面试题总结(2022最新)的主要内容,如果未能解决你的问题,请参考以下文章