Cocos 3.x 由浅到浅入门批量渲染
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Cocos 3.x 由浅到浅入门批量渲染相关的知识,希望对你有一定的参考价值。
参考技术A 参考
由浅到浅入门批量渲染(一)
由浅到浅入门批量渲染(二)
由浅到浅入门批量渲染(三)
由浅到浅入门批量渲染(四)
由浅到浅入门批量渲染(完)
【Unity游戏开发】静态、动态合批与GPU Instancing
本文只摘抄部分原文,达到概念性了解。
批量渲染其实是个老生常谈的话题,它的另一个名字叫做“合批”。在日常开发中,通常说到优化、提高帧率时,总是会提到它。
可以简单的理解为: 批量渲染是通过减少CPU向GPU发送渲染命令(DrawCall)的次数,以及减少GPU切换渲染状态的次数,尽量让GPU一次多做一些事情,来提升逻辑线和渲染线的整体效率。 但这是建立在GPU相对空闲,而CPU把更多的时间都耗费在渲染命令的提交上时,才有意义。
如果瓶颈在GPU,比如GPU性能偏差,或片段着色器过于复杂等,那么没准适当减少批处理,反而能达到优化的效果。所以要做性能优化,还是应该先定位瓶颈到底在哪儿,然后再考虑优化方案,而不是一股脑的就啪啪啪合批。当然,通常情况下,确实是以CPU出现瓶颈更为常见,所以适当的了解些批量渲染的技法,是有那么一丢丢必要的。
静态合批是一种听起来很常用,但在大多数手游项目里又没那么常用的合批技术。这里,我简单的将静态合批分为预处理阶段的合并,和运行阶段的批处理。
合并时,引擎将符合合批条件的渲染器身上的网格取出,对网格上的顶点进行空间变换,变换到合并根节点的坐标系下后,再合并成一个新的网格;这里需要注意的是,新网格是以若干个子网格的形式组合而成的,因为需要记录每一个合并前网格的索引数量和起始索引(相对于合并后的新网格)。
空间变换的目的,是为了“固化”顶点缓冲区和索引缓冲区内的数据,使其顶点位置等信息都在相同的坐标系下。这样运行时如果需要对合并后的对象进行空间变换(手动静态合批对象的根节点可被空间变换),则无需修改缓冲区内的顶点属性,只提供根节点的变换矩阵即可。
在Unity中,可以通过勾选静态批处理标记,让引擎在打包时自动合并;当然,也可以在运行时调用合并函数,手动合并。打包时的自动合并会膨胀场景文件,会在一定程度上影响场景的加载时间。此外,不同平台对于合并是有顶点和索引数量限制的,超过此限制则会合并成多个新网格。
运行时是否可以合批(Batch)成功,还取决于渲染器材质的设置。
当然,如果手动替换过场景中所有Material,也会打断批次。
静态合批与直接使用大网格(是指直接制作而成,非静态合并产生的网格)的不同,主要体现在两方面。
其一,静态合批可以主动隐藏部分对象。静态合批在运行时,由于每个参与合并的对象可以通过起始索引等彼此区分,因此可以通过上述多次DrawCall的策略,实现隐藏指定的对象;而直接使用大网格,则无法做到这一点。
其二,静态合批可以有效参与CPU的视锥剔除。当有剔除发生时,被送进渲染管线的顶点数量就会减少(通过参数控制),也就意味着被顶点着色器处理的顶点会减少,提升了GPU的效率;而使用大网格渲染时,由于整个网格都会被送进渲染管线,因此每一个顶点都需要被顶点着色器处理,如果摄像机只能照到一点点,那么绝大多数参与计算的顶点最后都会被裁减掉,有一些浪费。
当然,这并不意味着静态合批一定就比使用大网格要更好。如果子网格数量非常多,视锥剔除时CPU的压力也会增加,所以具体情况具体分析吧~
静态合批采用了以空间换时间的策略来提升渲染效率。
其优势在于:网格通常在预处理阶段(打包)时合并,运行时顶点、索引信息也不会发生变化,所以无需CPU消耗算力维护;若采用相同的材质,则以一次渲染命令,便可以同时渲染出多个本来相对独立的物体,减少了DrawCall的次数。
在渲染前,可以先进行视锥体剔除,减少了顶点着色器对不可见顶点的处理次数,提高了GPU的效率。
其弊端在于:合批后的网格会常驻内存,在有些场景下可能并不适用。比如森林中的每一棵树的网格都相同,如果对它采用静态合批策略,合批后的网格基本等同于:单颗树网格 x 树的数量,这对内存的消耗可能就十分巨大了。
总而言之,静态合批在解决场景中材质基本相同、网格不同、且自始至终都保持静止的物体上时,很适用。
试想一个场景:一场激烈的战斗中,双方射出的箭矢飞行在空中,数量很多,材质也相同;但因为都在运动状态,所以无法进行静态合批;倘若一个一个的绘制这些箭矢,则会产生非常多次绘制命令的调用。
对于这些模型简单、材质相同、但处在运动状态下的物体,有没有适合的批处理策略呢?有吧,动态合批就是为了解决这样的问题。
动态合批没有像静态合批打包时的预处理阶段,它只会在程序运行时发生。 动态合批会在每次绘制前,先将可以合批的对象整理在一起(Unity中由引擎自动完成),然后将这些单位的网格信息进行“合并”,接着仅向GPU发送一次绘制命令,就可以完成它们整体的绘制。
动态合批比较简单,但有两点仍然需要注意:
动态合批不会在绘制前创建新的网格,它只是将可以参与合批单位的顶点属性,连续填充到一块顶点和索引缓冲区中,让GPU认为它们是一个整体。
在Unity中,引擎已自动为每种可以动态合批的渲染器分配了其类型公用的顶点和索引缓冲区,所以动态合批不会频繁的创建顶点和索引缓冲区。
在向顶点和索引缓冲区内填充数据前,引擎会处理被合批网格的每个顶点信息,将其空间变换到世界坐标系下。
这是因为这些对象可能都不属于相同的父节点,因此无法对其进行统一的空间转换(本地到世界),需要在送进渲染管线前将每个顶点的坐标转换为世界坐标系下的坐标(所以Unity中,合并后对象的顶点着色器内被传入的M矩阵,都是单位矩阵)。
相对于上述看起来有点厉害但是本质上无用的知识而言,了解动态合批规则其实更为重要。比如:
当我们想要呈现这样的场景:一片茂密的森林、广阔的草原或崎岖的山路时,会发现在这些场景中存在大量重复性元素:树木、草和岩石。它们都使用了相同的模型,或者模型的种类很少,比如:树可能只有几种;但为了做出差异化,它们的颜色略有不同,高低参差不齐,当然位置也各不相同。
使用静态合批来处理它们(假设它们都没有动画),是不合适的。因为数量太多(林子大了,多少树都有), 所以合并后的网格体积可能非常大,这会引起内存的增加 ;而且,这个合并后的网格还是由大量重复网格组成的,不划算。
使用动态合批来处理他们,虽然不会“合并”网格,但是仍然需要在渲染前遍历所有顶点,进行空间变换的操作;虽然单颗树、石头的顶点数量可能不多,但由于 数量很多,所以也会在一定程度上增加CPU性能的开销,没必要 。
那么,对于场景中这些模型重复、数量多的渲染需求,有没有适合的批处理策略呢?有吧,实例化渲染就是为了解决这样的问题。
实例化渲染,是通过调用“特殊”的渲染接口,由GPU完成的“批处理”。
它与传统的渲染方式相比,最大的差别在于:调用渲染命令时需要告知GPU这次渲染的次数(绘制N个)。当GPU接到这个命令时,就会连续绘制N个物体到我们的屏幕上,其效率远高于连续调用N次传统渲染命令的和(一次绘制一个)。
举个例子,假设希望在屏幕上绘制出两个颜色、位置均不同的箱子。如果使用传统的渲染,则需要调用两次渲染命令(DrawCall = 2),分别为:画一个红箱子 和 画一个绿箱子。
如果使用实例化渲染,则只需要调用一次渲染命令(DrawCall = 1),并且附带一个参数2(表示绘制两个)即可。
当然,如果只是这样,那GPU就会把两个箱子画在相同的位置上。所以我们还需要告诉GPU两个箱子各自的位置(其实是转换矩阵)以及颜色。
这个位置和颜色我们会按照数组的方式传递给GPU,大概这个样子吧:
那接下来GPU在进行渲染时,就会在渲染每一个箱子的时候,根据当前箱子的索引(第几个),拿到正确的属性(位置、颜色)来进行绘制了。
静、动态合批实质上是将可以合批的对象真正的合并成一个大物体后,再通知GPU进行渲染,也就是其顶点索引缓冲区中必须包含全部参与合批对象的顶点信息; 因此,可以认为是CPU完成的批处理。
实例化渲染是对网格信息的重复利用,无论最终要渲染出几个单位,其顶点和索引缓冲区内都只有一份数据, 可以认为是GPU完成的批处理 。
其实这么总结也有点问题,本质上讲: 动、静态合批解决的是合批问题,也就是先有大量存在的单位,再通过一些手段合并成为批次;而实例化渲染其实是个复制的事儿,是从少量复制为大量,只是利用了它“可以通过传入属性实现差异化”的特点,在某些条件下达到了与合批相同的效果。
无论是静态合批、动态合批或实例化渲染,本质上并无孰优孰劣,它们都只是提高渲染效率的解决方案,也都有自己适合的场景或擅长解决的问题。个人以为:
Unity下可以通过以下两种方式快速优化骨骼蒙皮动画:
在相同的测试环境下,再次进行测试后可以发现,这种方法确实可以产生一定效果。其原因我认为主要有以下两点:
开启GPU蒙皮,Unity会通过ComputeShader的方式,使用GPU进行蒙皮。GPU上有大量的ALU(算数逻辑单元),可以并行大量的数值计算,效率较高,应该很适合这种针对顶点属性的数值计算。
但是实际情况是:在移动设备上使用GPU蒙皮反而会使主线程的耗时增加。通过Profiler可以发现,CPU把更多的时间放在了执行ComputeShader上,由于骨骼动画的实例很多(500个),所以这个调用时间本身成为了性能热点。所以,以目前的情况来看,这种在移动设备上使用GPU蒙皮的方式,似乎不适合处理大量骨骼蒙皮动画实例(也许是我使用的方式存在问题)。
简单来说,它们基本的思路,都是将骨骼蒙皮动画的“结果”预先保存在一张纹理中;然后在运行时通过GPU从这张纹理中采样,并使用采样结果来更新顶点属性; 再结合实例化技术(GPU instancing) ,达到高效、大批量渲染的目的。
可以简单的将它的工作流程分为两个阶段:
这个阶段其实是为后面的播放阶段准备动画资源,你也可以把这个资源简单的理解为一种特殊类型的动画文件。
首先,在编辑状态下,让携带骨骼蒙皮动画的角色,按照一定帧率播放动画。我们知道:动画播放时,角色网格会被蒙皮网格渲染器(SkinnedMeshRenderer)更新而产生变形(顶点变化);如果在动画播放的同时,记录下每一个顶点在这一时刻相对于角色坐标系(通常是角色脚下)的位置。那么,当动画播放完毕时,我们会得到一张“每一个顶点在每一个关键帧时的位置表”,我们就叫它“帧顶点位置表”吧。可是“帧顶点位置表”名字太长,你可能不太好记,我打字也比较麻烦,所以我们后面就叫它“表表”吧。
除了表表,我们还能得到与它对应的动画信息,比如这个动画的名称、时长、帧率、总帧数、是否需要循环播放等信息。
到这里,第一个阶段我们需要的内容就准备就绪了,可以进入下一个阶段:播放动画阶段。
在动画播放时,通过一个变量(播放时长)来更新播放进度;结合上一阶段我们记录下来的动画总长度、动画总帧数信息,就可以计算出当前动画播放到了第几帧(当前帧数 = 已播放时长 / 动画总时长 x 动画总帧数)。一旦得到当前动画帧,就表示可以通过表表锁定一行顶点数据。
接下来,只要遍历这行顶点数据;然后根据索引找到网格中对应的顶点并更新它的位置,就等于完成了蒙皮工作。
既然通过一个播放进度、表表和一些简单的动画信息,就能直接完成蒙皮(对顶点属性的更新),那么我们就不再需要以下内容了:
使用CPU来读取表表,并遍历更新所有顶点,显然不如GPU来的高效;所以接下来,我们将这一步放到渲染管线中的顶点变换阶段,借着GPU处理顶点的契机,完成使用表表中的数据对顶点属性进行更新。
实例化渲染的特点是使用相同网格,相同材质,通过不同的实例属性完成大批量的带有一定差异性的渲染;而烘焙顶点恰好符合了实例化渲染的使用需求。
所以,我们只需将控制动画播放的关键属性:比如过渡动画播放的V坐标、当前和下一个动画的插值比例等,放入实例化数据数组中进行传递;再在顶点着色器中,对关键属性获取并使用即可。
与蒙皮网格渲染器的比较
烘焙顶点的主要问题
除了烘焙顶点,另一种常用的优化方案是烘焙骨骼矩阵动画。
听名字就知道,烘焙骨骼矩阵与烘焙顶点位置,原理十分相似;最大的差异在于它们在烘焙时所记录的内容不一样:烘焙顶点记录下来的是每个顶点的位置,而烘焙骨骼矩阵记录下来的是每一根骨骼的矩阵,仅此而已。
烘焙骨骼矩阵最大的意义在于它补上了烘焙顶点的短板:受顶点数量限制、烘焙的动画纹理过大 及 纹理数量较多。
烘焙顶点对于纹理(面积)的使用是受顶点数量决定的,可以简单理解为:
所以,当模型的顶点数量过多时(数以千计),这种烘焙方式或者无法烘焙下整个模型(顶点数量>2048),或者需要一张或多张(法线、切线)大尺寸纹理(<2048 && > 1024)。
但是,烘焙骨骼矩阵主要取决于骨骼的数量,可以简单理解为:
在移动平台上,通常20根左右的骨骼就可以取得不错的表现效果,所以相对于烘焙顶点,烘焙骨骼可以记录下更长的动画,同时它也不再受顶点数量的限制,也无需对法线或切线进行特殊处理(因为可以在采样后通过矩阵计算得出)。
针对这两种方案,我个人认为并没有绝对的孰优孰劣;正如你所看到的,烘焙骨骼在处理复杂模型或多动作时更具优势;但如果渲染数量较多、模型顶点数较少、表现需求较弱(无需法向量参与计算)时,烘焙顶点也是值得尝试的,因为它在性能上会更好一些。
目前静态合批方案为运行时静态合批,通过调用 BatchingUtility.batchStaticModel 可进行静态合批。
该函数接收一个节点,然后将该节点下的所有 MeshRenderer 里的 Mesh 合并成一个,并将其挂到另一个节点下。
在合批后,将无法改变原有的 MeshRenderer 的 transform,但可以改变合批后的根节点的 transform。只有满足以下条件的节点才能进行静态合批:
引擎目前提供两套动态合批系统,instancing 合批和合并 VB 方式的合批,两种方式不能共存,instancing 优先级大于合并 VB。
要开启合批,只需在模型所使用的材质中对应勾选 USE_INSTANCING 或 USE_BATCHING 开关即可。
通过 Instancing 的合批适用于绘制大量顶点数据完全相同的动态模型,启用后绘制时会根据材质和顶点数据分组,每组内组织 instanced attributes 信息,然后一次性完成绘制。
合并 VB 合批适用于绘制大量低面数且顶点数据各不相同的非蒙皮动态模型,启用后绘制时会根据材质分组,然后每组内每帧合并顶点和世界变换信息,然后分批完成绘制
通常来说合批系统的使用优先级为:静态合批 > instancing 合批 > 合并 VB 合批。
骨骼动画是一种常见但类型特殊的动画,我们提供了 预烘焙骨骼动画 和 实时计算骨骼动画 两套系统,针对不同方向的需求,分别优化。
这两套系统的唯一开关就是 SkeletalAnimation 上的 useBakedAnimation 开关,启用时会使用预烘焙骨骼动画系统,禁用后会使用实时计算骨骼动画系统,运行时也可以无缝切换。
目前所有模型资源在导入后,prefab 中全部默认使用预烘焙系统,以达到最佳性能。我们建议只在明显感到预烘焙系统的表现力无法达标的情况下,再使用实时计算系统。虽然两套系统可以在运行时无缝切换,但尽量不要高频执行,因为每次切换都涉及底层渲染数据的重建。
基于预烘焙系统的框架设计,蒙皮模型的 instancing 也成为了触手可及的功能,但要保证正确性还需要收集一些比较底层的信息。
这里的根本问题是,同一个 drawcall 内的各个模型使用的骨骼贴图必须是同一张,如果不是同一张,显示效果会完全错乱。所以如何将动画数据分配到每张骨骼贴图上,就成为了一个需要用户自定义的信息,对应在编辑器项目设置的 骨骼贴图布局面板 进行配置。
注意 :
目前底层上传 GPU 的骨骼纹理已做到全局自动合批复用,上层数据目前可以通过使用 批量蒙皮模型组件(BatchedSkinnedMeshRenderer)将同一个骨骼动画组件控制的所有子蒙皮模型合并:
由浅到深理解ROS
ROS文件系统
ROS文件系统中的两个最基本的概念:Package和Manifest,即包和清单文件。
(1)Package是组织ROS代码的最基本单位,每一个Package都可以包括库文件,可执行文件,脚本及其它的一些文件。
(2)Manifest文件是对Package的相关信息的一个描述。他提供了Package之间的依赖性,以及一个包的元信息,比如版本、维护着和许可证等信息。
catkin 编译构建系统的功能包 ——编译产生的可执行文件并未存放在功能包目录下,而是存放在一个单独的标准化目录层次结构中。对于使用 apt-get 安装的功能包,其所在根目录为/opt/ros/indigo。可执行文件存储在这个根目录下的 lib 子目录里。同样,在自动生成的头文件存储在 include 子目录下。当有需要时,ROS通过搜索 CMAKE_PREFIX_PATH 环境变量列出的目录,这个环境变量由 setup.bash 自动设置。
注意:你有可能在一些文档中看到功能包集( stack)的概念。功能包集是紧密相关的功能包的集合。从ROS的 groovy版本开始,功能包集的概念被逐步淘汰,取而代之的是元功能包( metapackages),元功能包像其他功能包一样有功能包清单,但其目录下没有其他的功能包,而功能包集则将其包含的功能包存放在其目录下。
节点管理器(The Master)
节点(Nodes)
ROS节点之间进行通信所利用的最重要的机制就是消息传递。在ROS中,消息有组织地存放在话题里。消息传递的理念是:当一个节点想要分享信息时,它就会发布(publish)消息到对应的一个或者多个话题;当一个节点想要接收信息时,它就会订阅(subscribe)它所需要的一个或者多个话题。ROS节点管理器负责确保发布节点和订阅节点能找到对方;而且消息是直接地从发布节点传递到订阅节点,中间并不经过节点管理器转交。
查看节点构成的计算图:先介绍个工具rqt_graph,要查看节点之间的连接关系,恐怕将其表示为图形是最便于查看的。在ROS 系统中查看节点之间的发布-订阅关系的最简单方式就是在终端输入如下令:rqt_graph。r 代表ROS,qt 指的是用来实现这个可视化程序的Qt 图形界面(GUI)工具包。
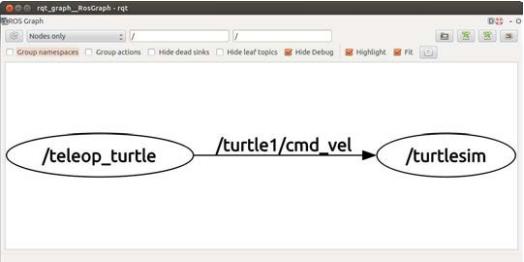
在该图中,椭圆形表示节点,有向边表示其两端节点间的发布-订阅关系。该计算图告诉们,/teleop_turtle节点向话题/turtle1/cmd_vel发布消,而/turtlesim 节点订阅了这些消息(“cmd_vel”是“command velocity”的缩写)。但是其中省略了调试节点,包括 rosout 节点,这是因为在默认情况下,rqt_graph 隐藏了其认为只在调试过程中使用的节点。你可以通过取消“Hide debug”选项来禁止这个特性,下图是完整的:

这些消息。这样有助于减少各个节点之间的耦合度。
以上是关于Cocos 3.x 由浅到浅入门批量渲染的主要内容,如果未能解决你的问题,请参考以下文章