22.json&pickle
Posted 星空月零
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了22.json&pickle相关的知识,希望对你有一定的参考价值。
转载:https://www.cnblogs.com/yuanchenqi/article/5732581.html
json
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
import json
x="[null,true,false,1]"
print(eval(x))
print(json.loads(x))
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
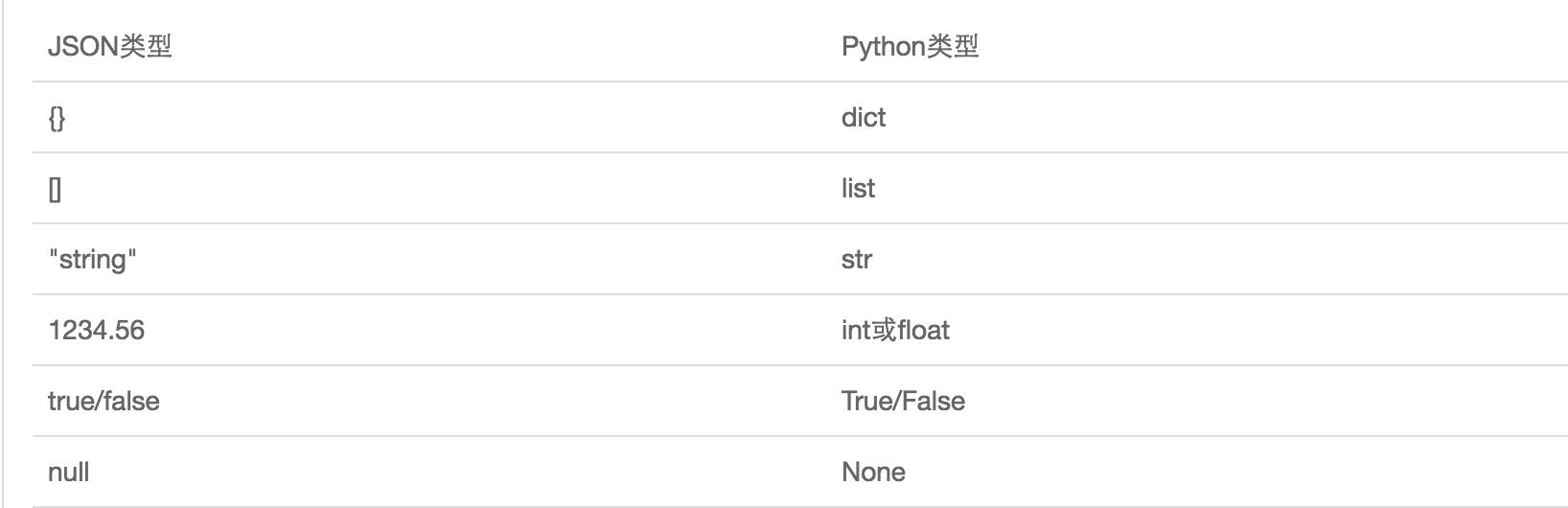
JSON表示的对象就是标准的javascript语言的对象,JSON和Python内置的数据类型对应如下:
#----------------------------序列化
import json
dic={\'name\':\'alvin\',\'age\':23,\'sex\':\'male\'}
print(type(dic))#<class \'dict\'>
j=json.dumps(dic)
print(type(j))#<class \'str\'>
f=open(\'序列化对象\',\'w\')
f.write(j) #-------------------等价于json.dump(dic,f)
f.close()
#-----------------------------反序列化<br>
import json
f=open(\'序列化对象\')
data=json.loads(f.read())# 等价于data=json.load(f)
# eval
# dic=\'{"name":"alex"}\'
# f=open("hello","w")
# f.write(dic)
# f_read=open("hello","r")
# data=f_read.read()
# print(type(data))
# data=eval(data)
# print(data["name"])
# import json
#
#
# dic={\'name\':\'alex\'}#---->{"name":"alex"}----->\'{"name":"alex"}\'
# i=8 #---->\'8\'
# s=\'hello\' #---->"hello"------>\'"hello"\'
# l=[11,22] #---->"[11,22]"
#
# f=open("new_hello","w")
# dic_str=json.dumps(dic)
# f.write(dic_str) #json.dump(dic,f)
# f_read=open("new_hello","r")
# data=json.loads(f_read.read()) # data=json.load(f)
#
# print(data["name"])
# print(data)
# print(type(data))
# print(s)
# print(type(s))
# data=json.dumps(dic)
#
# print(data) #{"name": "alex"}
# print(type(data))
#注意:
# import json
#
# with open("Json_test","r") as f:
# data=f.read()
# data=json.loads(data)
# print(data["name"])
注意:
import json
#dct="{\'1\':111}"#json 不认单引号
#dct=str({"1":111})#报错,因为生成的数据还是单引号:{\'one\': 1}
dct=\'{"1":"111"}\'
print(json.loads(dct))
#conclusion:
# 无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
注意点
pickle
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
import pickle
dic = {\'name\': \'alvin\', \'age\': 23, \'sex\': \'male\'}
print(type(dic)) # <class \'dict\'>
# j = pickle.dumps(dic)
# print(type(j)) # <class \'bytes\'>
#
# f = open(\'序列化对象_pickle\', \'wb\') # 注意是w是写入str,wb是写入bytes,j是\'bytes\'
# f.write(j) # -------------------等价于pickle.dump(dic,f)
#
# f.close()
# # -------------------------反序列化
import pickle
f = open(\'序列化对象_pickle\', \'rb\')
data = pickle.loads(f.read()) # 等价于data=pickle.load(f)
print(data[\'age\'])
shelve
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve
f = shelve.open(r\'shelve1\') # 目的:将一个字典放入文本 f={}
#
# f[\'stu1_info\']={\'name\':\'alex\',\'age\':\'18\'}
# f[\'stu2_info\']={\'name\':\'alvin\',\'age\':\'20\'}
# f[\'school_info\']={\'website\':\'oldboyedu.com\',\'city\':\'beijing\'}
# f.close()
print(f.get(\'stu1_info\')[\'age\'])
# dic={}
#
# dic["name"]="alvin"
# dic["info"]={"name":"alex"}
以上是关于22.json&pickle的主要内容,如果未能解决你的问题,请参考以下文章