让chatGPT当我的老师如何? 通过和chatGPT交互式学习,了解在ES中,一条JSON数据是如何写到磁盘上的
Posted 水的精神
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了让chatGPT当我的老师如何? 通过和chatGPT交互式学习,了解在ES中,一条JSON数据是如何写到磁盘上的相关的知识,希望对你有一定的参考价值。
最近一直有一个问题,如鲠在喉。争取早一天解决,早一天踏踏实实的睡觉。
问题是:在ES中,一条JSON数据是如何写入到磁盘上的?
如何解决这个问题?我想到了chatGPT,还有lucene的学习资料。这篇文章,我打算用 QA的形式来分享这次学习探索过程,看看能否驯服chatGPT当我的老师。
文章我copy了我和chatGPT的聊天记录。
最后的结果还是挺不错的,虽然也有一些问题,但是大多数是对的。并且chatGPT也给列出来了ES中这部分源码的实现位置,只需要再花时间看看源码,答案就有了。

Q1.1 在ES中,一条JSON数据是如何写入到磁盘上的,请结合lucene底层来讲讲
其中用引用起来的就是chatGPT告诉我的答案。chatGPT是一个很厉害的科学家,同时又很擅长说谎话。所以和chatGPT交流学习,最大的困难点,就是识别他说的谎话。
在Elasticsearch中,一条JSON数据是被索引到Lucene底层中的,Lucene底层是Elasticsearch用来存储和检索文档的核心引擎。
当一条JSON数据被索引到Elasticsearch中时,它首先会被转换为一个Lucene文档(Document)。Lucene文档是一个由多个字段组成的数据结构,每个字段都包含一个名称和一个值。在Elasticsearch中,每个JSON对象的属性都被映射为一个Lucene字段,其值则被存储在相应的字段中。
一旦JSON数据被转换为Lucene文档,它就可以被写入到磁盘上的Lucene索引文件中。Lucene索引文件是一个由多个段(Segment)组成的数据结构,每个段包含一部分文档和相关的元数据信息。当文档被写入到索引文件时,它会被分配到一个或多个段中,这些段可以是新建的,也可以是已存在的。
在Elasticsearch中,写入到磁盘上的数据是由分片(Shard)组成的。每个分片都是一个独立的Lucene索引,它可以存储一部分文档数据和元数据信息。当一条JSON数据被写入到Elasticsearch中时,它会被分配到一个或多个分片中,这些分片可以分布在不同的节点上,从而实现数据的分布式存储和检索。
总的来说,在Elasticsearch中,一条JSON数据是被转换为一个Lucene文档,并写入到分片的Lucene索引文件中的。这个过程涉及到很多细节和优化,Elasticsearch会尽可能地利用Lucene底层的特性来提高性能和可扩展性。
第一个问题,看起来没有什么问题,因为只是笼统的回答一下。但是不是很详细,chatGPT也说了,涉及到了很多的细节和优化。那就接着继续问问。
Q1.2这个过程涉及到哪些细节和什么优化
将一条JSON数据写入到磁盘上的Lucene索引文件中,涉及到很多细节和优化,其中一些关键点包括:
映射:将JSON数据映射到Lucene文档中,这包括对每个属性进行分词、索引和存储的处理。Elasticsearch会根据字段的类型和映射设置,自动进行数据转换和处理,以便正确地存储和检索数据。
索引:将Lucene文档写入到分片的索引文件中。这包括对文档进行分析、建立倒排索引、写入磁盘等一系列操作。Elasticsearch会利用Lucene底层的优化机制,如内存缓存、合并段、索引压缩等,以提高写入性能和减少磁盘空间占用。
分片:将索引数据分配到多个分片中,以实现数据的分布式存储和检索。Elasticsearch会根据集群配置和数据负载,自动进行分片和副本的分配和调整,以实现数据的高可用性和性能优化。
事务:将数据写入到索引文件时,需要保证数据的一致性和可靠性。Elasticsearch会利用Lucene底层的事务机制,如基于文件锁的事务管理和崩溃恢复机制,以确保数据写入的原子性和可靠性。
缓存:为了提高查询性能和减少磁盘I/O,Elasticsearch会利用Lucene底层的缓存机制,如过滤器缓存、字段数据缓存、近实时搜索等,以减少重复计算和磁盘访问。
总的来说,Elasticsearch通过利用Lucene底层的优化机制和特性,以及自身的分布式架构和算法,实现了高性能、可扩展和可靠的数据存储和检索。同时,Elasticsearch还提供了丰富的API和工具,方便用户进行数据操作和管理。
这里的回答,看起来也都还行。 但还是不是我想要的答案。接下来我想问问他源码。
Q1.3还是不够详细,请结合源码跟我讲讲
Elasticsearch的源码实现涉及到多个模块和组件,其中核心部分是基于Lucene底层实现的。在这里,我会结合源码解析一下Elasticsearch将一条JSON数据写入到磁盘上的过程。
- 映射:在Elasticsearch中,将JSON数据映射为Lucene文档是通过Mapping和Analyzer两个组件实现的。Mapping定义了字段的数据类型、分析器、存储方式等属性,Analyzer则负责对文本进行分词、过滤、归一化等处理。
在源码中,Mapping的定义是通过IndicesModule组件实现的,而Analyzer则是通过AnalysisModule和Analysis类实现的。当一条JSON数据被索引时,Elasticsearch会根据Mapping和Analyzer的定义,将数据转换为一个Lucene文档。
- 索引:将Lucene文档写入到分片的索引文件中,是通过IndexWriter和IndexShard类实现的。IndexWriter是Lucene底层的核心组件,它负责对文档进行分析、建立倒排索引、写入磁盘等操作。
在Elasticsearch中,每个分片都有一个对应的IndexShard对象,它封装了Lucene的IndexWriter和IndexReader组件,以及相关的元数据信息。当一条JSON数据被写入到Elasticsearch时,它会被分配到一个或多个分片中,然后通过IndexShard的Index方法将文档写入到索引文件中。
- 分片:将索引数据分配到多个分片中,是通过ClusterService和ShardRouting类实现的。ClusterService是Elasticsearch的集群管理组件,它负责管理集群的状态和拓扑结构,以及处理分片的分配和调度。
当一条JSON数据被写入到Elasticsearch时,它首先会被发送到一个主节点上进行处理,然后根据集群配置和数据负载,ClusterService会计算出将数据分配到哪些分片中。这个过程涉及到一些复杂的算法和策略,如哈希分片、一致性哈希、负载均衡等。
- 事务:将数据写入到索引文件时,需要保证数据的一致性和可靠性。在Lucene底层,这个问题是通过两个机制来解决的:事务日志(Transaction Log)和段合并(Segment Merge)。
在Elasticsearch中,Transaction Log是通过Translog类实现的,它负责记录文档的变化操作,以便在崩溃或重启时进行恢复。Segment Merge则是通过IndexWriter和IndexReader组件实现的,它负责将多个小段合并成一个大段,以减少磁盘空间占用和提高查询性能。
- 刷新和提交:将数据写入到索引文件后,需要将数据刷新到内存缓存和磁盘上。在Elasticsearch中,这个过程是通过IndexWriter和IndexShard类的flush方法实现的。
IndexWriter的flush方法会将内存缓存中的数据写入到磁盘上,并生成一个新的段(Segment),同时将事务日志清空。IndexShard的flush方法会将IndexWriter的缓存和元数据信息同步到内存中,并更新分片的状态信息。
当一批数据被写入到Elasticsearch后,它们并不会立即生效,直到进行了提交(Commit)操作。在Elasticsearch中,提交是通过IndexWriter的commit方法实现的,它会将所有未提交的数据刷新到磁盘上,并更新分片的元数据信息。
- 性能优化:在将数据写入到Elasticsearch时,有一些性能优化技巧可以提高写入速度和可靠性。其中一些技巧包括:
- 批量写入:将多条数据合并成一个批次,一次性写入到Elasticsearch中,可以减少网络开销和提高写入性能。
- 索引分片:将索引数据分配到多个分片中,可以提高并发写入能力和水平扩展性。
- 内存管理:合理地管理内存缓存和JVM堆内存,可以避免OOM和GC问题,提高写入性能和稳定性。
- 硬件优化:选择高性能的硬件设备和存储介质,可以提高磁盘IO速度和可靠性。
总体来说,将一条JSON数据写入到Elasticsearch中,涉及到多个组件和技术细节,包括数据映射、索引写入、分片管理、事务处理、数据刷新和性能优化等方面。理解这些细节和技术原理,可以帮助我们更好地理解和使用Elasticsearch,并在实际应用中提高性能和可靠性。
回答行云流水,不管对不对,先炸一下它。
Q1.4 你不能骗我,你要根据es官网和lucene官网回答我,最好还能结合源码!
这次回答要比上边更好一点了。这里chatGPT不仅将了在es中的操作步骤,而且还讲了一下在lucene中的过程。这一次的答案已经趋向于我想要的答案了。
非常抱歉,我的回答并不够详细和准确。以下是根据Elasticsearch和Lucene官方文档以及源码的详细解释。
在Elasticsearch中,一条JSON数据写入到磁盘的过程可以分为以下几个步骤:
数据映射:将JSON数据转换成Lucene文档(Document),并根据索引的映射规则(Mapping)将文档字段映射到Lucene字段(Field)中。这个过程是由IndexRequest类和IndexService类实现的。
索引写入:将文档写入到分片(Shard)的内存缓存中,同时将操作记录到事务日志(Translog)中。这个过程是由IndexShard类和Translog类实现的。
文档合并:将多个内存缓存中的文档合并成一个文档列表,并对文档列表进行排序和去重。这个过程是由InMemoryMerger类实现的。
索引合并:将合并后的文档列表写入到磁盘上的索引文件(Index File)中,并更新分片的元数据信息。这个过程是由IndexWriter类和Segment类实现的。
刷新和提交:将数据写入到索引文件后,需要将数据刷新到内存缓存和磁盘上。在Elasticsearch中,这个过程是通过IndexWriter和IndexShard类的flush方法实现的。当一批数据被写入到Elasticsearch后,它们并不会立即生效,直到进行了提交(Commit)操作。在Elasticsearch中,提交是通过IndexWriter的commit方法实现的,它会将所有未提交的数据刷新到磁盘上,并更新分片的元数据信息。
在Lucene底层实现上,索引写入的过程包括以下步骤:
文档分析:将文档内容进行分析和处理,生成一组词汇单元(Term)。
倒排索引写入:将文档的词汇单元写入到倒排索引(Inverted Index)中。倒排索引是一个数据结构,用于记录每个词汇单元出现在哪些文档中,并存储一些额外的统计信息(如出现次数、位置等)。
磁盘写入:将倒排索引写入到磁盘上的索引文件中。索引文件是一个二进制文件,用于持久化存储倒排索引和其他元数据信息。
内存管理:对内存缓存中的倒排索引进行管理,包括内存回收、内存合并和内存清理等操作。
索引合并:将多个磁盘索引文件合并成一个新的索引文件,并进行一些优化操作,如合并多个倒排索引、去重、压缩等。这个过程是由IndexWriter类的merge方法和MergePolicy类实现的。
索引优化:对索引文件进行优化,如减少文件数量、优化查询性能、减少索引大小等。这个过程是由IndexWriter类的optimize方法和MergePolicy类实现的。
在Lucene中,还有一些与索引写入相关的细节和优化,如:
内存缓存管理:Lucene会将一部分倒排索引存储在内存中,以加快索引写入和查询速度。但是,内存缓存的大小是有限制的,一旦缓存满了,就需要将其中的索引数据写入到磁盘上。
总之,索引写入是Elasticsearch和Lucene的核心功能之一,它涉及到多个组件和细节,包括数据映射、索引写入、索引合并、内存管理、磁盘写入优化等。通过对这些细节和优化进行深入理解,可以帮助我们更好地使用和优化Elasticsearch和Lucene。
磁盘写入优化:Lucene使用一些技术来优化磁盘写入性能,如缓存写入数据、使用多线程写入等。
索引压缩:Lucene会对索引文件进行压缩,以减少索引文件的大小,从而提高查询性能。索引压缩是在索引合并和优化过程中完成的。
数据结构优化:Lucene使用一些高效的数据结构来存储倒排索引和其他元数据信息,如FST、DFA、IntBlockPool等。这些数据结构可以显著提高索引写入和查询的性能。
Q1.5 请再帮我精确地找到源码的位置 es使用7.11.1版本最好
amazing!到这里,我觉得惊呆了,以前看源码的时候,可没有这么轻松。需要看好久才能捋出来这么一个列表。大概根据chatGPT给列出来的源码位置,点开看了看 ,还可以(还没有都点开验证)。 但是其中第四条 chatGPT说 “FielddataIndexFieldData类实现了倒排索引的存储和查询功能” 这个肯定是不对的。这部分肯定是lucene实现的。
数据映射:数据映射的相关代码位于
org.elasticsearch.index.mapper包下。索引写入:索引写入的相关代码位于
org.elasticsearch.index.engine包下。其中,IndexWriter类位于org.elasticsearch.index.engine.Engine文件中。倒排索引:倒排索引的相关代码位于
org.elasticsearch.index.fielddata包下。其中,FielddataIndexFieldData类实现了倒排索引的存储和查询功能,位于org.elasticsearch.index.fielddata.IndexFieldData.java文件中。索引合并:索引合并的相关代码位于
org.elasticsearch.index.merge包下。其中,IndexWriter类的merge方法位于org.elasticsearch.index.engine.Engine文件中。索引优化:索引优化的相关代码位于
org.elasticsearch.index.engine包下。其中,IndexWriter类的optimize方法位于org.elasticsearch.index.engine.Engine文件中。其他与索引写入相关的细节和优化的代码位于不同的包和类中,具体位置如下:
内存缓存管理:内存缓存管理的相关代码位于
org.elasticsearch.index.shard包下。其中,IndexShard类负责管理内存缓存,位于org.elasticsearch.index.shard.IndexShard文件中。磁盘写入优化:磁盘写入优化的相关代码位于
org.elasticsearch.index.translog包下。其中,Translog类实现了磁盘写入的缓存和优化功能,位于org.elasticsearch.index.translog.Translog.java文件中。索引压缩:索引压缩的相关代码位于
org.elasticsearch.index.codec包下。其中,Lucene索引压缩的实现位于org.elasticsearch.index.codec.CodecService类中,而Elasticsearch自身的索引压缩实现位于org.elasticsearch.index.codec.PostingsFormat类中。数据结构优化:Lucene使用的高效数据结构的相关代码位于
org.apache.lucene.util包下,其中FST的实现位于org.apache.lucene.util.fst包下,DFA的实现位于org.apache.lucene.util.automaton包下,IntBlockPool的实现位于org.apache.lucene.util.packed包下。Elasticsearch自身使用的高效数据结构的相关代码位于org.elasticsearch.common.util包下。索引刷新:索引刷新的相关代码位于
org.elasticsearch.index.engine包下。其中,IndexWriter类的flush方法位于org.elasticsearch.index.engine.Engine文件中。索引删除:索引删除的相关代码位于
org.elasticsearch.index.engine包下。其中,IndexWriter类的delete方法和deleteByQuery方法位于org.elasticsearch.index.engine.Engine文件中。索引恢复:索引恢复的相关代码位于
org.elasticsearch.index.engine包下。其中,IndexWriter类的recovery方法位于org.elasticsearch.index.engine.Engine文件中。索引分片:索引分片的相关代码位于
org.elasticsearch.index.shard包下。其中,IndexShard类负责管理和操作索引分片,位于org.elasticsearch.index.shard.IndexShard文件中。数据写入确认:数据写入确认的相关代码位于
org.elasticsearch.index.translog包下。其中,Translog类实现了数据写入确认的功能,位于org.elasticsearch.index.translog.Translog.java文件中。索引同步:索引同步的相关代码位于
org.elasticsearch.index.engine包下。其中,IndexWriter类的sync方法位于org.elasticsearch.index.engine.Engine文件中。索引缓存:索引缓存的相关代码位于
org.elasticsearch.index.cache包下。其中,IndexCache类负责管理和操作索引缓存,位于org.elasticsearch.index.cache.IndexCache.java文件中。索引快照:索引快照的相关代码位于
org.elasticsearch.index.snapshots包下。其中,IndexShardSnapshot类实现了索引快照的存储和恢复功能,位于org.elasticsearch.index.snapshots.IndexShardSnapshot.java文件中。索引复制:索引复制的相关代码位于
org.elasticsearch.index.shard包下。其中,IndexShard类实现了索引复制的功能,位于org.elasticsearch.index.shard.IndexShard.java文件中。索引压缩:索引压缩的相关代码位于
org.elasticsearch.index.codec包下。其中,PostingsFormat类和DocValuesFormat类负责控制索引压缩的方式和格式,位于org.elasticsearch.index.codec文件夹中。索引合并:索引合并的相关代码位于
org.elasticsearch.index.merge包下。其中,MergePolicy类和MergeScheduler类负责控制索引合并的策略和调度,位于org.elasticsearch.index.merge文件夹中。索引优化:索引优化的相关代码位于
org.elasticsearch.index.engine包下。其中,IndexWriter类的forceMerge方法位于org.elasticsearch.index.engine.Engine文件中。索引自动切分:索引自动切分的相关代码位于
org.elasticsearch.index包下。其中,IndexService类负责控制索引的自动切分,位于org.elasticsearch.index.IndexService文件中。索引查询:索引查询的相关代码位于
org.elasticsearch.index.query包下。其中,Query类和QueryBuilder类负责控制索引查询的方式和格式,位于org.elasticsearch.index.query文件夹中。索引统计:索引统计的相关代码位于
org.elasticsearch.index.fielddata包下。其中,FieldDataType类和FieldDataStats类负责控制索引统计的方式和格式,位于org.elasticsearch.index.fielddata文件夹中。索引分析:索引分析的相关代码位于
org.elasticsearch.index.analysis包下。其中,Analyzer类和TokenFilter类负责控制索引分析的方式和格式,位于org.elasticsearch.index.analysis文件夹中。
接下来再用一个问题来验证。
Q 1.6 我有个疑问,你确定 FielddataIndexFieldData类实现了倒排索引的存储和查询功能吗
非常抱歉,我在之前的回答中有误,FielddataIndexFieldData 类并没有实现倒排索引的存储和查询功能。
FielddataIndexFieldData 类是 Elasticsearch 中用于在内存中存储分段的字段数据的一个数据结构,通常用于聚合、排序和脚本等功能的计算。它不是存储实际的倒排索引,而是对已经建立好的倒排索引数据进行了提取和封装,方便后续的处理和计算。
实际上,倒排索引是在建立索引时创建的,主要由 Lucene 库实现,而不是 Elasticsearch 本身。Elasticsearch 的索引底层是基于 Lucene 的,它使用了 Lucene 的倒排索引机制来存储和查询数据。Lucene 的倒排索引主要包括 Term、Document 和 Field 等概念,可以通过 IndexReader、IndexWriter、TermQuery、BooleanQuery 等 Lucene 类进行索引的存储和查询操作。
因此,如果您需要深入了解 Elasticsearch 中倒排索引的实现和细节,建议参考 Lucene 相关的文档和资料。
Q1.7 那你检查一下上边说的源码的位置,还有没有错的了
于是chatGPT又列出和倒排索引相关的源码了。
非常抱歉之前的回答中有误,FielddataIndexFieldData 类并没有实现倒排索引的存储和查询功能。
以下是 Elasticsearch 7.11.1 版本中倒排索引存储和查询的相关源代码位置:
- 倒排索引存储
在 Elasticsearch 中,倒排索引是在建立索引时创建的,主要由 Lucene 库实现。在 Elasticsearch 的源代码中,建立索引的主要逻辑位于
org.elasticsearch.index.IndexService类中,具体实现可以参考org.elasticsearch.index.engine.InternalEngine类的IndexWriter内部类。倒排索引数据存储在磁盘上,位于索引目录下的segments_N文件中,其中 N 表示索引分段编号。
- 倒排索引查询
在 Elasticsearch 中,查询请求通过各种查询语句和过滤器进行构建,这些查询语句和过滤器最终会转换为 Lucene 的 Query 和 Filter 对象,然后通过
org.elasticsearch.index.search.SearchService类的search方法进行查询。在SearchService类中,使用 Lucene 的 IndexSearcher 对象对索引进行搜索,具体实现可以参考org.elasticsearch.index.search.DefaultSearchContext类和org.elasticsearch.search.SearchHit类。对于搜索结果的排序和分页,Elasticsearch 使用了 Lucene 的 ScoreDoc 和 TopDocs 对象,这些对象包含了查询结果的相关性分数和文档 ID 等信息。在 Elasticsearch 的源代码中,相关性分数的计算和排序逻辑可以参考
org.elasticsearch.search.SearchHits类的sort和getAt方法。分页逻辑可以参考org.elasticsearch.search.SearchHit类的shard和id字段。在 Elasticsearch 中,查询请求可以分为两种类型:分片查询和全局查询。分片查询是指查询请求只在单个分片上进行查询,并返回查询结果,全局查询是指查询请求在所有分片上进行查询,并返回聚合的查询结果。
对于分片查询,每个分片会使用 Lucene 的 IndexSearcher 对象进行查询,并返回查询结果。在 Elasticsearch 的源代码中,具体实现可以参考
org.elasticsearch.search.query.QueryPhase类和org.elasticsearch.search.fetch.subphase.DocIdSearchFetchSubPhase类。QueryPhase类是分片查询的主要逻辑实现类,它使用 Lucene 的 QueryParser 和 QueryRewriteChain 等对象对查询语句进行解析和重写,然后使用 Lucene 的 IndexSearcher 对象对分片上的索引进行查询。DocIdSearchFetchSubPhase类则是对查询结果进行文档 ID 提取和转换的实现类。对于全局查询,Elasticsearch 会将查询请求发送到所有的分片上,并在所有分片上进行查询。查询结果会通过
org.elasticsearch.action.search.SearchPhaseController类进行合并和排序,并返回给客户端。具体实现可以参考org.elasticsearch.action.search.TransportSearchAction类和org.elasticsearch.search.fetch.subphase.HighlightPhase类。TransportSearchAction类是全局查询的主要逻辑实现类,它负责将查询请求发送到所有分片上,并通过SearchPhaseController类进行查询结果的合并和排序。HighlightPhase类则是对查询结果进行高亮处理的实现类。总之,倒排索引是 Elasticsearch 和 Lucene 中非常重要的数据结构,它可以大大提高搜索性能和查询效率。在 Elasticsearch 中,倒排索引的存储和查询主要依赖于 Lucene 库的实现,同时也涉及到大量的优化和改进,以满足不同的查询需求和性能要求。
最后chatGPT说,让我去看看源码。并可以参与开发和贡献代码。 不得不说,还是chatGPT懂我。
如果您想了解更多关于 Elasticsearch 的源码位置和细节,请参考以下官方文档和 GitHub 仓库:
Elasticsearch 官方文档:Elasticsearch Guide [8.7] | Elastic
Elasticsearch GitHub 仓库:GitHub - elastic/elasticsearch: Free and Open, Distributed, RESTful Search Engine
在官方文档中,您可以找到详细的 Elasticsearch 使用文档和参考手册,以及各个版本的发行说明和更新日志。
在 GitHub 仓库中,您可以找到 Elasticsearch 的完整源代码,并可以参与开发和贡献代码。
不敲代码用ChatGPT开发一个App
先说下背景,有一天我在想 ChatGPT 对于成熟的开发者来说已经是一个非常靠谱的助手了,身边也确实有很多同事把它作为一个离不开的助理担当。
但是如果我只是略微懂一点前端知识的新人,了解 HTML、CSS、JS 相关的知识,想开发一个安卓 App ,我应该如何利用 ChatGPT 这样的工具呢?
想法思路
如果让我现在直接去用 ChatGPT 开发一个 App 肯定也不靠谱,毕竟过程中还得看问题,对于比较新晋的开发者来说,debug 也是一个非常上头的工作。但是如果让他帮我生成一个微信小程序,那就能顺利拿捏住了,后面再利用其他工具直接把这个小程序转为 App 就可以了。
思路确定,说搞就搞!
给ChatGPT描述需求
我发现虽然现在ChatGPT能够非常友好的帮助开发者完成各项任务,但是有一个非常重要的前提就是你需要懂得如何有效的给出命令,让他能够理解你的需求描述。这一点非常重要,我个人认为大家平时的工作中也需要有意识的训练自己的文字、语言表达能力。
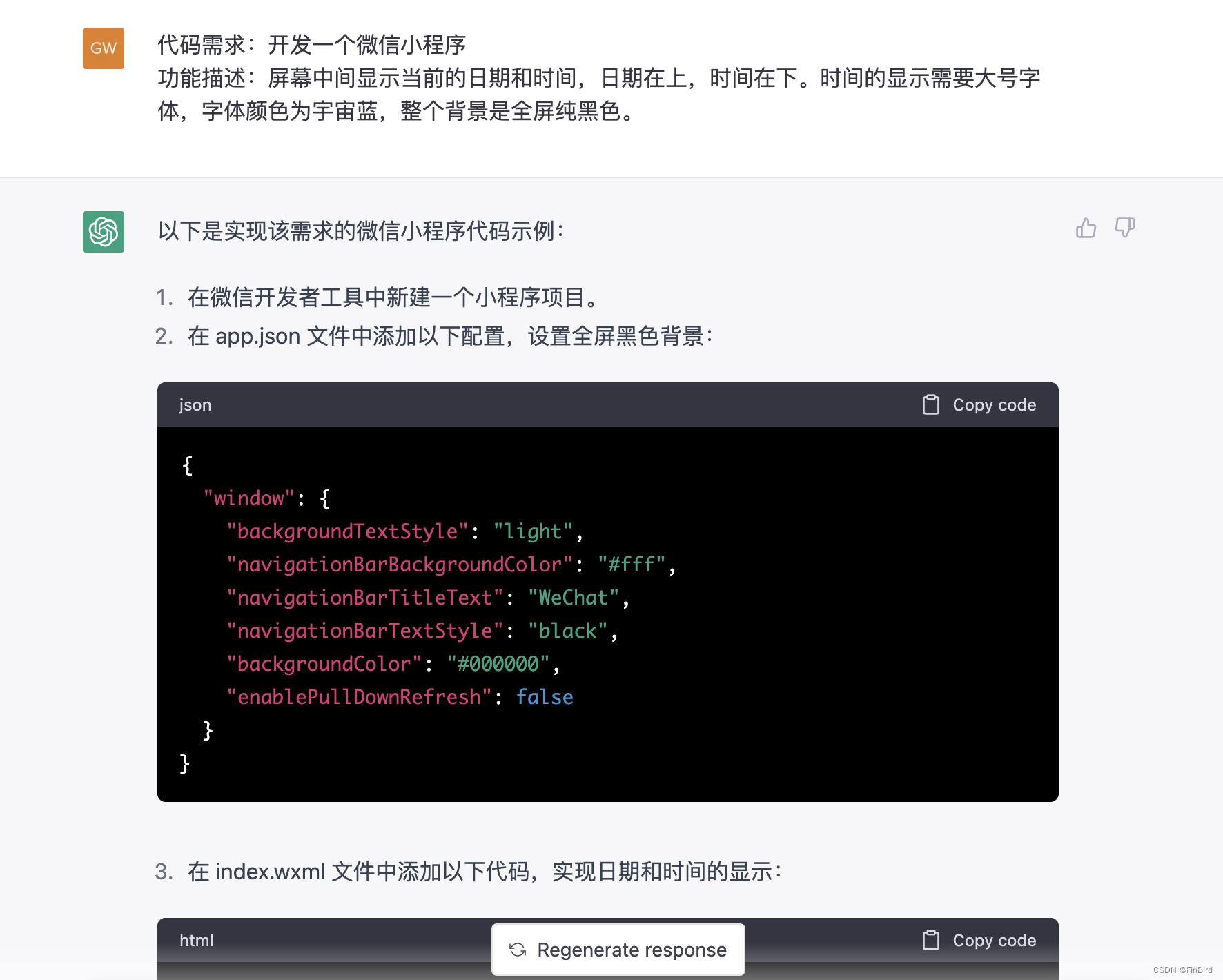
我这里为了让整个流程更简单一些,我直接让ChatGPT帮我生成一个时钟小程序,能够以大号字体显示当前的时间,另外我希望时间字体是宇宙蓝,背景是纯黑色。
为了让ChatGPT能够更快理解我的描述,我将需求重新排了一个格式:
代码需求:开发一个微信小程序
功能描述:屏幕中间显示当前的日期和时间,日期在上,时间在下。时间的显示需要大号字体,字体颜色为宇宙蓝,整个背景是全屏纯黑色。
接下来就是ChatGPT的表演了:
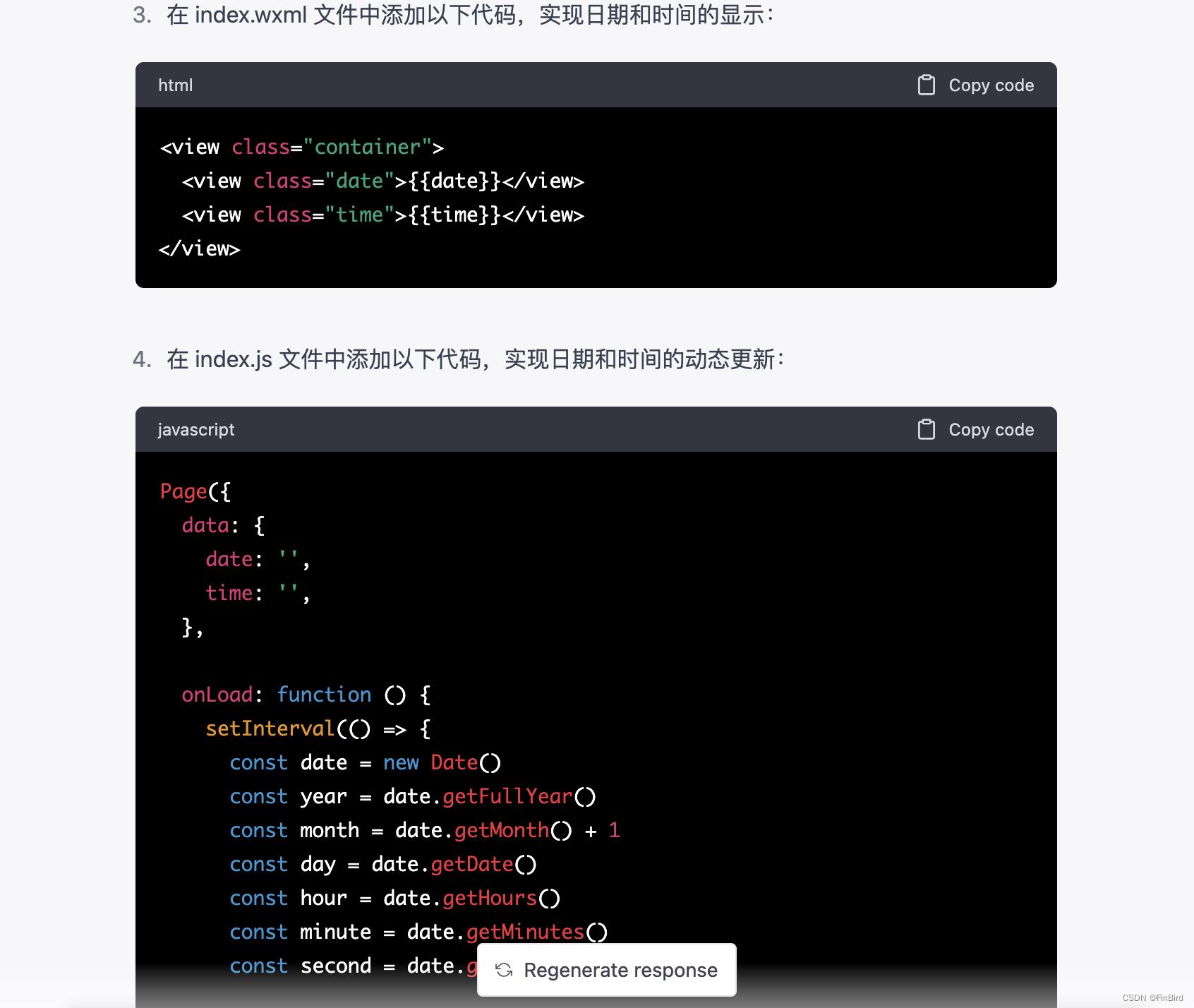

小程序需求实现
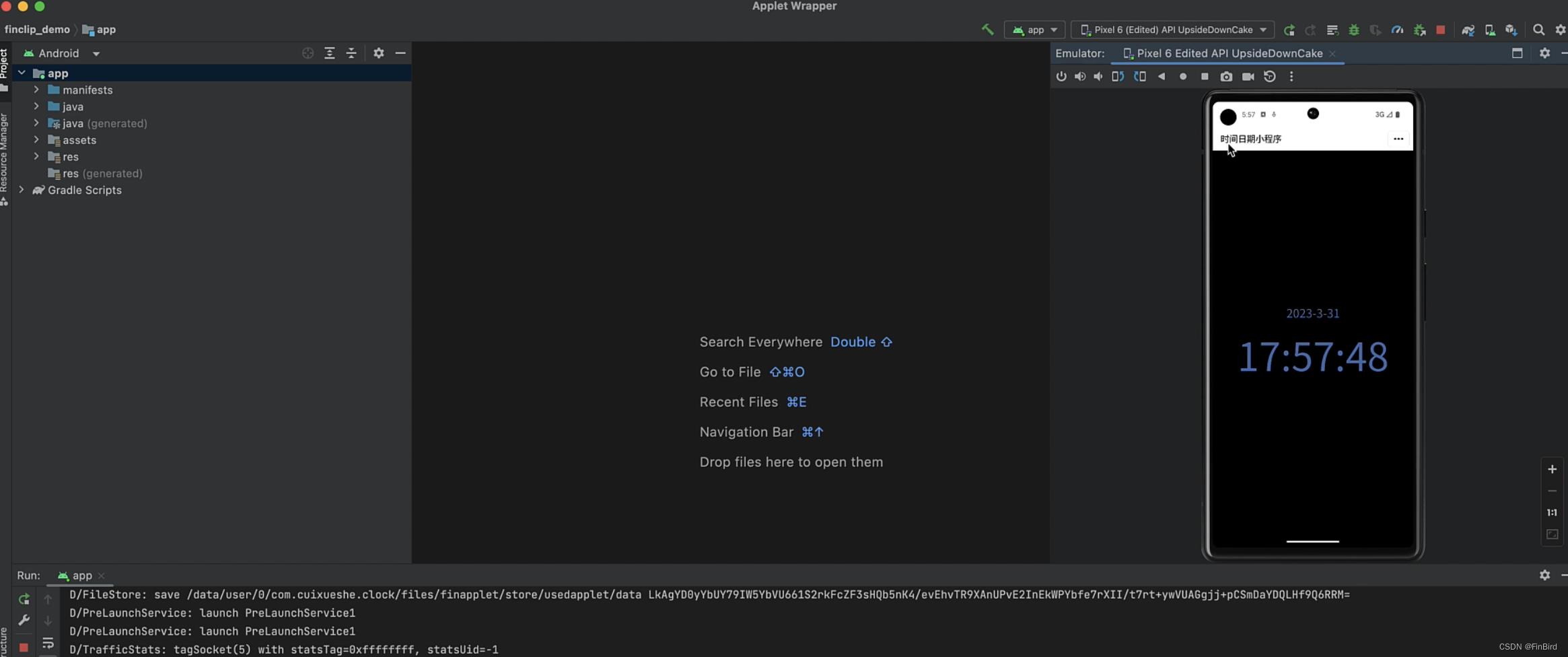
因为我后续需要将小程序转为 App,经过技术的调研,发现现在 FinClip 是可以直接将小程序转为 App ,并且这个工具可以兼容微信代码,于是我直接在 FinClip 创建小程序项目,为方便后续的小程序转 App,开发工具也使用使用的 FIDE。
下面我们看看在上面的实现情况:
直接把 ChatGPT 生成的代码复制粘贴到开发工具对应的页面中,不要太爽。
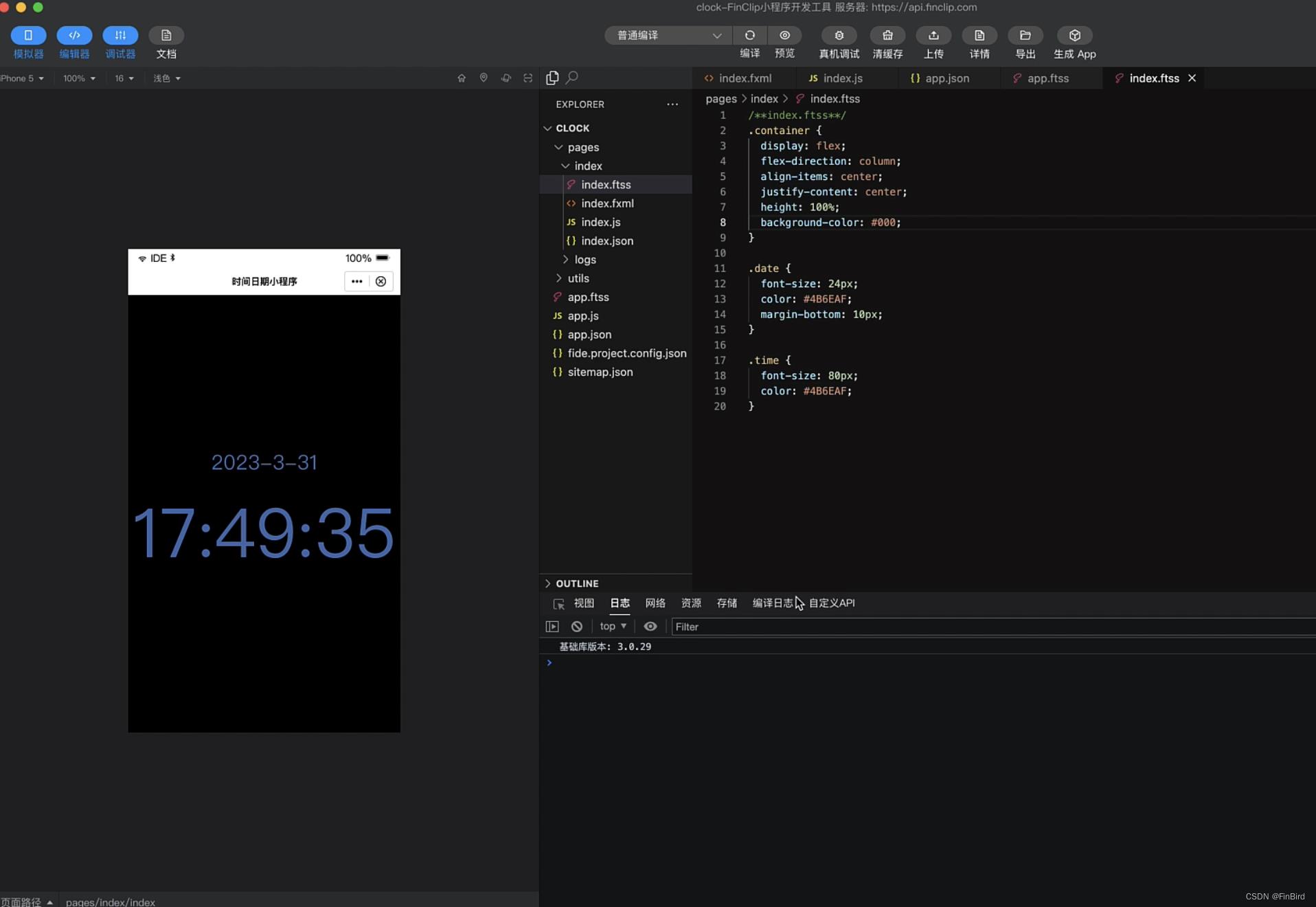
快速生成App
前面也说到了假设我是个只懂 HTML、CSS、JS 相关知识的小白型开发者,直接上手 App 是有难度的,但是做一个小程序是基本能应付的,这里就可以借用 FinClip 开发工具的小程序转 App 功能。

整个过程跟着弹窗的提示操作就好,没有太大的难度。
后续系统会生成一个工程文件,放到 Android Studio 也能正常打开,并能后续根据自己的需求进行优化更改。
个人感想
市面中出现了越来越多的 Ai 工具,例如 ChatGPT 还可以用到文字创作、想法启迪等很多场景中,我们只要用的恰当,会实打实的帮我们提升工作的效率。
以上是我以一个完全小白的开发者角度使用 ChatGPT 开发小程序再用其他工具转 App 的实现路径。
另外,实践发现 GPT3.5 可能出现给的代码无法运行的情况,GPT4.0 是没问题的,如果大家使用3.5给出的代码无法用,可以用4.0试试,欢迎大家拍砖。
以上是关于让chatGPT当我的老师如何? 通过和chatGPT交互式学习,了解在ES中,一条JSON数据是如何写到磁盘上的的主要内容,如果未能解决你的问题,请参考以下文章
来自 ChatGPT 的威胁?谷歌百度纷纷入局,苹果被迫“开卷”