hive架构和原理以及与传统数据库的区别
Posted ChlinRei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive架构和原理以及与传统数据库的区别相关的知识,希望对你有一定的参考价值。
hive
1.1 hive简介
1.1.1 什么是hive?
hive是一个构建在Hadoop上的数据仓库工具(框架),可以将结构化的数据文件映射成一张数据表,并可以使用类似sql的方式来对这样的数据文件进行读、写以及管理(包括元数据)。Hive SQL 简称HQL。hive的执行引擎可以是MR、Spark、tez。
如果执行引擎是MapReduce的话,hive会将Hql翻译成MR进行数据的计算。 用户可以使用命令行工具或JDBC驱动程序来连接到hive。
1.1.2 为什么使用hive
因为直接使用Map Reduce,需要面临一下问题:
- 人员学习成本高
- 项目周期要求太短
- Map Reduce实现复杂查询逻辑开发难度大
1.1.3 hive的优缺点
1.1.3.1 hive的优点
- 学习成本低
- 可扩展性好
- 适合做离线分析处理(OLAP)
- 延展性好
- 良好的容错性
- 统计管理
1.1.3.2 hive的缺点
- hive的HQL表达能力有限
- hive的效率比价低
1.2 hive架构和原理
1.2.1 hive的架构
-
用户连接接口
CLI:是指Shell命令行
JDBC/ODBC:是指hive的Java实现,与传统数据库JDBC类似。
WebUI:是指可通过浏览器访问hive。
-
thriftserver:
hive的可选组件,此组件是一个软件框架服务,允许客户端使用包括Java、c++、Ruby和其他多种语言,通过编程的方式远程访问hive。
- 元数据
hive将元数据存储在数据库中,如mysql、derby。hive中的元数据包括(表名、表所属的数据库名、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等)
- 驱动器(Driver)
- 解析器(SQLParser):
将HQL字符串转换成抽象的语法树AST,这一步一般都用第三方工具库完成,比如antlr:对AST进行语法分析,比如表是否存在、SQL语义是否有误。
- 编译器(Compiler):
对HQL语句进行词法、语法、语义的编译(需要跟元数据关联),编译完成后会生成一个执行计划。hive上就是编译成mapreduce的job。
- 优化器(Optimizer):
将执行计划进行优化,减少不必要的列、使用分区、使用索引等。优化job。
- 执行器(Executer):
将优化后的执行计划提交给Hadoop的yarn上执行。提交job。
- hadoop
Jobtracker是hadoop1.x中的组件,它的功能相当于:Resourcemanager+AppMaster
TaskTracker相当于Nodemanager + yarnchild
Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成
注意:
- 包含*的全表查询,比如select * from table 不会生成MapRedcue任务
- 包含*的limit查询,比如select * from table limit 3 不会生成MapRedcue任务
1.2.2 hive的工作原理
-
用户提交查询等任务给Driver。
-
驱动程序将Hql发送编译器,检查语法和生成查询计划。
-
编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
-
编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce), 最后选择最佳的策略。
-
将最终的计划提交给Driver。到此为止,查询解析和编译完成。
-
Driver将计划Plan转交给ExecutionEngine去执行。
-
在内部,执行作业的过程是一个MapReduce工作。执行引擎发送作业给JobTracker,在名称节点并把它分配作业到TaskTracker,这是在数据节点。在这里,查询执行MapReduce工作。
7.1 与此同时,在执行时,执行引擎可以通过Metastore执行元数据操作。
-
执行引擎接收来自数据节点的结果。
-
执行引擎发送这些结果值给驱动程序。
-
驱动程序将结果发送给Hive接口。
1.2.3 hive和Hadoop的关系
- hive本身其实没有多少功能,hive就相当于在Hadoop上面包了一个壳子,就是对Hadoop进行了一次封装。
- hive的存储是基于hdfs/hbase的,hive的计算是基于mapreduce。
1.3 hive与传统型数据库的区别
-
Hive采用了类SQL的查询语言HQL,因此很容易将Hive理解为数据库。其实从结构上来看,Hive和数据库除了拥有类似的查询语言,再无类似之处。
-
数据库可以用在OLTP的应用中,但是Hive是为数据仓库而设计的,清楚这一点,有助于从应用角度理解Hive的特性。
-
Hive不适合用于联机事务处理(OLTP),也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。Hive 的特点是可伸缩(在Hadoop 的集群上动态的添加设备),可扩展、容错、输入格式的松散耦合。Hive 的入口是DRIVER ,执行的SQL语句首先提交到DRIVER驱动,然后调COMPILER解释驱动,最终解释成MapReduce 任务执行,最后将结果返回。
-
MapReduce 开发人员可以把自己写的 Mapper 和 Reducer 作为插件支持 Hive 做更复杂的数据分析。 它与关系型数据库的 SQL 略有不同,但支持了绝大多数的语句(如 DDL、DML)以及常见的聚合函数、连接查询、条件查询等操作。
1.3.1 hive和MySQL的比较
-
mysql用自己的存储存储引擎,hive使用的hdfs来存储。
-
mysql使用自己的执行引擎,而hive使用的是mapreduce来执行。
-
mysql使用环境几乎没有限制,hive是基于hadoop的。
-
mysql的低延迟,hive是高延迟。
-
mysql的handle的数据量较小,而hive的handle数据量较大。
-
mysql的可扩展性较低,而hive的扩展性较高。
-
mysql的数据存储格式要求严格,而hive对数据格式不做严格要求。
-
mysql可以允许局部数据插入、更新、删除等,而hive不支持局部数据的操作。
10Hive核心概念和架构原理
1、 Hive核心概念和架构原理1.1、 Hive概念
Hive由FaceBook开发,用于解决海量结构化日志的数据统计。
Hive是基于Hadoop的数据仓库工具,可以将结构化数据映射为一张表,提供类似SQL语句查询功能
本质:将Hive SQL转化成MapReduce程序。
1.2、Hive与数据库的区别
| 对变项 | Hive | 数据库软件 |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Raw Devce or Loal FS |
| 执行器 | MapReduce | Executor |
| 数据插入 | 支持批量导入/单条插入 | 支持单条或者批量导入 |
| 数据操作 | 覆盖追加 | 行级更新删除 |
| 处理数据规模 | 大 | 小 |
| 执行延迟 | 高 | 低 |
| 分区 | 支持 | 支持 |
| 索引 | 0.8版本之后加入了索引 | 支持复杂的索引 |
| 扩展性 | 高 | 有限 |
| 数据加载模式 | 读时模式(快) | 写时模式(慢) |
| 应用场景 | 海量数据查询 | 实时查询 |
读时模式:Hive在加载数据到表中的时候不会校验.
写时模式:Mysql数据库插入数据到表的时候会进行校验.
总结:Hive只适合用来做海量离线的数据统计分析,也就是数据仓库。
1.3、Hive的优缺点
优点:操作接口采用了类SQL语法,提供快速开发的能力,避免了去写MapReduce;Hive还支持用户自定义函数,用户可以根据自己的需求实现自己的函数。
缺点:Hive不支持纪录级别的增删改操作;Hive查询延迟很严重;Hive不支持事务。
1.4、Hive架构原理
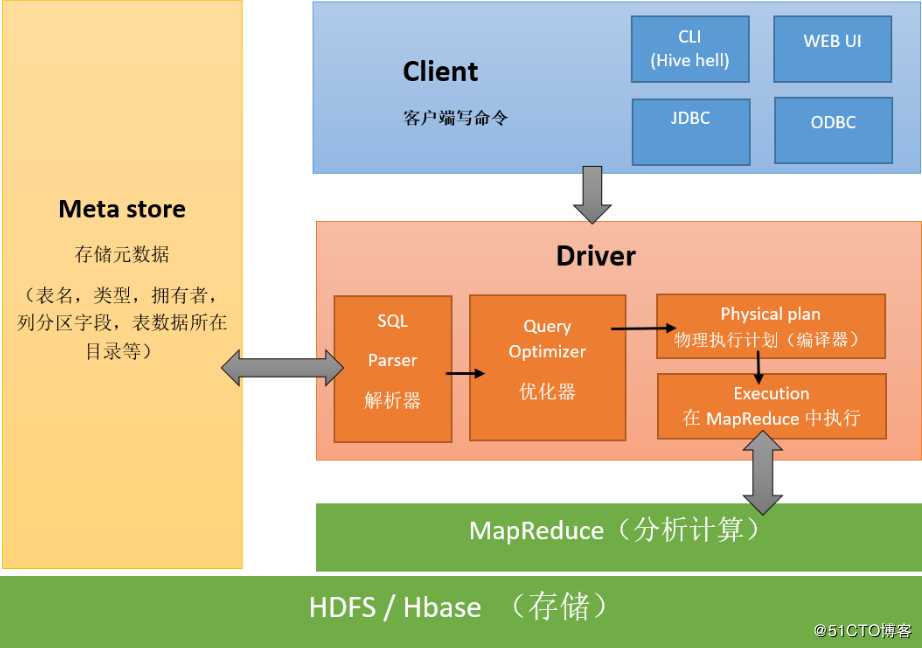
? (1)用户接口:CLI(hive shell);JDBC(java访问Hive);WEBUI(浏览器访问Hive)
? (2)元数据:MetaStore
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段,标的类型(表是否为外部表)、表的数据所在目录。这是数据默认存储在Hive自带的derby数据库中,推荐使用MySQL数据库存储MetaStore。
(3)Hadoop集群:
使用HDFS进行存储数据,使用MapReduce进行计算。
(4)Driver:驱动器
解析器(SQL Parser):将SQL字符串换成抽象语法树AST,对AST进行语法分析,像是表是否存在、字段是否存在、SQL语义是否有误。
编译器(Physical Plan):将AST编译成逻辑执行计划。
优化器(Query Optimizer):将逻辑计划进行优化。
执行器(Execution):把执行计划转换成可以运行的物理计划。对于Hive来说默认就是Mapreduce任务。
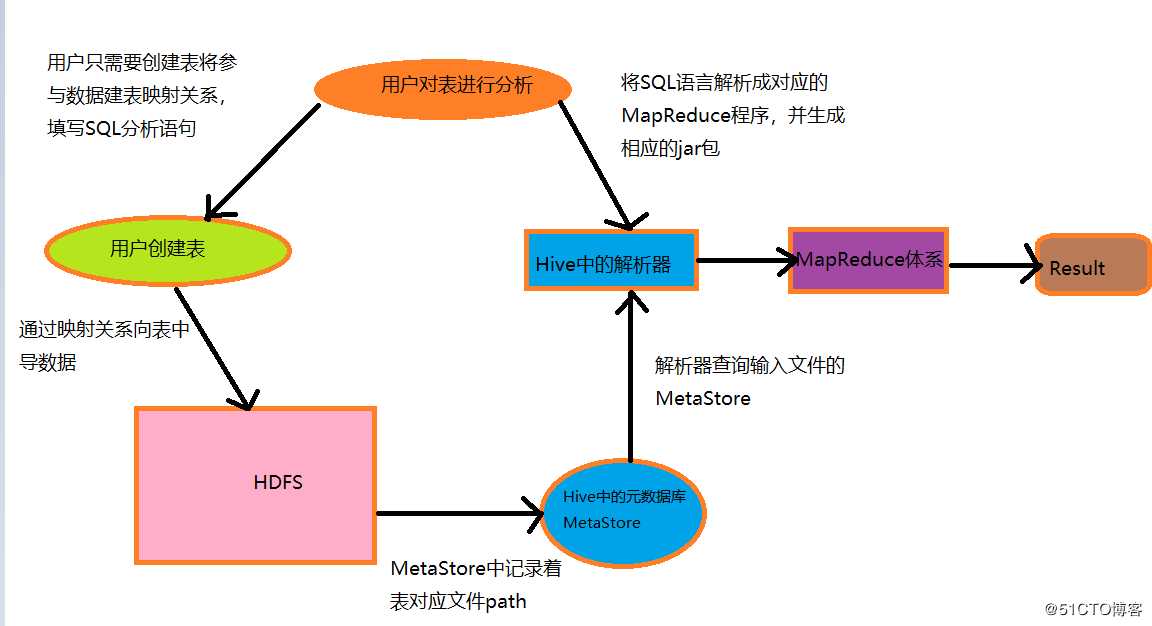
通过Hive**对数据进行数据分析过程**:
2、 Hive交互方式
需要先启动hadoop集群和MySQL服务
2.1、Hive交互shell
cd /opt/bigdata2.7/hive (hive的安装路径,根据自己实际情况改变)bin/hive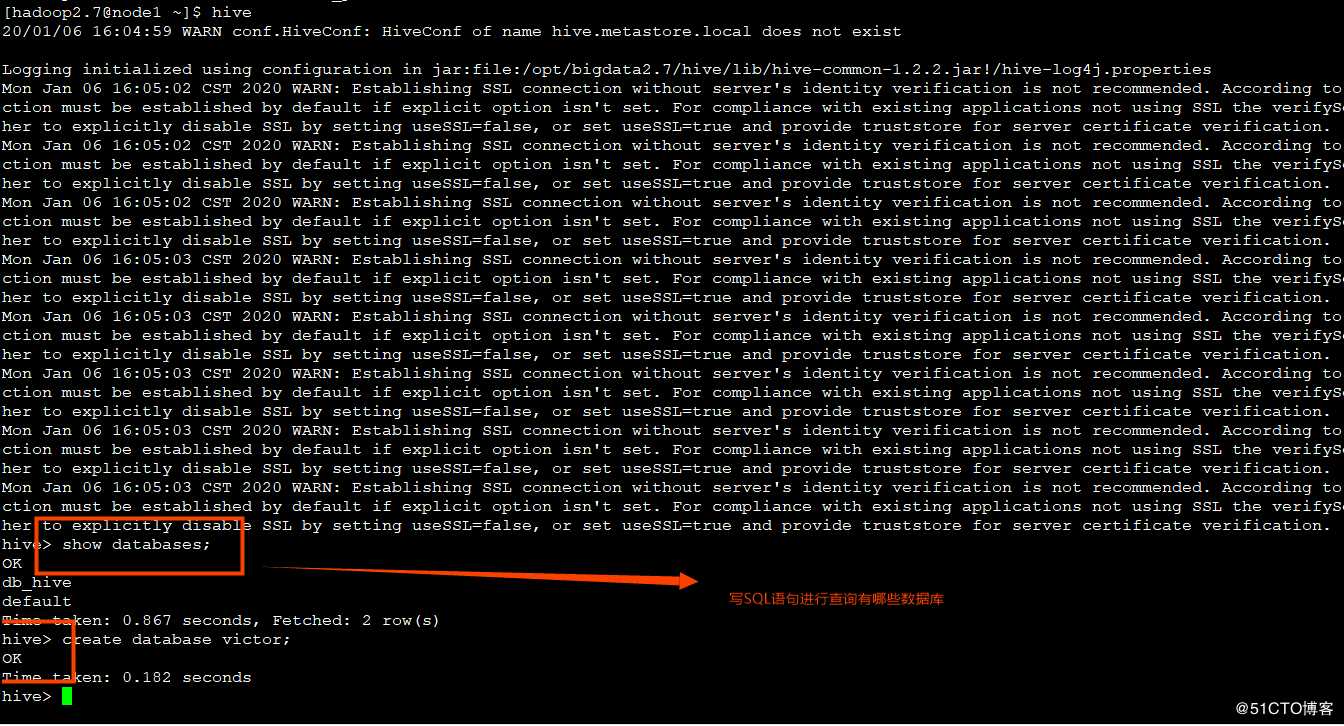
? 可以在命令端口写上HQL语句:show databases;验证是否可用。
2.2、JDBC交互
输入hiveserver2相当于开启了一个服务端,查看hivesever2的转态
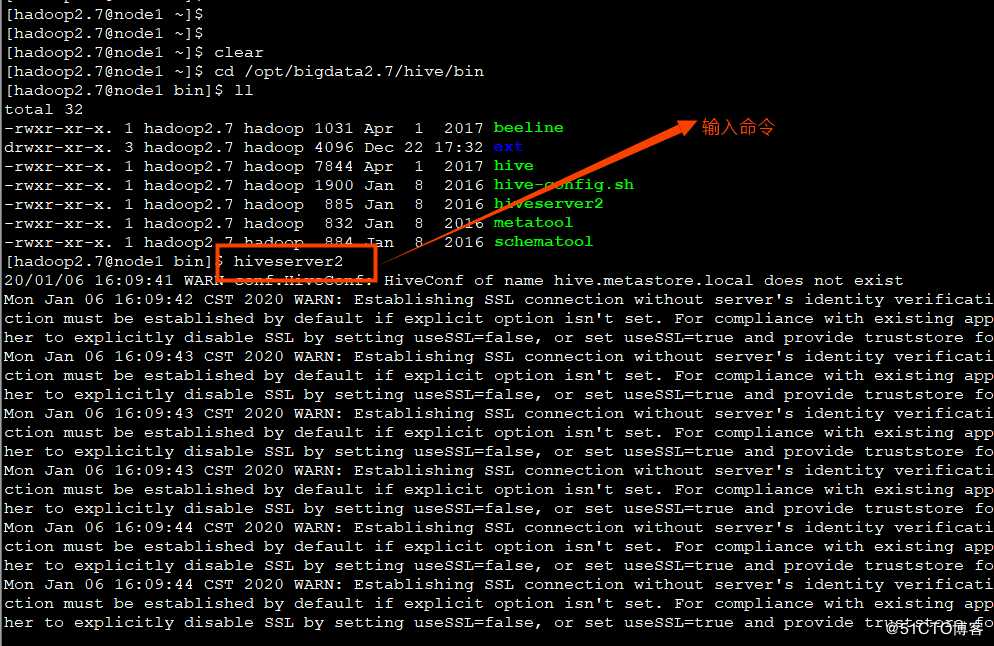
输入netstat –nlp命令查看: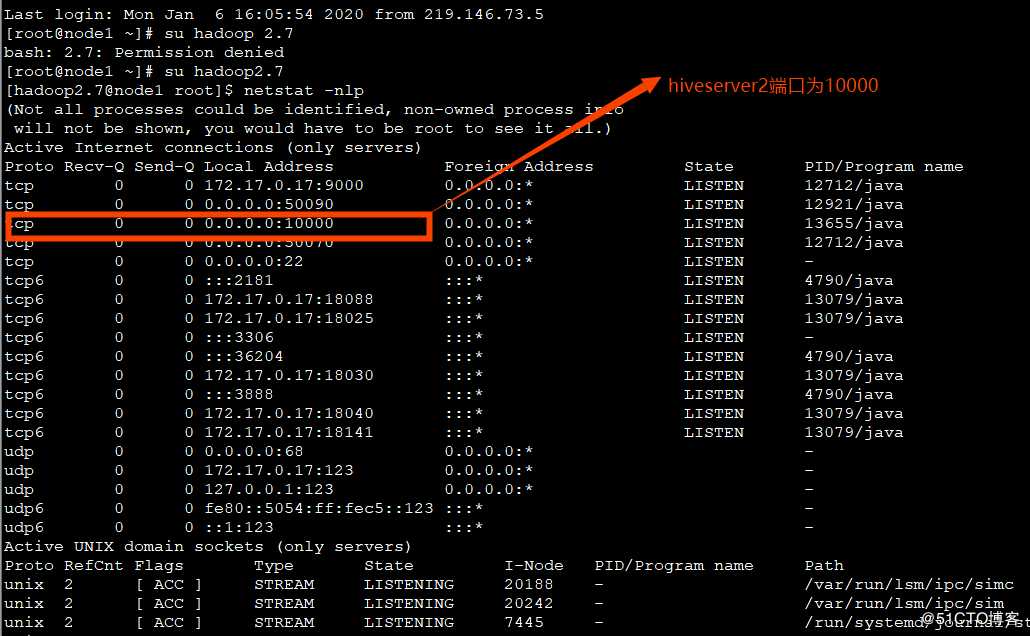
? 运行hiveserver2相当于开启了一个服务端,端口号10000,需要开启一个客户端进行通信,所以打开另一个窗口,输入命令beeline.
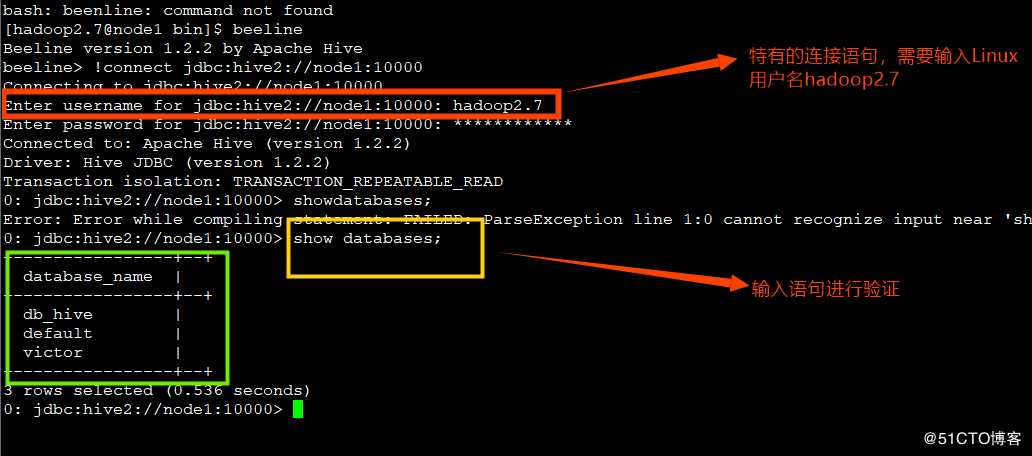
Beeline连接方式:!connect jdbc:hive2://node1:10000
主意不要省略!
当然了hiveserver2服务端可以运行在后台:
nohup hiveserver2 &3、 Hive数据类型
3.1基本数据类型
| 类型名称 | 描述 | 举例 |
|---|---|---|
| boolean | True/false | True |
| tinyint | 1字节的有符号整数 | 1 |
| Smallint | 2字节的有符号整数 | 1 |
| int | 4字节的有符号整数 | 1 |
| Bigint | 8字节的有符号整数 | 1 |
| Float | 4字节精度浮点数 | 1.0 |
| Double | 8字节精度浮点数 | 1.0 |
| String | 字符串(不设长度) | “adcadfaf” |
| Varchar | 字符串(1-65355) | “adfafdafaf” |
| Timestamp | 时间戳 | 123454566 |
| date | 日期 | 20160202 |
3.2复合数据类型
| 类型名称 | 描述 | 举例 |
|---|---|---|
| Array | 一组有序的字段,字段类型必须相同的array(元素1,元素2) | Array(1,2,4) |
| Map | 一组无序的键值对map(k1,v1,k2,v2) | Map(‘a’,1,’b’,2) |
| Struct | 一组命名的字段,字段类型可以不同struct(元素1,元素2) | Struct(‘a’,1,2,0) |
? (1)Array字段的元素访问方式:下标获取元素,下标从0开始
比如:获取第一元素:array[0]
(2)Map字段的访问方式:通过键获取值
比如:获取a这个key对应的value:map[‘a’]
(3)struct字段的元素获取方式:
定义一个字段c的类型为struct(a int;b string)
获取a和b的值:
create table complex(
col1 array<int>,
col2 map<string,int>,
col3 struct<a:string,b:int,c:double>
)4、 Hive数据类型转换
4.1、隐式类型转换
? 系统自动实现类型转换,不需要客户干预
如:tinyint可以转换成int,int可以转成bigint
所有整数类型、float、string类型都可以隐式转转换成double
tinyint、samllint、int都可以转成float
boolean不可以转成其他任何类型
4.2、手动类型转换
? 可以使用cast函数显示的进行数据类型转换
? 例如:cast(‘1’ as int)把字符串’1’转成整数1
? 如果强制转换类型失败,如执行cast(‘x’ as int)表达式返回NULL。
以上是关于hive架构和原理以及与传统数据库的区别的主要内容,如果未能解决你的问题,请参考以下文章