分布式事务详解
Posted 林在闪闪发光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式事务详解相关的知识,希望对你有一定的参考价值。

🏆今日学习目标:
🍀分布式事务详解
✅创作者:林在闪闪发光
⏰预计时间:30分钟
🎉个人主页:林在闪闪发光的个人主页🍁林在闪闪发光的个人社区,欢迎你的加入: 林在闪闪发光的社区
目录
所有的愤怒,基本上都源自于没钱;所有的励志,基本上目标都是挣钱;所有的幸福,基本上状态都是有钱。
分布式事务概要
分布式事务:在分布式系统中一次操作需要由多个服务协同完成,这种由不同的服务之间通过网络协同完成的事务称为分布式事务
在微服务架构盛行的情况下,在分布式的多个服务中保证业务的一致性,即分布式事务就显得尤为重要。本文将讲述分布式事务及其解决方案,有XA协议、TCC和Saga事务模型、本地消息表、事务消息和阿里开源的Seata。
聊什么是分布式事务前,先聊一下我们熟悉的单机事务。所谓单机事务是相对分布式事务来说的,即数据库事务。大家都知道数据库事务有ACID这四个特性:
-
A(Atomicity):指单个事务中的操作要不都执行,要不都不执行
-
C(Consistency):指事务前后数据的完整性必须保持一致
-
I(Isolation):指多个事务对数据可见性的规则
-
D(Durability):指事务提交后,就会被永久存储下来
既然数据库事务有这四个特性的,那么分布式事务也不例外,应该具备这四个特性。
在微服务架构下,服务之间通过RPC远程调用,相对单机事务来说,多了“网络通信”这一不确定因素,使得本来服务的调用只有“成功”和“失败”这两种返回结果,变为“成功”、“失败”和“未知”三种返回结果。系统之间的通信可靠性从单一系统中的可靠变成了微服务架构之间的不可靠,分布式事务其实就是在不可靠的通信下实现事务的特性。一般因为网络导致的异常可能有机器宕机、网络异常、消息丢失、消息乱序、数据错误、不可靠的TCP、存储数据丢失、其他异常等等。
分布式事务详解
一、2PC:
2PC,两阶段提交,将事务的提交过程分为资源准备和资源提交两个阶段,并且由事务协调者来协调所有事务参与者,如果准备阶段所有事务参与者都预留资源成功,则进行第二阶段的资源提交,否则事务协调者回滚资源。
1、第一阶段:准备阶段
由事务协调者询问通知各个事务参与者,是否准备好了执行事务,具体流程图如下:

- ① 协调者向所有参与者发送事务内容,询问是否可以提交事务,并等待答复
- ② 各参与者执行本地事务操作,将 undo 和 redo 信息记入事务日志中(但不提交事务)
- ③ 如参与者执行成功,给协调者反馈同意,否则反馈中止,表示事务不可以执行
2、第二阶段:提交阶段
协调者收到各个参与者的准备消息后,根据反馈情况通知各个参与者commit提交或者rollback回滚
(1)事务提交:
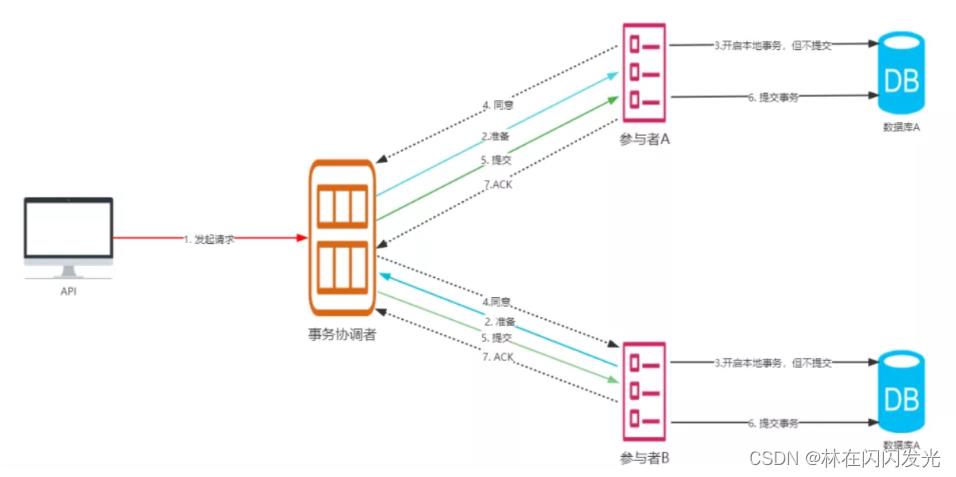
当第一阶段所有参与者都反馈同意时,协调者发起正式提交事务的请求,当所有参与者都回复同意时,则意味着完成事务,具体流程如下:
- ① 协调者节点向所有参与者节点发出正式提交的 commit 请求。
- ② 收到协调者的 commit 请求后,参与者正式执行事务提交操作,并释放在整个事务期间内占用的资源。
- ③ 参与者完成事务提交后,向协调者节点发送ACK消息。
- ④ 协调者节点收到所有参与者节点反馈的ACK消息后,完成事务。
所以,正常提交时,事务的完整流程图如下:
(2)事务回滚:
如果任意一个参与者节点在第一阶段返回的消息为中止,或者协调者节点在第一阶段的询问超时之前无法获取所有参与者节点的响应消息时,那么这个事务将会被回滚,具体流程如下:
- ① 协调者向所有参与者发出 rollback 回滚操作的请求
- ② 参与者利用阶段一写入的undo信息执行回滚,并释放在整个事务期间内占用的资源
- ③ 参与者在完成事务回滚之后,向协调者发送回滚完成的ACK消息
- ④ 协调者收到所有参与者反馈的ACK消息后,取消事务
所以,事务回滚时,完整流程图如下:

3、2PC的缺点:
二阶段提交确实能够提供原子性的操作,但是不幸的是,二阶段提交还是有几个缺点的:
(1)性能问题:执行过程中,所有参与节点都是事务阻塞性的,当参与者占有公共资源时,其他第三方节点访问公共资源就不得不处于阻塞状态,为了数据的一致性而牺牲了可用性,对性能影响较大,不适合高并发高性能场景
(2)可靠性问题:2PC非常依赖协调者,当协调者发生故障时,尤其是第二阶段,那么所有的参与者就会都处于锁定事务资源的状态中,而无法继续完成事务操作(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与者处于阻塞状态的问题)
(3)数据一致性问题:在阶段二中,当协调者向参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求过程中协调者发生了故障,这回导致只有一部分参与者接受到了commit请求。而在这部分参与者接到commit请求之后就会执行commit操作。但是其他部分未接到commit请求的机器则无法执行事务提交。于是整个分布式系统便出现了数据部一致性的现象。
(4)二阶段无法解决的问题:协调者在发出 commit 消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了,那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。
二、3PC:
3PC,三阶段提交协议,是二阶段提交协议的改进版本,三阶段提交有两个改动点:
- (1)在协调者和参与者中都引入超时机制
- (2)在第一阶段和第二阶段中插入一个准备阶段,保证了在最后提交阶段之前各参与节点的状态是一致的。
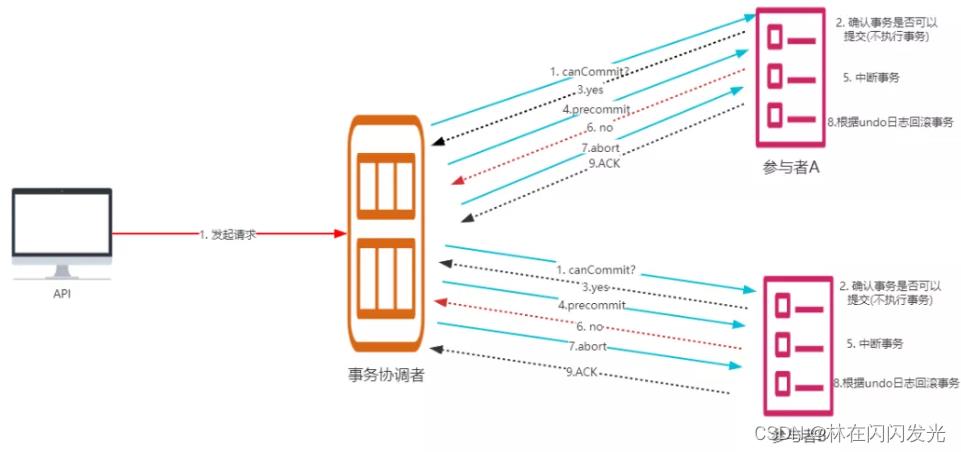
所以3PC会分为3个阶段,CanCommit 准备阶段、PreCommit 预提交阶段、DoCommit 提交阶段,处理流程如下:
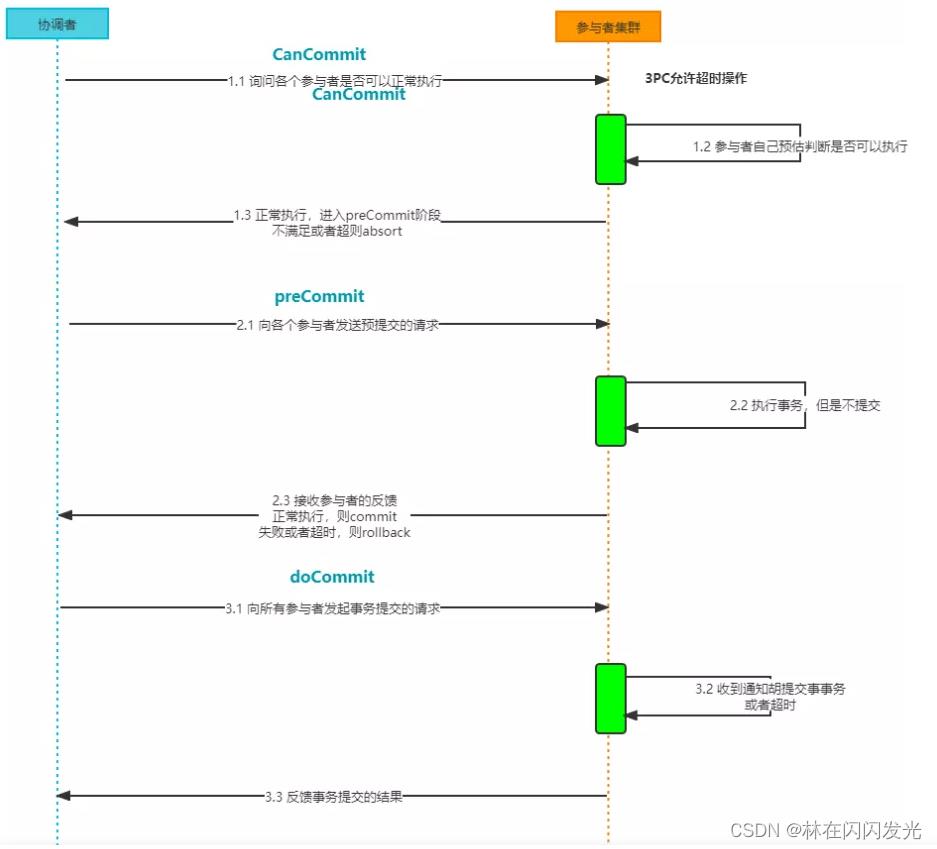
1、阶段一:CanCommit 准备阶段
协调者向参与者发送 canCommit 请求,参与者如果可以提交就返回Yes响应,否则返回No响应,具体流程如下:
- (1)事务询问:协调者向所有参与者发出包含事务内容的 canCommit 请求,询问是否可以提交事务,并等待所有参与者答复。
- (2)响应反馈:参与者收到 canCommit 请求后,如果认为可以执行事务操作,则反馈 yes 并进入预备状态,否则反馈 no。
2、阶段二:PreCommit 阶段
协调者根据参与者的反应情况来决定是否可以进行事务的 PreCommit 操作。根据响应情况,有以下两种可能:
(1)执行事务:
假如所有参与者均反馈 yes,协调者预执行事务,具体如下:
- ① 发送预提交请求:协调者向参与者发送 PreCommit 请求,并进入准备阶段
- ② 事务预提交 :参与者接收到 PreCommit 请求后,会执行本地事务操作,并将 undo 和 redo 信息记录到事务日志中(但不提交事务)
- ③ 响应反馈 :如果参与者成功的执行了事务操作,则返回ACK响应,同时开始等待最终指令。

(2)中断事务:
假如有任何一个参与者向协调者发送了No响应,或者等待超时之后,协调者都没有接到参与者的响应,那么就执行事务的中断,流程如下:
- ① 发送中断请求 :协调者向所有参与者发送 abort 请求。
- ② 中断事务 :参与者收到来自协调者的 abort 请求之后(或超时之后,仍未收到协调者的请求),执行事务的中断。
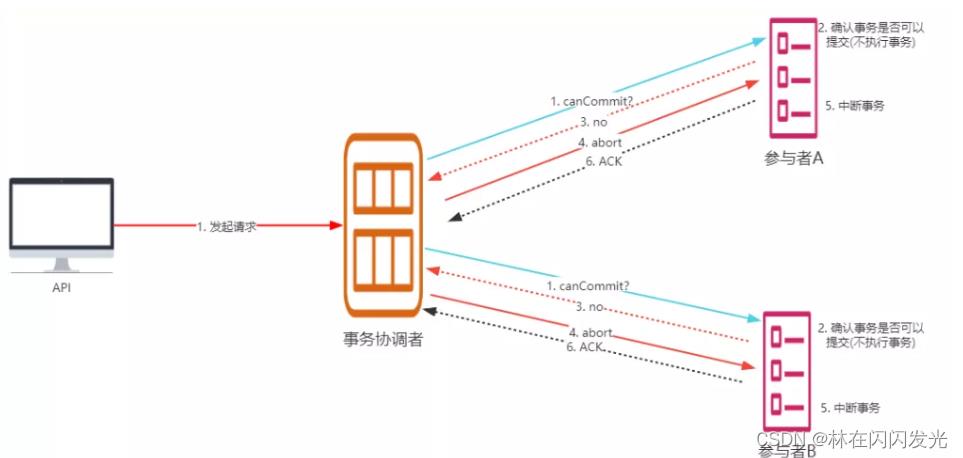
3、阶段三:doCommit阶段
该阶段进行真正的事务提交,也可以分为以下两种情况:
(1)提交事务:
- ① 发送提交请求:协调接收到所有参与者发送的ACK响应,那么他将从预提交状态进入到提交状态,并向所有参与者发送 doCommit 请求
- ② 本地事务提交:参与者接收到doCommit请求之后,执行正式的事务提交,并在完成事务提交之后释放所有事务资源
- ③ 响应反馈:事务提交完之后,向协调者发送ack响应。
- ④ 完成事务:协调者接收到所有参与者的ack响应之后,完成事务。
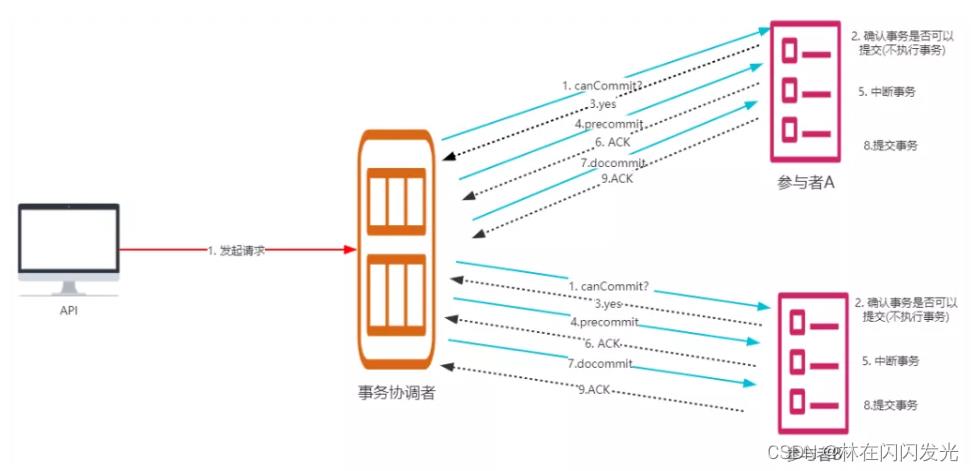
(2)中断事务:任何一个参与者反馈 no,或者等待超时后协调者尚无法收到所有参与者的反馈,即中断事务
- ① 发送中断请求:如果协调者处于工作状态,向所有参与者发出 abort 请求
- ② 事务回滚:参与者接收到abort请求之后,利用其在阶段二记录的undo信息来执行事务的回滚操作,并在完成回滚之后释放所有的事务资源。
- ③ 反馈结果:参与者完成事务回滚之后,向协调者反馈ACK消息
- ④ 中断事务:协调者接收到参与者反馈的ACK消息之后,执行事务的中断。
4、3PC的优缺点:
与2PC相比,3PC降低了阻塞范围,并且在等待超时后,协调者或参与者会中断事务,避免了协调者单点问题,阶段三中协调者出现问题时,参与者会继续提交事务。
数据不一致问题依然存在,当在参与者收到 preCommit 请求后等待 doCommit 指令时,此时如果协调者请求中断事务,而协调者因为网络问题无法与参与者正常通信,会导致参与者继续提交事务,造成数据不一致。
2PC和3PC都无法保证数据绝对的一致性,一般为了预防这种问题,可以添加一个报警,比如监控到事务异常的时候,通过脚本自动补偿差异的信息。
三、TCC:
1、什么是TCC:
TCC(Try Confirm Cancel)是应用层的两阶段提交,所以对代码的侵入性强,其核心思想是:针对每个操作,都要实现对应的确认和补偿操作,也就是业务逻辑的每个分支都需要实现 try、confirm、cancel 三个操作,第一阶段由业务代码编排来调用Try接口进行资源预留,当所有参与者的 Try 接口都成功了,事务协调者提交事务,并调用参与者的 confirm 接口真正提交业务操作,否则调用每个参与者的 cancel 接口回滚事务,并且由于 confirm 或者 cancel 有可能会重试,因此对应的部分需要支持幂等。
2、TCC的执行流程:
TCC的执行流程可以分为两个阶段,分别如下:
(1)第一阶段:Try,业务系统做检测并预留资源 (加锁,锁住资源),比如常见的下单,在try阶段,我们不是真正的减库存,而是把下单的库存给锁定住。
(2)第二阶段:根据第一阶段的结果决定是执行confirm还是cancel
- Confirm:执行真正的业务(执行业务,释放锁)
- Cancle:是对Try阶段预留资源的释放(出问题,释放锁)
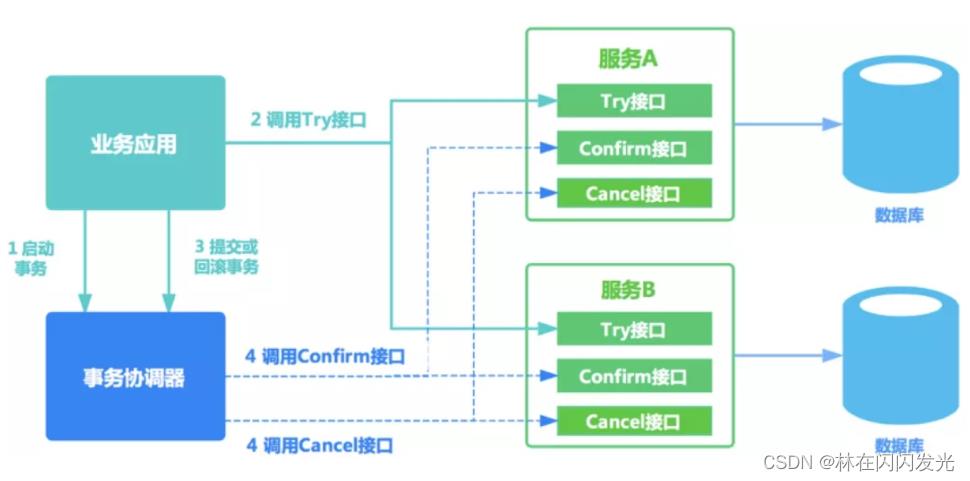
3、TCC如何保证最终一致性:
- TCC 事务机制以 Try 为中心的,Confirm 确认操作和 Cancel 取消操作都是围绕 Try 而展开。因此,Try 阶段中的操作,其保障性是最好的,即使失败,仍然有 Cancel 取消操作可以将其执行结果撤销。
- Try阶段执行成功并开始执行 Confirm 阶段时,默认 Confirm 阶段是不会出错的,也就是说只要 Try 成功,Confirm 一定成功(TCC设计之初的定义)
- Confirm 与 Cancel 如果失败,由TCC框架进行重试补偿
- 存在极低概率在CC环节彻底失败,则需要定时任务或人工介入
4、TCC的注意事项:
(1)允许空回滚:
空回滚出现的原因是 Try 超时或者丢包,导致 TCC 分布式事务二阶段的 回滚,触发 Cancel 操作,此时事务参与者未收到Try,但是却收到了Cancel 请求,如下图所示:
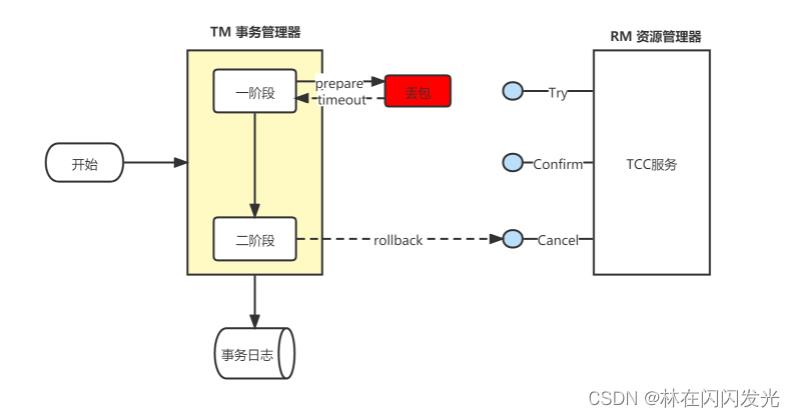
所以 cancel 接口在实现时需要允许空回滚,也就是 Cancel 执行时如果发现没有对应的事务 xid 或主键时,需要返回回滚成功,让事务服务管理器认为已回滚。
(2)防悬挂控制:
悬挂指的是二阶段的 Cancel 比 一阶段的Try 操作先执行,出现该问题的原因是 Try 由于网络拥堵而超时,导致事务管理器生成回滚,触发 Cancel 接口,但之后拥堵在网络的 Try 操作又被资源管理器收到了,但是 Cancel 比 Try 先到。但按照前面允许空回滚的逻辑,回滚会返回成功,事务管理器认为事务已回滚成功,所以此时应该拒绝执行空回滚之后到来的 Try 操作,否则会产生数据不一致。因此我们可以在 Cancel 空回滚返回成功之前,先记录该条事务 xid 或业务主键,标识这条记录已经回滚过,Try 接口执行前先检查这条事务xid或业务主键是否已经标记为回滚成功,如果是则不执行 Try 的业务操作。

(3)幂等控制:
由于网络原因或者重试操作都有可能导致 Try - Confirm - Cancel 3个操作的重复执行,所以使用 TCC 时需要注意这三个操作的幂等控制,通常我们可以使用事务 xid 或业务主键判重来控制。
5、TCC方案的优缺点:
(1)TCC 事务机制相比于上面介绍的 XA 事务机制,有以下优点:
- 性能提升:具体业务来实现,控制资源锁的粒度变小,不会锁定整个资源。
- 数据最终一致性:基于 Confirm 和 Cancel 的幂等性,保证事务最终完成确认或者取消,保证数据的一致性。
- 可靠性:解决了 XA 协议的协调者单点故障问题,由主业务方发起并控制整个业务活动,业务活动管理器也变成多点,引入集群。
(2)缺点:TCC 的 Try、Confirm 和 Cancel 操作功能要按具体业务来实现,业务耦合度较高,提高了开发成本。
四、Saga事务:
1、什么是Saga事务:
Saga 事务核心思想是将长事务拆分为多个本地短事务并依次正常提交,如果所有短事务均执行成功,那么分布式事务提交;如果出现某个参与者执行本地事务失败,则由 Saga 事务协调器协调根据相反顺序调用补偿操作,回滚已提交的参与者,使分布式事务回到最初始的状态。Saga 事务基本协议如下:
- (1)每个 Saga 事务由一系列幂等的有序子事务(sub-transaction) Ti 组成。
- (2)每个 Ti 都有对应的幂等补偿动作 Ci,补偿动作用于撤销 Ti 造成的结果。
与TCC事务补偿机制相比,TCC有一个预留(Try)动作,相当于先报存一个草稿,然后才提交;Saga事务没有预留动作,直接提交。
2、Saga的恢复策略:
对于事务异常,Saga提供了两种恢复策略,分别如下:
(1)向后恢复(backward recovery):
当执行事务失败时,补偿所有已完成的事务,是“一退到底”的方式,这种做法的效果是撤销掉之前所有成功的子事务,使得整个 Saga 的执行结果撤销。如下图:

从上图可知事务执行到了支付事务T3,但是失败了,因此事务回滚需要从C3,C2,C1依次进行回滚补偿,对应的执行顺序为:T1,T2,T3,C3,C2,C1。
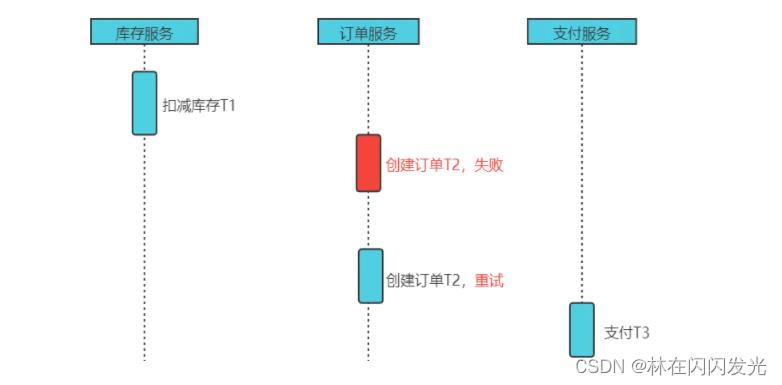
(2)向前恢复(forward recovery):
对于执行不通过的事务,会尝试重试事务,这里有一个假设就是每个子事务最终都会成功,这种方式适用于必须要成功的场景,事务失败了重试,不需要补偿。流程如下图:
3、Saga事务的实现方式:
Saga事务有两种不同的实现方式,分别如下:
- 命令协调(Order Orchestrator)
- 事件编排(Event Choreographyo)
(1)命令协调:
中央协调器(Orchestrator,简称 OSO)以命令/回复的方式与每项服务进行通信,全权负责告诉每个参与者该做什么以及什么时候该做什么。整体流程如下图:
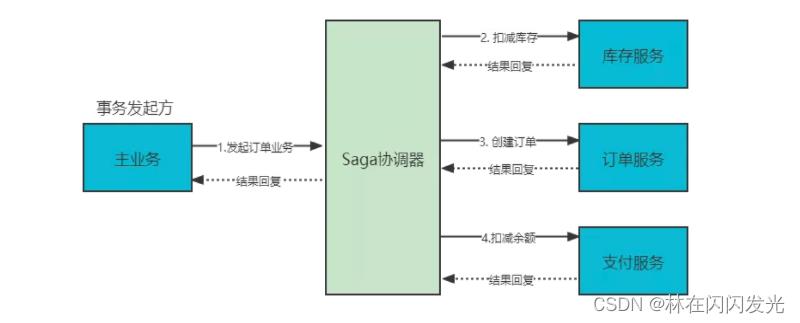
- ① 事务发起方的主业务逻辑请求 OSO 服务开启订单事务
- ② OSO 向库存服务请求扣减库存,库存服务回复处理结果。
- ③ OSO 向订单服务请求创建订单,订单服务回复创建结果。
- ④ OSO 向支付服务请求支付,支付服务回复处理结果。
- ⑤ 主业务逻辑接收并处理 OSO 事务处理结果回复。
中央协调器 OSO 必须事先知道执行整个事务所需的流程,如果有任何失败,它还负责通过向每个参与者发送命令来撤销之前的操作来协调分布式的回滚,基于中央协调器协调一切时,回滚要容易得多,因为协调器默认是执行正向流程,回滚时只要执行反向流程即可。
(2)事件编排:
命令协调方式基于中央协调器实现,所以有单点风险,但是事件编排方式没有中央协调器。事件编排的实现方式中,每个服务产生自己的时间并监听其他服务的事件来决定是否应采取行动。
在事件编排方法中,第一个服务执行一个事务,然后发布一个事件,该事件被一个或多个服务进行监听,这些服务再执行本地事务并发布(或不发布)新的事件。当最后一个服务执行本地事务并且不发布任何事件时,意味着分布式事务结束,或者它发布的事件没有被任何 Saga 参与者听到都意味着事务结束。

- ① 事务发起方的主业务逻辑发布开始订单事件。
- ② 库存服务监听开始订单事件,扣减库存,并发布库存已扣减事件。
- ③ 订单服务监听库存已扣减事件,创建订单,并发布订单已创建事件。
- ④ 支付服务监听订单已创建事件,进行支付,并发布订单已支付事件。
- ⑤ 主业务逻辑监听订单已支付事件并处理。
如果事务涉及 2 至 4 个步骤,则非常合适使用事件编排方式,它是实现 Saga 模式的自然方式,它很简单,容易理解,不需要太多的代码来构建。
4、Saga事务的优缺点:
(1)命令协调设计的优缺点:
① 优点:
- 服务之间关系简单,避免服务间循环依赖,因为 Saga 协调器会调用 Saga 参与者,但参与者不会调用协调器。
- 程序开发简单,只需要执行命令/回复(其实回复消息也是一种事件消息),降低参与者的复杂性。
- 易维护扩展,在添加新步骤时,事务复杂性保持线性,回滚更容易管理,更容易实施和测试。
② 缺点:
- 中央协调器处理逻辑容易变得庞大复杂,导致难以维护。
- 存在协调器单点故障风险。
(2)事件编排设计的优缺点:
① 优点:
- 避免中央协调器单点故障风险。
- 当涉及的步骤较少服务开发简单,容易实现。
② 缺点:
- 服务之间存在循环依赖的风险。
- 当涉及的步骤较多,服务间关系混乱,难以追踪调测。
由于 Saga 模型没有 Prepare 阶段,因此事务间不能保证隔离性。当多个 Saga 事务操作同一资源时,就会产生更新丢失、脏数据读取等问题,这时需要在业务层控制并发,例如:在应用层面加锁,或者应用层面预先冻结资源。
五、本地消息表:
1、什么是本地消息表:
本地消息表的核心思路就是将分布式事务拆分成本地事务进行处理,在该方案中主要有两种角色:事务主动方和事务被动方。事务主动发起方需要额外新建事务消息表,并在本地事务中完成业务处理和记录事务消息,并轮询事务消息表的数据发送事务消息,事务被动方基于消息中间件消费事务消息表中的事务。
这样可以避免以下两种情况导致的数据不一致性:
- 业务处理成功、事务消息发送失败
- 业务处理失败、事务消息发送成功
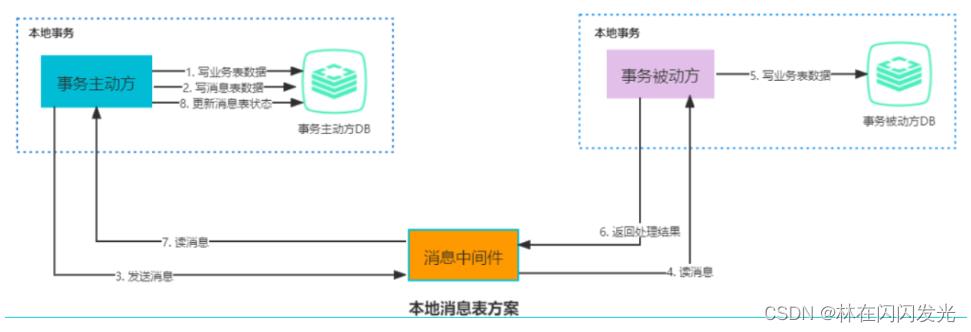
- ① 事务主动方在同一个本地事务中处理业务和写消息表操作
- ② 事务主动方通过消息中间件,通知事务被动方处理事务消息。消息中间件可以基于 Kafka、RocketMQ 消息队列,事务主动方主动写消息到消息队列,事务消费方消费并处理消息队列中的消息。
- ③ 事务被动方通过消息中间件,通知事务主动方事务已处理的消息。
- ④ 事务主动方接收中间件的消息,更新消息表的状态为已处理。
一些必要的容错处理如下:
- 当①处理出错,由于还在事务主动方的本地事务中,直接回滚即可
- 当②、③处理出错,由于事务主动方本地保存了消息,只需要轮询消息重新通过消息中间件发送,通知事务被动方重新读取消息处理业务即可。
- 如果是业务上处理失败,事务被动方可以发消息给事务主动方回滚事务
- 如果事务被动方已经消费了消息,事务主动方需要回滚事务的话,需要发消息通知事务主动方进行回滚事务。
3、本地消息表的优缺点:
(1)优点:
- 从应用设计开发的角度实现了消息数据的可靠性,消息数据的可靠性不依赖于消息中间件,弱化了对 MQ 中间件特性的依赖。
- 方案轻量,容易实现。
(2)缺点:
- 与具体的业务场景绑定,耦合性强,不可公用
- 消息数据与业务数据同库,占用业务系统资源
- 业务系统在使用关系型数据库的情况下,消息服务性能会受到关系型数据库并发性能的局限
六、MQ事务消息:
1、MQ事务消息的执行流程:
基于MQ的分布式事务方案本质上是对本地消息表的封装,整体流程与本地消息表一致,唯一不同的就是将本地消息表存在了MQ内部,而不是业务数据库中,如下图:

由于将本地消息表存在了MQ内部,那么MQ内部的处理尤为重要,下面主要基于 RocketMQ4.3 之后的版本介绍 MQ 的分布式事务方案
2、RocketMQ事务消息:
在本地消息表方案中,保证事务主动方发写业务表数据和写消息表数据的一致性是基于数据库事务,而 RocketMQ 的事务消息相对于普通 MQ提供了 2PC 的提交接口,方案如下:

(1)正常情况:
在事务主动方服务正常,没有发生故障的情况下,发消息流程如下:
- 步骤①:发送方向 MQ Server(MQ服务方)发送 half 消息
- 步骤②:MQ Server 将消息持久化成功之后,向发送方 ack 确认消息已经发送成功
- 步骤③:发送方开始执行本地事务逻辑
- 步骤④:发送方根据本地事务执行结果向 MQ Server 提交二次确认(commit 或是 rollback)。
- 最终步骤:MQ Server 如果收到的是 commit 操作,则将半消息标记为可投递,MQ订阅方最终将收到该消息;若收到的是 rollback 操作则删除 half 半消息,订阅方将不会接受该消息
(2)异常情况:
在断网或者应用重启等异常情况下,图中的步骤④提交的二次确认超时未到达 MQ Server,此时的处理逻辑如下:
- 步骤⑤:MQ Server 对该消息发起消息回查
- 步骤⑥:发送方收到消息回查后,需要检查对应消息的本地事务执行的最终结果
- 步骤⑦:发送方根据检查得到的本地事务的最终状态再次提交二次确认。
- 最终步骤:MQ Server基于 commit/rollback 对消息进行投递或者删除。
3、MQ事务消息的优缺点:
(1)优点:相比本地消息表方案,MQ 事务方案优点是:
- 消息数据独立存储 ,降低业务系统与消息系统之间的耦合
- 吞吐量大于使用本地消息表方案
(2)缺点:
- 一次消息发送需要两次网络请求(half 消息 + commit/rollback 消息) 。
- 业务处理服务需要实现消息状态回查接口。
七、最大努力通知:
最大努力通知也称为定期校对,是对MQ事务方案的进一步优化。它在事务主动方增加了消息校对的接口,如果事务被动方没有接收到主动方发送的消息,此时可以调用事务主动方提供的消息校对的接口主动获取
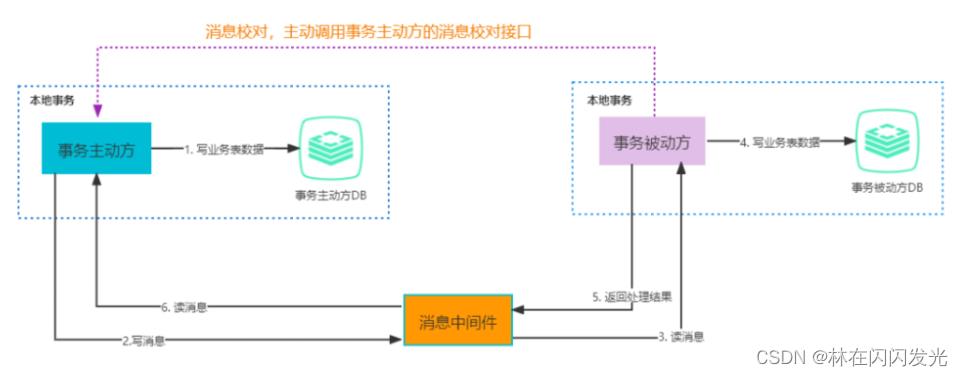
在可靠消息事务中,事务主动方需要将消息发送出去,并且让接收方成功接收消息,这种可靠性发送是由事务主动方保证的;但是最大努力通知,事务主动方仅仅是尽最大努力(重试,轮询....)将事务发送给事务接收方,所以存在事务被动方接收不到消息的情况,此时需要事务被动方主动调用事务主动方的消息校对接口查询业务消息并消费,这种通知的可靠性是由事务被动方保证的。
所以最大努力通知适用于业务通知类型,例如微信交易的结果,就是通过最大努力通知方式通知各个商户,既有回调通知,也有交易查询接口。
八、各方案常见使用场景总结:
- 2PC/3PC:依赖于数据库,能够很好的提供强一致性和强事务性,但延迟比较高,比较适合传统的单体应用,在同一个方法中存在跨库操作的情况,不适合高并发和高性能要求的场景。
- TCC:适用于执行时间确定且较短,实时性要求高,对数据一致性要求高,比如互联网金融企业最核心的三个服务:交易、支付、账务。
- 本地消息表/MQ 事务:适用于事务中参与方支持操作幂等,对一致性要求不高,业务上能容忍数据不一致到一个人工检查周期,事务涉及的参与方、参与环节较少,业务上有对账/校验系统兜底。
- Saga 事务:由于 Saga 事务不能保证隔离性,需要在业务层控制并发,适合于业务场景事务并发操作同一资源较少的情况。Saga 由于缺少预提交动作,导致补偿动作的实现比较麻烦,例如业务是发送短信,补偿动作则得再发送一次短信说明撤销,用户体验比较差。所以,Saga 事务较适用于补偿动作容易处理的场景

ShardingShpere分库分表5-ShardingSphere分布式事务详解
文章目录
一、ShardingJDBC分布式事务快速上手
ShardingJDBC支持的分布式事务方式有三种 LOCAL, XA , BASE,这三种事务实现方式都是采用的对代码无侵入的方式实现的。具体见 TransactionTypeHolder.set(TransactionType.XA);
这里设置的TransactionType实际上是一个ThreadLocal的线程变量,只真对当前线程有效。并且通常用完之后都要使用TransactionTypeHolder.clear()将设置清除,以免影响线程内其他操作。
LOCAL本地事务
本地事务方式也就是使用Spring的@Transaction注解来进行配置。传统的本地事务是不具备分布式事务特性的,但是ShardingSphere对本地事务进行了增强。在ShardingSphere中,LOCAL本地事务已经完全支持由于逻辑异常导致的分布式事务问题。不过这种本地事务模式IBU支持因网络、硬件导致的跨库事务。例如同一个事务中,跨两个库更新,更新完毕后,提交之前,第一个库宕机了,则只有第二个库数据提交。
XA事务快速上手
这种模式下,是由ShardingJDBC所在的应用来作为事务协调者,通过XA方式来协调分布到多个数据库中的分库分表语句的分布式事务。
在ShardingJDBC的官方文档中,有对分布式事务的几个示例,可以用来参考下:
https://shardingsphere.apache.org/document/legacy/4.x/document/cn/manual/sharding-jdbc/usage/transaction/
简单来说,在SpringBoot中分为以下几个步骤:
1、引入maven依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>$sharding-sphere.version</version>
</dependency>
<!-- 使用XA事务时,需要引入此模块 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-transaction-xa-core</artifactId>
<version>$shardingsphere.version</version>
</dependency>
<!-- 使用XA事务时,可以引入其他几种事务管理器 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-transaction-xa-bitronix</artifactId>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-transaction-xa-narayana</artifactId>
</dependency>
XA是一种分布式事务规范,与之对应的是JAVA平台上的事务规范JTA(Java Transaction Api)。JTA定义了对XA事务的支持,实际上,JTA就是基于XA构建的。但是JTA只是相当于一组结构,定义了分布式事务的处理方式,具体实现还是需要由各个厂商提供。
目前JTA有两种实现方式,一种是由特定的J2EE容器提供,例如这里提到的 narayana 就是由JBOSS提供的。另一种就是适用于所有J2EE的通用规范,例如Atomokios,他是ShardingSphere默认使用的事务管理器。
2、配置事务管理器
@Configuration
@EnableTransactionManagement
public class TransactionConfiguration
@Bean
public PlatformTransactionManager txManager(final DataSource dataSource)
return new DataSourceTransactionManager(dataSource);
//如果不使用jdbctemplate就可以不注入。
@Bean
public JdbcTemplate jdbcTemplate(final DataSource dataSource)
return new JdbcTemplate(dataSource);
使用分布式事务管理器的重点是两个地方,一是配置@EnableTransactionManagement注解,启用事务管理;二是注入TransactionManager对象,其中对于这个事务管理器的重点就是要使用ShardingDatasource。
3、在业务代码中使用
@Transactional
@ShardingTransactionType(TransactionType.XA) // 支持TransactionType.LOCAL, TransactionType.XA, TransactionType.BASE
public void insert()
jdbcTemplate.execute("INSERT INTO t_order (user_id, status) VALUES (?, ?)", (PreparedStatementCallback<Object>) preparedStatement ->
preparedStatement.setObject(1, i);
preparedStatement.setObject(2, "init");
preparedStatement.executeUpdate();
);
使用时的重点是在@ShardingTransactionType注解中声明XA类型的事务。
ShardingSphere默认是使用的Atomikos作为XA事务管理器,在项目中会生成一个xa_tx.log,这个是XA崩溃恢复所需的日志,不要删除。另外,可以在项目的classpath中添加jta.properties来定制Atomikos的配置项。具体配置项参见 https://www.atomikos.com/Documentation/JtaProperties 。
测试案例
我们可以使用第二节中的application01.properties案例来进行简单的测试。 在application01.properties中,配置了逻辑表course的两个实际表course_1和course_2。当执行下面的测试案例时,会将两种表的user_id都一起进行更新。
@Test
public void updateCourse()
Course c = new Course();
UpdateWrapper<Course> wrapper = new UpdateWrapper<>();
wrapper.set("user_id","5");
courseMapper.update(c,wrapper);
现在手动给course_2表添加一个user_id字段的唯一索引。这样,再执行这个测试案例时,对于course_2分片的数据就会更新失败。这时我们可以来观察course_1分片的数据,有没有随着整个事务一起回滚。这时要注意给这个测试单元加上事务的注解。
@Test
@Transactional
@ShardingTransactionType(TransactionType.XA)
public void updateCourse()
Course c = new Course();
UpdateWrapper<Course> wrapper = new UpdateWrapper<>();
wrapper.set("user_id","6");
courseMapper.update(c,wrapper);
BASE柔性事务快速上手
这种模式,是由Seata作为事务协调者,来进行协调。使用方式需要先部署seata服务。官方建议是使用seata配合nacos作为配置中心来使用。实际上是使用的seata的AT模式进行两阶段提交。
seata部署方式:
nacos: 下载压缩包,解压执行bin目录下的startup指令即可。Demo中是使用的1.4.1版本
--以独立方式启动
sh startup.sh -m standalone
seata:同样是下载发布包,并解压。Demo中使用1.4.0版本
然后往nacos上初始化配置,这个脚本会在nacos上注册一组 Group=SEATA_GROUP 的配置项。
sh nacos-config.sh localhost
seata 1.4.0版本中已经没有这个脚本了,所有需要到老版本中去找。
这个脚本会将conf目录下的config.txt里的配置信息全部推送到目标Nacos上。 这个配置挺多的,有八九十个,而且很容易出错,要非常小心。
接下来修改seata-Server的解压目录下的conf/registry.conf文件,配置seata的注册中心。
registry
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
loadBalance = "RandomLoadBalance"
loadBalanceVirtualNodes = 10
nacos
application = "seata-server"
serverAddr = "192.168.65.232:8848"
namespace = "public"
group = "SEATA_GROUP"
cluster = "default"
#username = "nacos"
#password = "nacos"
config
# file、nacos 、apollo、zk、consul、etcd3
type = "nacos"
nacos
application = "seata-server"
serverAddr = "192.168.65.232:8848"
namespace = "29ccf18e-e559-4a01-b5d4-61bad4a89ffd"
group = "SEATA_GROUP"
cluster = "default"
username = "nacos"
password = "nacos"
这个配置里,是将seata的服务注册到nacos上,配置也从nacos上获取。registry部分对应seata注册到nacos上的服务。而config部分对应seata注册到nacos上的配置。但是配置信息是要另外手动上传到nacos中的。Seata中有专门的脚本辅助推送配置信息。
serverAddr、username、password分别为nacos的服务地址、用户名(默认nacos)、密码(默认nacos)。group(默认SEATA_GROUP)、namespac(默认public)这两个属性需要跟seata在nacos上的注册情况匹配。
这样就可以启动seata了。 启动成功后,可以在Nacos控制台上看到 服务名=serverAddr服务注册列表
sh seata-server.sh -p $LISTEN_PORT -m $STORE_MODE -h $IP(此参数可选)
其中 L I S T E N P O R T ∗ ∗ : S e a t a − S e r v e r 服 务 端 口 。 默 认 8848 ∗ ∗ LISTEN_PORT**: Seata-Server 服务端口。默认8848 ** LISTENPORT∗∗:Seata−Server服务端口。默认8848∗∗STORE_MODE: 事务操作记录存储模式:file、db。可以在registry.conf文件中配置。
$IP(可选参数): 用于多 IP 环境下指定 Seata-Server 注册服务的IP。单网卡不需要配置。
最后给nacos发送一个put请求,定制参数
curl -X PUT 'localhost:8848/nacos/v1/ns/operator/switches?entry=serverMode&value=AP'
客户端使用Base事务
使用BASE柔性事务需要引入maven依赖
<!-- 使用BASE事务时,需要引入此模块 -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-transaction-base-seata-at</artifactId>
<version>$sharding-sphere.version</version>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-all</artifactId>
<version>1.4.0</version>
</dependency>
<dependency>
<groupId>com.alibaba.nacos</groupId>
<artifactId>nacos-client</artifactId>
<version>1.4.1</version>
</dependency>
特别要注意seata的版本,必须与服务端匹配。 nacos版本与服务端不匹配的话,大部分情况下还不会有问题。但是如果seata的版本不匹配,那会出现很多莫名其妙的问题。
接下来,要使用Seata的AT模式,还需要在每个分片建立一个undo_log表
CREATE TABLE IF NOT EXISTS `undo_log`
(
`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT 'increment id',
`branch_id` BIGINT(20) NOT NULL COMMENT 'branch transaction id',
`xid` VARCHAR(100) NOT NULL COMMENT 'global transaction id',
`context` VARCHAR(128) NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` LONGBLOB NOT NULL COMMENT 'rollback info',
`log_status` INT(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` DATETIME NOT NULL COMMENT 'create datetime',
`log_modified` DATETIME NOT NULL COMMENT 'modify datetime',
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`, `branch_id`)
) ENGINE = InnoDB
AUTO_INCREMENT = 1
DEFAULT CHARSET = utf8 COMMENT ='AT transaction mode undo table';
接下来在classpath下增加seata.conf。ShardingSphere的SeataATShardingTransactionManager会读取这个配置文件。
client
application.id = example ## 应用唯一id
transaction.service.group = my_test_tx_group ## 所属事务组
注意配置时,application.id可以随意配置,但是transaction.service.group这个事务组不能随意配,需要在server端进行配置。对应 service.vgroupMapping.my_test_tx_group key =default 这个key中的后面一部分。
注意seata下的事务组配置: service.vgroupMapping.my_test_tx_group = default,其中这个my_test_tx_group 就是配置的事务组。这个事务组相当于是一个多租户的概念,不同的事务组之间的配置信息是隔离的。
然后后面的default对应的是Seata中的TC集群名。默认就是default。 而这个TC集群中有哪些服务节点是要另外配置的。 service.default.gouplist = 127.0.0.1:8091 这个配置中就配置了default这个集群中对应的节点列表。这些节点就会加入到同一个分布式事务中。
然后,还需要将服务端的registry.conf文件也复制到classpath目录下。也就是需要与服务端匹配。
最后使用的方式和XA基本是一样的,在声明@ShardingTransactionType注解时声明成BASE类型的就可以了。
Demo中提供了JUnit测试案例:TransactionTest
柔性事务使用的难点还是在seata上。用起来要非常小心。
二、分布式事务原理详解
快速上手,熟悉ShardingSphere的分布式事务处理方式后,我们再来深入理解下ShardingSphere涉及到的分布式事务。
XA事务
XA是由X/Open组织提出的分布式事务的规范。 主流的关系型 数据库产品都是实现了XA接口的。 例如在MySQL从5.0.3版本开始,就已经可以直接支持XA事务了,但是要注意只有InnoDB引擎才提供支持。
//1、 XA START|BEGIN 开启事务,这个test就相当于是事务ID,将事务置于ACTIVE状态
XA START 'test';
//2、对一个ACTIVE状态的XA事务,执行构成事务的SQL语句。
insert...//business sql
//3、发布一个XA END指令,将事务置于IDLE状态
XA END 'test'; //事务结束
//4、对于IDLE状态的XACT事务,执行XA PREPARED指令 将事务置于PREPARED状态。
//也可以执行 XA COMMIT 'test' ON PHASE 将预备和提交一起操作。
XA PREPARE 'test'; //准备事务
//PREPARED状态的事务可以用XA RECOVER指令列出。列出的事务ID会包含gtrid,bqual,formatID和data四个字段。
XA RECOVER;
//5、对于PREPARED状态的XA事务,可以进行提交或者回滚。
XA COMMIT 'test'; //提交事务
XA ROLLBACK 'test'; //回滚事务。
XA事务中,事务都是有状态控制的,例如如果对于一个ACTIVE状态的事务进行COMMIT提交,mysql就会抛出异常
ERROR 1399 (XAE07): XAER_RMFAIL: The command cannot be executed when global transaction is in the ACTIVE state
而MySQL的JDBC连接驱动包从5.0.0版本开始,也已经直接支持XA事务。
public class MysqlXAConnectionTest
public static void main(String[] args) throws SQLException
//true表示打印XA语句,,用于调试
boolean logXaCommands = true;
// 获得资源管理器操作接口实例 RM1
Connection conn1 = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "root");
XAConnection xaConn1 = new MysqlXAConnection((com.mysql.jdbc.Connection) conn1, logXaCommands);
XAResource rm1 = xaConn1.getXAResource();
// 获得资源管理器操作接口实例 RM2
Connection conn2 = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root","root");
XAConnection xaConn2 = new MysqlXAConnection((com.mysql.jdbc.Connection) conn2, logXaCommands);
XAResource rm2 = xaConn2.getXAResource();
// AP请求TM执行一个分布式事务,TM生成全局事务id
byte[] gtrid = "g12345".getBytes();
int formatId = 1;
try
// ==============分别执行RM1和RM2上的事务分支====================
// TM生成rm1上的事务分支id
byte[] bqual1 = "b00001".getBytes();
Xid xid1 = new MysqlXid(gtrid, bqual1, formatId);
// 执行rm1上的事务分支
rm1.start(xid1, XAResource.TMNOFLAGS);//One of TMNOFLAGS, TMJOIN, or TMRESUME.
PreparedStatement ps1 = conn1.prepareStatement("INSERT into user(name) VALUES ('tianshouzhi')");
ps1.execute();
rm1.end(xid1, XAResource.TMSUCCESS);
// TM生成rm2上的事务分支id
byte[] bqual2 = "b00002".getBytes();
Xid xid2 = new MysqlXid(gtrid, bqual2, formatId);
// 执行rm2上的事务分支
rm2.start(xid2, XAResource.TMNOFLAGS);
PreparedStatement ps2 = conn2.prepareStatement("INSERT into user(name) VALUES ('wangxiaoxiao')");
ps2.execute();
rm2.end(xid2, XAResource.TMSUCCESS);
// ===================两阶段提交================================
// phase1:询问所有的RM 准备提交事务分支
int rm1_prepare = rm1.prepare(xid1);
int rm2_prepare = rm2.prepare(xid2);
// phase2:提交所有事务分支
boolean onePhase = false; //TM判断有2个事务分支,所以不能优化为一阶段提交
if (rm1_prepare == XAResource.XA_OK
&& rm2_prepare == XAResource.XA_OK
) //所有事务分支都prepare成功,提交所有事务分支
rm1.commit(xid1, onePhase);
rm2.commit(xid2, onePhase);
else //如果有事务分支没有成功,则回滚
rm1.rollback(xid1);
rm1.rollback(xid2);
catch (XAException e)
// 如果出现异常,也要进行回滚
e.printStackTrace();
这其中,XA标准规范了事务XID的格式。有三个部分: gtrid [, bqual [, formatID ]] 其中
- gtrid 是一个全局事务标识符 global transaction identifier
- bqual 是一个分支限定符 branch qualifier 。如果没有提供,会使用默认值就是一个空字符串。
- formatID 是一个数字,用于标记gtrid和bqual值的格式,这是一个正整数,最小为0,默认值就是1。
但是使用XA事务时需要注意以下几点:
- XA事务无法自动提交
- XA事务效率非常低下,全局事务的状态都需要持久化。性能非常低下,通常耗时能达到本地事务的10倍。
- XA事务在提交前出现故障的话,很难将问题隔离开。
Base柔性事务
柔性事务是指 Basic Available(基本可用)、Soft-state(软状态/柔性事务)、Eventual Consistency(最终一致性)。他的核心思想是既然无法保证分布式事务每时每刻的强一致性,那就根据每个业务自身的特点,采用合适的方式来使系统达到最终一致性。这里所谓强一致性,就是指在任何时刻,分布式事务的各个参与方的事务状态都是对齐的。典型的强一致性场景就是操作系统的文件系统。不管有多少个软件操作同一个文件,文件的状态始终是一致的。
要保证分布式事务的强一致性,难度太大,所以实际业务中,只能根据业务特点进行适当的妥协。而阿里经过不断研究后,最终提出了柔性事务的妥协方式。大体上来说,形成了以下几种处理模式:
- 最大努力通知型: 即分布式事务参与方都努力将自己的事务处理结果通知给分布式事务的其他参与方,也就是只保证尽力而为,不保证一定成功。适用于很多跨公司、流程复杂的场景。例如 电商完成一笔支付需要电商自己更改订单状态,同时需要调用支付宝完成实际支付。这种场景下,如果支付宝处理订单支付出错了,就只能尽力将错误结果通知给电商网站,让电商网站回退订单状态。
- 补偿性:不保证事务实时的对齐状态,对于未对齐的事务,事后进行补偿。同样在电商调用支付宝的这个场景中,就只能通过定期对账的方式保证在一个账期内,双方的事务最终是对齐的,至于具体的每一笔订单,只能进行最大努力通知,不保证事务对齐。
- 异步确保型: 典型的场景就是RocketMQ的事务消息机制。通过不断的异步确认,保证分布式事务的最终一致性。
- 两阶段型: 通常用于都是操作数据库的分布式事务场景。 第一阶段准备阶段:分布式事务的各个参与方都提交自己的本地事务,并且锁定相关的资源。第二阶段提交阶段:由一个第三方的事务协调者综合处理各方的事务执行情况,通知各个参与方统一进行事务提交或者回退。
与两阶段协议对应的是增强版的三阶段协议。他们的本质区别在于,两阶段协议在准备阶段需要锁定资源,例如在数据库中,就是要加行锁。防止其他事务对数据做了调整,这样会导致在第二个阶段数据无法正常回滚。而对于Redis等其他的一些数据源,无法提供对应的锁资源操作。为了适应这样的场景,就在两阶段的准备阶段之前加一个询问阶段,在这一阶段,事务协调者只是询问各个参与方是否做好了准备。例如对于Redis,可能就是表示创建好了Redis连接。对于数据库,就只是表示已经创建好了JDBC连接。然后在准备阶段,参与者统一去写redo和undo日志,记录自己的事务提交状态。然后在最后的提交阶段,由事务协调者通知各个参与方统一进行事务提交或者回滚。
两阶段协议与三阶段协议的本质区别在于要不要锁资源。三阶段不用锁资源,所以适用性更强,并且对于事务的一致性强度也更高。
但是在编程实现上,两阶段对业务的侵入比较小,在很多框架中,直接声明一个注解就可以完成了。而三阶段对业务的侵入就比较大了,需要所有业务都按照三阶段的要求改造成TCC的模式。所以三阶段适合于一些对分布式事务准确性和时效性要求非常高的场景,比如很多银行系统。例如在一个典型的订单那支付操作中,A需要向B支付100元。使用TCC,在try阶段,通常会要求给订单设定一个状态UPDATING,同时A减少100元,B增加100元,并且将A需要减少的100元与B需要增加的100元这两个数据都单独记录下来,相当于锁定库存。这样可以用来实现类似锁资源的效果。然后在后续的confirm或者cancel操作中,将事务最终进行对齐。在这一步,首先需要修改订单状态,然后修改A和B的账户。这里注意,给A和B调整的账户都需要从锁定的资源中取,而不能凭空修改账户的数据。
- SAGA模式:由分布式事务的各个参与方自己提供正向的提交操作以及逆向的回滚操作。事务协调者可以在各个参与方提交事务后,随时协调各个事务参与方进行回滚。具体来说,每个SAGA事务包含T1,T2,T3…Tn操作,每个操作都对应具体的补偿操作C1,C2,C3…Cn。那么SAGA事务就需要保证: 1、所遇事务T1,T2,T3…Tn执行成功(最佳情况),2、如果有事务执行失败了, T1,T2,T3…Tj,Cj,…C3,C2,C1执行成功(0<j<n)。例如对于客户扣款100块钱的操作,电商网站和支付宝都提供扣减客户100块钱的操作作为正向事务,同时也提供给客户加100块钱余额的操作作为逆向操作。这样事务协调者可以在检查电商网站和支付宝的扣款行为后,随时通知他们进行回滚。 这种方式对业务的影响也是比较大的。适合于事务流程比较长,参与方比较多的场景。
所以从广义上来看,ShardingSphere支持的这种XA事务其实也是属于一种柔性事务。但是一般情况下,BASE柔性事务特指Seata框架提供的柔性事务,因为BASE实际上是集成了阿里对于分布式事务的所有研究,而阿里的这些研究成果,最终都沉淀到了Seata框架中。ShardingSphere中对于柔性事务的支持,其实也是更多的基于Seata的AT模式,来实现的两阶段提交。这里要注意的是,虽然XA和AT都是基于两阶段协议提供的实现,但是AT模式相比XA模式,简化了对于资源锁的要求,所以可以认为在大部分的业务场景下,AT模式比XA模式性能稍高。
ShardingJDBC扩展分布式事务管理器
分布式事务相关的扩展点,可以参见ShardingSphere的官方说明,也可以参考源码下的docs\\document\\content\\dev-manual\\transaction.cn.md。
事务管理器的父接口是ShardingTransactionManager,下面提供了SeataATShardingTransactionManager和XAShardingTransactionManager两个实现类,也可以通过SPI机制扩展出自己的分布式事务管理器。
ShardingTransactionManager接口的源码如下:
public interface ShardingTransactionManager extends AutoCloseable
// 初始化
void init(DatabaseType databaseType, Collection<ResourceDataSource> resourceDataSources, String transactionMangerType);
// 获取事务类型,ShardingSphere就是通过这个事务类型去加载对应的事务管理器
TransactionType getTransactionType();
// 判断事务是否在进行当中
boolean isInTransaction();
// 获得事务连接
Connection getConnection(String dataSourceName) throws SQLException;
// 开始本地事务
void begin();
// 提交本地事务
void commit();
// 回滚本地事务
void rollback();
其实,这里我们结合分布式事务的理论来看这个接口,可以看到,虽然ShardingSphere是按照两阶段协议实现的事务控制,但是光从这个
以上是关于分布式事务详解的主要内容,如果未能解决你的问题,请参考以下文章