(ICCV-2019)用于视频识别的 SlowFast 网络
Posted 顾道长生'
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(ICCV-2019)用于视频识别的 SlowFast 网络相关的知识,希望对你有一定的参考价值。
用于视频识别的 SlowFast 网络
paper题目:SlowFast Networks for Video Recognition
paper是FAIR发表在ICCV 2019的工作
论文地址:链接
Abstract
本文提出了用于视频识别的 SlowFast 网络。模型涉及(i)以低帧速率运行的慢速路径以捕获空间语义,以及(ii)以高帧速率运行的快速路径以捕获精细时间分辨率的运动。 Fast 路径可以通过减少其通道容量而变得非常轻量级,但可以学习用于视频识别的有用时间信息。本文的模型在视频中的动作分类和检测方面都实现了强大的性能,并且明确指出了slowfast的明确概念。本文报告了主要视频识别基准Kinetics、Charades 和 AVA 的最先进的准确性。代码地址:链接。
1. Introduction
在识别图像 I ( x , y ) I(x, y) I(x,y)时,习惯上对称地处理两个空间维度 x x x和 y y y。这是由自然图像的统计数据所证明的,自然图像首先是各向同性的,所有方向的可能性都是一样的,而且是移位不变的。但是视频信号 I ( x , y , t ) I(x, y, t) I(x,y,t)呢?运动是方位的时空对应物,但并非所有时空方向都具有相同的可能性。慢动作比快动作更有可能(事实上,我们看到的大部分世界在给定时刻都处于静止状态),这已在贝叶斯关于人类如何感知运动刺激的描述中得到了利用。例如,如果我们看到一个孤立的移动边缘,我们会认为它垂直于自身移动,即使原则上它也可能具有与自身相切的任意运动分量(光流中的孔径问题)。如果先验有利于缓慢的运动,这种看法是合理的。
如果所有时空方向的可能性不一样,那么我们就没有理由对称地对待空间和时间,就像基于时空卷积的视频识别方法所隐含的那样。我们可以用"因子 "架构来分别处理空间结构和时间事件。为了具体化,让我们在识别的背景下研究这个问题。视觉内容的分类空间语义往往发展缓慢。例如,挥舞的手在挥舞的过程中不会改变其作为 "手"的身份,而一个人总是在 "人"的类别中,尽管他/她可以从走路转到跑步。因此,对分类语义(以及它们的颜色、质地、灯光等)的识别可以相对缓慢地被刷新。另一方面,正在进行的运动可以比它们的主体身份发展得更快,如拍手、挥手、摇晃、行走或跳跃。可以希望使用快速刷新的帧(高时间分辨率)来有效地模拟潜在的快速变化的运动。
基于这种直觉,提出了一个用于视频识别的双路径SlowFast模型(图1)。一条途径被设计用来捕捉可由图像或少数稀疏帧提供的语义信息,它在低帧率和慢速刷新速度下运行。相比之下,另一个途径负责捕捉快速变化的运动,通过在快速刷新速度和高时间分辨率下操作。尽管它的时间率很高,但这一途径被做得很轻,例如,占总计算量的大约20%。这是因为这条通路被设计成具有较少的通道,处理空间信息的能力较弱,而这种信息可以由第一条通路以较少的冗余方式提供。称第一条通路为慢速通路,第二条通路为快速通路,由它们不同的时间速度驱动。这两条通路通过侧向连接融合在一起。
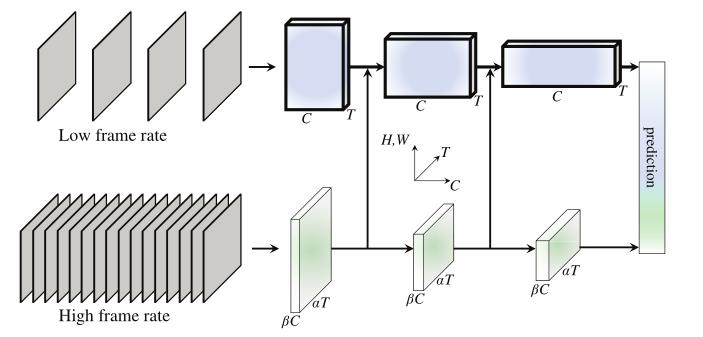
图1. 一个慢速网络有一个低帧率、低时间分辨率的慢速通路和一个高帧率、 α × \\alpha \\times α×高时间分辨率的快速通路。快速通路通过使用一部分通道 ( β , 例如 1 / 8 ) (\\beta, \\text例如 1 / 8) (β,例如1/8)来实现轻量化。横向连接将它们融合在一起。
作者的概念性想法导致了视频模型的灵活和有效的设计。快速路径,由于其轻量级的性质,不需要执行任何时间池化–它可以在所有中间层的高帧率上操作,并保持时间的保真度。同时,由于较低的时间速率,慢速途径可以更专注于空间领域和语义。通过以不同的时间速率处理原始视频,本文的方法允许这两种途径在视频建模上有自己的特长。
还有一个众所周知的视频识别架构,它有一个双流设计,但提供了概念上的不同观点。双流法没有探索不同时间速度的潜力,这是本文方法中的一个关键概念。双流方法对两个流采用相同的backbone结构,而本文的快速通道则更轻巧。本文的方法不计算光流,因此,我们的模型是从原始数据中端到端的学习。在本文的实验中,观察到SlowFast网络更有效。
本文的方法部分受到灵长类视觉系统中视网膜神经节细胞生物学研究的启发,尽管这个类比是粗略和不成熟的。这些研究发现,在这些细胞中,约 80% 是细小细胞(P 细胞),约 15-20% 是大细胞(M 细胞)。 M 细胞在高时间频率下工作,并对快速的时间变化作出反应,但对空间细节或颜色不敏感。 P 细胞提供精细的空间细节和颜色,但时间分辨率较低,对刺激反应缓慢。本文的框架类似:(i)本文的模型有两条路径分别在低和高时间分辨率下工作; (ii) 本文的快速路径旨在捕捉快速变化的运动,但空间细节较少,类似于 M 细胞; (iii) 本文的 Fast 通路是轻量级的,类似于 M 细胞的小比例。希望这些关系能够激发更多用于视频识别的计算机视觉模型。
作者在 Kinetics-400、Kinetics-600、Charades和AVA数据集上评估本文的方法。对动力学动作分类的综合消融实验证明了慢速贡献的功效。SlowFast网络在所有数据集上实现了新的最先进精度,与文献中的先前系统相比有显著的进步。
2. Related Work
时空过滤。动作可以表述为时空对象,并通过时空定向过滤来捕获,如 HOG3D和cuboids所做的那样。 3D ConvNets将 2D 图像模型扩展到时空域,同等的处理空间和时间维度。还有一些相关方法专注于使用时间步长进行长期过滤和池化,以及将卷积分解为单独的 2D 空间和 1D 时间滤波器。
除了时空过滤或其可分离版本之外,本文的工作还通过使用两种不同的时间速度来追求更彻底的建模专业知识分离。
用于视频识别的光流。有一个经典的研究分支,专注于基于光流的手工制作的时空特征。这些方法,包括流直方图、运动边界直方图和轨迹,在深度学习流行之前已经显示出具有竞争力的动作识别性能。
在深度神经网络的背景下,双流方法通过将光流视为另一种输入模式来利用光流。这种方法已成为文献中许多竞争性结果的基础。然而,鉴于光流是一种手工设计的表示,并且双流方法通常不是与流一起端到端学习的,因此在方法上并不令人满意。
3. SlowFast Networks
SlowFast 网络可以描述为以两种不同帧速率运行的单流架构,但使用路径的概念来反映与生物 Parvo 和 Magnocellular 对应物的类比。本文的通用架构有一条慢速路径(第 3.1 节)和一条快速路径(第 3.2 节),它们通过横向连接融合到一个慢速网络(第 3.3 节)。图 1 说明了本文的概念。
3.1. Slow pathway
慢速路径可以是任何卷积模型,它可以将视频剪辑作为时空volume工作。慢速路径中的关键概念是输入帧上的大时间步幅 τ \\tau τ,即它只处理 τ \\tau τ帧中的一个。作者研究的 τ \\tau τ的典型值是16——对于 30 fps 的视频,这个刷新速度大约是每秒采样 2 帧。将慢速路径采样的帧数表示为 T T T,原始剪辑长度为 T × τ T \\times \\tau T×τ帧。
3.2. Fast pathway
与慢速路径平行,快速路径是另一种具有以下属性的卷积模型。
高帧率。本节的目标是在时间维度上有一个很好的表示。Fast路径以 τ / α \\tau / \\alpha τ/α的小时间步幅工作,其中 α > 1 \\alpha>1 α>1是Fast和Slow路径之间的帧速率比。两条路径在相同的原始剪辑上运行,因此Fast路径对 α T \\alpha T αT帧进行采样,比 Slow 路径密集 α \\alpha α倍。在本文的实验中,典型值为 α = 8 \\alpha=8 α=8。
α \\alpha α的存在是 SlowFast 概念的关键(图 1,时间轴)。它明确表明这两条路径以不同的时间速度工作,从而推动了实例化两条路径的两个子网的专业知识。
高时间分辨率特征。本文的 Fast 路径不仅具有高输入分辨率,而且在整个网络层次结构中追求高分辨率特征。在本文的实例中,在整个 Fast 路径中不使用时间下采样层(既不使用时间池化也不使用时间跨度卷积),直到分类前的全局池化层。因此,本文的特征张量在时间维度上始终具有 α T \\alpha T αT帧,尽可能地保持时间保真度。
通道容量低。Fast路径与现有模型的区别还在于,它可以使用显著较低的通道容量来实现 SlowFast 模型的良好精度。这使它变得轻量。
简而言之,Fast路径是一个类似于Slow路径的卷积网络,但具有Slow路径的 β ( β < 1 ) \\beta(\\beta<1) β(β<1)个通道的比率。在本文的实验中,典型值为 β = 1 / 8 \\beta=1 / 8 β=1/8。请注意,公共层的计算(浮点数运算,或 FLOPs)在其通道缩放比率方面通常是二次的。这就是使快速路径比慢速路径更具计算效率的原因。在本文的实例中,Fast 路径通常占总计算量的约20%。有趣的是,正如第二节中提到的那样。如图 1 所示,有证据表明,灵长类视觉系统中约 15-20% 的视网膜细胞是 M 细胞(对快速运动敏感,但对颜色或空间细节不敏感)。
低信道容量也可以解释为表示空间语义的能力较弱。从技术上讲,Fast路径在空间维度上没有特殊处理,因此它的空间建模能力应该低于Slow路径,因为通道较少。模型的良好结果表明,Fast路径在增强其时间建模能力的同时削弱其空间建模能力是一种理想的权衡。
受这种解释的启发,作者还探索了在快速路径中削弱空间容量的不同方法,包括降低输入空间分辨率和去除颜色信息。正如作者将通过实验展示的那样,这些版本都可以提供良好的准确性,这表明可以使空间容量较小的轻量级快速路径变得有益。
3.3. Lateral connections
两条路径的信息融合在一起,因此一条路径不会不知道另一条路径学习到的表示。通过横向连接来实现这一点,横向连接已用于融合基于光流的双流网络。在图像目标检测中,横向连接是一种流行的技术,用于合并不同级别的空间分辨率和语义。
与 [12, 35] 类似,作者在每个“阶段”的两条路径之间附加一个横向连接(图 1)。特别是对于 ResNets,这些连接就在 pool1、res2、res3 和 res4 之后。两条路径具有不同的时间维度,因此横向连接执行转换以匹配它们(详见第 3.4 节)。使用单向连接将快速路径的特征融合到慢速路径中(图 1)。作者已经尝试过双向融合,发现了类似的结果。
最后,对每个路径的输出执行全局平均池化。然后将两个池化特征向量连接起来作为全连接分类器层的输入。
3.4. Instantiations
SlowFast的想法是通用的,它可以用不同的backbone和实现细节来实例化。在本小节中,作者描述了网络架构的实例。
表 1 中指定了一个示例 SlowFast 模型。用 T × S 2 T \\times S^2 T×S2表示时空大小,其中 T T T是时间长度, S S S是方形空间的高度和宽度。接下来描述细节。
慢速路径。表 1 中的慢速路径是一个时间跨度的 3D ResNet,从 [12] 修改而来。它有 T = 4 T=4 T=4帧作为网络输入,从 64 帧原始剪辑中稀疏采样,时间步长 τ = 16 \\tau=16 τ=16。选择在此实例中不执行时间下采样,因为输入步长较大时,下采样有损性能。
与典型的 C3D/I3D 模型不同,作者仅在 res4 和 res5 中使用非退化时间卷积(kernel size > 1 >1 >1,在表 1 中划线);从 conv1 到 res3 的所有过滤器本质上都是该路径中的 2D 卷积核。
表 1. SlowFast 网络的实例化示例。对于时间、空间和通道大小,内核的维度用 T × S 2 , C \\left\\T \\times S^2, C\\right\\ T×S2,C表示。步长表示为 时间步长 , 空间步长 2 \\left\\\\text时间步长, \\text空间步长^2\\right\\ 时间步长,空间步长2。这里速度比为 α = 8 \\alpha=8 α=8,通道比为 β = 1 / 8 \\beta=1 / 8 β=1/8。 τ \\tau τ为 16。对于 Fast 路径,绿色标记更高的时间分辨率,橙色标记更少的通道。非退化时间滤波器加下划线。残差块用括号表示。backbone是 ResNet-50。
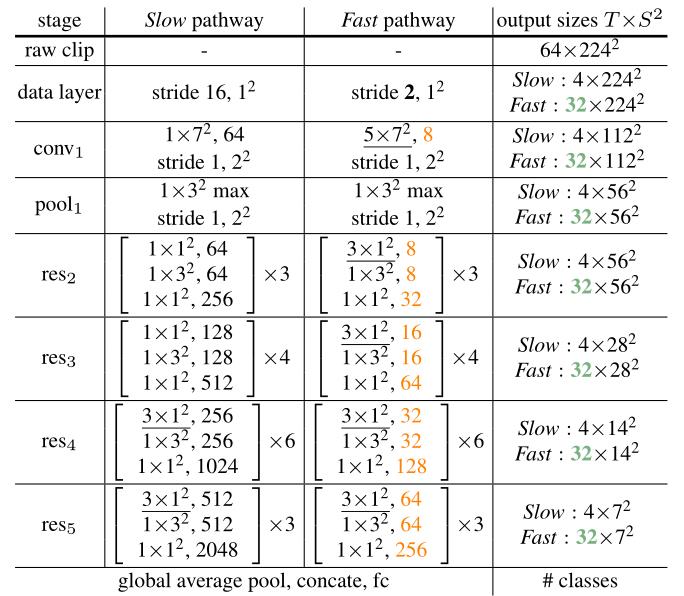
这是由实验观察所发现的,即在较早的层中使用时间卷积会降低准确性。作者认为这是因为当物体快速移动并且时间步长很大时,除非空间感受野足够大(即在后面的层中),否则时间感受野内几乎没有相关性。
快速路径。表 1 显示了快速路径的示例,其中 α = 8 \\alpha=8 α=8和 β = 1 / 8 \\beta=1 / 8 β=1/8。它具有更高的时间分辨率(绿色)和更低的通道容量(橙色)。
Fast 路径在每个块中都有非退化的时间卷积。这是由于观察到该路径具有良好的时间分辨率,以便时间卷积捕获详细的运动。此外,Fast 路径在设计上没有时间下采样层。
横向连接。横向连接从快速路径融合到慢速路径。它需要在融合之前匹配特征的大小。将Slow 路径的特征形状表示为 T , S 2 , C \\left\\T, S^2, C\\right\\ T,S2,C,Fast 路径的特征形状为 α T , S 2 , β C \\left\\\\alpha T, S^2, \\beta C\\right\\ αT,S2,βC。在横向连接中尝试以下变换:
(i) Time-to-channel:将 α T , S 2 \\left\\\\alpha T, S^2\\right. αT,S2, β C \\beta C\\ βC重塑并转置为 T , S 2 , α β C \\left\\T, S^2, \\alpha \\beta C\\right\\ T,S2,αβC,这意味着将所有 α \\alpha α帧打包到一帧的通道中。
(ii) 时间跨度采样:简单地从每个 α \\alpha α帧中采样一个,因此 α T , S 2 , β C \\left\\\\alpha T, S^2, \\beta C\\right\\ αT,S2,βC变为 T , S 2 , β C \\left\\T, S^2, \\beta C\\right\\ T,S2,βC。
(iii) 时间跨度卷积:执行 5 × 1 2 5 \\times 1^2 5×12内核的 3D 卷积,输出通道为 2 β C 2 \\beta C 2βC,stride = α =\\alpha =α。
横向连接的输出通过求和或连接融合到慢速通路中。
参考文献
[12] Christoph Feichtenhofer, Axel Pinz, and Richard Wildes. Spatiotemporal residual networks for video action recognition. In NIPS, 2016. 2, 3
[35] Tsung-Yi Lin, Piotr Dollár, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In Proc. CVPR, 2017. 3, 7
(ICCV-2021)用于步态识别的3D局部卷积神经网络
文章目录
用于步态识别的3D局部卷积神经网络
论文题目:3D Local Convolutional Neural Networks for Gait Recognition
paper是中国科学技术大学发表在ICCV 2021的工作
论文地址:地址
Abstract
%22%20aria-hidden%3D%22true%22%3E%3C%2Fg%3E%0A%3C%2Fsvg%3E) 步态识别的目标是从人体的时间变化特征中学习关于人体形状的独特时空模式。由于不同的身体部位在行走过程中表现不同,因此可以直观地分别对每个部位的时空模式进行建模。然而,现有的基于部位的方法将每一帧的特征图平均划分为固定的水平条带以获得局部部位。显然,这些基于条带划分的方法无法准确定位身体部位。第一,
步态识别的目标是从人体的时间变化特征中学习关于人体形状的独特时空模式。由于不同的身体部位在行走过程中表现不同,因此可以直观地分别对每个部位的时空模式进行建模。然而,现有的基于部位的方法将每一帧的特征图平均划分为固定的水平条带以获得局部部位。显然,这些基于条带划分的方法无法准确定位身体部位。第一,不同的身体部位可能出现在同一条条带上(例如手臂和躯干),而一个部位可能出现在不同帧的不同条纹上(例如手)。第二,不同的身体部位拥有不同的尺度,甚至同一部位在不同的帧中也会有不同的位置和尺度。第三,不同的部位还表现出不同的运动模式(例如,运动从哪一帧开始,位置变化频率,持续多长时间)。为了克服这些问题,本文提出了一种新的3D局部操作,作为3D步态识别主干中的通用构建模块系列。这个3D局部操作支持在序列中提取具有自适应空间和时间尺度、位置和长度的身体部位的局部3D体积(volume)。这样一来,身体部位的时空模式就能很好地从3D局部邻域的特定部位尺度、位置、频率和长度中学习到。实验表明,本文的3D局部卷积神经网络在流行步态数据集上实现了最先进的性能。代码可从以下网址获取:地址
1. Introduction
步态是最重要和最有效的生物特征模式之一,因为它可以在远离摄像机的情况下进行身份验证,而无需受试者(subject)的配合。步态识别在犯罪预防、法医鉴定和社会安全保障方面有着广泛的应用。在现实场景中,除了步行运动引起的体型变化之外,背包、穿大衣、相机视角切换等变化也会导致身体外观的剧烈变化,从而给步态识别带来了巨大的挑战。步态识别的基本目标是从人体形状的时间变化特征中学习独特和不变的表示。步态识别的早期工作集中于使用卷积神经网络(CNN)提取全局特征。GaitNet提出了一种自动编码器框架,从原始RGB图像中提取步态相关特征,然后使用LSTM对步态序列的时间变化进行建模。Thomas等人直接应用3DCNN来提取序列信息,使用一个在自然图像分类任务上预训练的模型。然而,全局特征不考虑身体形状的空间结构和局部细节,因此在面对视角变化时没有足够的判别力。一个自然的选择是学习详细的基于身体部位的局部特征,作为对全局特征的补充,或者学习它们两者的特征嵌入。
由于人体由定义明确的部位组成,即头部、手臂、腿部和躯干,基于部位的模型有可能解决步态识别中的变化。以前的基于部位的模型通过将特征图等分成固定的水平条来提取局部特征。在GaitPart中,首先通过对每个输入帧的输出CNN特征图应用预先定义的水平分割来提取2D外观特征。然后,来自所有帧的同一条带的相应特征通过局部短距离 2D 部位特征的时间串联聚合。在 GaitSet和GLN中,首先将最后一个 2D 卷积的帧级特征图分割成均匀的条带,然后沿集合维度对其应用最大池化以提取集合级部位特征。在 MT3D中,使用多个时间尺度3D CNN来探索序列中的时间关系。然后,输出特征图也被划分为多个条带。然而,这些基于部位的步态识别方法忽略了两个问题。首先,人体的不同部位有不同的尺度,甚至同一个部位在不同的帧中也可能有不同的位置和尺度。其次,不同的部位表现出不同的运动模式,例如运动从哪一帧开始、位置变化的频率以及持续多长时间。因此,在一个步态周期,视觉外观和时间运动变化是相互依赖的,人体不同的部位的特征也各不相同。这表明步态识别模型应该支持对每个特定人体部位的自适应 3D 局部体积的提取和处理。
为了克服步态识别中的上述问题,本文提出了一种新的3D局部操作,作为3D步态识别主干中的通用构建模块系列。这个3D局部操作支持在序列中提取具有自适应空间和时间尺度、位置和长度的身体部位的局部3D体积(volume)。这样,不同身体部位的3D局部邻域在特定的部位尺度、位置和运动位置、频率、长度上进行处理,如图1所示。2D 局部操作已经被证明在图像识别中是有效的,其中利用可微分的 2D 注意力机制来产生位置和尺度平滑变化的 2D 图像/特征块。然而,由于时间注视(temporal foveation)的不同机制,将这个想法应用于 3D 局部操作是非常具有挑战性的。原因有两方面。1)像素的空间采样遵循人眼的焦点,而帧的时间采样则是遵循光流的分布。2) 空间采样处理2D切片,时间采样处理1D序列,时空采样处理3D视频体积。因此,需要一种新的2D和1D联合采样策略。

图1.主干CNN中的块。所有这些块都从局部邻域提取特征。在C2D和C3D中,局部邻域是固定的2D切片(
)或3D体积(
)。非局部网络学习所有位置(
)的自适应长距离依赖。本文的3D局部CNN旨在为多个局部路径定位自适应3D体积,而不是固定的局部邻域,并提取相应的局部特征。
局部操作包括4个模块:定位、采样、特征提取和融合。定位模块用于学习头部、躯干、左臂、右臂、左腿和右腿六个身体部位的自适应时空尺度、位置和时间长度。采样模块对平稳变化的位置、尺度和时间长度的局部体积进行采样。与一般卷积块一样,特征提取模块由几个卷积和ReLU层组成。融合模块由全局和局部输出的级联层形成,后跟%22%20aria-hidden%3D%22true%22%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-31%22%20x%3D%220%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-D7%22%20x%3D%22722%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-31%22%20x%3D%221723%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-D7%22%20x%3D%222446%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%20%3Cuse%20xlink%3Ahref%3D%22%23E1-MJMAIN-31%22%20x%3D%223446%22%20y%3D%220%22%3E%3C%2Fuse%3E%0A%3C%2Fg%3E%0A%3C%2Fsvg%3E) 卷积层。在实践中,现有3D主干CNN的任何构建块都可以被视为全局路径,并且提出的局部路径可以很容易地插入到这些块中,而无需改变训练方案。此外,对于不同的配置,局部操作中每个组件的体系结构都非常灵活。
卷积层。在实践中,现有3D主干CNN的任何构建块都可以被视为全局路径,并且提出的局部路径可以很容易地插入到这些块中,而无需改变训练方案。此外,对于不同的配置,局部操作中每个组件的体系结构都非常灵活。
这项工作的主要贡献总结如下:
- 与C3D、P3D和非局部网络相比,作者为主干3D CNN设计了一个新的构建块,它包含人体特定部位的序列信息,称为3D局部卷积神经网络。
- 实现了一种简单但有效的3D局部CNN,用于步态识别。该模型在两个最流行的数据集 CASIA-B 和 OU-MVLP 上优于最先进的步态识别方法。
- 据作者所知,他们是第一个提出这个框架的人,该框架能够在任何3DCNN层中交互/增强全局和局部3D体积信息。
2. Related Works
Gait Recognition. 许多关于步态识别的研究都集中在空间特征提取和时间建模。为了获得空间表示,大多数基于CNN的研究在整个特征图上沿空间维度采用常规2D或3D卷积运算。虽然对所有特征图进行同等扫描是很自然的,但这些方法忽略了步态任务中人体部位之间的显著差异。GaitSet、GaitPart、GLN、MT3D都试图通过将主干的输出特征图平均水平分割为m条带来获得部位级空间特征。然而,对于明确定义的人体部位,它既没有灵活性也没有细粒度性。此外,为了获得步态序列的时空表征,许多研究直接将整个序列压缩为一帧,或者从每个轮廓中独立提取帧级特征,并使用Max Pooling沿时间维度简单地聚合帧级特征。从而忽略了连续帧之间的时间相关性。另一种方法使用LSTM明确捕捉时间变化,在时间序列中聚合姿势特征,生成最终步态特征,这种方法保留了周期步态序列不必要的顺序约束。所有这些方法都分别提取空间特征和时间特征,忽略了不同帧的不同位置的时空依赖性,这对于识别人类步态的时空运动模式至关重要。
Local-based model. 基于局部的模型已经在许多视觉任务中得到了应用。在细粒度图像分类中,许多工作已经自动定位了信息区域,以捕获细微的区分细节,从而使从属类彼此不同。Sun等人利用多通道注意力来学习几个相关区域。Wang等人使用一组卷积滤波器来捕获特征图中的判别性区域。Zheng等人提出了三线性注意力采样网络来从不同的细节中学习特征。
在行人重识别领域,Li等人将第一卷积层的输出特征图横向平均分成m个局部区域,并分别学习局部/全局特征。Cheng等人将低层特征图视频动作定位的分层自关注网络:ICCV2019论文解析