[转]爬虫 selenium + phantomjs / chrome
Posted JackieZhengChina
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[转]爬虫 selenium + phantomjs / chrome相关的知识,希望对你有一定的参考价值。
selenium 模块
Web自动化测试工具, 可运行在浏览器,根据指定命令操作浏览器, 必须与第三方浏览器结合使用
安装
sudo pip3 install selenium
phantomjs 浏览器
无界面浏览器(无头浏览器), 在内存中进行页面加载,高效
安装
windows
下载对应安装包,将文件放到python安装目录的Scripts目录下
Linux
下载, 解压到任意路径
chromedriver 接口
性质完全同 phantomjs
下载地址 : 这里
安装
- 查看本机Chrome浏览器版本(设置-帮助-关于Google Chrome)
- 下载对应版本的chromedriver
- 拷贝到python安装目录的Scripts目录下
对比两个接口
chromedriver 比 phantomjs 性能好, 在 windows下更适合用 chromedriver
phantomjs 更适合用在 无界面环境下. 比如 linux 中, 且 phantomjs 多进程下性能下降严重
而且 phantomjs 很不稳定
整合使用
基本实例
简单实例 - 访问百度
# 导入接口 from selenium import webdriver # 创建 PhantomJS 浏览器对象 driver = webdriver.PhantomJS() # 发送请求 driver.get(\'http://www.baidu.com/\') # 查看截图 driver.save_screenshot(\'百度.png\') # 关闭当前页 driver.close() # 关闭浏览器 driver.quit()
稍微复杂的实例 - 百度输入跳转
# _*_ coding:utf-8 _*_ import time # 导入接口 from selenium import webdriver # 创建 PhantomJS 浏览器对象 driver = webdriver.PhantomJS() # 发送请求 driver.get(\'http://www.baidu.com/\') # 向搜索框 ( id=kw ) 输入"初音未来" driver.find_element_by_id(\'kw\').send_keys(\'初音未来\') # 点击 百度一下 按钮 ( id=su ) driver.find_element_by_id(\'su\').click() # driver.find_element_by_class_name(\'btn self-btn bg s_btn btn_h btnhover\') time.sleep(2) # 加载需要点时间 # 查看截图 driver.save_screenshot(\'miku.png\') # 查看响应内容 html = driver.page_source print(html) # 类似于 res = request.get().text() # 关闭当前页 driver.close() # 关闭浏览器 driver.quit()
特殊实例 - qq 邮箱登录
qq 邮箱页面是使用的 ifram子框架 (两个页面的嵌套页面) . 普通的方式是不行的
from selenium import webdriver import time browser = webdriver.PhantomJS() browser.get(\'https://mail.qq.com/\') # 切换到ifram子框架(网页中又嵌套了一个网页) login_frame = browser.find_element_by_id(\'login_frame\') browser.switch_to_frame(login_frame) # 输入qq号 密码 点击登录按钮 uname = browser.find_element_by_xpath(\'//*[@id="u"]\') uname.send_keys(\'\') pwd = browser.find_element_by_xpath(\'//*[@id="p"]\') pwd.send_keys(\'\') login = browser.find_element_by_xpath(\'//*[@id="login_button"]\') login.click() time.sleep(2) browser.save_screenshot(\'login.png\')
常用属性方法
导入
from selenium import webdriver
创建 phantomjs 浏览器对象
driver = webdriver.PhantomJS()
可选参数 executable_path
driver = webdriver.PhantomJS(executable_path="/xxxx")
可以指定 phantomjs 的路径, 如果已经放在 python 的 script 中就不用这样设置了.
因此推荐解压后放置在 python 的 script 中 ( 因为环境变量设置了 )
创建 chrome 浏览器对象
driver = webdriver.Chrome()
可选参数 executable_path 同上
可选参数 option
设置谷歌浏览器隐藏页面
options = webdriver.ChromeOptions() * 方法1 :options.add_argument(\'--headless\') * 方法2 :options.set_headless()
browser = webdriver.Chrome(options=options)
browser.get(\'http://www.baidu.com/\')
发请求
driver.get(\'http://www.baidu.com/\')
查看源码
html = driver.page_source print(html) # 类似于 res = request.get().text()
源码中搜索字符串
可以是文本值也可以是属性值
html = driver.page_source res = html.find(\'字符串\')
返回值
-1 未找到
其他 找到
关闭当前页面
driver.close()
关闭浏览器
driver.quit()
定位节点
单节点查找
推荐使用 xpath
xpath 可以直接检查中定位标签后复制即可. 是最为精准的方式
# 利用标签的属性
driver.find_element_by_id(\'\') driver.find_element_by_name(\'\') driver.find_element_by_class_name(\'\')
# 上面都没有的话可以用 xpath driver.find_element_by_xpath(\'\')
多节点查找
driver.find_elements_by_xxxxxxx(\'\') for ele in [节点对象列表]: print(ele.text)
节点查找实例
from selenium import webdriver # 创建浏览器对象 browser = webdriver.PhantomJS() browser.get(\'https://www.qiushibaike.com/text/\') # 单元素查找 div = browser.find_element_by_class_name(\'content\') # 多元素查找 divs = browser.find_elements_by_class_name(\'content\') for div in divs: # text是获取当前节点对象中所有文本内容(所有节点) print(div.text) print(\'*\' * 50)
节点操作
ele.text
拿到节点的内容 (包括后代节点的所有内容)
driver.find_element_by_id(\'\').text
ele.send_keys("")
搜索框赋值
driver.find_element_by_id(\'kw\').send_keys("初音未来")
ele.click()
点击标签
driver.find_element_by_id(\'su\').click()
ele.get_attribute("")
获取属性值
# 获取元素标签的内容 att01 = a_href.get_attribute(\'textContent\') text_01 = a_href.text # # 获取元素内的全部HTML att02 = a_href.get_attribute(\'innerHTML\') # # 获取包含选中元素的HTML att03 = a_href.get_attribute(\'outerHTML\') # 获取该元素的标签类型 tag01 = a_href.tag_name
其他操作
不请求图片模式
只需要如下设置则不会请求图片, 会加快效率
代码 - 设置 chromedriver 不加载图片
chrome_opt = webdriver.ChromeOptions() prefs = {"profile.managed_default_content_settings.images": 2} chrome_opt.add_experimental_option("prefs", prefs)
查看截图
因为是在内存中的处理, 且无头浏览器也没办法看到具体的页面
使用此方法可以查看回传的截图
driver.save_screenshot(\'百度.png\')
切换子框架
此操作主要作用与 ifram子框架 的互相切换使用
iframe = driver.find_element_by_xxx(\'\') driver.switch_to_frame(节点对象)
执行 JS 代码
execute_script 方法来执行 js 代码
browser.execute_script( \'window.scrollTo(0,document.body.scrollHeight)\' )
实例解析 - 京东商品爬取
页面分析
爬取京东商品
模拟操作搜索框输入查询商品后点击搜索
将返回页面的商品列表进行爬取
京东的页面展示机制中有配合 ajax 的请求
初始页面的提供了 30 个页面数据, 然后通过滑轮往下在发起 ajax 的请求剩下的30个
准备工作
URL 地址 https://www.jd.com/
搜索框节点 //*[@id="key"]
搜索按钮 //*[@id="search"]/div/div[2]/button
商品信息节点对象列表 //*[@id="J_goodsList"]/ul/li
爬虫代码
from selenium import webdriver import time class JdSpirder(object): def __init__(self, key): self.browser = webdriver.PhantomJS() self.url = \'https://www.jd.com/\' self.key = key # 获取商品页面 def get_page(self): self.browser.get(self.url) # 找节点 self.browser.find_element_by_xpath(\'//*[@id="key"]\').send_keys(self.key) self.browser.find_element_by_xpath(\'//*[@id="search"]/div/div[2]/button\').click() time.sleep(2) self.parse_page() # 解析页面 def parse_page(self): # 把下拉菜单拉到底部,执行JS脚本 self.browser.execute_script( \'window.scrollTo(0,document.body.scrollHeight)\' ) time.sleep(1) # 匹配所有商品节点对象列表 li_list = self.browser.find_elements_by_xpath(\'//*[@id="J_goodsList"]/ul/li\') for li in li_list: li_info = li.text.split(\'\\n\') if li_info[0][0:2] == \'每满\': price = li_info[1] name = li_info[2] commit = li_info[3] market = li_info[4] else: price = li_info[0] name = li_info[1] commit = li_info[2] market = li_info[3] print([price, commit, market, name]) def main(self): self.get_page() while True: self.parse_page() # 判断是否该点击下一页,没有找到说明不是最后一页 if self.browser.page_source.find(\'pn-next disabled\') == -1: self.browser. \\ find_element_by_class_name(\'pn-next\').click() time.sleep(2) else: break if __name__ == \'__main__\': spider = JdSpirder("爬虫书籍") spider.main()
实例解析 - 小米应用下载页面爬虫
页面分析
爬取小米应用商店指定分类下的app 名字和连接
预被爬取的数据是 ajax 请求, F12 抓包选择 XHR 即可看到
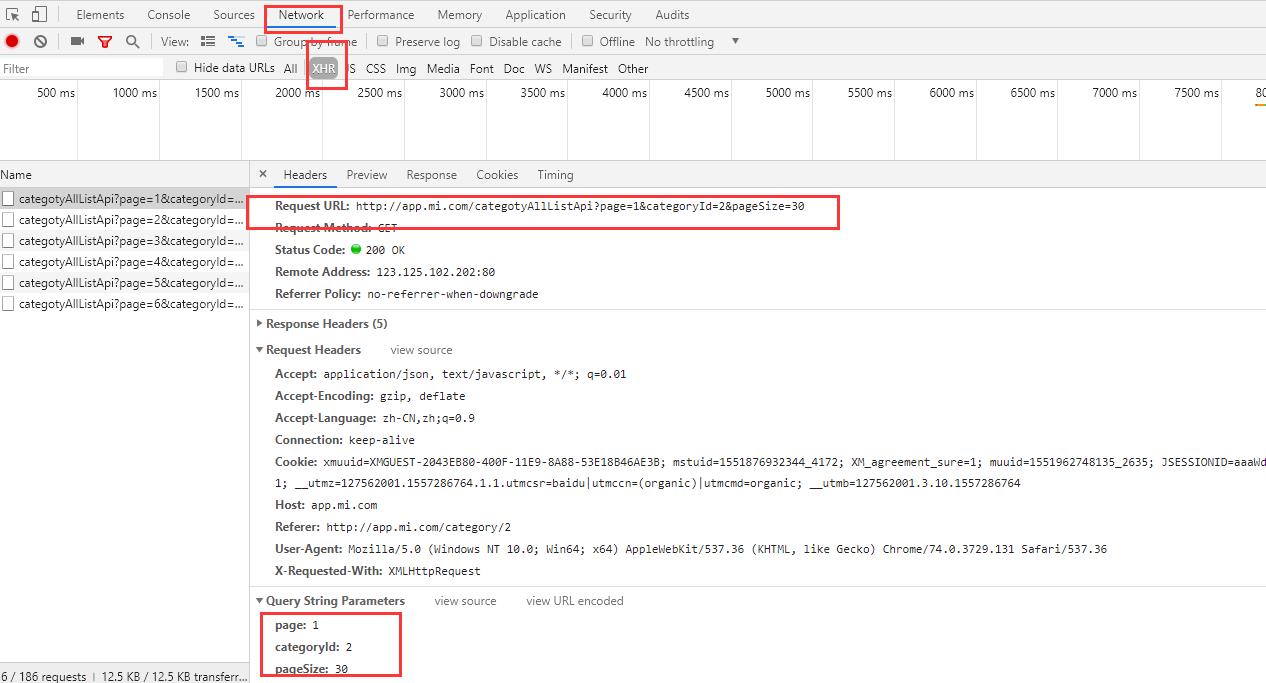
配合 并发编程 ( 多线 / 进程 )
* 队列(from multiprocessing import Queue) q = Queue() q.put(url) q.get() :参数block=False,空时抛异常 q.get(block=True,timeout=2) * 线程模块(threading) from threading import Thread t = Thread(target=函数名) t.start() t.join()
准备工作
URL 地址 \'http://app.mi.com/categotyAllListApi?page=%s&categoryId=2&pageSize=30\' %str(数字)
爬虫代码
多线程版本
import requests from threading import Thread from multiprocessing import Queue import json import time class XiaomiSpider(object): def __init__(self): self.url_queue = Queue() self.headers = {\'User-Agent\': \'Mozilla/5.0\'} # URL入队列 def url_in(self): # 拼接多个URL地址,然后put()到队列中 for i in range(67): url = \'http://app.mi.com/\' \\ \'categotyAllListApi?\' \\ \'page=%s\' \\ \'&categoryId=2\' \\ \'&pageSize=30\' % str(i) self.url_queue.put(url) # 线程事件函数(请求,解析提取数据) def get_page(self): # 先get()URL地址,发请求 # json模块做解析 while True: # 当队列不为空时,获取url地址 if not self.url_queue.empty(): url = self.url_queue.get() res = requests.get(url, headers=self.headers) res.encoding = \'utf-8\' html = res.text self.parse_page(html) else: break # 解析函数 def parse_page(self, html): html = json.loads(html) for h in html[\'data\']: # 应用名称 name = h[\'displayName\'] # 应用链接 link = \'http://app.mi.com/details?id={}\' \\ .format(h[\'packageName\']) d = { \'名称\': name, \'链接\': link } with open(\'小米.json\', \'a\') as f: f.write(str(d) + \'\\n\') # 主函数 def main(self): self.url_in() # 存放所有线程的列表 t_list = [] for i in range(10): t = Thread(target=self.get_page) t.start() t_list.append(t) # 统一回收线程 for p in t_list: p.join() if __name__ == \'__main__\': start = time.time() spider = XiaomiSpider() spider.main() end = time.time() print(\'执行时间:%.2f\' % (end - start))
多进程版本
进程需要考虑到多个进程在写一个文件的问题
稍微不太稳定, 所以最好上锁
import requests from multiprocessing import Process, Lock from multiprocessing import Queue import json import time class XiaomiSpider(object): def __init__(self): self.url_queue = Queue() self.headers = {\'User-Agent\': \'Mozilla/5.0\'} # 创建锁,操作文件时加锁 self.lock = Lock() # URL入队列 def url_in(self): # 拼接多个URL地址,然后put()到队列中 for i in range(67): url = \'http://app.mi.com/\' \\ \'categotyAllListApi?\' \\ \'page=%s\' \\ \'&categoryId=2\' \\ \'&pageSize=30\' % str(i) self.url_queue.put(url) # 线程事件函数(请求,解析提取数据) def get_page(self): # 先get()URL地址,发请求 # json模块做解析 while True: # 当队列不为空时,获取url地址 if not self.url_queue.empty(): url = self.url_queue.get() res = requests.get(url, headers=self.headers) res.encoding = \'utf-8\' html = res.text self.parse_page(html) else: break # 解析函数 def parse_page(self, html): html = json.loads(html) for h in html[\'data\']: # 应用名称 name = h[\'displayName\'] # 应用链接 link = \'http://app.mi.com/details?id={}\' \\ .format(h[\'packageName\']) d = { \'名称\': name, \'链接\': link } # 加锁 self.lock.acquire() with open(\'小米.json\', \'a\') as f: f.write(str(d) + \'\\n\') # 释放锁 self.lock.release() # 主函数 def main(self): self.url_in() # 存放所有进程的列表 t_list = [] for i in range(4): t = Process(target=self.get_page) t.start() t_list.append(t) # 统一回收进程 for p in t_list: p.join() if __name__ == \'__main__\': start = time.time() spider = XiaomiSpider() spider.main() end = time.time() print(\'执行时间:%.2f\' % (end - start))
特殊操作 - 集成 selenium 到Scrapy中
中间件 - selenium 操作
在中间件中执行创建以及爬取相关的操作
但是默认的中间件结束后会交给下载器进行再次爬取
所以这里直接返回 HtmlResponse 返回 response 来绕过
class JSPageMiddleware(object): # 通过chrome请求动态网页 def process_request(self, request, spider): if spider.name == "jobbole": # browser = webdriver.Chrome(executable_path="D:/Temp/chromedriver.exe") spider.browser.get(request.url) import time time.sleep(3) print("访问:{0}".format(request.url)) return HtmlResponse(url=spider.browser.current_url, body=spider.browser.page_source, encoding="utf-8", request=request)
爬虫类 - 写 初始化 / 释放 函数
因为涉及到 selenium 的创建, 以及释放
如果在中间件中执行就会导致每次的访问都进行操作频繁的释放资源
因此在 爬虫文件中使用更加理想
配合信号量在爬虫爬取结束后自动释放关闭
from selenium import webdriver from scrapy.xlib.pydispatch import dispatcher from scrapy import signals
class JobboleSpider(scrapy.Spider): name = "jobbole" allowed_domains = ["blog.jobbole.com"] start_urls = [\'http://blog.jobbole.com/all-posts/\'] def __init__(self): self.browser = webdriver.Chrome(executable_path="D:/Temp/chromedriver.exe") super(JobboleSpider, self).__init__() dispatcher.connect(self.spider_closed, signals.spider_closed) def spider_closed(self, spider): #当爬虫退出的时候关闭chrome print ("spider closed") self.browser.quit()
---------------------
作者:羊驼之歌
来源:CNBLOGS
原文:https://www.cnblogs.com/shijieli/p/10826743.html
版权声明:本文为作者原创文章,转载请附上博文链接!
内容解析By:CSDN,CNBLOG博客文章一键转载插件
以上是关于[转]爬虫 selenium + phantomjs / chrome的主要内容,如果未能解决你的问题,请参考以下文章