WebRTC音频系统 音频发送和接收
Posted shichaog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了WebRTC音频系统 音频发送和接收相关的知识,希望对你有一定的参考价值。
文章目录
一个完整的音频发送涉及到音频采集、音频增强、混音、音频格式(采样率、声道数)以及编解码和RTP封包以及网络发送环节,在这一过程中WebRTC为了结构上清晰且解耦,对每一层进行了抽象,由于采集端数据是源源不断的,因而数据采集有一个单独的线程实现。
3.1音频数据流发送流程
音频发送流程涉及到的模块如下图所示

图3-1 WebRTC 音频发送数据流
3.2 发送中的编码、RTP打包
webrtc::AudioTransport 更像是个双向桥梁,既支持发送又支持接收,在发送之后还衔接了一个或多个数据流发送模块webrtc::AudiosendStream,其连接了数据采集和发送两端,但是发送端在发送之前还需要对数据降噪、去回声以及编解码和RTP打包,数据的降噪增强就是APM模块实现的,具体APM各个算法处理的细节可见《实时语音处理实践指南》,此小节看 webrtc::AudioSender/webrtc::AudioSendStream 中音频数据编码、RTP 包打包及发送控制的设计和实现。webrtc::AudioSender/webrtc::AudioSendStream 的实现位于 webrtc/audio/audio_send_stream.h / webrtc/audio/audio_send_stream.cc,相关的类层次结构如下图:

图3-2 SendSteam UML关系图
在交互式实时通信场景中,实时通信音频数据的编码发送不同于直播场景 RTMP 之类的推流方案不同,实时通信的实时性优先,而直播场景的可靠性优先,因而实时通信场景上层一般采用UDP/RTP协议,而直播推流场景采用RTMP/TCP协议,实时通信的实时性优先,并不意味着质量要求不高,基于UDP传输的丢包、抖动乱序都会带来通信质量的下降,因而在接收端WebRTC采用了NetEQ技术,而在发送端则需要根据探测到的网络条件、接收端发回来的 RTCP 包来动态调整控制编码码率。
webrtc::AudioSendStream则是实现发送流式音频的接口类,该类主要功能是已经罗列在UML图中的方法中了,主要有以下几点:
- 使用
bool SetupSendCodec(const Config& new_config)设置编码器类型,以及配置编码器编码目标比特率; - 设置SendStream的最大、最小以及默认优先比特率,及动态更新的分配码率。
webrtc::AudioSendStream的生命周期控制,由图中start()和stop()方法实现;- 对ADM模块采集数据做音量控制、降噪、编码;
- 接收和处理回传的RTCP包,调节编码比特率;
发送流程中的编码、rtp封包、pacing都是在webrtc::AudioSendStream 中实现的,数据流程由图中带编号的数字所示,ADM采集到的PCM数据通过webrtc::AudioTransport经过APM处理后传递给webrtc::AudioSendStream,webrtc::AudioSendStream内部先调用ACM模块编码,然后将编码后的比特流用rtp_rtcp模块打包接口打包成RTP打包,然后使用pacing模块做平滑和优先级发送控制,最后通过rtp_rtcp模块发送接口调 webrtc::Transport 将包交给网络传输层。
3.3 AudioSendStream类关系
webrtc::AudioSendStream 是一个接口类,在其派生类图X.2中webrtc:internal::AudioSendStream实现了音频数据处理流式结构, 音频数据流式处理结构定义搭建过程如下。 webrtc::AudioSendStream 和 webrtc::AudioTransport的关系如下UML所示,

图3-3 AudioSendSteam UML图
该3-3图中AudioTransportImpl的audio_senders_的类型是vector类型的AduioSender,这也印证了前文说的一个AudioTransport可以对应多个AudioSendStream。 webrtc::AudioTransport采集到数据以后会调用RecordedDataIsAvailable方法,这个方法的实现如下:
// Not used in Chromium. Process captured audio and distribute to all sending
// streams, and try to do this at the lowest possible sample rate.
int32_t AudioTransportImpl::RecordedDataIsAvailable(
const void* audio_data,
const size_t number_of_frames,
const size_t bytes_per_sample,
const size_t number_of_channels,
const uint32_t sample_rate,
const uint32_t audio_delay_milliseconds,
const int32_t /*clock_drift*/,
const uint32_t /*volume*/,
const bool key_pressed,
uint32_t& /*new_mic_volume*/,
const int64_t
estimated_capture_time_ns) // NOLINT: to avoid changing APIs
RTC_DCHECK(audio_data);
RTC_DCHECK_GE(number_of_channels, 1);
RTC_DCHECK_LE(number_of_channels, 2);
RTC_DCHECK_EQ(2 * number_of_channels, bytes_per_sample);
RTC_DCHECK_GE(sample_rate, AudioProcessing::NativeRate::kSampleRate8kHz);
// 100 = 1 second / data duration (10 ms).
RTC_DCHECK_EQ(number_of_frames * 100, sample_rate);
RTC_DCHECK_LE(bytes_per_sample * number_of_frames * number_of_channels,
AudioFrame::kMaxDataSizeBytes);
int send_sample_rate_hz = 0;
size_t send_num_channels = 0;
bool swap_stereo_channels = false;
MutexLock lock(&capture_lock_);
send_sample_rate_hz = send_sample_rate_hz_;
send_num_channels = send_num_channels_;
swap_stereo_channels = swap_stereo_channels_;
std::unique_ptr<AudioFrame> audio_frame(new AudioFrame());
InitializeCaptureFrame(sample_rate, send_sample_rate_hz, number_of_channels,
send_num_channels, audio_frame.get());
voe::RemixAndResample(static_cast<const int16_t*>(audio_data),
number_of_frames, number_of_channels, sample_rate,
&capture_resampler_, audio_frame.get());
ProcessCaptureFrame(audio_delay_milliseconds, key_pressed,
swap_stereo_channels, audio_processing_,
audio_frame.get());
audio_frame->set_absolute_capture_timestamp_ms(estimated_capture_time_ns /
1000000);
RTC_DCHECK_GT(audio_frame->samples_per_channel_, 0);
if (async_audio_processing_)
async_audio_processing_->Process(std::move(audio_frame));
else
SendProcessedData(std::move(audio_frame));
return 0;
RecordedDataIsAvailable()方法会挨个调用audio_senders_向量中的每个 webrtc::internal::AudioSendStream 的SendAudioData()方法,SendAudioData()的作用是调用合适的编码器对数据进行编码和发送编码后的比特流数据,这意味着可以把录制的一份数据使用不同的编码器编码以及使用不同发送控制策略进行发送,如视频会议中使用UDP协议传输RTP协议的包,也可以是直播推流中的TCP协议传输RTMP协议的包,图3-3中显示了这两个类的关系和这两个核心API,这里有个问题,就是audio_senders_是何时被设置进webrtc::AudioTransport的,这是在 webrtc::AudioSendStream 的生命周期函数 Start() 被调用时执行,这个添加的过程大体如下:
//webrtc/audio/audio_transport_impl.cc
#0 webrtc::AudioTransportImpl::UpdateAudioSenders(std::vector<webrtc::AudioSender*, std::allocator<webrtc::AudioSender*> >, int, unsigned long) ()
//webrtc/audio/audio_state.cc
#1 webrtc::internal::AudioState::UpdateAudioTransportWithSendingStreams() ()
//webrtc/audio/audio_state.cc
#2 webrtc::internal::AudioState::AddSendingStream(webrtc::AudioSendStream*, int, unsigned long) ()
webrtc/audio/audio_send_stream.cc:
#3 webrtc::internal::AudioSendStream::Start() ()
webrtc::AudioSendStream 将其自身加进 webrtc::AudioState,webrtc::AudioState 把新加的 webrtc::AudioSendStream 和之前已经添加的 webrtc::AudioSendStream 通过UpdateAudioSenders 添加到webrtc::AudioTransport里。如果新添加的 webrtc::AudioSendStream 是第一个 webrtc::AudioSendStream,则webrtc::AudioState 还将初始化设备并启动录音。
3.4webrtc::AudioSendStream 创建和初始化
webrtc::AudioSendStream 内部数据处理组件见图X.1所示,通过代码可知,创建 webrtc::AudioSendStream 对象,最终会调用 webrtc::voe::(anonymous namespace)::ChannelSend 对象创建一些关键对象/模块,并建立部分各个对象/模块之间的联系,调用过程如下图所示:

图3-4 webrtc::AudioSendStream 初始化函数调用栈
在WebRTC中,音频起始于VoiceEngine,而VoiceEngine中WebRTCVoiceMediaChannel是非常重要的对象,其调用 webrtc::Call 创建创建新的AudioSendStream对象,创建时传递的参数config_是 webrtc::AudioSendStream::Config 类型,包含与编解码、比特率、RTP、加密以及 webrtc::Transport 等配置。
webrtc::voe::(anonymous namespace)::ChannelSend 对象的构造函数创建了大多数和发送有关对象/模块,其构造函数如下:
Clock* clock,
TaskQueueFactory* task_queue_factory,
Transport* rtp_transport,
RtcpRttStats* rtcp_rtt_stats,
RtcEventLog* rtc_event_log,
FrameEncryptorInterface* frame_encryptor,
const webrtc::CryptoOptions& crypto_options,
bool extmap_allow_mixed,
int rtcp_report_interval_ms,
uint32_t ssrc,
rtc::scoped_refptr<FrameTransformerInterface> frame_transformer,
TransportFeedbackObserver* feedback_observer,
const FieldTrialsView& field_trials)
: ssrc_(ssrc),
event_log_(rtc_event_log),
_timeStamp(0), // This is just an offset, RTP module will add it's own
// random offset
input_mute_(false),
previous_frame_muted_(false),
_includeAudioLevelIndication(false),
rtcp_observer_(new VoERtcpObserver(this)),
feedback_observer_(feedback_observer),
//创建一个 `RtpPacketSenderProxy` 对象
rtp_packet_pacer_proxy_(new RtpPacketSenderProxy()),
retransmission_rate_limiter_(
new RateLimiter(clock, kMaxRetransmissionWindowMs)),
frame_encryptor_(frame_encryptor),
crypto_options_(crypto_options),
fixing_timestamp_stall_(
field_trials.IsDisabled("WebRTC-Audio-FixTimestampStall")),
encoder_queue_(task_queue_factory->CreateTaskQueue(
"AudioEncoder",
TaskQueueFactory::Priority::NORMAL))
//创建一个 webrtc::AudioCodingModule 对象
audio_coding_.reset(AudioCodingModule::Create(AudioCodingModule::Config()));
RtpRtcpInterface::Configuration configuration;
configuration.bandwidth_callback = rtcp_observer_.get();
configuration.transport_feedback_callback = feedback_observer_;
configuration.clock = (clock ? clock : Clock::GetRealTimeClock());
configuration.audio = true;
configuration.outgoing_transport = rtp_transport;
configuration.paced_sender = rtp_packet_pacer_proxy_.get();
configuration.event_log = event_log_;
configuration.rtt_stats = rtcp_rtt_stats;
configuration.retransmission_rate_limiter =
retransmission_rate_limiter_.get();
configuration.extmap_allow_mixed = extmap_allow_mixed;
configuration.rtcp_report_interval_ms = rtcp_report_interval_ms;
configuration.rtcp_packet_type_counter_observer = this;
configuration.local_media_ssrc = ssrc;
//建了一个 webrtc::ModuleRtpRtcpImpl2 对象
rtp_rtcp_ = ModuleRtpRtcpImpl2::Create(configuration);
rtp_rtcp_->SetSendingMediaStatus(false);
//创建 `webrtc::RTPSenderAudio` 对象
rtp_sender_audio_ = std::make_unique<RTPSenderAudio>(configuration.clock,
rtp_rtcp_->RtpSender());
// Ensure that RTCP is enabled by default for the created channel.
rtp_rtcp_->SetRTCPStatus(RtcpMode::kCompound);
int error = audio_coding_->RegisterTransportCallback(this);
RTC_DCHECK_EQ(0, error);
if (frame_transformer)
InitFrameTransformerDelegate(std::move(frame_transformer));
webrtc::voe::(anonymous namespace)::ChannelSend 对象的构造函数的主要完成的事项如下:
- 创建
RtpPacketSenderProxy对象;其方法EnqueuePackets是将RTP包添加到pacing队列,然后根据目标发送比特率以及发送调度优先级发送RTP包 - 创建
webrtc::AudioCodingModule对象,对应图X.1中标号为 7的进AudioCodingModule方向的连接; - 创建
webrtc::ModuleRtpRtcpImpl2对象,其Create方法configuration参数的outgoing_transport配置项指向了传入的webrtc::Transport,对应图X.1中标号为13的连接,configuration参数的paced_sender指向了前面创建的RtpPacketSenderProxy对象,对应图X.1中标号为10的连接 - 创建
webrtc::RTPSenderAudio对象,通过rtp_sender_audio_config的rtp_sender传入了从webrtc::ModuleRtpRtcpImpl2对象获得的webrtc::RTPSender对象,对应图X.1中标号为8和9的连接; - 把
this作为webrtc::AudioPacketizationCallback注册给了webrtc::AudioCodingModule对象,对应图X.1中标号为7 进ChannelSendInterface方向连接。
在这个阶段acm2和rtp_rtcp已经接入 webrtc::voe::(anonymous namespace)::ChannelSend 的模块,而pacing模块的接入在 ChannelSend 的 RegisterSenderCongestionControlObjects() 函数中实现,其调用栈如图X.4所示。ChannelSend 对象的RegisterSenderCongestionControlObjects() 函数的实现如下:
//webrtc/audio/channel_send.cc
706 void ChannelSend::RegisterSenderCongestionControlObjects(
707 RtpTransportControllerSendInterface* transport,
708 RtcpBandwidthObserver* bandwidth_observer)
709 RTC_DCHECK_RUN_ON(&worker_thread_checker_);
710 RtpPacketSender* rtp_packet_pacer = transport->packet_sender();
711 PacketRouter* packet_router = transport->packet_router();
713 RTC_DCHECK(rtp_packet_pacer);
714 RTC_DCHECK(packet_router);
715 RTC_DCHECK(!packet_router_);
716 rtcp_observer_->SetBandwidthObserver(bandwidth_observer);
717 rtp_packet_pacer_proxy_->SetPacketPacer(rtp_packet_pacer);
718 rtp_rtcp_->SetStorePacketsStatus(true, 600);
719 packet_router_ = packet_router;
720
ChannelSend::RegisterSenderCongestionControlObjects的710和711行提取 webrtc::RtpTransportControllerSendInterface 对象中的 webrtc::RtpPacketSender 实例和 webrtc::PacketRouter实例,webrtc::RtpPacketSender 实例设置给前面创建的 RtpPacketSenderProxy 对象,这样就建立起了前面的图中标号为11实际连接,11从这时起将不再是虚线,获得的 webrtc::PacketRouter 保存起来备用。
接下来看一下图3-1中ACM module(acm2)模块是如何将编码器接口层和具体编码器关联起来的,音频编码器在 webrtc::AudioSendStream 的配置接口 Reconfigure() 调用时创建,并将编码器注册进 webrtc::AudioCodingModule。这一过程如下:
//third_party/webrtc/audio/audio_send_stream.cc
void AudioSendStream::ConfigureStream(
const webrtc::AudioSendStream::Config& new_config,
bool first_time,
SetParametersCallback callback)
if (!ReconfigureSendCodec(new_config))
RTC_LOG(LS_ERROR) << "Failed to set up send codec state.";
webrtc::InvokeSetParametersCallback(
callback, webrtc::RTCError(webrtc::RTCErrorType::INTERNAL_ERROR,
"Failed to set up send codec state."));

图3-5 编码器初始化过程
webrtc::AudioSendStream 中调用MakeAudioEncoder创建音频编码器,除了具体的编码器( 如OPUS,AAC ,G7XX)等,还有舒适噪音编码器以及冗余帧 RED 编码器。至此acm2框中编码器的通用接口类和具体的编码器实现连接上了,至于启用哪个编码则取决于SDP协商的结果。
// Apply current codec settings to a single voe::Channel used for sending.
bool AudioSendStream::SetupSendCodec(const Config& new_config)
RTC_DCHECK(new_config.send_codec_spec);
const auto& spec = *new_config.send_codec_spec;
RTC_DCHECK(new_config.encoder_factory);
//创建特定类型的(由payload_type指定,如113是opus 单声道音频编码器)具体音频编码器
std::unique_ptr<AudioEncoder> encoder =
new_config.encoder_factory->MakeAudioEncoder(
spec.payload_type, spec.format, new_config.codec_pair_id);
if (!encoder)
RTC_DLOG(LS_ERROR) << "Unable to create encoder for "
<< rtc::ToString(spec.format);
return false;
// If a bitrate has been specified for the codec, use it over the
// codec's default.
if (spec.target_bitrate_bps)
encoder->OnReceivedTargetAudioBitrate(*spec.target_bitrate_bps);
// Enable ANA if configured (currently only used by Opus).
if (new_config.audio_network_adaptor_config)
if (encoder->EnableAudioNetworkAdaptor(
*new_config.audio_network_adaptor_config, event_log_))
RTC_LOG(LS_INFO) << "Audio network adaptor enabled on SSRC "
<< new_config.rtp.ssrc;
else
RTC_LOG(LS_INFO) << "Failed to enable Audio network adaptor on SSRC "
<< new_config.rtp.ssrc;
// Wrap the encoder in an AudioEncoderCNG, if VAD is enabled.
if (spec.cng_payload_type)
AudioEncoderCngConfig cng_config;
cng_config.num_channels = encoder->NumChannels();
cng_config.payload_type = *spec.cng_payload_type;
cng_config.speech_encoder = std::move(encoder);
cng_config.vad_mode = Vad::kVadNormal;
encoder = CreateComfortNoiseEncoder(std::move(cng_config));
RegisterCngPayloadType(*spec.cng_payload_type,
new_config.send_codec_spec->format.clockrate_hz);
// Wrap the encoder in a RED encoder, if RED is enabled.
if (spec.red_payload_type)
AudioEncoderCopyRed::Config red_config;
red_config.payload_type = *spec.red_payload_type;
red_config.speech_encoder = std::move(encoder);
encoder = std::make_unique<AudioEncoderCopyRed>(std::move(red_config),
field_trials_);
// Set currently known overhead (used in ANA, opus only).
// If overhead changes later, it will be updated in UpdateOverheadForEncoder.
MutexLock lock(&overhead_per_packet_lock_);
size_t overhead = GetPerPacketOverheadBytes();
if (overhead > 0)
encoder->OnReceivedOverhead(overhead);
StoreEncoderProperties(encoder->SampleRateHz(), encoder->NumChannels());
channel_send_->SetEncoder(new_config.send_codec_spec->payload_type,
std::move(encoder));
return true;
webrtc::PacketRouter 和 webrtc::ModuleRtpRtcpImpl2 是在 webrtc::AudioSendStream 的生命周期函数 Start() 调用时连接起来的,即webrtc::internal::AudioSendStream::Start()调用webrtc::voe::(anonymous namespace)::ChannelSend::StartSend()实现二者的连接,ChannelSend::StartSend() 函数实现如下:
void ChannelSend::StartSend()
RTC_DCHECK_RUN_ON(&worker_thread_checker_);
RTC_DCHECK(!sending_);
sending_ = true;
RTC_DCHECK(packet_router_);
packet_router_->AddSendRtpModule(rtp_rtcp_.get(), /*remb_candidate=*/false);
rtp_rtcp_->SetSendingMediaStatus(true);
int ret = rtp_rtcp_->SetSendingStatus(true);
RTC_DCHECK_EQ(0, ret);
// It is now OK to start processing on the encoder task queue.
encoder_queue_.PostTask([this]
RTC_DCHECK_RUN_ON(&encoder_queue_);
encoder_queue_is_active_ = true;
);
至此图3-1中各个模块之间建立的关系分析完毕。
3.5 创建 CreateChannels
依然是基于WebRTC的Native层peerconnection_client例子,音频的发送和接收使用了rtp协议,
webrtc::PeerConnection::Initialize(const webrtc::PeerConnectionInterface::RTCConfiguration&, webrtc::PeerConnectionDependencies)函数会调用InitializeTransportController_n方法,最终调用webrtc::JsepTransportController::JsepTransportController创建JsepTransportController,jesp是javascript Session Establishment Protocol的缩写,因为webrtc是基于Web的,而Web用java开发的比较多,所以针对这些通用性的协议需求,WebRTC实现了一套服务于Web的协议和实现,这使得基于Web的开发可以直接调用已经实现好的JS(JavaScript)而使得程序编写简单很多,而这里用是c++实现了JESP功能。有了JsepTransportController之后,回调调用webrtc::JsepTransportCollection::RegisterTransport创建并注册transport。之所以在这层创建创建transport是因为WebRTC支持DTLS(Datagram Transport Layer Security )传输协议,这协议之下还影藏了ICE等协议,接下来就是多媒体数据流使用该transport实现具体发送和接收的细节了。
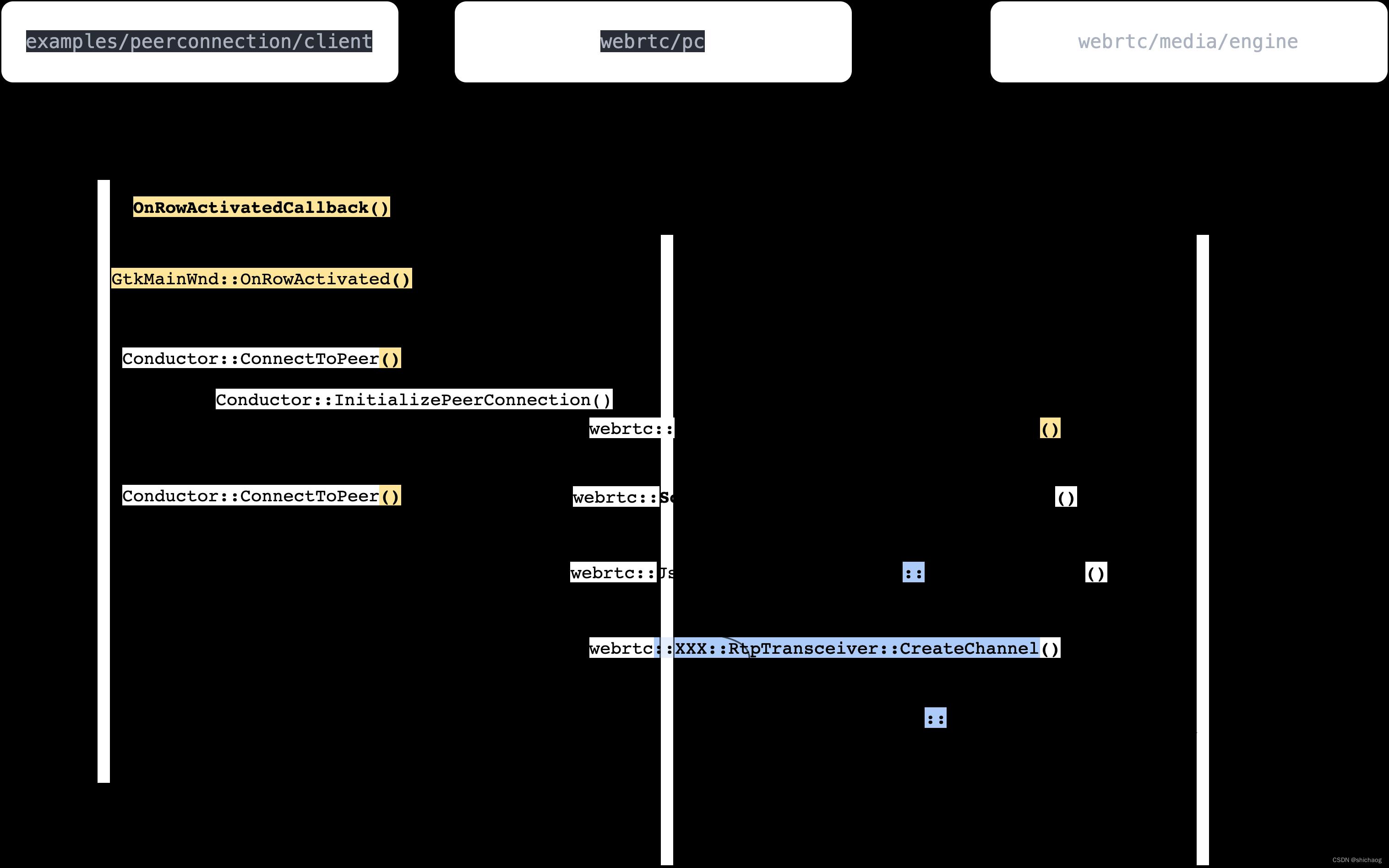
在SDP协商的时候offer端会调用SdpOfferAnswerHandler::ApplyLocalDescription() 而answer端会调用SdpOfferAnswerHandler::ApplyRemoteDescription(),这两个API都会调用SdpOfferAnswerHandler::UpdateTransceiversAndDataChannels()创建音频channel,在 SdpOfferAnswerHandler::CreateChannels() 中根据 mid (media ID)通过 PeerConnection 获得JESP协议创建的 RTP transport。
//webrtc/pc/sdp_offer_answer.cc
//参数desc中包括了媒体的类型,WebRTC目前支持视频、音频以及数据三种类型的Channel创建。
RTCError SdpOfferAnswerHandler::CreateChannels(const SessionDescription& desc)
TRACE_EVENT0("webrtc", "SdpOfferAnswerHandler::CreateChannels");
// Creating the media channels. Transports should already have been created
// at this point.
RTC_DCHECK_RUN_ON(signaling_thread());
//对于Voice类型的多媒体,其返回值为MEDIA_TYPE_AUDIO
const cricket::ContentInfo* voice = cricket::GetFirstAudioContent(&desc);
if (voice && !voice->rejected &&
//对于还没设置local/remote description的transceiver其channel是还没创建的,因而会执行下面的CreateChannel()方法
!rtp_manager()->GetAudioTransceiver()->internal()->channel())
//CreateChannel()最后一个参数std::function<RtpTransportInternal*(absl::string_view)> transport_lookup使用Lambda表达式获取。其return返回的是transport的引用。
auto error =
rtp_manager()->GetAudioTransceiver()->internal()->CreateChannel(
voice->name, pc_->call_ptr(), pc_->configuration()->media_config,
pc_->SrtpRequired(), pc_->GetCryptoOptions(), audio_options(),
video_options(), video_bitrate_allocator_factory_.get(),
[&](absl::string_view mid)
RTC_DCHECK_RUN_ON(network_thread());
return transport_controller_n()->GetRtpTransport(mid);
);
if (!error.ok())
return error;
//video媒体类型的channel创建
const cricket::ContentInfo* video = cricket::GetFirstVideoContent(&desc);
if (video && !video->rejected &&
!rtp_manager()->GetVideoTransceiver()->internal()->channel())
auto error =
rtp_manager()->GetVideoTransceiver()->internal()->CreateChannel(
video->name, pc_->call_ptr(), pc_->configuration()->media_config,
pc_->SrtpRequired(), pc_->GetCryptoOptions(),
audio_options(), video_options(),
video_bitrate_allocator_factory_.get(), [&](absl::string_view mid)
RTC_DCHECK_RUN_ON(network_thread());
return transport_controller_n()->GetRtpTransport(mid);
);
if (!error.ok())以上是关于WebRTC音频系统 音频发送和接收的主要内容,如果未能解决你的问题,请参考以下文章