自动把动态的jsp页面(或静态html)生成PDF文档,并且上传至服务器
Posted 云端观云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自动把动态的jsp页面(或静态html)生成PDF文档,并且上传至服务器相关的知识,希望对你有一定的参考价值。
这几天,任务中有一个难点是把一个打印页面自动给生成PDF文档,并且上传至服务器,然而公司框架只有手动上传文档,打印时可以保存为PDF在本地吧,所以感到很头疼,刚开始没有方向,所以只有surf the Internet了,网上看了很多资料,渐渐的从一点方向也不懂,到慢慢开始了解怎么着手去做,废话就不说了,
我看网上大概介绍了三种方式:Jasper Report 、 iText 、 flying sauser
jasper report和flying sauser感觉上要比iText的实现要强大一点,但是我实际用的时候对CSS没有太大的需求,因为是一个很简单的表格形式,(如果对pdf的样式有很高的要求,可以去看看flying sauser,这东西能解析html和CSS,而且能输出成image,PDF等格式),我用的则是iText,我用的jar是:
itext-asian-5.2.0、itextpdf-5.5.1、xmlworker-5.5.4、jsoup-1.10.2(此包是java的html解析器)
1、自动生成PDF,
下面CreatePdfDocument.java、AsianFontProvider.java是两个工具类,AsianFontProvider 是在CreatePdfDocument里面调用的,而CreatePdfDocument则会在待会儿的实现里面调用。
-
import com.itextpdf.text.*;
-
import com.itextpdf.text.pdf.BaseFont;
-
import com.itextpdf.text.pdf.PdfWriter;
-
import com.itextpdf.tool.xml.XMLWorkerHelper;
-
import org.jsoup.Jsoup;
-
-
import java.io.ByteArrayInputStream;
-
import java.io.FileOutputStream;
-
import java.io.InputStream;
-
-
/**
-
* Created by Sinoprof Codeproducer
-
* User: ck
-
* Date: 2017-10-31
-
* Time: 09:25:06
-
* 实现生成PDF文件
-
*/
-
-
public class CreatePdfDocument {
-
-
/**
-
* 根据URL提前blog的基本信息,返回结果
-
* @param URL 例:http://localhost:8080/scm/scm/po/gather/pdftest/pdftesthtml3.html(能直接返回某个html的URL,
-
* 我开始传url时候被struts1拦截了,应为get不到session的登录人信息,所以得到的是登录页面的html)
-
* @return
-
* @throws Exception
-
*/
-
public static String[] extractHtmlInfo(String URL) throws Exception {
-
/*这里为什么用数组,是因为返回的时候不仅可以返回选择的html,
-
还有从document提取其他的信息单独存在数组里返回,然后利用iText在pdf里面组装数据,可以在网上查*/
-
String[] info = new String[1];
-
// 直接把URL解析成document,然后调用document.html()解析为html
-
org.jsoup.nodes.Document doc = Jsoup.connect(URL).get();
-
// 此doc.select是用来选择完整的html中某一部分这里为第一个div的css为entry的部分,所以你的html上要有div的class为entry哦
-
org.jsoup.nodes.Element entry = doc.select("div.entry").first();
-
info[0] = entry.html();
-
return info;
-
}
-
-
/**
-
* 直接通过得到html来取得想要的部分html
-
* @param html
-
* @return
-
* @throws Exception
-
*/
-
public static String[] extractHtmlInfo2(String html) throws Exception {
-
String[] info = new String[1];
-
// 把html转换为document
-
org.jsoup.nodes.Document doc = Jsoup.parse(html);
-
// 此doc.select是用来选择完整的html中某一部分这里为第一个div的css为entry的部分,所以你的html上要有div的class为entry哦
-
org.jsoup.nodes.Element entry = doc.select("div.entry").first();
-
info[0] = entry.html();
-
return info;
-
}
-
-
/**
-
* 把String 转为 InputStream
-
* @param content
-
* @return
-
*/
-
public static InputStream parse2Stream(String content) {
-
try {
-
ByteArrayInputStream stream = new ByteArrayInputStream(
-
content.getBytes("GBK"));
-
return stream;
-
} catch (Exception e) {
-
-
return null;
-
}
-
}
-
-
-
/**
-
* 直接把网页内容转为PDF文件
-
*
-
* @param
-
* @throws Exception
-
*/
-
public static String parseURL2PDFFile(String pdfFile, String html) {
-
String returnVal = "";
-
try {
-
BaseFont bfCN = BaseFont.createFont("STSongStd-Light", "UniGB-UCS2-H",
-
false);
-
// 中文字体定义
-
Font chFont = new Font(bfCN, 14, Font.NORMAL, BaseColor.BLUE);
-
Font secFont = new Font(bfCN, 12, Font.NORMAL, new BaseColor(0, 204,
-
255));
-
Font textFont = new Font(bfCN, 12, Font.NORMAL, BaseColor.BLACK);
-
-
Document document = new Document(PageSize.A4);
-
// 设置pdf的背景图片
-
Image image = Image.getInstance("D:/移动背景图片.jpg");
-
image.setAlignment(image.UNDERLYING);
-
image.setAbsolutePosition(0,0);
-
image.scaleAbsolute(595,842);
-
-
PdfWriter pdfwriter = PdfWriter.getInstance(document,
-
new FileOutputStream(pdfFile));
-
pdfwriter.setViewerPreferences(PdfWriter.HideToolbar);
-
document.open();
-
document.add(image);
-
//得到解析的html
-
String[] blogInfo = extractHtmlInfo2(html);
-
/*html文件转换为pdf文档
-
AsianFontProvider()函数是用来解决XMLWorkerHelper.getInstance().parseXHtml()转pdf中文不显示问题*/
-
XMLWorkerHelper.getInstance().parseXHtml(pdfwriter, document,parse2Stream(blogInfo[0]),null, new AsianFontProvider());
-
-
document.close();
-
returnVal = "YES";
-
} catch (Exception e) {
-
returnVal = "NO";
-
e.printStackTrace();
-
} finally {
-
return returnVal;
-
}
-
}
-
}
-
import com.itextpdf.text.BaseColor;
-
import com.itextpdf.text.Font;
-
import com.itextpdf.text.pdf.BaseFont;
-
import com.itextpdf.tool.xml.XMLWorkerFontProvider;
-
-
/**
-
* Created by Sinoprof Codeproducer
-
* User: ck
-
* Date: 2017-10-31
-
* Time: 09:25:06
-
* 用来解决XMLWorkerHelper.getInstance().parseXHtml()转pdf中文不显示问题
-
*/
-
public class AsianFontProvider extends XMLWorkerFontProvider{
-
-
public Font getFont(final String fontname, final String encoding,
-
final boolean embedded, final float size, final int style,
-
final BaseColor color) {
-
BaseFont bf = null;
-
try {
-
bf = BaseFont.createFont("STSong-Light", "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED);
-
} catch (Exception e) {
-
e.printStackTrace();
-
}
-
Font font = new Font(bf, size, style, color);
-
font.setColor(color);
-
return font;
-
}
-
}
/**
* @param args
*/
public static void main(String[] args) throws Exception {
// 网页必须是可以直接访问的URL,
String blogURL = "http://localhost:8080/scm/scm/po/gather/pdftest/pdftesthtml3.html";
// 传入自己的html,注意html要符合w3c的标准html,因为itext对html格式有点严格,
String html = "";
// PDF最后的输出文档,注意d:/test/itext这些folder要先建好
String pdfFile = "d:/test/itext/demo-URL.pdf";
// 直接把网页内容转为PDF文件 但是这个网页必须是可以直接访问的URL,注意在CreatePdfDocument.java的parseURL2PDFFile方法中要调用extractHtmlInfo方法
Demo4URL2PDF.parseURL2PDFFile(pdfFile, blogURL);
// 直接传入html的,注意在CreatePdfDocument.javaparseURL2PDFFile方法中要调用extractHtmlInfo2方法
Demo4URL2PDF.parseURL2PDFFile(pdfFile, html);
}
这样子基本就能在你指定的位置生成PDF文档了,但注意前面说过iText对html的样式支持的很少,所以生成的pdf文档比较简单,jtext-asian-5.2.0、itextpdf-5.5.1、xmlworker-5.5.4,这三个jar是我在网上找的支持table标签的,(刚开始找的低版本的jar不支持table,所以我的表格出不来),还有就是AsianFontProvider.java这个类对中文的支持,因为iText的XMLWorkerHelper.getInstance().parseXHtml转PDF的时候,中文不显示,
(网上说是什么没有默认的中文字体,我看网上有人修改xmlworker源码的,使其默认一个字体),
但是我没有成功,机缘巧合之下我找到了这种不用修改源码的就像这样
XMLWorkerHelper.getInstance().parseXHtml(pdfwriter,document,parse2Stream(blogInfo[0]),null,newAsianFontProvider());
刚好能帮我解决我的需求,结果图片如下:
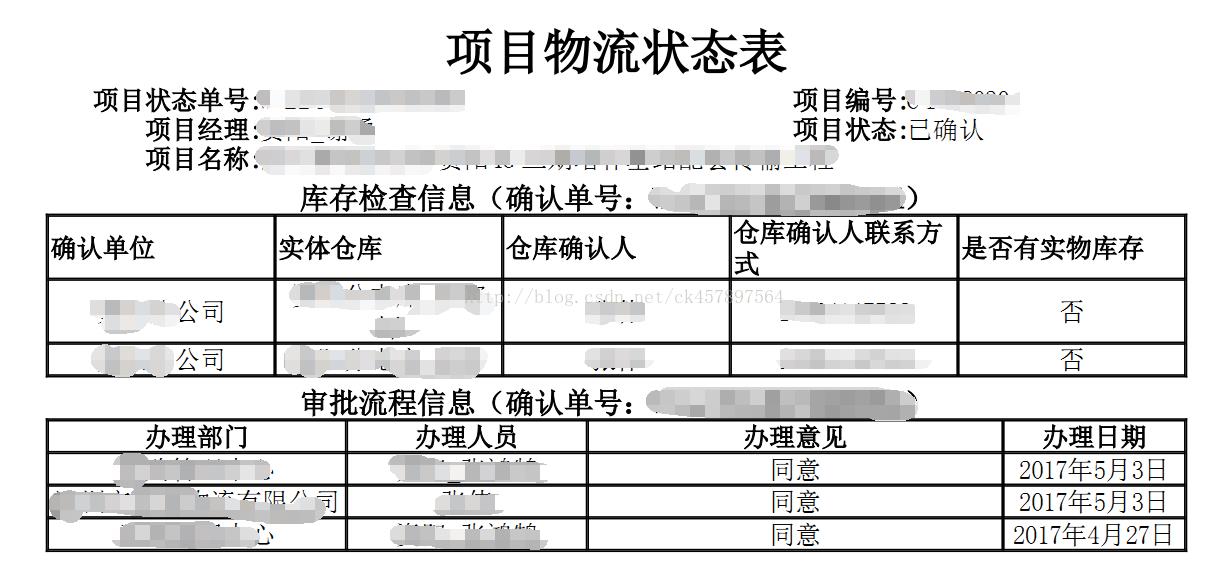
下面说说任务中的遇到的困难,上面说自动生成PDF时可以直接传入string类型的html或者URL,但这个URL要是课可以直接访问的,比如说网页的网址,但是我们的项目中有struts1会拦截没有登陆的,没有登陆就会跳转到登录页面,所以每次我用URL的去测试的时候,返回的始终是一个登录页面的html,其实我需要的就是一个动态的jsp生成PDF。
刚好,又让我找到了现成的方法,其实原理是:得到数据后,让jsp页面不输在浏览器上显示,而是输出到字节流最后以字符的形式返回,这样我就可以得到动态的jsp组装好后输出的静态的html,这样就得到了我想要的html。
具体的我直接po博主的博客吧http://www.cnblogs.com/Iran1112/p/6013474.html,这里面我学习了怎么让动态的jsp以流的方式输出html。
至于上传至服务器,要看看自己服务器要怎么存储了,一般的思路:先读写文件比如这样:
// 输入流
FileInputStream fi = new FileInputStream(fPath);
BufferedInputStream bi = new BufferedInputStream(fi);
// 输出流
FileOutputStream fo = new FileOutputStream(newFile);
BufferedOutputStream bo = new BufferedOutputStream(fo);
// 先定义一个字节缓冲区,减少I/O次数,提高读写效率
byte[] buf = new byte[1024];
int len = 0;
while ((len=bi.read(buf))!=-1){
bo.write(buf,0,len);
// 使缓冲的输出字节 被写到底层输出流中 避免电脑断电等特殊情况导致缓冲区中的数据被清空
bo.flush();
}
fi.close();
fo.close();
然后拿到文件的信息,比如说:文件名称、存储路径、大小...,再insert(存入)自己的表里面,基本上大概就是这样。
以上是关于自动把动态的jsp页面(或静态html)生成PDF文档,并且上传至服务器的主要内容,如果未能解决你的问题,请参考以下文章