编译原理词法分析器(C/C++)
Posted xiaoyuer2815
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译原理词法分析器(C/C++)相关的知识,希望对你有一定的参考价值。
前言&思路
词法分析器不用多说,一开始我还不知道是什么样的,看了下别人的博客,再看看书,原来是输出二元组,这不就是字符串操作嘛。然后细看几篇博客,发现大都是用暴力判断来写的。我对代码重复性比较高的方法不太感冒,不是说我编程有多好,就是单纯的不喜欢。
于是我就想到了用偏移量的方法,先弄好单词分类器,再用几个数组将关键字、运算符、界符的所有定义的字符串保存为全局变量,顺序要按单词分类器的顺序,然后根据这三种字符串在表中的位置,定一个偏移量。当输入的时候,将字符串进行切割提取,然后放到全局数组里面判断,返回下标加上偏移量,这样就可以得到这一个字符串在单词表中的位置(种别码)了,最后根据种别码的范围可以知道数据类型。
上面的思路说起来比较复杂,主要是我表达能力不太好,其实一看代码就明白了。
哦对了,补充一句,我要分析的语言是C语言,然后也是用C语言来写。但是因为有使用布尔类型,所以需要C++的运行环境。另外,我的代码没有代码检错。(老师没有要求)
NFA和DFA图
这两个图不是我画的,看看就好。
我要写的词法分析器有六个类型:关键字、界符、运算符、标识符、整型和浮点型。


单词分类表
关键字在网上找了32个,然后自己加了几个,运算符和界符都是百度找的,其中,运算符有>>=这种三个字符的,因为不是必要的我就删去了,这样方便写代码
| 单词符号 | 种类 | 种别码 |
| auto | 关键字 | 1 |
| bool | 关键字 | 2 |
| break | 关键字 | 3 |
| case | 关键字 | 4 |
| char | 关键字 | 5 |
| const | 关键字 | 6 |
| continue | 关键字 | 7 |
| default | 关键字 | 8 |
| do | 关键字 | 9 |
| double | 关键字 | 10 |
| else | 关键字 | 11 |
| enum | 关键字 | 12 |
| extern | 关键字 | 13 |
| float | 关键字 | 14 |
| for | 关键字 | 15 |
| goto | 关键字 | 16 |
| if | 关键字 | 17 |
| int | 关键字 | 18 |
| long | 关键字 | 19 |
| main | 关键字 | 20 |
| register | 关键字 | 21 |
| return | 关键字 | 22 |
| short | 关键字 | 23 |
| signed | 关键字 | 24 |
| sizeof | 关键字 | 25 |
| static | 关键字 | 26 |
| struct | 关键字 | 27 |
| switch | 关键字 | 28 |
| typedef | 关键字 | 29 |
| union | 关键字 | 30 |
| unsigned | 关键字 | 31 |
| void | 关键字 | 32 |
| volatile | 关键字 | 33 |
| while | 关键字 | 34 |
| scanf | 关键字 | 35 |
| printf | 关键字 | 36 |
| include | 关键字 | 37 |
| define | 关键字 | 38 |
| + | 运算符 | 39 |
| - | 运算符 | 40 |
| * | 运算符 | 41 |
| / | 运算符 | 42 |
| % | 运算符 | 43 |
| ++ | 运算符 | 44 |
| -- | 运算符 | 45 |
| == | 运算符 | 46 |
| != | 运算符 | 47 |
| > | 运算符 | 48 |
| < | 运算符 | 49 |
| >= | 运算符 | 50 |
| <= | 运算符 | 51 |
| && | 运算符 | 52 |
| || | 运算符 | 53 |
| ! | 运算符 | 54 |
| = | 运算符 | 55 |
| += | 运算符 | 56 |
| -= | 运算符 | 57 |
| *= | 运算符 | 58 |
| /= | 运算符 | 59 |
| %= | 运算符 | 60 |
| &= | 运算符 | 61 |
| ^= | 运算符 | 62 |
| |= | 运算符 | 63 |
| & | 运算符 | 64 |
| | | 运算符 | 65 |
| ^ | 运算符 | 66 |
| ~ | 运算符 | 67 |
| << | 运算符 | 68 |
| >> | 运算符 | 69 |
| ( | 界符 | 70 |
| ) | 界符 | 71 |
| [ | 界符 | 72 |
| ] | 界符 | 73 |
| 界符 | 74 | |
| 界符 | 75 | |
| . | 界符 | 76 |
| , | 界符 | 77 |
| ; | 界符 | 78 |
| ’ | 界符 | 79 |
| # | 界符 | 80 |
| ? | 界符 | 81 |
| ’’ | 界符 | 82 |
| 整型 | 整型 | 83 |
| 浮点型 | 浮点型 | 84 |
| 标识符 | 标识符 | 85 |
具体代码解释
下面是定义的全局变量,因为+-*/这些符号比较特殊,在VS里面运行会报错,所以我使用[]将它括起来,主要看报不报错吧,不报错可以直接写。
我这样用全局变量写的好处就是,当我需要添加关键字或者其他什么的时候,只需要修改下面这一部分的代码就好。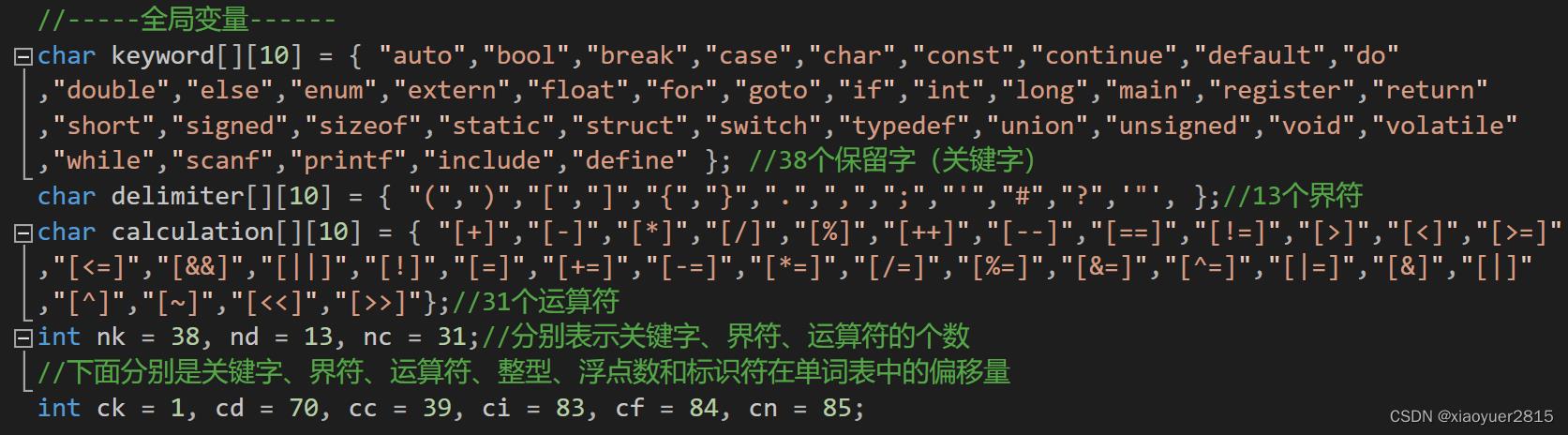
然后下面是函数的声明,具体就放在后面的源代码中了,看注释也可以很清楚的知道是做什么的。
其他都没什么好说的,还有一点就是下面,因为要返回一个字符串数组,所以我用静态局部变量来返回。
2023.3.26日补充:
有一个很关键的点忘记说了,这个思路还是挺重要的,就是如何不用暴力判断的方法提取出运算符。运算符的提取是在这个位置:

看一下代码,是不是特别简单?原本30个运算符只需要这十来行代码就可以从字符串中提取出来。这个思路我是觉得很好的,下面来讲一下我的思路。
因为运算符只有两种长度,1或者2(之前是有长度为3的,因为没必要我删掉了)。所以一开始我也是想直接暴力判断的,就是看第一位是什么,再看下一位是什么,能不能凑出和运算符里面一样的,然后差不多写完的时候发现,代码太多了,而且重复量很大,所以我就想能不能简单一点呢?然后我就简单列了个表。
+ 后缀:+,=
- 后缀:-,=
* 后缀:=
/ 后缀:=
% 后缀:=
= 后缀:=
! 后缀:=
> 后缀:>,=
< 后缀:<,=
& 后缀:&,=
| 后缀:|,=
^ 后缀:=
~ 后缀:无
列完了我就发现,除了一个单独会出现的~运算符外,其他运算符都是由单个运算符组合起来的,而且组合的话,要么第一个字符和第二个字符相等,要么就是第二个字符就是=(等号),按照这个思路,写出来的代码不就简单多了?解释完毕,应该很好理解哈哈。
更多的不进行分析,自行看代码注释。
源代码
用dev-c++或者vs、vsc都可以运行。(要是报错自己解决不了的可以找我)代码大概是160行,比其他博客少挺多的了,当然,我们老师没有要求我们进行代码的检错,所以我这就是很简单的字符串操作。
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#define Maxline 1024
//-----全局变量------
char keyword[][10] = "auto","bool","break","case","char","const","continue","default","do"
,"double","else","enum","extern","float","for","goto","if","int","long","main","register","return"
,"short","signed","sizeof","static","struct","switch","typedef","union","unsigned","void","volatile"
,"while","scanf","printf","include","define" ; //38个保留字(关键字)
char delimiter[][10] = "(",")","[","]","","",".",",",";","'","#","?",'"', ;//13个界符
char calculation[][10] = "[+]","[-]","[*]","[/]","[%]","[++]","[--]","[==]","[!=]","[>]","[<]","[>=]"
,"[<=]","[&&]","[||]","[!]","[=]","[+=]","[-=]","[*=]","[/=]","[%=]","[&=]","[^=]","[|=]","[&]","[|]"
,"[^]","[~]","[<<]","[>>]";//31个运算符
int nk = 38, nd = 13, nc = 31;//分别表示关键字、界符、运算符的个数
//下面分别是关键字、界符、运算符、整型、浮点数和标识符在单词表中的偏移量
int ck = 1, cd = 70, cc = 39, ci = 83, cf = 84, cn = 85;
//------函数声明------
bool pd_integer(char ch); //判断是否是整数
bool pd_character(char ch); //判断是否是字母
int pd_keyword(char s[]); //判断字符串是否是保留字(关键字)是则返回下标,否则返回-1
int pd_delimiter(char ch); //判断字符是否是界符,是返回下标,否则返回-1
int pd_calculation(char s[]); //判断字符串是否是运算符,是返回下标,否则返回-1
char* pd_spcode(int n); //根据种别码的范围判断类别
int search_spcode(char s[]); //查询字符串s的种别码
//------主函数------
int main()
char test[1030] = 0 ;
FILE* fp = fopen("test.txt", "r");
if (fp == NULL)
printf("打开文件失败!\\n");
return 0;
while (fgets(test, Maxline, fp) != NULL)
int i = 0, j = 0;
while (i < strlen(test))
if (test[i] == ' ' || test[i] == '\\n' || test[i] == '\\t')
i++;
continue;//遇到空格或换行符,跳过
bool flag = true;
char str[100] = 0 ;
j = 0;
if (pd_integer(test[i]))
//如果是数字,循环读取,包括小数点,因为可能是浮点数
while (pd_integer(test[i]) || (test[i] == '.' && flag))
if (test[i] == '.')flag = false;//浮点型只允许出现一个小数点
str[j++] = test[i++];
i--;
else if (pd_character(test[i]) || test[i] == '_')
//如果是字母或下划线或数字(标识符可以有数字)
while (pd_character(test[i]) || test[i] == '_' || pd_integer(test[i]))str[j++] = test[i++];
i--;
else if (test[i] == '+' || test[i] == '-' || test[i] == '*' || test[i] == '/'
|| test[i] == '%' || test[i] == '=' || test[i] == '!' || test[i] == '>'
|| test[i] == '<' || test[i] == '&' || test[i] == '|' || test[i] == '^')
if (test[i + 1] == '=' || test[i] == test[i + 1])
str[0] = test[i], str[1] = test[i + 1];
i++;
else
str[0] = test[i];
else
str[0] = test[i];
i++;
printf("( %s , %d )------%s\\n", str, search_spcode(str), pd_spcode(search_spcode(str)));
return 0;
//------函数实现------
bool pd_integer(char ch) //判断是否是整数
if (ch >= '0' && ch <= '9')return true;
return false;
bool pd_character(char ch) //判断是否是字母
if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z'))return true;
return false;
int pd_keyword(char s[]) //判断字符串是否是保留字(关键字)是则返回下标,否则返回-1
for (int i = 0; i < nk; i++)
if (strcmp(s, keyword[i]) == 0)return i;
return -1;
int pd_delimiter(char ch) //判断字符是否是界符,是返回下标,否则返回-1
for (int i = 0; i < nd; i++)
if (ch == delimiter[i][0])return i;
return -1;
int pd_calculation(char s[]) //判断字符是否是运算符,是返回下标,否则返回-1
for (int i = 0; i < nc; i++)
if (strlen(calculation[i]) - 2 == strlen(s)) //如果长度相等
bool flag = true;
for (int j = 1, k = 0; j < strlen(calculation[i]) - 1 && k < strlen(s); j++, k++)
if (calculation[i][j] != s[k])
flag = false;//有一个元素不等,标记后直接退出
break;
if (flag)return i;//返回下标
return -1;
char* pd_spcode(int n) //根据种别码的范围判断类别
static char name[20];//静态局部变量
if (n >= 1 && n <= nk) strcpy(name, "关键字");
else if (n >= cc && n < cd) strcpy(name, "运算符");
else if (n >= cd && n < ci) strcpy(name, "界符");
else if (n == ci) strcpy(name, "整型");
else if (n == cf)strcpy(name, "浮点型");
else if (n == cn) strcpy(name, "标识符");
else strcpy(name, "未识别");
return name;
int search_spcode(char s[]) //查询字符串s的种别码
if (pd_character(s[0])) //如果第一个字符是字母,说明是关键字或标识符
if (pd_keyword(s) != -1) //说明是关键字
return pd_keyword(s) + ck;//下标从0开始,要+1
else return cn; //否则就是标识符(标识符可以有下划线)
if (s[0] == '_')return cn;//下划线开头一定是标识符
if (pd_integer(s[0])) //开头是数字说明是整数或者浮点数
if (strstr(s, ".") != NULL)return cf;//如果有小数点说明是浮点型
return ci;//否则就是整型
if (strlen(s) == 1) //长度为1,说明是界符或者运算符
char ch = s[0];
if (pd_delimiter(ch) != -1)//判断是否是界符
return pd_delimiter(ch) + cd;
if (pd_calculation(s) != -1)//如果是运算符
return pd_calculation(s) + cc;
return -1;//否则就是未标识符
运行结果展示
运行后代码是使用文件进行输入的。
代码中最好不要有中文哈,因为没有处理中文,会有一堆未识别出来的(一个中文站字符串数组的两个位置)然后头文件里面,stdio.h里面的点可以不用理会,拆开就拆开了,老师不会考察这个的。
#include<stdio.h>
#include<string.h>
int main()
int n,_m,k=666;
scanf("%d %d",&n,&_m);
printf("%d+%d=%d",n,_m,n+_m);
return 0;
运行结果:
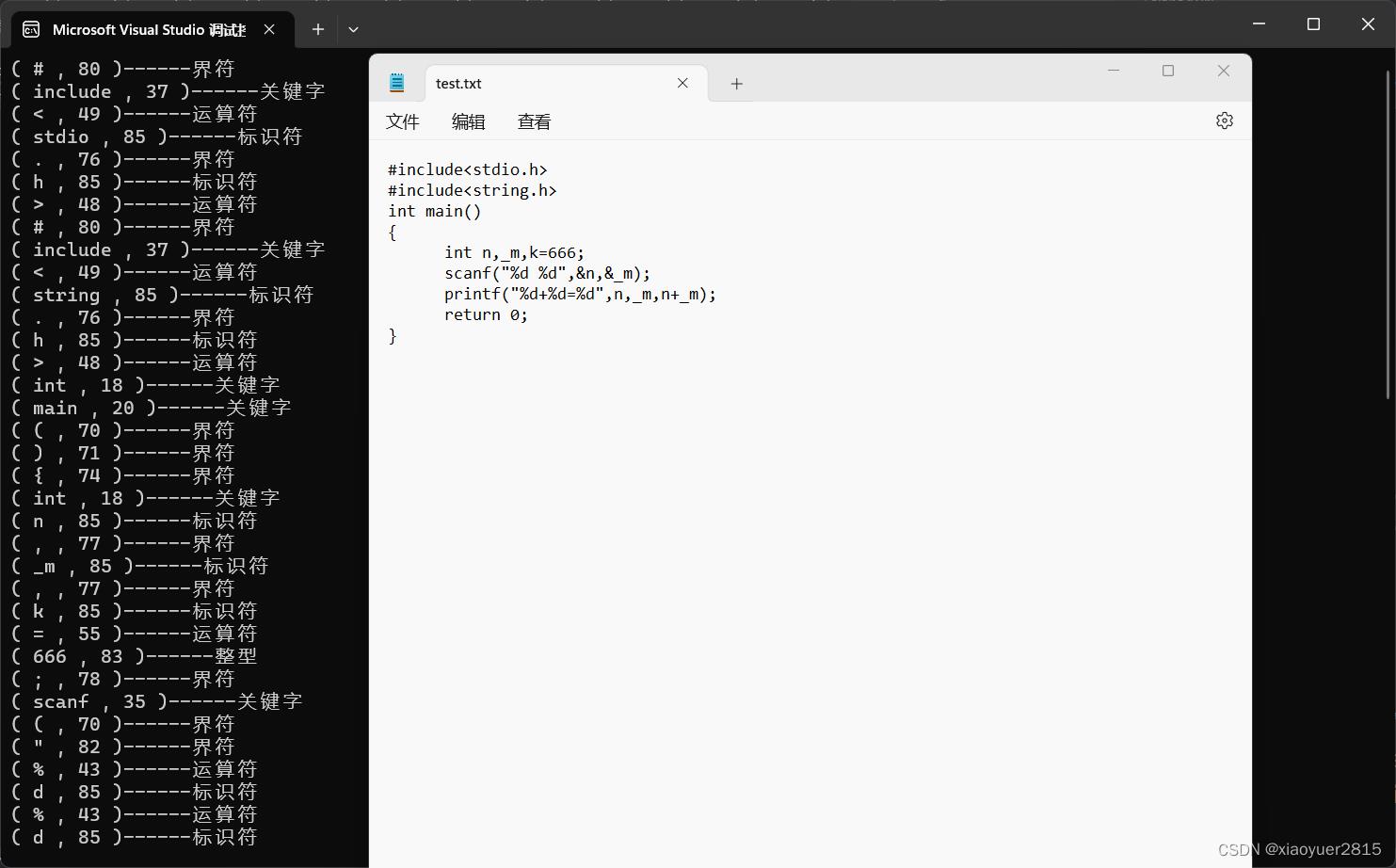
实验验收的时候不会有带有头文件和函数的,就算有也是加几个关键字就行。
词法分析器验收
我们老师的验收方式是当场给出题目,然后现场改代码,上完课改不完的估计是会扣分了。然后不需要写实验报告啥的,有好有坏吧。
如果你的老师也是说要出题目现场改代码的话,可以借鉴一下这个。
我也是今天验收了之后才来写这篇博客的。
题目:在源语言中,增加新的数据类型int36,请实现对下面代码段的词法分析
int36 a=A7,b=5TU,z=A+B;
int c=10;
for(int i=0;i<10;i++)
if(c%2==0)z=z+10;
else z=z+1Z;
c=c+1;
说明:
1、int36类型的常量都是大写,可以是字母开头,也可以是数字开头;可以全是数字,也可以全是大写字母。
2、除了int36的常量会大写外,凡是带有字母的都是小写字母。
3、int36当作关键字输出
例如:上面的代码中:z=z+10;中10是int36类型的,同类型才能相加,需要进行输出说明。
题目分析:
1、问题主要是如何标记int36类型的常量和区分代码中的3个10。
2、如果提取的字符串中带有大写字母,那么一定是int36类型的常量
3、直接分析10这种整型是int36还是int不现实,所以需要将int36类型的变量名称进行标记,可以将变量复制语句里面的等号前面的字母/数字/下划线提取出来,放到一个数组里面,当遇到完全是数字的时候进行判断,看等号前面的变量名在不在数组里面,如果在的话,说明这个整型其实是int36类型的常量,进行标记方便后面进行输出(后面输出的时候要取消标记)(目前我只想到这个方法,有其他想法的可以评论交流)
简单的几句分析,代码还是要进行挺大的改动的(只是在原有功能上面添加,原本的功能不变)。源代码就不进行解释了,相信大部分同学都是不用进行验收的。
验收后的源代码
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#define Maxline 1024
//-----全局变量------
char keyword[][10] = "auto","bool","break","case","char","const","continue","default","do"
,"double","else","enum","extern","float","for","goto","if","int","long","main","register","return"
,"short","signed","sizeof","static","struct","switch","typedef","union","unsigned","void","volatile"
,"while","scanf","printf","include","define","int36"; //39个保留字(关键字)
char delimiter[][10] = "(",")","[","]","","",".",",",";","'","#","?",'"',;//13个界符
char calculation[][10] = "[+]","[-]","[*]","[/]","[%]","[++]","[--]","[==]","[!=]","[>]","[<]","[>=]"
,"[<=]","[&&]","[||]","[!]","[=]","[+=]","[-=]","[*=]","[/=]","[%=]","[&=]","[^=]","[|=]","[&]","[|]"
,"[^]","[~]","[<<]","[>>]";//31个运算符
int nk = 39, nd = 13, nc = 31;//分别表示关键字、界符、运算符的个数
//下面分别是关键字、界符、运算符、整型、浮点数和标识符在单词表中的偏移量,int36类型为87;
int ck = 1, cd = 71, cc = 40, ci = 84, cf = 85, cn = 86, cint36 = 87;
char int36[100][100]; //int36类型的变量标识符
int p = 0;
bool flag3 = false, flag4 = false;//用于标记
//------函数声明------
bool pd_integer(char ch); //判断是否是数字
bool pd_character(char ch); //判断是否是小写字母
bool pd_character2(char ch); //判断是否是大写字母
int pd_keyword(char s[]); //判断字符串是否是保留字(关键字)是则返回下标,否则返回-1
int pd_delimiter(char ch); //判断字符是否是界符,是返回下标,否则返回-1
int pd_calculation(char s[]); //判断字符串是否是运算符,是返回下标,否则返回-1
char* pd_spcode(int n); //根据种别码的范围判断类别
bool pd_int36(char s[]); //判断是否是int36类型的变量
int search_spcode(char s[]); //查询字符串s的种别码
//------主函数------
int main(int argc,void *argv)
char test[1030] = 0 ;
FILE* fp = fopen("test.txt", "r");
if (fp == NULL)
printf("打开文件失败!\\n");
return 0;
while (fgets(test, Maxline, fp) != NULL)
int i = 0, j = 0;
while (i < strlen(test))
if (test[i] == ' ' || test[i] == '\\n' || test[i] == '\\t')
i++;
continue;//遇到空格或换行符,跳过
bool flag = true;
char str[100] = 0 ;
j = 0;
if (test[i] == 'i' && test[i + 1] == 'n' && test[i + 2] == 't' && test[i + 3] == '3' && test[i + 4] == '6')
str[j++] = test[i];
str[j++] = test[i + 1];
str[j++] = test[i + 2];
str[j++] = test[i + 3];
str[j] = test[i + 4];
i += 4;
//printf("%s\\n", str);
else if (pd_character2(test[i]))
while (pd_character2(test[i]) || pd_integer(test[i]))str[j++] = test[i++];
i--;
else if (pd_integer(test[i]))
//如果是数字,循环读取,包括小数点,因为可能是浮点数
int k = i;
bool flag2 = false;
while (pd_integer(test[k]) || pd_character2(test[k]))
if (pd_character2(test[k]))flag2 = true;
k++;
if (flag2)
while (pd_integer(test[i]) || pd_character2(test[i]))
if (test[i] == '.')flag = false;//浮点型只允许出现一个小数点
str[j++] = test[i++];
else
while (pd_integer(test[i]) || (test[i] == '.' && flag))
if (test[i] == '.')flag = false;//浮点型只允许出现一个小数点
str[j++] = test[i++];
i--;
if (search_spcode(str) == ci) //如果是整型,判断是否是int36类型
k = i;
int l = 0;
char str1[20] = 0 , str2[20] = 0 ;//用一个新建的变量来保存变量
while (test[k] != '=' || test[k] == ' ')k--;//test[k]=='=';
k--;
while (pd_integer(test[k]) || pd_character(test[k]) || test[k] == '_')
str1[l++] = test[k];
k--;
//将变量名倒过来
int jj = 0;
for (int ii = 0; ii < l; ii++)
str2[jj++] = str1[l - ii - 1];
if (pd_int36(str2)) flag4 = true;
else if (pd_character(test[i]) || test[i] == '_')
//如果是字母或下划线或数字(标识符可以有数字)
while (pd_character(test[i]) || test[i] == '_'||pd_integer(test[i]))str[j++] = test[i++];
i--;
else if (test[i] == '+' || test[i] == '-' || test[i] == '*' || test[i] == '/'
|| test[i] == '%' || test[i] == '=' || test[i] == '!' || test[i] == '>'
|| test[i] == '<' || test[i] == '&' || test[i] == '|' || test[i] == '^')
if (test[i + 1] == '=' || test[i] == test[i + 1])
str[0] = test[i], str[1] = test[i+1];
i++;
else
str[0] = test[i];
else
str[0] = test[i];
i++;
if (strcmp(str, "int36") == 0 && !flag3)flag3 = true;
else if (str[0] == ';' && flag3)flag3 = false;
if (flag3 && (str[0] == '_' || pd_character(str[0])))
if (!pd_int36(str))strcpy(int36[p++], str);//如果变量不在数组里面,就放进去
int a = search_spcode(str);//用一个变量临时保存种别码
printf("( %s , %d )------%s\\n", str, a, pd_spcode(a));
//for (int i = 0; i < p; i++)printf("%s\\n", int36[i]);//测试用
return 0;
//------函数实现------
bool pd_integer(char ch) //判断是否是整数
if (ch >= '0' && ch <= '9')return true;
return false;
bool pd_character(char ch) //判断是否是小写字母
if ((ch >= 'a' && ch <= 'z'))return true;
return false;
bool pd_character2(char ch) //判断是否是大写字母
if ((ch >= 'A' && ch <= 'Z'))return true;
return false;
int pd_keyword(char s[]) //判断字符串是否是保留字(关键字)是则返回下标,否则返回-1
for (int i = 0; i < nk; i++)
if (strcmp(s, keyword[i]) == 0)return i;
return -1;
int pd_delimiter(char ch) //判断字符是否是界符,是返回下标,否则返回-1
for (int i = 0; i < nd; i++)
if (ch == delimiter[i][0])return i;
return -1;
int pd_calculation(char s[]) //判断字符是否是运算符,是返回下标,否则返回-1
for (int i = 0; i < nc; i++)
if (strlen(calculation[i]) - 2 == strlen(s)) //如果长度相等
bool flag = true;
for(int j=1,k=0;j<strlen(calculation[i])-1&&k<strlen(s);j++,k++)
if (calculation[i][j] != s[k])
flag = false;//有一个元素不等,标记后直接退出
break;
if (flag)return i;//返回下标
return -1;
bool pd_int36(char s[]) //判断是否是int36类型的变量
for (int i = 1; i < p; i++)
if (strcmp(int36[i], s) == 0) return true;
return false;
char* pd_spcode(int n) //根据种别码的范围判断类别
static char name[20];//静态局部变量
if (n >= 1 && n <= nk) strcpy(name, "关键字");
else if (n >= cc && n < cd) strcpy(name, "运算符");
else if (n >= cd && n < ci) strcpy(name, "界符");
else if (n == ci) strcpy(name, "整型");
else if (n == cf)strcpy(name, "浮点型");
else if (n == cn) strcpy(name, "标识符");
else if (n == cint36)
strcpy(name, "int36");
flag4 = false;//取消标记
else strcpy(name,"未识别");
return name;
int search_spcode(char s[]) //查询字符串s的种别码
if (pd_character2(s[0]))return cint36;
for (int i = 0; i < strlen(s); i++)
if (pd_character2(s[i])) return cint36;
if (pd_character(s[0])) //如果第一个字符是小写字母,说明是关键字或标识符
if (pd_keyword(s) != -1) //说明是关键字
return pd_keyword(s) + ck;//下标从0开始,要+1
else return cn; //否则就是标识符(标识符可以有下划线)
if (s[0] == '_')return cn;//下划线开头一定是标识符
if (pd_integer(s[0])) //开头是数字说明是整数或者浮点数
if (flag4) return cint36;//如果被做了标记,说明是int36类型
if (strstr(s, ".") != NULL)return cf;//如果有小数点说明是浮点型
return ci;//否则就是整型
if (strlen(s) == 1) //长度为1,说明是界符或者运算符
char ch = s[0];
if (pd_delimiter(ch) != -1)//判断是否是界符
return pd_delimiter(ch) + cd;
if (pd_calculation(s) != -1)//如果是运算符
return pd_calculation(s) + cc;
return -1;//否则就是未标识符
验收后代码运行结果
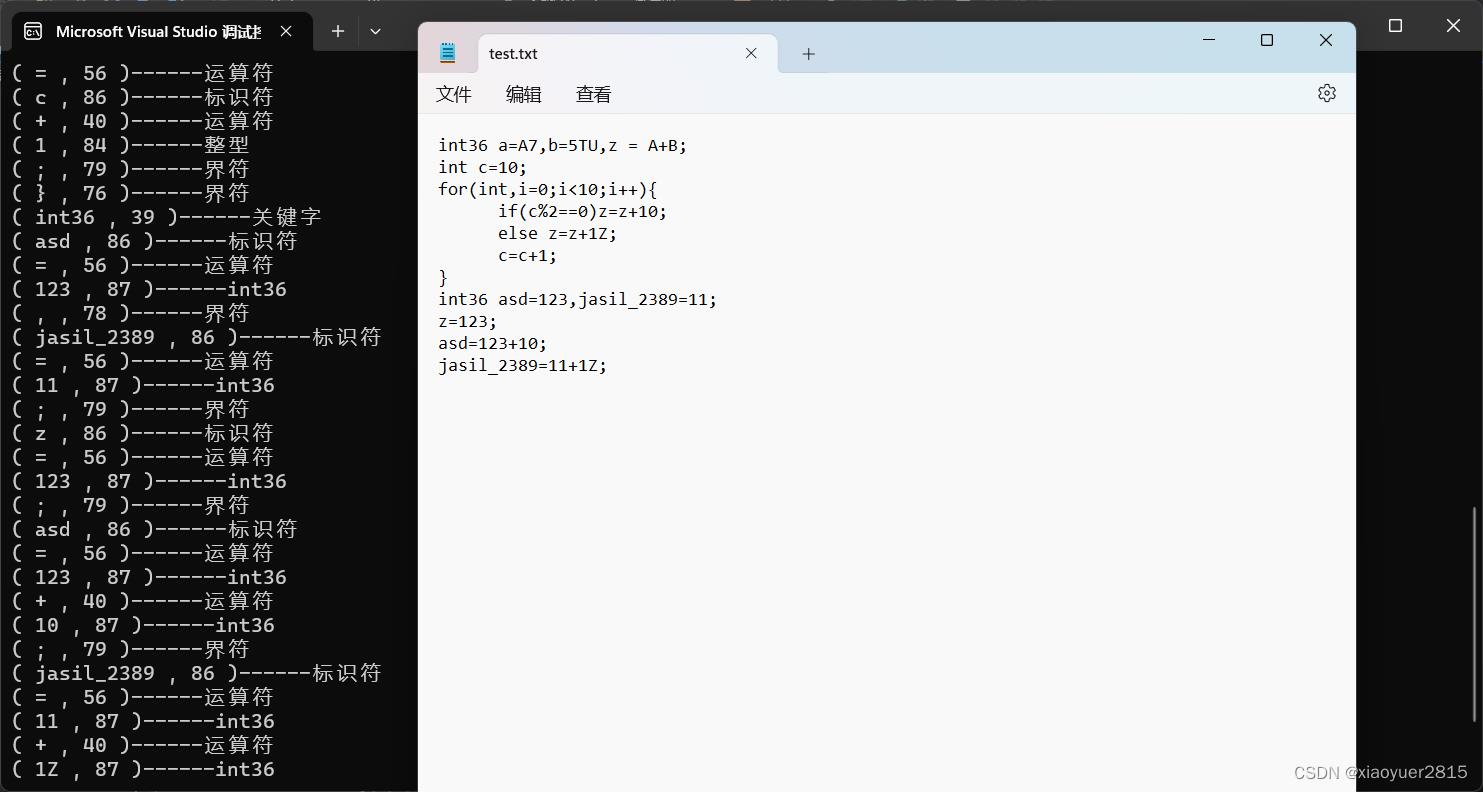
我加多了几条语句,测试结果都是正确的,应该没有什么问题了。
有问题可以评论提问或者私信我。(担心代码有bug)
验收感想
平时写代码还是太顺了,验收的时候竟然卡在了将局部变量当成全局变量来用,一直得不到想要的结果。果然一紧张就会犯错,还是需要进行更多的练习。要提高自身的抗压能力。
实验一 词法分析器+编译原理
实验一 词法分析器+【编译原理】
前言
2023-4-2 20:04:46
以下内容源自《【编译原理】》
仅供学习交流使用
推荐
实验一 词法分析器【编译原理】
实验一 词法分析器+
书接上文
要求:代码的高级功能
更多的关键字(运算符)
需要编写keywords.txt
更多的常数(科学计数法 浮点数 字符串常量)
需要重写analyzer
更多的功能(过滤无效字符、数值转换、宏展开、预包含处理)
需要重写analyzer
还有
出错位置没有行数
需要修改loadInput()逻辑
使其每读入一行,就进行语法分析处理
并且需要row行数属性来配合
下面实现C语言的词法分析
keywords.txt
除了32个关键字,还有用户预编译单词
并把34种运算符拆开为符号
有可能仍有遗漏
1 include
2 define
3 ifdef
4 ifndef
5 auto
6 break
7 case
8 char
9 const
10 continue
11 default
12 do
13 double
14 else
15 enum
16 extern
17 float
18 for
19 goto
20 if
21 int
22 long
23 register
24 return
25 short
26 signed
27 sizeof
28 static
29 struct
30 switch
31 typedef
32 union
33 unsigned
34 void
35 volatile
36 while
此处没有了
identifierList
constantList
operators.txt
新建一个运算符表
注意:
虽然有重复的但是他们的功能不一样
需要根据上下文环境确定具体功能
1 #
2 $
3 ‘
4 “
5 \\
6
7
8 ;
9 (
10 )
11 [
12 ]
13 ->
14 .
15 !
16 ~
17 ++
18 --
19 +
20 -
21 *
22 &
23 *
24 /
25 %
26 +
27 -
28 <<
29 >>
30 <
31 <=
32 >
33 >=
34 ==
35 !=
36 &
37 ^
38 |
39 &&
40 ||
41 ?
42 :
43 =
44 +=
45 -=
46 *=
47 /=
48 %=
49 <<=
50 >>=
51 &=
52 ^=
53 |=
54 ,
测试
package s1;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class SeniorLexicalAnalyzer extends AbstractLexicalAnalyzer
public List<Symbol> operatorList=new ArrayList<>();//运算符表
//创建关键字表 根据表3.1实现
File file = new File("operators.txt");
if (file.exists())
System.out.println("operators.txt文件存在");
System.out.println("读取文件,加载运算符表");
loadOperatorList();
else
System.out.println("operators.txt文件不存在");
System.out.println("采用默认的运算符表");
initOperatorList();
//读取operators.txt文件的内容加载到operatorList中
public void loadOperatorList()
try
BufferedReader reader = new BufferedReader(new FileReader("operators.txt"));
String line;
while ((line = reader.readLine()) != null)
String[] arr = line.split("\\\\s+");
operatorList.add(new Symbol(Integer.parseInt(arr[0]), arr[1]));
reader.close();
catch (IOException e)
e.printStackTrace();
//默认的运算符表
public void initOperatorList()
keywordList.add(new Symbol(1,"="));
keywordList.add(new Symbol(2,"+"));
keywordList.add(new Symbol(3,"*"));
keywordList.add(new Symbol(4,"**"));
keywordList.add(new Symbol(5,","));
keywordList.add(new Symbol(6,"("));
keywordList.add(new Symbol(7,")"));
//重写 状态转移图实现
@Override
public void analyzer()
//测试词法分析器
private void testAnalyzers()
//重写出错处理,跳过1下,继续分析
@Override
public void procError()
System.out.println("词法分析出错"+"\\n"+"出错位置为"+position);
System.out.println("跳过错误,继续分析");
position++;
if(ch!=EOF)
ch=' ';
//测试关键词表的赋值
private void testKeywordList()
for (Symbol s:keywordList)
System.out.println(s);
//测试运算符表的赋值
private void testOperatorList()
for (Symbol s:operatorList)
System.out.println(s);
public static void main(String[] args)
SeniorLexicalAnalyzer lex = new SeniorLexicalAnalyzer();
//测试
lex.testKeywordList();
lex.testOperatorList();
//测试
// new SeniorLexicalAnalyzer().testAnalyzers();
重申:
关键词表中的code没有什么意义
只有单词表中的code有意义
所以运算符表中就没有设置code
测试结果
keywords.txt文件存在
读取文件,加载关键词表
operators.txt文件存在
读取文件,加载运算符表
Symbolid=1, value='include', code=0
Symbolid=2, value='define', code=1
Symbolid=3, value='ifdef', code=2
Symbolid=4, value='ifndef', code=3
Symbolid=5, value='auto', code=4
Symbolid=6, value='break', code=5
Symbolid=7, value='case', code=6
Symbolid=8, value='char', code=7
Symbolid=9, value='const', code=8
Symbolid=10, value='continue', code=9
Symbolid=11, value='default', code=10
Symbolid=12, value='do', code=11
Symbolid=13, value='double', code=12
Symbolid=14, value='else', code=13
Symbolid=15, value='enum', code=14
Symbolid=16, value='extern', code=15
Symbolid=17, value='float', code=16
Symbolid=18, value='for', code=17
Symbolid=19, value='goto', code=18
Symbolid=20, value='if', code=19
Symbolid=21, value='int', code=20
Symbolid=22, value='long', code=21
Symbolid=23, value='register', code=22
Symbolid=24, value='return', code=23
Symbolid=25, value='short', code=24
Symbolid=26, value='signed', code=25
Symbolid=27, value='sizeof', code=26
Symbolid=28, value='static', code=27
Symbolid=29, value='struct', code=28
Symbolid=30, value='switch', code=29
Symbolid=31, value='typedef', code=30
Symbolid=32, value='union', code=31
Symbolid=33, value='unsigned', code=32
Symbolid=34, value='void', code=33
Symbolid=35, value='volatile', code=34
Symbolid=36, value='while', code=35
Symbolid=1, value='#', code=0
Symbolid=2, value='$', code=0
Symbolid=3, value='‘', code=0
Symbolid=4, value='“', code=0
Symbolid=5, value='\\', code=0
Symbolid=6, value='', code=0
Symbolid=7, value='', code=0
Symbolid=8, value=';', code=0
Symbolid=9, value='(', code=0
Symbolid=10, value=')', code=0
Symbolid=11, value='[', code=0
Symbolid=12, value=']', code=0
Symbolid=13, value='->', code=0
Symbolid=14, value='.', code=0
Symbolid=15, value='!', code=0
Symbolid=16, value='~', code=0
Symbolid=17, value='++', code=0
Symbolid=18, value='--', code=0
Symbolid=19, value='+', code=0
Symbolid=20, value='-', code=0
Symbolid=21, value='*', code=0
Symbolid=22, value='&', code=0
Symbolid=23, value='*', code=0
Symbolid=24, value='/', code=0
Symbolid=25, value='%', code=0
Symbolid=26, value='+', code=0
Symbolid=27, value='-', code=0
Symbolid=28, value='<<', code=0
Symbolid=29, value='>>', code=0
Symbolid=30, value='<', code=0
Symbolid=31, value='<=', code=0
Symbolid=32, value='>', code=0
Symbolid=33, value='>=', code=0
Symbolid=34, value='==', code=0
Symbolid=35, value='!=', code=0
Symbolid=36, value='&', code=0
Symbolid=37, value='^', code=0
Symbolid=38, value='|', code=0
Symbolid=39, value='&&', code=0
Symbolid=40, value='||', code=0
Symbolid=41, value='?', code=0
Symbolid=以上是关于编译原理词法分析器(C/C++)的主要内容,如果未能解决你的问题,请参考以下文章