分析Ajax并爬取微博列表
Posted 一蓑烟雨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分析Ajax并爬取微博列表相关的知识,希望对你有一定的参考价值。
Ajax,全称为Asynchronous javascript and XML,即异步的JavaScript和XML。它不是一门编程语言,而是利用JavaScript在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。
对于传统的网页,如果想更新其内容,那么必须要刷新整个页面,但有了Ajax,便可以在页面不被全部刷新的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行了数据交互,获取到数据之后,再利用JavaScript改变网页,这样网页内容就会更新了。
浏览网页的时候,我们会发现很多网页都有下滑查看更多的选项。比如,拿微博来说,牛客网微博为例,https://m.weibo.cn/u/2165760972 切换到微博页面,一直下滑,可以发现下滑几个微博之后,再向下就没有了,转而会出现一个加载的动画,不一会儿下方就继续出现了新的微博内容,这个过程其实就是Ajax加载的过程。
我们注意到页面其实并没有整个刷新,也就意味着页面的链接没有变化,但是网页中却多了新内容,也就是后面刷出来的新微博。这就是通过Ajax获取新数据并呈现的过程。
初步了解了Ajax之后,我们再来详细了解它的基本原理。发送Ajax请求到网页更新的这个过程可以简单分为以下3步:
(1) 发送请求; (2) 解析内容; (3) 渲染网页。
借助浏览器的开发者工具,在Elements选项卡中便会观察到网页的源代码,右侧便是节点的样式。不过这不是我们想要寻找的内容。切换到Network选项卡,随后重新刷新页面,可以发现这里出现了非常多的条目,这里其实就是在页面加载过程中浏览器与服务器之间发送请求和接收响应的所有记录。
Ajax其实有其特殊的请求类型,它叫作xhr。我们可以发现一个名称以getIndex开头的请求,其Type为xhr,这就是一个Ajax请求。用鼠标点击这个请求,可以查看这个请求的详细信息。
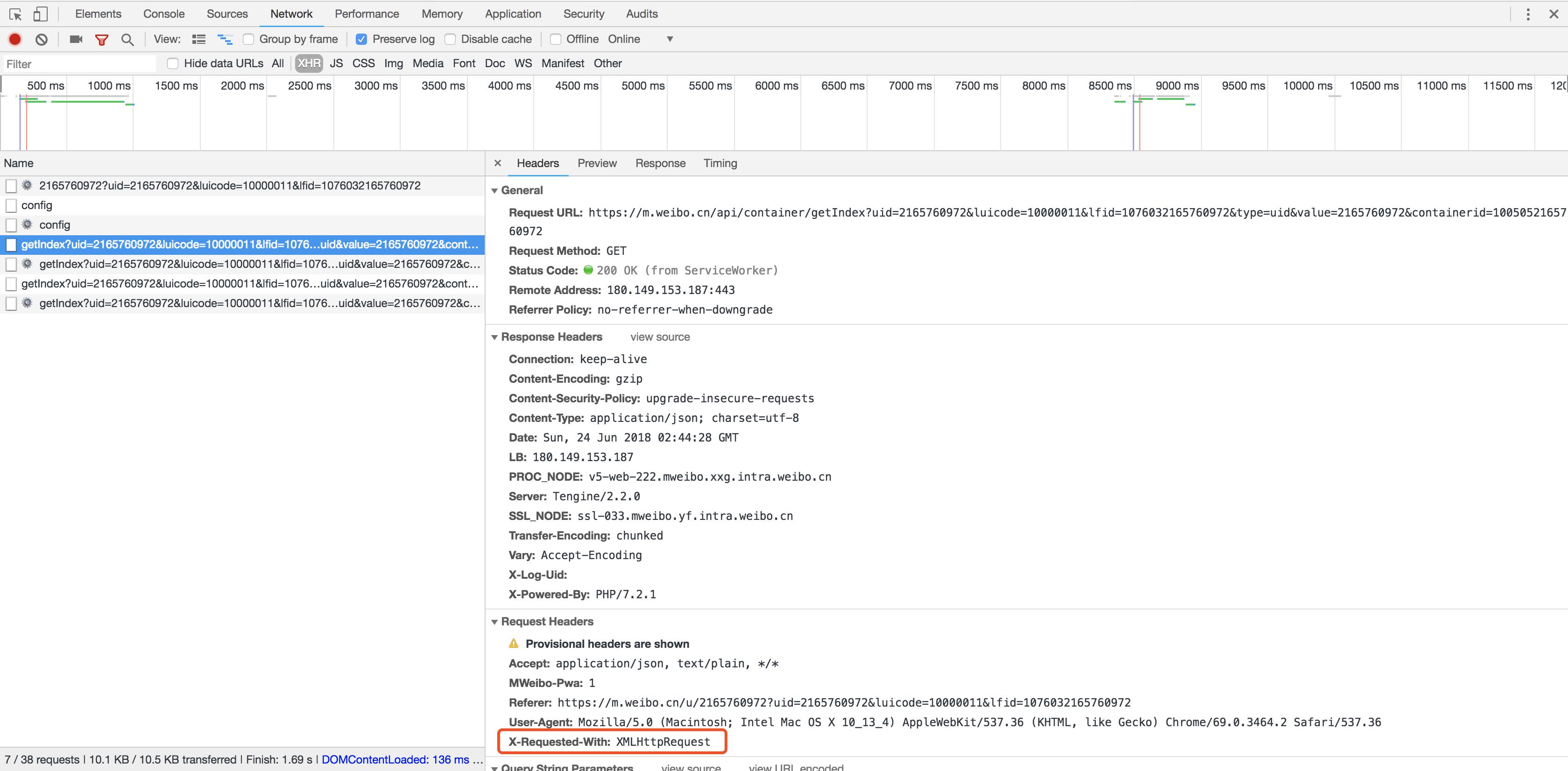
在右侧可以观察到其Request Headers、URL和Response Headers等信息。其中Request Headers中有一个信息为X-Requested-With:XMLHttpRequest,这就标记了此请求是Ajax请求,如图
随后点击一下Preview,即可看到响应的内容,它是JSON格式的。这里Chrome为我们自动做了解析,点击箭头即可展开和收起相应内容,如图:
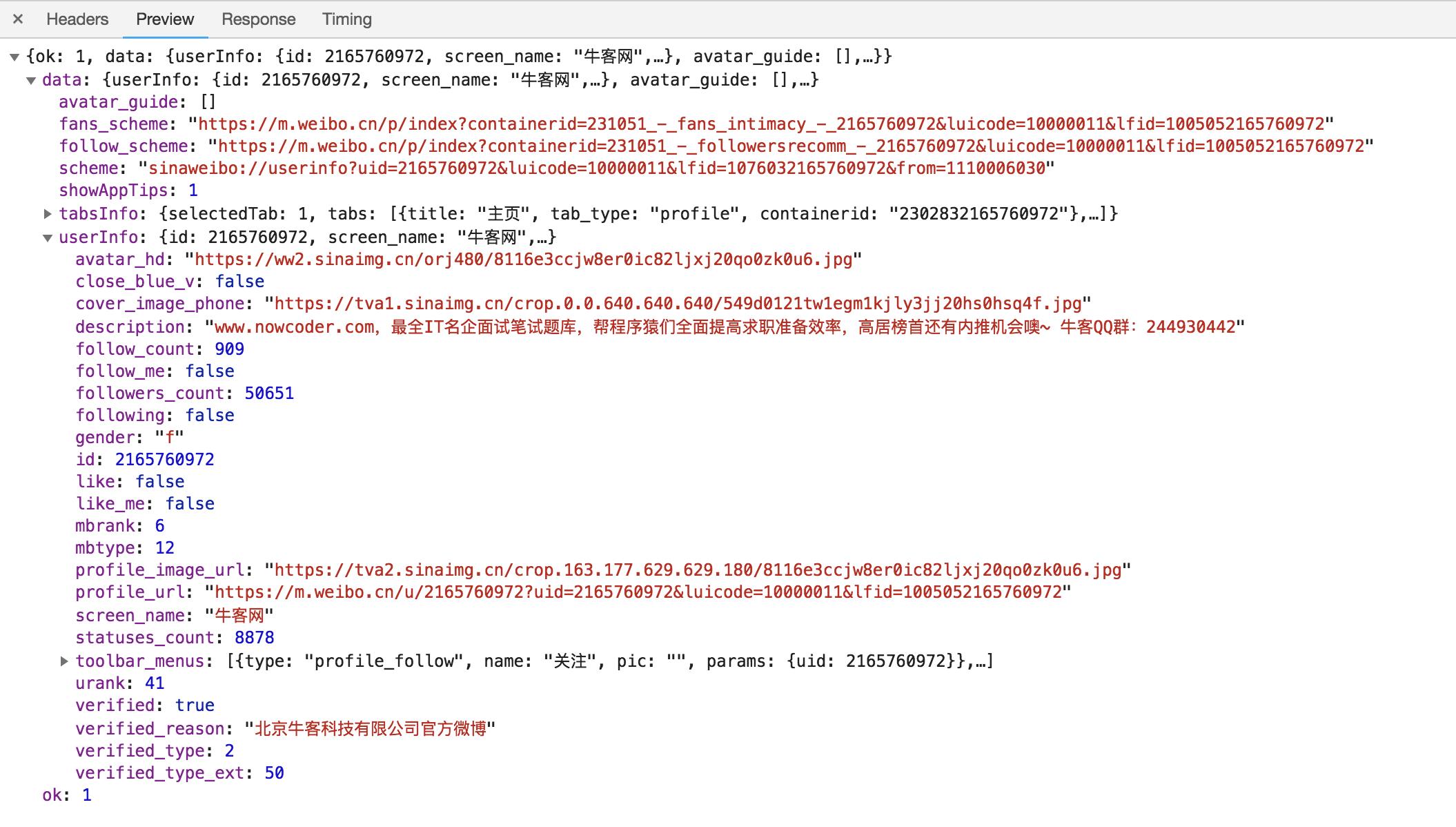
这里的返回结果是个人信息,如昵称、简介、头像等,这也是用来渲染个人主页所使用的数据。JavaScript接收到这些数据之后,再执行相应的渲染方法,整个页面就渲染出来了。
也可以切换到Response选项卡,从中观察到真实的返回数据,代码结构也非常简单,只是执行了一些JavaScript。
所以说,我们看到的微博页面的真实数据并不是最原始的页面返回的,而是后来执行JavaScript后再次向后台发送了Ajax请求,浏览器拿到数据后再进一步渲染出来的。
利用Chrome开发者工具的筛选功能筛选出所有的Ajax请求。在请求的上方有一层筛选栏,直接点击XHR,此时在下方显示的所有请求便都是Ajax请求了。
分析参数信息
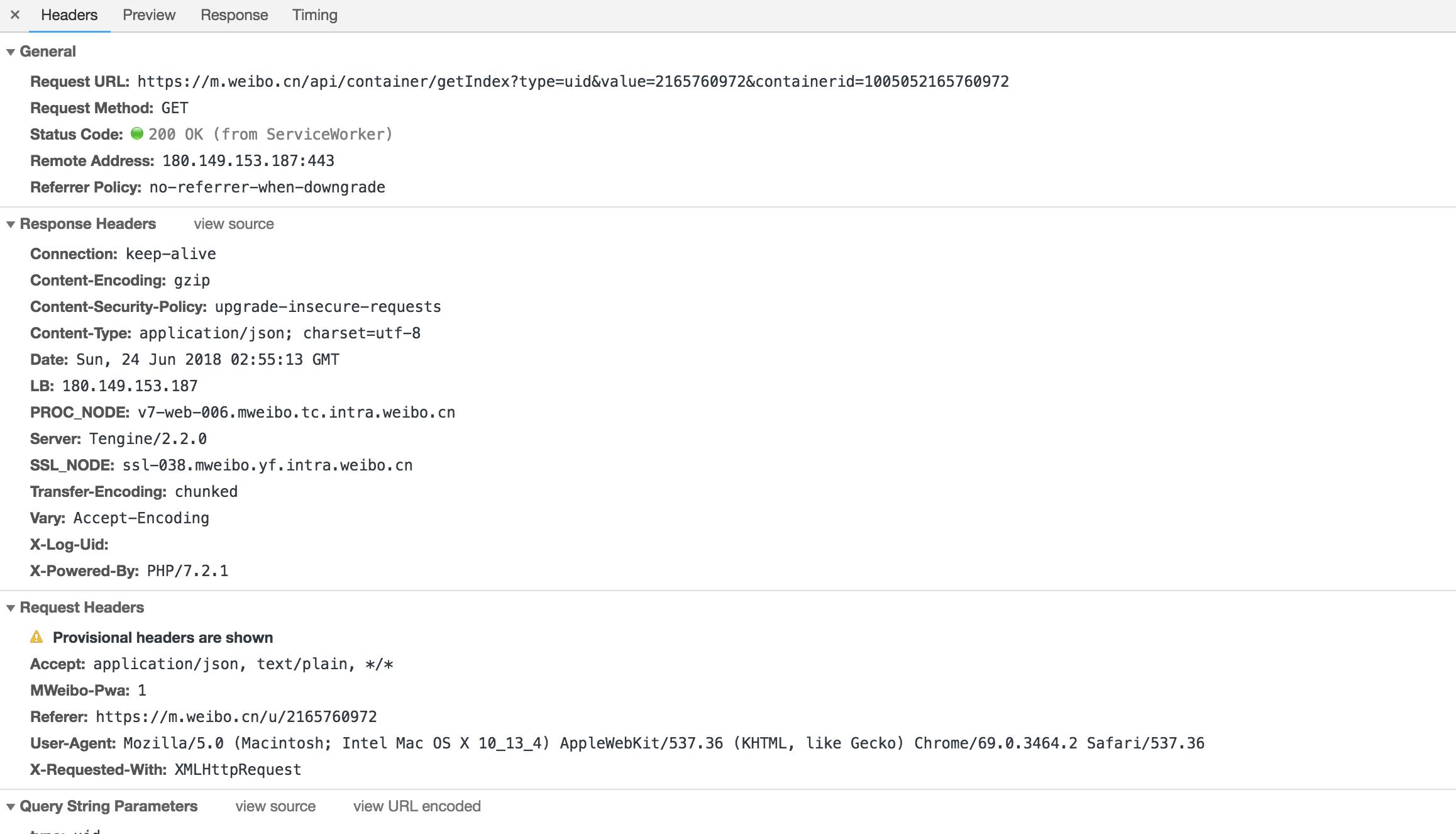
可以发现,这是一个GET类型的请求,请求链接为https://m.weibo.cn/api/container/getIndex?type=uid&value=2165760972&containerid=1005052165760972。
网页下滑:https://m.weibo.cn/api/container/getIndex?type=uid&value=2165760972&containerid=1076032165760972&page=2
请求的参数有4个:type、value、containerid和page。
随后再看看其他请求,可以发现,它们的type、value和containerid始终如一。type始终为uid,value的值就是页面链接中的数字,其实这就是用户的id。另外,还有containerid。可以发现,它就是107603加上用户id。改变的值就是page,很明显这个参数是用来控制分页的,page=1代表第一页,page=2代表第二页,以此类推。
观察这个请求的响应内容
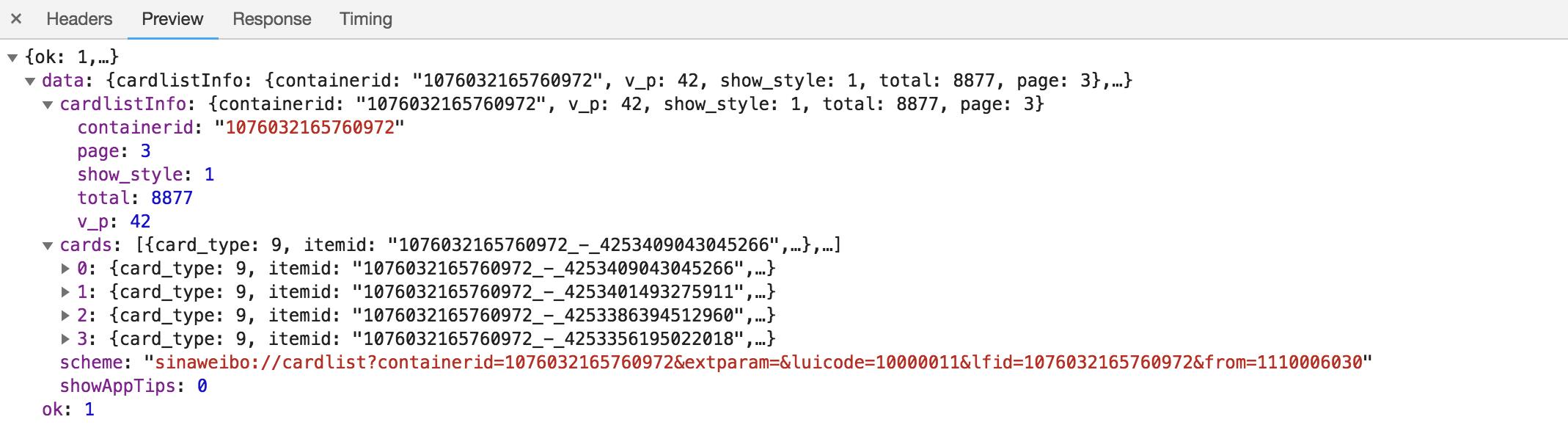
这个内容是JSON格式的,浏览器开发者工具自动做了解析以方便我们查看。可以看到,最关键的两部分信息就是cardlistInfo和cards:前者包含一个比较重要的信息total,观察后可以发现,它其实是微博的总数量,我们可以根据这个数字来估算分页数;后者则是一个列表,它包含10个元素,展开其中一个看一下。
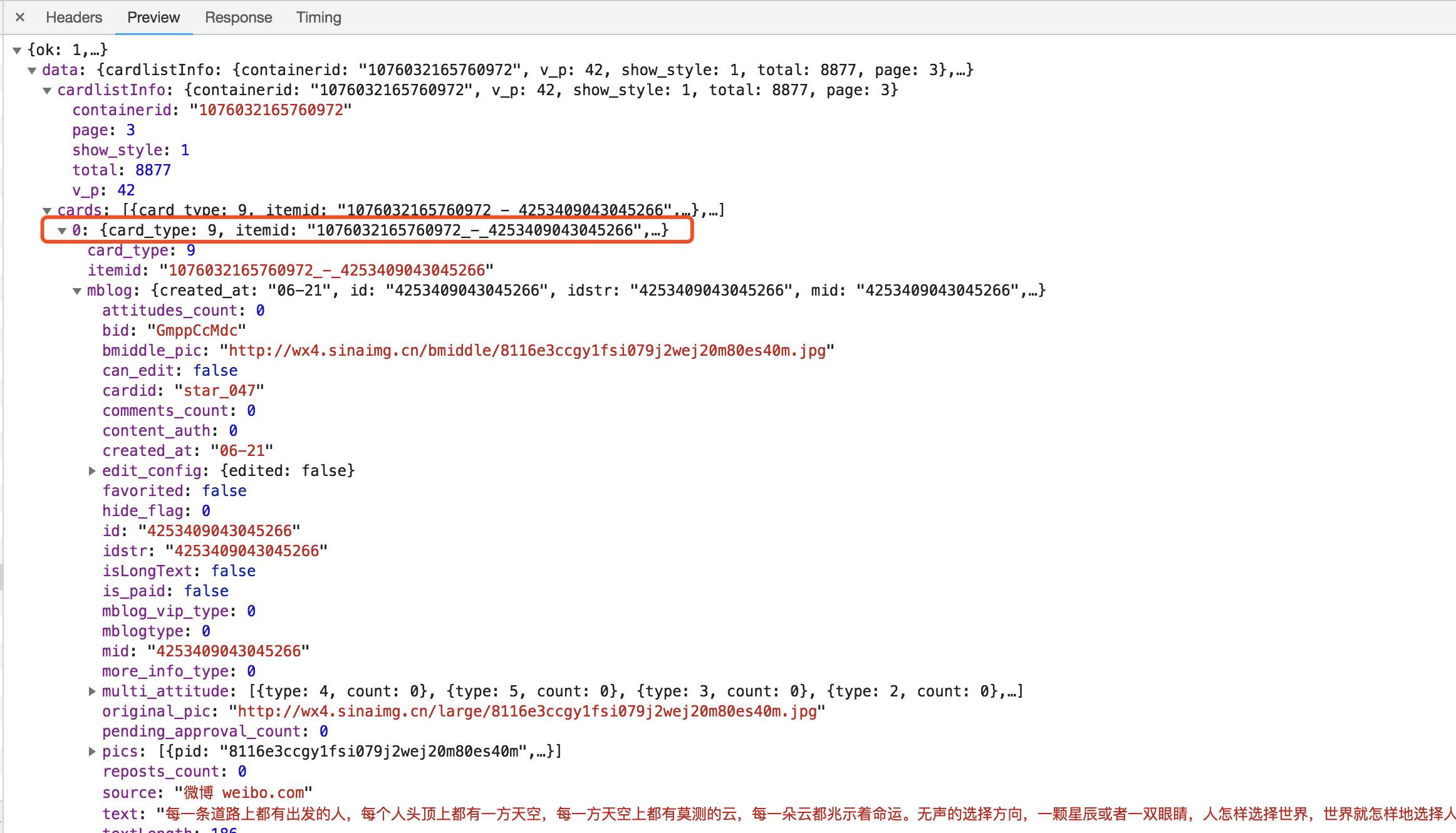
可以发现,这个元素有一个比较重要的字段mblog。展开它,可以发现它包含的正是微博的一些信息,比如attitudes_count(赞数目)、comments_count(评论数目)、reposts_count(转发数目)、created_at(发布时间)、text(微博正文)等,而且它们都是一些格式化的内容。
这样我们请求一个接口,就可以得到10条微博,而且请求时只需要改变page参数即可。
这样的话,我们只需要简单做一个循环,就可以获取所有微博了。
这里我们用程序模拟这些Ajax请求,将前10页微博全部爬取下来。
首先,定义一个方法来获取每次请求的结果。在请求时,page是一个可变参数,所以我们将它作为方法的参数传递进来,相关代码如下:
from urllib.parse import urlencode import requests base_url = \'https://m.weibo.cn/api/container/getIndex?\' headers = { \'Host\': \'m.weibo.cn\', \'Referer\': \'https://m.weibo.cn/u/2165760972\', \'User-Agent\': \'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/58.0.3029.110 Safari/537.36\', \'X-Requested-With\': \'XMLHttpRequest\', } def get_page(page): params = { \'type\': \'uid\', \'value\': \'2165760972\', \'containerid\': \'1076032165760972\', \'page\': page } url = base_url + urlencode(params) try: response = requests.get(url, headers=headers) if response.status_code == 200: return response.json() except requests.ConnectionError as e: print(\'Error\', e.args)
首先,这里定义了base_url来表示请求的URL的前半部分。接下来,构造参数字典,其中type、value和containerid是固定参数,page是可变参数。接下来,调用urlencode()方法将参数转化为URL的GET请求参数,即类似于type=uid&value=
首先,这里定义了base_url来表示请求的URL的前半部分。接下来,构造参数字典,其中type、value和containerid是固定参数,page是可变参数。接下来,调用urlencode()方法将参数转化为URL的GET请求参数,即类似于type=uid&value=2165760972&containerid=1076032165760972&page=2这样的形式。随后,base_url与参数拼合形成一个新的URL。接着,我们用requests请求这个链接,加入headers参数。然后判断响应的状态码,如果是200,则直接调用json()方法将内容解析为JSON返回,否则不返回任何信息。如果出现异常,则捕获并输出其异常信息。
随后,我们需要定义一个解析方法,用来从结果中提取想要的信息,比如这次想保存微博的id、正文、赞数、评论数和转发数这几个内容,那么可以先遍历cards,然后获取mblog中的各个信息,赋值为一个新的字典返回即可:
from pyquery import PyQuery as pq def parse_page(json): if json: items = json.get(\'data\').get(\'cards\') for item in items: item = item.get(\'mblog\') weibo = {} weibo[\'id\'] = item.get(\'id\') weibo[\'text\'] = pq(item.get(\'text\')).text() weibo[\'attitudes\'] = item.get(\'attitudes_count\') weibo[\'comments\'] = item.get(\'comments_count\') weibo[\'reposts\'] = item.get(\'reposts_count\') yield weibo
最后,遍历一下page,一共10页,将提取到的结果打印输出即可:
if __name__ == \'__main__\': for page in range(1, 11): json = get_page(page) results = parse_page(json) for result in results: print(result)
另外,我们还可以加一个方法将结果保存到MongoDB数据库:
from pymongo import MongoClient client = MongoClient() db = client[\'weibo\'] collection = db[\'weibo\'] def save_to_mongo(result): if collection.insert(result): print(\'Saved to Mongo\')
这样所有功能就实现完成了,通过分析Ajax并编写爬虫爬取下来了微博列表。
1 import requests 2 from urllib.parse import urlencode 3 from pyquery import PyQuery as pq 4 from pymongo import MongoClient 5 6 base_url = \'https://m.weibo.cn/api/container/getIndex?\' 7 headers = { 8 \'Host\': \'m.weibo.cn\', 9 \'Referer\': \'https://m.weibo.cn/u/2165760972\', 10 \'User-Agent\': \'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36\', 11 \'X-Requested-With\': \'XMLHttpRequest\', 12 } 13 client = MongoClient() 14 db = client[\'weibo\'] 15 collection = db[\'weibo\'] 16 max_page = 10 17 18 19 def get_page(page): 20 params = { 21 \'type\': \'uid\', 22 \'value\': \'2165760972\', 23 \'containerid\': \'1076032165760972\', 24 \'page\': page 25 } 26 url = base_url + urlencode(params) 27 try: 28 response = requests.get(url, headers=headers) 29 if response.status_code == 200: 30 return response.json(), page 31 except requests.ConnectionError as e: 32 print(\'Error\', e.args) 33 34 35 def parse_page(json, page: int): 36 if json: 37 items = json.get(\'data\').get(\'cards\') 38 for index, item in enumerate(items): 39 if page == 1 and index == 1: 40 continue 41 else: 42 item = item.get(\'mblog\') 43 weibo = {} 44 weibo[\'id\'] = item.get(\'id\') 45 weibo[\'text\'] = pq(item.get(\'text\')).text() 46 weibo[\'attitudes\'] = item.get(\'attitudes_count\') 47 weibo[\'comments\'] = item.get(\'comments_count\') 48 weibo[\'reposts\'] = item.get(\'reposts_count\') 49 yield weibo 50 51 52 def save_to_mongo(result): 53 if collection.insert(result): 54 print(\'Saved to Mongo\') 55 56 57 if __name__ == \'__main__\': 58 for page in range(1, max_page + 1): 59 json = get_page(page) 60 results = parse_page(*json) 61 for result in results: 62 print(result) 63 save_to_mongo(result)
以上是关于分析Ajax并爬取微博列表的主要内容,如果未能解决你的问题,请参考以下文章