去除人声--安装和使用spleeter分离人声和背景声
Posted 咿呀咿呀咿呀哟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了去除人声--安装和使用spleeter分离人声和背景声相关的知识,希望对你有一定的参考价值。
在实现过程中遇到了一些问题也在此记录下来,希望大家能少踩这些坑。
文章目录
前言
最近处理音视频,想把音频中的人声去掉,保留背景音乐。网上说AU 有人声移除的功能,我想AU竟然如此强大,于时去下载了AU,去除人声之后,整个都没有声音了。原因可能是:原音频看起来是立体声,实际上左声道和右声道是相同的,而人声消除的原理恰恰是消除左声道与右声道相同的声音,这样一搞自然就什么声音都没了。之后发现网上有很多吐槽AU的中置声道提取 。
*‘AU的中置声道提取算法就是个垃圾’ *
就好像:需要扣掉照片的主体保留背景,结果直接拿剪子在照片中间剜个洞。
后来看到github上面有spleeter,效果比AU好多了,下面是安装使用过程
一、最后效果是什么样的
成功分离出人声和背景声
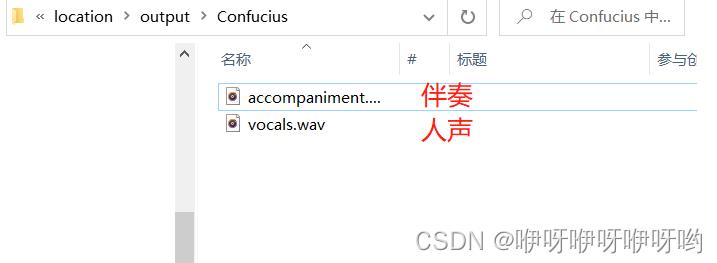
二、安装FFmpeg(不能跳)
注意FFmpeg这步必须安装
因为spleeter库依赖FFmpeg
1.打开官网
http://ffmpeg.org/download.html
下面以windows 64bit为例,不要点击绿色Download 标识,点击下面windows图标
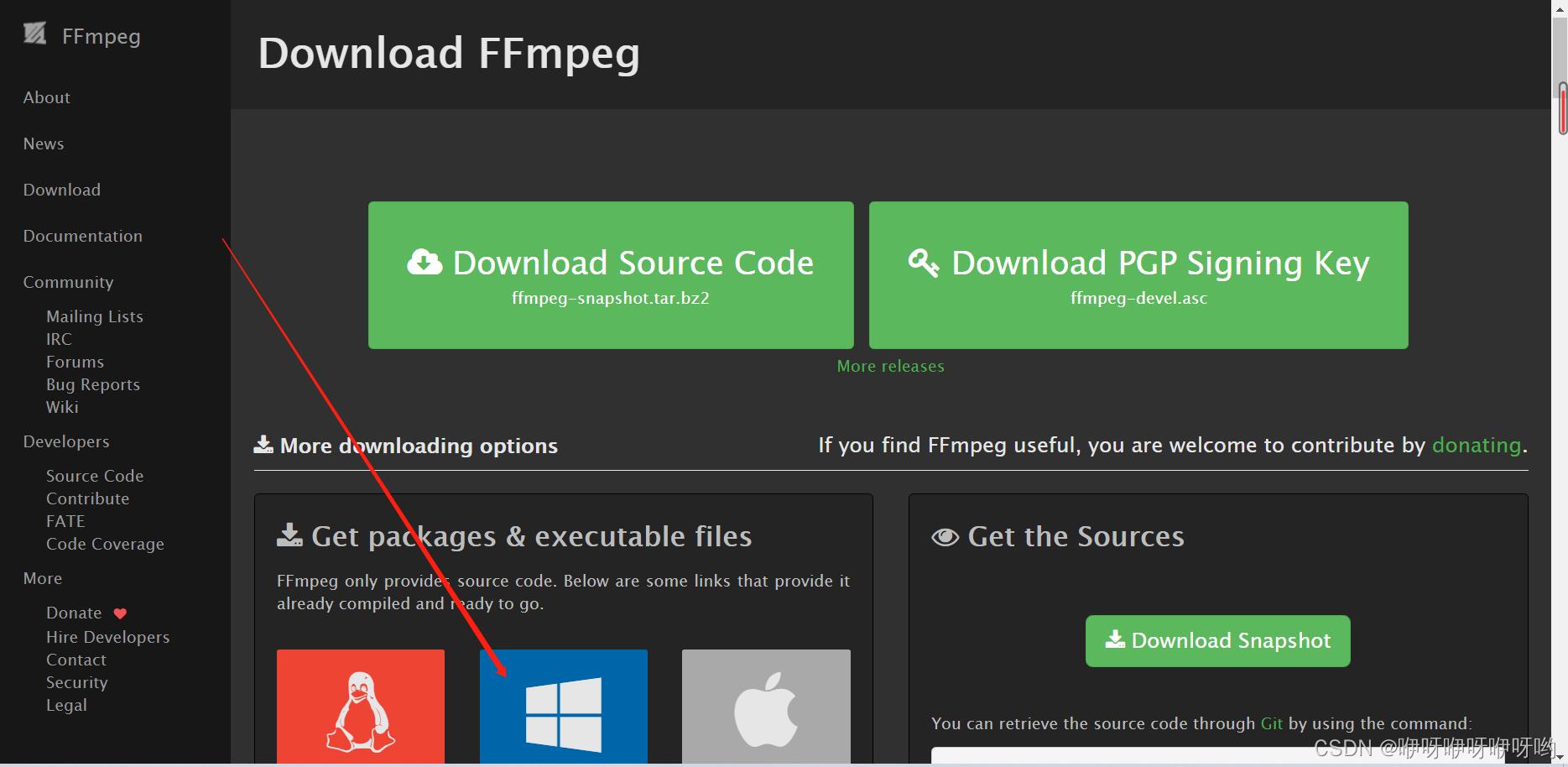
点击第二行,进入github
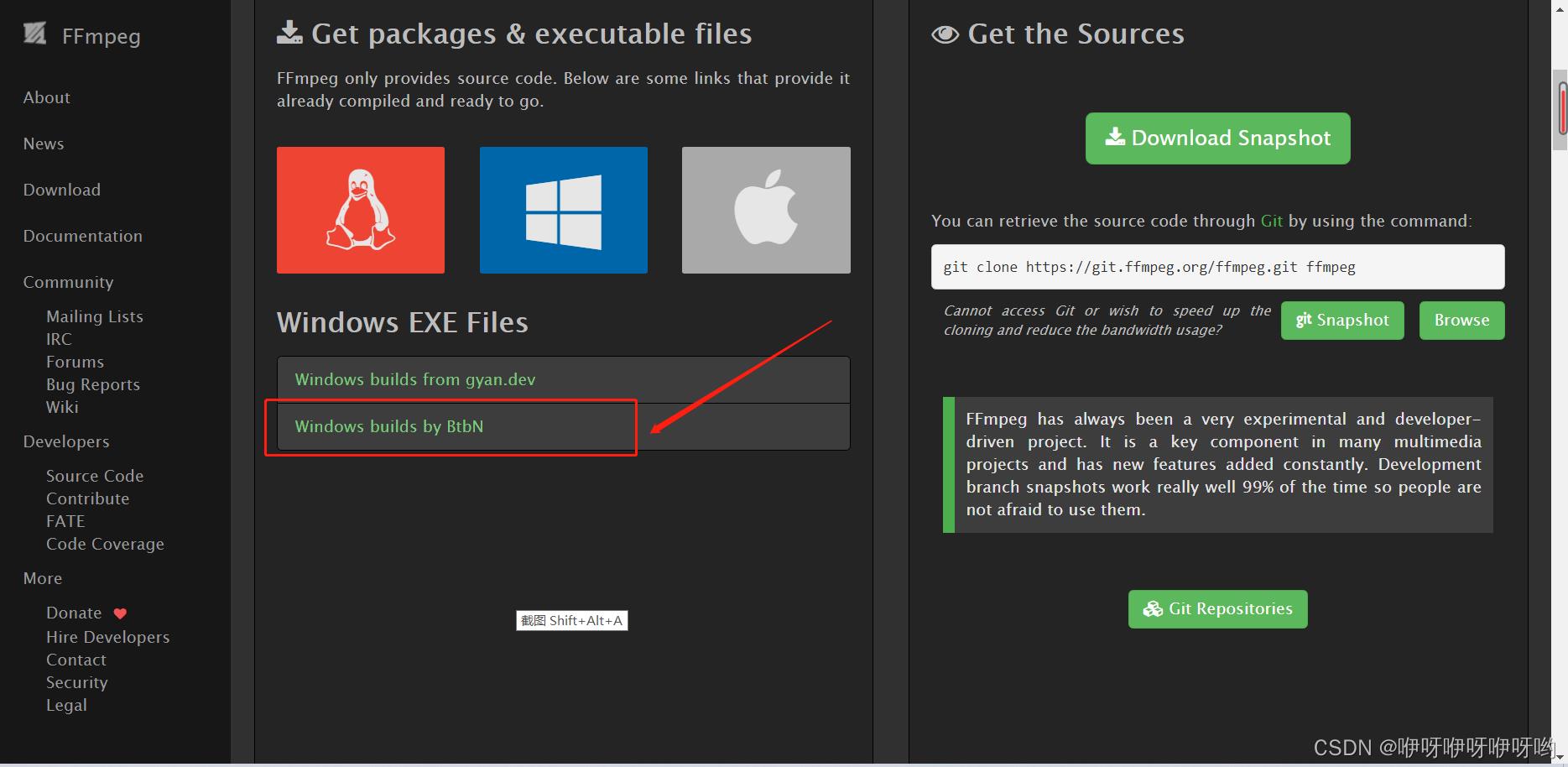
下载win64-gpl.zip,如果下载速度太慢,半天下载不来,进入这个github加速网站
直接输入下载的网址:
https://github.com/BtbN/FFmpeg-Builds/releases

FFmpeg分为3个版本:Static、 Shared、 Dev
这篇博客有说明:https://www.jianshu.com/p/7ed3be01228b
下载完之后解压,进入到bin目录,看到3个文件
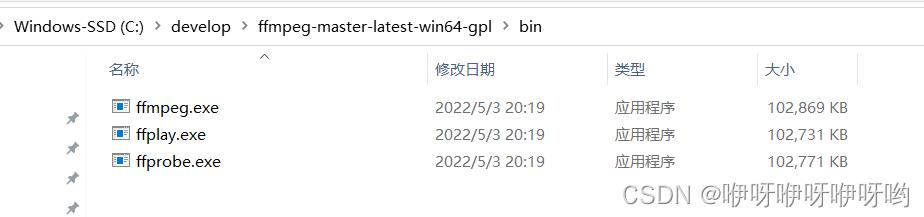
复制bin目录所在文件路径,进入下一步,设置环境变量
系统变量->选择PATH条目
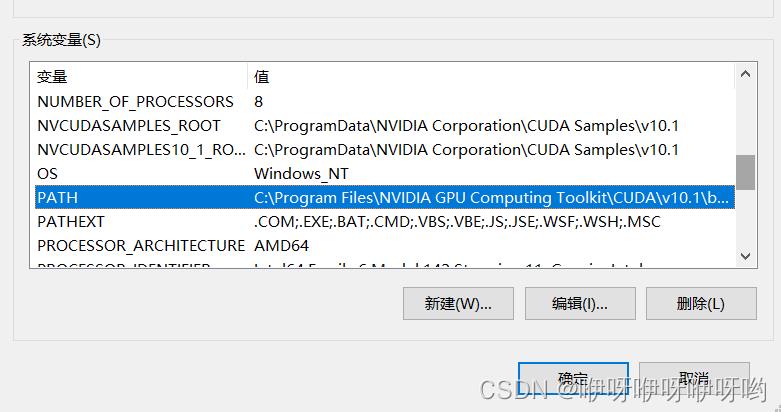
双击->新建->将bin目录路径添加进去。

打开cmd命令行窗口,输入命令ffmpeg –version
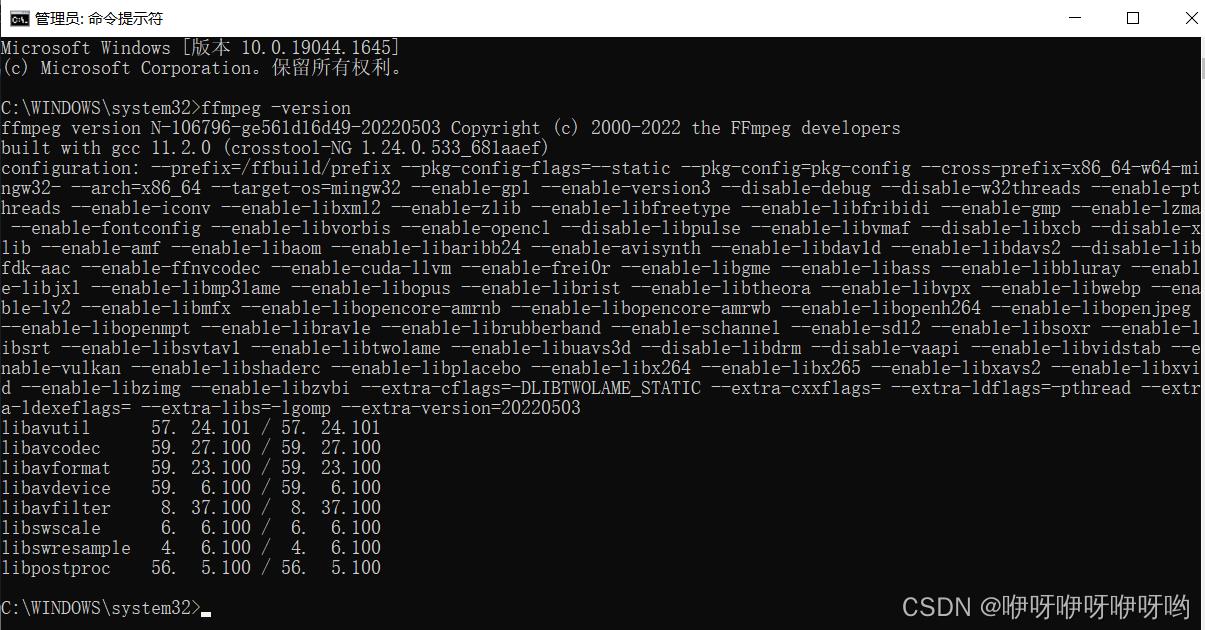
出现ffmpeg版本信息,说明安装成功。
三、安装spleeter模块
1.通过Anaconda创建一个虚拟环境
为了程序的稳定性,建议先通过Anaconda创建一个环境专门用来运行Spleeter,命名为music,选择python3.6。
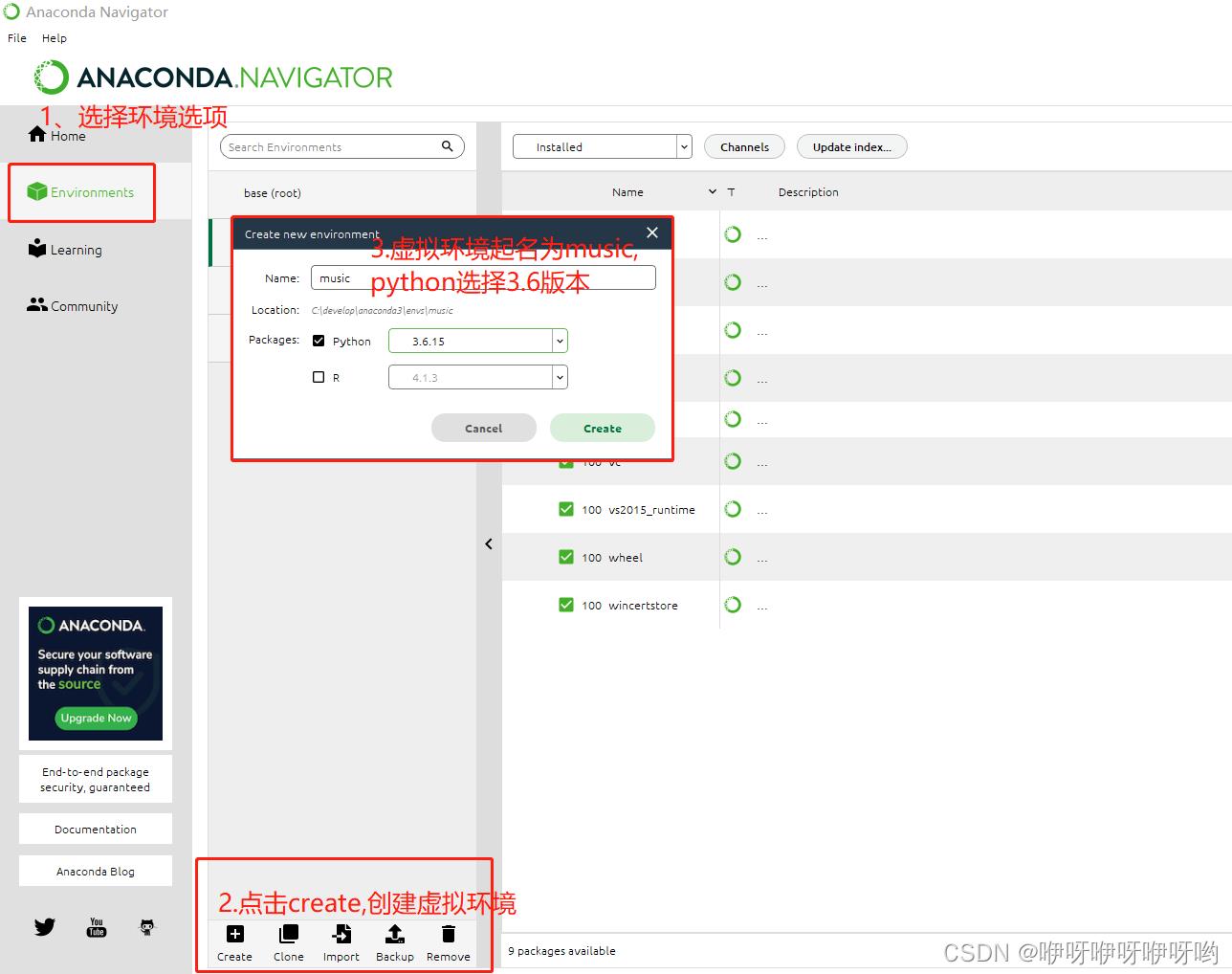
点击三角按钮,选择open in Terminal,进入虚拟环境,输入下面命令
注意:我刚开始创建了Python3.6的虚拟环境,结果输入下面命令不行,于时改成3.7版本,就可以了。
conda install -c conda-forge spleeter
安装完成后,窗口会自动清屏并出现一个done
2.下载预训练模型
下载地址,点击这里
https://github.com/deezer/spleeter/releases/tag/v1.4.0
我这里下载了最通用的2stem分离,就是人声和背景声
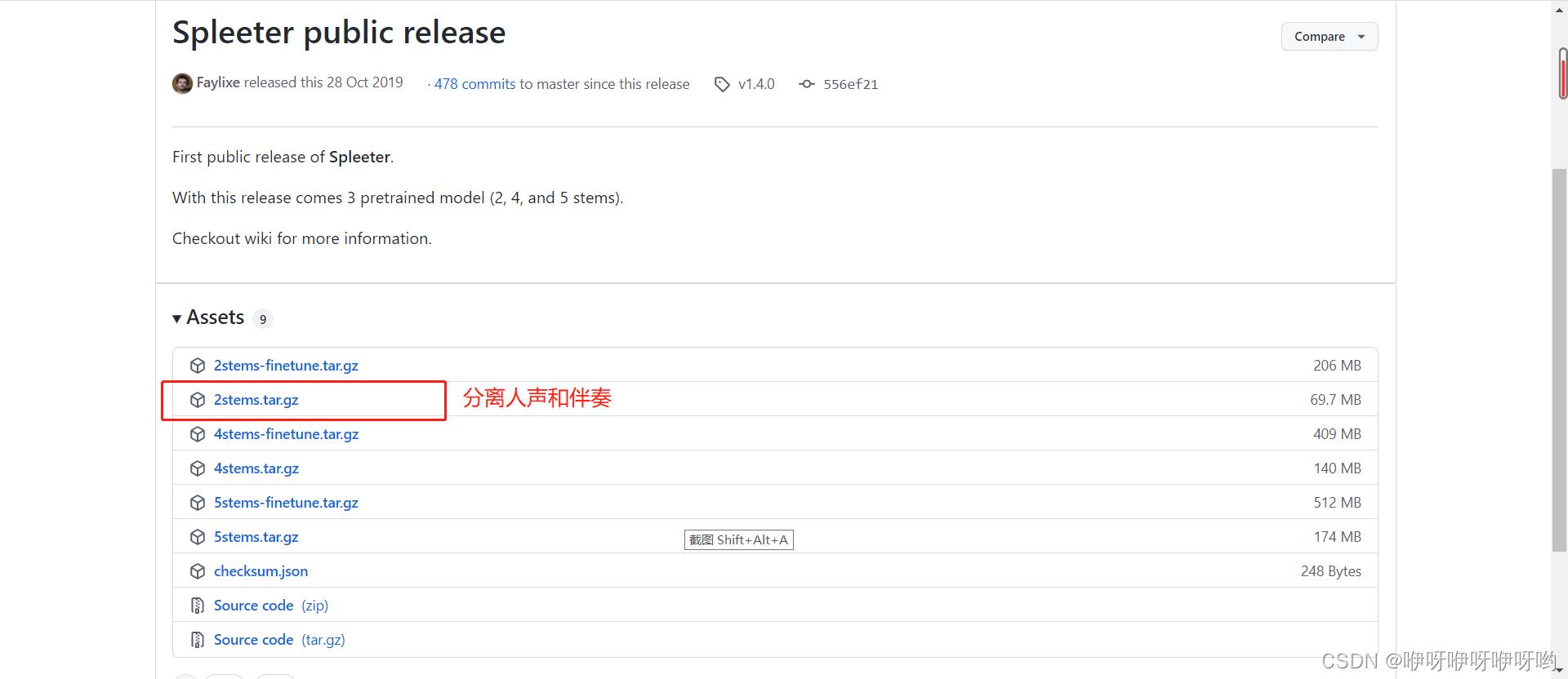
新建一个spleeter工作文件夹,我这里命名为location,在location文件夹中建立一个pretrained_models文件夹
将下载的2stem解压到C:\\location\\pretrained_models中。
3.文件结构(要特别注意)
1.在spleeter工作文件夹location中新建output文件夹,作为分离后的音频输出的地方。
2.将音频也放在spleeter工作目录中。
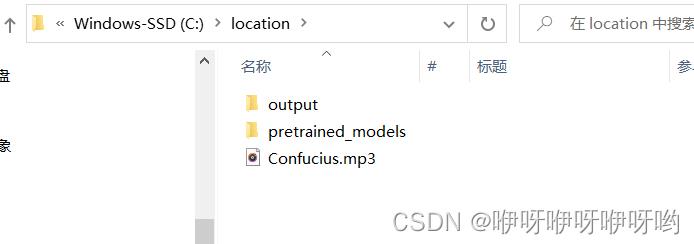
上面文件结构存放最好保持一致,不然下面运行之后又可能出现一大推错误,血泪教训。
四、使用spleeter分离人声和背景声
- 打开创建的虚拟环境命令行,切换目录到spleeter工作文件夹
location中,cd C:\\location - 输入命令
spleeter separate -i C:/location/Confucius.mp3 -p spleeter:2stems -o C:/location/output/

成功在output文件夹中输出。
output文件夹中多出来一个以音频名命名的文件夹

错误示范
没有搞清楚文件结构,应建立哪些文件,分别装什么,以至于出现很多错误,安装成功,就不需要往下看了。
下面以人声分离为例
新建一个2stems文件夹
https://github.com/deezer/spleeter/releases
进入这个下载地址,下载Source code (tar.gz)

解压到2stems文件夹中
输入命令,分离人声
spleeter separate -p spleeter:2stems -o C:/Users/Desktop C:/Users/Desktop/music.mp3
但遇到下面错误
usage: spleeter separate [-h] [-a AUDIO_ADAPTER] [-p CONFIGURATION]
[--verbose] -i INPUTS [INPUTS ...] [-o OUTPUT_PATH]
[-f FILENAME_FORMAT] [-d DURATION] [-s OFFSET]
[-c wav,mp3,ogg,m4a,wma,flac] [-b BITRATE] [-m]
[-B tensorflow,librosa,auto]
spleeter separate: error: the following arguments are required: -i/--inputs
再换下面这个命令
------spleeter指令--|----目标文件-----|----输出目录------|
spleeter separate -c mp3 C:/Users/Desktop/music.mp3 -o C:/Users/Desktop
还是有这个错误
这个错误意思是:
spletter separate:错误:需要以下参数:i/-inputs
换成下面这个命令,有-i参数
python -m spleeter separate -i C:/Users/Desktop/music.mp3 -p spleeter:2stems -o C:/Users/Desktop
一直遇到下面这个错误
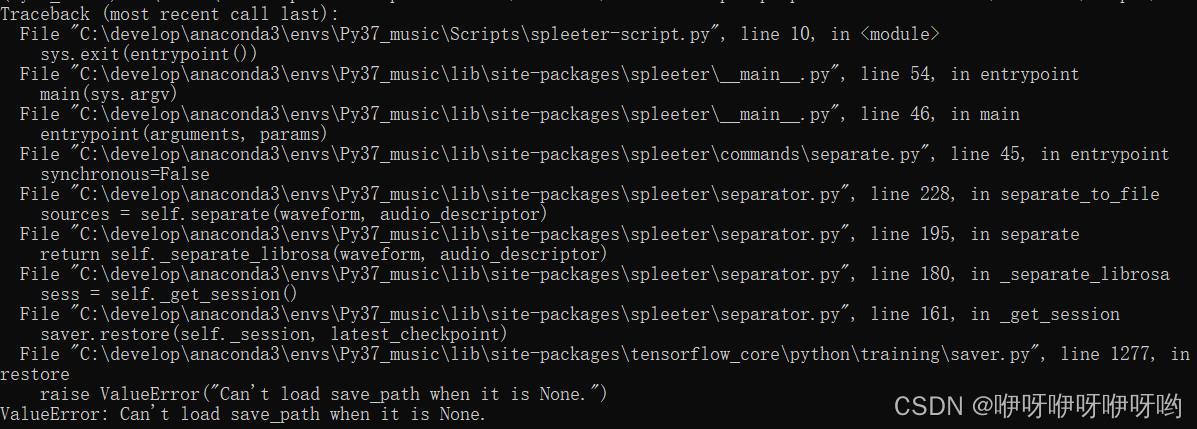
Traceback (most recent call last):
File "C:\\develop\\anaconda3\\envs\\Py37_music\\Scripts\\spleeter-script.py", line 10, in <module>
sys.exit(entrypoint())
File "C:\\develop\\anaconda3\\envs\\Py37_music\\lib\\site-packages\\spleeter\\__main__.py", line 54, in entrypoint
main(sys.argv)
File "C:\\develop\\anaconda3\\envs\\Py37_music\\lib\\site-packages\\spleeter\\__main__.py", line 46, in main
entrypoint(arguments, params)
File "C:\\develop\\anaconda3\\envs\\Py37_music\\lib\\site-packages\\spleeter\\commands\\separate.py", line 45, in entrypoint
synchronous=False
File "C:\\develop\\anaconda3\\envs\\Py37_music\\lib\\site-packages\\spleeter\\separator.py", line 228, in separate_to_file
sources = self.separate(waveform, audio_descriptor)
File "C:\\develop\\anaconda3\\envs\\Py37_music\\lib\\site-packages\\spleeter\\separator.py", line 195, in separate
return self._separate_librosa(waveform, audio_descriptor)
File "C:\\develop\\anaconda3\\envs\\Py37_music\\lib\\site-packages\\spleeter\\separator.py", line 180, in _separate_librosa
sess = self._get_session()
File "C:\\develop\\anaconda3\\envs\\Py37_music\\lib\\site-packages\\spleeter\\separator.py", line 161, in _get_session
saver.restore(self._session, latest_checkpoint)
File "C:\\develop\\anaconda3\\envs\\Py37_music\\lib\\site-packages\\tensorflow_core\\python\\training\\saver.py", line 1277, in restore
raise ValueError("Can't load save_path when it is None.")
ValueError: Can't load save_path when it is None.
原来是模型还没有生成,就去训练。
参考博客
https://blog.csdn.net/qq_39377418/article/details/97135361?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165183023516782388011424%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=165183023516782388011424&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-1-97135361-null-null.nonecase&utm_term=spleeter++raise+ValueError%28Cant+load+save_path+when+it+is+None.%29+ValueError%3A+Cant+load+save_path+when+it+is+None.&spm=1018.2226.3001.4450
解决方案:
建议在某个盘的根目录里新建一个全英文的文件夹(尽量不要出现中文或者特殊符号,因为这样它有可能会找不到路径,会报错)用于存放你将要处理的MP3或者wav文件,其次你本身要处理的文件的名字也应该是全英文
参考博客:
https://blog.csdn.net/qq_44976743/article/details/108632618
但是还是不行。
最后才发现是预训练模型下载错了
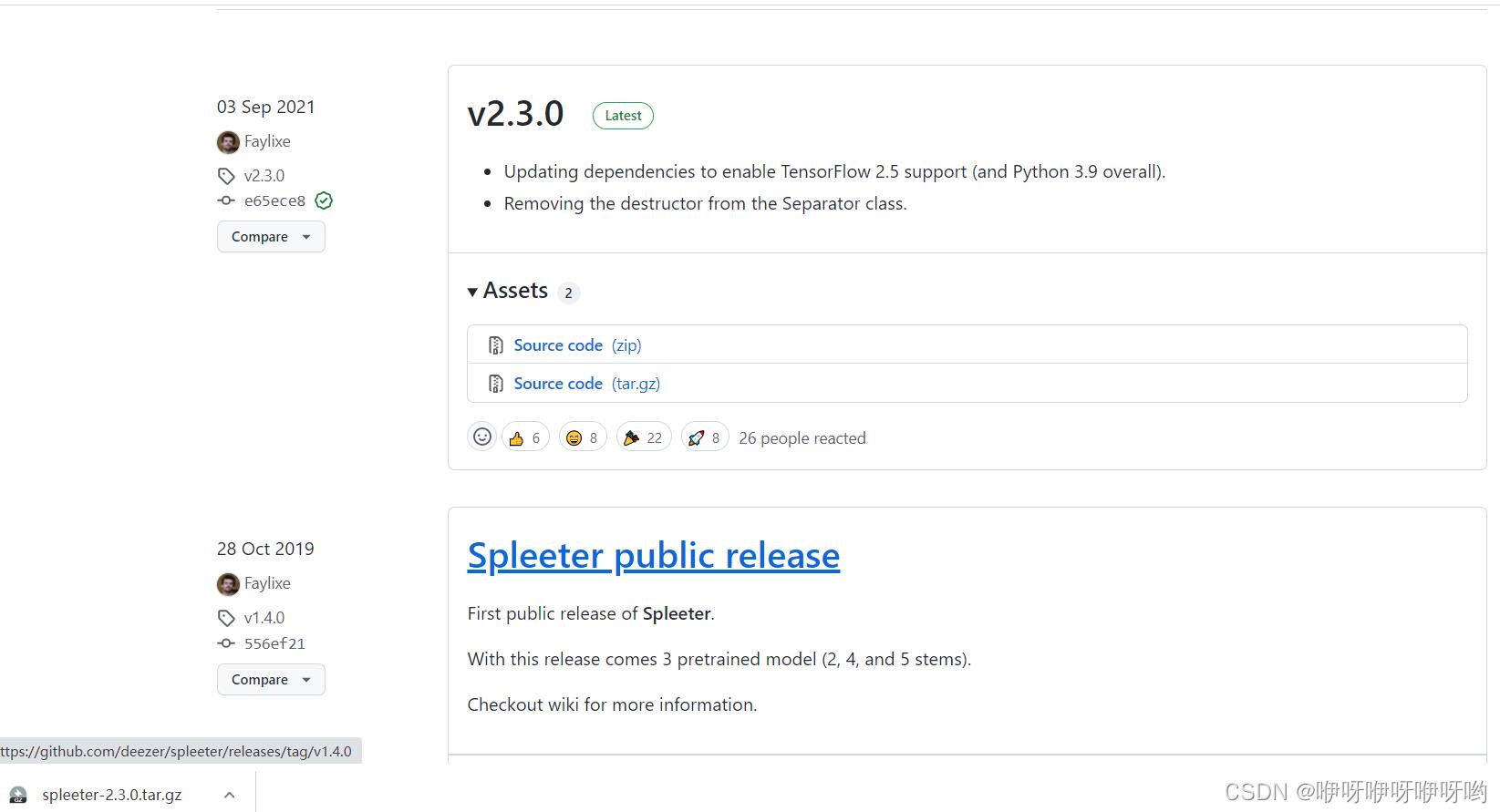
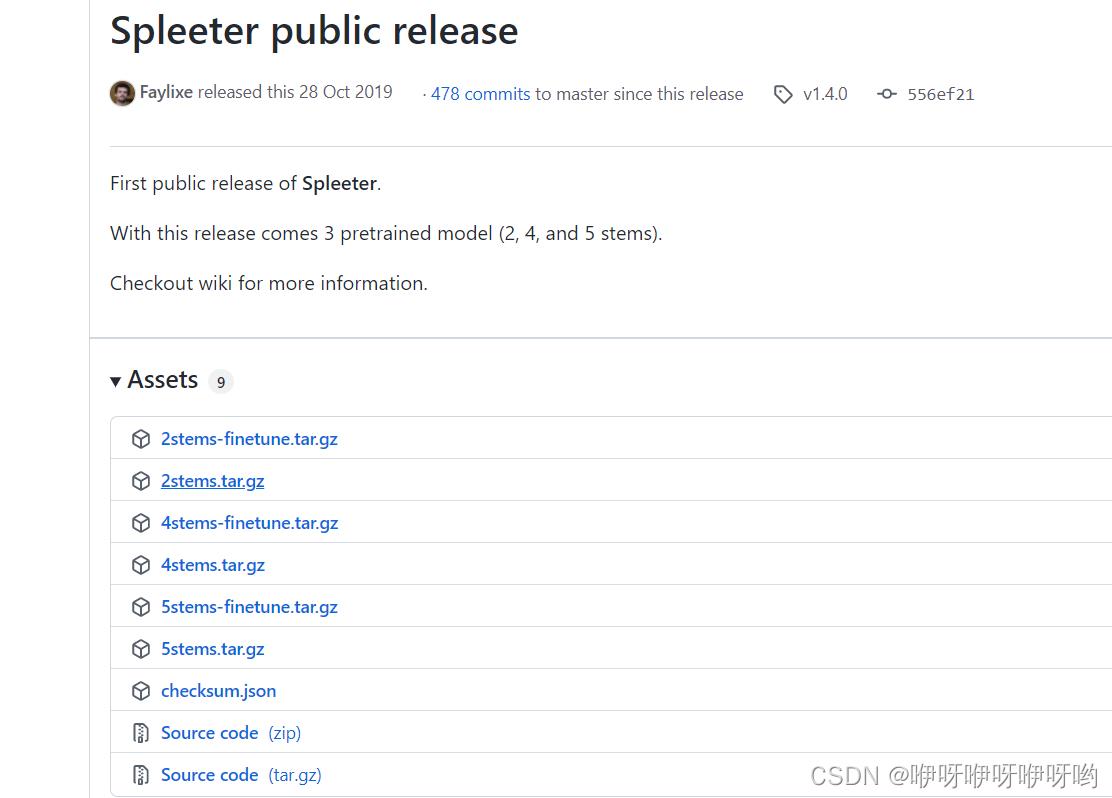
github页面往下滑才发现应该下载下面Spleeter public release
分离人声和背景音乐就下载2stems.tar.gz
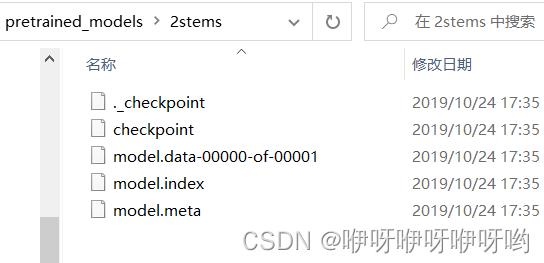
文件夹中只有这几个文件
最后再次输入命令

结果还是报错。
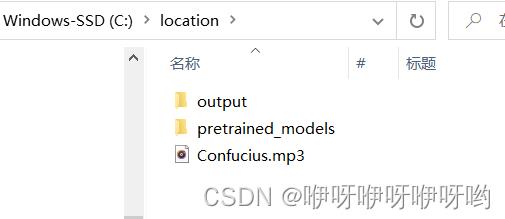
又仔细搜寻其他博客,一个字一个字,仔细瞅了,才发现是要切换到spleeter工作目录下,
我把工作目录命名为location,文件结构如下
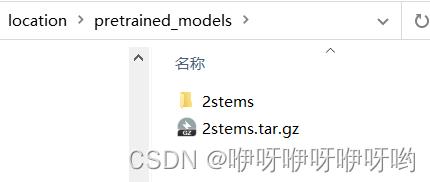

可以看到
INFO:spleeter:File C:/location/output/Confucius/accompaniment.wav written succesfully
INFO:spleeter:File C:/location/output/Confucius/vocals.wav written succesfully
输出成功了,output文件夹中多出了一个文件夹
总结
终于将一段音频实现了人音和伴奏分离了,效果还不错,可能人音部分还是又一点伴奏声音,不过我主要想要这段音频的伴奏,自己进行配音。
总结整个实现过程最困难的就是一直报
raise ValueError("Can't load save_path when it is None.")
ValueError: Can't load save_path when it is None.
这个错误,让我整了半天,才整出来,最主要原因还是文件结构以及路径的问题,这点一定要仔细。
仔细安装,一步一步来就没有什么大问题。
参考文献:
https://zhuanlan.zhihu.com/p/324472015
https://zhuanlan.zhihu.com/p/149944571
https://tancolin.blog.csdn.net/article/details/122572573?spm=1001.2101.3001.6650.5&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-5-122572573-blog-115488883.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-5-122572573-blog-115488883.pc_relevant_default&utm_relevant_index=6
https://www.bilibili.com/read/cv13211840
伴奏人声分离工具 Spleeter 免费本地处理无限制
链接: /s/1cRbPpBzjHjPvvPfrR2veZg 提取码: wj9d 复制这段内容后打开百度网盘手机App,操作更方便哦

以上是关于去除人声--安装和使用spleeter分离人声和背景声的主要内容,如果未能解决你的问题,请参考以下文章