Mybatis批量更新优化方案
Posted lianaozhe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mybatis批量更新优化方案相关的知识,希望对你有一定的参考价值。
目录
前言
今天在对接客户接口的时候,对方同步数据到我们系统,涉及到数据批量更新,插入的逻辑,出于性能方面的考虑,决定对自己写的逻辑进行优化,下面对几种优化方案进行总结。
需求
同步部门数据到mysql数据库,响应示例:
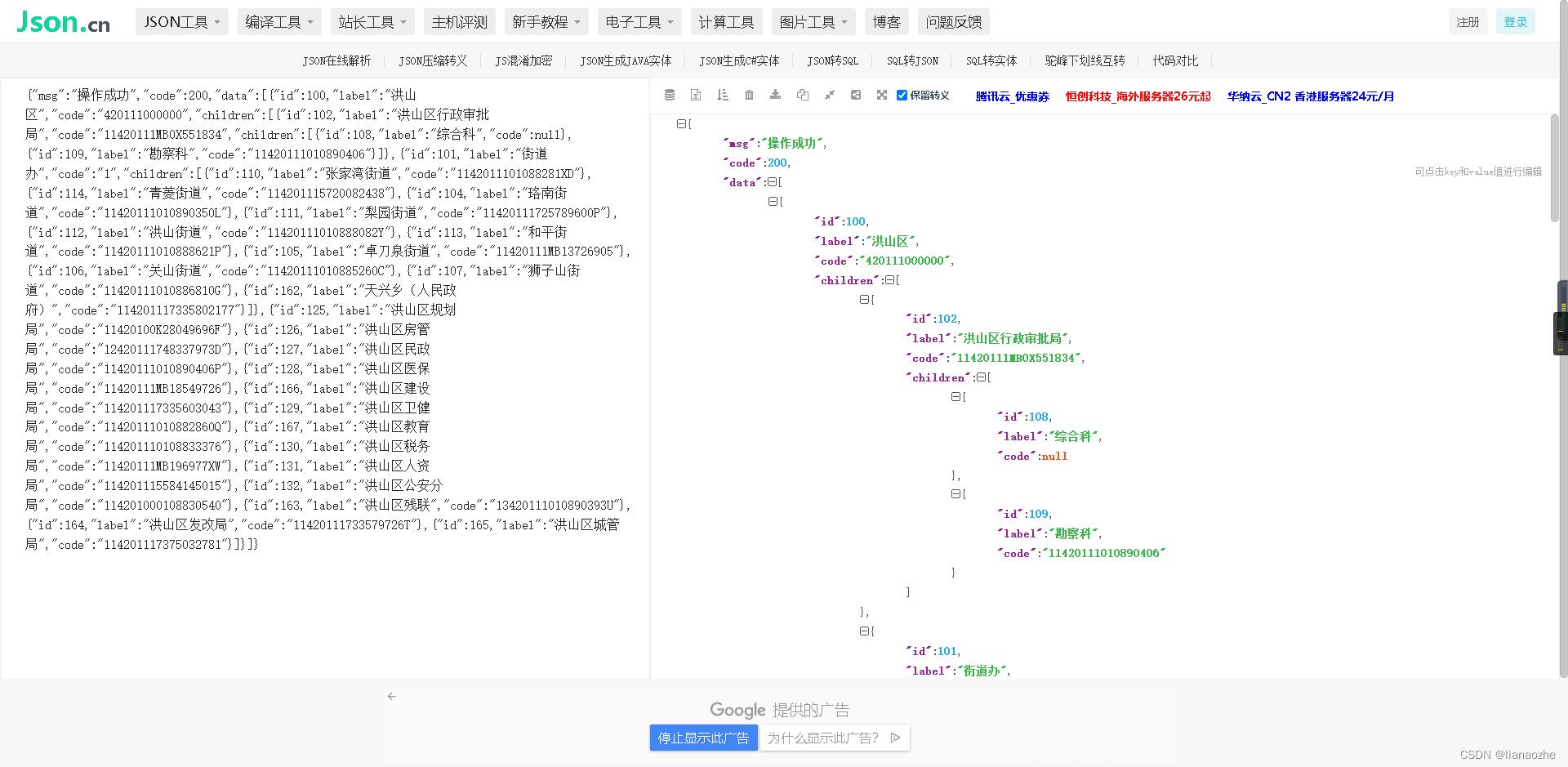
拿到json后,如果数据库不存在部门数据,则进行插入操作;存在部门数据,则做修改操作。这里演示存在数据进行修改操作。
原方案
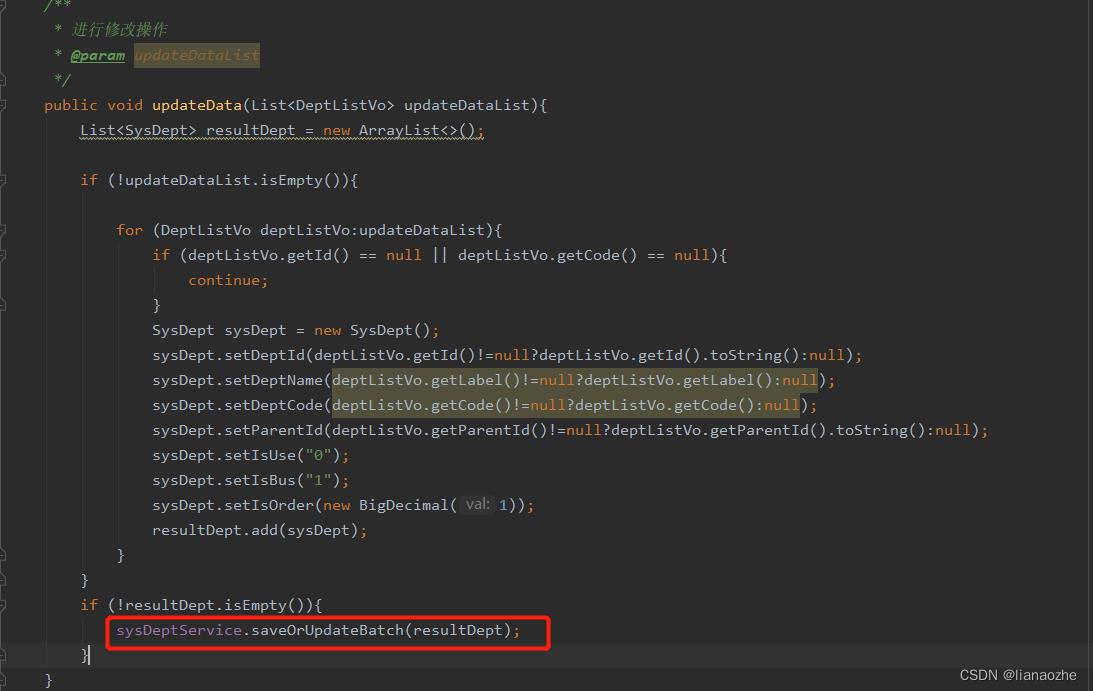
使用mybatis-plus的saveOrUpdateBatch接口
修改部分代码逻辑:
启动项目进行测试:
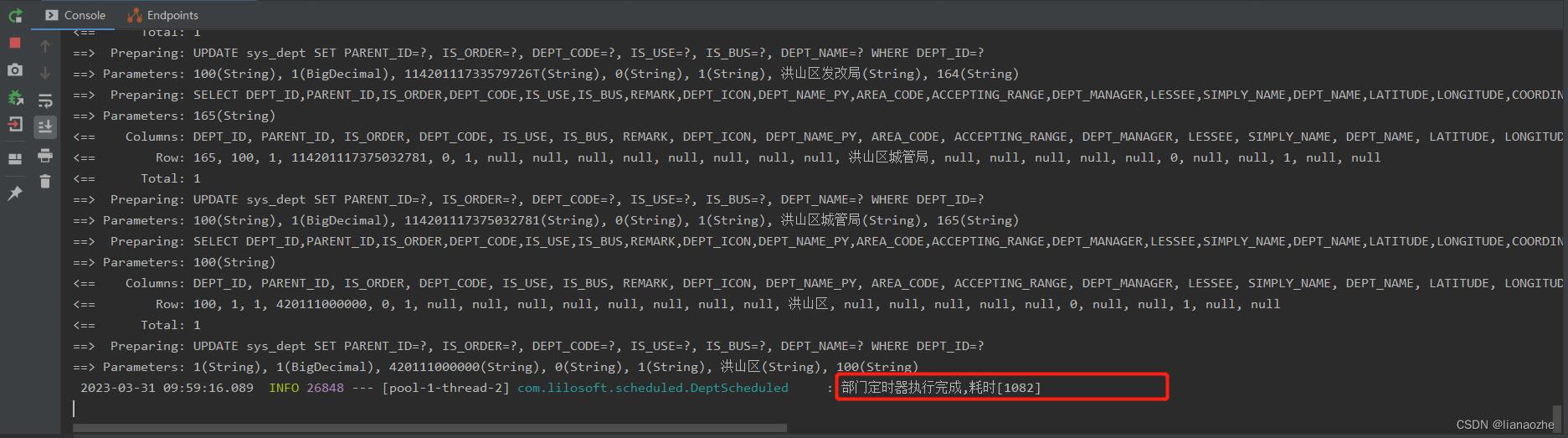
经测试,接收的数据30条左右,耗时 1082ms ,显然达不到预期的性能要求,于是针对此进行优化。
优化方案一
在mybatis的xml文件中,使用foreach标签来拼接SQL语句。
代码示例:
<update id="updateBatchById">
<foreach collection="list" item="item" separator=";">
update
`sys_dept`
set
`DEPT_NAME` = #item.deptName,
`DEPT_CODE` = #item.deptCode,
`PARENT_ID` = #item.parentId
where
dept_id = #item.deptId
</foreach>
</update>
mapper层:
/**
* 批量更新
* @param list
*/
void updateBatchById(@Param("list") List<SysDept> list);
然后在修改数据的逻辑中,直接调用mapper的接口
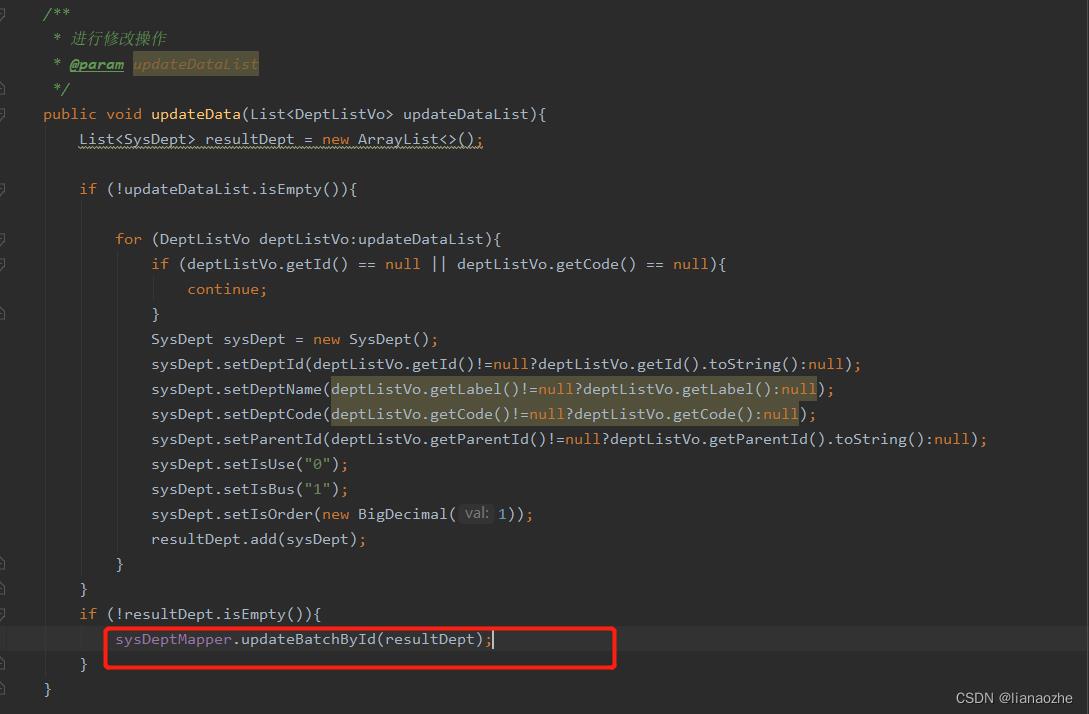
重启项目,再次测试:

可以看到,同样的数据,这个方案耗时273ms
优化方案二
foreach标签配合case when拼接SQL语句。
代码示例:
<update id="batchUpdate" parameterType="java.util.List">
update sys_dept
<trim prefix="set" suffixOverrides=",">
<trim prefix=" `DEPT_NAME` = case " suffix=" end, ">
<foreach collection="list" item="item">
<if test="item.deptName != null">
when dept_id = #item.deptId then #item.deptName
</if>
</foreach>
</trim>
<trim prefix=" `DEPT_CODE` = case " suffix=" end, ">
<foreach collection="list" item="item">
<if test="item.deptCode != null">
when dept_id = #item.deptId then #item.deptCode
</if>
</foreach>
</trim>
<trim prefix=" `PARENT_ID` = case " suffix=" end, ">
<foreach collection="list" item="item">
<if test="item.parentId != null">
when dept_id = #item.deptId then #item.parentId
</if>
</foreach>
</trim>
</trim>
where
dept_id in
<foreach collection="list" item="item" open="(" close=")" separator=",">
#item.deptId
</foreach>
</update>
mapper层:
/**
* 批量更新
* @param list
*/
void batchUpdate(@Param("list") List<SysDept> list);
修改逻辑处直接调用:
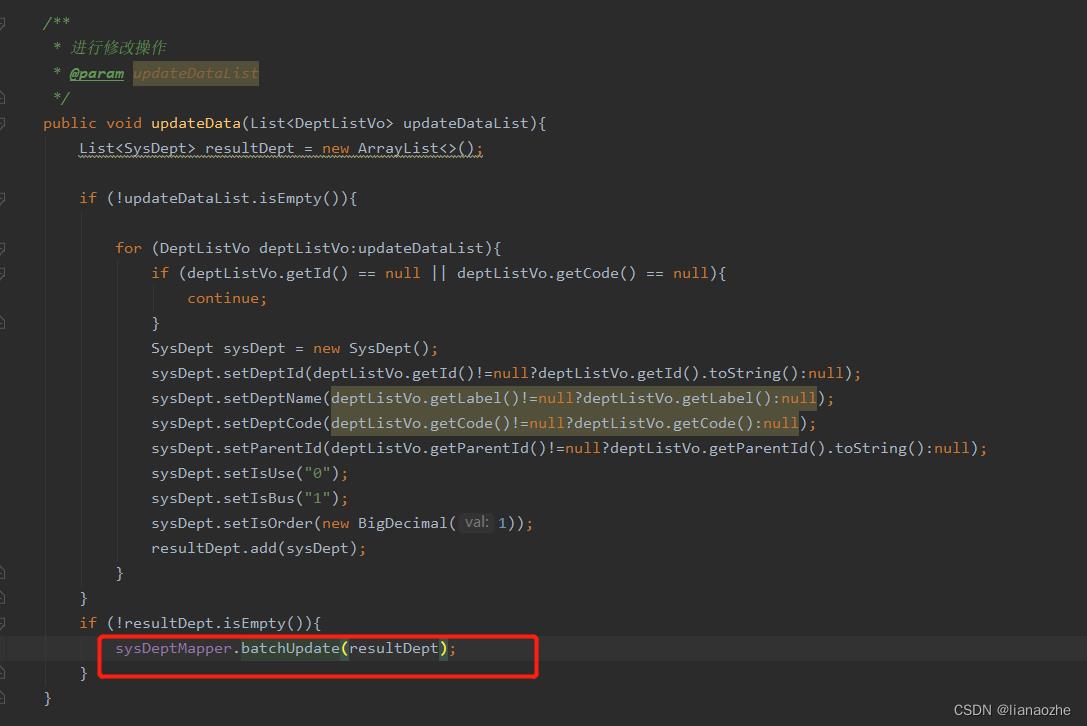
重启项目,再次测试:

可以看到,同样的数据,这个方案耗时131ms。
经过多次测试会发现,在本案例中,优化方案二性能略强于优化方案一。
总结
使用mybatisplus的saveOrUpdateBatch操作效率极低,查看sql日志可以发现,实际上还是一条一条插入的,而且在插入之前还要查询数据库是否存在该数据,耗时很久,建议不要使用。优化方案一是多条sql语句,需要数据库执行多次修改操作,而优化方案二是一条sql语句,只需要数据库执行一次修改操作。在数据量不是特别大的情况下,优化方案二优于优化方案一。
在数据量不大的情况下,推荐使用方案二。
MyBatis动态批量插入更新Mysql数据库的通用实现方案
一、业务背景
由于需要从A数据库提取大量数据同步到B系统,采用了tomikos+jta进行分布式事务管理,先将系统数据源切换到数据提供方,将需要同步的数据查询出来,然后再将系统数据源切换到数据接收方,进行批量的插入和更新操作,
关于数据源的切换可以参考之前的文章《spring+springMVC+Mybatis架构下采用AbstractRoutingDataSource、atomikos、JTA实现多数据源灵活切换以及分布式事务管理》
二、批量插入的具体实现
1.查询需要同步的数据:
@Autowired SysPersonPOMapper sysPersonPOMapper; public void dataDs(){ //根据具体情况可以创建查询条件或者采用自定义的Mapper进行查询 SysPersonPOExample sysPersonPOExample = new SysPersonPOExample(); sysPersonPOExample.createCriteria().andIsDeleteEqualTo(false); //查询需要同步的数据 List<SysPersonPO> persons = sysPersonPOMapper.selectByExample(sysPersonPOExample); }
2.将不能进行遍历的PO实体对象转为Map,此处有一个前提条件:MySQL中的表字段是按全大写加下划线命名,实体类PO映射字段为对应的标准驼峰命名方式,进行PO到Map
的转换时,会遵循这一规则。
@Autowired SysPersonPOMapper sysPersonPOMapper; public void dataDs() throws Exception{ //1.查询需要同步的数据 //根据具体情况可以创建查询条件或者采用自定义的Mapper进行查询 SysPersonPOExample sysPersonPOExample = new SysPersonPOExample(); sysPersonPOExample.createCriteria().andIsDeleteEqualTo(false); //查询需要同步的数据 List<SysPersonPO> persons = sysPersonPOMapper.selectByExample(sysPersonPOExample); //2.将不能进行遍历的PO实体对象转为Map //用于存放转换后的对象的List List<Map<String,Object>> insertItems = Lists.newArrayList(); for (SysPersonPO sysPersonPO : persons) { Map<String,Object> insertItem = BeanMapUtil.convertBean2MapWithUnderscoreName(sysPersonPO); insertItems.add(insertItem); } }
BeanMapUtil类,PO到Map的转换方法,基于类反射技术:
import com.fms.common.utils.other.StringUtil; import java.beans.BeanInfo; import java.beans.Introspector; import java.beans.MethodDescriptor; import java.beans.PropertyDescriptor; import java.lang.reflect.Method; import java.sql.Timestamp; import java.util.Date; import java.util.HashMap; import java.util.Map; import org.apache.commons.beanutils.BeanUtils; public class BeanMapUtil { @SuppressWarnings({"unchecked", "rawtypes"}) public static Map convertBean2MapWithUnderscoreName(Object bean) throws Exception { Map returnMap = null; try { Class type = bean.getClass(); returnMap = new HashMap(); BeanInfo beanInfo = Introspector.getBeanInfo(type); PropertyDescriptor[] propertyDescriptors = beanInfo .getPropertyDescriptors(); for (int i = 0; i < propertyDescriptors.length; i++) { PropertyDescriptor descriptor = propertyDescriptors[i]; String propertyName = descriptor.getName(); if (!propertyName.equalsIgnoreCase("class")) { Method readMethod = descriptor.getReadMethod(); Object result = readMethod.invoke(bean, new Object[0]); returnMap.put( StringUtil.underscoreName(propertyName), result); } } } catch (Exception e) { // 解析错误时抛出服务器异常 记录日志 throw new Exception("从bean转换为map时异常!", e); } return returnMap; } }
StringUtil类,标准驼峰命名与数据库下划线命名之间转换的方法:
public class StringUtil { /** * 将驼峰式命名的字符串转换为下划线大写方式。如果转换前的驼峰式命名的字符串为空,则返回空字符串。</br> * 例如:HelloWorld->HELLO_WORLD * * @param name 转换前的驼峰式命名的字符串 * @return 转换后下划线大写方式命名的字符串 */ public static String underscoreName(String name) { StringBuilder result = new StringBuilder(); if (name != null && name.length() > 0) { // 将第一个字符处理成大写 result.append(name.substring(0, 1).toUpperCase()); // 循环处理其余字符 for (int i = 1; i < name.length(); i++) { String s = name.substring(i, i + 1); // 在大写字母前添加下划线 if (s.equals(s.toUpperCase()) && !Character.isDigit(s.charAt(0))) { result.append("_"); } // 其他字符直接转成大写 result.append(s.toUpperCase()); } } return result.toString(); } }
3.编写Mybatis映射文件fmsDataDsMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.fms.common.dao.fmsDataDsMapper">
<!-- 批量插入,传入表名和需要插入的数据的集合 -->
<insert id="insertDatas" parameterType="map">
insert into ${table_name}
<foreach collection="fields" index="field" item="fieldVal" separator="," open="(" close=")">
${field}
</foreach>
values
<foreach collection="list" index="index" item="record" separator="," >
<foreach collection="record" index="key" item="item" separator="," open="(" close=")">
#{item}
</foreach>
</foreach>
</insert>
</mapper>
4.调用sqlsession相关API的insert方法插入数据:
@Autowired SysPersonPOMapper sysPersonPOMapper; public void dataDs() throws Exception{ //1.查询需要同步的数据 //根据具体情况可以创建查询条件或者采用自定义的Mapper进行查询 SysPersonPOExample sysPersonPOExample = new SysPersonPOExample(); sysPersonPOExample.createCriteria().andIsDeleteEqualTo(false); //查询需要同步的数据 List<SysPersonPO> persons = sysPersonPOMapper.selectByExample(sysPersonPOExample); //2.将不能进行遍历的PO实体对象转为Map //用于存放转换后的对象的List List<Map<String,Object>> insertItems = Lists.newArrayList(); for (SysPersonPO sysPersonPO : persons) { Map<String,Object> insertItem = BeanMapUtil.convertBean2MapWithUnderscoreName(sysPersonPO); insertItems.add(insertItem); } //3.插入数据 insertDatas(insertItems,"sys_person"); } @Autowired SqlSessionTemplate sqlSessionTemplate; private String dataDsNameSpace = "com.fms.common.dao.fmsDataDsMapper"; private void insertDatas(List<Map<String,Object>> insertItems, String tableName){ if (!insertItems.isEmpty()) { Map<String,Object> params = Maps.newHashMap();
//这里把数据分成每1000条执行一次,可根据实际情况进行调整 int count = insertItems.size() / 1000; int yu = insertItems.size() % 1000; for (int i = 0; i <= count; i++) { List<Map<String,Object>> subList = Lists.newArrayList(); if (i == count) { if(yu != 0){ subList = insertItems.subList(i * 1000, 1000 * i + yu); }else { continue; } } else { subList = insertItems.subList(i * 1000, 1000 * (i + 1)); } params.put("table_name", tableName); params.put("fields", subList.get(0)); params.put("list", subList); sqlSessionTemplate.insert(dataDsNameSpace+".insertDatas", params); } } }
三 、批量更新的具体实现
通常我们根据主键更新时的语句是 update table_name set column1 = val1 , column2 = val2 [,......] where id = ? 或者使用Mybatis提供的updateByPrimaryKey接口,
当我们希望一次性更新大量数据时,每条SQL只能执行一条更新,MySQL支持另外一种更新方式,让我们可以实现通过一条SQL语句一次性更新多条 根据主键更新的记录:
ON DUPLICATE KEY UPDATE
注意:这不同于在满足where条件时将某个table中的某一字段全部更新为同一各值,而是每条记录修改后的值都不一样。
1.构建需要更新的数据,需要注意的是如果PO中存在不想要更新的字段,你有两种处理方式,一种是将该字段的值在此处设为数据库中原来的值,另一种方式就是在进行Map转换时,
不将此字段构建到Map中,这只需要对convertBean2MapWithUnderscoreName方法做一些小的修改,你可以把不需要保留的字段作为参数传给它,然后在转换的时候过滤掉(主键不能省略)。
//4.构建批量更新的数据 //用于存放转换后的对象的List List<Map<String,Object>> updateItems = Lists.newArrayList(); for (SysPersonPO sysPersonPO : persons) { sysPersonPO.setCode(sysPersonPO.getCode()+"updateTest"); Map<String,Object> updatetItem = BeanMapUtil.convertBean2MapWithUnderscoreName(sysPersonPO); updateItems.add(updatetItem); }
2.编写Mybatis映射文件fmsDataDsMapper.xml
<!-- 根据主键批量更新某个字段,传入表名和需要更新的数据的集合 -->
<insert id="updateDatas" parameterType="map">
INSERT INTO ${table_name}
<foreach collection="fields" index="field" item="fieldVal" separator="," open="(" close=")">
${field}
</foreach>
VALUES
<foreach collection="list" index="index" item="record" separator="," >
<foreach collection="record" index="key" item="item" separator="," open="(" close=")">
#{item}
</foreach>
</foreach>
ON DUPLICATE KEY UPDATE
<foreach collection="fields" index="field" item="fieldVal" separator=",">
${field}=VALUES(${field})
</foreach>
</insert>
3.更新数据
//5.更新数据 updateDatas(updateItems,"sys_person"); private void updateDatas(List<Map<String,Object>> updateItems, String tableName){ if (!updateItems.isEmpty()) { Map<String,Object> params = Maps.newHashMap();
//这里将数据分成每1000条执行一次,可根据实际情况调整 int count = updateItems.size() / 1000; int yu = updateItems.size() % 1000; for (int i = 0; i <= count; i++) { List<Map<String,Object>> subList = Lists.newArrayList(); if (i == count) { if(yu != 0){ subList = updateItems.subList(i * 1000, 1000 * i + yu); }else { continue; } } else { subList = updateItems.subList(i * 1000, 1000 * (i + 1)); } params.put("table_name", tableName); params.put("fields", subList.get(0)); params.put("list", subList); sqlSessionTemplate.insert(dataDsNameSpace+".updateDatas", params); } } }
以上是关于Mybatis批量更新优化方案的主要内容,如果未能解决你的问题,请参考以下文章