m3u8视频爬虫下载及合并
Posted S1aine
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了m3u8视频爬虫下载及合并相关的知识,希望对你有一定的参考价值。
前言
爬虫获取m3u8视频资源的步骤
目前所要作的流程处理
先把m3u8里下载链接批量提取.png
把这几百个切片链接先批量下载.png
再批量改文件后缀为.ts
再按照m3u8文件提取所有不规则链接文件的【顺序】.png
然后改切片的文件名为0001,0002,0003......顺序.png
然后用ffmpeg或者moviepy或者其他工具合并就行.png
看起来也没有那么麻烦…(流汗黄豆)
开始操作
目前已有材料:爬下来的网页源码和从中获取的m3u8文件

把.m3u8改成.txt格式便于操作
批量正则提取和下载
写脚本从原来的m3u8文件中正则表达提取出所有干净的下载链接,将其放到另外一个.txt文件;并且从中下载所有的切片文件
程序代码如下
import requests
import re
from io import BytesIO
import urllib3
import os
t = open("b7729bb022ae5d382df1fd28ac61f1178c3f424c.txt", "r", encoding='utf-8')
data = t.readlines()
t.close()
for line in data:
pattern = re.compile(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+')
string = str(line)
url = re.findall(pattern,string)
f1 = open("url提取.txt", "a+", encoding='utf-8')
for urls in url:
f1.write(urls+'\\n')
f1.close()
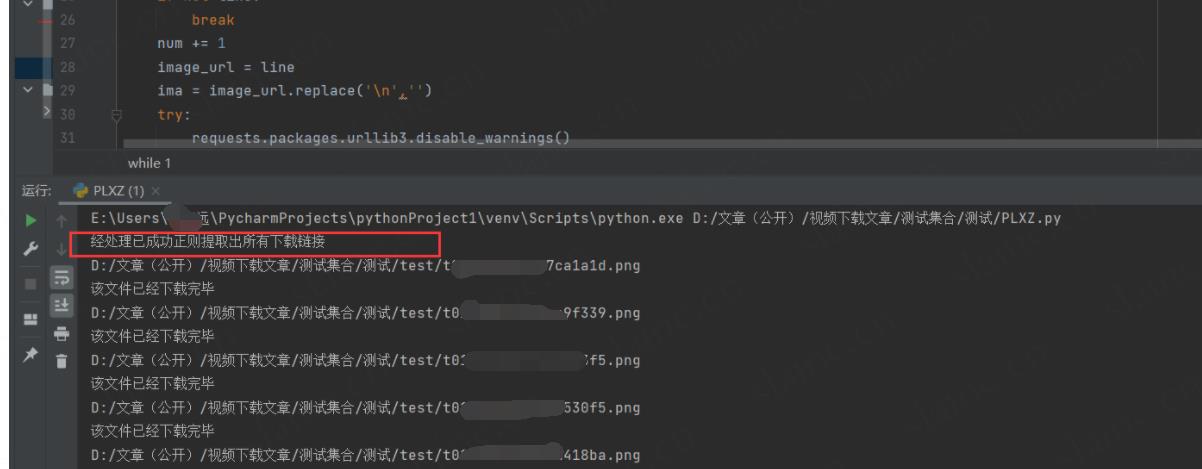
print("经处理已成功正则提取出所有下载链接")
file = open("./url提取.txt") # 打开存放链接的TXT文档
num = 0
while 1:
line = file.readline()
if not line:
break
num += 1
image_url = line
ima = image_url.replace('\\n','')
try:
requests.packages.urllib3.disable_warnings()
r = requests.get(ima,verify=False)
path = re.sub("https://p0.ssl.cdn.btime.com/|https://p1.ssl.cdn.btime.com/|https://p2.ssl.cdn.btime.com/|https://p3.ssl.cdn.btime.com/|https://p4.ssl.cdn.btime.com/", "D:/文章(公开)/视频下载文章/测试集合/测试/test/", line)
path = re.sub('\\n', '',path)
path = path.replace("?size=1x1", "")
print(path)
f = open(path, "wb")
f.write(r.content) # 将响应对象的内容写下来
print("该文件已经下载完毕")
f.close()
except Exception as e:
print('无法下载,%s' % e)
continue
print("经处理所有切片文件已经下载完毕")
file.close()
正常运行
生成提取出的下载链接
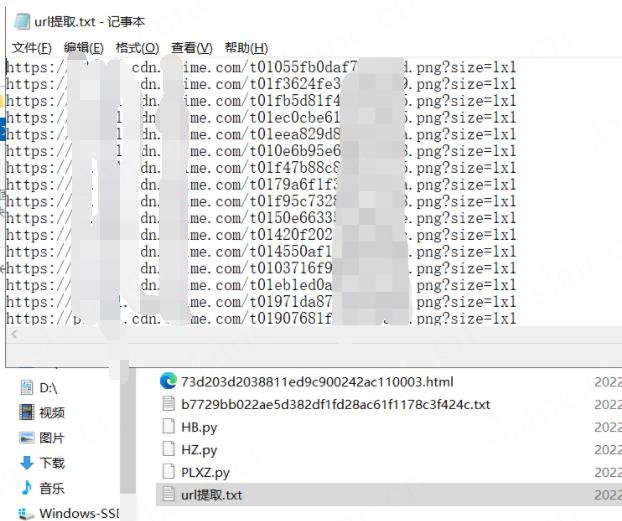
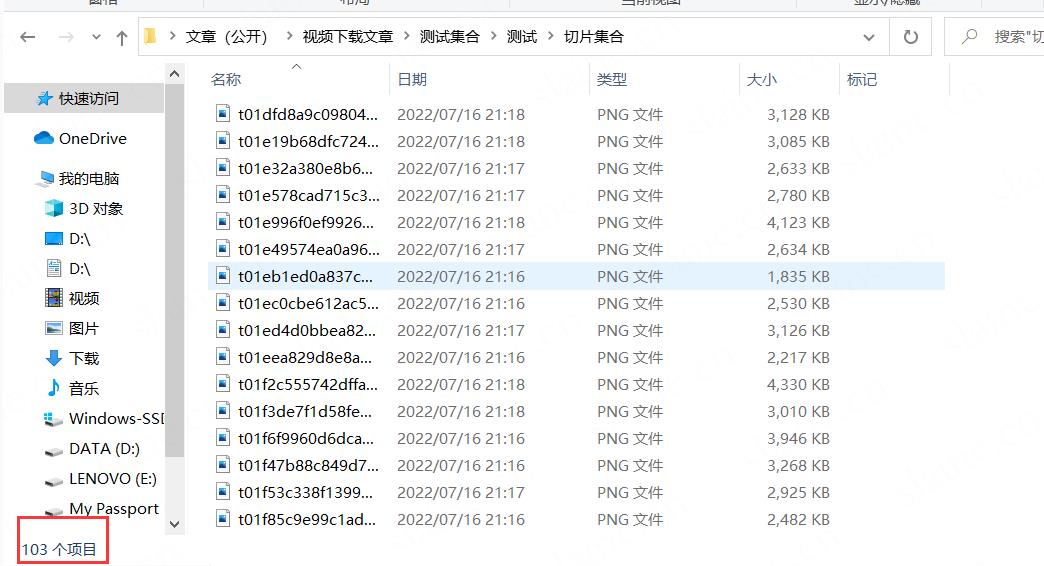
并且下载到指定位置
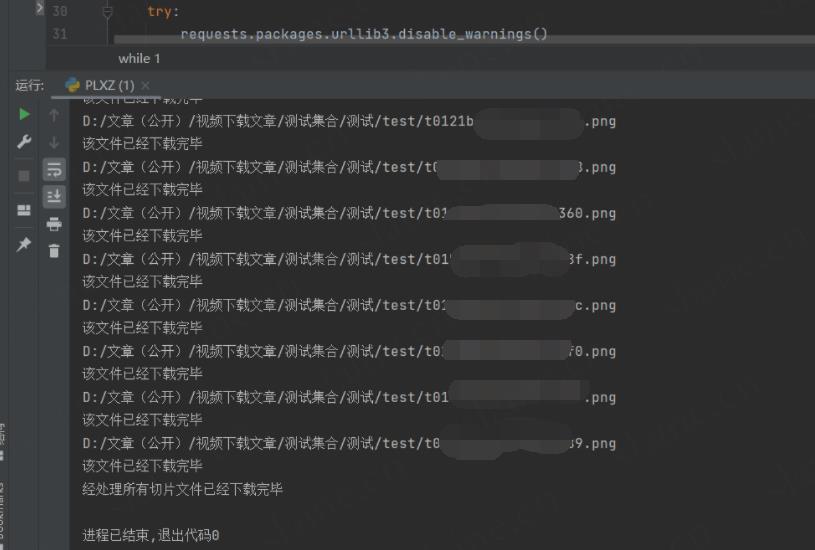
运行结束
批量改后缀
程序代码如下
import os
files = os.listdir('.')
for filename in files:
portion = os.path.splitext(filename)
if portion[1] == ".png":
newname = portion[0] + ".ts"
os.rename(filename,newname)
正常运行
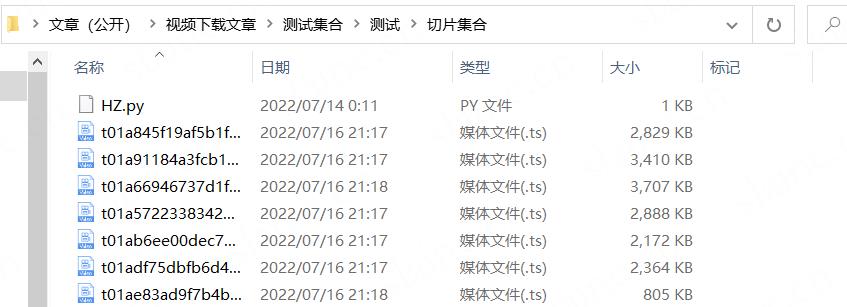
按m3u8指定顺序改文件切片名
接下来就是最关键的根据.m3u8里文件下载链接顺序批量修改文件名的环节
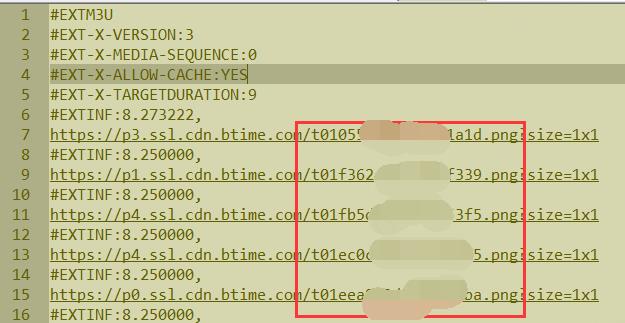
根据已有顺序改文件名为0001,0002,0003…顺序,这对之后的文件合并至关重要
这里就用到刚才提取的url文件
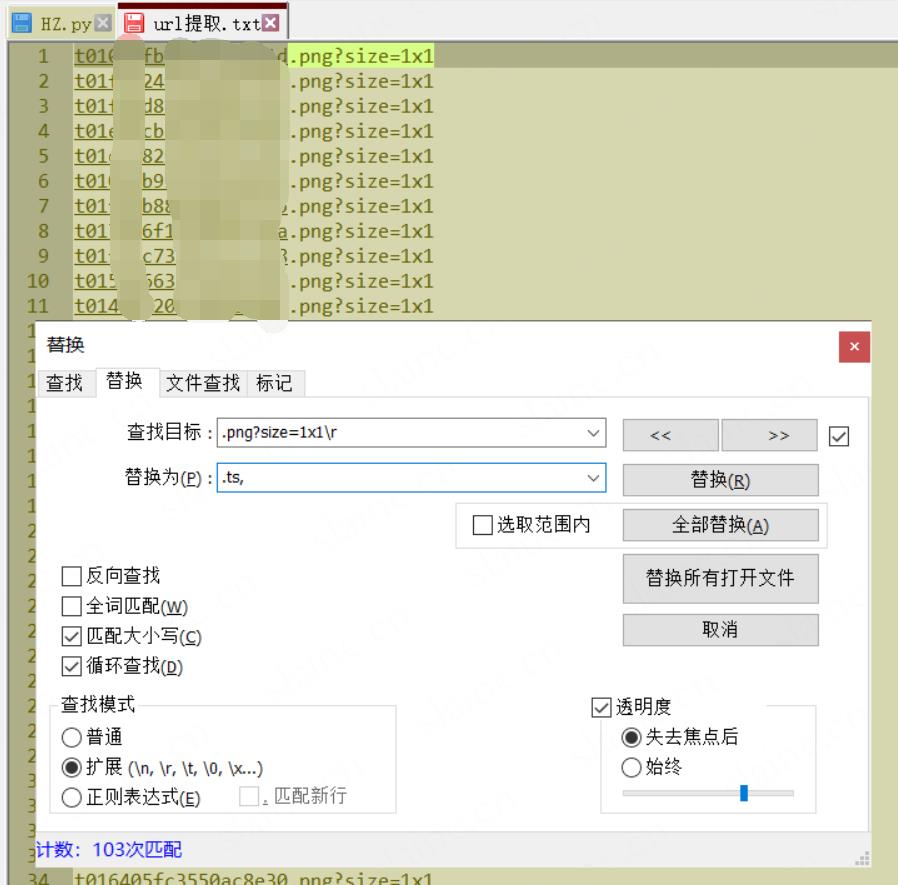
全部替换为.ts结尾且 , 间隔,整理为一行的队列形式

前提需要都准备好了,现在开始批量按照顺序改文件名
程序代码如下
import os
with open("01.txt","r",encoding="utf-8") as f:
list =f.readline().split(",")
list
print("01.txt内文件名数量:",len(list))
filelist=os.listdir(os.getcwd()+"/test")
print("test文件夹内文件数量:",len(filelist))
a=1
for i in list:
old_name=os.getcwd()+"\\\\test\\\\"+i
print("修改旧文件:",old_name)
if len(str(a))==1:
temp="000"+str(a)
elif len(str(a))==2:
temp="00"+str(a)
elif len(str(a))==3:
temp="0"+str(a)
else:
temp=str(a)
#print(temp)
new_name=os.getcwd()+"\\\\test\\\\"+temp+".ts"
print('新文件:',new_name)
a+=1
os.rename(old_name, new_name) # 用os模块中的rename方法对文件改名
正常运行完成
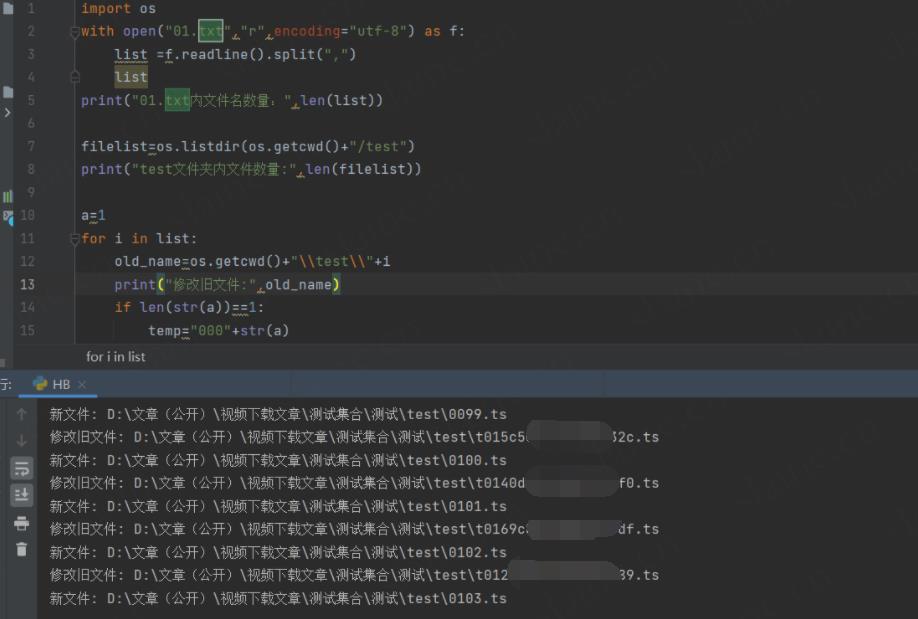
所有视频文件按照指定顺序排列完成
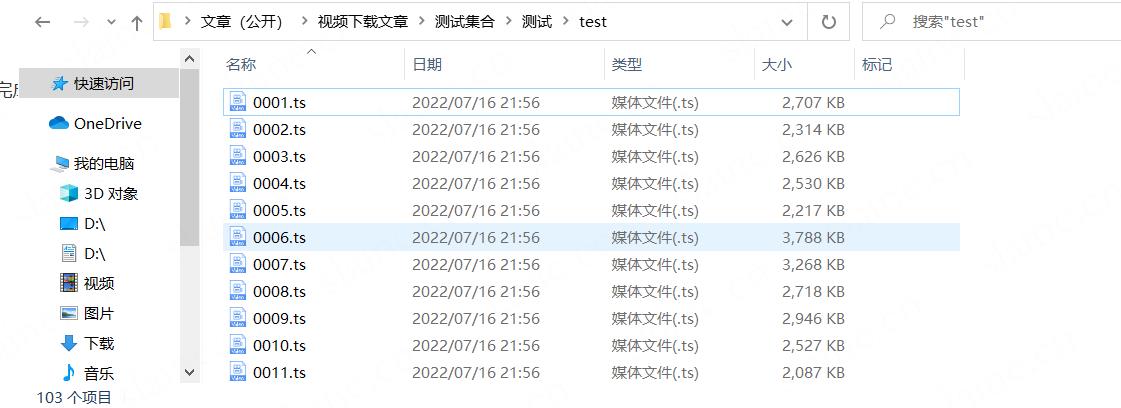
文件合并
然后用ffmpeg或者moviepy包或者其他工具合并就行
注意:前提必须是按照m3u8里下载链接的顺序改文件名(上操作)后才能正常合并出成品视频,否则会导致视频片段混乱(作者亲测)
这里网上随便一搜就找到了
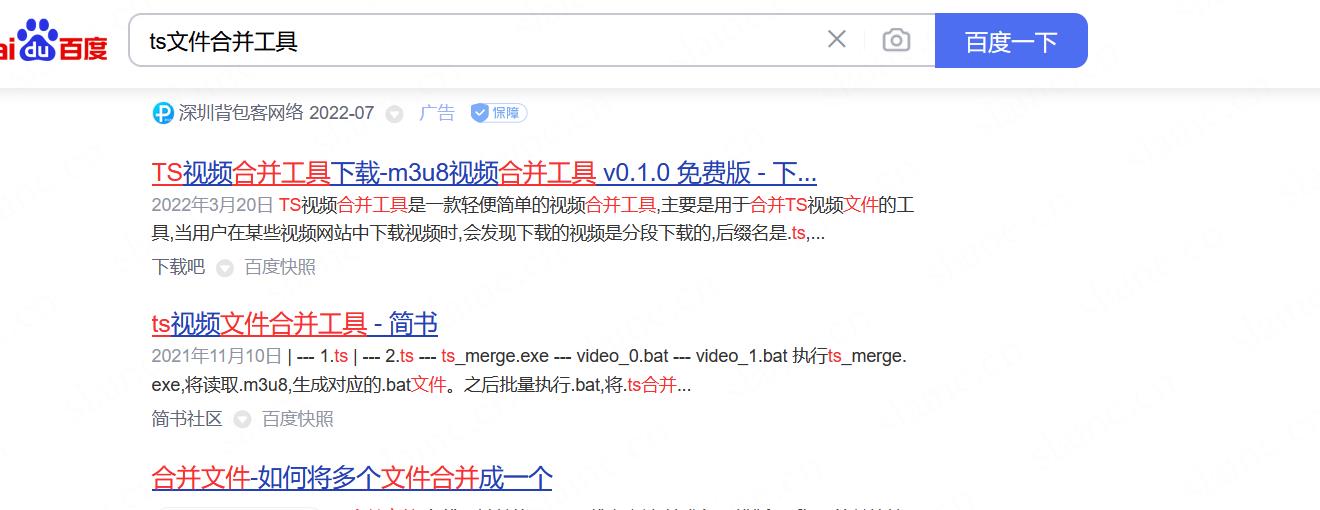
小东西真不错
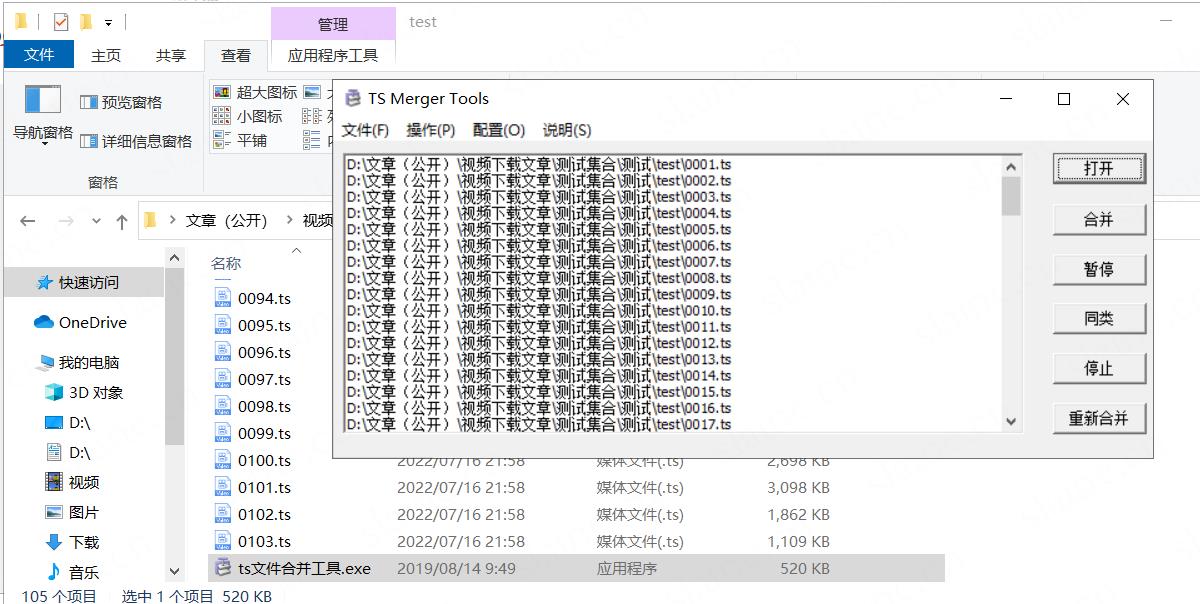
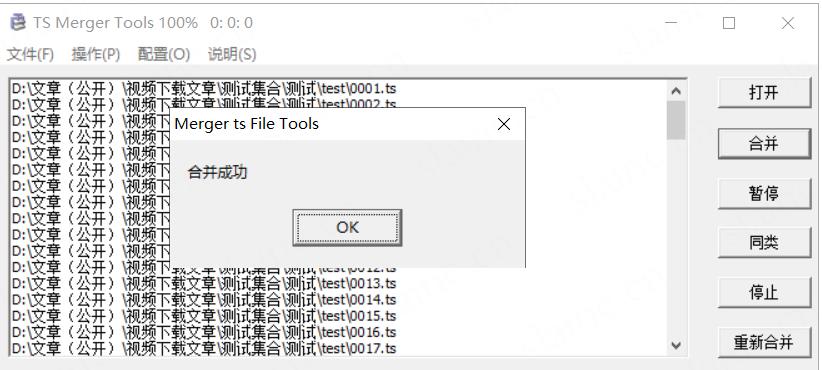
完成
然后就得到成品的文件了
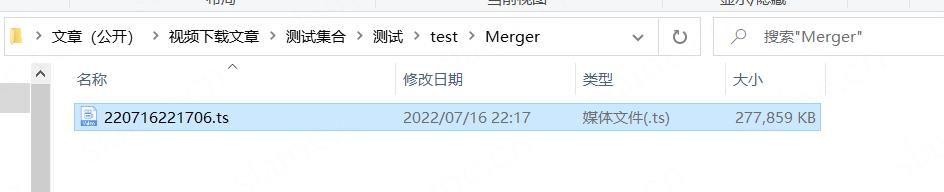
打开看看

内容清晰,完整流畅,达到目的
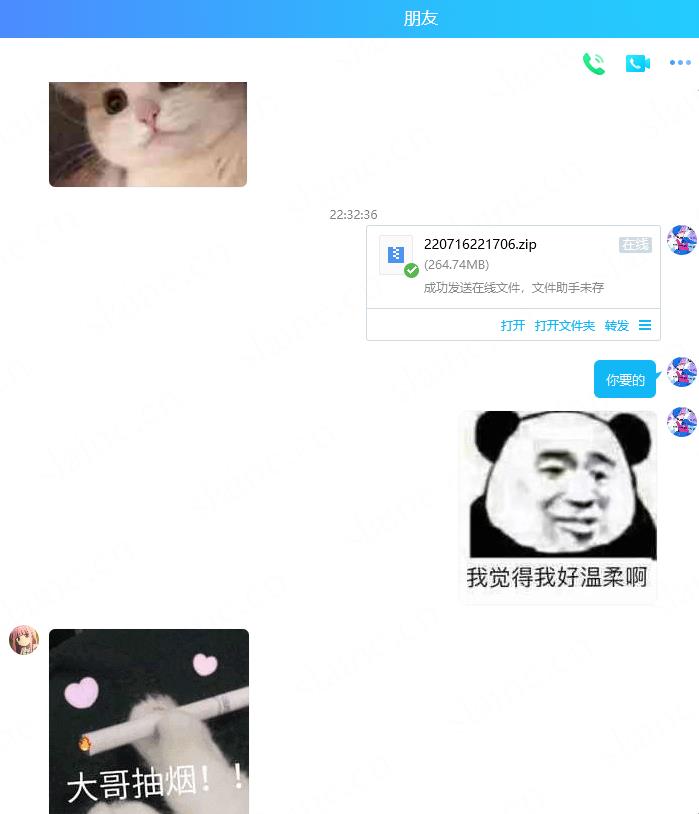
OVER
老工具人了
python 爬虫下载视频 并 安装使用 ffmpeg 合并ts视频文件 使用16进制 修改文件头类型
示例:私聊获取示例链接
第一步找到 视频资源接口
这是m3u8的资源 获取接口
使用 postman 模拟发送 请求
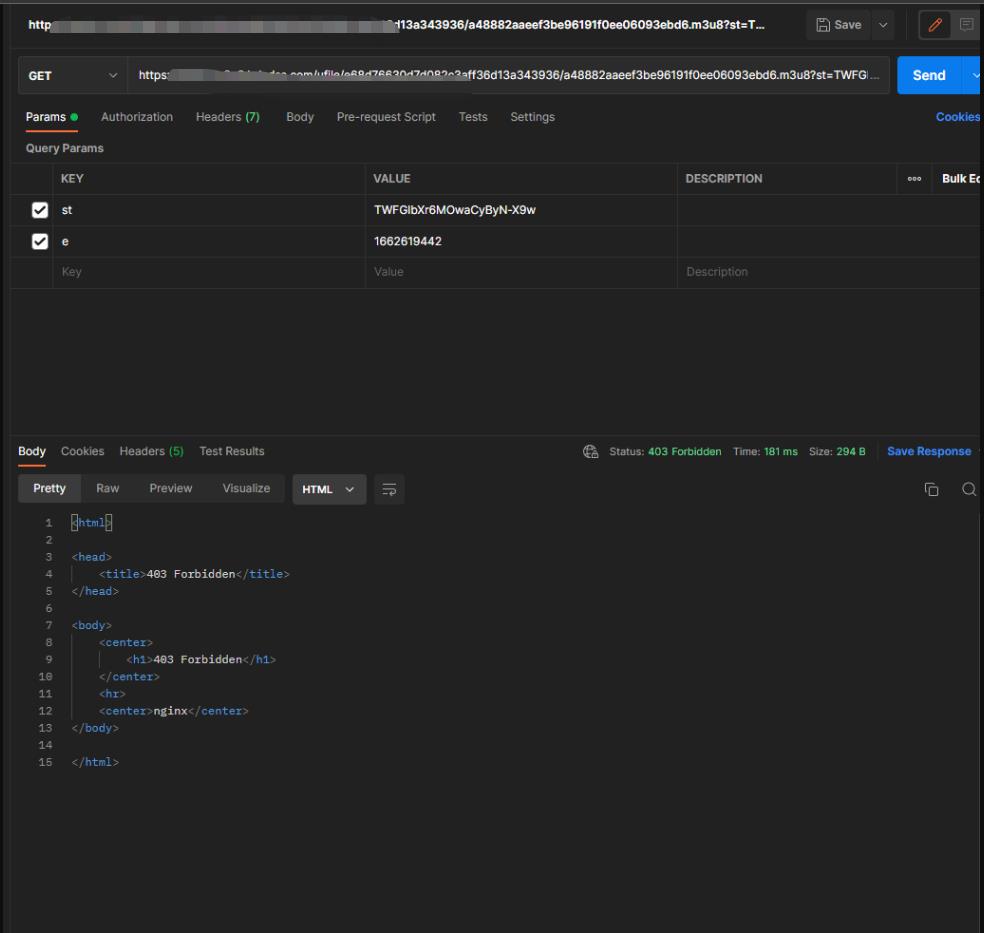
发现无法获取到数据 报错 403
查看请求头发现 还有其他请求参数
设置请求头
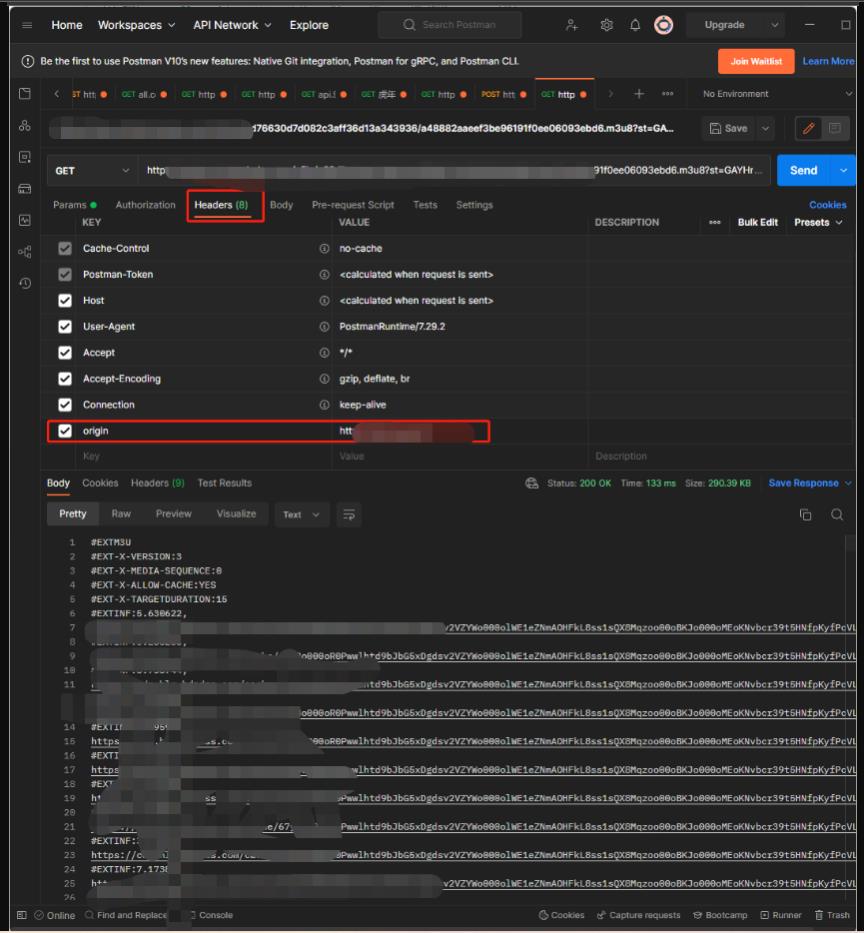
在pyhton 中 使用request 请求
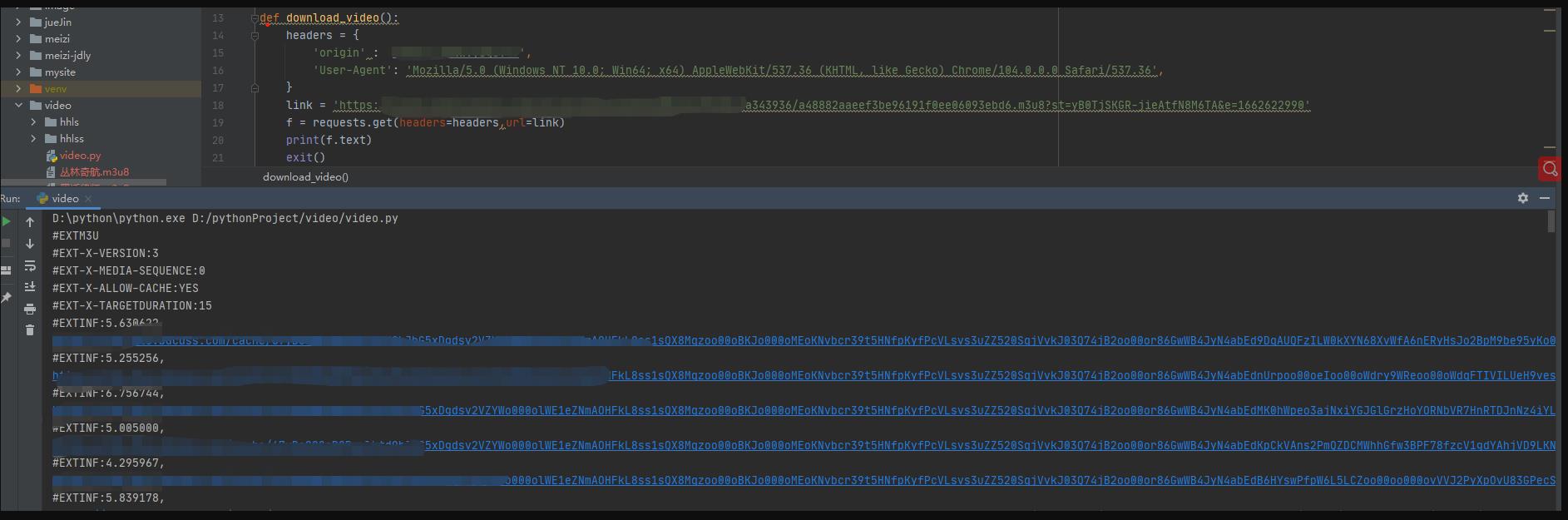
获取到资源文档 发现 链接内容都是 ts文件 采用多线程下载 ts文件
# 采用线程池下载m3u8里的ts
def down_ts():
# 读取 文件内容
with open("./hhls.m3u8", "r", encoding="utf-8") as f:
# n = 0
# 创建 10 个线程
with ThreadPoolExecutor(10) as t:
# 循环 文件内容
for n, line in enumerate(f):
line = line.strip()
# print(line)
# 判断是否是忽略内容
if line.startswith("#"):
# 是则跳过循环
continue
# 提交线程
t.submit(ts_video, n, line)
下载方法
# 下载ts视频 ./hhls 为下载ts视频存放的路径
def ts_video(n, line):
headers =
'origin' : 'https://xxxxx',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36',
resp3 = requests.get(headers=headers, url=line)
print(resp3.status_code)
with open(f"./hhls/n.ts", "wb+") as f:
f.write(resp3.content)
视频下载完成之后 则需要将 ts 文件 合并成MP4 文件
这时则需要使用到 ffmpeg
ffmpeg 安装步骤
下载成功后解压即可
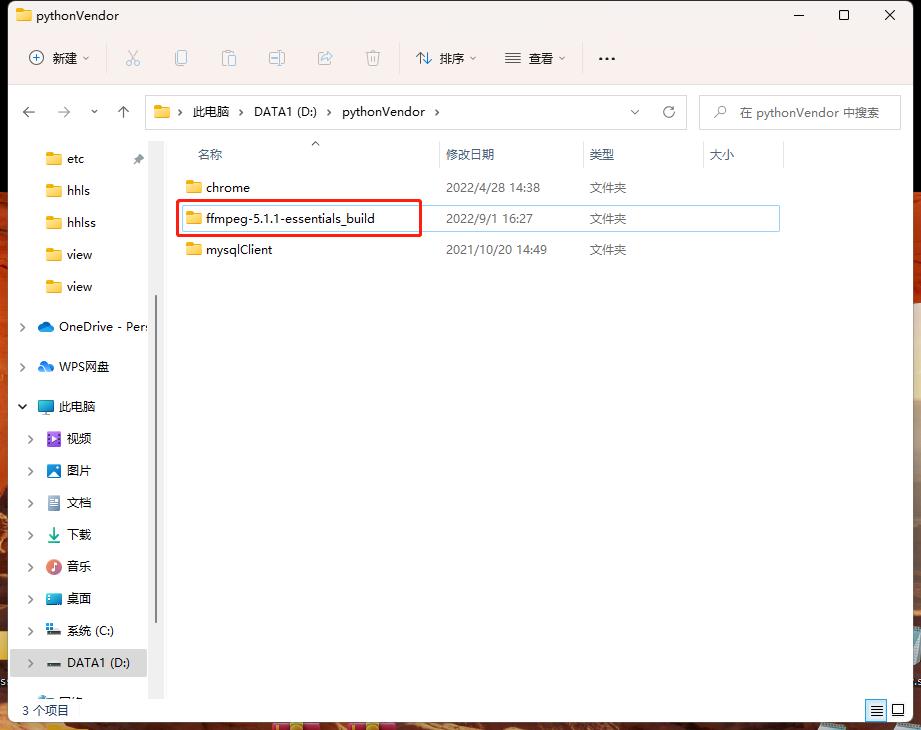
执行 合并视频代码
def movie_video():
filePath = "./hhls"
# 获取当前文件夹下 使用文件名称
file_list = os.listdir(filePath)
print(file_list)
li = []
for file in file_list:
# 字符串截取
file = file.split(".")[0]
# 添加进 列表
li.append(int(file))
# 列表进行排序
li.sort()
ts_file_name = []
# 循环列表
for i in li:
i = str(i) + ".ts"
# 添加 文件名进入列表
ts_file_name.append(i)
# 创建或打开文件 执行写入
with open("./hhls/file_list.txt", "w+") as f:
# 循环 文件名列表
for file in ts_file_name:
# 循环写入文件
f.write("file ''\\n".format(file))
print("file_list.txt已生成")
txt_file = "./hhls/file_list.txt"
mp4 = "./hhls/hhls.mp4"
# 执行合并命令
cmd = f"ffmpeg -f concat -i " + txt_file + " -c copy " + mp4
print(cmd)
try:
# 执行命令
os.system(cmd)
except Exception as e:
print(e)
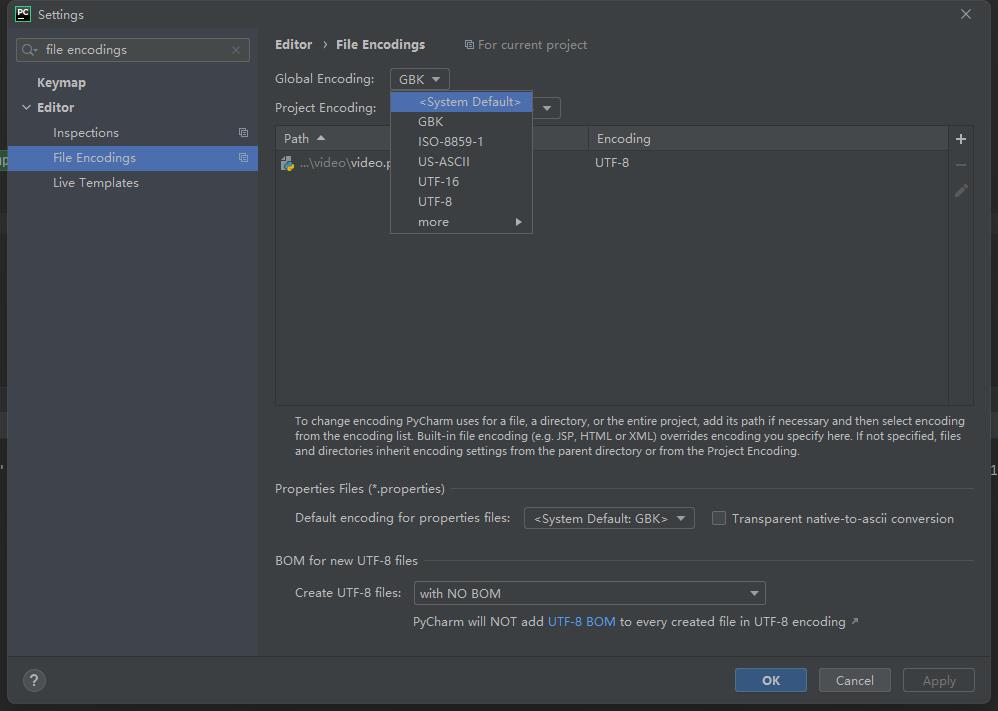
print("done")发现报错乱码

乱码解决方法 在 pycharm 中 修改配置 打开 file 下 settings 中 搜索 file encodings 修改字符集为 GBK 即可
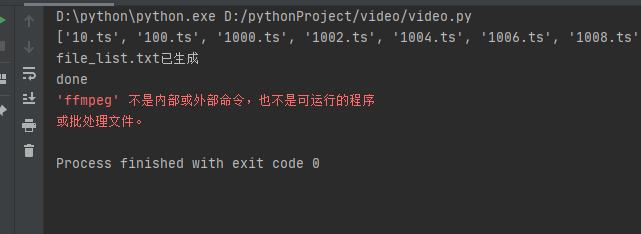
这是由于没有将 ffmpeg 添加到环境变量导致
回到桌面 右键点击此电脑 点击属性 添加系统环境变量 ffmpeg.exe 所在的文件位置即可
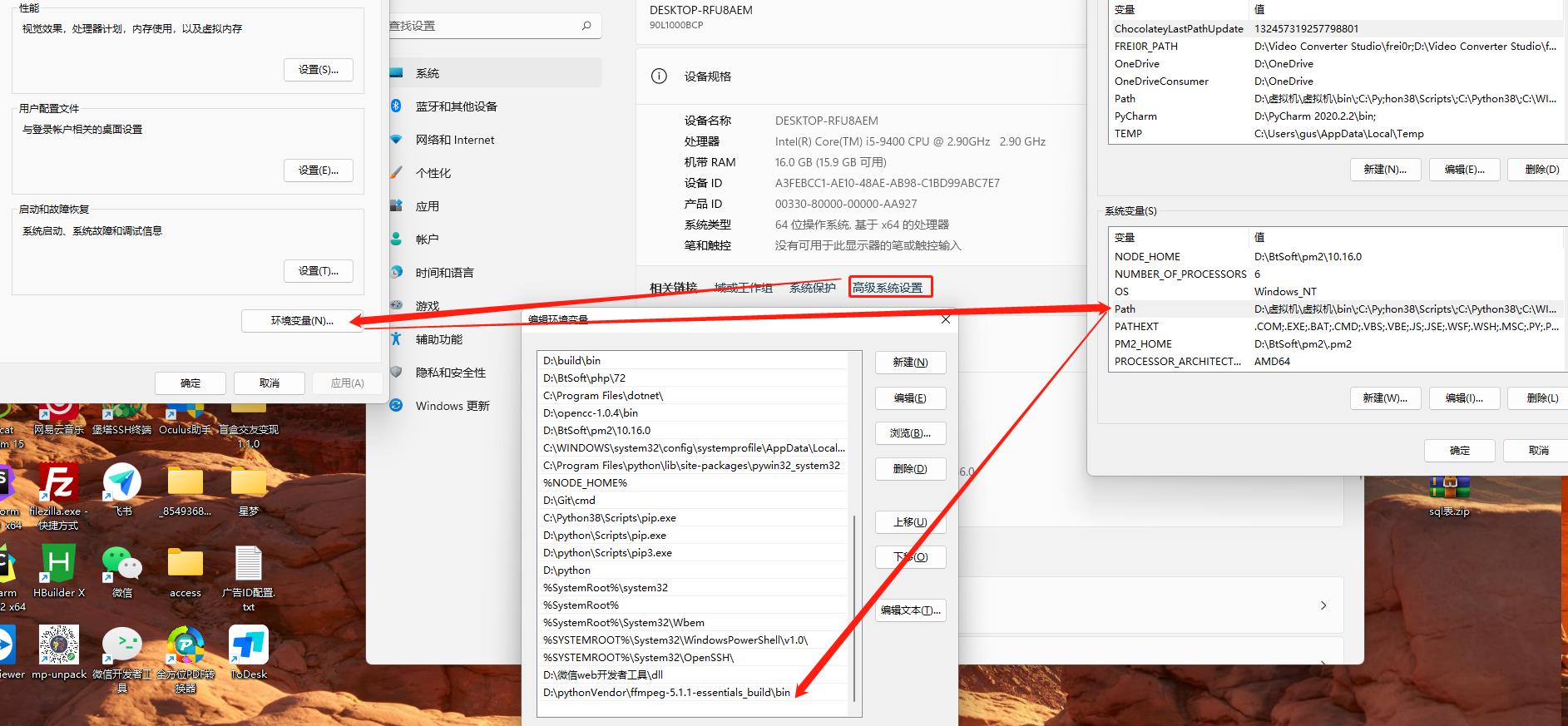
打开cmd 执行命令 ffmpeg -v 查看是否添加成功
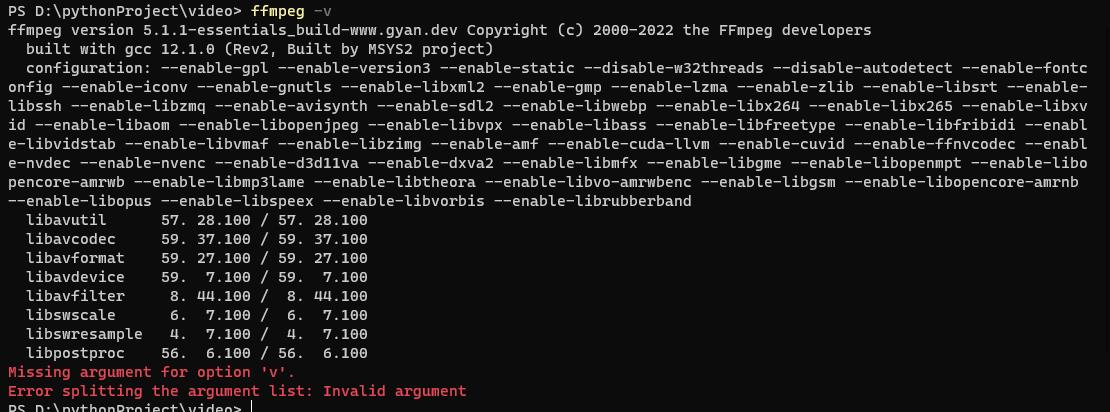
添加成功重启 pycharm 编辑器 即可
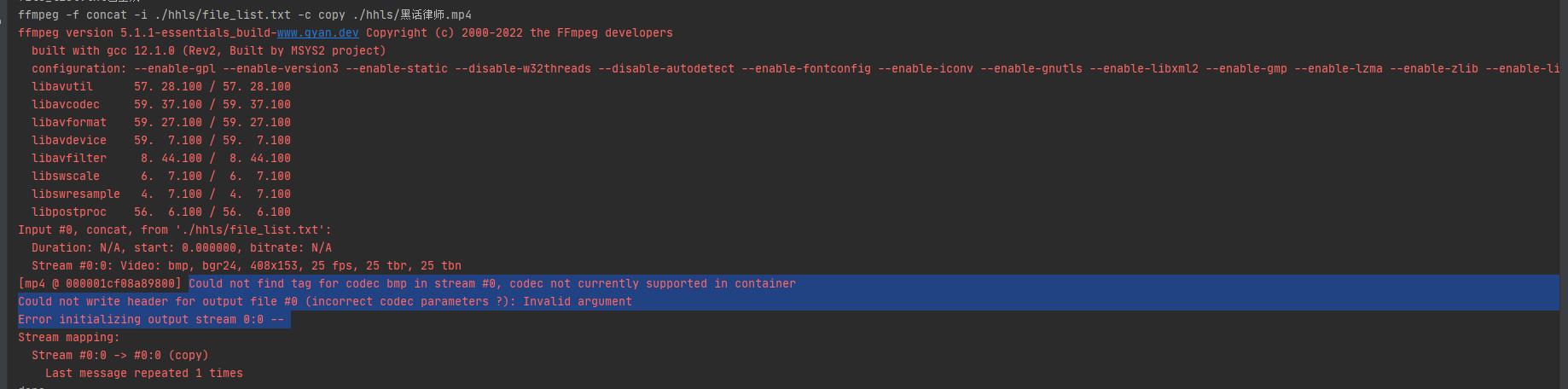
重新运行 合并ts文件时报错
Could not find tag for codec bmp in stream #0, codec not currently supported in container
Could not write header for output file #0 (incorrect codec parameters ?): Invalid argument
Error initializing output stream 0:0 --
这种是利用图床来存储视频切片 文件前被增加了BMP的header信息,导致ffmpeg错误地识别为BMP图片,自然不能合并了。
其实他就是 ts文件,被改成.bmp 后缀,放到图床,达到白嫖图床的目的
那么如何解决这个问题呢
使用16进制查看器WinHex 编辑 删除
47 40 11 之前的数据即可 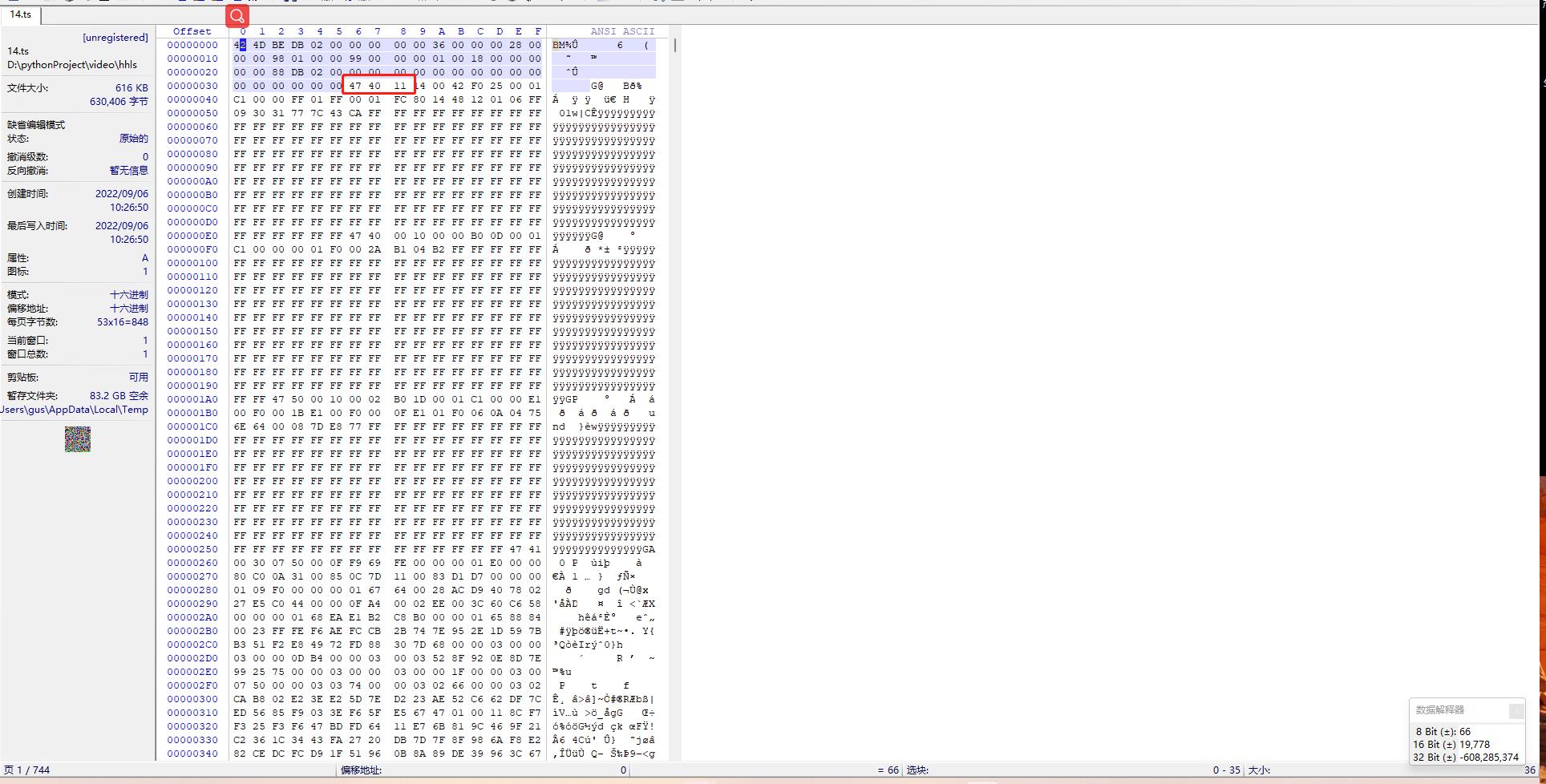
片段示例
12.ts 文件 16进制数据
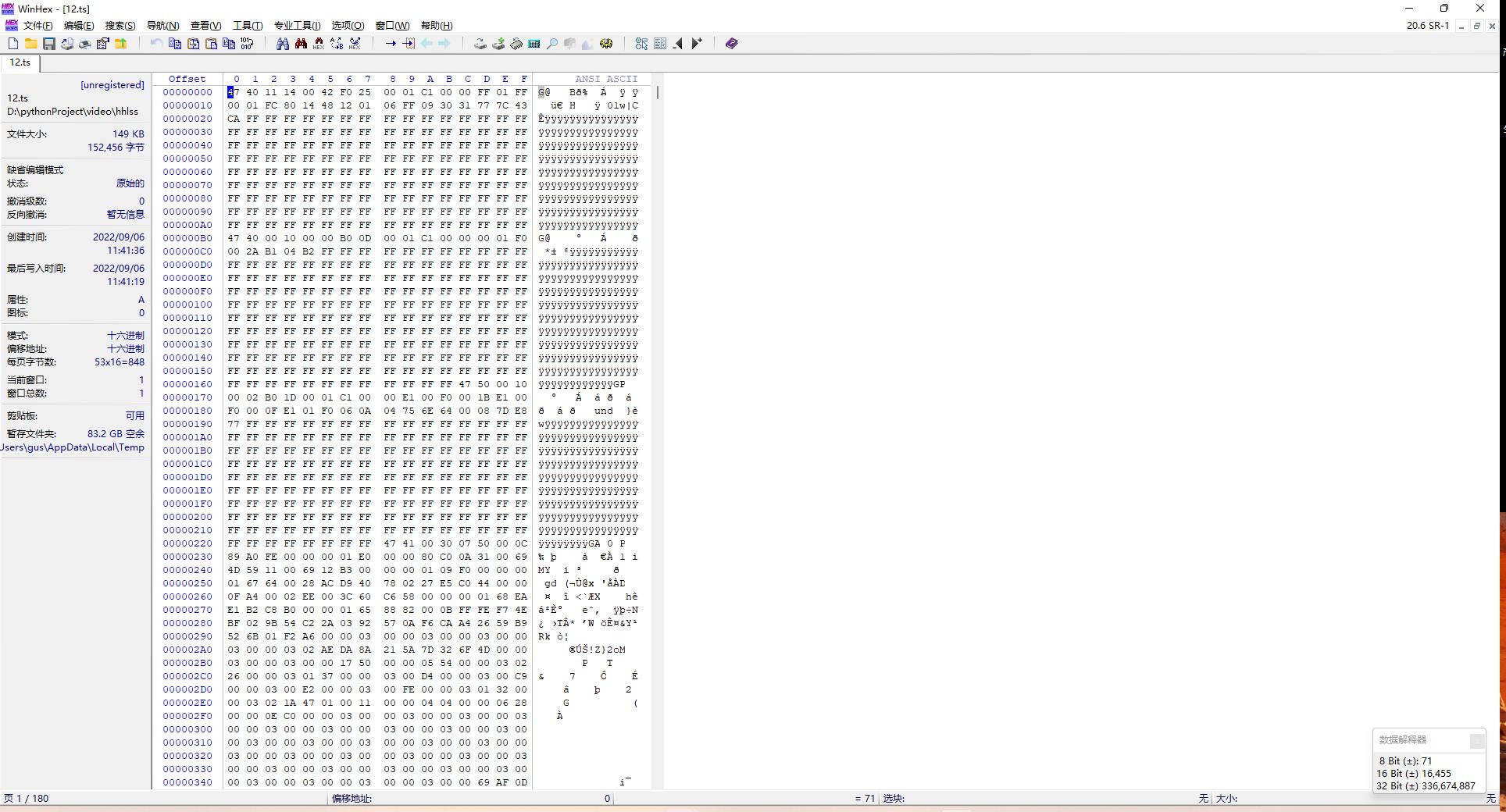
删除 bmp头后 执行合并成功
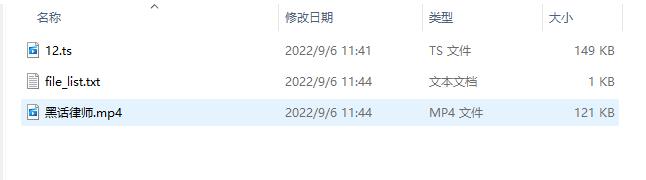

png 头部信息 ts片段数据

常用文件格式十六进制文件头
JPEG (jpg),文件头:FFD8FF
PNG (png),文件头:89504E47
GIF (gif),文件头:47494638
TIFF (tif),文件头:49492A00
Windows Bitmap (bmp),文件头:424D
CAD (dwg),文件头:41433130
Adobe Photoshop (psd),文件头:38425053
Rich Text Format (rtf),文件头:7B5C727466
XML (xml),文件头:3C3F786D6C
HTML (html),文件头:68746D6C3E
Email [thorough only] (eml),文件头:44656C69766572792D646174653A
Outlook Express (dbx),文件头:CFAD12FEC5FD746F
Outlook (pst),文件头:2142444E
MS Word/Excel (xls.or.doc),文件头:D0CF11E0
MS Access (mdb),文件头:5374616E64617264204A
WordPerfect (wpd),文件头:FF575043
Adobe Acrobat (pdf),文件头:255044462D312E
Quicken (qdf),文件头:AC9EBD8F
Windows Password (pwl),文件头:E3828596
ZIP Archive (zip),文件头:504B0304
RAR Archive (rar),文件头:52617221
Wave (wav),文件头:57415645
AVI (avi),文件头:41564920
Real Audio (ram),文件头:2E7261FD
Real Media (rm),文件头:2E524D46
MPEG (mpg),文件头:000001BA
MPEG (mpg),文件头:000001B3
Quicktime (mov),文件头:6D6F6F76
Windows Media (asf),文件头:3026B2758E66CF11
MIDI (mid),文件头:4D546864
那么问题来了 如何在代码中实现呢
示例:
# bmp标头文件示例
f = open(f'./hhls/648.ts','rb')# 二进制读
# 读取文件流
a = f.read()# 打印读出来的数据
# 转换16进制
hexstr = binascii.b2a_hex(a)
# 转换成 字符串
hexstr = hexstr.decode('UTF-8')
# print(hexstr)
#判断是否 存在 特定标头
header = ['FFD8FF','89504E47','47494638','424D']
for value in header:
# 搜索 判断16进制内容是否 存在 特定标头
if hexstr.startswith(value.lower()) :
# 进行字符串截图
new_hexstr = hexstr[len(value):]
# 字符串转为bytes 类型 数据
new_hexstr = bytes.fromhex(new_hexstr)
f = open(f'./hhls/648.ts', 'wb') # 二进制写模式
f.write(new_hexstr) # 二进制写入成功合成之后


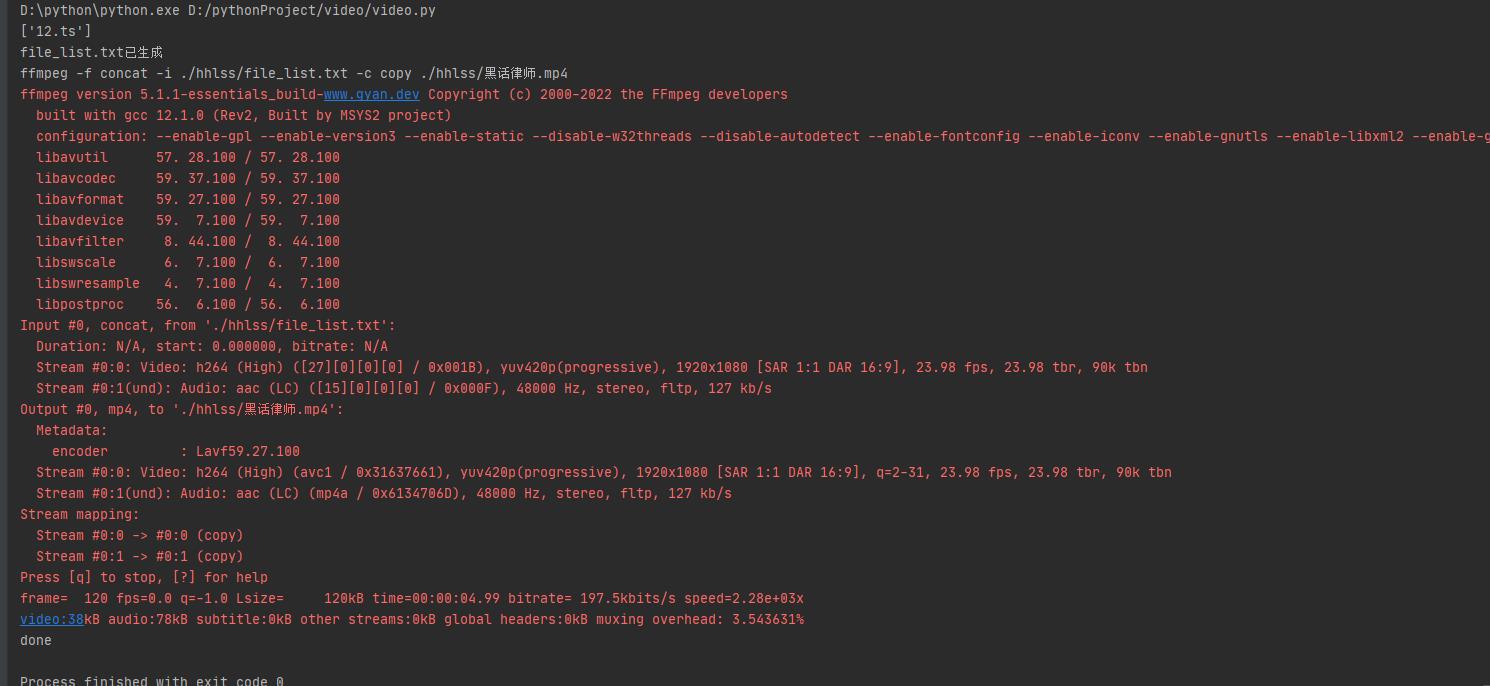
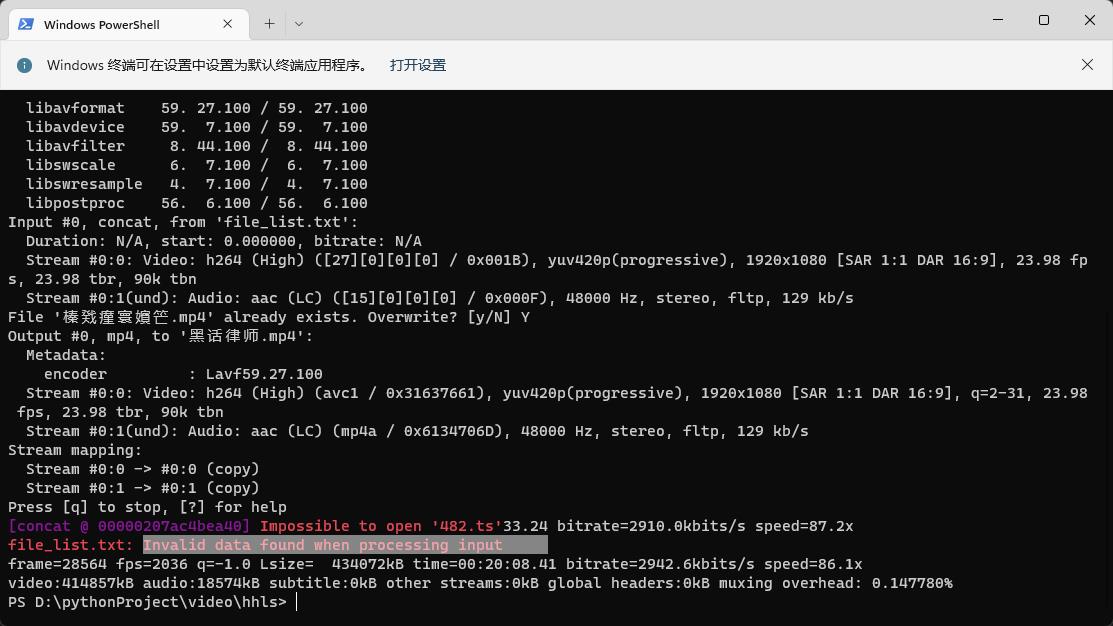
发现 视频时长不正确 在命令行 执行合并 发现 482.ts文件 有问题无法合并
打开文件发现文件资源有问题 属于无效文件
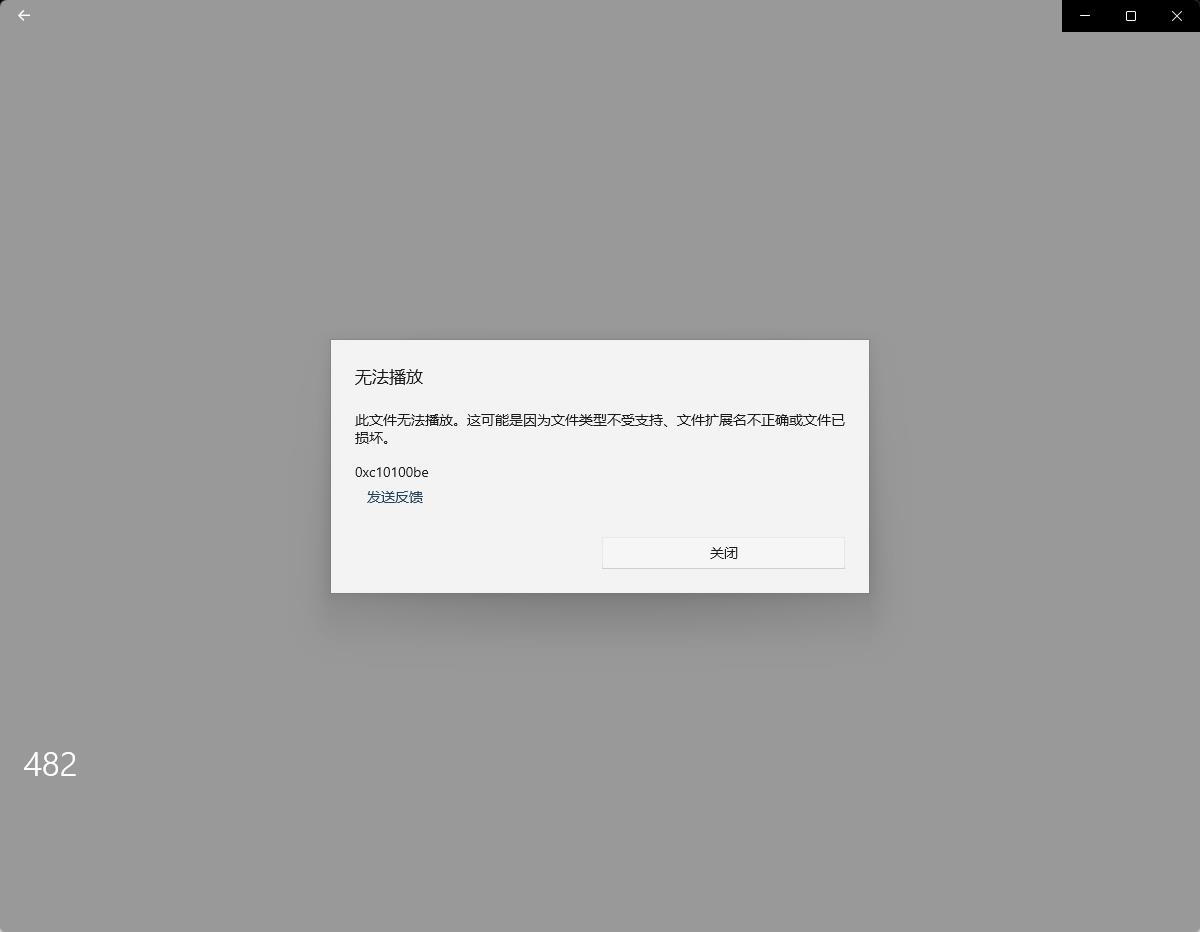
查看网站后发现 网站资源也丢失这一片段
解决方法 删除 482.ts 文件 重新执行 脚本
或
修改 file_list.txt 删除 file '482.ts' 即可 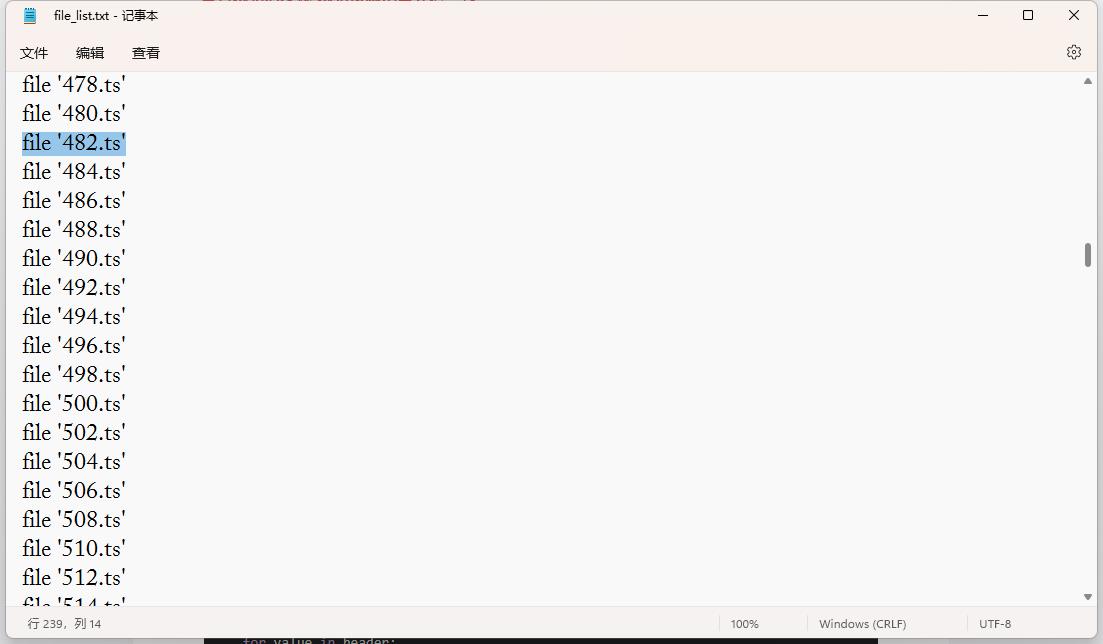
重新执行合并命令
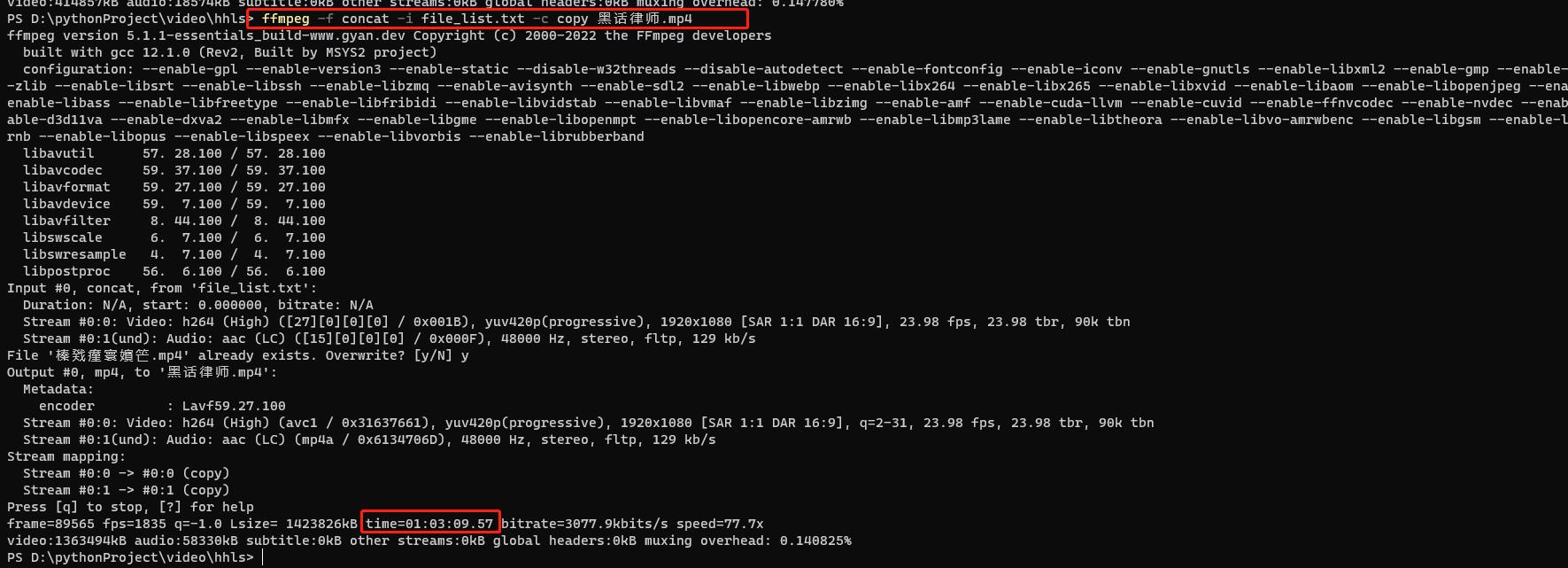
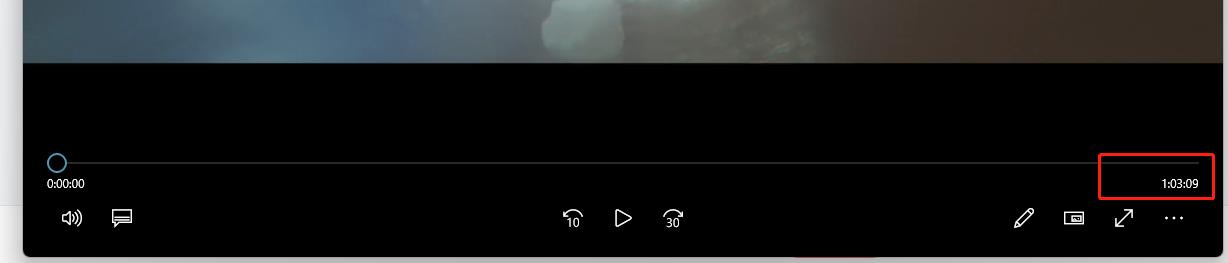
合并ts 资源成功
下载方法 优化 后
# 下载ts视频 ./hhls 为下载ts视频存放的路径
def ts_video(n, line):
headers =
'origin' : 'https://xxxxx',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36',
resp3 = requests.get(headers=headers, url=line)
print(resp3.status_code)
with open(f"./hhls/n.ts", "wb+") as f:
f.write(resp3.content)
# bmp标头文件示例
f = open(f'./hhls/n.ts','rb')# 二进制读
# 读取文件流
a = f.read()# 打印读出来的数据
# 转换16进制
hexstr = binascii.b2a_hex(a)
# 转换成 字符串
hexstr = hexstr.decode('UTF-8')
# print(hexstr)
#判断是否 存在 特定标头
header = ['FFD8FF','89504E47','47494638','424D']
for value in header:
# 搜索 判断16进制内容是否 存在 特定标头
if hexstr.startswith(value.lower()) :
# 进行字符串截图
new_hexstr = hexstr[len(value):]
# 字符串转为bytes 类型 数据
new_hexstr = bytes.fromhex(new_hexstr)
f = open(f'./hhls/n.ts', 'wb') # 二进制写模式
f.write(new_hexstr) # 二进制写入
print(n, "下载完成")
完整代码示例
示例网站地址:私聊获取
import requests
import os
import binascii
from concurrent.futures import ThreadPoolExecutor
def download_video():
headers =
'origin' : 'xxxxxx',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36',
# 当前链接只有 几分钟 时效 请去示例网站地址 实时获取
link = 'xxxxxx'
resp = requests.get(headers=headers,url=link)
# print(resp)
m3u8text = resp.text
with open("hhls.m3u8", "w") as f:
f.write(m3u8text)
print("hhls.m3u8下载完成")
# 采用线程池下载m3u8里的ts
def down_ts():
# 读取 文件内容
with open("./hhls.m3u8", "r", encoding="utf-8") as f:
# n = 0
# 创建 10 个线程
with ThreadPoolExecutor(10) as t:
# 循环 文件内容
for n, line in enumerate(f):
line = line.strip()
# print(line)
# 判断是否是忽略内容
if line.startswith("#"):
# 是则跳过循环
continue
# 提交线程
t.submit(ts_video, n, line)
# 下载ts视频 ./hhls 为下载ts视频存放的路径
def ts_video(n, line):
headers =
'origin' : 'xxxxxx',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36',
resp3 = requests.get(headers=headers, url=line)
print(resp3.status_code)
with open(f"./hhls/n.ts", "wb+") as f:
f.write(resp3.content)
# bmp标头文件示例
f = open(f'./hhls/n.ts','rb')# 二进制读
# 读取文件流
a = f.read()# 打印读出来的数据
# 转换16进制
hexstr = binascii.b2a_hex(a)
# 转换成 字符串
hexstr = hexstr.decode('UTF-8')
# print(hexstr)
#判断是否 存在 特定标头
header = ['FFD8FF','89504E47','47494638','424D']
for value in header:
# 搜索 判断16进制内容是否 存在 特定标头
if hexstr.startswith(value.lower()) :
# 进行字符串截图
new_hexstr = hexstr[len(value):]
# 字符串转为bytes 类型 数据
new_hexstr = bytes.fromhex(new_hexstr)
f = open(f'./hhls/n.ts', 'wb') # 二进制写模式
f.write(new_hexstr) # 二进制写入
print(n, "下载完成")
def movie_video():
filePath = "./hhls"
# 获取当前文件夹下 使用文件名称
file_list = os.listdir(filePath)
print(file_list)
li = []
for file in file_list:
# 字符串截取
file = file.split(".")[0]
# 添加进 列表
li.append(int(file))
# 列表进行排序
li.sort()
ts_file_name = []
# 循环列表
for i in li:
i = str(i) + ".ts"
# 添加 文件名进入列表
ts_file_name.append(i)
# 创建或打开文件 执行写入
with open("./hhls/file_list.txt", "w+") as f:
# 循环 文件名列表
for file in ts_file_name:
# 循环写入文件
f.write("file ''\\n".format(file))
print("file_list.txt已生成")
txt_file = "./hhls/file_list.txt"
mp4 = "./hhls/hhls.mp4"
# 执行合并命令
cmd = f"ffmpeg -f concat -i " + txt_file + " -c copy " + mp4
print(cmd)
try:
# 执行命令
os.system(cmd)
except Exception as e:
print(e)
print("done")
if __name__ == '__main__':
download_video()
down_ts()
movie_video()以上是关于m3u8视频爬虫下载及合并的主要内容,如果未能解决你的问题,请参考以下文章