人工智能交互系统界面设计(Tkinter界面设计)
Posted lyx4949
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了人工智能交互系统界面设计(Tkinter界面设计)相关的知识,希望对你有一定的参考价值。
文章目录
前言
在现代信息化时代,图形化用户界面(Graphical User Interface, GUI)已经成为各种软件应用和设备交互的主流方式,与传统的命令行界面(CLI)相比,GUI 具有直观性、易用性、交互性、可视化和多任务处理等优势。设计良好的用户交互界面可以让用户以更加直观、友好的方式与计算机系统进行交互,提高用户的满意度和使用体验。本项目将设计一款实用人机交互界面,用户通过界面的按钮、文本框、图表等能够更加便捷地完成人脸采识别、语音交互下单等任务。
下面是界面演示视频。
人工智能系统界面操作视频
一、项目介绍
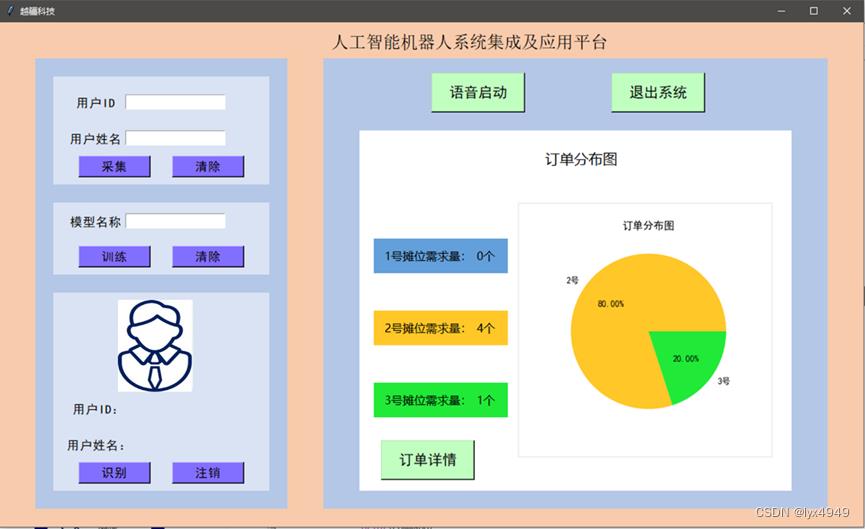
本项目利用Tkinter模块搭建了一个人工智能系统界面,如图1和图2所示,用户在界面按下按钮或者输入文本框内容,可以与系统进行数据交互,避免通过命令行等繁琐的输入方式来执行程序。本项目设计的界面主要包含以下两大功能。
1.人脸信息验证
界面的左边栏目中用户可进行人脸采集、模型训练、人脸识别验证。
(1)人脸采集。用户首先需要完成人脸采集,输入“用户ID”“用户姓名”后,点击“采集”按钮,可以调取摄像头,完成100张人脸图像的采集。
(2)模型训练。用户需要在“模型名称”中输入对应人脸模型的名字,例如“lyx”,点击“训练”按钮后,系统会自动生成一个命为“lyx.yml”的模型,并自动保存到“FaceRecognition/Model”文件夹下。
(3)人脸识别。用户完成人脸采集与模型训练之后,才能点击“识别”按钮,当人脸识别成功后,系统会调取该用户的人脸图像显示在系统界面上。
当用户按下界面中的“清除”“注销”按钮可以消除已有的信息。
2.订单信息可视化
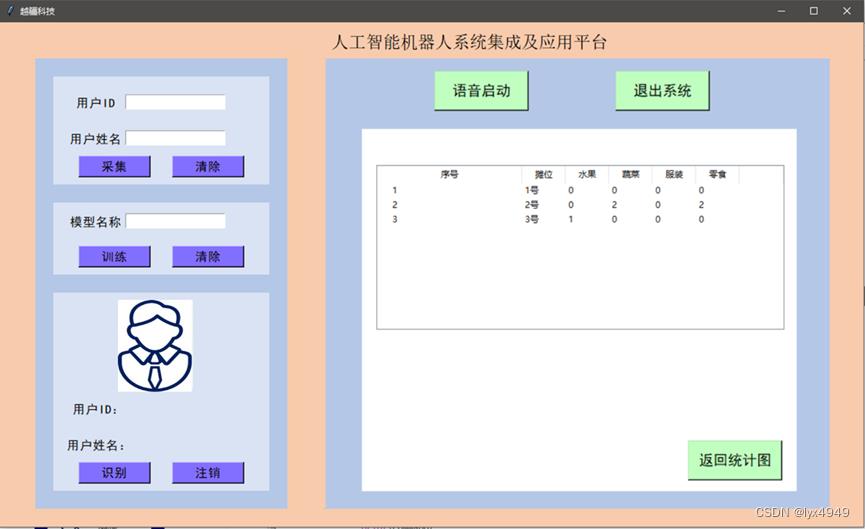
用户可在界面右边栏目中,通过按下“语音启动”按钮,说出“系统启动”来开启后续操作。系统启动后,会通过语音合成提醒用户完成人脸识别,只有用户的身份信息核实通过后,用户才能够向3位摊主进行下单任务,下单时同样需要用户通过与系统进行语音交互来完成。订单完成后,界面显示用户向每位摊主下单的总数,并通过扇形图展示出来。点击下方的“订单详情”,界面会切换到对每位摊主详细的需求。
二、项目准备
1.Tkinter模块相关组件的知识,可以详看我前面写过的文章
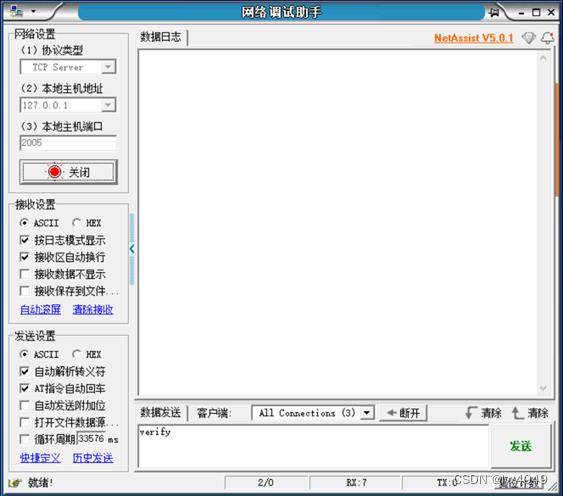
2.准备一个TCP调试助手,用于TCP通信。如果没有,可见文末附件。打开TCP调试助手,设置为服务端,其IP地址为“127.0.0.1”,端口为“2005”,打开开关。
3.安装好相关的库文件,详细见下图,版本是3.75。

4.本项目中的程序人脸识别和语音功能是直接调用已经写好的人脸采集、训练、识别和语音识别、语音合成的函数,可以见人脸识别和语音识别和语音合成这3篇文章,全部的程序都会放在本文末附录。
三、项目实施
备注:界面设计的参考程序建议从后面的主程序往前看,找到对应的功能函数。
1.导入相关库文件
from tkinter import *
from tkinter import ttk
from PIL import Image, ImageTk
import time
import cv2
from playsound import playsound #播放声音
from FaceCollect import GetFace #导入采集程序中的函数
import socket #连接服务器
from FaceTrain import getImagesAndLabels,recognizer #导入训练程序中的函数
import numpy as np
from FaceRecognition import Face #导入识别程序中的函数
from baiduasr import record, asr_updata #语音合成文件中的函数
import baiduasr #语音合成文件
from TTS import tts #语音合成文件
import threading #开启线程所用
import openpyxl #表格处理模块
import matplotlib #绘图
from matplotlib.figure import Figure
2.人脸信息验证功能
# 人脸图片显示函数,所有的人脸图片显示的时候可以加载这个函数
def face_image(face_photo):
global photo1 # 一定要将photo设置成全局变量不然调用显示不出来 image
photo_open1 = Image.open('./' + face_photo + '.jpg') # 打开图片
photo1 = photo_open1.resize((100 , 120)) # 图片尺寸
photo1 = ImageTk.PhotoImage(photo1)
Label(Frame1_3,image=photo1).place(x= 90,y = 10) # 放置人脸图像的标签及位置
#清除函数
def clear(entry1,entry2):
print("文本清除")
entry1.delete(0,END) #清除文本框内容,从第一个字符到最后一个字符
entry2.delete(0,END) #清除文本框内容,从第一个字符到最后一个字符
# 人脸注销函数。function:face_logout
def face_logout():
print("图像注销")
Label(Frame1_3,text = " " , bg = "#DAE3F3").place(x= 100,y = 150) # 用空格顶掉原有的信息
Label(Frame1_3,text = " " , bg = "#DAE3F3").place(x= 100,y = 200) # 用空格顶掉原有的信息
face_image('face')
# 采集函数。function:fece_collect
#利用get()方法获取用户输入的姓名、ID,调用FaceCollect中的Getface函数完成图像采集。
def register():
print("人脸采集")
Name = name.get()
ID = id.get() #获取文本框内容
GetFace(Name,ID) #采集人脸数据
# 人脸训练函数。function:fece_train
#利用get()方法获取用户输入的模型名称,调用FaceTrain中的函数完成人脸模型的训练,生成的模型文件保存到Model文件夹内,并以用户输入的模型名称命名。
def Train():
print("人脸训练")
Moudle = moudle_name1.get() #获取文本框内容
faces, ids = getImagesAndLabels(path) #获取训练程序中的人脸和标签
# 开始训练
recognizer.train(faces, np.array(ids))
# 保存文件
recognizer.write(r'./Model/'+ Moudle +'.yml') #以用户输入的模型名称给生成的模型命名
# 人脸识别函数
#完善“识别”按钮函数。调用FaceRecognition中的Face函数来识别用户身份,并将信息显示在界面。
def face_recognition():
print("人脸识别")
Name,idnum,Confidence = Face() #调用人脸识别函数
print("您的名字是:", Name,"您的ID是:", idnum)
Label(Frame1_3,text=idnum,font=("黑体",15),width=4,bg = "#DAE3F3").place(x=110,y=150)#ID
Label(Frame1_3,text=Name ,font= ("黑体",15),width=4,bg = "#DAE3F3").place(x=110,y=200)#姓名
face_image('image') #设置界面的人脸图像
这段程序即界面左边人脸信息验证部分的功能。
3.语音交互与TCP数据通信
(1)创建socket客户端变量,利用socket_client.send方法向TCP发送数据,该客户端变量是在最下面的主函数中定义的。
(2)执行Start()函数时,首先通过tts合成语音提示用户进行录音,然后进行语音识别,用户说出“系统启动后”,再进行人脸识别,并给TCP客户端发送匹配度指数和“start”指令。
# 向TCP服务端发送数据
def senddata(text):
socket_client.send(text.encode())
# 按下“语音启动”按钮
def Start():
print("系统启动")
global face_flag
tts("开始进行语音识别")
while True:
msg = ''
baiduasr.record() # 录音
data = baiduasr.asr_updata() # 语音识别
t = data.split(',') # 字符串分割
print(t)
for i in range(len(t)):
if '系统启动' in t[i]:
tts("开始进行人脸识别.") #语音合成
Name,idnum,Confidence = Face() #调用人脸识别函数
score = str("0".format(round(200 - Confidence))) #匹配度指数
tts("您的名字是:" + Name)
#显示人脸图像代码
faceimg = cv2.imread('./image.jpg')
cv2.imshow('image',faceimg)
cv2.waitKey(3000)
cv2.destroyAllWindows() #摧毁窗口
msg = f'score'
senddata(msg) #发送发送匹配指数
tts("人脸识别通过")
face_image('image') #将用户人脸放在界面上
face_flag = 1 # 人脸识别标志置1
Label(Frame1_3,text = idnum ,font = ("黑体",15),width = 4 , bg = "#DAE3F3").place(x= 110,y = 150)#ID
Label(Frame1_3,text = Name ,font = ("黑体",15),width = 4 , bg = "#DAE3F3").place(x= 110,y = 200) #姓名
break
if face_flag == 1: #人脸验证通过后可以开始执行订单指令
msg='start'
print(msg)
senddata(msg) #向TCP发送start
break #人脸识别通过后跳出循环
4.数据信息可视化
人工智能系统界面的订单数据可视化功能,要求实现当用户通过语音完成下单后,在订单分布界面能够显示用户向每位摊主的需求总数,按下“订单详情”按钮,能够切换到新的界面,显示每位摊主的4类物料的需求数量。
(1)定义订单数量函数,用于后于语音识别中判断用户输入的语音信息中的订单数量。
def num(text):
if '一' in text:
return '1'
elif '两' in text:
return '2'
elif '三' in text:
return '3'
elif '四' in text:
return '4'
elif '五' in text:
return '5'
else:
return '0'
(2)定义wait_order函数,该函数在主函数中通过开启threading线程来启动,用于等待接受TCP服务端发送过来“xiadingdan”指令,通过开启线程来持续等待,这样才不会导致界面刷新不出来。初始化各个变量,等待接受TCP服务端发送过来“xiadingdan”的指令后,通过语音交互,让用户向三位摊主分别下单。
#人脸验证通过后,等待PLC发送过来'xiadingdan',用户才能语音下单
def wait_order():
global face_flag
while 1:
if face_flag == 1: #只有人脸验证通过后,接收到的PLC下单指令才有用
while (True):
command = socket_client.recv(1024).decode()
print(command)
time.sleep(0.1)
dingdan_list = ["dingdan"] # 初始化订单的值
order = '' # 初始化每个摊主的订单
sum = 0 #摊主个数
label1 = '0' # 每次给新的摊主下订单需要初始化对应变量
label2 = '0'
label3 = '0'
label4 = '0'
No1 = 0
No2 = 0
No3 = 0
need_list = []
need_new = []
fraces = [] # 扇形图的占比初始值
labels = [] # 扇形图的标签初始值
colors = []
if command == 'xiadingdan':
for k in range(3):
tts("请为"+ str(k+1) +"号位摊主下单")
sum +=1 #摊主个数
tts("开始录音")
baiduasr.record() # 录音
data = baiduasr.asr_updata() # 语音识别
t = data.split(',') # 字符串分割
print(t)
for i in range(len(t)):
if '水果' in t[i]:
label1 = num(t[i])
order = f'label1,label2,label3,label4' # 输出
elif '蔬菜' in t[i]:
label2 = num(t[i])
order = f'label1,label2,label3,label4' # 输出
elif '服装' in t[i]:
label3 = num(t[i])
order = f'label1,label2,label3,label4' # 输出
elif '零食' in t[i]:
label4 = num(t[i])
order = f'label1,label2,label3,label4' # 输出
else:
order = '0,0,0,0' #如果没有上述物品或者输入错误,则全部置零
dingdan_list.append(order) # 把每一个向摊主下的单组合到列表dingdan_list
(3)把用户的向每一位摊主下的订单信息order,填写到表格中。然后将用户输入订单信息转为列表dingdan_list,获取每一位摊主的订单需求量。例如dingdan_list=[dingdan,[1,0,0,0],[1,1,1,0],[1,1,1,1]],那么No1=1,No2=3,No1=4。设置绘制扇形图需要的各个变量,这里调用draw_pie函数,其参数frame,colors,fraces,为列表类型,labels为元组类型。
# 填写相关信息到表格
max_row1 = sheet1.max_row # 获取该表格最大行行数
#将表格中的内容为order的值, order为字符串 '0,0,0,0' ,字符长度是6
sheet1.cell(max_row1+1,1).value = str(sum) # 填写到“序号”一栏
sheet1.cell(max_row1+1,2).value = str(sum) + "号" # 填写到“摊主”一栏
sheet1.cell(max_row1+1,3).value = order[0] # 填写到“水果”一栏
sheet1.cell(max_row1+1,4).value = order[2] # 填写到“蔬菜”一栏
sheet1.cell(max_row1+1,5).value = order[4] # 填写到“零食”一栏
sheet1.cell(max_row1+1,6).value = order[6] # 填写到“服装”一栏
sheets.save("Data.xlsx") # 保存表格
#将每个摊位的元素相加,得到总数!
print(dingdan_list)
No1 = int(dingdan_list[1][0]) + int(dingdan_list[1][2]) + int(dingdan_list[1][4]) + int(dingdan_list[1][6]) #1号摊主需求量
No2 = int(dingdan_list[2][0]) + int(dingdan_list[2][2]) + int(dingdan_list[2][4]) + int(dingdan_list[2][6]) #2号摊主需求量
No3 = int(dingdan_list[3][0]) + int(dingdan_list[3][2]) + int(dingdan_list[3][4]) + int(dingdan_list[3][6]) #3号摊主需求量
#print("No1,No2,No3:",No1,No2,No3)
#将各个摊主及其需求量和扇形图对应颜色组合到列表
need_list = [["1号",No1, "#63A0DB"], ["2号",No2 , "#FFC727"] , ["3号" , No3 , "#20EA37" ] ]
#以下操作是为了剔除占比为需求量为0的那部分,需求量为0则不显示在扇形图上
for k in need_list:
if k[1]== 0: #提取列表索引为0的值
continue #不做处理
else:
need_new.append(k) #把值不为0的部分拼接起来,例如[["1号摊主",No1, "#63A0DB"],["2号",No2 , "#FFC727"] ]
for k in need_new: #遍历列表,获得每一个扇形函数的参数,labels参数是标签,fraces是扇形的占比,colors对应的颜色
labels.append(k[0]) # 获取摊主对应的列表
fraces.append(k[1]) # 获取需求量对应占比的列表
colors.append(k[2]) # 获取摊主对应颜色的列表
labels = tuple(labels) # 转为元组,获取摊主对应标签 labels = ("1号","2号","3号")
#print(labels,fraces,colors)
draw_pie(Frame2_1,labels,fraces,colors) # 画扇形图
pie_image() # 扇形图显示函数
Label(Frame2_1,text = str(No1)+ "个", font = ("微软雅黑",12), bg = "#63A0DB" , width = 4 , height = 2 , anchor = 'w').place(x= 160,y = 150)
Label(Frame2_1,text = str(No2)+ "个", font = ("微软雅黑",12), bg = "#FFC727" , width = 4 , height = 2 , anchor = 'w').place(x= 160,y = 250)
Label(Frame2_1,text = str(No3)+ "个", font = ("微软雅黑",12), bg = "#20EA37" , width = 4 , height tkinter小部件界面交互式按钮
我对交互式python编程很新,所以请耐心等待。我在Python 3.3中使用PyCharm。
我正在尝试构建以下内容:
我想生成一个带有两个文本输入字段和两个按钮的交互式窗口的函数:
- 第一个按钮(START)运行一个小的文本搜索功能(我已经编写并测试过),而第二个按钮(QUIT)将退出应用程序。
- 第一个文本输入字段需要搜索一个字符串(例如:“Hello Stack World”),而另一个文本输入字段需要在第一个输入字符串中搜索一个字符串(例如:“Stack”)。
计划是,一旦填写了两个文本字段,按“开始”按钮将启动文本搜索功能,而“退出”按钮将停止程序。
问题是,'QUIT'按钮按照应有的方式工作,但'START'按钮什么都不做。我认为它实际上将我的程序发送到无限循环中。
任何和所有的帮助真的很感激。我是界面/小部件编程的新手。
提前致谢!
这是我现在的代码:
import tkinter
from tkinter import *
class Application(Frame):
def text_scan(self):
dataf = str(input()) '''string to be searched'''
s = str(input()) ''' string to search for'''
''' ... I will leave out the rest of this function code for brevity'''
def createWidgets(self):
root.title("text scan")
Label (text="Please enter your text:").pack(side=TOP,padx=10,pady=10)
dataf = Entry(root, width=10).pack(side=TOP,padx=10,pady=10)
Label (text="Please enter the text to find:").pack(side=TOP,padx=10,pady=10)
s = Entry(root, width=10).pack(side=TOP,padx=10,pady=10)
self.button = Button(root,text="START",command=self.text_scan)
self.button.pack()
self.QUIT = Button(self)
self.QUIT["text"] = "QUIT"
self.QUIT["fg"] = "red"
self.QUIT["command"] = self.quit
self.QUIT.pack({"side": "left"})
def __init__(self, master=None):
Frame.__init__(self, master)
self.filename = None
self.pack()
self.createWidgets()
root = Tk()
root.title("text scan")
root.quit()
app = Application(master=root)
app.mainloop()
答案
您不能将GUI与input混合使用。要从条目小部件中获取值,您需要执行s.get()和dataf.get()。但是,在执行此操作之前,您需要在创建窗口小部件时删除对pack的调用,并将其移动到单独的语句中。原因是pack返回None,所以目前dataf和s是None。您还需要将对这些小部件的引用保存为类属性。
def text_scan(...):
dataf_value = self.dataf.get()
...
...
self.dataf = Entry(...)
self.dataf.pack(...)
...
以上是关于人工智能交互系统界面设计(Tkinter界面设计)的主要内容,如果未能解决你的问题,请参考以下文章