zookeeper基本架构
Posted Mary Ling
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了zookeeper基本架构相关的知识,希望对你有一定的参考价值。
要全面了解zookeeper,首先我们得知道什么是zookeeper,能做什么。zookeeper是一个开源的分布式协调服务,主要用于数据订阅/发布,集群管理,配置管理,分布式锁。
基本架构
zookeeper基本架构如下,zookeeper client连接zookeeper集群中的任一节点进行api操作,同时zookeeper节点中的Following节点连接zookeeper Leader节点进行数据同步跟将对zookeeper节点修改操作的请求转发到zookeeper leader节点进行操作。
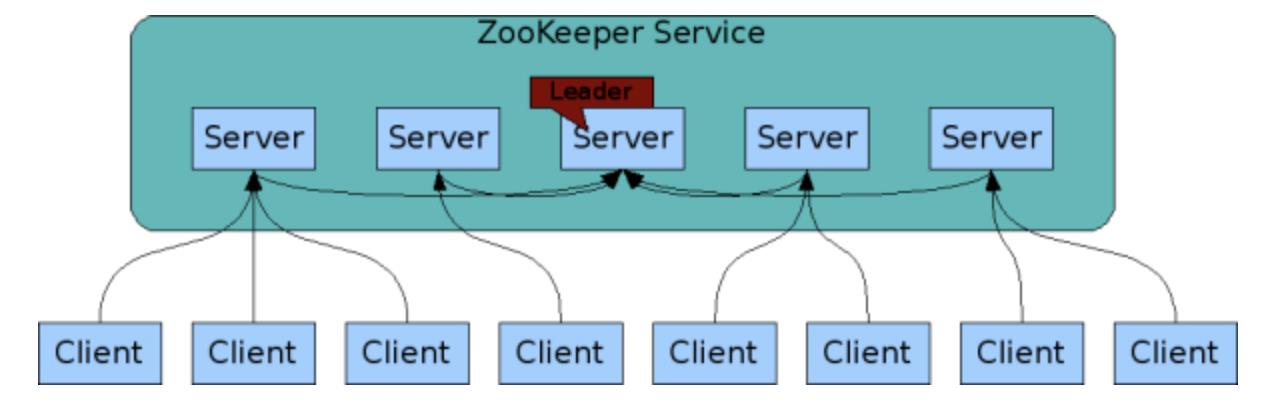
Server节点角色
Zookeeper server节点有3种角色,Leading角色,Follower角色和Observer角色。
| 角色 | 介绍 |
|---|---|
| Follower角色 | Follower角色可以用于跟zookeeper客户端进行session连接和通信,处理客户端获取Znode节点数据的请求,负责将对Znode节点数据修改的操作转发给Leader节点,同时参与zookeeper leader的选举 |
| Leader角色 | Leader角色可以用于跟zookeeper客户端进行session连接和通信,处理Follower节点和Observer节点对数据更新的请求并更新数据 |
| Observer角色 | Observer角色主要负责跟zookeeper客户端进行session连接和通信,处理客户端获取Znode节点数据请求,负责将对Znode节点数据修改的操作转发给Leader节点,但是不参与zookeeper leader的选举,可以通过添加 peerType=observer来设置节点为Observer角色,对于集群模式,同时需要设置server.1:localhost:2181:3181:observer |
Server状态
| 选举状态 | 基本介绍 |
|---|---|
| LOOKING | Server的初始状态都是LOOKING |
| LEADING | Server参与选举成功的节点将进入LEADING状态 |
| FOLLOWING | 如果没选举成功,则进入FOLLOWING状态 |
| OBSERVING | 如果节点为Observer角色,则进入OBSERVING状态 |
Session生命周期
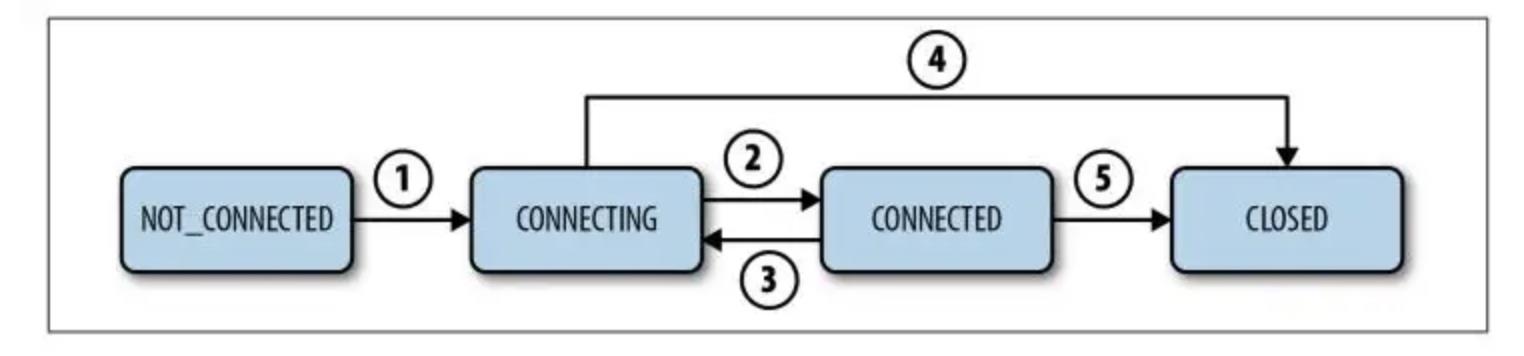
Session刚启动的时候处于初始状态NOT_CONNECTED, 当Zookeeper客户端初始化成功之后Session进入CONNECTING状态,然后Zookeeper客户端连接服务器成功之后进入CONNECTED状态,一旦Zookeeper客户端与服务器失去连接或者指定时间都没有收到服务器的心跳,则回到CONNECTING状态。当zookeeper client关闭session,则会进入CLOSED状态。
Zookeeper负载均衡
zooekeeper通过client对多个服务器连接的rehash来实现简单的负载均衡。
02_Pulsar的集群架构架构基本介绍Pulsar提供的组件介绍Brokers介绍Zookeeper的元数据存储基于bookKeeper持久化存储Pulsar代理
1.2. Apache Pulsar的集群架构
1.2.1.架构基本介绍
1.2.2.Apache Pulsar提供的组件介绍
1.2.2.1.Brokers介绍
1.2.2.2.Zookeeper的元数据存储
1.2.2.3.基于bookKeeper持久化存储
1.2.2.4.基于bookKeeper持久化存储
1.2.2.5.Pulsar代理
1.2. Apache Pulsar的集群架构
1.2.1.架构基本介绍
单个 Pulsar 集群由以下三部分组成:
- 多个broker 负责处理和负载均衡 producer 发出的消息,并将这些消息分派给 consumer;Broker 与 Pulsar 配置存储交互来处理相应的任务,并将消息存储在 BookKeeper 实例中(又称 bookies);Broker 依赖 ZooKeeper集群处理特定的任务,等等。
- 多个 bookie 的 BookKeeper 集群负责消息的持久化存储。
- 一个zookeeper集群,用来处理多个Pulsar集群之间的协调任务。
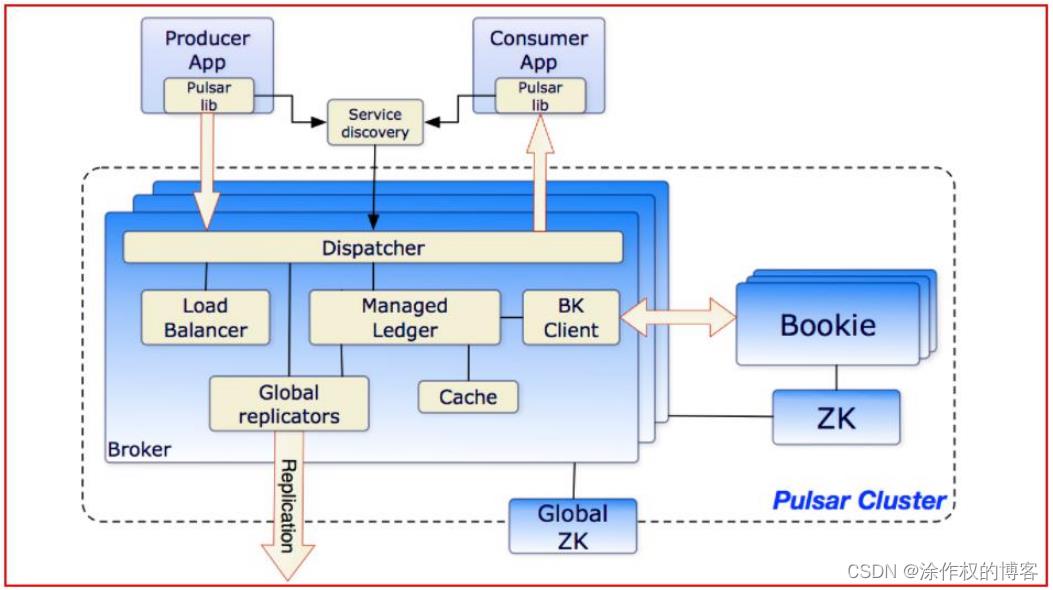
1.2.2.Apache Pulsar提供的组件介绍
1.2.2.1.Brokers介绍
Pulsar的broker是一个无状态组件,主要负责运行另外的两个组件:
- 一个 HTTP服务器, 它暴露了REST 系统管理接口以及在生产者和消费者之间进行Topic查找的API。
- 一个调度分发器, 它是异步的TCP服务器,通过自定义二进制协议应用于所有相关的数据传输。
出于性能考虑,消息通常从Managed Ledger缓存中分派出去,除非积压超过缓存大小。如果积压的消息对于缓存来说太大了, 则Broker将开始从BookKeeper那里读取Entries(Entry同样是BookKeeper中的概念,相当于一条记录)。
最后,为了支持全局Topic异地复制,Broker会控制Replicators追踪本地发布的条目,并把这些条目用Java客户端重新发布到其他区域。
1.2.2.2.Zookeeper的元数据存储
Pulsar使用Apache Zookeeper进行元数据存储、集群配置和协调。
配置存储:存储租户,命名域和其他需要全局一致的配置项。
每个集群有自己独立的Zookeeper保存集群内部配置和协调信息,例如归属信息,broker负载报告,BookKeeper ledger信息(这个是BookKeeper本身所依赖的)等等。
1.2.2.3.基于bookKeeper持久化存储
Apache Pulsar 为应用程序提供有保证的信息传递, 如果消息成功到达broker, 就认为其预期到达了目的地。
为了提供这种保证,未确认送达的消息需要持久化存储直到它们被确认送达。这种消息传递模式通常称为持久消息传递. 在Pulsar内部,所有消息都被保存并同步N份,例如,2个服务器保存四份,每个服务器上面都有镜像的RAID存储。
Pulsar用Apache bookKeeper作为持久化存储。 bookKeeper是一个分布式的预写日志(WAL)系统,有如下几个特性特别适合Pulsar的应用场景:
- 使pulsar能够利用独立的日志,称为ledgers. 可以随着时间的推移为topic创建多个Ledgers。
- 它为处理顺序消息提供了非常有效的存储。
- 保证了多系统挂掉时Ledgers的读取一致性。
- 提供不同的Bookies之间均匀的IO分布的特性。
- 它在容量和吞吐量方面都具有水平伸缩性。能够通过增加bookies立即增加容量到集群中,并提升吞吐量
- Bookies被设计成可以承载数千的并发读写的ledgers。 使用多个磁盘设备 (一个用于日志,另一个用于一般存储) ,这样Bookies可以将读操作的影响和对于写操作的延迟分隔开。
1.2.2.4.基于bookKeeper持久化存储
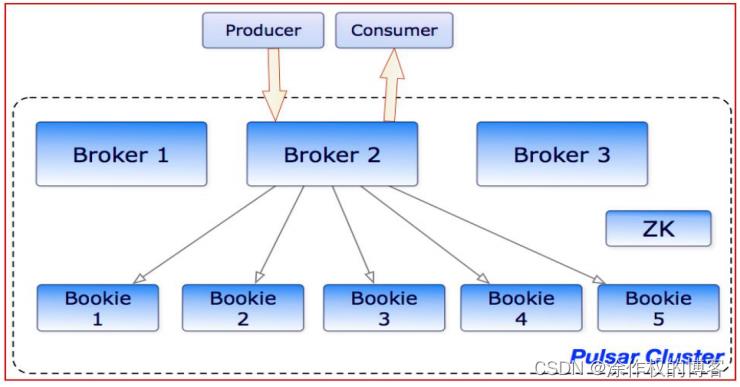
Ledger是一个只追加的数据结构,并且只有一个写入器,这个写入器负责多个bookKeeper存储节点(就是Bookies)的写入。 Ledger的条目会被复制到多个bookies。 Ledgers本身有着非常简单的语义:
- Pulsar Broker可以创建ledeger,添加内容到ledger和关闭ledger。
- 当一个ledger被关闭后,除非明确的要写数据或者是因为写入器挂掉导致ledger关闭,ledger只会以只读模式打开。
- 最后,当ledger中的条目不再有用的时候,整个ledger可以被删除(ledger分布是跨Bookies的)。
1.2.2.5.Pulsar代理
Pulsar客户端和Pulsar集群交互的一种方式就是直连Pulsar brokers。然而,在某些情况下,这种直连既不可行也不可
取,因为客户端并不知道broker的地址。 例如在云环境或者Kubernetes以及其他类似的系统上面运行Pulsar,直连
brokers就基本上不可能了。
Pulsar proxy 为这个问题提供了一个解决方案, 为所有的broker提供了一个网关, 如果选择运行了Pulsar Proxy。所有的客户都会通过这个代理而不是直接与brokers通信。
以上是关于zookeeper基本架构的主要内容,如果未能解决你的问题,请参考以下文章
Zookeeper之Zookeeper底层客户端架构实现原理(转载)
02_Pulsar的集群架构架构基本介绍Pulsar提供的组件介绍Brokers介绍Zookeeper的元数据存储基于bookKeeper持久化存储Pulsar代理