JavaScript--正则表达式
Posted BetiaStar
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JavaScript--正则表达式相关的知识,希望对你有一定的参考价值。
语法
var reg = new RegExp(pattern, modifiers) 或者更简单的方式: var reg = /pattern/modifiers
pattern(模式)描述了表达式的模式
modifiers(修饰符)用于指定全局匹配、区分大小写的匹配和多行匹配
注意:当使用构造函数(new RegExp())创建正则对象时,需要常规的字符转义规则(在前面加反斜杠\\)。比如,以下是等价的
var reg = new RegExp(\'\\\\d+\'); var reg = /\\d+/;
常用方法
reg.test(str) => 按照规则校验字符串是否符合,返回true/false
str.match(reg) => 在字符串中按照规则查找,返回数组
str.search(reg) => 在字符串中按照规则查找,返回(第一个符合条件的)下标
注:str是字符串,reg是正则表达式
修饰符(可随意组合)
i 执行对大小写不敏感(不区分)的匹配。
g 执行全局匹配(查找所有匹配而非在找到第一个匹配后停止)。
m 执行多行匹配。
注意事项: m修饰符的作用是修改^和$在正则表达式中的作用,让它们分别表示行首和行尾。
在默认状态下,一个字符串无论是否存在换行符(\\n)只有一个开始^和结尾$,如果采用多行匹配,那么每一个换行符(\\n)都有一个^和结尾$。
var str = \'This TEACHER is very good at teaching.\\n Students like her VERY much.\'
var reg = /er/
console.log(str.match(reg)) //[er] => (very)
var reg1 = /er/i
console.log(str.match(reg1)) //[ER] => (TEACHER)
var reg2 = /er/g
console.log(str.match(reg2)) //[er, er] => (very, her)
var reg3 = /er$/m
console.log(str.match(reg3)) //null
var reg4 = /er/ig
console.log(str.match(reg4)) //[ER, er, er, ER] => (TEACHER, very, her, VERY)
var reg5 = /er$/im
console.log(str.match(reg5)) //null
var reg6 = /er$/gm
console.log(str.match(reg6)) //null
var reg7 = /er$/igm
console.log(str.match(reg7)) //null
第一种,无修饰符,将匹配 \'er\' ,如果匹配到就显示,匹配不到显示null
第二种,加了修饰符i,不区分大小,即可以匹配的类型应该有 \'er\' , \'eR\' , \'Er\' , \'ER\'
第三种,加了修饰符g,全局匹配,即将所有 \'er\' 找出来
第四种,加了修饰符m,多行匹配,上面注意事项介绍了,在js代码中 ‘\\n’ 是换行符,修饰符m只对 开头\'^\'和结尾\'$\' 这两种量词进行多行匹配,即在使用修饰符m的情况下,碰到 \'\\n\' 后,就相当于在其前多了一个结尾 \'$\',在其后面多了一个开头 ‘^’,这样说可能不够清楚,看下面分析,将上面demo拿来具体问题具体分析
var str = \'This TEACHER is very good at teaching.\\n Students like her VERY much.\'
var reg3 = /er$/m
console.log(str.match(reg3)) //null
其实,一开始看到结果是null,我也是一愣,匹配不到?好吧,分析看看,请看我上面说的(红色字体或者查看注意事项),恩,\'\\n\'?在str里面是存在,那么根据上面的意思,上面的代码在修饰符m的作用下就变成,下面用截图来展示

看到我上面截图加的结尾符和开头符,是不是有点理解了呢,恩,那么开始按照匹配条件进行匹配, \'er$\' , 字符串(str)中最后以$结束前两位字符是\'er\'的有吗?并没有符合要求的,所以就返回null,如果换成英文的小数点 \'g.\'或 \'h.\' 就可找到,不信的可以试试。
var str = \'This TEACHER is very good at teaching.\\n Students like her VERY much.\' var reg3 = /g.$/m console.log(str.match(reg3)) // [ \'g.\' ] => (teaching.) var str = \'This TEACHER is very good at teaching.\\n Students like her VERY much.\' var reg3 = /h.$/m console.log(str.match(reg3)) // [ \'h.\' ] => (much.)
相信,前面这几种分析完后,后面的大家一看就能够明白,后面的就不浪费口舌了,大家自行消化。(相信大家都是大牛,不用来看我写的博客)
方括号
[abc] 查找方括号之间的任何字符。
[^abc] 查找任何不在方括号之间的字符。
[0-9] 查找任何从 0 至 9 的数字。
[a-z] 查找任何从小写 a 到小写 z 的字符。
[A-Z] 查找任何从大写 A 到大写 Z 的字符。
[A-z] 查找任何从大写 A 到小写 z 的字符。
(red|blue|green) 查找任何指定的选项。
// [abc]: var str = \'this is RegExp grammar\' var reg = /[a-g]/g console.log(str.match(reg)) // // [^abc]: var str = \'this is RegExp grammar\' var reg = /[^a-g]/g console.log(str.match(reg)) // ["t", "h", "i", "s", " ", "i", "s", " ", "R", "E", "x", "p", " ", "r", "m", "m", "r"] // [0-9]: var str = \'sd12452asdfd\' var reg = /[0-9]/g console.log(str.match(reg)) // ["1", "2", "4", "5", "2"] // [a-z]: var str = \'sd12452asdfd\' var reg = /[a-z]/g console.log(str.match(reg)) // ["s", "d", "a", "s", "d", "f", "d"] // [A-Z]: var str = \'sd12452Asdfd\' var reg = /[A-Z]/g console.log(str.match(reg)) // ["A"] // (ab|bc|cd): var str = \'abcad\' var reg = /(bc|ab|cd)/g console.log(str.match(reg)) // ["ab"]
这些都是很简单的匹配,相信大家一看就能明白。这里就只给出说明和例子,下面开始要集中精神啦。
元字符
. 查找单个字符,除了换行和行结束符。(注:行结束符在Linux和Windows是不同的,Linux是 \'\\n\', Windows是 \'\\r\\n\',这个需要注意)
\\w 查找单词字符。(单词字符包括:a-z、A-Z、0-9,以及下划线, 包含 _ (下划线) 字符。)
\\W 查找非单词字符。
\\d 查找数字。
\\D 查找非数字字符。
\\s 查找空白字符。( \'\\t\', \' \', \'\\r\', \'\\n\', \'\\v\', \'\\f\')
\\S 查找非空白字符。
\\b 匹配单词边界。(查找位于单词的开头或结尾的匹配。)
\\B 匹配非单词边界。
\\0 查找 NULL 字符。
\\n 查找换行符。
\\f 查找换页符。
\\r 查找回车符。
\\t 查找制表符。
\\v 查找垂直制表符。
\\xxx 查找以八进制数 xxx 规定的字符。
\\xdd 查找以十六进制数 dd 规定的字符。
\\uxxxx 查找以十六进制数 xxxx 规定的 Unicode 字符。
上面是说明介绍,下面我们逐一分析
. 查找单个字符,除了换行和行结束符。
// new RegExp(\'regexp.\') or /regexp./ var str = \'That is hot\' var reg = /h.t/g console.log(str.match(reg)) // [hat, hot] => (That, hot)
var str = \'Tha\\nt is hot\'
var reg = /.t/g
console.log(str.match(reg)) // [ot] => (hot)
\\w 查找单词字符。单词字符包括:a-z、A-Z、0-9,以及下划线, 包含 _ (下划线) 字符。
// new RegExp(\'\\w\') or /\\w/ var str = \'this is word, this is ¥\' var reg = /\\w/ console.log(str.match(reg)) // [t] var reg = /\\w/g console.log(str.match(reg)) // ["t", "h", "i", "s", "i", "s", "w", "o", "r", "d", "t", "h", "i", "s", "i", "s"]
\\W 查找非单词字符。单词字符包括:a-z、A-Z、0-9,以及下划线, 包含 _ (下划线) 字符。
// new RegExp(\'\\W\') or /\\W/ var str = \'this is word, this is ¥\' var reg = /\\W/ console.log(str.match(reg)) // [ \'\' ] var reg = /\\W/g console.log(str.match(reg)) // [ \' \', \' \', \',\', \' \', \' \', \' \', \'¥\' ]
\\d 查找数字。
// new RegExp(\'\\d\') or /\\d/ var str = \'please pay me 100\' var reg = /\\d/g console.log(str.match(reg)) // [ "1", "0", "0" ]
\\D 查找非数字字符。
// new RegExp(\'\\D\') or /\\D/ var str = \'please pay me 100\' var reg = /\\D/g console.log(str.match(reg)) // ["p", "l", "e", "a", "s", "e", " ", "p", "a", "y", " ", "m", "e", " "]
\\s 查找空白字符。
// 空格符 => \' \' (space character) // 制表符 => \'\\t\' (tab character) // 回车符 => \'\\n\' (carriage return character) // 换行符 => \'\\r\' (new line character) // 垂直换行符 => \'\\v\' (vertical tab character) // 换页符 => \'\\f\' (form feed character) // new RegExp(\'\\s\') or /\\s/
var str = \' \\n\\r\\v\\f\'
var reg = /\\s/g
console.log(str.match(reg))
结果在谷歌和火狐的展示是不同的,但是结果是一样的。
谷歌:
火狐:
\\S 查找非空白字符。
// 空格符 (space character) // 制表符 (tab character) // 回车符 (carriage return character) // 换行符 (new line character) // 垂直换行符 (vertical tab character) // 换页符 (form feed character) // new RegExp(\'\\s\') or /\\s/ // new RegExp(\'\\S\') or /\\S/ var str = \'please pay me 100 !\\n\' var reg = /\\S/g console.log(str.match(reg)) // ["p", "l", "e", "a", "s", "e", "p", "a", "y", "m", "e", "1", "0", "0", "!"]
\\b 匹配单词边界。查找位于单词的开头或结尾的匹配。
// new RegExp(\'\\b\') or /\\b/ var str="javascript and testJava, thisisJavaScript."; var patt1=/\\bJava/g; //只要以Java开头就能匹配到 var patt2=/Java\\b/g; //只要以Java结束就能匹配到 console.log(str.match(patt1)); // [Java] => (JavaScript) console.log(str.match(patt2)) // [Java] => (testJava)
\\B 匹配非单词边界。
// new RegExp(\'\\B\') or /\\B/ var str="JavaScript and testJava, thisisJavaScript."; var patt1=/\\BJava/g; //只要不是以Java开头就能匹配到 var patt2=/Java\\B/g; //只要不是以Java结束就能匹配到 console.log(str.match(patt1)); //[Java, Java] => (testJava, thisisJavaScript) console.log(str.match(patt2)) //[Java, Java] => (JavaScript, thisisJavaScript)
\\0: 用于匹配转义字符 \'\\0\'(空字符) => 空字符 不等于 空白符 [\\t \\n \\x0B \\f \\r]
\\n 查找换行符。
\\f 查找换页符。
\\r 查找回车符。
\\t 查找制表符。
\\v 查找垂直制表符。
上面这几个比较简单,都是正常用法,就不介绍了。
\\xxx: 用于查找以八进制数 xxx 规定的字符。
// new RegExp(\'\\xxx\') or /\\xxx/ var str="this is javascript"; var reg=/\\141/g; console.log(str.match(reg)); // [a, a] => (javascript)
\\xdd: 用于查找以十六进制数 dd 规定的字符。
// new RegExp(\'\\xdd\') or /\\xdd/ var str="this is javascript"; var reg=/\\x61/g; console.log(str.match(reg)); // [a, a] => (javascript)
\\uxxxx: 查找以十六进制数 xxxx 规定的 Unicode 字符。
// new RegExp(\'\\uxxxx\') or /\\uxxxx/ var str="this is javascript"; var reg=/\\u0061/g; console.log(str.match(reg)); // [a, a] => (javascript)
量词
n+ 匹配任何包含至少一个 n 的字符串。
// new RegExp(\'n+\') or /n+/ var str = \'abcddefdsas\' var reg = /a+/g console.log(str.match(reg)) // [a,a] console.log(str.search(reg)) // 0 console.log(reg.test(str)) // true
n\\* 匹配任何包含零个或多个 n 的字符串。
// new RegExp(\'n\\*\') or /n\\*/ var str = \'abcddefdsas\' var reg = /a*/g console.log(str.match(reg)) // ["a", "", "", "", "", "", "", "", "", "a", "", ""] console.log(str.search(reg)) // 0 console.log(reg.test(str)) // true
n? 匹配任何包含零个或一个 n 的字符串。
// new RegExp(\'n?\') or /n?/ var str = \'abcddefdsas\' var reg = /a?/g console.log(str.match(reg)) // ["a", "", "", "", "", "", "", "", "", "a", "", ""] console.log(str.search(reg)) // 0 console.log(reg.test(str)) // true
n{X} 匹配包含 X 个 n 的序列的字符串。 (X是正整数)
// new RegExp(\'n{X}\') or /n{X}/ var str = \'aabcddefdsas\' var reg = /a{1}/g console.log(str.match(reg)) // ["a", "a", "a"] console.log(str.search(reg)) // 0 console.log(reg.test(str)) // true
n{X,} 匹配包含 X 个 n 的序列的字符串。但是n必须连续出现至少X次 (X是正整数)
// new RegExp(\'n{X,}\') or /n{X,}/ var str = \'aabcddefdsas\' var reg = /a{1,}/g console.log(str.match(reg)) // ["aa", "a"] console.log(str.search(reg)) // 0 console.log(reg.test(str)) // true
n{X,Y} 匹配包含至少 X 个 n,至多 Y 个 n的序列的字符串。(X,Y都是正整数)
// > new RegExp(\'n{X,Y}\') or /n{X,Y}/ var str = \'aabcddaaaaaefdsas\' var reg = /a{1,3}/g console.log(str.match(reg)) // ["aa", "aaa", "aa", "a"] console.log(str.search(reg)) // 0 console.log(reg.test(str)) // true
^n 匹配任何开头为 n 的字符串。
// new RegExp(\'^n\') or /^n/ var str = \'issue is javascript\' var reg = /^is/g console.log(str.match(reg)) // ["is"] console.log(str.search(reg)) // 0 console.log(reg.test(str)) // true
n$ 匹配任何结尾为 n 的字符串。
// new RegExp(\'n$\') or /n$/ var str = \'What a fine day!\' var reg = /!$/g console.log(str.match(reg)) // [!] console.log(str.search(reg)) // 15 console.log(reg.test(str)) // true
?=n 匹配任何其后紧接指定字符串 n 的字符串。
// new RegExp(\'regexp()?=n\') or /regexp(?=n)/ var str = \'this is javaScript not java\' var reg1 = /is(?= java)/g console.log(str.match(reg1)) // [is] => (is java) var str = \'thisisjavascriptnotjava\' var reg1 = /is(?=java)/g console.log(str.match(reg1)) // [is] => (isjava)
?!n 量词匹配其后没有紧接指定字符串 n 的任何字符串。
// new RegExp(\'regexp()?!n\') or /regexp(?!n)/ var str = \'this is javaScript not java\' var reg1 = /is(?! java)/g console.log(str.match(reg1)) // [is] => (this) var str = \'this is javaScript not java\' var reg1 = /is(?!java)/g console.log(str.match(reg1)) // [is is] => (this is)
上面量词的介绍,语法,demo我都给了出来了,大家多看几遍或者拿到自己本地跑跑看,稍微思考一下应该都能懂。
方法
exec() 方法用于检索字符串中的正则表达式的匹配。如果字符串中有匹配的值返回该匹配值,否则返回 null。多次使用此方法,该方法会在检索不到值(返回null)的情况后,再次检索又从新开始检索。下面demo有分析
- RegExpObject.exec(string)
- string 必须,要搜索的字符串
var str = \'this is RegExp RegExp\' var reg = /RegExp/g; console.log(reg.exec(str)) // ["RegExp", index: 8, input: "this is RegExp RegExp"] => (谷歌浏览器) | ["RegExp"] => (火狐浏览器) console.log(reg.exec(str)) // ["RegExp", index: 15, input: "this is RegExp RegExp"] => (谷歌浏览器) | ["RegExp"] => (火狐浏览器) console.log(reg.exec(str)) // null console.log(reg.exec(str)) // ["RegExp", index: 8, input: "this is RegExp RegExp"] => (谷歌浏览器) | ["RegExp"] => (火狐浏览器)
test()检索字符串中指定的值。返回 true 或 false。
- RegExpObject.test(string)
- string 必需。要检测的字符串。
var str = \'this is JavaScript\' var reg = /java/gi console.log(reg.test(str)) // true
toString()方法返回正则表达式的字符串值。
- RegExpObject.toString()
var reg = new RegExp(\'javascript\', \'g\') console.log(reg) console.log(reg.toString())
谷歌: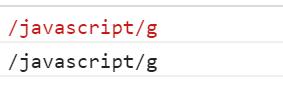
火狐: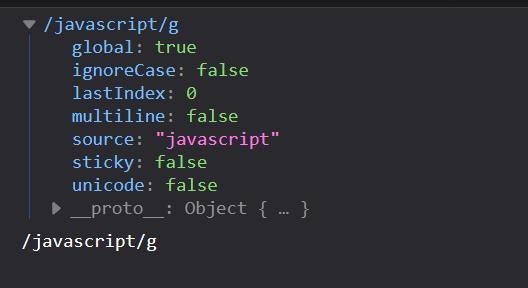
支持正则表达式的String对象的方法
search()方法用于检索字符串中指定的子字符串,返回其下标。如果没有找到任何匹配的子串,则返回 -1。
- string.search(searchvalue)
- searchvalue 必须。查找的字符串或者正则表达式。
var str = \'not java,this is javascript\' var reg = /java/g console.log(str.search(reg)) // 4 var str = \'this is javascript\' var reg = \'java\' console.log(str.search(reg)) // 8
match() 方法可在字符串内检索指定的值,或找到一个或多个正则表达式的匹配。
- string.match(regexp)
- regexp 必需。规定要匹配的模式的 RegExp 对象。如果该参数不是 RegExp 对象,则需要首先把它传递给 RegExp 构造函数,将其转换为 RegExp 对象。
var str = \'not java,this is javascript\' var reg = /java/g console.log(str.match(reg)) // [java, java] => (not java, is javascript)
replace() 方法用于在字符串中用一些字符替换另一些字符,或替换一个与正则表达式匹配的子串。
- string.replace(searchvalue,newvalue)
- searchvalue 必须。规定子字符串或要替换的模式的 RegExp 对象。请注意,如果该值是一个字符串,则将它作为要检索的直接量文本模式,而不是首先被转换为 RegExp 对象。
- newvalue 必需。一个字符串值。规定了替换文本或生成替换文本的函数。
var str = \'not java,this is javascript\' var reg = /java/g var newStr = \'VB\' console.log(str.replace(reg, newStr)) // not VB,this is VBscript var str = \'not java,this is javascript\' var reg = \'java\' var newStr = \'VB\' console.log(str.replace(reg, newStr)) // not VB,this is javascript
split() 方法用于把一个字符串分割成字符串数组。
- string.split(separator,limit)
- separator 可选。字符串或正则表达式,从该参数指定的地方分割 string Object。
- limit 可选。该参数可指定返回的数组的最大长度。如果设置了该参数,返回的子串不会多于这个参数指定的数组。如果没有设置该参数,整个字符串都会被分割,不考虑它的长度。
var colors = "red,blue,green,yellow"; console.log(colors.split(/[^\\,]+/)); // ["", ",", ",", ",", ""]
上面几个方法都还是挺好理解的,但是上面这个split这个demo我个人思考了很久,后面再写几个小demo后才将其理解透。
var colors = colorText.match(/\\,/g); //[ ",", ",", "," ] console.log(colors) //将所有的逗号 \',\' 查询出来并放到数组里面去
首先我将里面的正则表达式进行分解,拿到最简单的正则表达式 => /\\,/g 其实就是将查询到所有的逗号。
var colorText = "red,blue,green,yellow"; var colors1 = colorText.match(/^\\,/g); //null console.log(colors1) //逗号 \',\' 开头, 找不到为null
我继续将正则表达式进一步添加条件后, 查询必须是逗号开头的匹配条件,当然啦,我们这里的字符串肯定找不到。
var colorText = "red,blue,green,yellow"; var colors2 = colorText.match(/[^\\,]/g); //["r", "e", "d", "b", "l", "u", "e", "g", "r", "e", "e", "n", "y", "e", "l", "l", "o", "w"] console.log(colors2) //将只要不是逗号 \',\' 分隔的都检索出来
将中括号加上去,额,发现这下子是将符合逗号这个条件给排除了,那么就是除逗号以外的都是符合要求的。
var colorText = "red,blue,green,yellow"; var colors3 = colorText.match(/[^\\,]+/g); //["red", "blue", "green", "yellow"] console.log(colors3) //检索出 一至多 除去逗号以外的字符
将正则表达式完善到跟上面一开始demo的一样, /[^\\,]+ 相当于 n+(即可以看做 {1,} ) , n就是上面那个除逗号以外条件, 即除了逗号以外的字符至少要有一个, 那么 \'r\', \'e\', \'d\'都不是逗号,
而且red后面是逗号,那么 \'red\' 这三个字符符合 一至多字符,分为一组,那么在下一个逗号之前的blue也是一组,green也是一组,yellow页没有是逗号的也是一组。
以上是关于JavaScript--正则表达式的主要内容,如果未能解决你的问题,请参考以下文章
JavaScript中 正则表达式的使用 及 常用正则表达式