爬虫日记01:爬取m3u8格式视频和解密
Posted 新手_six
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫日记01:爬取m3u8格式视频和解密相关的知识,希望对你有一定的参考价值。
开发环境
·python3.10
·pycharm
相关模块的应用
import requests
from bs4 import BeautifulSoup
import asyncio
import aiohttp
import aiofiles确定目标需求
对某盗版网站进行浴血黑帮视频的爬取

嘿嘿
进行网页数据分析,找寻我们所需的数据来源

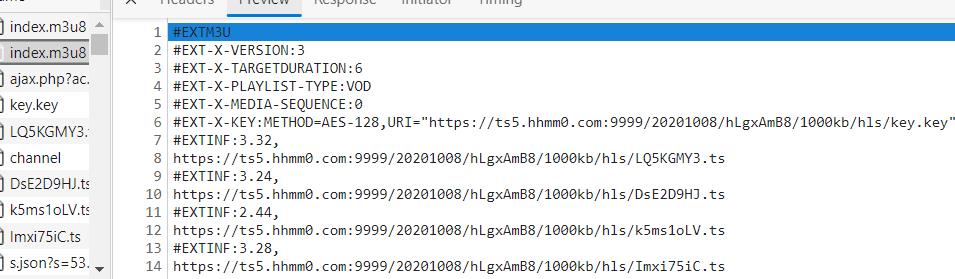
由于该视频存在2个m3u8
所以我们得先得到第一层的m3u8文件下载地址,再从第一层m3u8文件中得到第二层m3u8文件的下载地址。当然,你也可以直接在第二个m3u8里获取它的url进行视频下载。
整体思路
1.拿到主页面的页面源代码,找到iframe
2.从iframe的页面源代码中拿到m3u8文件
3.下载第一层m3u8文件,----》下载第二层m3u8文件(得到视频的全部ts路径)
4.下载视频
5.下载秘钥进行解密操作
6.合并所有ts文件为一个mp4文件(利用各种办法:工具或者代码都行)
代码的实现
1.对浴血黑帮视频的下载
import requests
from bs4 import BeautifulSoup
import asyncio
import aiohttp
import aiofiles
# 获取iframe_src
def get_iframe_src(url):
res = requests.get(url) # 获取页面源代码
main_page = BeautifulSoup(res.text,"html.parser") # 解析页面源码
src = main_page.find("iframe").get("src") # 得到我们所需的iframe的src
return src
# 得到第一层的m3u8下载地址
def get_first_m3u8(url):
# 取出第一层m3u8的真正下载地址
# 由于所得到的的url存在其他的字符,将它们进行删除
src_url = url.strip("/js/player/?url=")
src_url_2 = src_url.strip("&id=16721&num=1&count=6&vt=1")
# print(src_url_2)
return src_url_2
# 下载第m3u8文件
def download_m3u8_file(url, name):
res = requests.get(url) # 请求m3u8的url
with open(name,mode="wb") as f:
f.write(res.content)
async def download_ts(ts_url,name,session):
async with session.get(ts_url) as res_ts:
async with aiofiles.open(f"./m3u8/浴血黑帮第五季/name",mode="wb") as f:
await f.write(await res_ts.content.readany()) # 把下载到的内容写入文件中
print(f"name下载完毕!")
async def aio_download():
tasks = []
async with aiohttp.ClientSession() as session: # 因为有很多个视频片段所以提前准备好session
async with aiofiles.open("浴血黑帮第五季第一集_second_m3u8.txt",mode="r",encoding="utf-8") as f:
async for line in f:
if line.startswith("#"): #从第二层m3u8文件里读取文件内容,遇到#开始的内容就不要
continue
line = line.strip() # 去除空白换行符
name = line.rsplit("/",1)[1] # 取ts文件最后一个/后面的内容作为视频名字
task = asyncio.create_task(download_ts(line,name,session)) # 创建协程任务
tasks.append(task)
await asyncio.wait(tasks) #等待任务结束
def main(url):
# 1.拿到主页面的页面源代码,找到iframe对应的url
iframe_src = get_iframe_src(url)
# 2.拿到第一层的m3u8文件的下载地址
first_m3u8_url = get_first_m3u8(iframe_src)
# print(first_m3u8_url)
# 3.1下载第一层的m3u8文件
download_m3u8_file(first_m3u8_url,"浴血黑帮第五季第一集_first_m3u8.txt")
# 3.2下载第二层的m3u8文件
with open("浴血黑帮第五季第一集_first_m3u8.txt",mode="r",encoding="utf-8") as f2:
for line in f2:
if line.startswith("#"): # 读取本地文件,遇到#开始的内容不要
continue
else:
line = line.strip() # 去掉空白或换行符
# 拼接第二层m3u8的下载路径
second_m3u8_url = first_m3u8_url.split("/20201008")[0] +line
download_m3u8_file(second_m3u8_url,"浴血黑帮第五季第一集_second_m3u8.txt")
# print(second_m3u8_url)
# 4.下载视频
# 异步协程(利用异步协程下载速度会很快)
# 这俩个运行方法都会报警告,如果有大佬知道怎么解决希望能告知
# asyncio.run(aio_download())
loop = asyncio.get_event_loop()
loop.run_until_complete(aio_download())
if __name__ == '__main__':
url = "http://www.wbdy.tv/play/16721_1_1.html"
main(url)
print("下载完成!")
但这些视频不可播放,在第二层m3u8的文件里得知这些视频是被AES加密进行加密了

2.对视频进行解密
import asyncio
import aiofiles
import requests
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad
# 得到秘钥
def get_key(url):
res = requests.get(url)
return res.text
async def dec_ts(name, key):
# 对key进行编码,不然会报错:Object type <class 'str'> cannot be passed to C code
aes = AES.new(key=key.encode("utf-8"),IV=b"0102030405060708",mode=AES.MODE_CBC)
async with aiofiles.open(f"m3u8/浴血黑帮第五季/name",mode="rb") as f1,\\
aiofiles.open(f"m3u8/浴血黑帮第五季/解密/name",mode="wb") as f2:
bs = await f1.read() # 从源文件获取
bs = pad(bs,16) # 对加密数据padding到16byte的整数倍,不然会报错:Data must be padded to 16 byte boundary in CBC mode
await f2.write(aes.decrypt(bs)) # 把解密好的内容写入文件
print(f"name处理完毕!")
async def aio_dec(key):
tasks = []
# 解密
async with aiofiles.open("浴血黑帮第五季第一集_second_m3u8.txt",mode="r",encoding="utf-8") as f:
async for line in f:
if line.startswith("#"):
continue
line = line.strip()
name = line.rsplit("/",1)[1]
# 创建异步任务
task = asyncio.create_task(dec_ts(name,key))
tasks.append(task)
await asyncio.wait(tasks) # 等待任务结束
if __name__ == '__main__':
# 5.1 拿到秘钥
# 从第二层m3u8文件里得到AES加密的url地址
key_url = "https://ts5.hhmm0.com:9999/20201008/hLgxAmB8/1000kb/hls/key.key"
key = get_key(key_url)
# 5.2 解密
loop = asyncio.get_event_loop()
loop.run_until_complete(aio_dec(key))因为视频是被AES进行加密,所以需要导入相关的库

如果不对加密数据填充到16byte的整数倍,会报错:
Data must be padded to 16 byte boundary in CBC mode
最后就是把视频合成了 ,你可以利用各种工具,也可以视频python的FFmpeg库,反正有手就行了。

新手一枚,还有很多不知,可以多交流交流!
Node 爬虫,批量爬取头条视频并保存
项目地址:GitHub
目标网站:西瓜视频
项目功能:下载头条号【维辰财经】下的最新20个视频
姊妹项目:批量下载美女图集
简介
一般批量爬取视频或者图片的套路是,使用爬虫获得文件链接集合,然后通过 writeFile 等方法逐个保存文件。然而,头条的视频,在需要爬取的 html 文件(服务端渲染输出)中,无法捕捉视频链接。视频链接是页面在客户端渲染时,通过某些 js 文件内的算法或者解密方法,根据视频的已知 key 或者 hash 值,动态计算出来并添加到 video 标签的。这也是网站的一种反爬措施。
我们在浏览这些页面时,通过审核元素,可以看到计算后的文件地址。然而在批量下载时,逐个手动的获取视频链接显然不可取。开心的是,puppeteer 提供了模拟访问 Chrome 的功能,使我们可以爬取经过浏览器渲染出来的最终页面。
今日头条里有很多有意思的头条号玩家,他们发布了很多视频在里面。如果大家有批量下载某个头条号视频的需求,这个爬虫就派上用场了。当然,其他视频站也都大同小异,更改下部分代码设置就可以使用啦。
项目启动
命令
npm i npm start // 安装 puppeteer 的过程稍慢,耐心等待。
单个文件下载命令
npm run single // 在文件 single.js 中设置视频名称和 src 即可。
配置文件
// 配置相关 module.exports = { originPath: ‘https://www.ixigua.com‘, // 页面请求地址 savePath: ‘D:/videoZZ‘ // 存放路径 }
// 单个视频下载设置 const folderName = ‘D:/videoLOL‘ const fileName = ‘S8预选赛TOP5:Haro李青无解操作支配战局「LOL七周年」‘ const videoSrc = ‘http://v11-tt.ixigua.com/e2b7cbd320031f6c19890001503a6ca0/5b9fd7bb/video/m/2203ce04dd18e0e426381abfe64ea44f19b115bbe0a000027c1f6e94a77/‘ // 初始化方法 const start = async () => { method.mkdirSaveFolder(folderName) let video = { src: videoSrc, title: fileName } downloadVideo(video) }
技术点
puppeteer
puppeteer 提供一个高级 API 来控制 Chrome 或者 Chromium。
puppeteer 主要作用:
- 利用网页生成 PDF、图片
- 爬取SPA应用,并生成预渲染内容(即“SSR” 服务端渲染)
- 可以从网站抓取内容
- 自动化表单提交、UI测试、键盘输入等
使用到的 API:
- puppeteer.launch() 启动浏览器实例
- browser.newPage() 创建一个新页面
- page.goto() 进入指定网页
- page.screenshot() 截图
- page.waitFor() 页面等待,可以是时间、某个元素、某个函数
- page.$eval() 获取一个指定元素,相当于 document.querySelector
- page.$$eval() 获取某类元素,相当于 document.querySelectorAll
- page.$(‘#id .className‘) 获取文档中的某个元素,操作类似jQuery
代码示例
const puppeteer = require(‘puppeteer‘); (async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(‘https://example.com‘); await page.screenshot({path: ‘example.png‘}); await browser.close(); })();
视频文件下载方法
- 下载视频主方法
const downloadVideo = async video => { // 判断视频文件是否已经下载 if (!fs.existsSync(`${config.savePath}/${video.title}.mp4`)) { await getVideoData(video.src, ‘binary‘).then(fileData => { console.log(‘下载视频中:‘, video.title) savefileToPath(video.title, fileData).then(res => console.log(`${res}: ${video.title}`) ) }) } else { console.log(`视频文件已存在:${video.title}`) } }
- 获取视频数据
getVideoData (url, encoding) { return new Promise((resolve, reject) => { let req = http.get(url, function (res) { let result = ‘‘ encoding && res.setEncoding(encoding) res.on(‘data‘, function (d) { result += d }) res.on(‘end‘, function () { resolve(result) }) res.on(‘error‘, function (e) { reject(e) }) }) req.end() }) }
- 将视频数据保存到本地
savefileToPath (fileName, fileData) { let fileFullName = `${config.savePath}/${fileName}.mp4` return new Promise((resolve, reject) => { fs.writeFile(fileFullName, fileData, ‘binary‘, function (err) { if (err) { console.log(‘savefileToPath error:‘, err) } resolve(‘已下载‘) }) }) }
爬取结果截图

说明
此爬虫仅用于个人学习,如果侵权,即刻删除!
项目地址:GitHub
以上是关于爬虫日记01:爬取m3u8格式视频和解密的主要内容,如果未能解决你的问题,请参考以下文章