PyTorch深度学习实战 | 猫狗分类
Posted TiAmo zhang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch深度学习实战 | 猫狗分类相关的知识,希望对你有一定的参考价值。

本文内容使用TensorFlow和Keras建立一个猫狗图片分类器。

图1 猫狗图片
01、安装TensorFlow和Keras库
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。
节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。
TensorFlow最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。如图2所示。
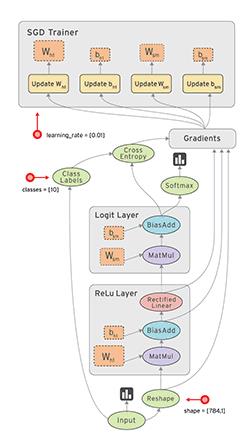
图2 TensorFlow数据流图
运行Anaconda Prompt工具,在该工具命令窗口下安装数值计算开源库(tensorflow),如图3和图4所示,输入以下pip命令:
pip install tensorflow
图3 安装tensorflow库
图4 tensorflow库安装成功
Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化,即高层神经网络API。
Keras的命名来自古希腊语“κέρας(牛角)”或“κραίνω(实现)”,意为将梦境化为现实的“牛角之门”。Keras的最初版本以Theano为后台,设计理念参考了Torch但完全由Python编写,自2017年起,Keras得到了Tensorflow团队的支持,其大部分组件被整合至Tensorflow的Python API中。在2018年Tensorflow 2.0.0公开后,Keras被正式确立为Tensorflow高阶API,即tf.keras。此外自2017年7月开始,Keras也得到了CNTK 2.0的后台支持。
Keras在代码结构上由面向对象方法编写,完全模块化并具有可扩展性,其运行机制和说明文档有将用户体验和使用难度纳入考虑,并试图简化复杂算法的实现难度。Keras支持现代人工智能领域的主流算法,包括前馈结构和递归结构的神经网络,也可以通过封装参与构建统计学习模型。在硬件和开发环境方面,Keras支持多操作系统下的多GPU并行计算,可以根据后台设置转化为Tensorflow、Microsoft-CNTK等系统下的组件。Keras为支持快速实验而生,能够把你的 idea 迅速转换为结果。
运行Anaconda Prompt工具,在该工具命令窗口下安装开源人工神经网络库(keras),输入以下pip命令:
pip install keras如图5、图6所示。
图5 安装keras库
图6 keras库安装成功
环境配置好后,开始着手建立一个可以将猫狗图片分类的卷积神经网络,并使用到深度学习框架TensorFlow和Keras,配置网络以便远程访问Jupyter Notebook。
02、案例实现
【目的】
面向小数据集,使用keras进行数据增强;
使用keras构建两层卷积神经网络,实现猫狗分类;
对学习模型进行性能评估。
【原理】
基于keras框架,构建顺序神经网络,包含3层卷积,使用relu激活函数,同时使用max池化,后接2个全连接层,中间使用dropout进行降采样。
【训练时长】
50个epoch,每个epoch大概需要50秒,在it1080下训练过程共需要40分钟左右。
【数据资源】
cat_dog数据集,从kaggle猫狗数据集中随机抽取3000个样本,其中训练集包含猫狗各1000,测试集包含猫狗各500。
【步骤1】数据预处理
使用小数据集(几百张到几千张图片)构造高效、实用的图像分类器的方法,需要通过一系列随机变换进行数据增强,可以抑制过拟合,使得模型的泛化能力更好。
在Keras中,这个步骤可以通过keras.preprocessing.image.ImageGenerator来实现:
(1) 在训练过程中,设置要施行的随机变换
(2) 通过.flow或.flow_from_directory(directory)方法实例化一个针对图像batch的生成器,这些生成器可以被用作keras模型相关方法的输入,如fit_generator,evaluate_generator和predict_generator
导入相关资源的代码如下所示。
import numpy as np
from keras.preprocessing.image import ImageDataGenerator #图像预处理
import keras.backend as K
K.set_image_dim_ordering('tf')
from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
加载数据的代码如下:
使用.flow_from_directory()来从jpgs图片中直接产生数据和标签
# 用于生成训练数据的对象
train_gen= ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# 用于生成测试数据的对象
test_datagen = ImageDataGenerator(rescale=1./255)
参数解释如下:
rotation_range是一个0~180的度数,用来指定随机选择图片的角度。
width_shift和height_shift用来指定水平和竖直方向随机移动的程度,这是两个0~1之间的比例。
rescale值将在执行其他处理前乘到整个图像上,图像在RGB通道都是0~255的整数,这样的操作可能使图像的值过高或过低,所以将这个值定为0~1之间的数。
shear_range是用来进行剪切变换的程度。
zoom_range用来进行随机的放大
horizontal_flip随机地对图片进行水平翻转,这个参数适用于水平翻转不影响图片语义的时候
fill_mode用来指定当需要进行像素填充,如旋转,水平和竖直位移时,如何填充新出现的像素
# 从指定路径小批量读取数据
train_data = train_gen.flow_from_directory(
'../datas/min_data/train', # t路径
target_size=(150, 150), # 图片大小
batch_size=32, # 每次读取的数量
class_mode='binary') # 标签编码风格
# 从测试集中分批读取验证数据
val_data= test_gen.flow_from_directory(
'../datas/min_data/test',
target_size=(150, 150),
batch_size=32,
class_mode='binary')使用小数据集(几百张到几千张图片)构造高效、实用的图像分类器的方法,需要通过一系列随机变换进行数据增强,可以抑制过拟合,使得模型的泛化能力更好。
【步骤2】构建神经网络
模型包含3层卷积加上ReLU激活函数,再接max-pooling层,代码如下所示
model = Sequential()
model.add(Convolution2D(32, 3, 3, input_shape=(3, 150, 150)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(32, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))两个全连接网络,并以单个神经元和sigmoid激活结束模型。这种选择会产生二分类的结果,与这种配置相适应使用binary_crossentropy作为损失函数,每个卷积层的滤波器数目并不多。
为了防止过拟合,需要添加Dropout层,代码如下所示。
model.add(Flatten()) # 展平
model.add(Dense(64)) # 全连接
model.add(Activation('relu')) # 激活
model.add(Dropout(0.5)) # 降采样
model.add(Dense(1)) # 全连接
model.add(Activation('sigmoid')) # 激活
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])投入数据,训练网络,代码如下所示。
model.fit_generator(
train_data, # 训练集
samples_per_epoch=2000, # 训练样本数量
nb_epoch=50, # 训练次数
validation_data=val_data, #验证数据
nb_val_samples=800 # 验证集大小
)
model.save_weights('../model/cat_dog.h5') # 保存模型文件完整代码如下所示。
【案例1】Conv_3.ipynb
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras import backend as K
# 图片大小
img_width, img_height = 150, 150
train_data_dir = '../datas/min_data/train'
validation_data_dir = '../datas/min_data/test'
nb_train_samples = 2000
nb_val_samples =1000
epochs = 50
batch_size = 16
if K.image_data_format() == 'channels_first':
input_shape = (3, img_width, img_height)
else:
input_shape = (img_width, img_height, 3)
# 数据读取、数据增强
train_gen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
val_gen = ImageDataGenerator(rescale=1. / 255)
train_data= train_gen.flow_from_directory(
train_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='binary')
val_data=val_gen.flow_from_directory(
validation_data_dir,
target_size=(img_width, img_height),
batch_size=batch_size,
class_mode='binary')
# 构建3层卷积神经网络
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=input_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# 添加站平层、全连接层、降采样层
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
# 定义损失函数和优化策略
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# 开始训练
model.fit_generator(
train_data,
steps_per_epoch=nb_train_samples // batch_size,
epochs=epochs,
validation_data=val_data,
validation_steps=nb_val_samples // batch_size)
# 保存
yaml_string = model.to_yaml()
with open('cat_dog.yaml', 'w') as outfile:
outfile.write(yaml_string)
model.save_weights('cat_dog.h5')运行结果如下:
Found 2000 images belonging to 2 classes.
Found 1000 images belonging to 2 classes.
WARNING:tensorflow:From /home/yangrh/anaconda3/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:1208: calling reduce_prod (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims instead
WARNING:tensorflow:From /home/yangrh/anaconda3/lib/python3.6/site-packages/keras/backend/tensorflow_backend.py:1297: calling reduce_mean (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.
Instructions for updating:
keep_dims is deprecated, use keepdims instead
Epoch 1/50
125/125 [==============================] - 40s - loss: 0.7057 - acc: 0.5140 - val_loss: 0.6797 - val_acc: 0.5363
Epoch 2/50
125/125 [==============================] - 40s - loss: 0.6851 - acc: 0.5865 - val_loss: 0.6391 - val_acc: 0.6839
......
Epoch 50/50
125/125 [==============================] - 40s - loss: 0.3996 - acc: 0.8370 - val_loss: 0.5988 - val_acc: 0.7947【性能评估】
50个epoch,每个epoch大概需要50秒,在it1080下训练过程共需要40分钟左右,在验证集上的准确率达到80%,训练准确率与错误率如图7所示。
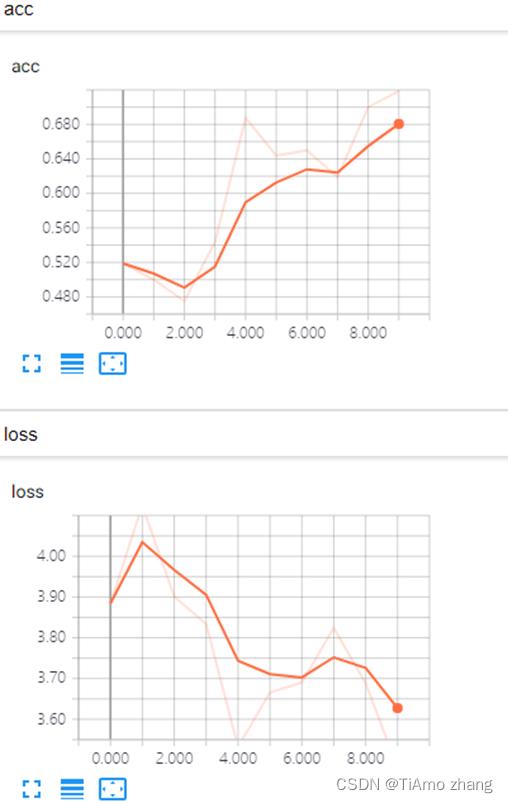
图7 准确率与错误率
下面案例代码使用训练好的模型对猫狗图片进行分类。
【案例2】Predict_Model.ipynb
import os
import keras
import keras.backend as K
from tables.tests.test_tables import LargeRowSize
K.set_image_dim_ordering('tf')
import numpy as np
from keras import callbacks
from keras.models import Sequential, model_from_yaml, load_model
from keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPool2D
from keras.optimizers import Adam, SGD
from keras.preprocessing import image
from keras.utils import np_utils, plot_model
from sklearn.model_selection import train_test_split
from keras.applications.resnet50 import preprocess_input, decode_predictions
img_h, img_w = 150, 150
image_size = (150, 150)
nbatch_size = 256
nepochs = 48
nb_classes = 2
def pred_data():
with open('cat_dog.yaml') as yamlfile:
loaded_model_yaml = yamlfile.read()
model = model_from_yaml(loaded_model_yaml)
model.load_weights('cat_dog.h5')
sgd = Adam(lr=0.0003)
model.compile(loss='categorical_crossentropy',optimizer=sgd, metrics=['accuracy'])
images = []
path='../datas/pred/'
for f in os.listdir(path):
img = image.load_img(path + f, target_size=image_size)
img_array = image.img_to_array(img)
x = np.expand_dims(img_array, axis=0)
x = preprocess_input(x)
result = model.predict_classes(x,verbose=0)
print(f,result[0])
# 0表示猫,1表示狗
pred_data()运行结果如下:
c7.jpg [0]
dog.33.jpg [0]
dog.34.jpg [1]
dog.41.jpg [0]
c3.jpg [0]
c1.jpg [1]
dog.36.jpg [0]
c4.jpg [0]
dog.35.jpg [0]
dog.39.jpg [0]
c5.jpg [0]
dog.38.jpg [0]
c2.jpg [0]
dog.40.jpg [0]
c6.jpg [1]
c0.jpg [0]
dog.37.jpg [0]Pytorch Note55 迁移学习实战猫狗分类
Pytorch Note55 迁移学习实战猫狗分类
文章目录
全部笔记的汇总贴: Pytorch Note 快乐星球
在这一部分,我会用迁移学习的方法,实现kaggle中的猫狗分类,这是一个二分类的问题,我们可以直接使用修改我们的预训练的网络卷积部分提取我们自己图片的特征,对于我们的猫狗二分类,我们就用自己的分类全连接层就可以了。
加载数据集
数据集可以去https://www.kaggle.com/c/dogs-vs-cats/data下载,一个是训练集文件夹,一个是测试集文件夹。这两个文件内部都有两个文件夹:一个文件夹放狗的图片,一个文件夹中放猫的图片
下载完成后,我这里需要将我们的图片移动成以下格式,方便我们加载数据,如果还不清楚加载数据的话,具体可以看Note52 灵活的数据读取介绍
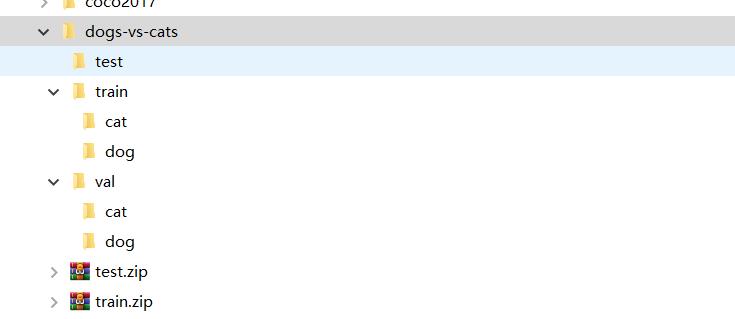
接着我们就可以用我们的代码载入数据了
首先导入我们需要的包
# import
import torch
import torchvision
from torchvision import transforms
from PIL import Image
import numpy as np
import torch.nn as nn
import torchvision.models as models
import os
import time
定义对数据的transforms,标准差和均值都是取ImageNet的标准差和均值,保持一致
transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
读入数据,如果要换自己的路径,可以换root
root = 'D:/data/dogs-vs-cats/'
trainset = torchvision.datasets.ImageFolder('D:/data/dogs-vs-cats/train',transform=transform)
valset = torchvision.datasets.ImageFolder('D:/data/dogs-vs-cats/val',transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,shuffle=True,num_workers=8)
valloader = torch.utils.data.DataLoader(valset, batch_size=64,shuffle=False,num_workers=8)
我设定我们的训练集中,我们猫狗图片各10000张,验证集图片猫狗各2500张。总共就是训练集有20000张,验证集有5000张
print(u"训练集个数:", len(trainset))
print(u"验证集个数:", len(valset))
训练集个数: 20000 验证集个数: 5000
trainset
Dataset ImageFolder Number of datapoints: 20000 Root location: D:/data/dogs-vs-cats/train StandardTransform Transform: Compose( Resize(size=256, interpolation=bilinear) CenterCrop(size=(224, 224)) ToTensor() Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) )
trainset.class_to_idx
{'cat': 0, 'dog': 1}
trainset.classes
['cat', 'dog']
trainset.imgs[0][0]
'D:/data/dogs-vs-cats/train\\\\cat\\\\cat.0.jpg'
随机打开一张图片
n = np.random.randint(0,20000)
Image.open(trainset.imgs[n][0])

trainset[0][0].shape
torch.Size([3, 224, 224])
迁移学习网络
import torch
import torch.nn as nn
import torchvision.models as models
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
定义训练模型的函数
def get_acc(outputs, label):
total = outputs.shape[0]
probs, pred_y = outputs.data.max(dim=1) # 得到概率
correct = (pred_y == label).sum().data
return correct / total
def train(net,path = './model.pth',epoches = 10, writer = None, verbose = False):
optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
criterion = nn.CrossEntropyLoss()
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer,patience=3,factor=0.5,min_lr=1e-6)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
best_acc = 0
train_acc_list, val_acc_list = [],[]
train_loss_list, val_loss_list = [],[]
lr_list = []
for i in range(epoches):
start = time.time()
train_loss = 0
train_acc = 0
val_loss = 0
val_acc = 0
if torch.cuda.is_available():
net = net.to(device)
net.train()
for step,data in enumerate(trainloader,start=0):
im,label = data
im = im.to(device)
label = label.to(device)
optimizer.zero_grad()
# 释放内存
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
# formard
outputs = net(im)
loss = criterion(outputs,label)
# backward
loss.backward()
# 更新参数
optimizer.step()
train_loss += loss.data
train_acc += get_acc(outputs,label)
# 打印下载进度
rate = (step + 1) / len(trainloader)
a = "*" * int(rate * 50)
b = "." * (50 - int(rate * 50))
print('\\r train {:3d}|{:3d} {:^3.0f}% [{}->{}] '.format(i+1,epoches,int(rate*100),a,b),end='')
train_loss = train_loss / len(trainloader)
train_acc = train_acc * 100 / len(trainloader)
if verbose:
train_acc_list.append(train_acc)
train_loss_list.append(train_loss)
# print('train_loss:{:.6f} train_acc:{:3.2f}%' .format(train_loss ,train_acc),end=' ')
# 记录学习率
lr = optimizer.param_groups[0]['lr']
if verbose:
lr_list.append(lr)
# 更新学习率
scheduler.step(train_loss)
net.eval()
with torch.no_grad():
for step,data in enumerate(valloader,start=0):
im,label = data
im = im.to(device)
label = label.to(device)
# 释放内存
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
outputs = net(im)
loss = criterion(outputs,label)
val_loss += loss.data
# probs, pred_y = outputs.data.max(dim=1) # 得到概率
# test_acc += (pred_y==label).sum().item()
# total += label.size(0)
val_acc += get_acc(outputs,label)
rate = (step + 1) / len(valloader)
a = "*" * int(rate * 50)
b = "." * (50 - int(rate * 50))
print('\\r test {:3d}|{:3d} {:^3.0f}% [{}->{}] '.format(i+1,epoches,int(rate*100),a,b),end='')
val_loss = val_loss / len(valloader)
val_acc = val_acc * 100 / len(valloader)
if verbose:
val_loss_list.append(val_loss)
val_acc_list.append(val_acc)
end = time.time()
print(
'\\rEpoch [{:>3d}/{:>3d}] Train Loss:{:>.6f} Train Acc:{:>3.2f}% Val Loss:{:>.6f} Val Acc:{:>3.2f}% Learning Rate:{:>.6f}'.format(
i + 1, epoches, train_loss, train_acc, val_loss, val_acc,lr), end='')
time_ = int(end - start)
h = time_ / 3600
m = time_ % 3600 /60
s = time_ % 60
time_str = "\\tTime %02d:%02d" % ( m, s)
# ====================== 使用 tensorboard ==================
if writer is not None:
writer.add_scalars('Loss', {'train': train_loss,
'valid': val_loss}, i+1)
writer.add_scalars('Acc', {'train': train_acc ,
'valid': val_acc}, i+1)
# writer.add_scalars('Learning Rate',lr,i+1)
# =========================================================
# 打印所用时间
print(time_str)
# 如果取得更好的准确率,就保存模型
if val_acc > best_acc:
torch.save(net,path)
best_acc = val_acc
Acc = {}
Loss = {}
Acc['train_acc'] = train_acc_list
Acc['val_acc'] = val_acc_list
Loss['train_loss'] = train_loss_list
Loss['val_loss'] = val_loss_list
Lr = lr_list
return Acc, Loss, Lr
定义一个测试的函数
import matplotlib.pyplot as plt
def test(path, model):
# 读取要预测的图片
img = Image.open(path).convert('RGB') # 读取图像
data_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
class_indict = ["cat", "dog"]
plt.imshow(img)
img = data_transform(img)
img = img.to(device)
img = torch.unsqueeze(img, dim=0)
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img))
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).data.cpu().numpy()
print(class_indict[predict_cla], predict[predict_cla].data.cpu().numpy())
plt.show()
if not os.path.exists('./model/'):
os.mkdir('./model')
1.AlexNet
# 导入Pytorch封装的AlexNet网络模型
alexnet = models.alexnet(pretrained=True)
# 固定卷积层参数
for param in alexnet.parameters():
param.requires_grad = False
# 获取最后一个全连接层的输入通道数
num_input = alexnet.classifier[6].in_features
# 获取全连接层的网络结构
feature_model = list(alexnet.classifier.children())
# 去掉原来的最后一层
feature_model.pop()
# 添加上适用于自己数据集的全连接层
feature_model.append(nn.Linear(num_input, 2))
# 仿照这里的方法,可以修改网络的结构,不仅可以修改最后一个全连接层
# 还可以为网络添加新的层
# 重新生成网络的后半部分
alexnet.classifier = nn.Sequential(*feature_model)
for param in alexnet.classifier.parameters():
param.requires_grad = True
alexnet = alexnet.to(device)
#打印一下
print(alexnet)
AlexNet( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2)) (1): ReLU(inplace=True) (2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) (4): ReLU(inplace=True) (5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (7): ReLU(inplace=True) (8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (9): ReLU(inplace=True) (10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) ) (avgpool): AdaptiveAvgPool2d(output_size=(6, 6)) (classifier): Sequential( (0): Dropout(p=0.5, inplace=False) (1): Linear(in_features=9216, out_features=4096, bias=True) (2): ReLU(inplace=True) (3): Dropout(p=0.5, inplace=False) (4): Linear(i以上是关于PyTorch深度学习实战 | 猫狗分类的主要内容,如果未能解决你的问题,请参考以下文章