PaddleSpeech 音频和视频惊艳众人的准确率
Posted 会发paper的学渣
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PaddleSpeech 音频和视频惊艳众人的准确率相关的知识,希望对你有一定的参考价值。
1、关于视频抽取固定采样率音频:ffmpeg -i test2.mp4 -f wav -ar 16000 test3.wav
其中
参数说明
-i .[迅雷下载xunbo.cc]爱情公寓第二季EP20.rmvb // 输入的文件路径
-f wav ///输出wav格式的文件
-ar 16000 //采样率为16K
2-20.wav // 输出的文件名
关于ffmpeg的安装见:https://blog.csdn.net/sslfk/article/details/123050218
2、关于音频转文字部分,模型使用paddle预训练的模型,并进行部署:
环境部署参考:https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/docs/source/install.md
3、关于模型应用部分:https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/speech_recognition/README.md
4、关于准确率说明:调研了一圈 中文中关于音频转文字的开源预训练模型,paddle的是最高的,达到了95%+,可直接使用。
5、模型应用中的入参部分文件名不要有中文
飞桨PaddleSpeech语音技术课程— 语音识别-流式服务
FastAPI websocket 流式语音识别服务
0. 背景
流式语音识别(Streaming ASR)或者在线语音识别(Online ASR) 是随着输入语音的数据不断增加,实时给出语音识别的文本结果。与之相对的是非实时或者离线语音识别,是传入完整的音频数据,一次给出整个音频的语音识别文本结果。
训练完一个流式的语音识别模型之后,需要将流式语音识别模型封装成一个服务,使用者通过网络访问流式语音识别服务实时获取音频的文本内容。
流式语音识别服务在实时字幕,视频直播,实时会议转写,输入法等场景都有大规模的应用。
1. Websocket 协议
在流式语音识别中,客户端client和服务端server需要进行长时间进行数据交互,client端不断地将数据传入到服务端,server需要将实时识别的文本返回给client端,因此client需要和server保持长时间的网络连接。
PaddleSpeech采用Websocket协议,保证client和server可以长时间保持网络连接。
WebSocket 协议支持全双工通信,client端和server端可以在一个网络连接上收发消息,使用WebSocket协议,可以实现client不断地向server端发送数据,进行实时语音识别。
# 下载流式ASR的demo视频
!mkdir -p work/source/
!test -f work/source/streaming_asr_demo.mp4 || wget -c https://paddlespeech.bj.bcebos.com/demos/asr_demos/streaming_asr_demo.mp4 -P work/source/
import IPython.display as dp
from IPython.display import HTML
html_str = '''
<video controls width="600" height="360" src="">animation</video>
'''.format("work/source/streaming_asr_demo.mov")
dp.display(HTML(html_str))
2. 测试服务
2.1 PaddleSpeech 流式协议
在PaddleSpeech中,client端使用websocket协议与server建立连接进行通信。
PaddleSpeech中client与server端的通信协议如下图所示。
在PaddleSpeech流式服务协议主要由三个部分组成,即建立链接握手,数据处理,结束链接握手。

2.1 建立链接握手
在语音识别流式服务中,client端和server端需要建立长链接。
在语音识别流式服务中,client是语音识别业务的请求方,因此client需要主动和server端建立连接,client根据PaddleSpeech的流式协议主动发送建立链接的握手信息,协议过程如下图所示:
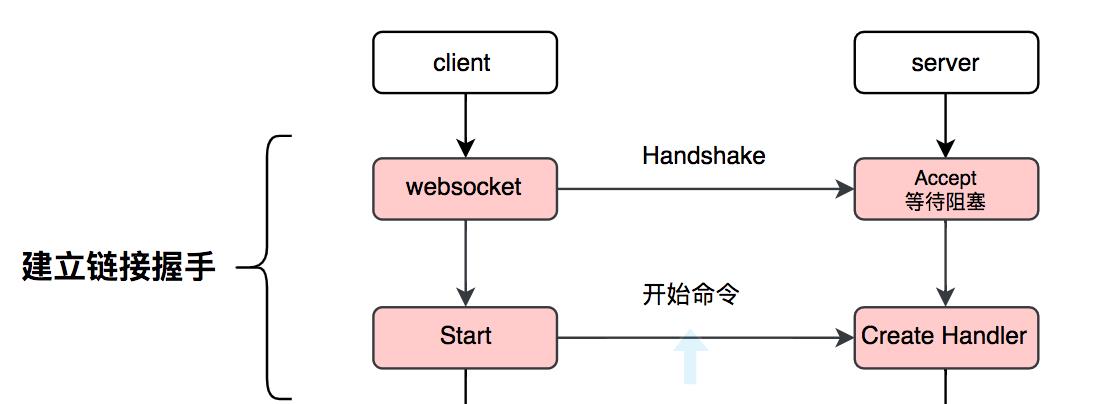
建立握手的详细步骤如下所示:
-
Client 需要发送 WebSocket 协议用于握手的 HandShake 信息,Server一直阻塞等待 WebSocket 的握手信息;
每当Server端接收到一个WebSocket 协议的HandShake之后,会开启一个线程用于处理该请求,同时继续阻塞等待下一个握手信息。 -
Server 接收到 WebSocket的握手信息后,等待 Client 的命令;
Server 端会进入到等待命令的循环中,根据client的命令进行处理。 -
Client 发送开始 start 命令信息,Server只有接收到 start 命令之后才会让 server 进行语音识别相关准备工作。
当server完成准备工作之后,将该链接的准备情况发送给client。 -
Server 接收到开始信息之后,创建处理音频的Session,并把能否创建Session的信息发送给Client
经过上述4个步骤之后,表示client和server建立了流式语音识别的连接,同时server已经为语音识别做好的必要的准备工作。
2.2 数据处理
在流式语音识别中,最核心的部分是数据处理的部分。数据处理包括client端数据处理和server端数据处理部分。
client负责将音频以数据流的形式发送给server端。
server不断地接收到client发送的数据,对接收到的数据进行处理。
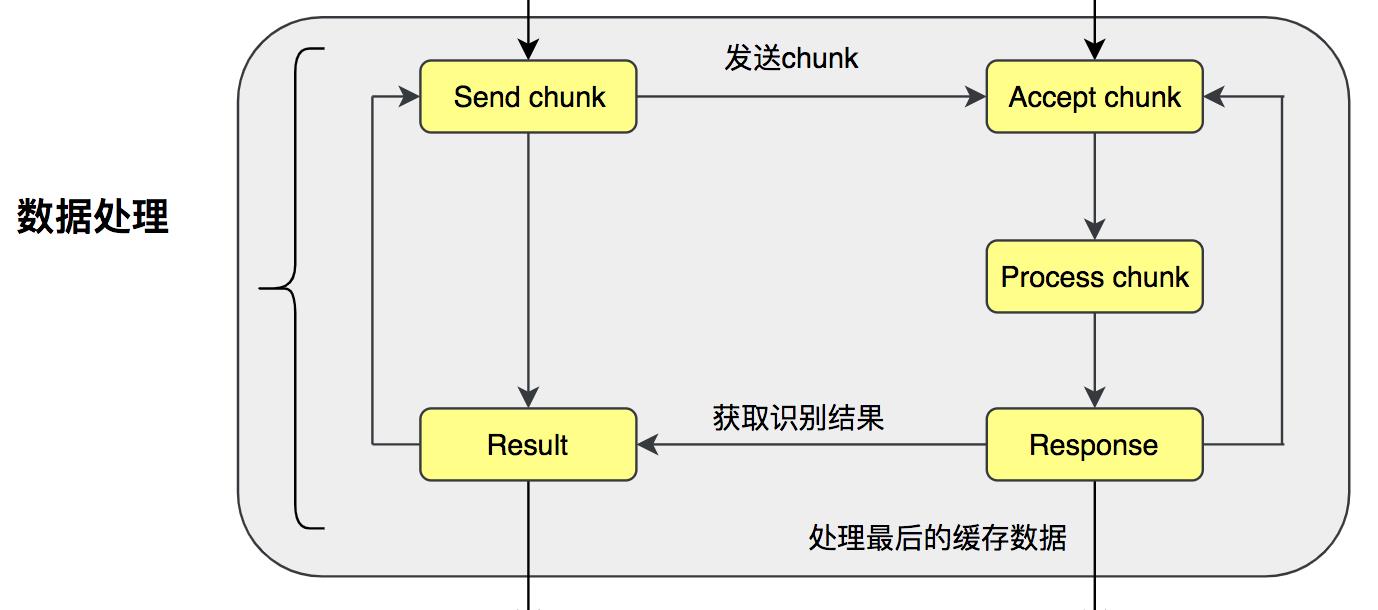
-
Client 接收到流式连接Handler创建信息,如果Handler创建成功,则开始发送chunk音频数据。
-
Server 接收到音频数据信息之后,开始处理音频,处理好之后将结果返回给Client端。
Server在处理音频的这段时间,Client 禁止发送数据,直到Server给Client 响应; -
Client 接收到 Server 的识别结果之后,开始发送下一个chunk音频数据;
-
Server端接收到最后一个chunk之后,开始识别。
Client 发送最后一个chunk之后,只要没有发送结束session的信息,server则默认还有数据未发送结束。
下面针对client和server分别进行讲解:
2.2.1 client数据处理
client接收到Handler创建成功之后,需要将数据一批一批发送给server端,我们称每一批数据为一个chunk或者一个数据包。
数据包的大小,推荐为200ms左右。
假设一个数据包的样本点为 L L L, 整个音频的样本点为 N N N,音频数据被切割为 n n n 个数据包,则client的逻辑如下所示:

需要注意的是,如果最后一个数据包的长度不满足 L L L 的长度,也是可以发送过去。
2.2.2 server数据处理
server 端接收到 client 的数据之后,就需要进行处理,包括提取特征,声学模型推理,CTC解码等一系列操作。
2.2.2.1 提取特征
server端获取音频的样本数据之后,提取音频特征,如Fbank特征等。而提取Fbank特征的时候,通常帧长是25ms或者20ms,帧移10ms。
我们以帧长25ms,帧移为10ms为例,图示提取特征过程:

在上图中,当接收到数据包2时,提取第三帧frame3的特征时,需要用到数据包1里面的数据,因此在数据包1提取好特征之后,需要缓存一部分音频的样本数据。如果不缓存数据包1的音频样本点,那么在提取特诊时,会丢失很多音频数据,导致最后识别的结果变差。
2.2.2 声学模型推理
server端提取好特征之后,需要将音频特征送入到声学模型中进行解码,以获取每个每个声学符号似然概率。以conformer模型为例,在conformer模型的前两层有下采样层,其网络结构处理如下所示:

从上图中可以看到,声学模型推理时,每7帧语音数据组成一个声学模型解码的chunk,每两个chunk是有3帧的重叠部分。
与提取音频特征过程类似,当一个chunk(7帧语音数据)处理结束之后,需要将剩下的数据缓存起来,等待接收到下一个数据包,重新组合成一个新的chunk数据,送入到声学模型中。
在conformer模型中,可以配置一次解码的chunk的数据 n n n,即将 n n n 个chunk数据组合在一起进行一起解码,这就要求解码时,系统缓存的数据帧至少有
( n − 1 ) ∗ 4 + 7 = 4 n + 3 (n-1) * 4 + 7 = 4n + 3 (n−1)∗4+7=4n+3
2.2.3 CTC 解码
声学模型对语音帧数据进行解码之后,得到每个语音识别建模符号的似然概率,然后使用CTC对每个解码符号进行解码,详细的解码过程可以参考我们aistudio教程中流式训练的部分。
2.3 结束连接握手
当client发送完最后一个数据包之后,client知道整个音频已经发送结束,需要结束这次流式语音识别的过程。server端并不知道client是否还有数据包需要发送,因此需要client端主动发送数据包发送结束的握手信息,server端接收到该信息后知道整个音频已经接收完成,不需要接收新的数据。详细的处理步骤如下所示:

-
Client 发送 Finished 信息,表示已经发送完音频,此时Server将最后缓存数据进行处理结束,得到最后的解码结果,然后销毁 Handler
-
Server 发送给 Client 信息,表示收到 Finished 信息,Client可以关闭连接,
如果有缓存的音频信息未处理完,server识别该缓存音频同时也发送识别结果。
最后缓存解码的结果,可以使用语言模型,或者attention模型进行rescoring进行优化,因此server端发送最后的Finished握手时,也发送最后一次解码结果。
-
Client 收到信息之后,关闭连接,结束本次会话。
3. FastAPI 流式语音识别实战
3.1 安装 PaddleSpeech
实战FastAPI 流式ASR 的过程时,需要安装最新版本的PaddleSpeech
下载好测试音频之后,通过PaddleSpeech的cli方式访问服务。
# 1. 安装 PaddleSpeech
!pip install -U paddlespeech==1.0.1
# 2. 安装 PaddleAudio
!pip install paddleaudio==1.0.0
# 3. 安装 uvicorn==0.18.3 (防止版本问题引发错误)
!pip install uvicorn==0.18.3
!unzip PaddleSpeech-r1.0.zip
!wget https://paddlespeech.bj.bcebos.com/Parakeet/tools/nltk_data.tar.gz
!tar zxvf nltk_data.tar.gz
# punc
!paddlespeech_server start --conf PaddleSpeech/demos/streaming_asr_server/conf/punc_application.yaml &> punc.log &
# asr
!paddlespeech_server start --conf PaddleSpeech/demos/streaming_asr_server/conf/ws_conformer_wenetspeech_application.yaml &> asr.log &
3.2 client 发送数据
!wget -c https://paddlespeech.bj.bcebos.com/PaddleAudio/zh.wav
!ls ./zh.wav
# asr
!paddlespeech_client asr_online --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
# asr + punc
!paddlespeech_client asr_online --server_ip 127.0.0.1 --port 8090 --punc.server_ip 127.0.1 --punc.port 8190 --input ./zh.wav
以上是关于PaddleSpeech 音频和视频惊艳众人的准确率的主要内容,如果未能解决你的问题,请参考以下文章