Apache loTDB技术与架构-1
Posted uesowys
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache loTDB技术与架构-1相关的知识,希望对你有一定的参考价值。
1 前言
Apache loTDB是一款应用于工业物联网领域的时序数据库,其创立于中华人民共和国清华大学软件学院,loTDB使用列式存储、数据编码、预计算以及索引技术提供大规模的、基于时序的数据存储服务与数据管理服务,loTDB也提供类SQL的接口支持每节点每秒写入的数据点可达到数百万级别、支持从TB级别的数据点中查询数据的耗时只需要几秒,loTDB提供能力轻易地支持与Apache Hadoop MapReduce、Apache Spark的集成并用于数据分析领域。
1.1 架构描述
Apache loTDB存储引擎的核心组件提供的一系列服务包括数据采集、数据写入、数据存储、数据查询、数据可视化以及数据分析,这些核心组件以及组件提供的服务构成loTDB的总体应用架构,loTDB的总体应用架构如下所示:
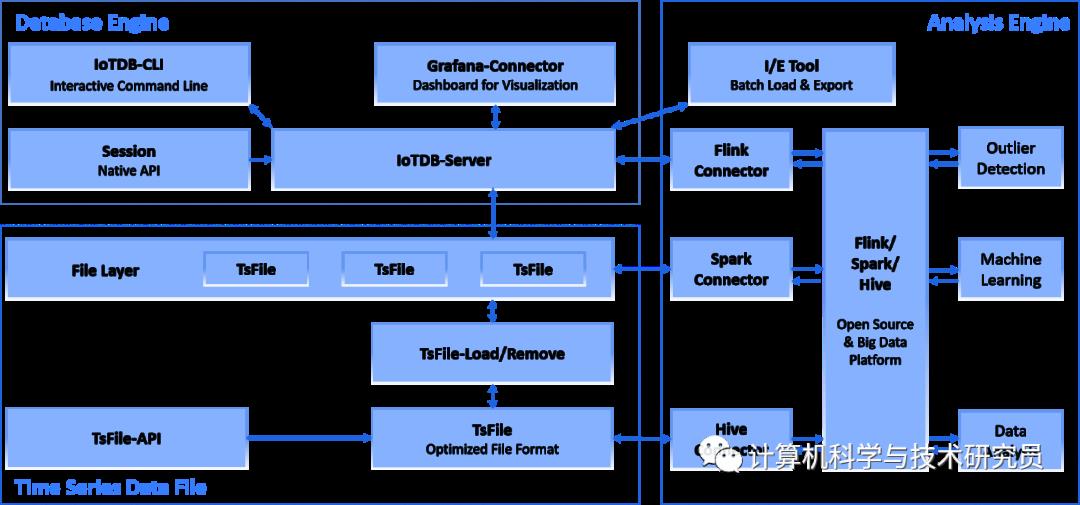
从以上的总体应用架构可知,用户可以使用JDBC协议直接连接本地或者远程的loTDB存储引擎导入来自传感器设备的时序数据。按照数据来源的分类,时序数据可以包括系统状态数据(例如服务器上软件或硬件的运行信息)、消息队列数据、应用层的时序数据、数据库中的时序数据,用户也可以直接写入时序数据到本地文件系统的tsFile或者HDFS的tsFile。
loTDB存储引擎的数据文件tsFile可以存储在HDFS中,因此,用户可以使用Hadoop的MapReduce以及Spark的计算技术对HDFS中的tsFile数据文件执行机器学习、预测分析、数据分析。
用户可以使用TsFile-Hadoop-Connector、TsFile-Spark-Connector连接器连接本地tsFile或者HDFS中的tsFile执行数据加载、数据计算与分析。
用户可以使用loTDB提供的不同客户端工具写入数据或者以SQL形式、脚本形式、图形式查询数据。
下表描述loTDB总体应用架构的不同组件提供的功能:
| Database Engine loTDB数据库存储引擎结构 |
| loTDB-CLI是客户端命令工具,提供用户与数据库服务器之间的命令行交互的控制台 |
| Grafana-connector是数据可视化管理平台 |
| Session会话管理组件,用户登录会话相关的授权与鉴权 |
| loTDB-Server是时序数据库的服务器端,提供数据存储与数据管理的核心服务 |
| Time Series Data File 时序数据文件结构 |
| File Layer是数据文件层,提供时序数据的存储服务 |
| TsFile是数据文件,存储时序数据的文件,提供时序数据的组织存储 |
| TsFile-API是对数据文件的服务接口,提供时序数据的操作服务 |
| TsFile(Optimized File Format)提供文件格式的优化,改善时序数据操作的性能 |
| TsFile-Load/Remove提供数据文件的加载与删除服务 |
| Analysis Engine 时序数据分析引擎结构 |
| Flink/Spark/Hive(Open Source & Big Data Platform)大数据平台,提供大规模的数据存储服务与数据处理服务 |
| I/E Tool(Batch Load & Export)数据导入导出工具,提供数据输入与数据输出 |
| Flink Connector流式计算框架Flink的数据连接器,提供Flink与loTDB之间的数据交互 |
| Spark Connector大规模数据分析框架Spark的数据连接器,提供Spark与loTDB之间的数据交互 |
| Hive Connector大规模数据仓库集成框架Hive的数据连接器,提供Hive与loTDB之间的数据交互 |
| Outliner Detection数据检测组件 |
| Machine Learning机器学习组件 |
| Data Analysis数据分析组件 |
(未完待续)
Hadoop技术之HDFS工作流程与机制Apache Hadoop概述
一、HDFS集群角色与职责
官方架构图

主角色: namenode
NameNode是Hadoop分布式文件系统的核心,架构中的主角色。
NameNode维护和管理文件系统元数据,包括名称空间目录树结构、文件和块的位置信息、访问权限等信息。
基于此, NameNode成为了访问HDFS的唯一入口。

主角色: namenode
NameNode内部通过内存和磁盘文件两种方式管理元数据。
其中磁盘上的元数据文件包括Fsimage内存元数据镜像文件和edits log (Journal)编辑日志。

从角色: datanode
DataNode是Hadoop HDFS中的从角色,负责具体的数据块存储。
DataNode的数量决定了HDFS集群的整体数据存储能力。通过和NameNode配合维护着数据块。

主角色辅助角色: secondarynamenode
Secondary NameNode充当NameNode的辅助节点,但不能替代NameNode。
主要是帮助主角色进行元数据文件的合并动作。可以通俗的理解为主角色的“秘书”。

namenode职责
NameNode仅存储HDFS的元数据:文件系统中所有文件的目录树, 并跟踪整个集群中的文件, 不存储实际数据。
NameNode知道HDFS中任何给定文件的块列表及其位置。使用此信息NameNode知道如何从块中构建文件。
NameNode不持久化存储每个文件中各个块所在的datanode的位置信息, 这些信息会在系统启动时从DataNode
重建。
NameNode是Hadoop集群中的单点故障。
NameNode所在机器通常会配置有大量内存(RAM) 。

datanode职责
DataNode负责最终数据块block的存储。是集群的从角色,也称为Slave。
DataNode启动时,会将自己注册到NameNode并汇报自己负责持有的块列表。
当某个DataNode关闭时,不会影响数据的可用性。
NameNode将安排由其他DataNode管理的块进行副本复制。
DataNode所在机器通常配置有大量的硬盘空间, 因为实际数据存储在DataNode中。

二、HDFS写数据流程(上传文件)
写数据完整流程图

核心概念--Pipeline管道
Pipeline,中文翻译为管道。这是HDFS在上传文件写数据过程中采用的一种数据传输方式。
客户端将数据块写入第一个数据节点, 第一个数据节点保存数据之后再将块复制到第二个数据节点, 后者保存后将其复制到第三个数据节点。

核心概念--Pipeline管道
为什么datanode之间采用pipeline线性传输,而不是一次给三个datanode拓扑式传输呢?
因为数据以管道的方式, 顺序的沿着一个方向传输, 这样能够充分利用每个机器的带宽,避免网络瓶颈和高延迟时的连接,最小化推送所有数据的延时。
在线性推送模式下,每台机器所有的出口宽带都用于以最快的速度传输数据,而不是在多个接受者之间分配宽带。

核心概念--ACK应答响应
ACK (Acknowledge character)即是确认字符,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已确认接收无误。
在HDFS pipeline管道传输数据的过程中,传输的反方向会进行ACK校验, 确保数据传输安全。

核心概念--默认3副本存储策略
默认副本存储策略是由BlockPlacementPolicyDefault指定。
核心概念--默认3副本存储策略
第一块副本:优先客户端本地, 否则随机
第二块副本:不同于第一块副本的不同机架。
第三块副本:第二块副本相同机架不同机器。

1、HDFS客户端创建对象实例DistributedFileSystem, 该对象中封装了与HDFS文件系统操作的相关方法。
2、调用DistributedFileSystem对象的create()方法,通过RPC请求NameNode创建文件。
NameNode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通过 , NameNode就会为本次请求记下一条记录,返回FSDataOutputStream输出流对象给客户端用于写数据。

3、客户端通过FSDataOutputStream输出流开始写入数据。
4、客户端写入数据时,将数据分成一个个数据包(packet 默认64k) , 内部组件DataStreamer请求NameNode挑 选出适合存储数据副本的一组DataNode地址,默认是3副本存储。
DataStreamer将数据包流式传输到pipeline的第一个DataNode,该DataNode存储数据包并将它发送到pipeline的第 二个DataNode。 同样,第二个DataNode存储数据包并且发送给第三个(也是最后一个) DataNode。

5、传输的反方向上, 会通过ACK机制校验数据包传输是否成功;
6、客户端完成数据写入后,在FSDataOutputStream输出流上调用close()方法关闭。

7、 DistributedFileSystem联系NameNode告知其文件写入完成,等待NameNode确认。
因为namenode已经知道文件由哪些块组成(DataStream请求分配数据块), 因此仅需等待最小复制块即可成功返回。
最小复制是由参数dfs.namenode.replication.min指定,默认是1.

三、HDFS读数据流程(下载文件)
读数据完整流程图

1、 HDFS客户端创建对象实例DistributedFileSystem, 调用该对象的open()方法来打开希望读取的文件。
2、 DistributedFileSystem使用RPC调用namenode来确定文件中前几个块的块位置(分批次读取) 信息。对于每个块, namenode返回具有该块所有副本的datanode位置地址列表,并且该地址列表是排序好的, 与客户端的 网络拓扑距离近的排序靠前。

3、 DistributedFileSystem将FSDataInputStream输入流返回到客户端以供其读取数据。
4、客户端在FSDataInputStream输入流上调用read()方法。然后,已存储DataNode地址的InputStream连接到文件 中第一个块的最近的DataNode。数据从DataNode流回客户端, 结果客户端可以在流上重复调用read () 。

5、当该块结束时, FSDataInputStream将关闭与DataNode的连接,然后寻找下一个block块的最佳datanode位置。 这些操作对用户来说是透明的。所以用户感觉起来它一直在读取一个连续的流。客户端从流中读取数据时,也会根据需要询问NameNode来检索下一批数据块的DataNode位置信息。
6、一旦客户端完成读取,就对FSDataInputStream调用close()方法。

以上是关于Apache loTDB技术与架构-1的主要内容,如果未能解决你的问题,请参考以下文章