Scrapy 框架架构
Posted 不一样的鑫仔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy 框架架构相关的知识,希望对你有一定的参考价值。
Scrapy 框架架构
目录
前言
- Scrapy (/ˈskreɪpaɪ/) 是一个用于抓取网站和提取结构化数据的应用程序框架,可用于如数据挖掘、信息处理,网络爬虫。
- scrapy基于异步框架实现的(Twisted)
这一节我们学习一下这个框架的基本架构,了解一下各组件是如何交互的。
一、核心组成
- 引擎(Engine):引擎负责控制系统所有组件之间的数据流。自动运行,无需关注。
- 调度器(Scheduler):接收来自引擎的请求,放在队列中,需要时在按一定次序交给引擎。
- 下载器(Downloader):获取请求信息后,从网络获取数据并返回响应。
- 爬虫(Spiders):我们操作最多的部分,用于解析下载器返回的响应。
- 管道(Item Pipeline):处理爬虫解析好的数据,例如数据持久化(存入数据库),查重等。
- 下载中间件(Downloader middlewares):处理引擎发来的请求和下载器发出的响应。
- 爬虫中间件(Spider middlewares):处理进入spider的响应和出spider的数据或新请求。
二、数据流
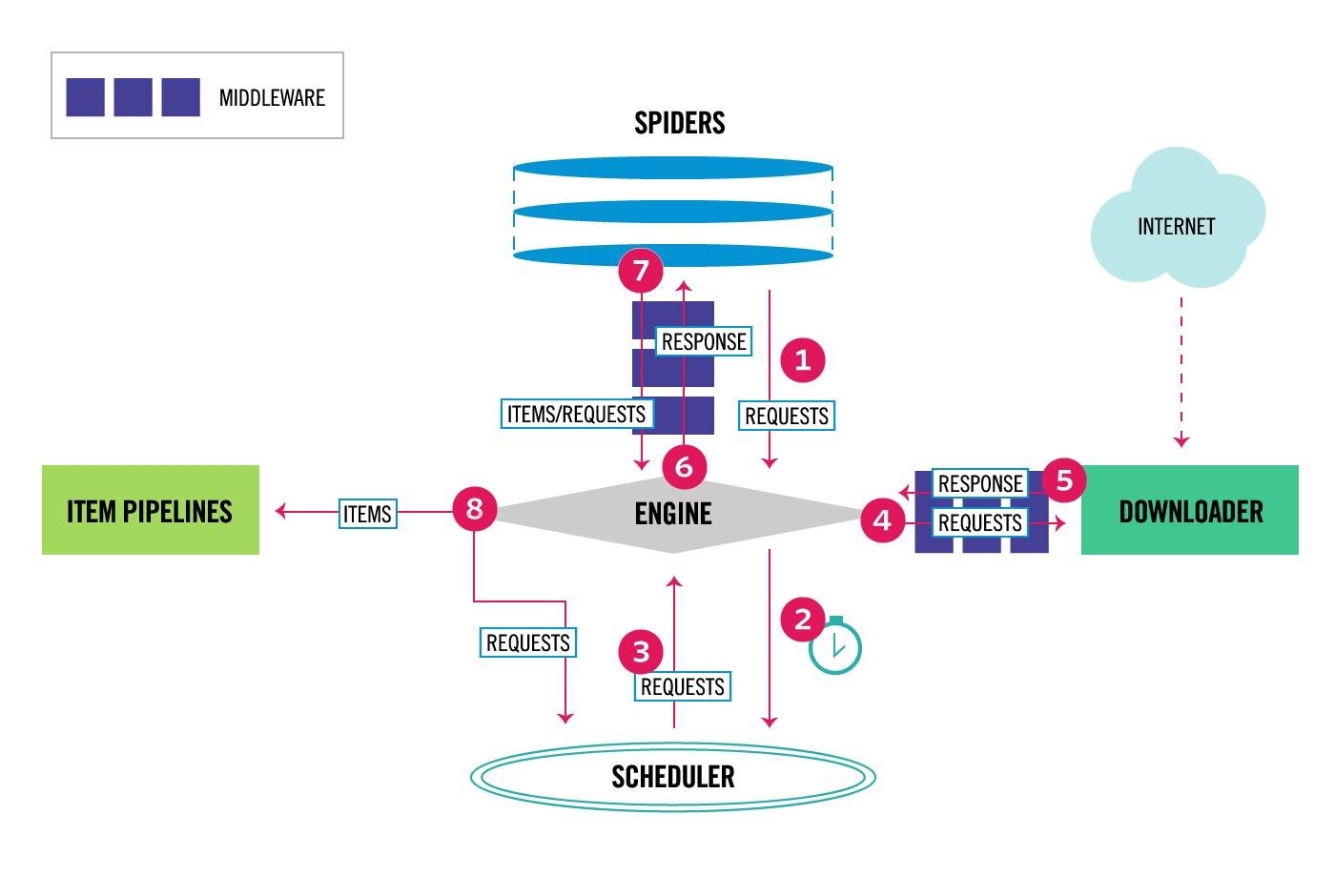
对照上面的图片:
- 引擎从Spider获取初始请求 。
- 引擎请求调度器,并准备下一次请求的抓取
- 调度器将请求交给引擎
- 引擎发出请求经过下载中间件交给下载器
- 下载完成后,下载器返回响应再次经过下载中间件交给引擎
- 引擎接收来自下载器的请求,经过爬虫中间件发送给 爬虫进行处理
- 爬虫处理响应返回数据item,或者新请求交给引擎,中间还会经过爬虫中间件。
- 引擎将item发送给管道,新请求发送给调度器等待调度
- 从第三步进行循环,直到调度其中没有请求
并不是所有部分我们都需要关注,这些组成中引擎,下载器和调度器,是不需要我们编写的。我们的重点在其他部分。
三、项目结构
接下来我们了解一下创建项目后的结构,在需要存储代码的目录下运行终端cmd:scrapy startproject 爬虫名称
完成后我们会发现已经出现了项目目录,内容如下:
爬虫名称/
scrapy.cfg # 项目配置文件,包含配置路径,部署信息
爬虫名称/ # 项目的Python模块,您将从这里导入代码
__init__.py
items.py # 用来定义Item数据结构
middlewares.py # 用来实现中间件
pipelines.py # 用于编写管道文件,也就是处理数据
settings.py # 项目的全局配置信息
spiders/ # 用来存放日后编写的爬虫文件
__init__.py
总结
本节介绍了Scrapy框架的基础知识,各部分具体如何实现后面会讲,但是这节要理解掌握工作流程,这有助于后面工作的进行。
Scrapy框架-scrapy框架架构详解
1.Scrapy框架介绍
写一个爬虫,需要做很多的事情。比如:发送网络请求、数据解析、数据存储、反反爬虫机制(更换ip代理、设置请求头等)、异步请求等。这些工作如果每次都要自己从零开始写的话,比较浪费时间。因此Scrapy把一些基础的东西封装好了,在他上面写爬虫可以变的更加的高效(爬取效率和开发效率)。因此真正在公司里,一些上了量的爬虫,都是使用Scrapy框架来解决。
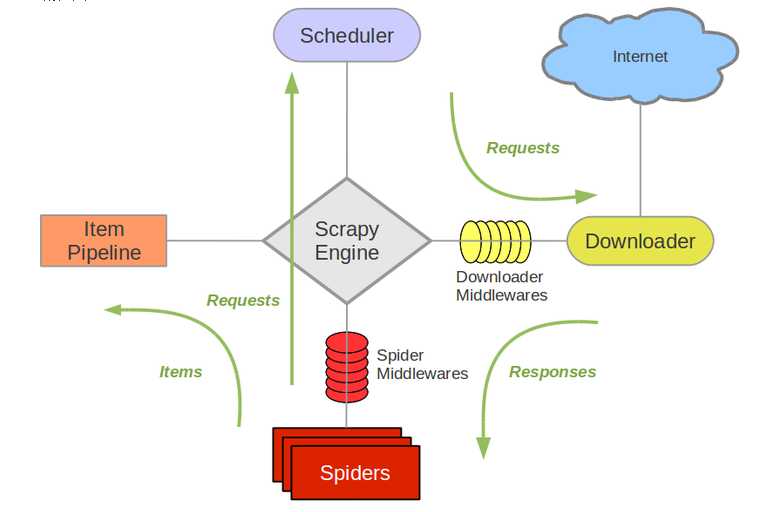
2.Scrapy架构图
流程图1:
流程图2:
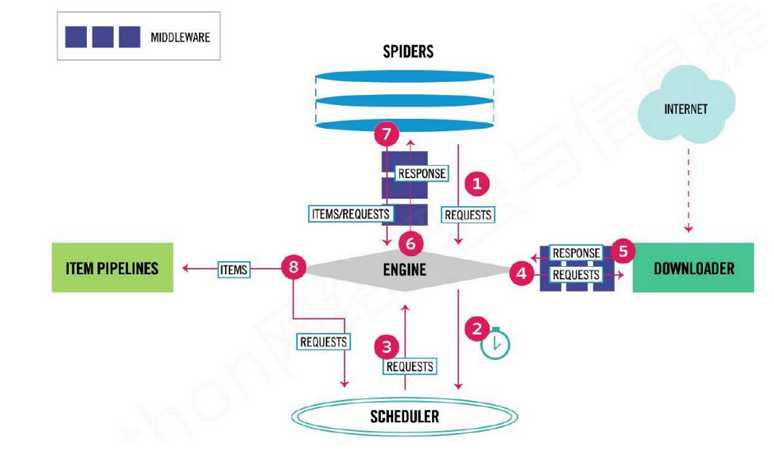
3.Scrapy框架模块功能
- Scrapy Engine(引擎):Scrapy框架的核心部分。负责在Spider和ItemPipeline、Downloader、Scheduler中间通信、传递数据等。
- Spider(爬虫):发送需要爬取的链接给引擎,最后引擎把其他模块请求回来的数据再发送给爬虫,爬虫就去解析想要的数据。这个部分是我们开发者自己写的,因为要爬取哪些链接,页面中的哪些数据是我们需要的,都是由程序员自己决定。
- Scheduler(调度器):负责接收引擎发送过来的请求,并按照一定的方式进行排列和整理,负责调度请求的顺序等。
- Downloader(下载器):负责接收引擎传过来的下载请求,然后去网络上下载对应的数据再交还给引擎。
- Item Pipeline(管道):负责将Spider(爬虫)传递过来的数据进行保存。具体保存在哪里,应该看开发者自己的需求。
- Downloader Middlewares(下载中间件):可以扩展下载器和引擎之间通信功能的中间件。
- Spider Middlewares(Spider中间件):可以扩展引擎和爬虫之间通信功能的中间件。
以上是关于Scrapy 框架架构的主要内容,如果未能解决你的问题,请参考以下文章