redis 三. hash应用场景及底层分析
Posted 苹果香蕉西红柿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis 三. hash应用场景及底层分析相关的知识,希望对你有一定的参考价值。
Hash 类型
一. 简单命令示例
- Hash 类型,可以简单理解为对应java的Map<String,Map<Object,object>>
- 简单命令使用示例
//1.一次设置一个字段值
HSET key field value
//2.一次获取一个字段值
HGET key field
//3.一次设置多个字段值
HMSET key field value[field value...]
//4.一次获取多个字段值
HMGET key field[field...]
//5.获取所有字段值
HGETALL key
//6.获取某个key内的全部数量
HLEN
//7.删除一个key
HDEL
//8.修改
HINCRBY KEY field value
二. java 操作示例
- 操作 Hash 散列类型,是一个string类型的field和value的映射表,hash特别适合用于存储对象
@Test
public void test02()
//1.创建操作 Hash类型数据的对象
HashOperations<String ,String,String> hashOperations = stringRedisTemplate.opsForHash();
//2.添加数据,第一个为redis的key,第二个为当前数据的field,点三个为值
hashOperations.put("userInfo","name","gggg");
//3.添加多条 map类型
Map<String ,String> map=new HashMap<>();
map.put("age","18");
map.put("sex","1");
//userInfo为redis的key,map中的键为field,值为value
hashOperations.putAll("userInfo", map);
//4.根据key,与field查询redis中的Hash类型数据
String name=hashOperations.get("userInfo","name");
//5.查询多条,创建查询的field集合
List<String> keyS=new ArrayList<>();
keyS.add("age");
keyS.add("sex");
//查询多条返回List集合
List<String> hashValL=hashOperations.multiGet("userInfo",keyS);
//查询多条返回Map集合
Map<String,String>hashValue= hashOperations.entries("userInfo");
//6.删除
hashOperations.delete("userInfo","name");
三. 使用场景
- 购物车
//1.对应新增商品命令
hset (购物车+用户id)key <商品id,商品数量>
//2.对应增加商品数量
hincrby (购物车+用户id)Key 商品id,商品数量累加
//3.商品总数
hlen (购物车+用户id)Key
//4.全部选择
hgetall (购物车+用户id)Key
四. 底层分析
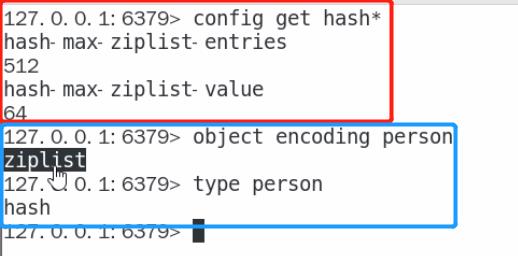
- 首先执行 “config get hash*” 命令了解两个参数
1)“hash-max-ziplist-entries”: 使用压缩列表保存时哈希集合中的最大元素个数,默认512
2)“hash-max-ziplist-value”: 使用压缩列表保存时哈希集合中单个元素的最大长度,默认64
3)修改"hash-max-ziplist-entries" 命令,修改为3示例: “config set hash-max-ziplist-entries 3”
4)修改"hash-max-ziplist-value" 命令,修改为8示例: “congif set hash-max-ziplist-value 8”
- hash类型键的字段个数小于"hash-max-ziplist-entries",并且每个字段名和字段值的长度小于"hash-max-ziplist-value"时, redis 才会使用"OBJ_ENCODING_ZIPLIST"编码格式存储该键,两个条件中任意一个不满足则会使用"OBJ_ENCODING_HT"(HT也就是hashTable)编码格式进行存储(下图中存储了一个hash类型的person数据,查看person的编码格式返回"ziplist")
- 示例2
- “config set hash-max-ziplist-entries 3”:修改哈希集合中的最大元素个数为3
- “congif set hash-max-ziplist-value 8”: 哈希集合中单个元素的最大长度为8
- “hset user01 name Z3”: 存储一个hash类型数据,key为user01
- “object encoding user01”: 查看 key为user01的编码格式,因为满足上面设置的两个条件3,8,所以返回ziplist
5)“hset user01 name z3aaaaaa”: 再次执行hset命令覆盖user01这个key值,修改name值为"z3aaaaaa",字段值的长度大于"hash-max-ziplist-value"
6)再次执行"object encoding user01" 查看编码格式返回 “hashtable”

- 由上面案例总结出: hash类型有两种编码格式: ziplist和hashtable, 当hash类型键的字段个数小于"hash-max-ziplist-entries",并且每个字段名和字段值的长度小于"hash-max-ziplist-value"时,采用ziplist,当两个条件任意一个不满足时采用hashtable编码,"hash-max-ziplist-entries"默认512, “hash-max-ziplist-value” 默认64, 注意点:ziplist可以升级为hashtable,但是不会降级
ziplist 压缩列表
- 思考,已经有链表了,为什么还需要压缩链表:
- 普通的双向链表中有两个指针,在存储数据小的情况下,实际存储的数据可能还没有指针占用空间大,通过ziplist一个特殊的双向链表,并没有维护指向上一个节点与下一个节点的指针,而是保存了上一个节点的长度,跟当前节点的长度,通过长度推算下一个节点的位置,稀释读取性能,获取高效的存储空间,(存储指针比存储长度更耗费内存),可以看为是通过拿长度推算位置的时间,换取直接存储位置指针的空间
- 链表在内存中一般不是连续的,遍历较慢,并且ziplist中存储的数据类型是不统一的长度更是不同的,所以ziplist在每个节点中都记录了偏移量(上一个节点的长度),能够更快的连续到上一个或下一个节点
- ziplist头节点中通过len属性,记录整个链表的长度,因此获取链表长度时不用去遍历获取,可以通过这个len属性直接获取,时间复杂度是0(1)
- ziplist压缩列表是一个经过特殊编码的双向链表,不存储指向上一个节点跟下一个节点的指针地址,存储了上一个节点的长度跟当前节点的长度,总体思想是通过时间换取空间,既以读写性能为代价换取极高的内存空间利用率,因此只会用于字段个数少,且字段值较小的场景,内存利用率高的原因跟连续内存的特性分不开的
- 整个ziplist结构:
- zlbytes: 记录 ziplist 整个结构体的占用空间大小,通过该字段当需要修改 ziplist 时候不需要遍历即可知道其本身的大小
- zltail: 记录整个 ziplist 中最后一个 entry 的偏移量,可以通过该属性直接获取尾部数据
- entry: 用于存储数据的节点
- zllen: 记录 entry 的数量, Redis 作了特殊的处理:当实体数超过 2^ 16 ,该值被固定为 2^16 - 1,当需要获取所有实体的数量时就必须要遍历整个结构
- zlend: ziplist 的结束标识

ziplist内部entry详解
- 在ziplist中会将数据存储在内部的entry节点中,了解entry节点内部详情
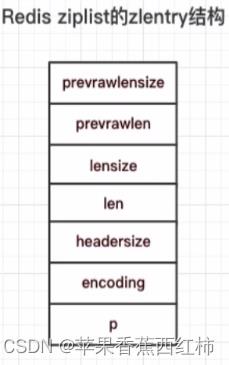
typedef struct zlentry
//上一个节点的长度用的字节
unsigned int prevrawlensize;
//上一个节点的长度
unsigned int prevrawlen;
//编码当前节点长度len锁需要的字节数
unsigned int lensize;
//当前节点长度
unsigned int len;
//当前节点header大小,headersize=prevrawlensize + lensize
unsigned int headersize;
//当前节点编码格式: ZIP_STR_*或ZIP_INT_*
unsigned char encoding;
//第一个节点的地址指针,prev-entry-len
unsigned char *p;
zlentry;
- 解释几个属性:
- prevrawlensize 上一个节点的长度用的字节
- prevrawlen 上一个节点的长度
enncoding: 记录了content保存的数据类型和长度
content: 保存的实际内容
- 由上面属性了解ziplist的遍历原理:
在ziplist中有个尾节点记录了整个ziplist的长度,通过尾节点的指针减去前一个节点的长度prevrawlensize就拿到了前一个节点的起始地址值,依次执行,就从表尾遍历到了表头,也就是说我们只要拿到某一个节点起始地址值,通过该节点中的"prevrawlensize 上一个节点的长度"属性,就可以来回遍历
- 也可这样取理解节点: 将一个节点看为三个部分: prevLen上一个节点的长度, encoding当前节点的编码, entrydata当前节点存储的实际内容

ziplist内存分配与连锁更新
- 在空间不足时,ziplist 节点的 prevlen 属性会根据前一个节点的长度进行分配:
- 如果前一个节点的长度小于 254 字节, prevlen 属性需要用 1 字节的空间来保存这个长度值
- 如果前一个节点的长度大于等于 254 字节, 那么 prevlen 属性需要用 5 字节的空间来保存这个长度值
- 假设有一个 ziplist,每个节点都是等于 253 字节的,此时新增了一个大于等于 254 字节的新节点,由于之前的节点 prevlen 长度是 1 个字节, 为了要记录新增节点的长度所以需要对节点 1 进行扩展,由于节点 1 本身就是 253 字节,再加上扩展为 5 字节的 pervlen 则长度超过了 254 字节,这时候下一个节点又要进行扩展了, 最终导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降,这就是说的连锁更新,也是在 v7.0 被 listpack 所替代的一个重要原因
ziplist 小总结:
- 一个ziplist由:总字节的长度zlbytes, 到尾节点的偏移量zltail,整个ziplist中节点的长度zllen, 还有entry集合(多个entry节点), 代表结束的zlend终节点组成
- 每个entry节点中也存在几个比较重要的属性: prevrawlensize 上一个节点的长度占用字节, prevrawlen上一个节点的长度 enncoding 当前节点中保存数据的编码格式及当前节点的长度, content 当前节点中存储的实际数据
优点: 提供len属性保存链表长度,不用再去遍历获取长度,去掉普通链表中指向上下节点的前指针与后指针,通过保存上一个节点的长度遍历更快,保证内存连续分配
- 通过这些属性我们了解到ziplist遍历原理: 在ziplist中有个尾节点zltail,并且记录了整个ziplist的长度,通过尾节点的指针减去前一个节点的长度prevrawlensize就拿到了前一个节点的起始地址值,依次执行,就从表尾遍历到了表头,也就是说我们只要拿到某一个节点起始地址值,通过该节点中的"prevrawlensize 上一个节点的长度"属性,就可以来回遍历
- 总结ziplist特点
- ziplist 为了节省内存,采用了紧凑的连续存储,但是在修改操作时需要从新分配新的内存,然后复制到新的空间。
- ziplist 是一个双向链表,可以在时间复杂度为 O(1) 从下头部、尾部进行 pop 或 push
- 新增或更新元素可能会出现连锁更新现象。
- 不能保存过多的元素,否则查询效率就会降低
hashtable 字典
- hashtable 是由数组+链表构成的, 编码格式"OBJ_ENCODING_HT", 该编码方式才是真正的哈希表结构,或称为字典,读写复杂度O(1),底层的散列表数据结构是一层一层套下去的,效率很高

redis 六. list应用场景及底层分析
List 类型
一. 简单命令示例
1.首先简单说明: List是一个双端链表的结构,内容是2的32次方减1个元素,大概40多亿,主要功能有push/pop等,一般用在栈,队列,消息队列等场景
2.简单命令
//1.向列表左边添加元素
LPUSH key value[value...]
//2.向列表右边添加元素
RPUSH key value[value...]
//3.查看列表
LRANGE key start stop
//4.获取列表中的元素个数
LLEN key
二. java 操作示例
- 操作 List 列表类型,按照插入顺序排序,可以添加一个元素到列表的头部(左边)或者尾部(右边),通过list进行指定下标的查询,可以做到简单分页
@Test
public void test03()
//1.创建操作List类型数据的对象
ListOperations<String ,String> listOperations= stringRedisTemplate.opsForList();
//2.左上添加,第一个添加的会被后一个添加的挤压到下面
listOperations.leftPush("student","liuliuliu");
//3.右下追加,第一个添加的会被后一个添加的挤到上面
listOperations.rightPush("students", "Zhao Liu");
//4.查询,根据key与下标获取指定位置的数据,左闭右闭,两边包含,返回一个List
List<String> students = listOperations.range("student", 0,2);
//5.根据key与指定下标获取单个数据
String stu = listOperations.index("student", 1);
//6.获取当前List类型数据的长度
Long total = listOperations.size("student");
//7.删除List类型数据,key为student的,value值为"Li",在List中第二次出现的,
listOperations.remove("student", 2, "Li");
// 删除多条,有左删除一条,右删除一条等
stringRedisTemplate.delete("student");
//8.从左边开始获取并删除
String srt1 = listOperations.leftPop("student");
//9.右边开始获取并删除
String str2= listOperations.rightPop("student");
三. 使用场景
- 公众号订阅: 假设用户a订阅了某个公众号sss,当sss公众号发布新文章,就会push到a用户的list中
//发布文章命令
LPUSH (like文章模块+a用户id) sss公众号文章id, bbb公众号文章id
//分页
LRANGE (like文章模块+a用户id) 0 9
- 商品评论列表: 一个商品会被不同用户评论,保存评论是按照先后顺序排序,查询商品时按照时间逆序排序,list存储时,key是商品id,value是评论信息:商品编号
LPUSH (品id)key 评论者id:评论信息
四. 底层分析
- list底层有linkedList、zipList和quickList三种存储方式
- 当列表对象保存的所有字符串元素的长度都小于 list-max-ziplist-value 默认 64字节, 并且保存的元素数量小于list-max-ziplist-entries默认512个时采用zipList, 否则采用linkedlist
- linkedlist: redis中自建了listNode对象, 通过内部的prev 和 next 指针组成的一个双端链表,
- 在redis 在 3.2 版本时,考虑到redis的空间存储效率和时间效率,引入了quicklist快速列表作为 list 的底层实现可以看成ziplist+linkedList实现的一个双端链表,链表中的每一个节点都以压缩列表ziplist的结构保存着数据,而ziplist有多个entry节点,保存着数据。相当于一个quicklist节点保存的是一片数据,而不再是一个数据
- redis中封装了quicklist 结构体变量, 内部通过quicklistNode 保存每一个节点数据,
typedef struct quicklist
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
quicklist;
typedef struct quicklistNode
//上一个node节点
struct quicklistNode *prev;
//下一个node
struct quicklistNode *next;
//保存的数据 压缩前ziplist 压缩后压缩的数据
unsigned char *zl;
//表示zl执行的ziplist的总大小,注意如果ziplist被压缩了,这个sz的值仍然时压缩前的大小
unsigned int sz;
//表示ziplist包含的数据个数,16bit
unsigned int count : 16;
//表示ziplist是否压缩,1表示没有,2表示压缩了
unsigned int encoding : 2;
//预留字段,当前是一个固定值2,表示使用zplist作为数据容器
unsigned int container : 2;
//解压标记1, 通过该标记可以再次压缩
unsigned int recompress : 1;
unsigned int attempted_compress : 1;
unsigned int extra : 10;
quicklistNode;
- 使用quicklist 插入数据时可以头部插入,或者尾部插入,
- 如果头节点(或尾节点) 上ziplist大小没有超过限制(即_quicklistModeAlLowEInsert 返回1),那么新数据被直接插入到ziplist中(调明ziplisteush ) 。
- 如果头节点(或尾节点)上ziplist太大了,那么新创建一个quicklistlode节点(对应地也会新创建一个ziplist),然后把这个新创建的节点插入到quicklist双向链表中
- quicklist 在任意指定位置插入数据时
- 当插入位置所在的ziplist大小没有超过限制时,直接插入到ziplist中
- 当插入位置所在的ziplist大小超过了限制,但插入的位置位于ziplist两端,并且相邻的quicklist链表节点的ziplist大小没有超过限制,那么就转而插入到相邻的那个quicklist链表节点的ziplist中;
- 当插入位置所在的ziplist大小超过了限制,但插入的位置位于ziplist两端,并且相邻的Squicklist链表节点的ziplist大小也超过限制,这时需要新创建一个quicklist链表节点插入。
- 对于插入位置所在的ziplist大小超过了限制的其它情况(主要对应于在ziplist中间插入数据的情况),则需要把当前ziplist分裂为两个节点,然后再其中一个节点上插入数据
- quicklist 查找: quicklist的节点是由一个一个的ziplist构成的每个ziplist都有大小,所以先根据每个node个数,找到对应的ziplist,调用ziplist的index就能成功找到。
- quicklist 删除: 在区间删除时,会先找到start 所在的 quicklistlode,计算删除的元素是否小于要删除的count,如果不满足删除的个数,则会移动至下一个quicklistNode 继续删除,依次循环直到删除完成为止
以上是关于redis 三. hash应用场景及底层分析的主要内容,如果未能解决你的问题,请参考以下文章