TensorRT8 meets Python TensorRT快速入门介绍
Posted 吸欧大王
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorRT8 meets Python TensorRT快速入门介绍相关的知识,希望对你有一定的参考价值。
一.前言
本系列教程是重点关注如何在Python环境中转换、使用TensorRT做深度模型的推理。在上篇中,我们介绍了TensorRT在python和ubuntu环境中的部署。重点就是解决好显卡驱动、cuda、cudnn和tensorRT之间的版本对应关系。在本篇中,我们快速介绍TensorRT的入门知识,为后续的TensorRT模型部署打下基础。
笔者建议还是过一遍Nvidia TensorRT官方教程,如果实在懒或者英语困难的同学,也可以看下我为大家划好的原文重点和解释。
二.TensorRT介绍
2.1 什么是TensorRT?
NVIDIA® TensorRT™ is an SDK for optimizing-trained deep learning models to enable high-performance inference. TensorRT contains a deep learning inference optimizer for trained deep learning models, and a runtime for execution.
After you have trained your deep learning model in a framework of your choice, TensorRT enables you to run it with higher throughput and lower latency.TensorRT是一个SDK,意思是可以被系统集成。
TensorRT是为了优化已经训练好的深度模型,目的是加快模型的推理速度。
TensorRT包含一个深度推理的优化器(Optimizer)、一个运行环境(Runtime)。
当你把一个深度模型训练好,可以使用TensorRT转换一下,以达到更高的吞吐量(throughput)和更低的推理延迟。
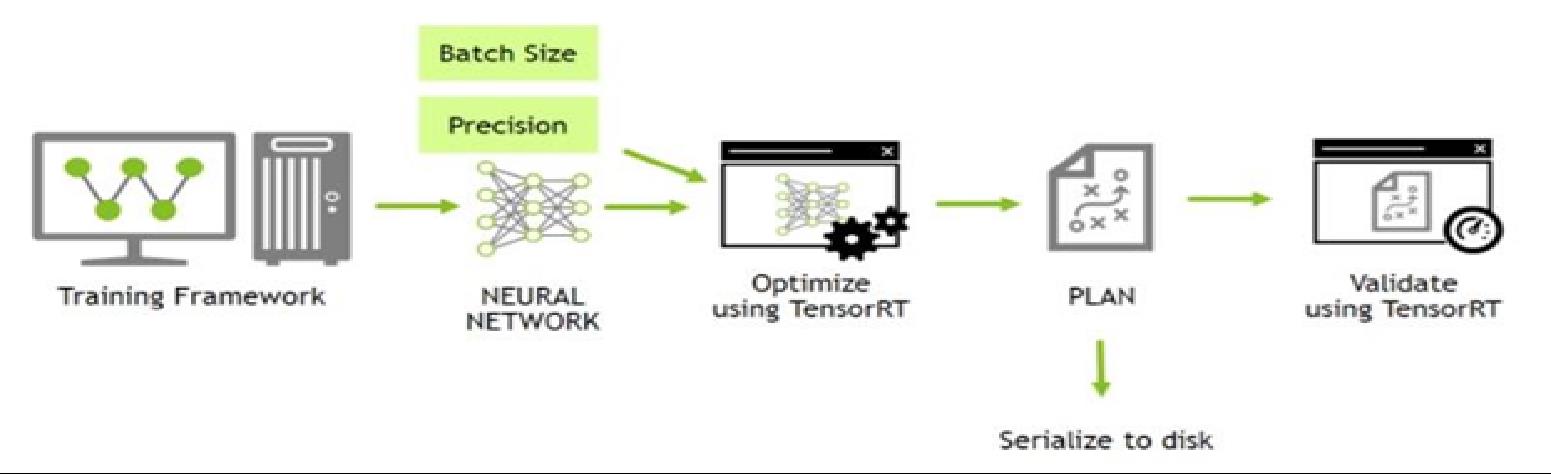
从上图可以看到,通过训练框架(Training Framework)训好的模型,我们重点选择好BatchSize批大小和Precision精度这两个参数。然后通过TensorRT进行优化,得到一个“PLAN”,而这个“PLAN”是可以序列化到磁盘的(可以离线加载使用)。最后我们使用TensorRT加载这个“PLAN”用于推理阶段。这里我理解“PLAN”就是我们常在TensorRT里面说到的engine。
2.2 TensorRT部署只需要5步
TensorRT provides several options for deployment, but all workflows involve the conversion of your model to an optimized representation, which TensorRT refers to as an engine. Building a TensorRT workflow for your model involves picking the right deployment option, and the right combination of parameters for engine creation.TensorRT支持多种部署方式,但是都依赖于优化后的模型,在TensorRT官方称之为engine。
构建TensorRT推理的workflow,需要注意选择合适的部署方式和engine构建的合理参数。

官方给出的5步部署顺序:
导出模型(onnx之类的)
选择batchsize
选择precision
转换模型(到engine)
部署模型
2.3 模型转换的选择
The various paths users can follow to convert their models to optimized TensorRT engines.
The various runtimes users can target with TensorRT when deploying their optimized TensorRT engines.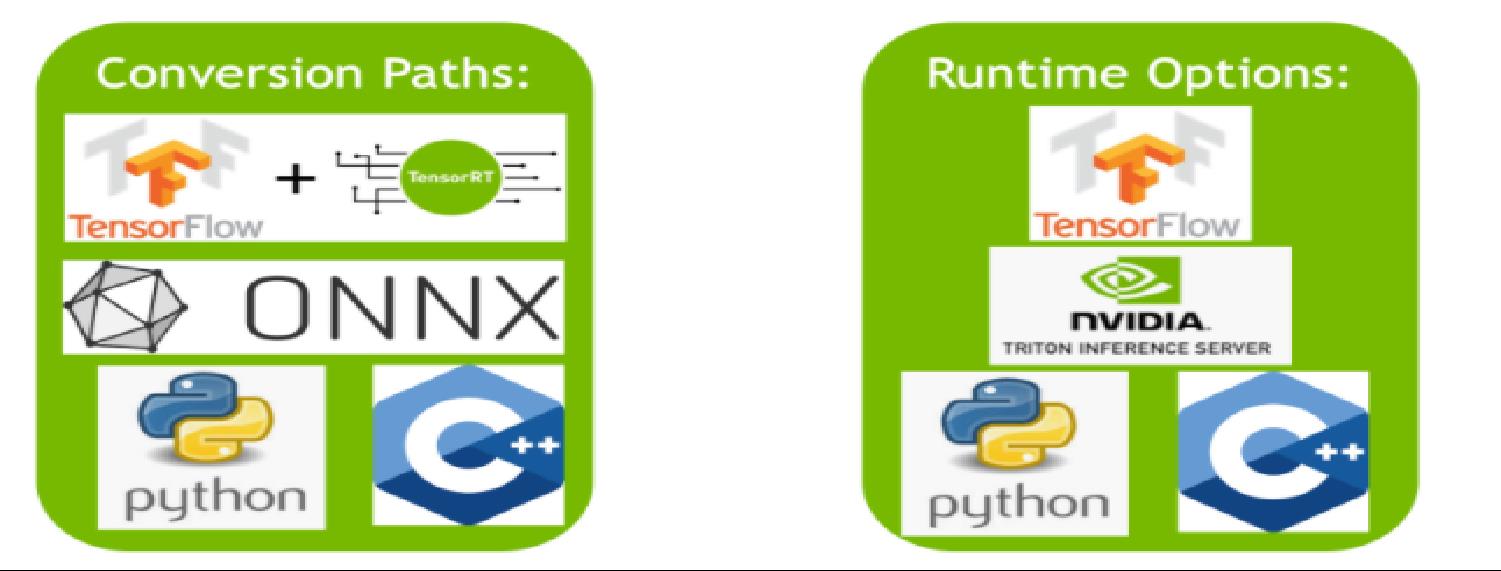
模型转换的方式:
2.3.1 使用TF-TRT(优势)
TensorFlow integration(TF-TRT)提供了模型转换和high-level的运行runtime API.
在这种方式下如果TensorRT遇到了一个不支持的算子,会自动退回到TensorFlow的实现上。
2.3.2 使用ONNX模型自动转换 (优势)
ONNX本身可以与TensorFlow、Pytorch以及更多的框架无缝对接。
TensorRT可以支持API或者是trtexec两种API转换ONNX模型。trtexec是命令行的方式。不用写代码,使用简单。
2.3.3 手动使用TensorRT API进行模型网络的构建
使用TensorRT构建一个与目标网络同构的模型
只将训练好的权重导出加载到TensorRT API构建的网络中去。
使用TensorRT API直接构建网络的方式如下所示,可以感受一下。
weights = mnist_model.get_weights()
conv1_w = weights['conv1.weight'].numpy()
conv1_b = weights['conv1.bias'].numpy()
conv1 = network.add_convolution(input=input_tensor, num_output_maps=20, kernel_shape=(5, 5), kernel=conv1_w, bias=conv1_b)
conv1.stride = (1, 1)
pool1 = network.add_pooling(input=conv1.get_output(0), type=trt.PoolingType.MAX, window_size=(2, 2))
pool1.stride = (2, 2)
...2.4 模型部署的选择
2.4.1 直接集成TensorFlow部署
TF-TRT 转换的结果是TensorRT的graph,graph本身是注入了优化后的TensorRT算子.
2.4.2 使用独立的TensorRT runtime API
包含python和c++两个独立运行环境。TensorRT的runtime API支持最低的资源消耗和最细粒度的控制。
2.4.3 使用Nvidia Triton Inference Server
开源推理引擎
具备一些高阶的能力:无论是异构的还是同构的模型并行推理(模型副本机制可以进一步降低推理延迟),负载均衡和模型分析。
2.4.4 如何选择?
关于如何选择runtime和部署方式,官方有一个讨论:
这里我也总结下各种方式的优劣:
TF-TRT:适合熟悉TensorFlow框架的开发人员,可以快速上手。缺点是性能最差。
Triton Inference Server:Triton对于不同框架的支持更好,可以支持直接Onnx模型加载,也可以支持TF-TRT模型加载,如果用不同的训练框架希望统一推理接口的时候可以使用。同时还具备在单块或多块GPU上并行化同构或者异构化模型推理、负载均衡等能力和策略。Triton Inference Server支持HTTP和GRPC接口。
python runtime:有一些性能损耗,但是如果最熟悉python开发可以使用。TensorFlow的python API提高了细粒度的控制API,包含内存的声明获取、Kernel的执行和数据从内存和显存之间的控制,都可以显示的使用API去控制。
C++ runtime:最低的性能损耗和最佳的运行速度。
整体总结一下就是,简单的方式中,如果熟悉TF可以快速使用TF-TRT进行tensorRT推理。如果熟悉python或者C++语言,可以倾向于选择独立的backend。如果是大规模使用,或者公司级的场景,训练框架各式各样,模型很多导致GPU分配出现问题,那么应考虑较重的方案使用Triton Inference Server。
对于独立的python backend以及Triton Inference Server我们后续会有独立的篇章进行讲解。
下篇我们将重点讲解基于ONNX路线的部署实践,讨论ONNX模型导出以及如何选择BatchSize和Precision这两个关键参数。下篇见!
Tensorflow-Onnx-Tensorrt 的准确度下降
【中文标题】Tensorflow-Onnx-Tensorrt 的准确度下降【英文标题】:Accuracy drops in Tensorflow-Onnx-Tensorrt 【发布时间】:2020-09-11 01:13:13 【问题描述】:我有一个经过 tensorflow 训练的模型,并在 tensorflow 上进行了测试,准确率达到了 95%。
Tensorflow 模型转换为 ONNX 并转换为 TensorRT。 TensorRT 引擎以 16 位精度运行。 在 TensorRT 中,准确率下降到 75%。即使使用 kTF32,准确率仍然是 75%。 为两个测试和相同的输入大小测试了相同的图像。
我应该在哪里查看这种准确度下降?唯一的区别是我在 TensorRT 中进行批量推理,而不是在 Tensorflow 中。
使用 OpenCV 为 Tensorflow 和 TensorRT 读取图像。
从 Tensorflow 到 ONNX 的转换精度会下降吗?
【问题讨论】:
【参考方案1】:现在我发现了问题。 Tensorflow 通过乘以 1/255.0 对输入图像进行归一化。但是在张量归一化中,它是 1-x/255.0。这就是问题所在。现在我有同样的准确性。
【讨论】:
以上是关于TensorRT8 meets Python TensorRT快速入门介绍的主要内容,如果未能解决你的问题,请参考以下文章