阅读Domain Adaption in One-Shot Learning(记录)
Posted dp不会就不会
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阅读Domain Adaption in One-Shot Learning(记录)相关的知识,希望对你有一定的参考价值。
研究背景
1、对于一个学习者来说,哪怕只懂英语基础知识,也能一眼分辨希腊字母。(one-shot leanring的观点)
2、假设有一个学习者想从一本不完整的百科全书中学习犬科动物,这本百科全书只包括猫科动物和昆虫的部分。只要给他们一些关于犬科动物的图片,学习者就会发现狗和猫比臭虫有更多的共同特征。经过几次试验,学习者应该更多地关注猫科,而不是昆虫,即使学习者可能对犬科的定义并不清楚。 (domain adaption)
提出方法
提出了基于对抗框架领域自适应的one-shot leanring方法。
需要同时训练一个one-shot classsfier 和一个领域discriminator。
带有强化采样选择的对抗领域自适应网络的定义和解释
在domain adaption中,训练集为源域,S代表,测试集为目标域,T代表,其数学表示为
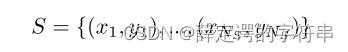
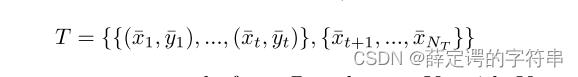
1、再给出了 K-way q-shot learning task的定义:
1、对于K个(support se中未曾出现,即S集合的一个子集)的类别,每个类别给定q个标注,将这些没有标签的query examples分配到这K个类别中。
2、support set和query examples的定义来源于第二章relate work中,是在q-shot learning 中提出的一种基于度量的方法,即:给定一个集,该集由一幅查询图像和一组支持图像组成,一种基于度量的方法计算嵌入查询图像和每一幅嵌入支持图像之间的某种相似度度量,然后将相似度作为加权的最近邻分类器的权重来预测查询图像的标签。
3、在q=1,时,对于一个采样x,属于第k个类别的概率定义为
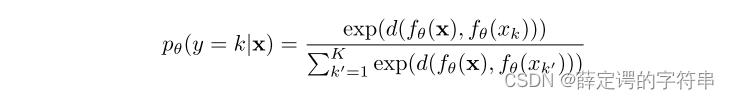 其中,fθ代表的是一个映射函数,可以将输出的特征做一个映射,让S域到T域之间平滑。
其中,fθ代表的是一个映射函数,可以将输出的特征做一个映射,让S域到T域之间平滑。
2、对抗自适应领域的定义
(1)在对抗自适应领域中,需要训练一个discriminator来实现,这个辨别器gφ接受一个embedding输入,输出这个embedding输入来自S域的可能性概率,它训练的目标是给定一个采样,能够识别出它是来自源域还是目标域的。它的优化是一个二值交叉熵损失,其计算公式为
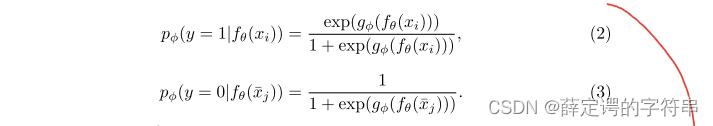
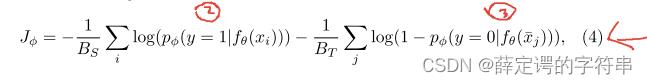 其中,Bs和Bt分别为源域和目标域的batch,在后面两个实验中,都设置为1。
其中,Bs和Bt分别为源域和目标域的batch,在后面两个实验中,都设置为1。
(2)在训练辨别器的同时,也要训练一个one-shot classifier,它的优化被认为是一个多值交叉熵损失。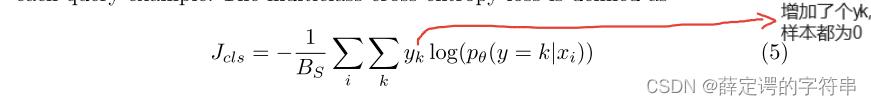 其中,yk是一个二进制,判断采样x是否为标签k。
其中,yk是一个二进制,判断采样x是否为标签k。
(3)对于在辨别器的训练中,也受映射函数的影响fθ(xi),由于最小化loss的目标是使模型预测的结果尽可能地接近真实值,从而提高模型的准确性和泛化能力。最大化loss的目标则相反,它会使模型预测的结果与真实值之间的差距更大。辨别器的目标是更好的区分是来自target域还是sourse域。因此对于最大化来自taget域的输入的fθ(xi),相当于最小化来自源域的输入,其对抗损失定义为
并且可以看见在对抗领域自适应中,训练过程是无标注的,仅有采样x的输入,并没有label的信息,对抗领域自适应是一个无监督的领域自适应
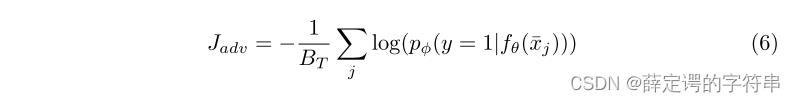
根据其优化策略,给出了K-way one shot learning task的训练伪代码
 # 然后作者又提出了在one shot中非常容易Overgeneralization,提出了reinforce sample selection来降低Overgeneralization的情况。
# 然后作者又提出了在one shot中非常容易Overgeneralization,提出了reinforce sample selection来降低Overgeneralization的情况。
其主要流程如下
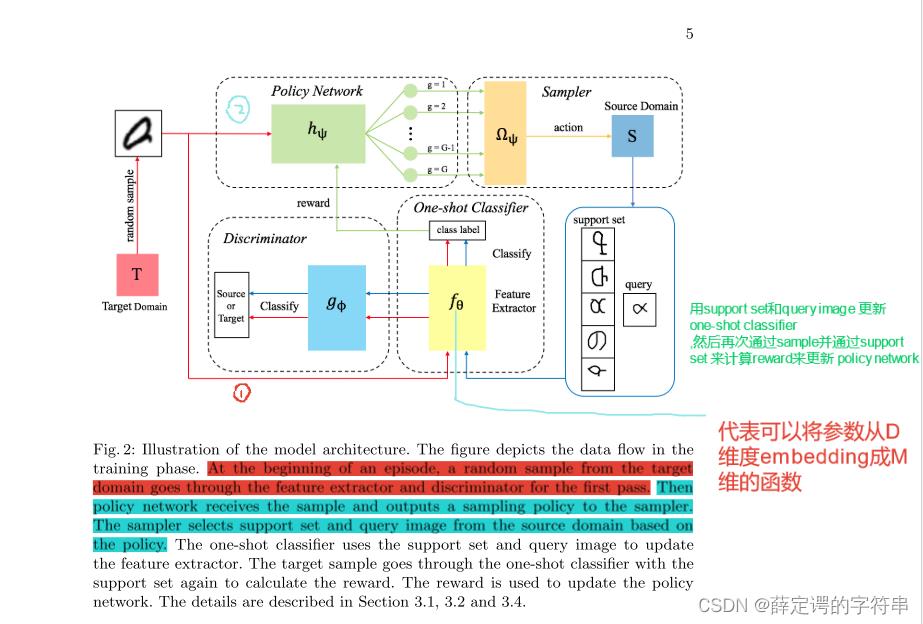
对reinforce sample selection的定义和解释
其采样的流程是,policy network根据target中的图像,输出一个policy(在论文中,并没有非常明确且直接的说明policy的细节,并在论文后面也说了难以直接给出选择set) 给采样器,采样器会输出一个来自源域的子集和query image。其中的set 应该包含有(xsim, ysim) ∈ S and (xdis, ydis) ∈ S,且要让采样的图像非常接近xsim,非常远离xdis。
 # 这里比较模糊,大概这个G就是,选择的那个K个要分的类,但是文章中,说G要互不相关,且为了计算的复杂度,最后把G的选取简单化为超类或者人为的选择一些非常不相关的类。然后,在选择了不同的类别G的基础上,给出了采用x,其来自target测试集,属于G中的某个类别的概率计算公式,其中hψ代表的是policy work的采样策略。注意这个[g]意味着已经把标注信息也放进去了,是有监督的。
# 这里比较模糊,大概这个G就是,选择的那个K个要分的类,但是文章中,说G要互不相关,且为了计算的复杂度,最后把G的选取简单化为超类或者人为的选择一些非常不相关的类。然后,在选择了不同的类别G的基础上,给出了采用x,其来自target测试集,属于G中的某个类别的概率计算公式,其中hψ代表的是policy work的采样策略。注意这个[g]意味着已经把标注信息也放进去了,是有监督的。
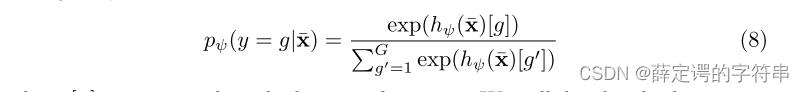
reward的计算。在文章中是说,如果当one-shot classifier 准确的将query image识别到,就会把query image替换为target image,然后在计算reward的时候,用的是target image来计算reward。(这里个人理解,就 query image 是出自S域的,那当根据来自target域的x输出的query image正确的分类的时候,说明target 的采样x和 query image十分相似) 这里的reward是积累的,是对每一个可能的类的query images进行计算。
这里的reward是积累的,是对每一个可能的类的query images进行计算。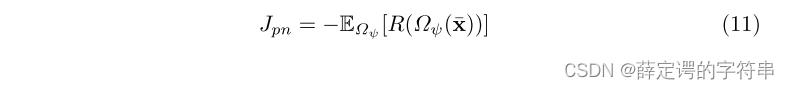
这个reward的优化可以定义为
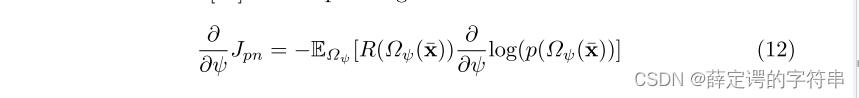
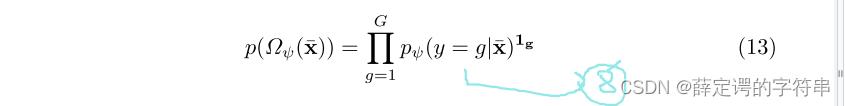
因此最后,这个adversarial domain adaption with reinforced sample selection for a K way one-shot learning task的流程可以定义为,右上方是上图的算法。

实验 细节
在这个论文中,作者主要做了两个实验。
第一个是纯 在Adversarial Domain Adaption中做的,大概流程如下图
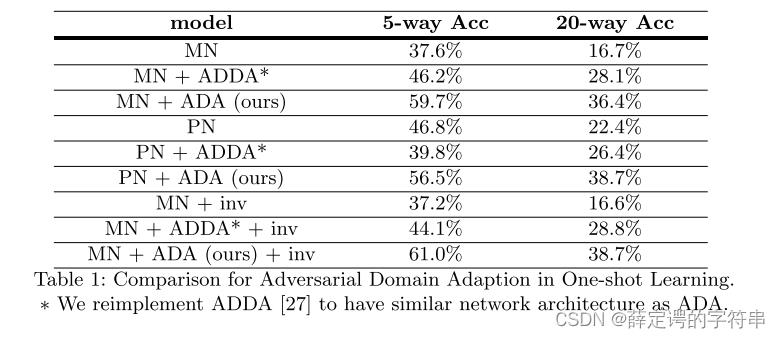
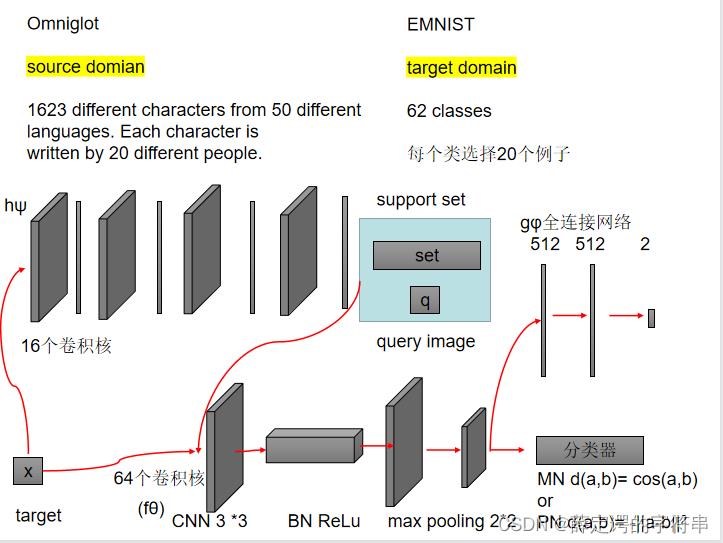 在这个实验中,作者给出了消融实验的结果
在这个实验中,作者给出了消融实验的结果
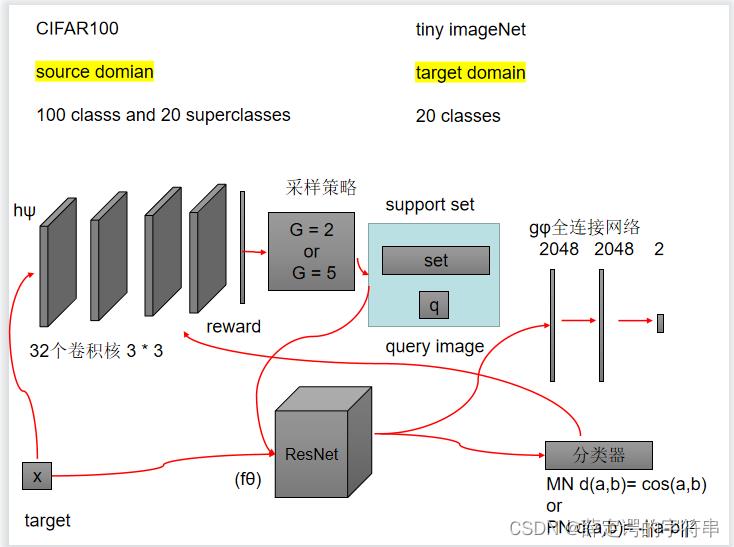
另一个是对图像进行分类,采样的是Reinforced Sample Selection
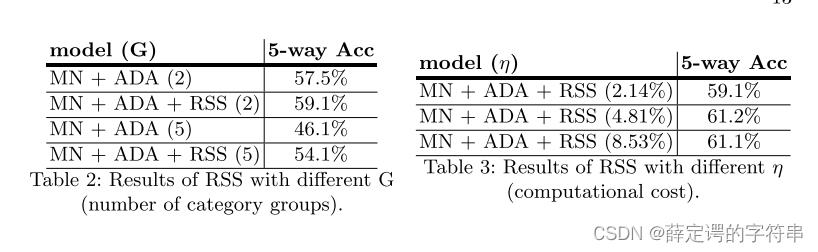
 结果
结果

style transfer/domain adaption简介
style transfer和domain adaption还是有很多相似之处的,本文挑选几篇文章进行简略介绍
Texture Synthesis Using Convolutional Neural Networks
从噪音开始合成纹理,用L2约束合成图与目标图的gram矩阵,通过梯度反传一步一步合成纹理。
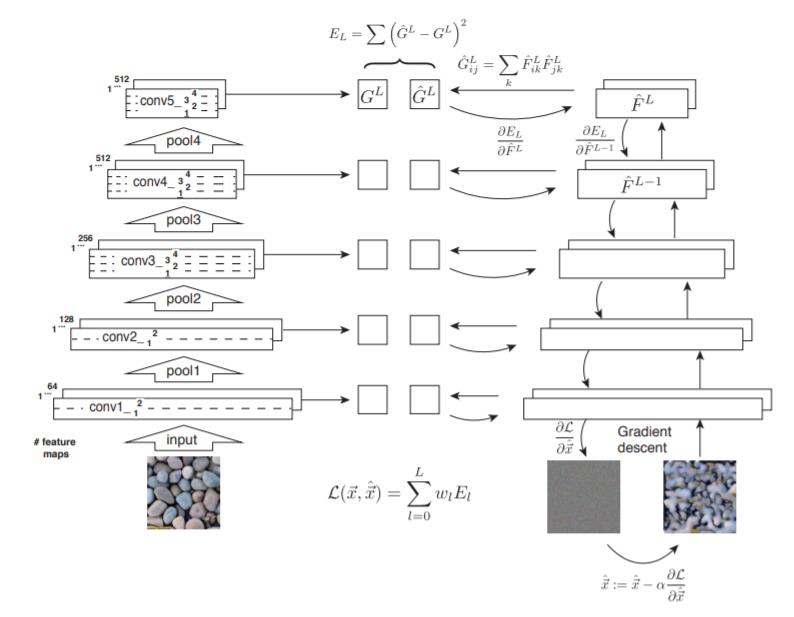
Image Style Transfer Using Convolutional Neural Networks 16年cvpr
和A neural algorithm of artistic style. 15年8月一样的吧
利用DNN进行style transfer的开篇之作,也是上一篇Texture Synthesis的扩展,Texture Synthesis只有style(纹理),这一篇再加上content。
做法:送入一张噪音图片,然后通过content和style loss约束,梯度下降更改输入使其content和内容图片一致,style和样式图片一致。
缺点:每次生成图片,都要经历这样一个训练过程,太慢了
Perceptual Losses for Real-Time Style Transfer and Super-Resolution
融合两派好处
- 做超分那一派,图像生成问题(Feed-forward image transformation),原图-》增强图,后面有pixel loss监督
- style transfer这一派,用perceptual loss但是当成了优化问题,速度慢
前向图像生成且用perceptual loss,速度快效果好,消除了上一篇那种看成优化问题每次都要重新训练的缺点。
Texture Networks: Feed-forward Synthesis of Textures and Stylized Images
与上一篇异曲同工,都是用生成的方式来做风格化
Ada BN
Adaptive Batch Normalization for practical domain
本文有个假设:
We hypothesize that the label related knowledge is stored in the weight matrix of each layer, whereas domain related knowledge is represented by the statistics of the BN.
翻译就是:标注知识存储在学习好的各层参数中,而各个域的特性是由各层参数的统计量里如BN的统计量。
正常的BN是每个batch减自己batch的均值除自己batch的方差,然后再维护一个running mean和running var用于test时用。即训练时每个batch只管自己,而test的mean var是融合了整个数据库的。
Adaptive BN是在源域上正常用BN训练,但是在目标域test前,需要先将已有的所有目标域图片送入网络进行一次前传,统计出一个running mean和running var,然后将这个mean和var用于目标域的test
Ada IN
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization
本文做法很简单:
AdaIN simply adjusts the mean and variance of the content input to match those of the style input. 换句话就是我们只需要把content图像在encoder后输出的均值和方差归一到style图像就行。(我还做了一点小实验,随意扰动mean var的顺序(本来是按channel算好的),可以得到不同的transfer结果,从结果中可以看到扰动mean影响大扰动var影响小,mean更多地代表着风格,而var则是细节的一些变化)
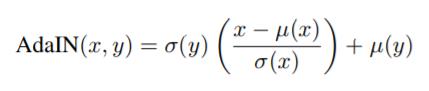

AutoDIAL
AutoDIAL: Automatic DomaIn Alignment Layers
adabn没有见过target 图片,target不能参与训练
AutoDIAL:训练时送入source和target,然后分别统计source和target的mean和std,更新时用
两者有个alpha融合,然后source利用label进行监督更新网络,target不能学习但是照样跟着更新bn的参数。
test时,只有target了,bn就用训练时统计的参数

以上是关于阅读Domain Adaption in One-Shot Learning(记录)的主要内容,如果未能解决你的问题,请参考以下文章