管理博文Hive大数据-Mysql的安装和启动---大数据之Hive工作笔记0007
Posted 脑瓜凉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了管理博文Hive大数据-Mysql的安装和启动---大数据之Hive工作笔记0007相关的知识,希望对你有一定的参考价值。

然后我们看,在给hive切换derby数据为,mysql数据库前,先去安装一下
mysql,这个已经安装了很多遍了
找到连接器,mysql的,然后
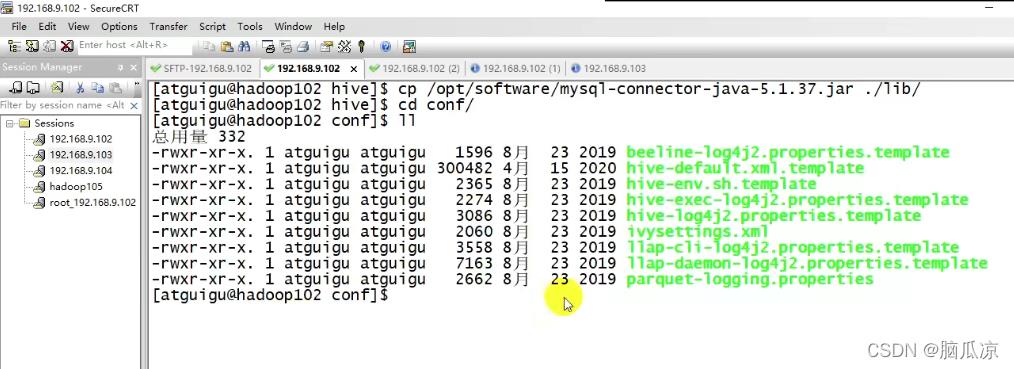
然后去看一下把这个mysql的驱动,copy到 hive的lib目录下
可以看到cp /opt/software/mysql-connector-java-5.1.37.jar ./lib/
copy过去以后,然后再进入conf这个hive的文件夹
2021年大数据Hive:Hive的三种安装模式和MySQL搭配使用
全网最详细的Hive文章系列,强烈建议收藏加关注!
后面更新文章都会列出历史文章目录,帮助大家回顾知识重点。
目录
系列历史文章
2021年大数据Hive(九):Hive的数据压缩
2021年大数据Hive(五):Hive的内置函数(数学、字符串、日期、条件、转换、行转列)
2021年大数据Hive(三):手把手教你如何吃透Hive数据库和表操作(学会秒变数仓大佬)
2021年大数据Hive(二):Hive的三种安装模式和MySQL搭配使用
2021年大数据Hive(一):Hive基本概念
前言
2021大数据领域优质创作博客,带你从入门到精通,该博客每天更新,逐渐完善大数据各个知识体系的文章,帮助大家更高效学习。
有对大数据感兴趣的可以关注微信公众号:三帮大数据

Hive的三种安装模式和MySQL搭配使用
一、Hive的安装方式
hive的安装一共有三种方式:内嵌模式、本地模式、远程模式
元数据服务(metastore)作用是:客户端连接metastore服务,metastore再去连接MySQL数据库来存取元数据。有了metastore服务,就可以有多个客户端同时连接,而且这些客户端不需要知道MySQL数据库的用户名和密码,只需要连接metastore 服务即可。
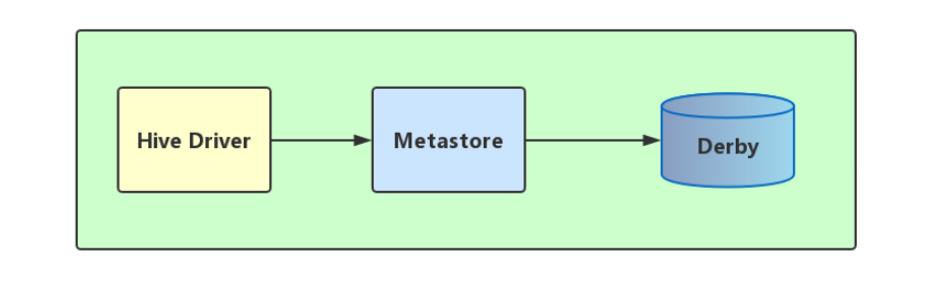
1、内嵌模式
内嵌模式使用的是内嵌的Derby数据库来存储元数据,也不需要额外起Metastore服务。数据库和Metastore服务都嵌入在主Hive Server进程中。这个是默认的,配置简单,但是一次只能一个客户端连接,适用于用来实验,不适用于生产环境。
解压hive安装包 bin/hive 启动即可使用
缺点:不同路径启动hive,每一个hive拥有一套自己的元数据,无法共享。
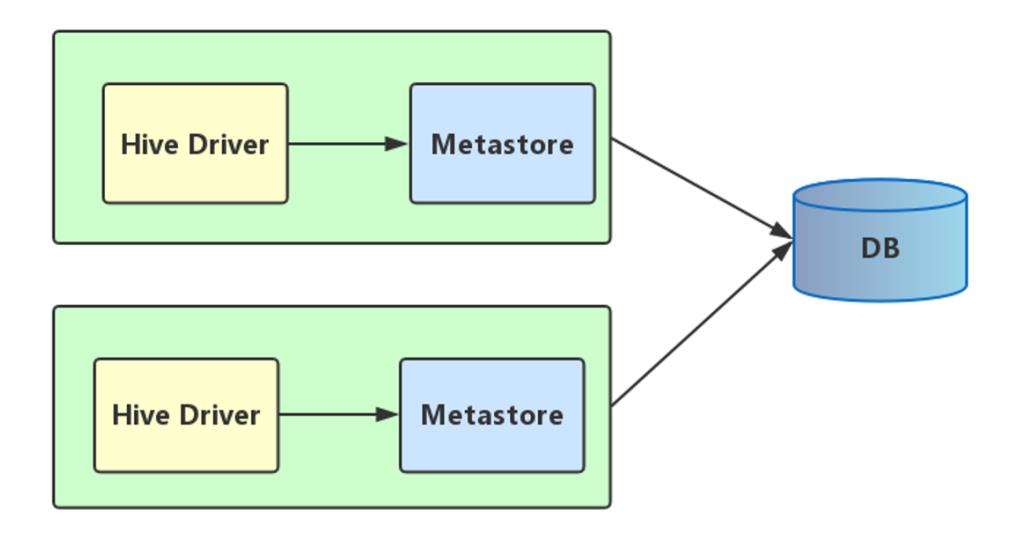
2、本地模式
本地模式采用外部数据库来存储元数据,目前支持的数据库有:MySQL、Postgres、Oracle、MS SQL Server.在这里我们使用MySQL。
本地模式不需要单独起metastore服务,用的是跟hive在同一个进程里的metastore服务。也就是说当你启动一个hive 服务,里面默认会帮我们启动一个metastore服务。
hive根据hive.metastore.uris 参数值来判断,如果为空,则为本地模式。
缺点是:每启动一次hive服务,都内置启动了一个metastore。
3、远程模式
远程模式下,需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。远程模式的metastore服务和hive运行在不同的进程里。
在生产环境中,建议用远程模式来配置Hive Metastore。
在这种情况下,其他依赖hive的软件都可以通过Metastore访问hive。
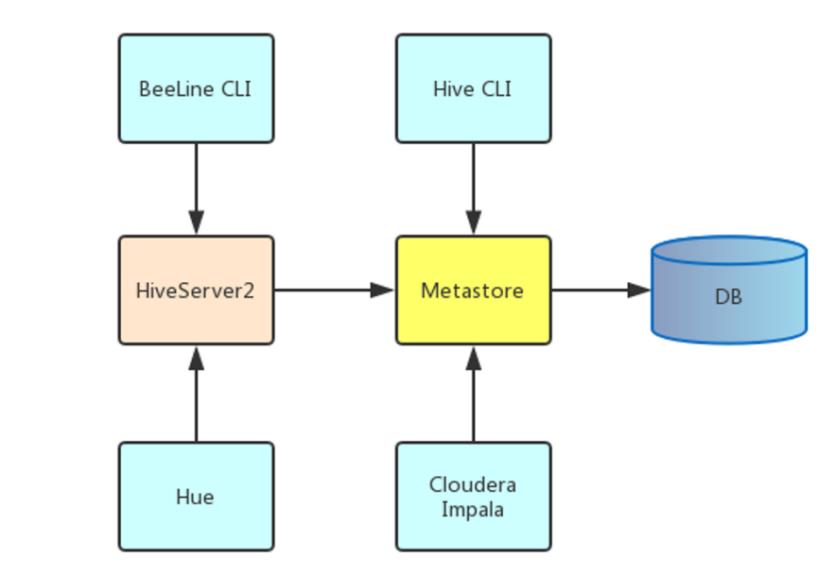
远程模式下,需要配置hive.metastore.uris 参数来指定metastore服务运行的机器ip和端口,并且需要单独手动启动metastore服务。
hiveserver2是Hive启动了一个server,客户端可以使用JDBC协议,通过IP+ Port的方式对其进行访问,达到并发访问的目的。
二、Hive的安装
我们在此处选择第三台机器node3作为我们hive的安装机器,安装方式使用远程方式。
1、准备工作
1、下载hive的安装包,这里我们选用hive的版本是2.1.0,软件包为:apache-hive-2.1.0-bin.tar.gz
Hive下载地址:http://archive.apache.org/dist/hive/
2、下载mysql的安装包,我们使用的mysql版本是5.7.29,软件包为:mysql-5.7.29-linux-glibc2.12-x86_64.tar.gz
下载地址:https://downloads.mysql.com/archives/community/
3、将apache-hive-2.1.0-bin.tar.gz上传到/export/software目录
4、将mysql-5.7.29-linux-glibc2.12-x86_64.tar.gz上传到/export/software目录
2、安装mysql数据库
在这里,我们使用mysql数据库作为Hive的元数据存储,所以在安装Hive之前,必须安装好mysql
注意!!!!!,在安装Mysql之前,给虚拟机保存一个快照,一旦安装失败,可以恢复快照,重新安装!
1、解压mysql安装包
#将MySQL的安装包提前上传到Linux的/export/software目录
cd /export/software
tar -zxvf mysql-5.7.29-linux-glibc2.12-x86_64.tar.gz -C /export/server/2、重命名
cd /export/server
mv mysql-5.7.29-linux-glibc2.12-x86_64 mysql-5.7.293、添加用户组与用户
groupadd mysql
useradd -r -g mysql mysql4、修改目录权限
chown -R mysql:mysql /export/server/mysql-5.7.29/5、配置mysql服务
cp /export/server/mysql-5.7.29/support-files/mysql.server /etc/init.d/mysql6、修改mysql配置文件
1)修改/etc/init.d/mysql文件
vim /etc/init.d/mysql将该文件的basedir和datadir路径修改为以下内容
basedir=/export/server/mysql-5.7.29
datadir=/export/server/mysql-5.7.29/data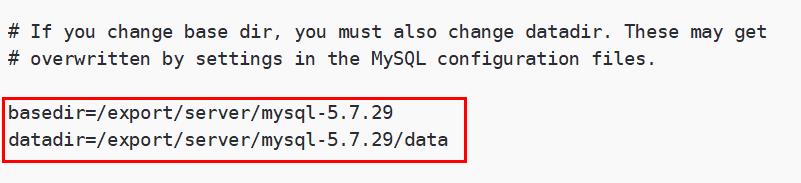
2)修改配置文件my.cnf
修改/etc/my.cnf文件
vim /etc/my.cnf将/etc/my.cnf原来的内容全部删除,然后将以下内容复制进去.
[client]
port=3306
default-character-set=utf8
[mysqld]
basedir=/export/server/mysql-5.7.29
datadir=/export/server/mysql-5.7.29/data
port=3306
character-set-server=utf8
default_storage_engine=InnoDB7、初始化mysql
/export/server/mysql-5.7.29/bin/mysqld --defaults-file=/etc/my.cnf --initialize --user=mysql --basedir=/export/server/mysql-5.7.29 --datadir=/export/server/mysql-5.7.29/data执行该命令之后,会生成一个mysql的临时密码,这个密码后边要使用。
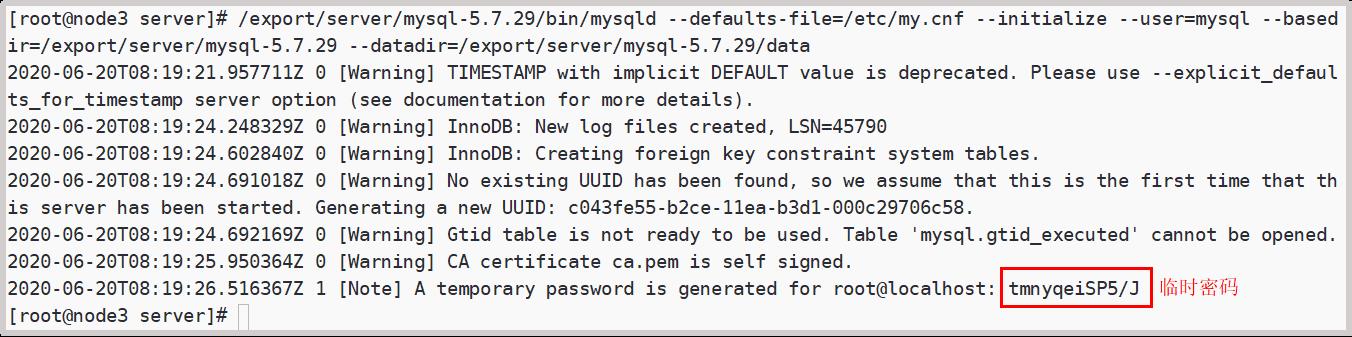
8、启动服务
service mysql start9、登录mysql
使用第7步生成的临时密码
/export/server/mysql-5.7.29/bin/mysql -uroot -p临时密码请注意,如果回车之后临时密码报错,则可以执行以下指令,然后手动输入临时密码:
/export/server/mysql-5.7.29/bin/mysql -uroot -p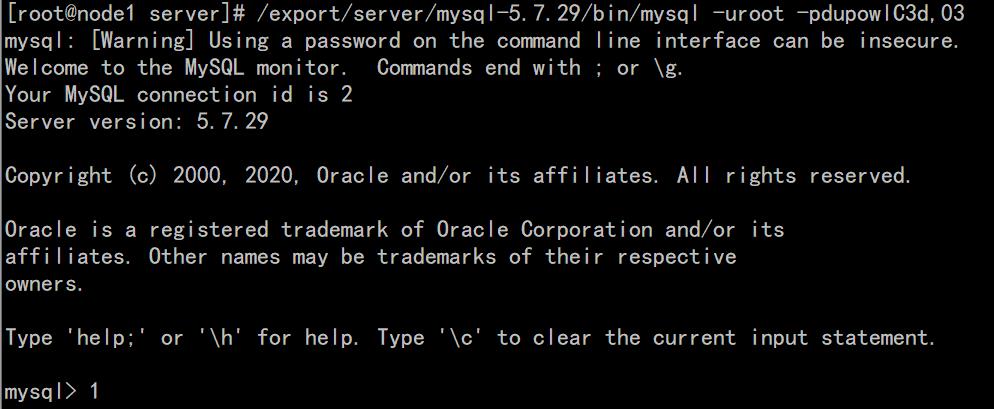
10、修改密码
注意这条命令是在登录mysql之后执行
set password=password('123456');11、开启远程访问权限
注意这条命令是在登录mysql之后执行
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456';
flush privileges;12、修改环境变量
退出mysql,然后修改Linux的/etc/profile文件
vim /etc/profile在该文件末尾最后添加以下内容
export MYSQL_HOME=/export/server/mysql-5.7.29
export PATH=$PATH:$MYSQL_HOME/bin保存修改之后,让该文件的修改生效
source /etc/profile13、将mysql设置为开机启动
chkconfig --add mysql #mysql服务到自启服务
chkconfig mysql on #设置自启3、安装Hive
1、解压Hive安装包并重命名
cd /export/software
tar -zxvf apache-hive-2.1.0-bin.tar.gz -C /export/server
cd /export/server
mv apache-hive-2.1.0-bin hive-2.1.02、修改hive的配置文件
hive-env.sh
添加我们的hadoop的环境变量
cd /export/server/hive-2.1.0/conf
cp hive-env.sh.template hive-env.sh
vim hive-env.sh修改内容如下:
HADOOP_HOME=/export/server/hadoop-2.7.5
export HIVE_CONF_DIR=/export/server/hive-2.1.0/conf3、修改hive-site.xml
cd /export/server/hive-2.1.0/conf
vim hive-site.xml在该文件中添加以下内容
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node3:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>datanucleus.schema.autoCreateAll</name>
<value>true</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node3</value>
</property>
</configuration>4、上传mysql的lib驱动包
将mysql的lib驱动包上传到hive的lib目录下
cd /export/server/hive-2.1.0/lib将mysql-connector-java-5.1.41-bin.jar 上传到这个目录下
5、拷贝相关jar包
将hive-2.1.0/jdbc/目录下的hive-jdbc-2.1.0-standalone.jar 拷贝到hive-2.1.0/lib/目录
cp /export/server/hive-2.1.0/jdbc/hive-jdbc-2.1.0-standalone.jar /export/server/hive-2.1.0/lib/6、配置hive的环境变量
node03服务器执行以下命令配置hive的环境变量
vim /etc/profile添加以下内容:
export HIVE_HOME=/export/server/hive-2.1.0
export PATH=:$HIVE_HOME/bin:$PATH三、Hive的交互方式
第一种交互方式:bin/hive
cd /export/server/hive-2.1.0/
#初始化元数据
bin/schematool -dbType mysql -initSchema
bin/hive创建一个数据库
create database mytest;
show databases;第二种交互方式:使用sql语句或者sql脚本进行交互
不进入hive的客户端直接执行hive的hql语句
cd /export/server/hive-2.1.0/
bin/hive -e "create database mytest2"或者我们可以将我们的hql语句写成一个sql脚本然后执行
cd /export/server
vim hive.sql脚本内容如下:
create database mytest3;
use mytest3;
create table stu(id int,name string);通过hive -f 来执行我们的sql脚本
bin/hive -f /export/server/hive.sql第三种交互方式:Beeline Client
hive经过发展,推出了第二代客户端beeline,但是beeline客户端不是直接访问metastore服务的,而是需要单独启动hiveserver2服务。
1)在node1的/export/server/hadoop-2.7.5/etc/hadoop目录下,修改core-site.xml,在该文件中添加以下配置,实现用户代理:
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>将修改好的core-site.xml文件分发到node2和node3,然后重启Hadoop(stop-all.sh start-all.sh)
2)在hive运行的服务器上,首先启动metastore服务,然后启动hiveserver2服务。
nohup /export/server/hive-2.1.0/bin/hive --service metastore &
nohup /export/server/hive-2.1.0/bin/hive --service hiveserver2 &nohup 和 & 表示后台启动
3)在node3上使用beeline客户端进行连接访问。
/export/server/hive-2.1.0/bin/beeline根据提醒进行以下操作:
[root@node3 ~]# /export/server/hive-2.1.0/bin/beeline
which: no hbase in (:/export/server/hive-2.1.0/bin::/export/server/hadoop-2.7.5/bin:/export/data/hadoop-2.7.5/sbin::/export/server/jdk1.8.0_241/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/export/server/mysql-5.7.29/bin:/root/bin)
Beeline version 2.1.0 by Apache Hive
beeline> !connect jdbc:hive2://node3:10000
Connecting to jdbc:hive2://node3:10000
Enter username for jdbc:hive2://node3:10000: root
Enter password for jdbc:hive2://node3:10000:123456
连接成功之后,出现以下内容,可以在提示符后边输入hive sql命令

四、Hive一键启动脚本
这里,我们写一个expect脚本,可以一键启动beenline,并登录到hive。expect是建立在tcl基础上的一个自动化交互套件, 在一些需要交互输入指令的场景下, 可通过脚本设置自动进行交互通信。
1、安装expect
yum -y install expect
2、创建脚本
cd /export/server/ hive-2.1.0
vim beenline.exp添加以下内容:
#!/bin/expect
spawn beeline
set timeout 5
expect "beeline>"
send "!connect jdbc:hive2://node3:10000\\r"
expect "Enter username for jdbc:hive2://node3:10000:"
send "root\\r"
expect "Enter password for jdbc:hive2://node3:10000:"
send "123456\\r"
interact3、修改脚本权限
chmod 777 beenline.exp4、启动beeline
expect beenline.exp- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于管理博文Hive大数据-Mysql的安装和启动---大数据之Hive工作笔记0007的主要内容,如果未能解决你的问题,请参考以下文章