满血BuffChatGPT科普篇,三段式介绍,内含各种高效率插件
Posted 追寻上飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了满血BuffChatGPT科普篇,三段式介绍,内含各种高效率插件相关的知识,希望对你有一定的参考价值。
【满血Buff】ChatGPT科普篇,三段式介绍,内含各种高效率插件
本篇博客采用三段论的叙事方式进行时下流行的人工智能工具ChatGPT的科普。
1、ChatGPT是什么
ChatGPT是Chat Generated by Pre-trained Transformer的缩写,拆解分为Chat和GPT。其中GPT是Generated by Pre-trained Transformer,可以翻译为生成式预训练转换器。
ChatGPT是OpenAI开发的一个大型预训练语言模型。它是GPT-3模型的变体,可以在对话中生成类似人类的文本响应。ChatGPT旨在用作聊天机器人,我们可以对其进行微调,以完成各种任务,如回答问题、提供信息或参与对话。
GPT模型是一个家族系列。由知名公司OpenAI研发,可以在非常复杂的NLP(自然语言处理,Natural Language Processing)任务中取得非常惊艳的效果,例如文章生成,代码生成,机器翻译,Q&A等。
GPT系列模型的结构秉承不断堆叠transformer的思想,通过不断提升训练语料的规模和质量,提升网络的参数数量来完成GPT系列的迭代更新。目前OpenAI已经发布了多个版本的GPT模型,包括GPT-1、GPT-2、GPT-3和最新发布的GPT-4。
这些版本之间主要区别在于模型规模、参数量、预训练数据量以及性能等方面,如下图所示。
| 模型 | 发布时间 | 参数量 | 预训练数据量 | 产品 |
|---|---|---|---|---|
| GPT-1 | 2018年6月 | 1.17亿 | 5GB | / |
| GPT-2 | 2019年2月 | 15亿 | 40GB | / |
| GPT-3 | 2020年5月 | 1750亿 | 45TB | / |
| GPT-3.5 | 2022年初 | 1750亿 | 45TB | ChatGPT |
| GPT-4 | 2023年3月 | 100万亿(预估,网上无真实的数据) | 未知 | ChatGPT PLUS |
值得一提的是,GPT-4可以接受图像和文本输入,并产生文本输出。虽然在许多现实场景中不如人类能力强,但GPT-4在各种专业和学术基准测试中表现出与人类水平相当的性能,包括通过得分约为前10%的考试者的模拟律师考试。 GPT-4在预测文档中下一个标记方面具有较高精度。后期训练对齐过程提高了其事实性和符合所需行为等指标上的表现。该项目的核心组成部分是开发可在广泛范围内可预测地运作的基础设施和优化方法。
我们使用的服务大多是基于GPT-3.5模型,知识截止日期是2022年初,我们向他提问晚于2022年初时间的问题,它是无法回答的。当然我们也有办法解决,在第5章节进行讲解。

2、为什么要掌握ChatGPT效能工具
掌握ChatGPT效能工具可以帮助我们在自然语言处理领域做出更高效、更精准的工作。ChatGPT是一种强大的自然语言生成模型,可以用于许多人工智能应用,例如聊天机器人、语音助手、翻译、摘要生成等。掌握ChatGPT效能工具可以帮助我们:
提高自然语言处理的效率:ChatGPT效能工具可以帮助我们快速生成自然语言文本,减少手动编写文本的工作量,提高工作效率。
改善自然语言处理的质量:ChatGPT效能工具可以生成高质量的自然语言文本,减少因为语法、拼写等问题带来的错误,提高自然语言处理的质量。
创造更多的自然语言处理应用:掌握ChatGPT效能工具可以帮助我们在自然语言处理领域创造更多的应用,例如聊天机器人、语音助手、翻译、摘要生成等。这些应用可以帮助我们更好地处理和利用自然语言数据,提高工作效率和工作质量。
对于语言描述偏弱的工科生来说,掌握ChatGPT效能工具可以有效帮助我们提升语言描述水平。
你可以让ChatGPT进行词语柔糅合,如图所示
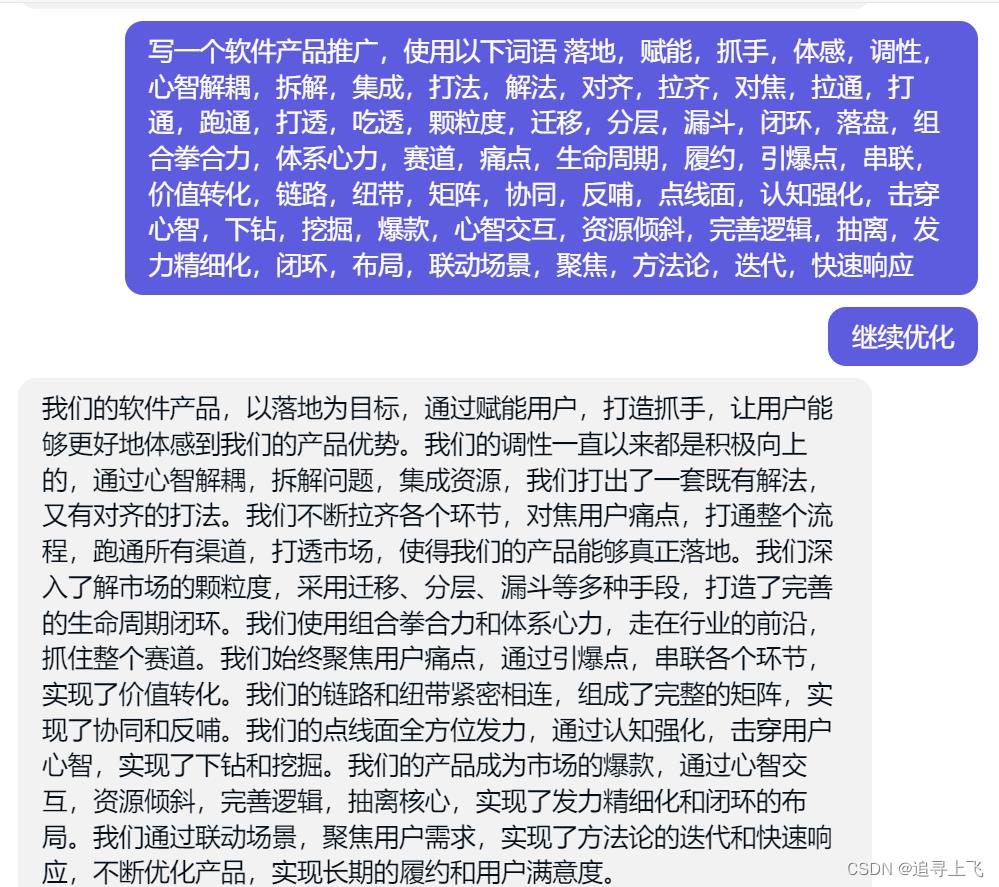
3、ChatGPT能做什么
ChatGPT的应用在不同岗位上有不同的具体工作,以下是一些例子:
客服岗位:ChatGPT可以用于构建自动客服机器人,回答客户的问题、提供服务支持,减轻人工客服的工作负担。
新闻编辑岗位:ChatGPT可以用于摘要生成,将新闻文章压缩成较短的概括性文本,帮助编辑更快地浏览和理解大量新闻文章,并从中提取关键信息。
营销岗位:ChatGPT可以用于构建广告创意生成模型,自动生成广告文案,提高广告的效果。
翻译岗位:ChatGPT可以用于构建翻译模型,将一种语言翻译成另一种语言,帮助翻译人员更快地完成翻译任务。
数据分析岗位:ChatGPT可以用于自然语言生成,将结构化数据转换成自然语言文本,帮助数据分析师更好地向非技术人员解释分析结果。
4、和ChatGPT相关的谷歌插件
4.1 WebChatGPT
这个插件可以进行联网搜索,解决第1章节中提出的问题。搜索就可以基于互联网上实时的信息进行回答。
4.2 OpenAI Ttanslator 翻译
这是一个使用 ChatGPT API 进行划词翻译和文本润色的浏览器插件。借助了 ChatGPT 强大的翻译能力,它将帮助您更流畅地阅读外语和编辑外语。
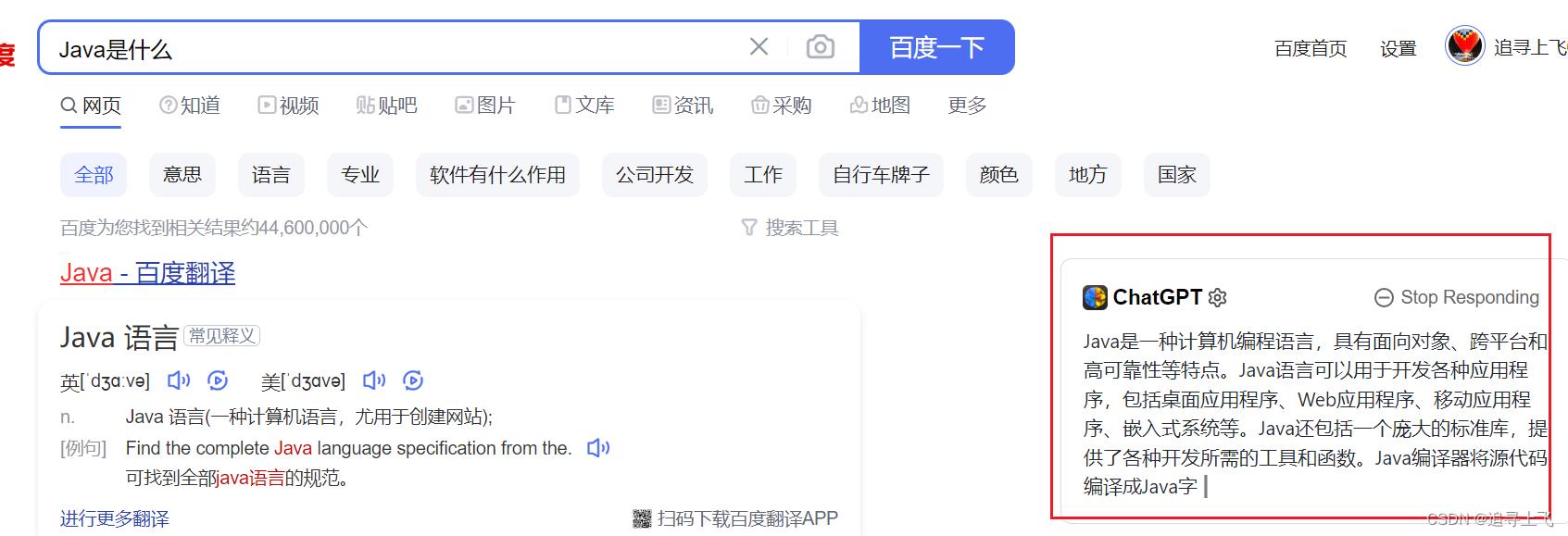
4.3 ChatGPT for Google
功能点:
- 支持所有主流的搜索引擎
- 在获得搜索结果后可直接开始聊天
- 支持OpenAI官方API
- 从插件弹窗里快速使用ChatGPT
- 支持Markdown渲染
- 支持代码高亮
- 支持深色模式
- 可自定义ChatGPT触发模式
扫盲科普篇SpringCloud 框架介绍和核心组件详解
目录
工作中没有接触 SpringCloud 的机会,但是看到很多其他公司都在用,而且它频繁地出现在招聘需求中,那就一起从 0 到 1 快速学习一下 SpringCloud 吧(期待地搓了搓小手)~
SpringCloud 是基于 SpringBoot 基础上开发的微服务框架,首先来介绍一下什么是微服务框架。
一. 微服务框架
微服务是系统架构上的一种设计风格,是将一个原本独立的系统拆分成多个小型服务,这些小型服务都在各自独立的进程中运行。
小型服务之间通过基于 HTTP/HTTPS 协议的 RESTful API 进行通信协作,也可以通过 RPC 协议进行。
被拆分的每一个小型服务都围绕着系统中一些耦合度较高的业务功能进行构建,并且每个服务都维护着自身的数据存储,业务开发,自动化测试案例以及独立部署机制。
由于有了轻量级的通信协作基础,所以这些微服务可以使用不同的语言来编写。
二. SpringCloud 是什么
Spring Cloud 是一系列框架的有序集合。
它利用 Spring Boot 的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用 Spring Boot 的开发风格做到一键启动和部署。
Spring Cloud 并没有重复制造轮子,它只是将各家公司开发的比较成熟、经得起实际考验的服务框架组合起来,通过 Spring Boot 风格进行再封装,从而屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。
三. SpringCloud 组件概览
SpringCloud 的组件分为两大类型,第一种是依赖其它组件并为其提供服务的,主要有 Ribbon,Hystrix,Feign,Stream,Bus,Sleuth。
Ribbon:客户端负载均衡,特性有区域亲和、重试机制。
Hystrix:客户端容错保护,特性有服务降级、服务熔断、请求缓存、请求合并、依赖隔离。
Feign:声明式服务调用,本质上就是 Ribbon + Hystrix。
Stream:消息驱动,有Sink、Source、Processor 三种通道,特性有订阅发布、消费组、消息分区。
Bus:消息总线,配合Config 仓库修改的一种 Stream 实现。
Sleuth:分布式服务追踪,需要搞清楚 TraceID 和 SpanID 以及抽样,如何与 ELK 整合。
第二种是独自启动不需要依赖其它组件,主要有 Eureka,Dashboard,Turbine,Zuul,Config。
Eureka:服务注册中心,特性有失效剔除、服务保护。
Dashboard:Hystrix 仪表盘,监控集群模式和单点模式,其中集群模式需要收集器 Turbine配合。
Turbine:集群收集器,服务于Dashboard。
Zuul:API 服务网关,功能有路由分发和过滤。
Config:分布式配置中心,支持本地仓库、SVN、Git、Jar 包内配置等模式。
四. SpringCloud 核心组件详解
SpringCloud 核心组件主要包括 Spring Cloud Netflix 项目下的 Eureka,Ribbon,Hystrix,Zuul 以及 Config 和 Feign。
1. Eureka
Eureka 是 Netflix 开源的一款提供服务注册和发现的产品,它提供了完整的 Service Registry 和 Service Discovery 实现,也是 Spring Cloud 体系中最重要最核心的组件之一。
我们可以把 Eureka 看作是一个服务中心,所有的可以提供的服务都注册到它这里来管理,其它调用者需要的时候去注册中心获取,然后再进行调用。
这样就避免了服务之间的直接调用,方便后续的水平扩展、故障转移等。
服务注册中心是非常重要的组件,一旦挂掉将会影响全部服务,因此需要搭建 Eureka 集群来保持高可用性,生产环境中最少两台。
如下图所示:
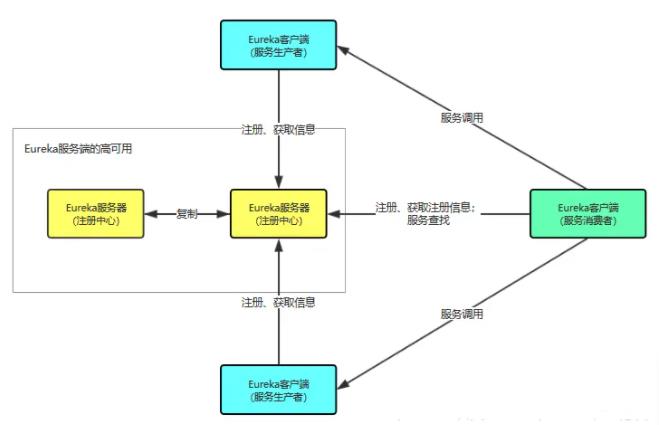
Eureka服务器(注册中心) 是一个Eureka Server ,提供服务注册和发现功能;
Eureka客户端(服务生产者) 是一个Eureka Client ,从注册中心注册、获取信息,用来提供服务;
Eureka客户端(服务消费者) 也是一个Eureka Client ,从注册中心注册、获取信息和进行服务查找,用来消费服务;
2. Ribbon
Ribbon 是一个客户端的负载均衡器(Load Balancer,简称LB),对大量的 HTTP 和 TCP 客户端提供访问控制。
Ribbon 将负载均衡逻辑集成到消费方,消费方从服务注册中心获取可用服务列表,然后根据指定的负载均衡策略选择合适的服务器。
Ribbon 的负载均衡策略主要包含以下三种:
(1) RoundRobinRule 轮询
轮询服务列表 List <Server> 的 index,选择 index 对应位置的服务。
(2) RandomRule 随机
随机访问服务列表List<Server>的 index,选择 index 对应位置的服务。
(3) RetryRule 重试
指定时间内,重试(请求)某个服务不成功达到指定次数,则不再请求该服务。
3. Hystrix
微服务架构特点就是多服务,多数据源,支撑系统应用,所以微服务之间存在着依赖关系。如果其中一个服务故障,可能导致系统宕机,这就是所谓的雪崩效应。
Hystrix 正是用于解决这种情况的,可以防止对某一故障服务持续进行访问。
分布式架构中的某个服务单元发生故障后,Hystrix 会监控到该故障,并向调用方返回一个错误响应,而不是长时间的等待。这样就不会使得线程因调用故障服务被长时间占用不释放,避免了故障在分布式系统中的蔓延。
Hystrix 具备了服务降级、服务熔断、线程和信号隔离、请求缓存、请求合并以及服务监控等强大功能。
4. Zuul
Zuul 网关主要提供动态路由,监控,限流,安全管控等功能。
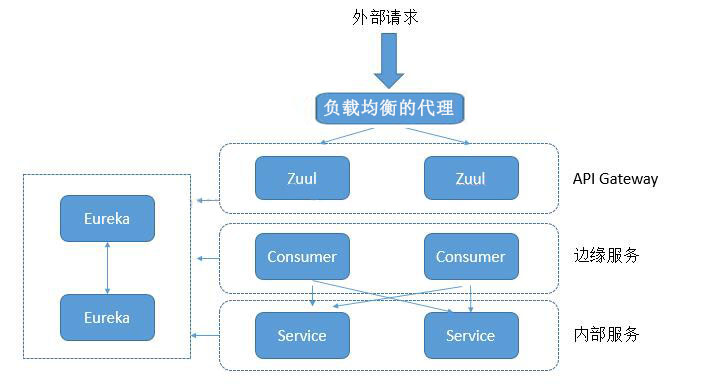
在分布式的微服务系统中,系统被拆分为了多个微服务模块,通过 Zuul 网关对用户请求进行路由,转发到具体的微服务模块中。
基于 Spring 的微服务结点在角色上分为 边缘服务 和 内部服务 两部分。
内部服务 是对内暴露服务的结点,供架构内部来调用;
边缘服务 是对外部网络暴露的服务结点,也就是对外的 API 接口。
如下图所示,外部请求会先到 Zuul 上,在Zuul 服务上对权限进行统一实现和过滤,以实现微服务结点的过滤和验证。
5. Config
当微服务还不是很多的时候,各种服务的配置管理起来还相对简单,但是当微服务的节点达到成百上千的时候,服务配置的管理就会变得复杂起来,Config 就是一个解决分布式系统的配置管理方案。
Config 包含 Client 和 Server 两个部分,Server 存储配置文件,并以接口的形式提供配置文件的内容,也就是将所有的配置文件统一整理,避免了配置文件的碎片化。Client 通过接口获取数据,并根据此数据来初始化自己的应用。
如果服务运行期间改变配置文件,服务是不会得到最新的配置信息的,需要解决这个问题就需要引入 Refresh 机制,它可以在服务的运行期间重新加载配置文件。
当所有的配置文件都存储在配置中心的时候,配置中心就成为了一个非常重要的组件。如果配置中心出现问题,将会导致灾难性的后果,因此在生产中建议对配置中心做集群,来支持配置中心的高可用性。
6. Feign
Feign 是一种声明式、模板化的 HTTP 客户端。在 Spring Cloud 中使用 Feign, 我们可以做到使用 HTTP 请求远程服务时能与调用本地方法一样的编码体验,开发者完全感知不到是远程方法,更感知不到这是个 HTTP 请求。
Feign 的一个关键机制就是使用了动态代理,如果对某个接口定义了 @FeignClient 注解,Feign会针对这个接口创建一个动态代理。
要是调用该接口,本质就是调用 Feign 创建的动态代理,Feign 的动态代理会根据在接口上的@RequestMapping等注解,来动态构造出要请求的服务的地址,最后针对这个地址,发起请求、解析响应。
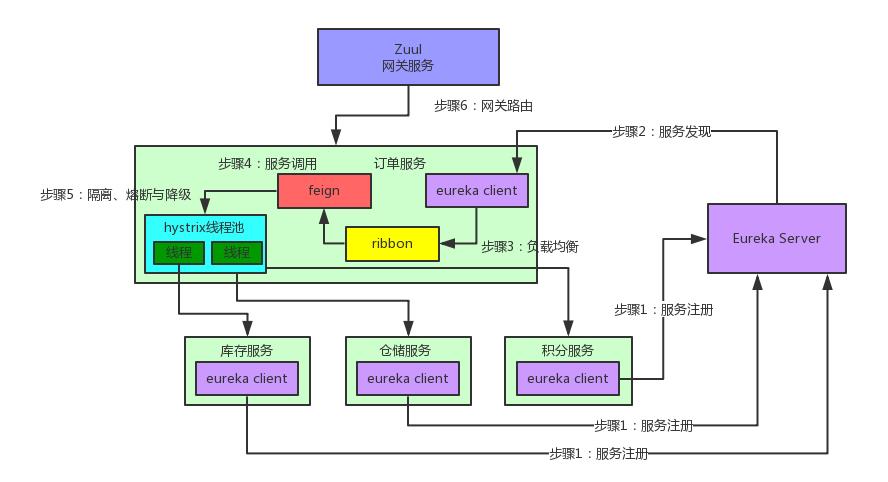
五. 实际场景案例
最后,我们可以用一个实际场景的例子来感受一下各个组件是如何进行分工和合作的:
以上是关于满血BuffChatGPT科普篇,三段式介绍,内含各种高效率插件的主要内容,如果未能解决你的问题,请参考以下文章