目标检测Faster R-CNN浅析
Posted hello_dear_you
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测Faster R-CNN浅析相关的知识,希望对你有一定的参考价值。
简介
Faster R-CNN是Ross B. Girshick在2016年提出的两阶段目标检测算法。Faster R-CNN将特征提取(feature extraction),感兴趣区域提取region proposal network,和最终的bounding box regression和classification都整合在一个网络中,使得网络的综合性能有较大的提升。
本文将Faster R-CNN从如下4个方面分析:
- Conv layers. Faster R-CNN首先使用一组简单的conv+relu+pooling层提取输入图像的feature maps。这个feature maps会被共享用于后续RPN层和全连接层;
- Region Proposal Networks。 RPN网络用于生成有效的region proposals. 该层通过softmax判断anchor是属于positive(后景)或者negative(前景),再利用bounding box regression修正anchors获得精确的proposals;
- Roi Pooling。该层收集输入的feature maps和proposals, 综合这些信息后提取proposal feature maps送入到后续的全连接层中;
- Classification and Regression. 利用proposal feature maps计算proposals的类别,同时再次进行bounding box regression获得最终的精确位置;
backbone
以VGG16为例,介绍Faster R-CNN的backbone组成。backbone中包含了conv、relu、pooling三种层,如下图所示,共有13个conv层、13个relu层、4个pooling层。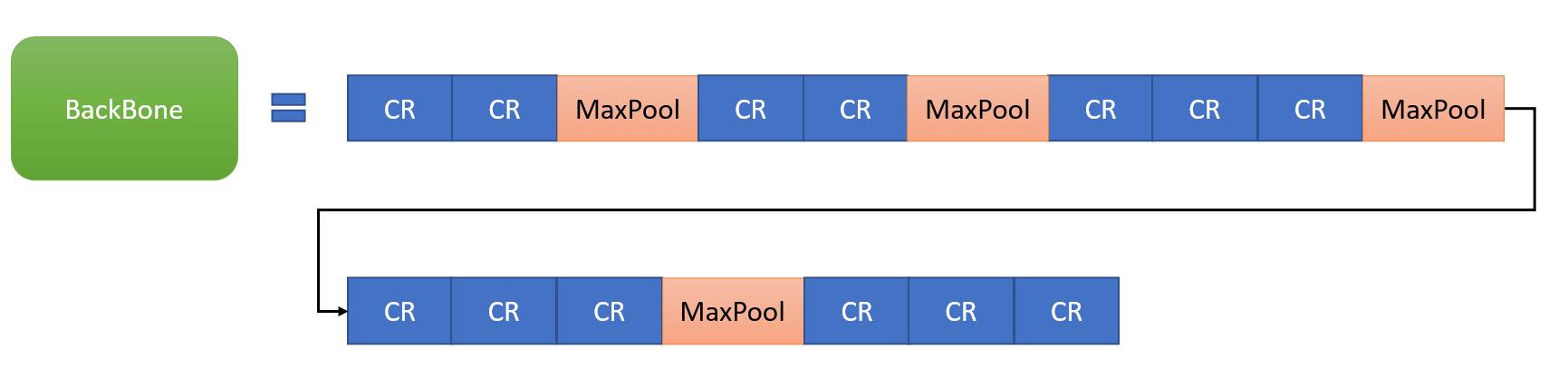
其中所有卷积层的参数设置都一样,kernel_size=3,pad=1,stride=1,也即输出与输入的特征图尺寸相同,pooling层的参数设置为:kernel_size=2,pad=0,stride=2,也即输出尺寸只有输入尺寸的1/2。
由于整个backbone中包含了4个pooling层,假设输入图像的尺寸为
M
∗
N
M *N
M∗N,那么经过backbone推理之后,输出特征图的大小为
M
16
∗
N
16
\\fracM16*\\fracN16
16M∗16N.
Region Proposal Networks(RPN)
输入图像经过backbone提供图像特征之后,进入到RPN网络中,具体结果如下图所示: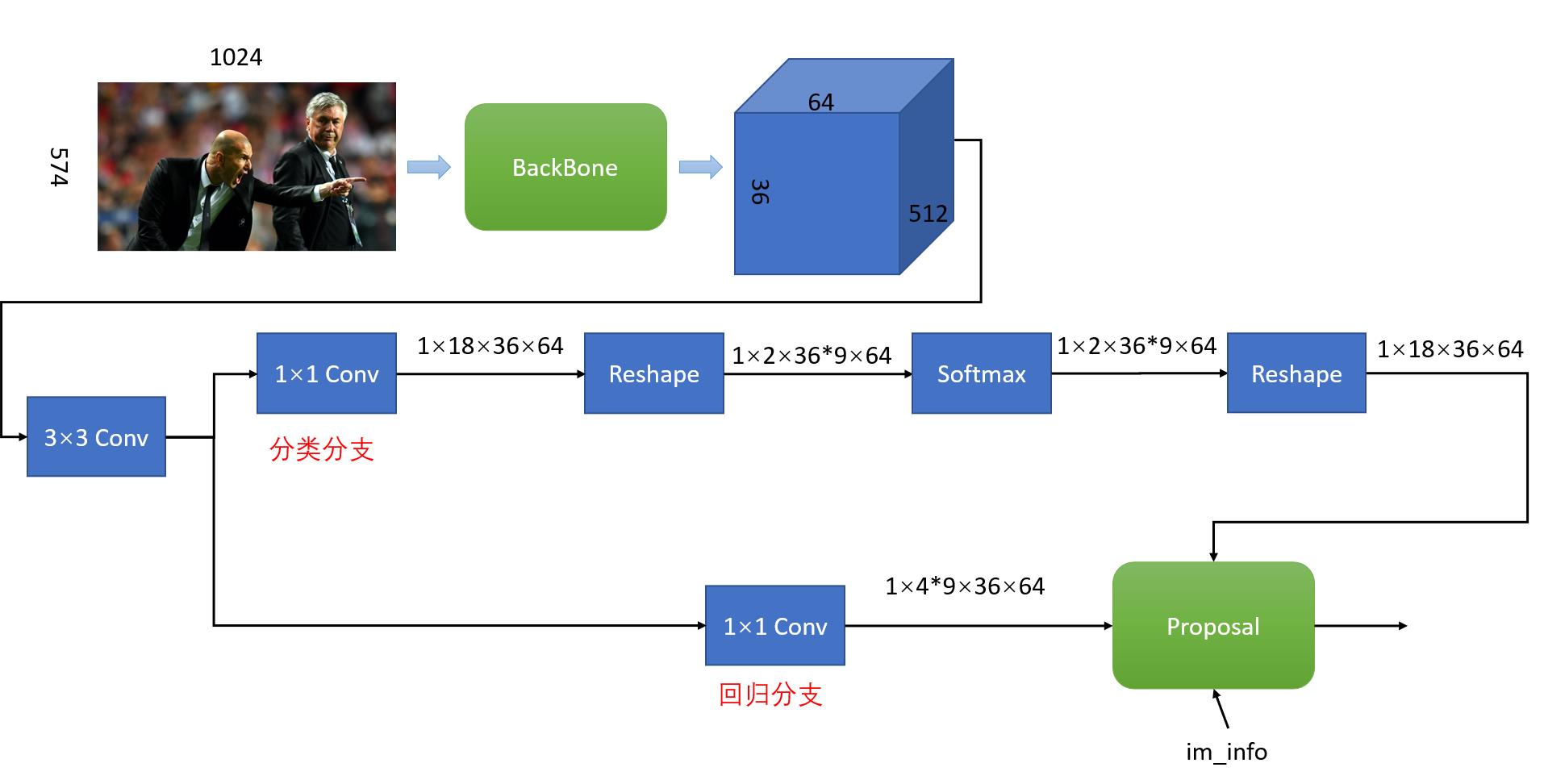
RPN网络分为分类和回归两个分支,分类分支使用sotfmax分类默认候选框anchor是positive还是negative;回归分支则负责预测实际目标框相对于默认候选框的偏移量。最后Proposal layer结合positive anchor和对应的regression偏移量得到proposal。
下面以输入图像尺寸为
C
=
3
,
H
=
576
,
W
=
1024
C=3,H=576,W=1024
C=3,H=576,W=1024例,则经过backbone提取特征之后,特征图的尺寸大小为1x512x36x64(NCHW排列)。
Anchors
在Faster R-CNN中,提供了9种不同大小、不同宽高比的anchors,其包含四个值
(
x
1
,
y
1
,
x
2
,
y
2
)
(x_1,y_1,x_2,y_2)
(x1,y1,x2,y2)表示矩形左上和右下角点坐标,anchor如下图所示: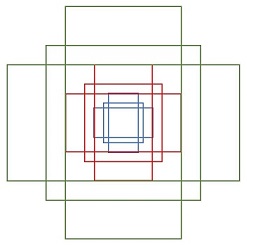
需要注意的一点是,Faster R-CNN中anchor的尺寸是相对于网络输入大小而言。以输入图像尺寸为
C
=
3
,
H
=
576
,
W
=
1024
C=3,H=576,W=1024
C=3,H=576,W=1024例,Faster R-CNN总共包含:
c
e
i
l
(
1024
/
16
)
∗
c
e
i
l
(
576
/
16
)
∗
9
=
64
∗
36
∗
9
=
20736
ceil(1024/16)*ceil(576/16)*9=64*36*9=20736
ceil(1024/16)∗ceil(576/16)∗9=64∗36∗9=20736
个anchors,这些anchors反映在网络输入上,就是如下图所示,对于每个anchor,都需要分类分支判断其是否包含物体,包含物体为positive,反之则为negative。同时,由于目标的真实位置与anchor之间存在偏移,因此需要regression分支来预测偏移量。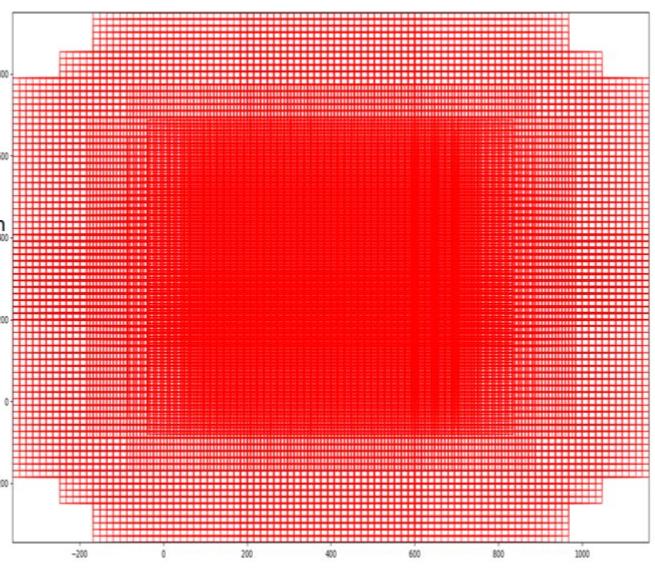
softmax分支
经过backbone之后,特征图的大小为1x512x36x64,首先通过1×1卷积,得到的特征图大小为1x18x36x64,其中18=2*9,即9个anchors,每个anchor可能是positive也可能是negative。
然后是一个reshape操作,得到特征图的维度为1x2x36*9x64,主要是为了方便softmax分类,之后再reshape恢复原状。分类分支的实现代码片段如下所示:
# define bg/fg classifcation score layer
self.nc_score_out = len(self.anchor_scales) * len(self.anchor_ratios) * 2 # 2(bg/fg) * 9 (anchors)
self.RPN_cls_score = nn.Conv2d(512, self.nc_score_out, 1, 1, 0) # 1×1卷积
def forward(): # 前向推理
# get rpn classification score
rpn_cls_score = self.RPN_cls_score(rpn_conv1)
# reshape + softmax + reshape
rpn_cls_score_reshape = self.reshape(rpn_cls_score, 2)
rpn_cls_prob_reshape = F.softmax(rpn_cls_score_reshape, 1)
rpn_cls_prob = self.reshape(rpn_cls_prob_reshape, self.nc_score_out)
sotfmax分类得到positive anchors,相当于初步提取了检测目标候选区域。
regression分支
regression分支回归得到的是anchor与ground truth之间的偏移量,因此在训练阶段,监督信号为anchor与真实框之间的差距
(
t
x
,
t
y
,
t
w
,
t
h
)
(t_x,t_y,t_w,t_h)
(tx,ty,tw,th),其中
t
x
,
t
y
t_x,t_y
tx,ty是中心点的平移值,
t
w
,
t
h
t_w,t_h
tw,th是宽高的缩放值。
(
t
x
,
t
y
,
t
w
,
t
h
)
(t_x,t_y,t_w,t_h)
(tx,ty,tw,th)的计算公式如下:
t
x
=
(
x
−
x
a
)
/
w
a
;
t
y
=
(
y
−
y
a
)
/
h
a
t_x = (x - x_a)/w_a; t_y=(y-y_a)/h_a
tx=(x−xa)/wa;ty=(y−ya)/ha
t
w
=
l
o
g
(
w
/
w
a
)
;
t
h
=
l
o
g
(
h
/
h
a
)
t_w=log(w/w_a);t_h=log(h/h_a)
tw=log(w/wa);th=log(h/ha)
其中
x
a
,
y
a
,
w
a
,
h
a
x_a,y_a,w_a,h_a
xa,ya,wa,ha是anchor的坐标值。regression分支的代码片段如下:
# define anchor box offset prediction layer
self.nc_bbox_out = len(self.anchor_scales) * len(self.anchor_ratios) * 4 # 4(coords) * 9 (anchors)
self.RPN_bbox_pred = nn.Conv2d(512, self.nc_bbox_out, 1, 1, 0)
def forward():
# get rpn offsets to the anchor boxes
rpn_bbox_pred = self.RPN_bbox_pred(rpn_conv1)
Proposal layer
proposal layer通过positive anchors和其对应的regression偏移量,计算出精准的proposal,送入到后续的RoI Pooling Layer。Proposal layer的定义如下:
# define proposal layer
self.RPN_proposal = _ProposalLayer(self.feat_stride, self.anchor_scales, self.anchor_ratios)
def forward():
rois = self.RPN_proposal((rpn_cls_prob.data, rpn_bbox_pred.data, im_info,
cfg_key))
Proposal Layer有三个输入:softmax分支和regression分支的输出,加上im_info。其中im_info=[M,N,scale_factor],M和N为网络的输入尺寸,scale_factor为原图PxQ,resize到MxN的缩放信息。
Proposal Layer 执行过程如下:
- 得到初步的目标框,根据预测的偏移量对所有的anchors进行回归得到初步的目标框;
anchors = self._anchors.view(1, A, 4) + shifts.view(K, 1, 4)
anchors = anchors.view(1, K * A, 4).expand(batch_size, K * A, 4)
# Transpose and reshape predicted bbox transformations to get them
# into the same order as the anchors:
bbox_deltas = bbox_deltas.permute(0, 2, 3, 1).contiguous()
bbox_deltas = bbox_deltas.view(batch_size, -1, 4)
# Convert anchors into proposals via bbox transformations
proposals = bbox_transform_inv(anchors, bbox_deltas, batch_size)
- 删除超出图像边界的positive anchors;
# 2. clip predicted boxes to image
proposals = clip_boxes(proposals, im_info, batch_size)
- 对输入的positive softmax scores进行排序,选择前RPN_PRE_NMS_TOP_N个anchors;
# # 4. sort all (proposal, score) pairs by score from highest to lowest
_, order = torch.sort(scores_keep, 1, True)
if pre_nms_topN > 0 and pre_nms_topN < scores_keep.numel():
order_single = order_single[:pre_nms_topN]
proposals_single = proposals_single[order_single, :]
scores_single = scores_single[order_single].view(-1,1)
- 删除尺寸非常小的positive anchors;
- 对剩余的positive anchors进行NMS;
# 6. apply nms (e.g. threshold = 0.7)
# 7. take after_nms_topN (e.g. 300)
# 8. return the top proposals (-> RoIs top)
keep_idx_i = nms(torch.cat((proposals_single, scores_single), 1), nms_thresh, force_cpu=not cfg.USE_GPU_NMS)
keep_idx_i = keep_idx_i.long().view(-1)
if post_nms_topN > 0:
keep_idx_i = keep_idx_i[:post_nms_topN]
proposals_single = proposals_single[keep_idx_i, :]
scores_single = scores_single[keep_idx_i, :]
proposal layer输出的proposal其目标信息是相对于输入图像M×N而言的。
RoI Pooling
RoI Pooling层负责收集proposal,并计算出proposal对应的feature maps,然后输入到后续网络中。其有两个输入:
- 共享的feature maps;
- RPN输出的 proposal boxes(相对于网络输入M×N而言)
# define anchor target layer
self.RPN_anchor_target = _AnchorTargetLayer(self.feat_stride, self.anchor_scales, self.anchor_ratios)
def forward():
rpn_data = self.RPN_anchor_target((rpn_cls_score.data, gt_boxes, im_info, num_boxes))
使用RoI Pooling的原因:
由于RPN输出的proposal boxes的大小形状各异,而对于一个训练好的模型要求输入和输出必须是固定大小。针对形状各异的boxes,Faster R-CNN提出使用RoI Pooling解决该问题。
RoI Pooling的工作流程:
假设输入的feature map如下图所示: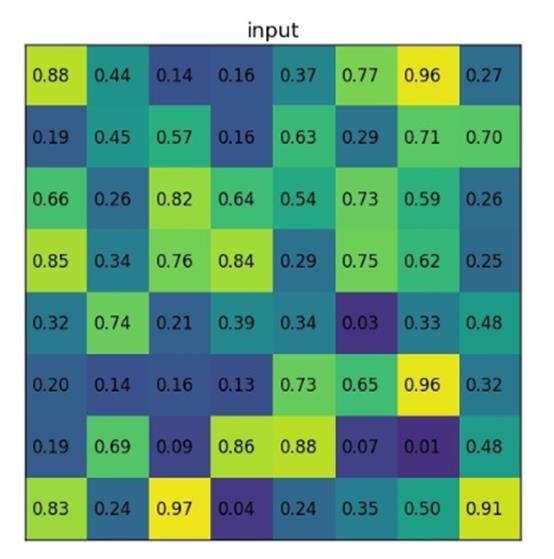
proposal boxes投影到feature map后的位置如图: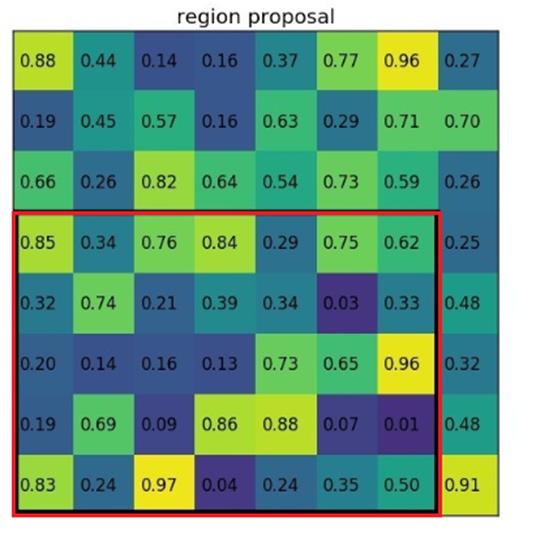
假设输出的是一个2×2的特征图,那么就将投影区域划分为2×2个sections,得到: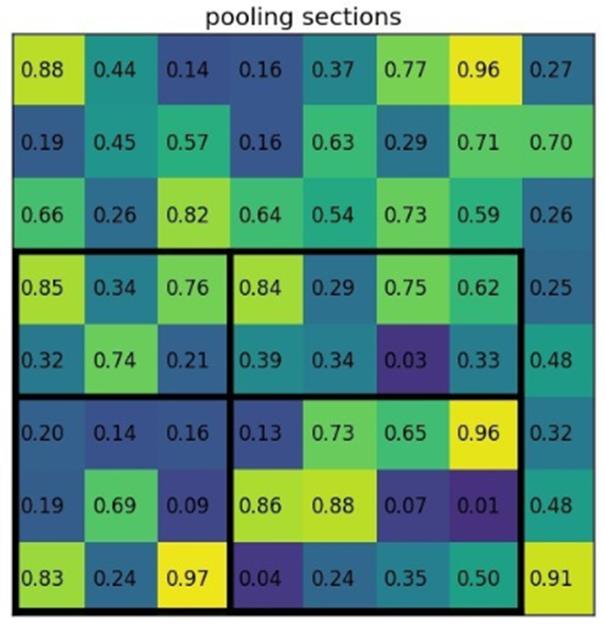
然后对每个section做max pooling,得到: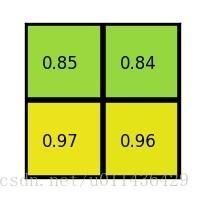
因此,RoI Pooling就是将大小不同的feature map池化成大小相同的feature map, 有利于输出到下一层网络中。
由于proposal的位置通常是模型回归得到的,一般是浮点数,而池化后的特征图要求尺寸固定,这个过程中存在两次量化:
- 将proposal边界量化为整数值坐标;
- 将量化后的边界区域平均分割为kxk个sections,对每个section的边界进行量化;
经过上述两次量化,此时候选框已经和最开始回归出来的位置有一定的偏差,这个偏差会影响检测准确度。
分类和回归
RoI Pooling输出的7×7大小的特征图,接着送入到一个Classifier模块中,然后通过Linear层和softmax计
目标检测Faster R-CNN+YOLO
目录
以上是关于目标检测Faster R-CNN浅析的主要内容,如果未能解决你的问题,请参考以下文章