智能湖仓架构实践:利用 Amazon Redshift 的流式摄取构建实时数仓
Posted 亚马逊云开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了智能湖仓架构实践:利用 Amazon Redshift 的流式摄取构建实时数仓相关的知识,希望对你有一定的参考价值。
Amazon Redshift 是一种快速、可扩展、安全且完全托管的云数据仓库,可以帮助用户通过标准 SQL 语言简单、经济地分析各类数据。相比其他任何云数据仓库,Amazon Redshift 可实现高达三倍的性能价格比。数万家客户正在借助 Amazon Redshift 每天处理 EB 级别的数据,借此为高性能商业智能(BI)报表、仪表板应用、数据探索和实时分析等分析工作负载提供强大动力。
我们很激动地为 Amazon Kinesis Data Streams 发布了 Amazon Redshift 流式摄取功能,借此用户无需事先将数据存储在 Amazon Simple Storage Service(Amazon S3)中,即可将 Kinesis 数据流摄取到云数据仓库中。流式摄取可以帮助用户以极低延迟,在几秒钟内将数百 MB 数据摄取到 Amazon Redshift 云数据仓库集群。
本文将介绍如何围绕 Amazon Redshift 云数据仓库创建 Kinesis 数据流,生成并加载流式数据,创建物化视图,并查询数据流并对结果进行可视化呈现。此外本文还讲介绍流式摄取的好处和常见用例。
云数据仓库有关流式摄取的需求
很多客户向我们反馈称想要将批处理分析能力进一步拓展为实时分析能力,并以低延迟高吞吐量的方式访问自己存储在数据仓库中的流式数据。此外,还有很多客户希望将实时分析结果与数据仓库中的其他数据源相结合,借此获得更丰富的分析结果。
Amazon Redshift 流式摄取的主要用例均具备这样的特征:用于处理不断生成的(流式)数据,并且需要在数据生成后很短的时间(延迟)里处理完成。从IoT设备到系统遥测,从公共事业服务到设备定位,数据来源五花八门。
在流式摄取功能发布前,如果希望从 Kinesis Data Steams 摄取实时数据,需要将数据暂存至 Amazon S3,然后使用 COPY 命令加载。这通常会产生数分钟的延迟,并且需要在从数据流加载数据的操作之上建立数据管道。但现在,用户已经可以直接从数据流摄取数据。
解决方案概述
Amazon Redshift 流式摄取可让用户直接连接到 Kinesis Data Streams,彻底消除了通过 Amazon S3 暂存数据并载入集群所导致的延迟和复杂性。借此,用户可以使用 SQL 命令连接并访问流式数据,并直接在数据流的基础上创建具体化试图,借此简化数据管道。物化视图亦可包含 ELT(提取、加载和转换)管道所需的 SQL 转换。
定义了物化视图后,即可刷新视图以查询最新流式数据。这意味着我们可以使用 SQL 对流式数据执行下游处理和转换,并且无需付出额外成本,随后即可使用原有的 BI 和分析工具进行实时分析。
Amazon Redshift 流式摄取会作为数据流的使用者来完成自己的工作,物化视图则可看作所要使用的流式数据的登陆区。刷新物化视图时,Amazon Redshift 计算节点会将每个数据分片分配给一个计算切片。每个计算切片会开始处理所分配数据分片中的数据,直到物化视图达到与数据流对等的程度。物化视图的第一次刷新可从数据流的 TRIM_HORIZON 中获取数据,后续刷新则可从上一次刷新所产生的最后一个 SEQUENCE_NUMBER 中读取数据,直到其状态与流式数据实现对等。整个流程如下图所示。

在 Amazon Redshift 中设置流式摄取需要执行两个步骤。首先,我们需要创建一个外部 Schema 以映射至 Kinesis Data Streams,随后需要创建一个物化视图以便从数据流中拉取数据。物化视图必须能够增量维护。
创建 Kinesis 数据流
首先我们需要创建接收流式数据的 Kinesis 数据流。
-
在 Amazon Kinesis 控制台中选择 Data streams。
-
选择 Create data stream。
-
为 Data stream name 输入
ev_stream_data。 -
为 Capacity mode 选择 On-demand。

-
按需提供其他配置以创建数据流。
使用 Kinesis Data Generator 生成流式数据
我们可以使用 Amazon Kinesis Data Generator(KDG)工具和下列模板,以聚合的方式生成 JSON 格式的数据:
"_id" : "random.uuid",
"clusterID": "random.number(
"min":1,
"max":50
)",
"connectionTime": "date.now("YYYY-MM-DD HH:mm:ss")",
"kWhDelivered": "commerce.price",
"stationID": "random.number(
"min":1,
"max":467
)",
"spaceID": "random.word-random.number(
"min":1,
"max":20
)",
"timezone": "America/Los_Angeles",
"userID": "random.number(
"min":1000,
"max":500000
)"
下图展示了 KDG 控制台中的模板。

加载参考数据
上一个步骤中,我们介绍了如何使用 Kinesis Data Generator 将聚合数据载入数据流。本节我们需要将与电动汽车充电站相关的参考数据载入到集群。
请从奥斯丁市开放数据门户下载插电式电动汽车充电站网络数据。将数据集中的经纬度数据拆分开,并将其载入到具备如下 Schema 的表中:
CREATE TABLE ev_station
(
siteid INTEGER,
station_name VARCHAR(100),
address_1 VARCHAR(100),
address_2 VARCHAR(100),
city VARCHAR(100),
state VARCHAR(100),
postal_code VARCHAR(100),
no_of_ports SMALLINT,
pricing_policy VARCHAR(100),
usage_access VARCHAR(100),
category VARCHAR(100),
subcategory VARCHAR(100),
port_1_connector_type VARCHAR(100),
voltage VARCHAR(100),
port_2_connector_type VARCHAR(100),
latitude DECIMAL(10, 6),
longitude DECIMAL(10, 6),
pricing VARCHAR(100),
power_select VARCHAR(100)
) DISTTYLE ALL创建物化视图
我们可以使用 SQL 从数据流中访问自己的数据,并直接在数据流的基础上创建物化视图,借此简化数据管道的搭建。为此请执行如下操作:
-
创建一个外部 Schema,以便将数据从 Kinesis Data Streams 映射至 Amazon Redshift 对象:
CREATE EXTERNAL SCHEMA evdata FROM KINESIS
IAM_ROLE 'arn:aws:iam::0123456789:role/redshift-streaming-role';-
创建一个 Amazon Identity and Access Management(IAM)角色(相关策略请参考流式摄取上手指南)。
随后即可创建用于使用流式数据的物化视图。我们可以选择使用 SUPER 数据类型来存储 JSON 格式的有效载荷,或使用 Amazon Redshift JSON 函数将JSON数据解析为单独的列。本文我们将使用第二种方法,因为 Schema 已经定义好了。
-
创建物化视图,使其根据数据流中的 UUID 值进行分布,并按
approximatearrivaltimestamp值排序:
CREATE MATERIALIZED VIEW ev_station_data_extract DISTKEY(5) sortkey(1) AS
SELECT approximatearrivaltimestamp,
partitionkey,
shardid,
sequencenumber,
json_extract_path_text(from_varbyte(data, 'utf-8'),'_id')::character(36) as ID,
json_extract_path_text(from_varbyte(data, 'utf-8'),'clusterID')::varchar(30) as clusterID,
json_extract_path_text(from_varbyte(data, 'utf-8'),'connectionTime')::varchar(20) as connectionTime,
json_extract_path_text(from_varbyte(data, 'utf-8'),'kWhDelivered')::DECIMAL(10,2) as kWhDelivered,
json_extract_path_text(from_varbyte(data, 'utf-8'),'stationID')::DECIMAL(10,2) as stationID,
json_extract_path_text(from_varbyte(data, 'utf-8'),'spaceID')::varchar(100) as spaceID,
json_extract_path_text(from_varbyte(data, 'utf-8'),'timezone')::varchar(30) as timezone,
json_extract_path_text(from_varbyte(data, 'utf-8'),'userID')::varchar(30) as userID
FROM evdata."ev_stream_data";-
刷新这个物化视图:
REFRESH MATERIALIZED VIEW ev_station_data_extract;目前的预览版中,物化视图不会自动刷新,因此我们需要在 Amazon Redshift 中计划一个查询,每分钟刷新一次物化视图。相关说明请参考在 Amazon Redshift 数据仓库中计划 SQL 查询。
查询数据流
随后即可查询刷新后的物化视图以查看使用情况统计数据:
SELECT to_timestamp(connectionTime, 'YYYY-MM-DD HH24:MI:SS') as connectiontime
,SUM(kWhDelivered) AS Energy_Consumed
,count(distinct userID) AS #Users
from ev_station_data_extract
group by to_timestamp(connectionTime, 'YYYY-MM-DD HH24:MI:SS')
order by 1 desc;结果如下表所示。

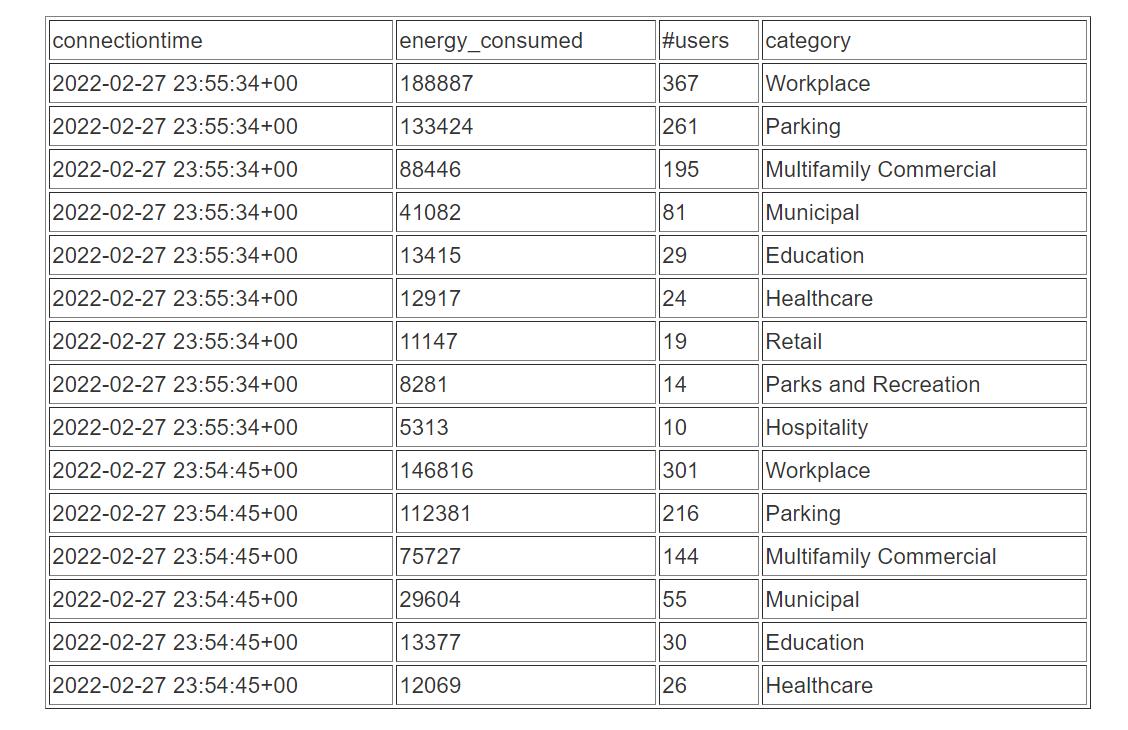
接下来,我们可以将物化视图与参考数据联接起来,进而分析过去5分钟里充电站的使用量数据,并按照充电站的类型进行细分:
SELECT to_timestamp(connectionTime, 'YYYY-MM-DD HH24:MI:SS') as connectiontime
,SUM(kWhDelivered) AS Energy_Consumed
,count(distinct userID) AS #Users
,st.category
from ev_station_data_extract ext
join ev_station st on
ext.stationID = st.siteid
where approximatearrivaltimestamp > current_timestamp -interval '5 minutes'
group by to_timestamp(connectionTime, 'YYYY-MM-DD HH24:MI:SS'),st.category
order by 1 desc, 2 desc结果如下表所示。
结果的可视化呈现
我们可以使用 Amazon QuickSight 设置一个简单的可视化呈现。相关说明请参考快速上手指南:使用样本数据创建一个具备单一可视化结果的 Amazon QuickSight 分析。
我们在 QuickSight 中创建了一个数据集,借此将物化视图与充电站参考数据联接在一起。

随后创建一个可以显示耗电量以及连接用户随时间变化的仪表板。该仪表板还会按照类别在地图上显示对应的地点。

流式摄取所带来的好处
本节我们将介绍流式摄取所能带来的一些好处。
高吞吐量低延迟
Amazon Redshift 能以每秒数 GB 的速度接收并处理来自 Kinesis Data Streams 的数据(吞吐量取决于数据流中数据分片的数量以及 Amazon Redshift 集群配置)。借此我们将能以低延迟高带宽的方式使用流式数据,进而在几秒钟之内从数据中获得见解,不再像以往那样等待数分钟。
如上文所述,Amazon Redshift 直接摄取并拉取的方法最大的优势在于延迟更低,通常只需数秒。这与创建流程以使用流式数据,将数据暂存到 Amazon S3,随后运行 COPY 命令将数据载入 Amazon Redshift 的做法形成了鲜明的对比。由于数据处理过程涉及多个环节,后一种方法往往会产生数分钟的延迟。
设置简单
流式摄取方法可以轻松上手。Amazon Redshift 中的所有设置与配置均可使用 SQL 完成,绝大部分云数据仓库的用户对此已经非常熟悉了。随后,无需管理复杂的管道,即可在几秒钟内获得实时见解。Amazon Redshift 和 Kinesis Data Streams 是完全托管的,用户无需管理基础结构即可运行自己的流式应用程序。
提高生产力
用户无需学习新的技能或语言,即可在 Amazon Redshift 中使用熟悉的 SQL 技能针对流失数据进行丰富的分析工作。此外还可以创建其他物化视图,或针对物化视图创建视图,借此直接在 Amazon Redshift 中使用 SQL 完成大部分ELT数据管道转换工作。
流式摄取用例
通过对流式数据进行近乎实时的分析,很多用例和垂直行业特定应用将变为可能。下文列举的仅仅是诸多用例中的一部分:
-
改善游戏体验:通过分析来自玩家的实时数据,即可专注于游戏转化率、玩家留存率并优化游戏体验。
-
分析在线广告的点击流用户数据:每个客户在一次会话中平均会访问几十个网站,然而营销人员通常只能分析自己网站的访问数据。我们可以分析数据仓库中摄入的已授权点击流数据,借此评估客户的足迹和行为,并即时为客户投放更有针对性的广告。
-
通过流式 POS 数据进行实时零售分析:我们可以访问并可视化所有全球销售点(POS)零售交易数据,借此进行实时分析、报表并可视化。
-
提供实时的应用程序洞察力:通过访问并分析来自应用程序日志文件和网络日志的流式数据,开发者和工程师可以围绕问题进行实时排错,打造更优质的产品,并通过警报提醒采取预防性措施。
-
实时分析 IoT 数据:我们可以将 Amazon Redshift 流式摄取与 Amazon Kinesis 服务配合使用来构建实时应用程序,例如设备状态和属性检测,如位置和传感器数据、应用程序监控、欺诈检测、实时仪表板等。我们可以使用 Kinesis Data Streams 摄取流式数据,使用 Amazon Kinesis Data Analytics 进行处理,随后使用 Kinesis Data Streams 以极低的端到端延迟将结果发送给任何数据存储或应用程序。
总结
本文介绍了如何创建 Amazon Redshift 物化视图,进而使用 Amazon Redshift 流式摄取功能从 Kinesis 数据流摄取数据。借助这个全新功能,我们可以轻松构建并维护数据管道,借此以低延迟、高吞吐量的方式摄取并分析流式数据。
流式摄取功能目前为预览版,所有提供了 Amazon Redshift 服务的亚马逊云科技区域均已可以使用该功能。若要上手使用 Amazon Redshift 流式摄取,请在您的当前栈上预配一个 Amazon Redshift 集群,并确认您的集群版本不低于1.0.35480。
详细信息请参考流式摄取(预览),此外也可查看 YouTube 上的使用 Amazon Redshift 流式摄取进行实时分析演示。同时亚马逊云科技现代数据架构给你更多思路,点击查看。
本篇作者
Sam Selvan
亚马逊云科技资深解决方案架构师。
汽车之家基于 Flink + Iceberg 的湖仓一体架构实践
简介:由汽车之家实时计算平台负责人邸星星在 4 月 17 日上海站 Meetup 分享的,基于 Flink + Iceberg 的湖仓一体架构实践。
内容简要:一、数据仓库架构升级的背景
二、基于 Iceberg 的湖仓一体架构实践
三、总结与收益
四、后续规划
GitHub 地址
https://github.com/apache/flink
欢迎大家给 Flink 点赞送 star~
一、数据仓库架构升级的背景
1. 基于 Hive 的数据仓库的痛点
原有的数据仓库完全基于 Hive 建造而成,主要存在三大痛点:
痛点一:不支持 ACID
1)不支持 Upsert 场景;
2)不支持 Row-level delete,数据修正成本高。
痛点二:时效性难以提升
1)数据难以做到准实时可见;
2)无法增量读取,无法实现存储层面的流批统一;
3)无法支持分钟级延迟的数据分析场景。
痛点三:Table Evolution
1)写入型 Schema,对 Schema 变更支持不好;
2)Partition Spec 变更支持不友好。
2. Iceberg 关键特性
Iceberg 主要有四大关键特性:支持 ACID 语义、增量快照机制、开放的表格式和流批接口支持。
支持 ACID 语义
- 不会读到不完整的 Commit;
- 基于乐观锁支持并发 Commit;
- Row-level delete,支持 Upsert。
增量快照机制
- Commit 后数据即可见(分钟级);
- 可回溯历史快照。
开放的表格式
- 数据格式:parquet、orc、avro
- 计算引擎:Spark、Flink、Hive、Trino/Presto
流批接口支持
- 支持流、批写入;
- 支持流、批读取。
二、基于 Iceberg 的湖仓一体架构实践
湖仓一体的意义就是说我不需要看见湖和仓,数据有着打通的元数据的格式,它可以自由的流动,也可以对接上层多样化的计算生态。
——贾扬清(阿里云计算平台高级研究员)
1. Append 流入湖的链路

上图为日志类数据入湖的链路,日志类数据包含客户端日志、用户端日志以及服务端日志。这些日志数据会实时录入到 Kafka,然后通过 Flink 任务写到 Iceberg 里面,最终存储到 HDFS。
2. Flink SQL 入湖链路打通
我们的 Flink SQL 入湖链路打通是基于 “Flink 1.11 + Iceberg 0.11” 完成的,对接 Iceberg Catalog 我们主要做了以下内容:
1)Meta Server 增加对 Iceberg Catalog 的支持;
2)SQL SDK 增加 Iceberg Catalog 支持。
然后在这基础上,平台开放 Iceberg 表的管理功能,使得用户可以自己在平台上建 SQL 的表。
3. 入湖 - 支持代理用户
第二步是内部的实践,对接现有预算体系、权限体系。
因为之前平台做实时作业的时候,平台都是默认为 Flink 用户去运行的,之前存储不涉及 HDFS 存储,因此可能没有什么问题,也就没有思考预算划分方面的问题。
但是现在写 Iceberg 的话,可能就会涉及一些问题。比如数仓团队有自己的集市,数据就应该写到他们的目录下面,预算也是划到他们的预算下,同时权限和离线团队账号的体系打通。

如上所示,这块主要是在平台上做了代理用户的功能,用户可以去指定用哪个账号去把这个数据写到 Iceberg 里面,实现过程主要有以下三个。
- 增加 Table 级别配置:'iceberg.user.proxy' = 'targetUser’
1)启用 Superuser
2)团队账号鉴权

- 访问 HDFS 时启用代理用户:

- 访问 Hive Metastore 时指定代理用户
1)参考 Spark 的相关实现:
org.apache.spark.deploy.security.HiveDelegationTokenProvider
2)动态代理 HiveMetaStoreClient,使用代理用户访问 Hive metastore
4. Flink SQL 入湖示例
DDL + DML

5. CDC 数据入湖链路

如上所示,我们有一个 AutoDTS 平台,负责业务库数据的实时接入。我们会把这些业务库的数据接入到 Kafka 里面,同时它还支持在平台上配置分发任务,相当于把进 Kafka 的数据分发到不同的存储引擎里,在这个场景下是分发到 Iceberg 里。
6. Flink SQL CDC 入湖链路打通
下面是我们基于 “Flink1.11 + Iceberg 0.11” 支持 CDC 入湖所做的改动:
- 改进 Iceberg Sink:
Flink 1.11 版本为 AppendStreamTableSink,无法处理 CDC 流,修改并适配。
- 表管理
1)支持 Primary key(PR1978)
2)开启 V2 版本:'iceberg.format.version' = '2'
7. CDC 数据入湖
1. 支持 Bucket
Upsert 场景下,需要确保同一条数据写入到同一 Bucket 下,这又如何实现?
目前 Flink SQL 语法不支持声明 bucket 分区,通过配置的方式声明 Bucket:
'partition.bucket.source'='id', // 指定 bucket 字段
'partition.bucket.num'='10', // 指定 bucket 数量
2. Copy-on-write sink
做 Copy-on-Write 的原因是原本社区的 Merge-on-Read 不支持合并小文件,所以我们临时去做了 Copy-on-write sink 的实现。目前业务一直在测试使用,效果良好。

上方为 Copy-on-Write 的实现,其实跟原来的 Merge-on-Read 比较类似,也是有 StreamWriter 多并行度写入和 FileCommitter 单并行度顺序提交。
在 Copy-on-Write 里面,需要根据表的数据量合理设置 Bucket 数,无需额外做小文件合并。
- StreamWriter 在 snapshotState 阶段多并行度写入
1)增加 Buffer;
2)写入前需要判断上次 checkpoint 已经 commit 成功;
3)按 bucket 分组、合并,逐个 Bucket 写入。
- FileCommitter 单并行度顺序提交
1)table.newOverwrite()
2)Flink.last.committed.checkpoint.id

8. 示例 - CDC 数据配置入湖

如上图所示,在实际使用中,业务方可以在 DTS 平台上创建或配置分发任务即可。
实例类型选择 Iceberg 表,然后选择目标库,表明要把哪个表的数据同步到 Iceberg 里,然后可以选原表和目标表的字段的映射关系是什么样的,配置之后就可以启动分发任务。启动之后,会在实时计算平台 Flink 里面提交一个实时任务,接着用 Copy-on-write sink 去实时地把数据写到 Iceberg 表里面。

9. 入湖其他实践
实践一:减少 empty commit
- 问题描述:
在上游 Kafka 长期没有数据的情况下,每次 Checkpoint 依旧会生成新的 Snapshot,导致大量的空文件和不必要的 Snapshot。
- 解决方案(PR - 2042):
增加配置 Flink.max-continuousempty-commits,在连续指定次数 Checkpoint 都没有数据后才真正触发 Commit,生成 Snapshot。
实践二:记录 watermark
- 问题描述:
目前 Iceberg 表本身无法直接反映数据写入的进度,离线调度难以精准触发下游任务。
- 解决方案( PR - 2109 ):
在 Commit 阶段将 Flink 的 Watermark 记录到 Iceberg 表的 Properties 中,可直观的反映端到端的延迟情况,同时可以用来判断分区数据完整性,用于调度触发下游任务。
实践三:删表优化
- 问题描述:
删除 Iceberg 可能会很慢,导致平台接口相应超时。因为 Iceberg 是面向对象存储来抽象 IO 层的,没有快速清除目录的方法。
- 解决方案:
扩展 FileIO,增加 deleteDir 方法,在 HDFS 上快速删除表数据。
10. 小文件合并及数据清理
定期为每个表执行批处理任务(spark 3),分为以下三个步骤:
1. 定期合并新增分区的小文件:
rewriteDataFilesAction.execute(); 仅合并小文件,不会删除旧文件。
2. 删除过期的 snapshot,清理元数据及数据文件:
table.expireSnapshots().expireOld erThan(timestamp).commit();
3. 清理 orphan 文件,默认清理 3 天前,且无法触及的文件:
removeOrphanFilesAction.older Than(timestamp).execute();
11. 计算引擎 – Flink
Flink 是实时平台的核心计算引擎,目前主要支持数据入湖场景,主要有以下几个方面的特点。
- 数据准实时入湖:
Flink 和 Iceberg 在数据入湖方面集成度最高,Flink 社区主动拥抱数据湖技术。
- 平台集成:
AutoStream 引入 IcebergCatalog,支持通过 SQL 建表、入湖 AutoDTS 支持将 MySQL、SQLServer、TiDB 表配置入湖。
- 流批一体:
在流批一体的理念下,Flink 的优势会逐渐体现出来。
12. 计算引擎 – Hive
Hive 在 SQL 批处理层面 Iceberg 和 Spark 3 集成度更高,主要提供以下三个方面的功能。
- 定期小文件合并及 meta 信息查询:
SELECT * FROM prod.db.table.history 还可查看 snapshots, files, manifests。
- 离线数据写入:
1)Insert into 2)Insert overwrite 3)Merge into
- 分析查询:
主要支持日常的准实时分析查询场景。
13. 计算引擎 – Trino/Presto
AutoBI 已经和 Presto 集成,用于报表、分析型查询场景。
- Trino
1)直接将 Iceberg 作为报表数据源
2)需要增加元数据缓存机制:https://github.com/trinodb/trino/issues/7551
- Presto
14. 踩过的坑
1. 访问 Hive Metastore 异常
问题描述:HiveConf 的构造方法的误用,导致 Hive 客户端中声明的配置被覆盖,导致访问 Hive metastore 时异常
解决方案(PR-2075):修复 HiveConf 的构造,显示调用 addResource 方法,确保配置不会被覆盖:hiveConf.addResource(conf);
2.Hive metastore 锁未释放
问题描述:“CommitFailedException: Timed out after 181138 ms waiting for lock xxx.” 原因是 hiveMetastoreClient.lock 方法,在未获得锁的情况下,也需要显示 unlock,否则会导致上面异常。
解决方案(PR-2263):优化 HiveTableOperations#acquireLock 方法,在获取锁失败的情况下显示调用 unlock 来释放锁。
3. 元数据文件丢失
问题描述:Iceberg 表无法访问,报 “NotFoundException Failed to open input stream for file : xxx.metadata.json”
解决方案(PR-2328):当调用 Hive metastore 更新 iceberg 表的 metadata_location 超时后,增加检查机制,确认元数据未保存成功后再删除元数据文件。
三、收益与总结
1. 总结
通过对湖仓一体、流批融合的探索,我们分别做了总结。
- 湖仓一体
1)Iceberg 支持 Hive Metastore;
2)总体使用上与 Hive 表类似:相同数据格式、相同的计算引擎。
- 流批融合
准实时场景下实现流批统一:同源、同计算、同存储。
2. 业务收益
- 数据时效性提升:
入仓延迟从 2 小时以上降低到 10 分钟以内;算法核心任务 SLA 提前 2 小时完成。
- 准实时的分析查询:
结合 Spark 3 和 Trino,支持准实时的多维分析查询。
- 特征工程提效:
提供准实时的样本数据,提高模型训练时效性。
- CDC 数据准实时入仓:
可以在数仓针对业务表做准实时分析查询。
3. 架构收益 - 准实时数仓

上方也提到了,我们支持准实时的入仓和分析,相当于是为后续的准实时数仓建设提供了基础的架构验证。准实时数仓的优势是一次开发、口径统一、统一存储,是真正的批流一体。劣势是实时性较差,原来可能是秒级、毫秒级的延迟,现在是分钟级的数据可见性。
但是在架构层面上,这个意义还是很大的,后续我们能看到一些希望,可以把整个原来 “T + 1” 的数仓,做成准实时的数仓,提升数仓整体的数据时效性,然后更好地支持上下游的业务。
四、后续规划
1. 跟进 Iceberg 版本
全面开放 V2 格式,支持 CDC 数据的 MOR 入湖。
2. 建设准实时数仓
基于 Flink 通过 Data pipeline 模式对数仓各层表全面提速。
3. 流批一体
随着 upsert 功能的逐步完善,持续探索存储层面流批一体。
4. 多维分析
基于 Presto/Spark3 输出准实时多维分析。
原文链接:https://developer.aliyun.com/article/784553?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
以上是关于智能湖仓架构实践:利用 Amazon Redshift 的流式摄取构建实时数仓的主要内容,如果未能解决你的问题,请参考以下文章
汽车之家:基于 Flink + Iceberg 的湖仓一体架构实践
汽车之家基于 Flink + Iceberg 的湖仓一体架构实践