视频博文结合的教程:用nodejs实现简单的爬虫
Posted maorongmaomao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视频博文结合的教程:用nodejs实现简单的爬虫相关的知识,希望对你有一定的参考价值。
先来段求分小视频:
https://www.iesdouyin.com/share/video/6550631947750608142/?region=CN&mid=6550632036246555405&titleType=title×tamp=1525407578&utm_campaign=client_share&app=aweme&utm_medium=ios&iid=30176260384&utm_source=qq&tt_from=mobile_qq&utm_source=mobile_qq&utm_medium=aweme_ios&utm_campaign=client_share&uid=92735989673&did=30176260384
本文的教学视频地址:
https://v.qq.com/x/page/b0643tut4ze.html
前言
本喵最近工作中需要使用node,并也想晋升为全栈工程师,所以开始了node学习之旅,在学习过程中,
我会总结一些实用的例子,做成博文和视频教程,以实例形式来理解体会node的用法,所以跟小猫一起由浅及深的学node吧!
近期都会是些基础文章,主要用来了解node的各种功能,非常适合对node有所了解但没有开发node基础的前端工程师,
等基础掌握后,后续会进行进阶的探索和总结哟
本文将以抓取百度搜索结果中关键词的相关搜索为例子,教会大家以nodejs制作最简单的爬虫:
将使用的node模块及属性介绍:
request:
用于发送页面请求,抓取页面代码
GET请求

cheerio:
cheerio 是一个 jQuery Core 的子集,其实现了 jQuery Core 中浏览器无关的 DOM 操作 API:
本例子中将使用load方法,以下是一个简单的示例:
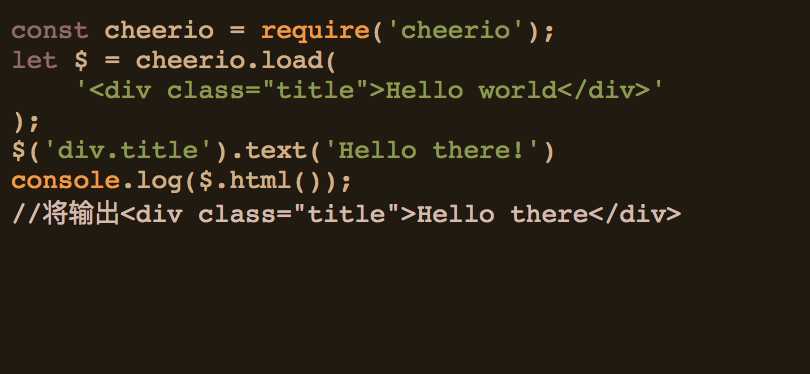
express:
基于Node.js 平台,快速、开放、极简的 web 开发框架,这里主要用来做简单的路由功能,就不做详细介绍了,主要是用了get,具体可以参考官网。
具体实现:
1.首先,我们要使用express搭建简单的node服务
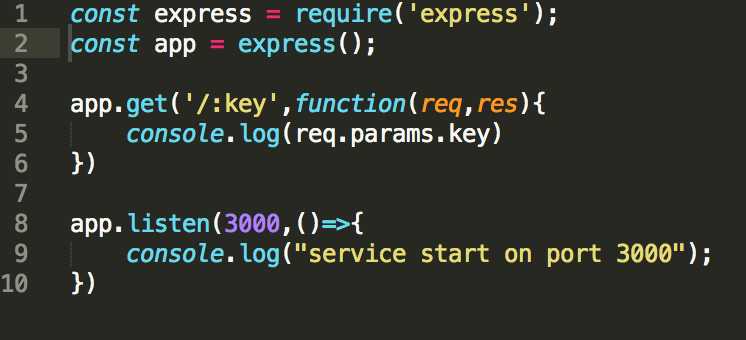
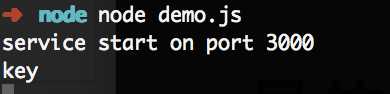
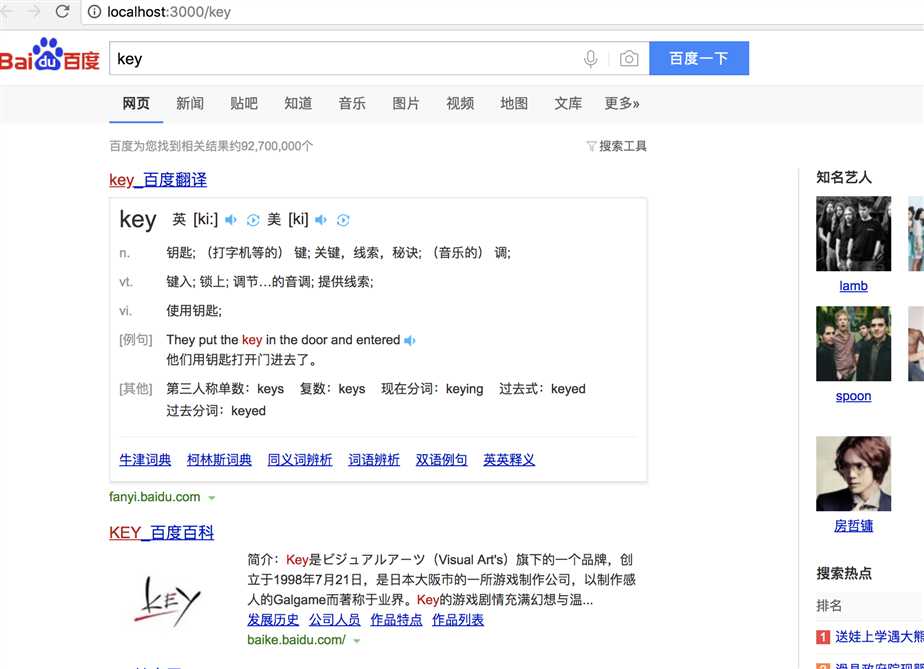
使用命令行运行node demo.js,并在浏览器中访问 localhost:3000/key 运行结果为
2. 使用request实现页面抓取功能
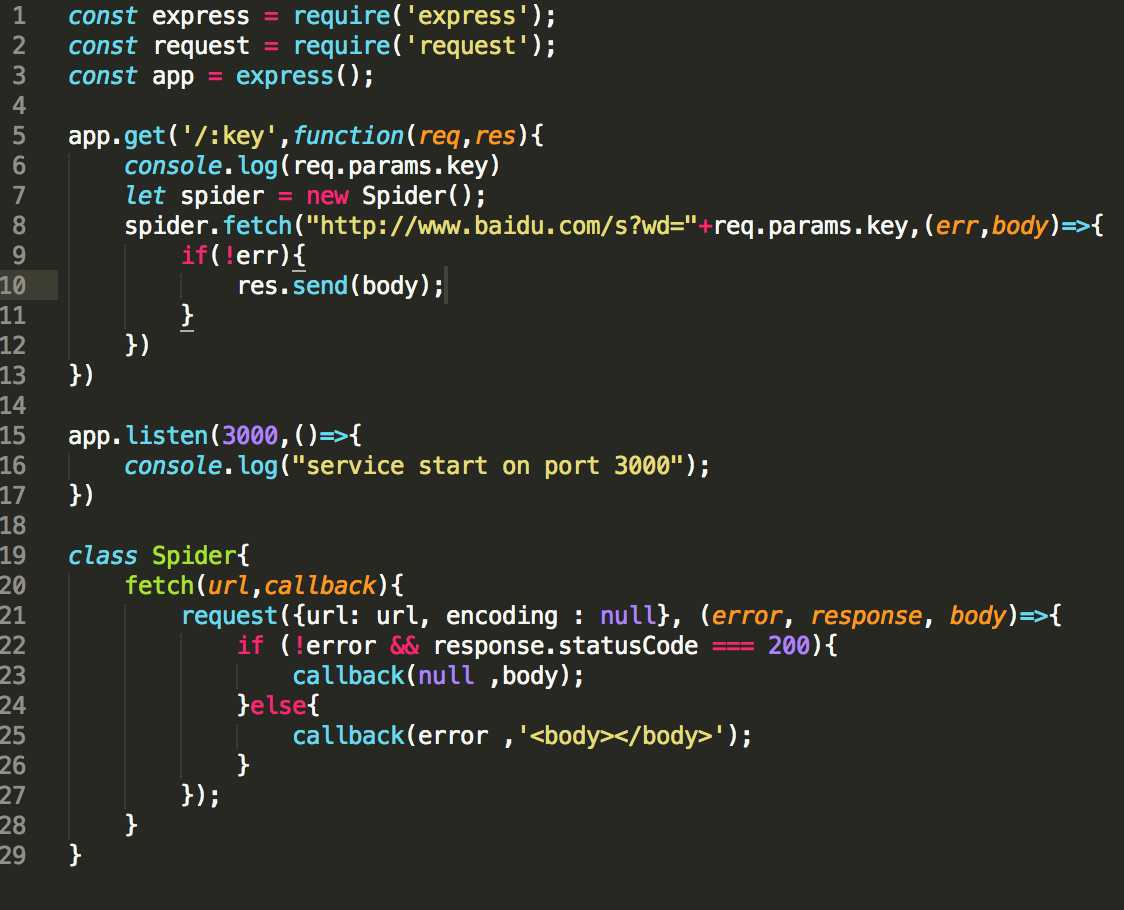
使用命令行运行node demo.js,并在浏览器中访问 localhost:3000/key 运行结果为
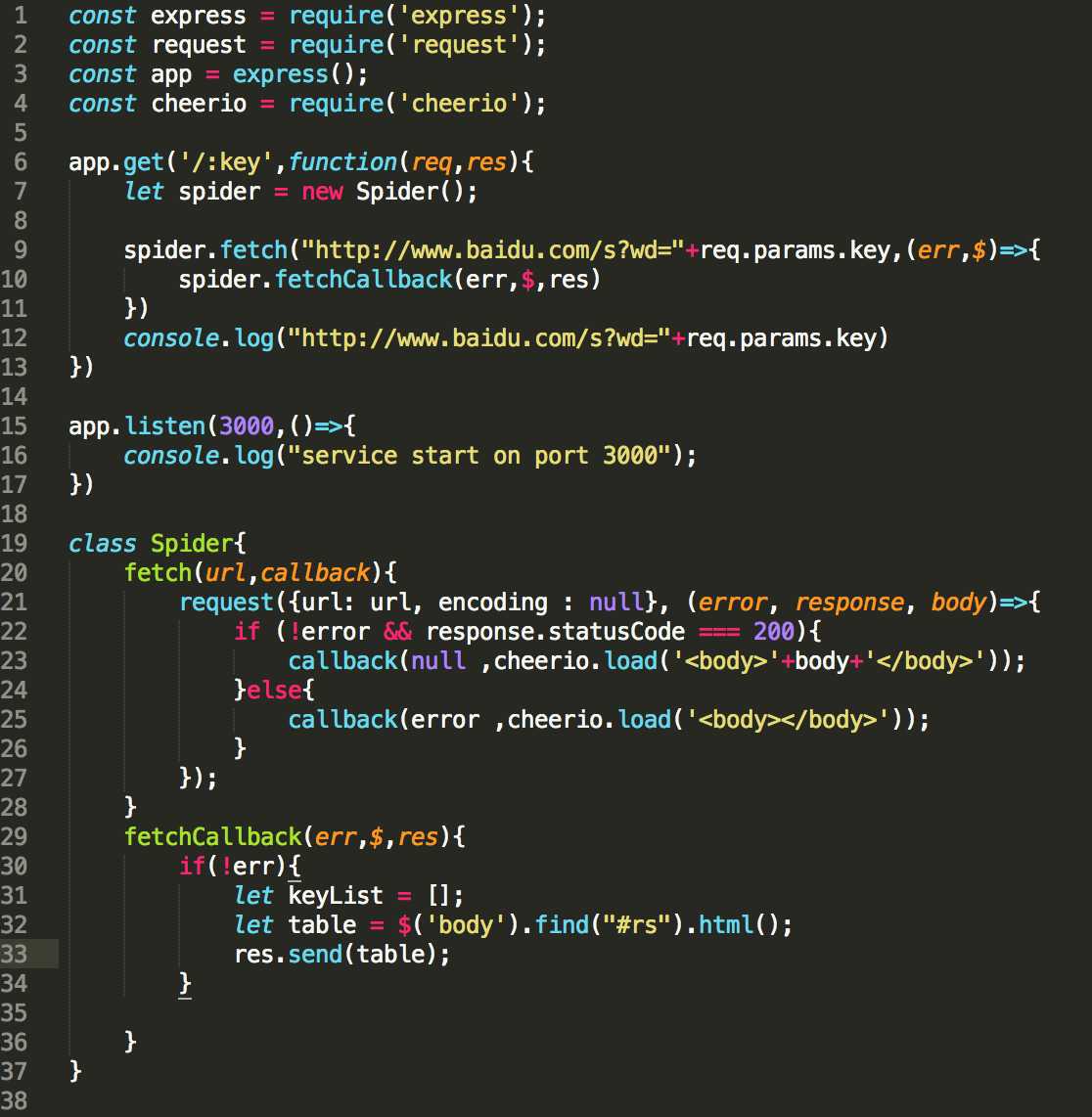
3.使用cheerio将页面代码解析为jquery格式,并用jQuery语法找到抓取的内容位置,这样这个爬虫就实现了!
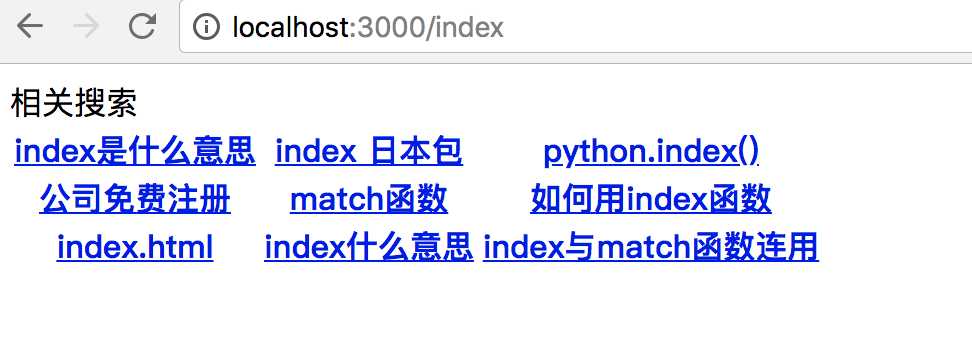
使用命令行运行node demo.js,并在浏览器中访问 localhost:3000/index 运行结果为
tips:
有些网站不是utf-8编码模式,这时可以使用iconv-lite来解除gb2312的乱码问题
当然各个网站都有反爬虫功能,可以通过 研究怎么模拟一个正常用户的请来规避部分问题(百度的中文搜索也会被屏蔽)
本文只是个入门,后序有机会将和大家详细讨论进阶版
谢谢大家的关注
以上是关于视频博文结合的教程:用nodejs实现简单的爬虫的主要内容,如果未能解决你的问题,请参考以下文章