SpringBoot集成Kafka实战学习笔记
Posted 艾-普-西-隆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SpringBoot集成Kafka实战学习笔记相关的知识,希望对你有一定的参考价值。
本篇只讲实战,有关kafka的基本知识请自行查找并学习,之后再看本篇。
目录
基本使用
项目结构如下:
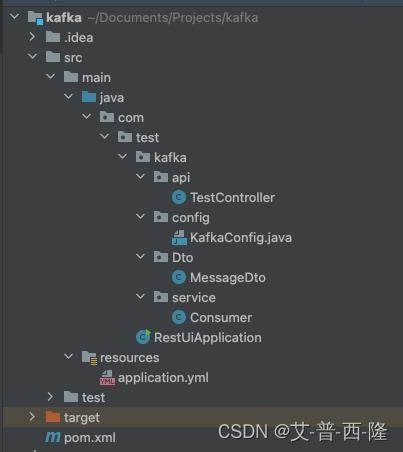
pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>kafka</artifactId>
<version>1.0-SNAPSHOT</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.0.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.2.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>7.6.0</version>
<scope>compile</scope>
</dependency>
</dependencies>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
</project>
RestUiApplication。
注意exclude的配置:因为该Project没有数据源,为了不报错,不让springboot主动扫描DataSource。
package com.test;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration;
import org.springframework.boot.autoconfigure.orm.jpa.HibernateJpaAutoConfiguration;
@SpringBootApplication(exclude=DataSourceAutoConfiguration.class, HibernateJpaAutoConfiguration.class)
public class RestUiApplication
public static void main(String[] args)
SpringApplication.run(RestUiApplication.class, args);
application.yml
server:
port: 8089
servlet:
context-path: /kafka
spring:
kafka:
bootstrap-servers: localhost:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: group1
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
missing-topics-fatal: false本地启动的kafka,默认的服务器地址是localhost:9092,根据需要可以自行修改该配置。
producer表示生产者,只配置了key和value的编码方式。
consumer表示消费者,配置了消费者组group,key和value的解码方式。
missing-topics-fatal设置为false,表示当kafka启动的时候如果未找到对应topic不报错。
Consumer类
监听kafka1的topic:
package com.test.kafka.service;
import lombok.extern.slf4j.Slf4j;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Service;
@Service
@Slf4j
public class Consumer
@KafkaListener(topics = "kafka1")
public void consumer1(String msg)
log.info("消费" + msg);
TestController
模拟生产者,每发送一次请求向topic=kafka1发送一条数据,数据的内容只是简单的一个字符串:
package com.test.kafka.api;
import com.test.kafka.Dto.MessageDto;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
@Slf4j
public class TestController
@Autowired
KafkaTemplate<String, Object> kafkaTemplate;
@PostMapping("/send")
@ResponseBody
public void send(String msg)
kafkaTemplate.send("kafka1", msg);
启动kafka,查看状态。进入kafka的bin目录,运行以下命令:
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 -group group1 --describe

可以看到显示group1不存在。
启动本项目,可以看到日志显示group1已经建立,并且消费者也已经加入group:

再次查看kafka状态:

group1已经存在,并且已经能看到消费者id。
现在发送一条消息到kafka:
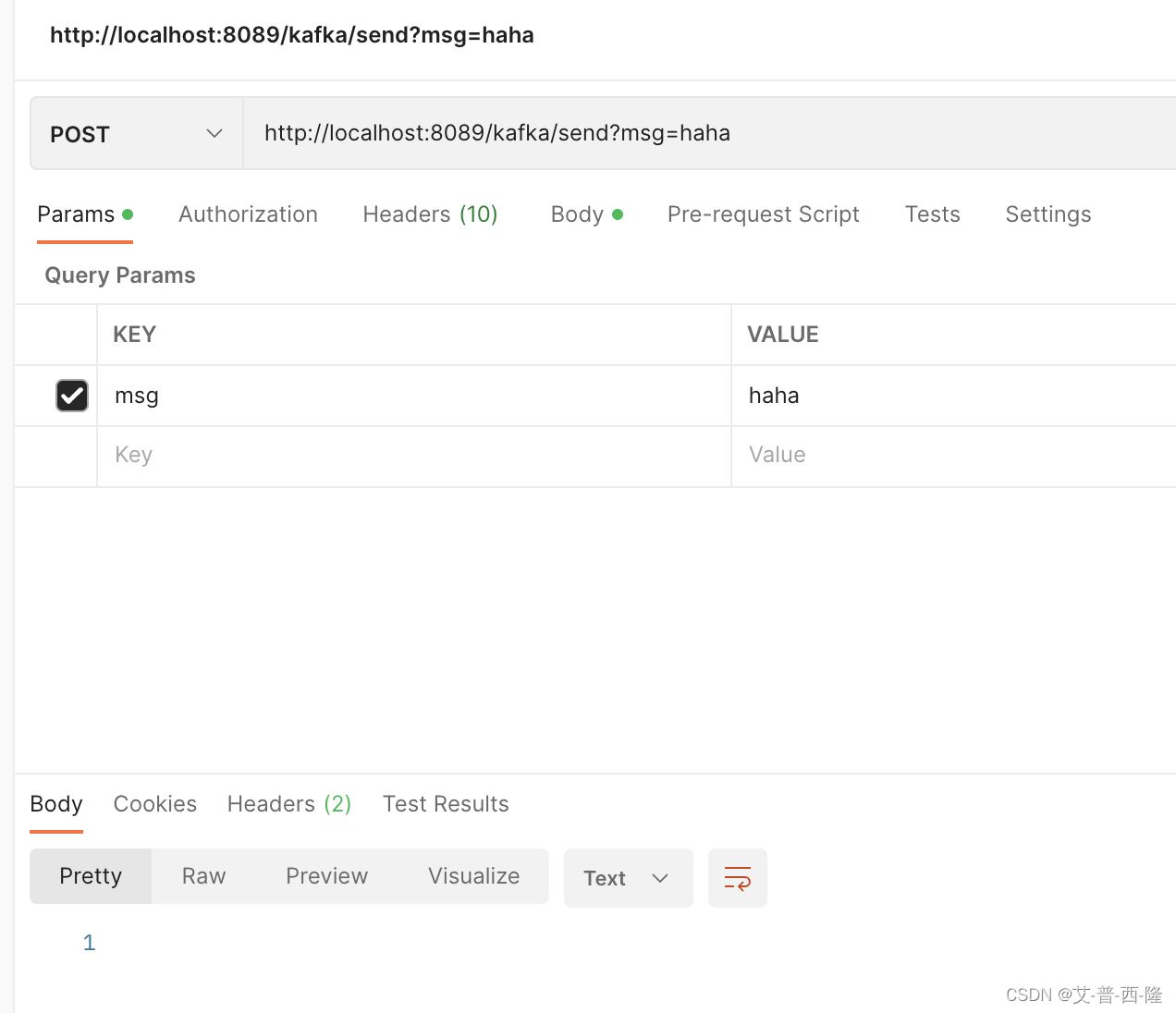
查看项目日志,可以看到正确获取并消费了消息:

再次查看kafka状态,current-offset和log-end-offset已经更新为1。

(current-offset表示当前已消费消息的最大位置,log-end-offset表示队列里最新消息的位置,lag表示二者的差。如果lag为0,且两个offset相等,说明队列里的所有消息都已经被消费掉了。如果current-offset小于log-end-offset,表示队列里还有消息未被消费。)
以上是最基本的kafka消息队列例子,下面我们看点有意思的。
传递复杂消息对象。
上面例子里的消息真的是字面意思的“消息”:一段字符串。如果我们想发送的消息是复杂对象怎么办?比如我想往kafka消息队列里放入以下对象,应该怎么操作?
package com.test.kafka.Dto;
import lombok.Data;
@Data
public class MessageDto
int id;
String msg;
首先,修改红框中的配置,将生产者和消费者的value编解码改成json。
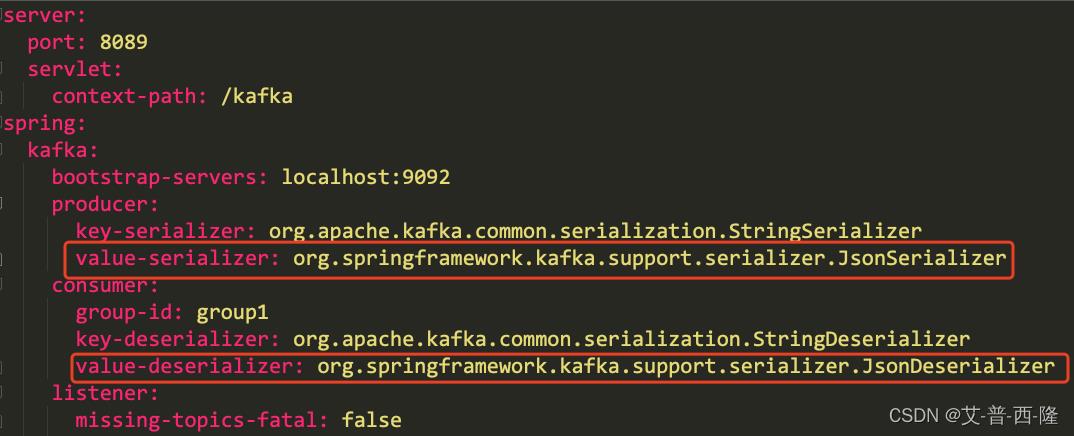
然后修改生产者的代码,注意这里的kafka模板的value一定设置为Object,这样代码才能正常运行。并且将发送的内容由字符串改为了MessageDto对象。
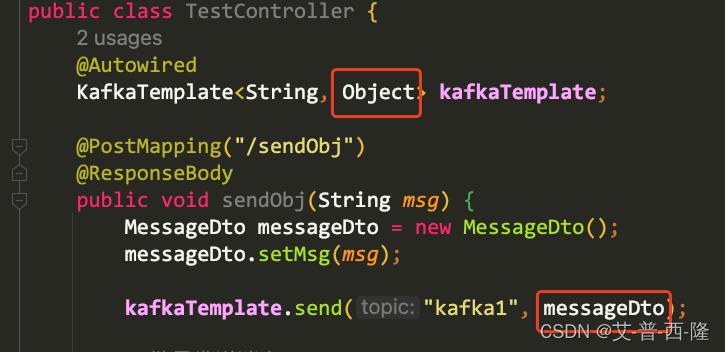 修改消费者的代码,注意入参也从字符串改为了对象:
修改消费者的代码,注意入参也从字符串改为了对象:
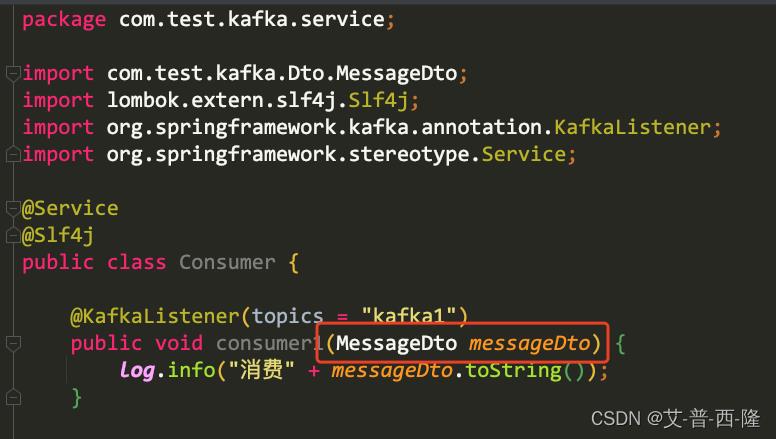
现在我们先清空一下kafka的topic中的数据,便于查看:

现在重新启动项目,并调用接口:
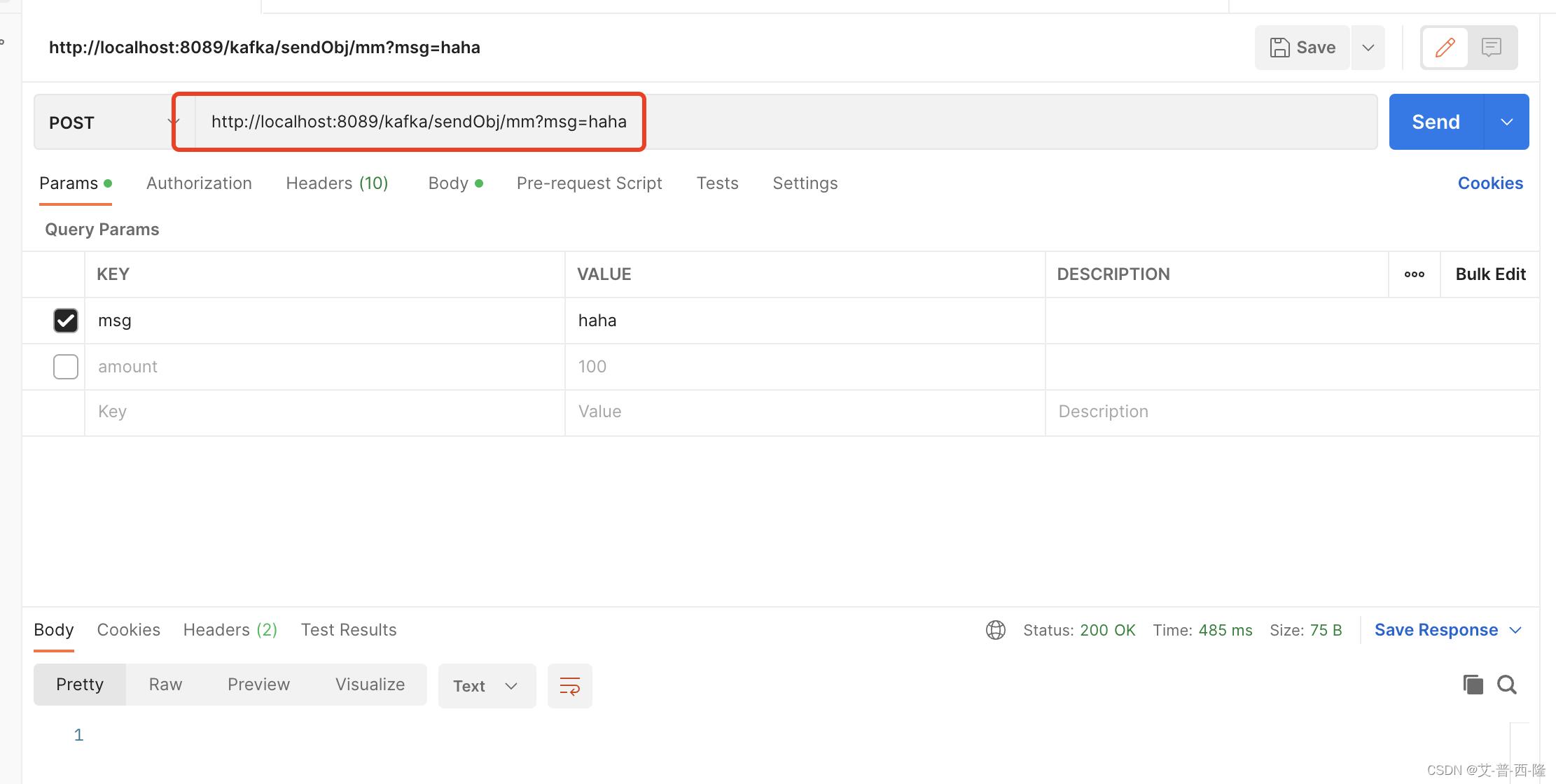
虽然postman显示接口调用成功,但是项目却抛错了,仔细查看错误日志:

大致意思是说kafka不信任我们要传递的对象类型,因此这里还有非常重要的一步,将我们要传递的对象加入到kafka的安全配置中。
spring:
kafka:
bootstrap-servers: localhost:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
consumer:
properties:
spring:
json:
trusted:
packages: com.test.kafka.Dto #要传递的实体类就在这个包下面
group-id: group1
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
listener:
missing-topics-fatal: false再次运行代码并调用接口,可以看到确实接收到了实体对象。
 到这儿我们知道了怎么传递复杂对象,现在更进一步,如果我们想获得当前消费者处理消息的元信息怎么办?比如当前消费者处理的是哪个topic,哪个group,哪个partition等。
到这儿我们知道了怎么传递复杂对象,现在更进一步,如果我们想获得当前消费者处理消息的元信息怎么办?比如当前消费者处理的是哪个topic,哪个group,哪个partition等。
我们只需要修改消费者的入参:
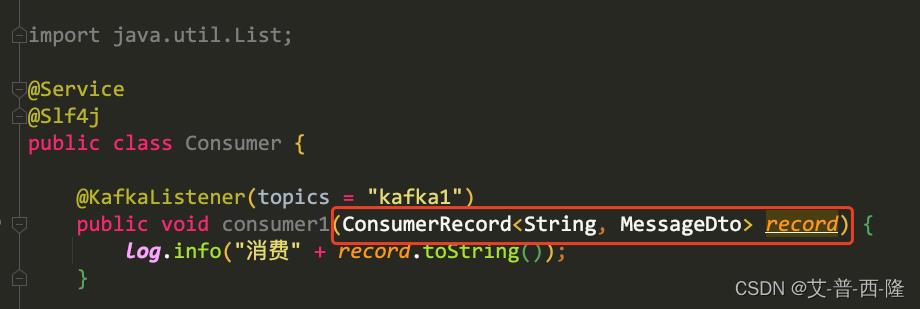 我们设置一个断点,再次调用接口。可以看到record里面包含了消费者当前处理的topic、partition、offset、timestamp等信息,当然我们要传递的实体类对象就在value里。
我们设置一个断点,再次调用接口。可以看到record里面包含了消费者当前处理的topic、partition、offset、timestamp等信息,当然我们要传递的实体类对象就在value里。
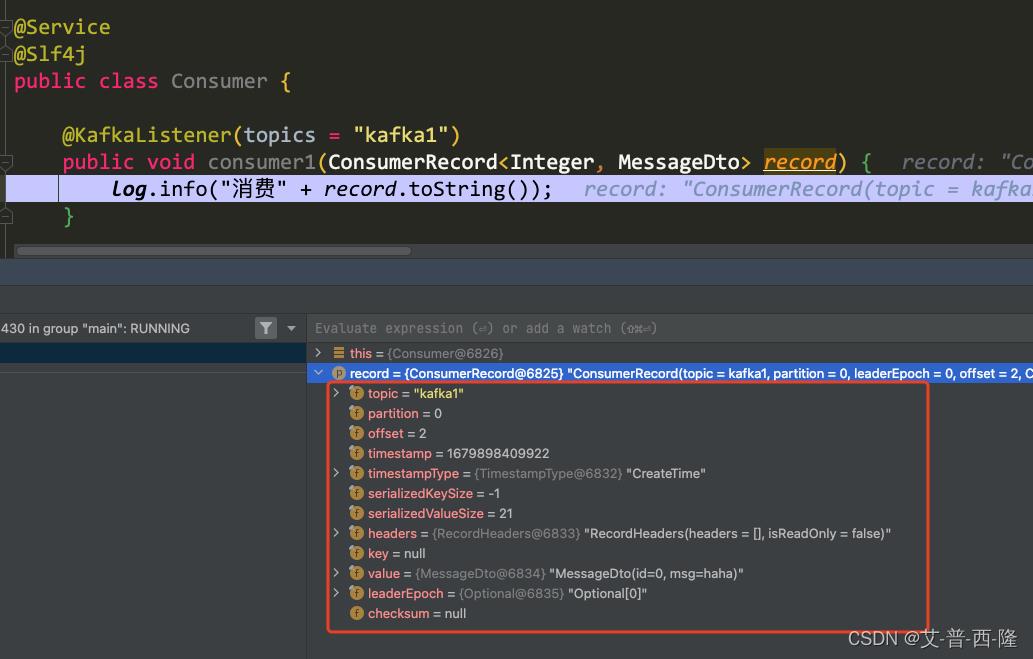
这里需要注意的是,ConsumerRecord的键值其实是生产者发送消息的时候传递的key值,但是本例中发送消息的时候我们没传key,kafka会默认设置为null。当然在使用的时候我们也可以手动设置key,key的类型需要和KafkaTemplate以及record的key对应:
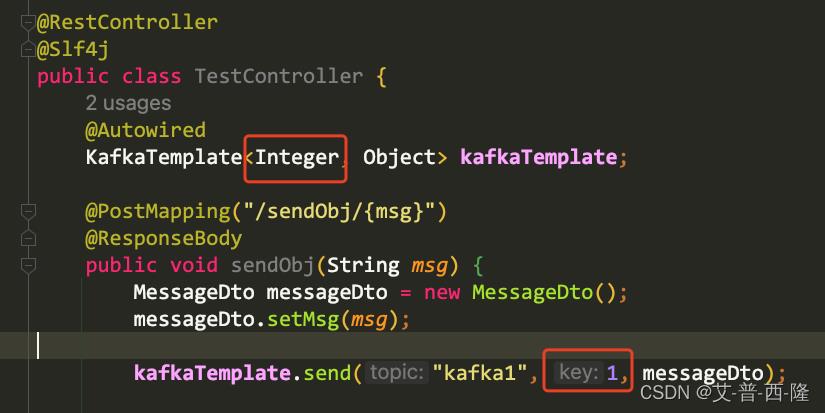
批量和并发
为了更高的处理效率,防止消息队列堵塞,我们可以加快消费消息。加快的方法有两种,批量和并发,我们一个个介绍。
所谓批量就是让消费者从消息队列中一次取多条消息,以此加快消费。注释掉application.yml,新建一个KafkaConfig,并配置一下。注意consumer factory中开启批量处理factory.setBatchListener(true);
package com.test.kafka.config;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import org.springframework.kafka.support.serializer.JsonDeserializer;
import org.springframework.kafka.support.serializer.JsonSerializer;
import java.util.HashMap;
import java.util.Map;
/**
* Kafka 配置类
*
* @author LiYang
*/
@Configuration
@EnableKafka
public class KafkaConfig
/**
* 生产者工厂
*
* @return org.springframework.kafka.core.ProducerFactory
*/
@Bean
public ProducerFactory<String, Object> producerFactory()
return new DefaultKafkaProducerFactory<>(producerProps());
/**
* kafka 生产者模板
*
* @return org.springframework.kafka.core.KafkaTemplate
*/
@Bean
public KafkaTemplate<String, Object> kafkaTemplate()
return new KafkaTemplate<>(producerFactory());
/**
* 生产者配置
*
* @return java.util.Map
*/
private Map<String, Object> producerProps()
Map<String, Object> props = new HashMap<>(16);
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, JsonSerializer.class);
return props;
@Bean(name = "consumerFactory1")
public KafkaListenerContainerFactory<?> batchFactory1()
ConcurrentKafkaListenerContainerFactory<String, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(consumerProps()));
factory.setBatchListener(true);//开启批量处理
factory.setMissingTopicsFatal(false);
return factory;
private Map<String, Object> consumerProps()
Map<String, Object> props = new HashMap<>(16);
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "group1");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, JsonDeserializer.class);
props.put("spring.json.trusted.packages", "com.test.kafka.Dto");
return props;
另外consumer需要配置上group(如果这里不配置会报错,原因未知)以及containerFactory。
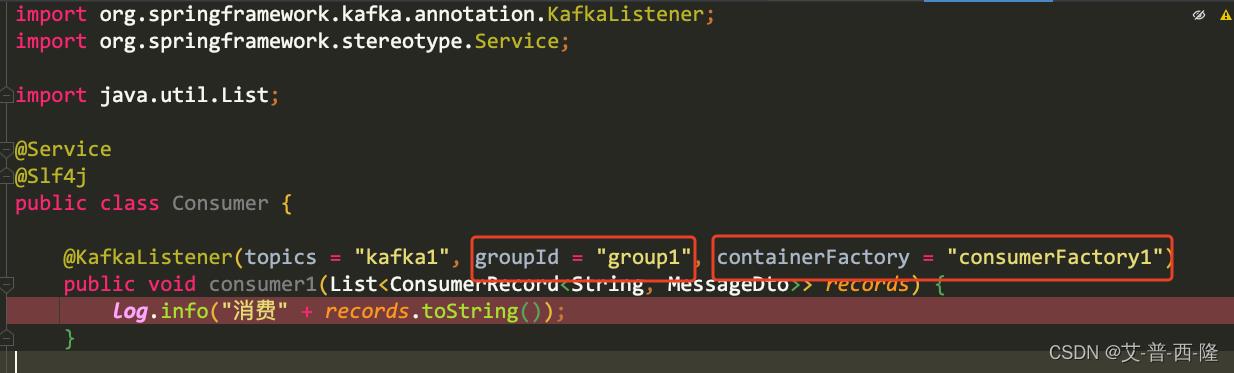
然后我们尝试一次性发送10条消息:
package com.test.kafka.api;
import com.test.kafka.Dto.MessageDto;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
@Slf4j
public class TestController
@Autowired
KafkaTemplate<String, Object> kafkaTemplate;
@PostMapping("/sendObj/msg")
@ResponseBody
public void sendObj(String msg)
MessageDto messageDto = new MessageDto();
messageDto.setMsg(msg);
//kafkaTemplate.send("kafka1", 1, messageDto);
//批量发送消息
for (int i=0;i<10;i++)
messageDto.setMsg(msg + i);
kafkaTemplate.send("kafka1", null, messageDto);
@PostMapping("/send/msg")
@ResponseBody
public void send(String msg)
kafkaTemplate.send("kafka1", msg);
启动项目,调用sendObj接口,打断点查看。可以看到这里消费者直接把10条消息都获取到了。注意,获取的条数在[1,10]之间,并不一定每次都是获取10条。
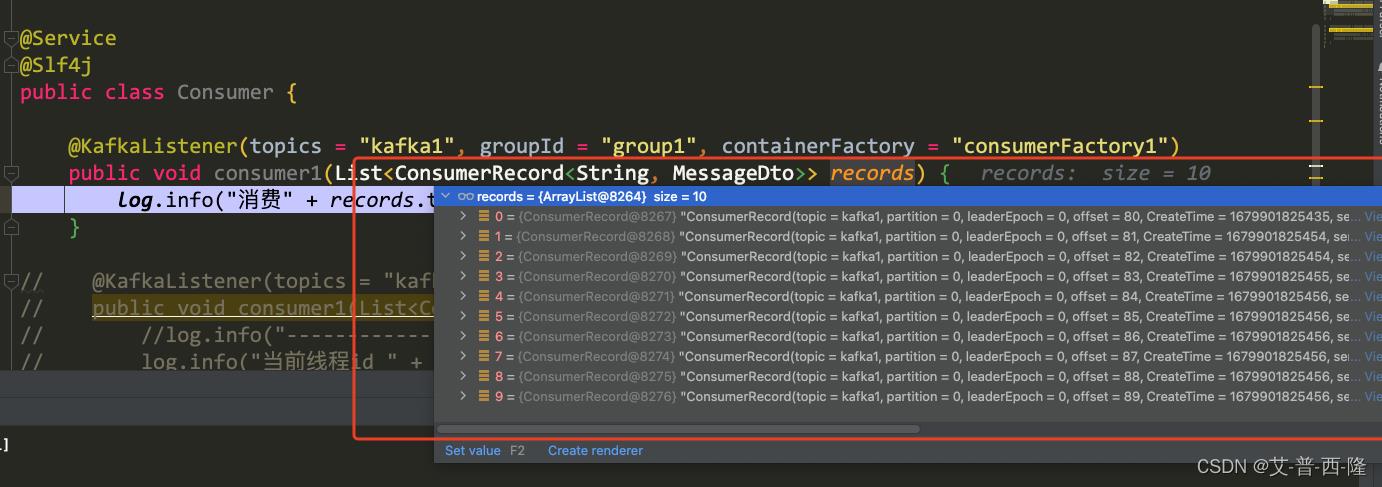
说完了批量再说说并发。
首先需要明确并发的适用场景。并发的前提是partition或者服务器足够多,并发的配置才有效。如果只有一台kafka服务器,topic只往一个partition中放数据,那么即便配置了并发也是无效的。
一些并发的适用场景:
1、n(n>1)台kafka服务器,每个服务器上都是单个partition;可以配置1~n个并发
2、单台kafka服务器,m(m>1)个partition;可以配置1~m个并发
3、n(n>1)台kafka服务器,m(m>1)个partition;可以配置1~n*m个并发
一个并发其实就是一个线程。
现在修改配置,首先修改kafka的配置文件,默认的是kafka的/config/server.properties:
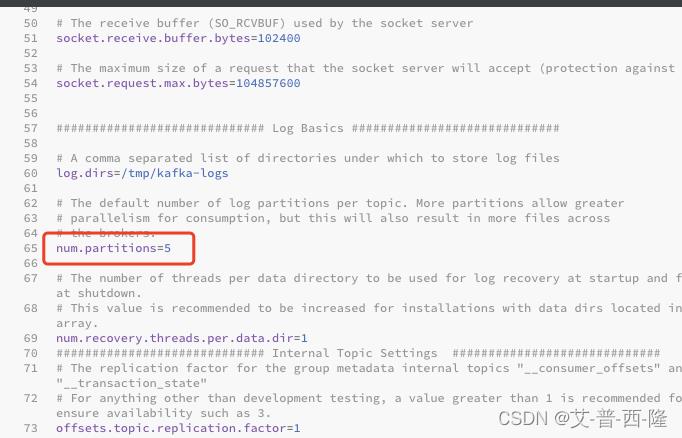
这里把partition从1修改为5,重启kafka。
修改项目的并发配置,这里先设置为5,正好和partition的数目一致:
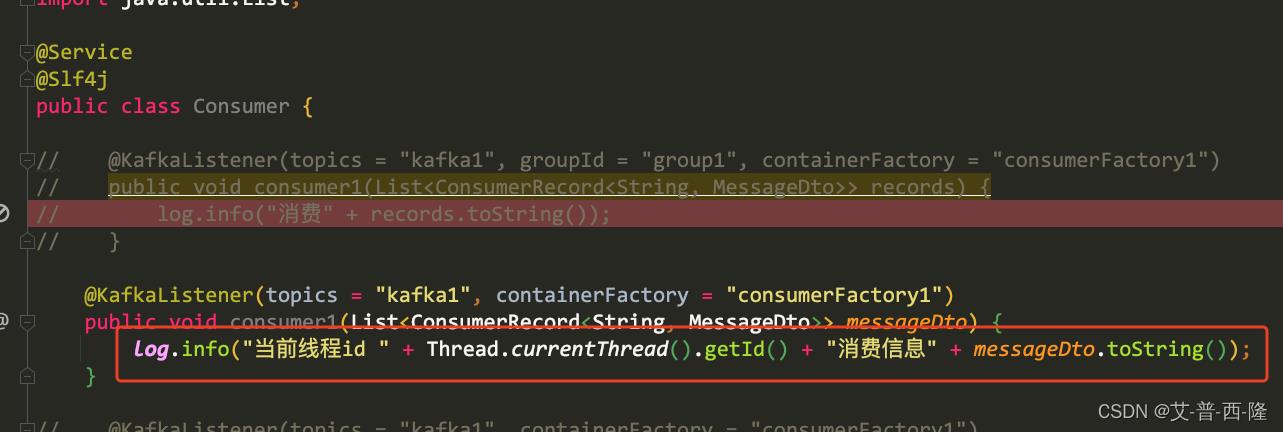
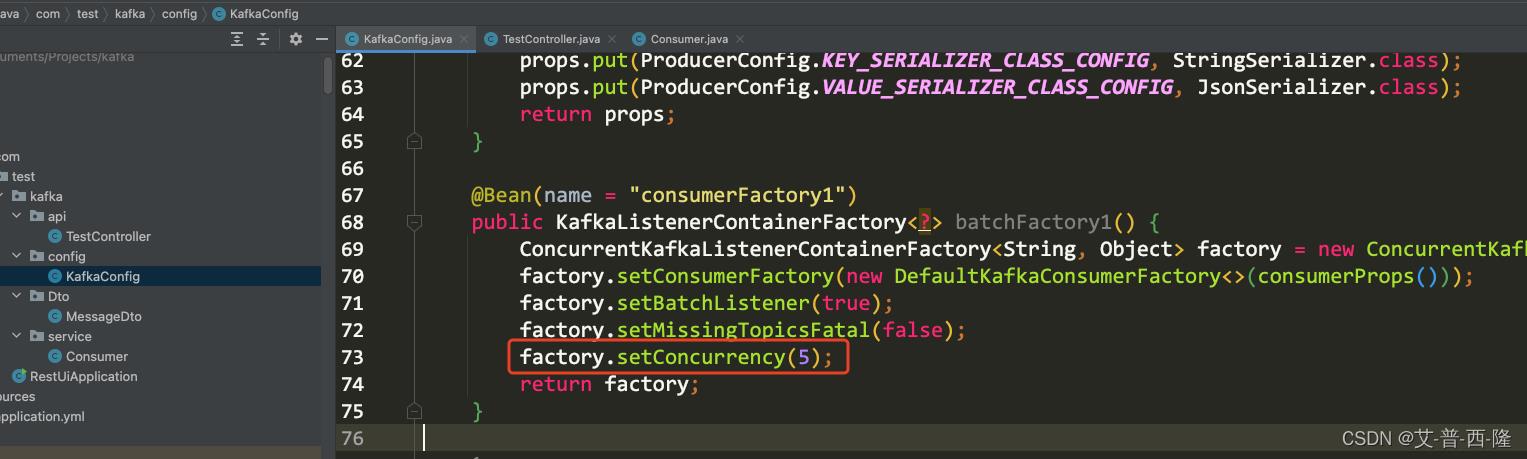 修改下打印日志代码:
修改下打印日志代码:
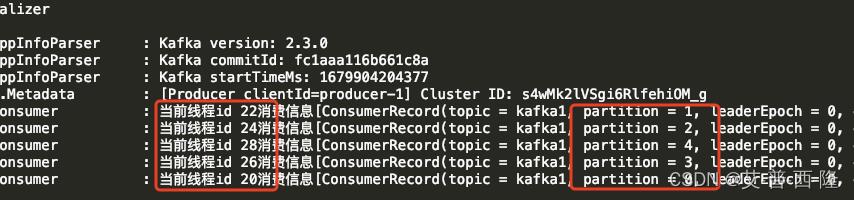
启动项目后,查看kafka的状态:

可以看到5个分区,分别对应5个消费者线程。
调用接口,查看项目日志,发现确实如此。
其实批量和并发可以一起使用。比如上面总共只处理了5次,消费掉了10条消息,说明批量是生效了的。
现在我们将并行数设置为10:
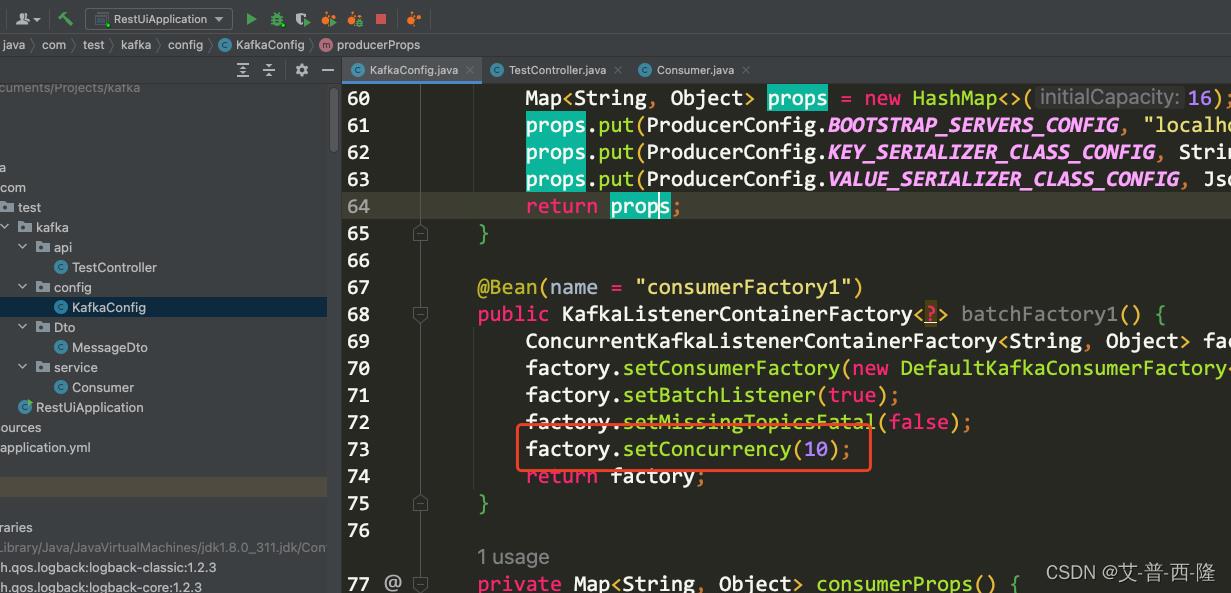
重启项目,查看kafka状态:
 可以看到每个partition只能有一个消费者线程监听,真正分到的消费者线程只有5个,还有5个就浪费掉了。
可以看到每个partition只能有一个消费者线程监听,真正分到的消费者线程只有5个,还有5个就浪费掉了。
如果有多个主题topic,想使用不同的消费者监听,那么只要配置多个消费者即可。
好的,有关Kafka的实战分享就到这里。源代码链接在此。
学习笔记Kafka—— Kafka 与Spark集成 —— 原理介绍与开发环境配置实战
一、环境
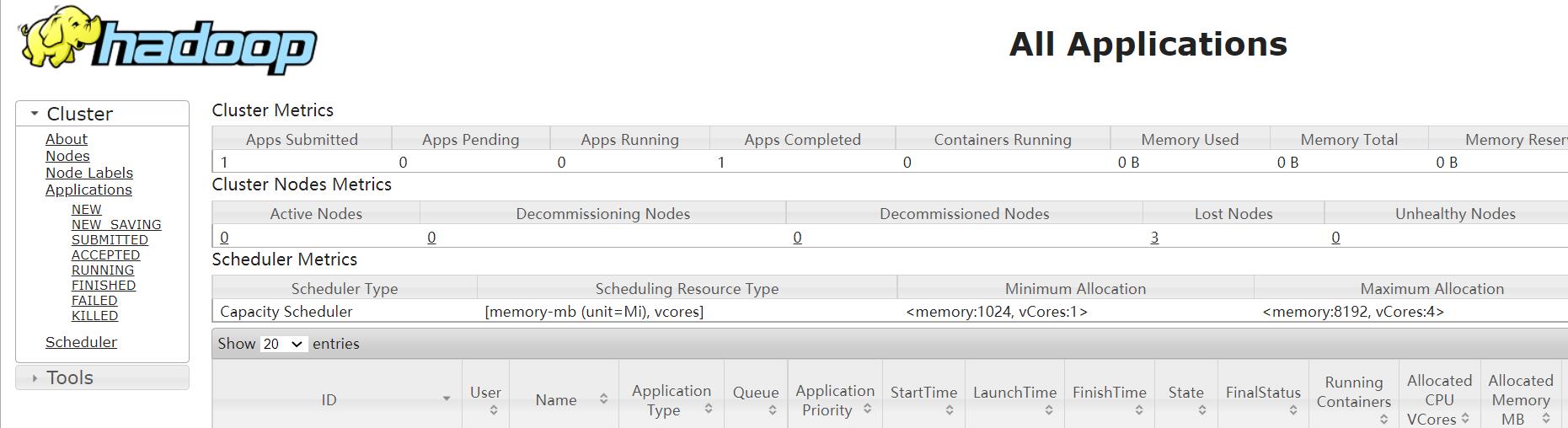
1.1、Hadoop环境

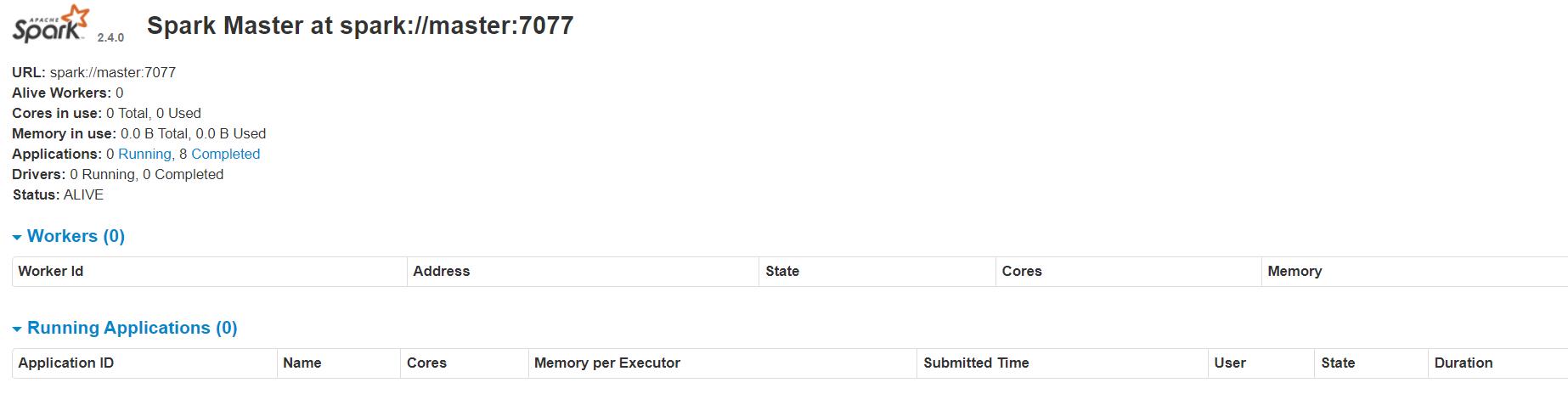
1.2、Spark环境
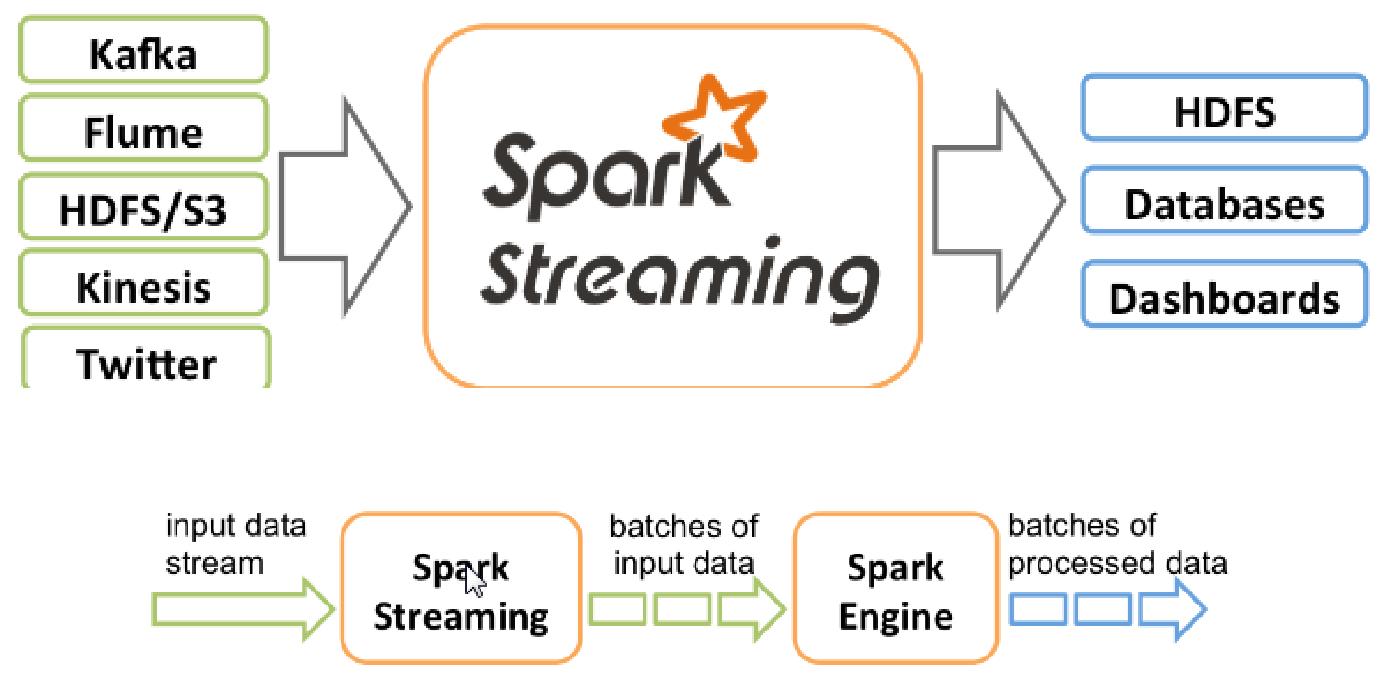
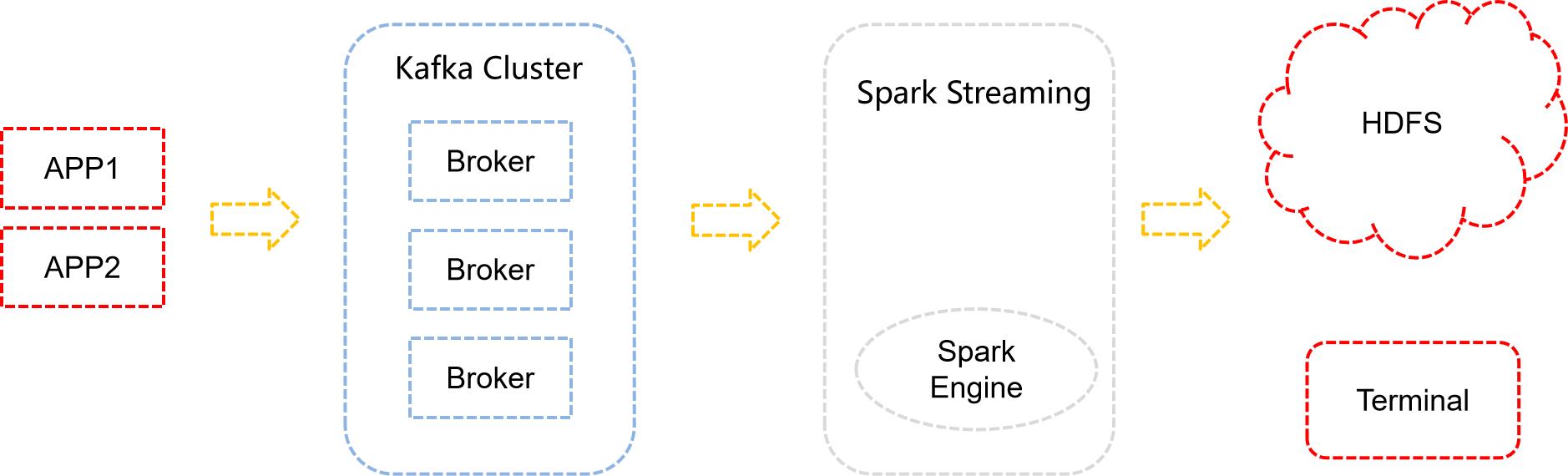
1.3、Spark Streaming
1.4、Add Maven Dependencies & 开发流程
Add Scala Framework Support
添加依赖(在pom.xml添加)
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.3</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.4.3</version>
</dependency>
开发流程

二、实战
实战一:Kafka消息输出到Console|本地测试|集群测试
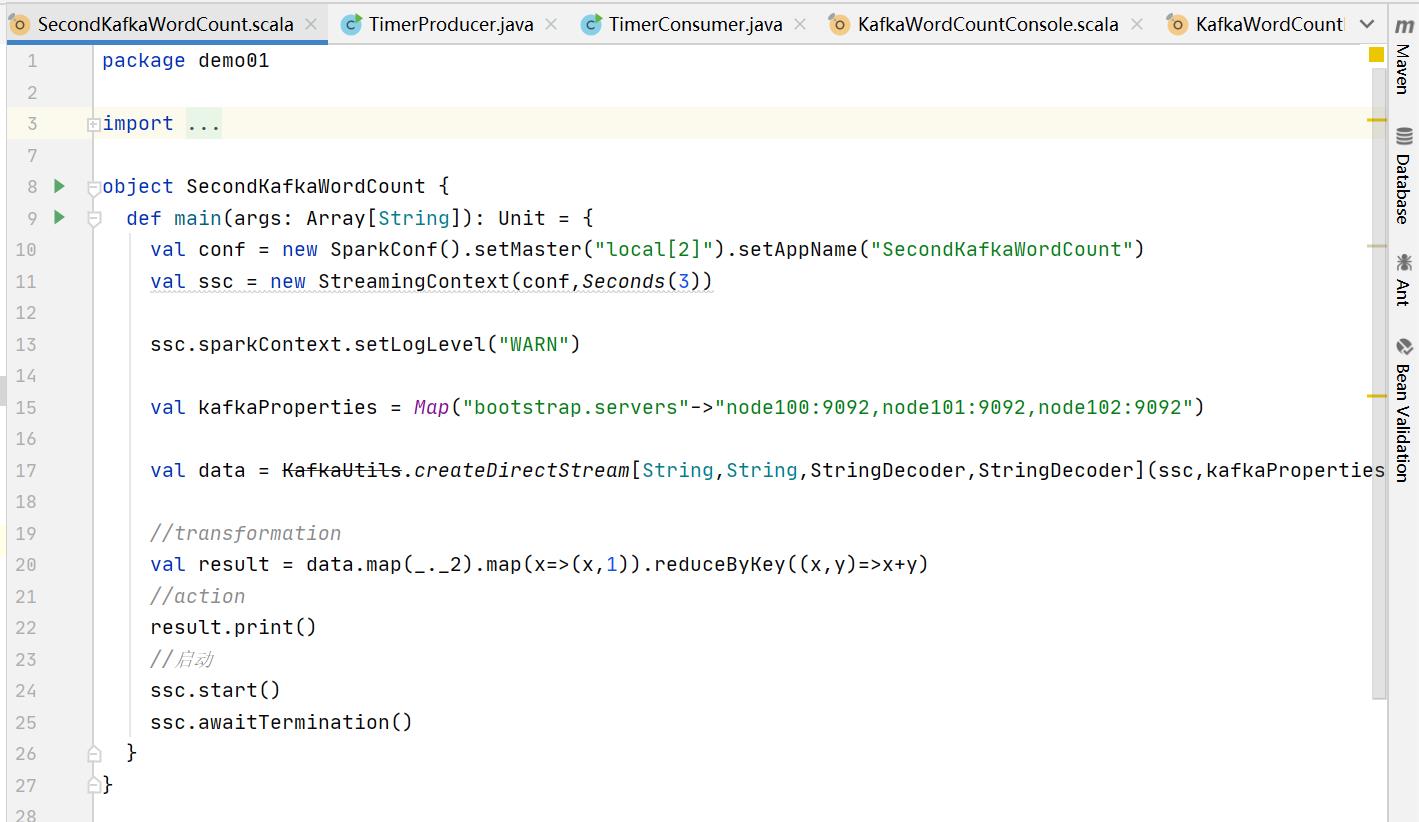
package demo01
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.Seconds, StreamingContext
object SecondKafkaWordCount
def main(args: Array[String]): Unit =
val conf = new SparkConf().setMaster("local[2]").setAppName("SecondKafkaWordCount")
val ssc = new StreamingContext(conf,Seconds(3))
ssc.sparkContext.setLogLevel("WARN")
val kafkaProperties = Map("bootstrap.servers"->"node100:9092,node101:9092,node102:9092")
val data = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaProperties,Set("test_02_02"))
//transformation
val result = data.map(_._2).map(x=>(x,1)).reduceByKey((x,y)=>x+y)
//action
result.print()
//启动
ssc.start()
ssc.awaitTermination()
编译打包,并上传jar文件

执行TimerProducer.java
结果:

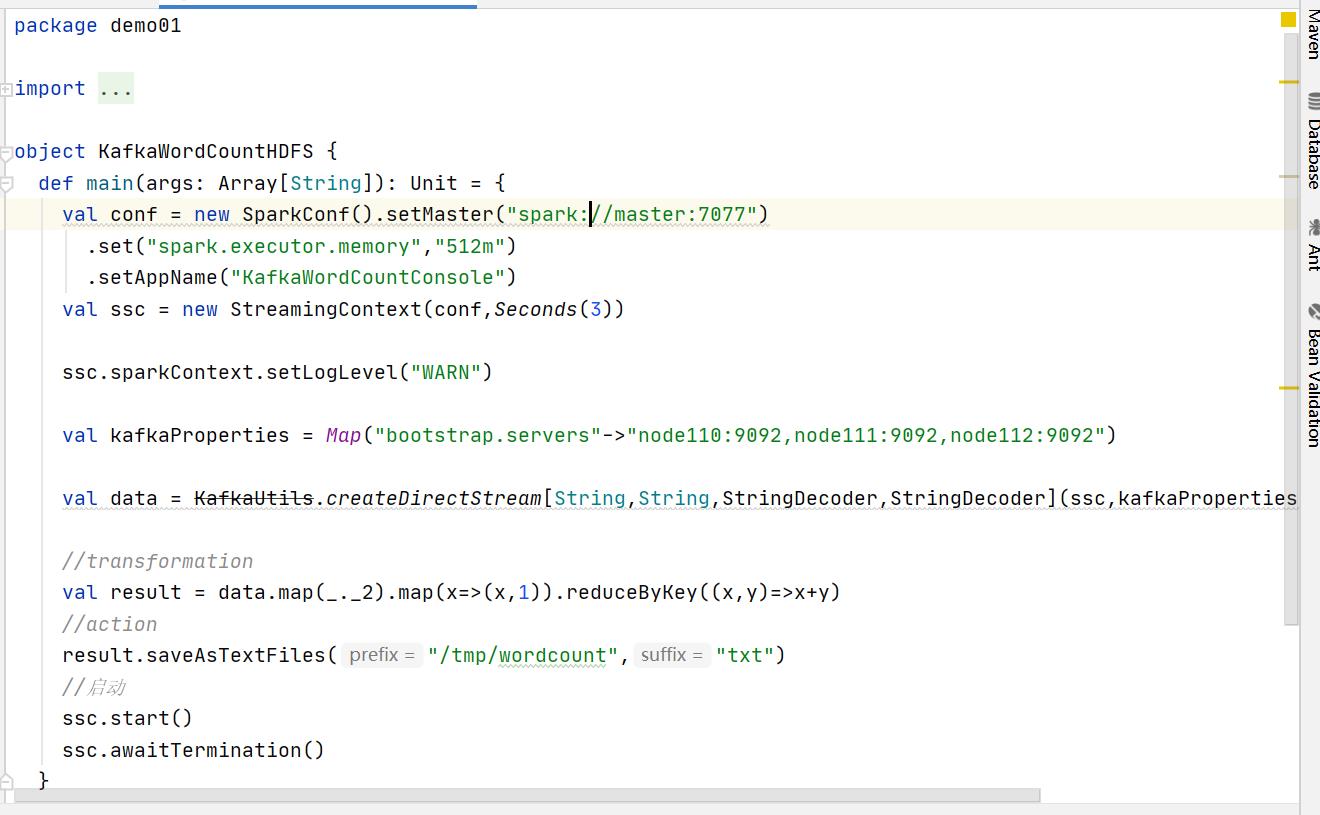
实战二:Kafka消息输出到HDFS|本地测试|集群测试
package demo01
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.Seconds, StreamingContext
object KafkaWordCountHDFS
def main(args: Array[String]): Unit =
val conf = new SparkConf().setMaster("spark://master:7077")
.set("spark.executor.memory","512m")
.setAppName("KafkaWordCountConsole")
val ssc = new StreamingContext(conf,Seconds(3))
ssc.sparkContext.setLogLevel("WARN")
val kafkaProperties = Map("bootstrap.servers"->"node110:9092,node111:9092,node112:9092")
val data = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,kafkaProperties,Set("test_02_02"))
//transformation
val result = data.map(_._2).map(x=>(x,1)).reduceByKey((x,y)=>x+y)
//action
result.saveAsTextFiles("/tmp/wordcount","txt")
//启动
ssc.start()
ssc.awaitTermination()
编译打包,上传jar文件
spark提交

运行TimerProducer.java文件
结果:

以上是关于SpringBoot集成Kafka实战学习笔记的主要内容,如果未能解决你的问题,请参考以下文章