web安全之信息收集
Posted The-Back-Zoom
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了web安全之信息收集相关的知识,希望对你有一定的参考价值。
💪💪 web安全之信息收集
web安全之信息收集)
1.网络入口/信息
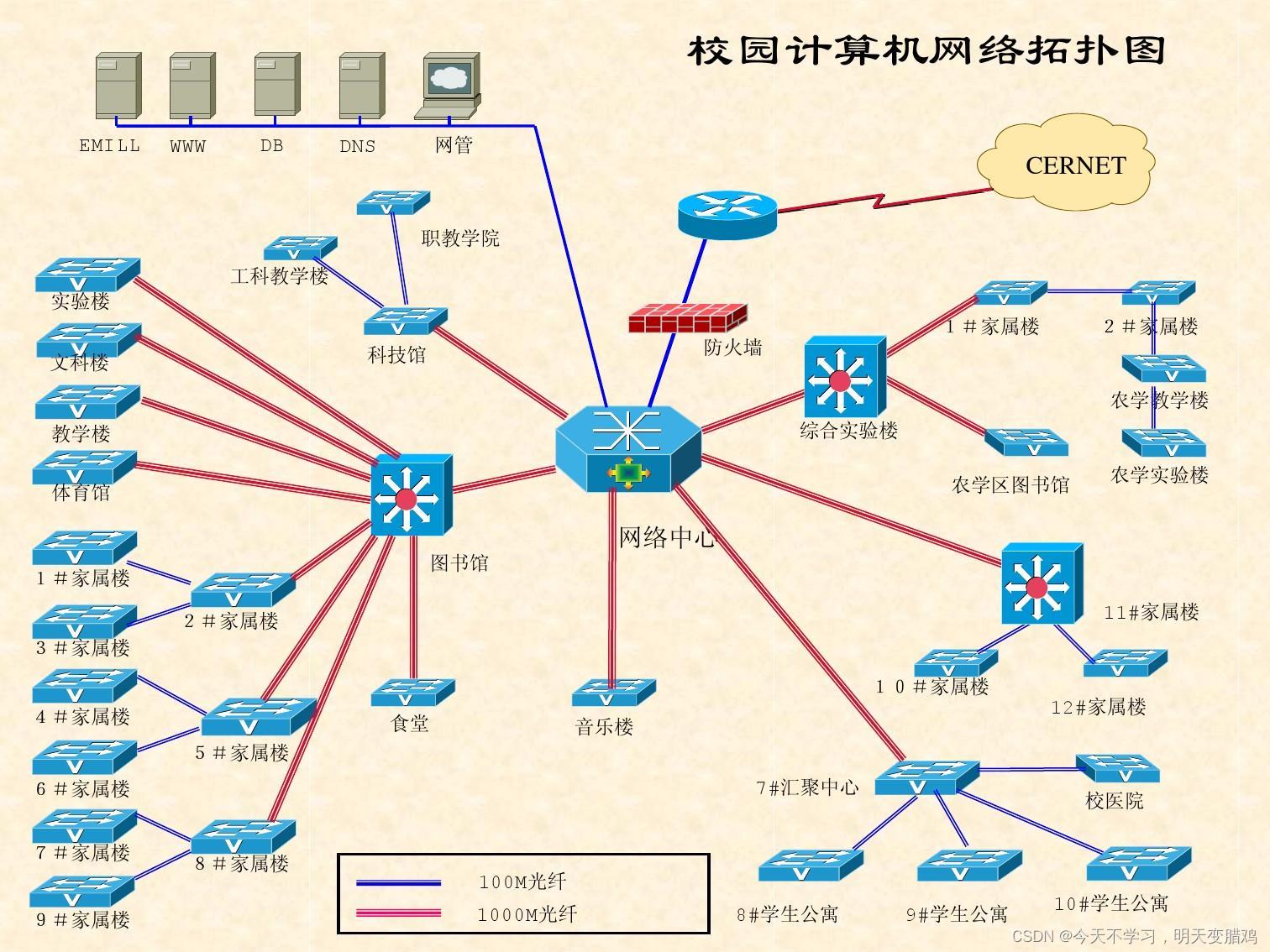
1.1网络拓扑信息
💪💪 如下是网络拓扑图,可能你会问,为什么要搞清楚网络拓扑图,下面我从两个方面说明:
查看防护设备
- 知识点:
防火墙
堡垒机
NAT - 如果你搞清楚了网络拓扑图,你就会发现你要渗透的网站有哪些防护设备,比如说防火墙和堡垒机,然后制定相对的绕过方案,再比如说有一些网站使用了
NAT技术,你根本就找不到要渗透的网站,了解网络拓扑结构,可以让你的渗透更方便
1.2 IP信息
💪💪
IP信息肯定是需要知道的,你都不知道IP你来干什么了,IP地址的作用不只是找到目标网站,知道了IP你可以扫描IP地址开放的端口,有些网站不同的端口有不同的服务,了解IP你也可以扫描目录,不同的目录有不同的服务,下面以查找端口为例:
- 扫描
ip可以使用工具,也可以使用暗黑搜索引擎zoomeye,扫描45.33.42.112,你会发现如下端口
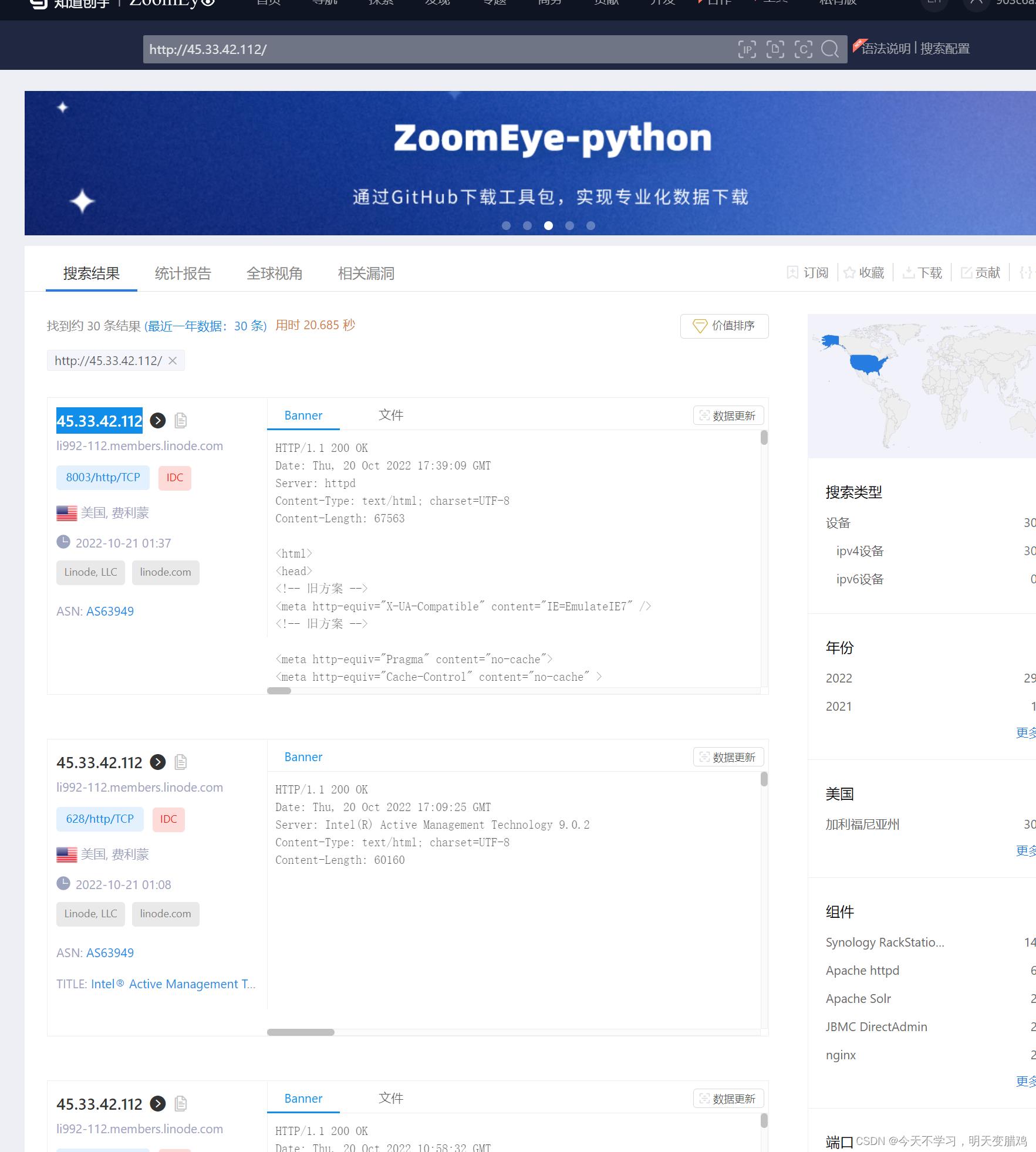
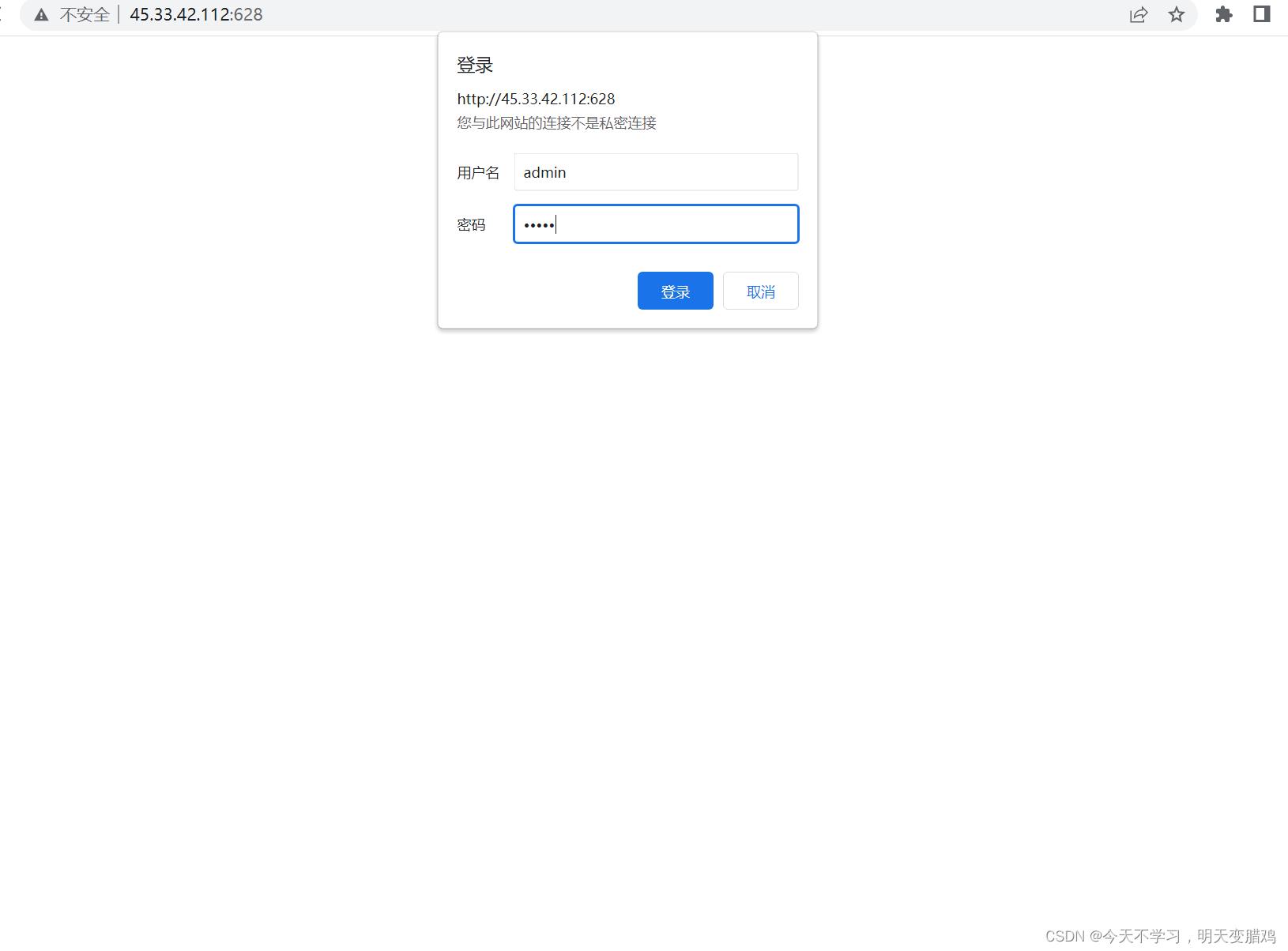
⚠️⚠️你会发现628端口有后门,如下,试试弱口令
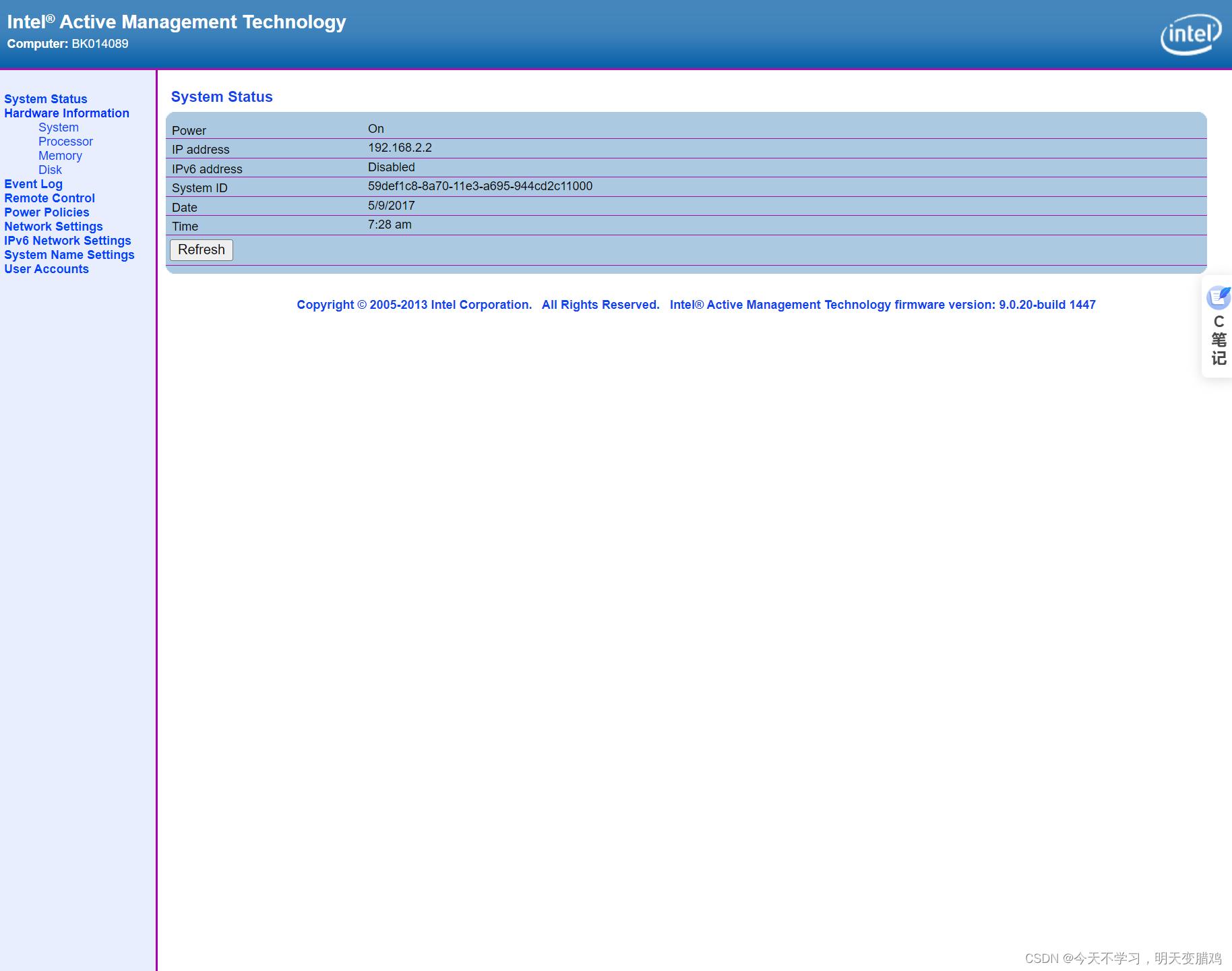
admin,admin,进入后台
1.3线下网络
💪💪线下网络就是查看目标网络的一些信息,比如说
wife信息和认证信息
2.域名信息
2.1Whios
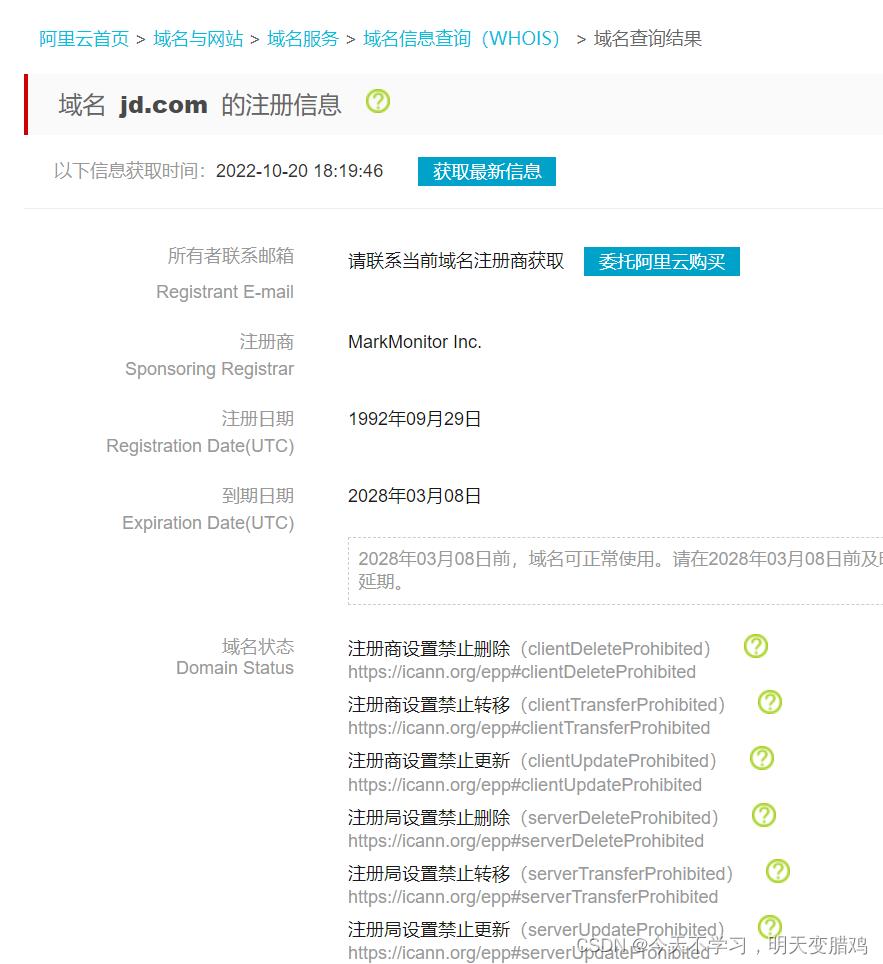
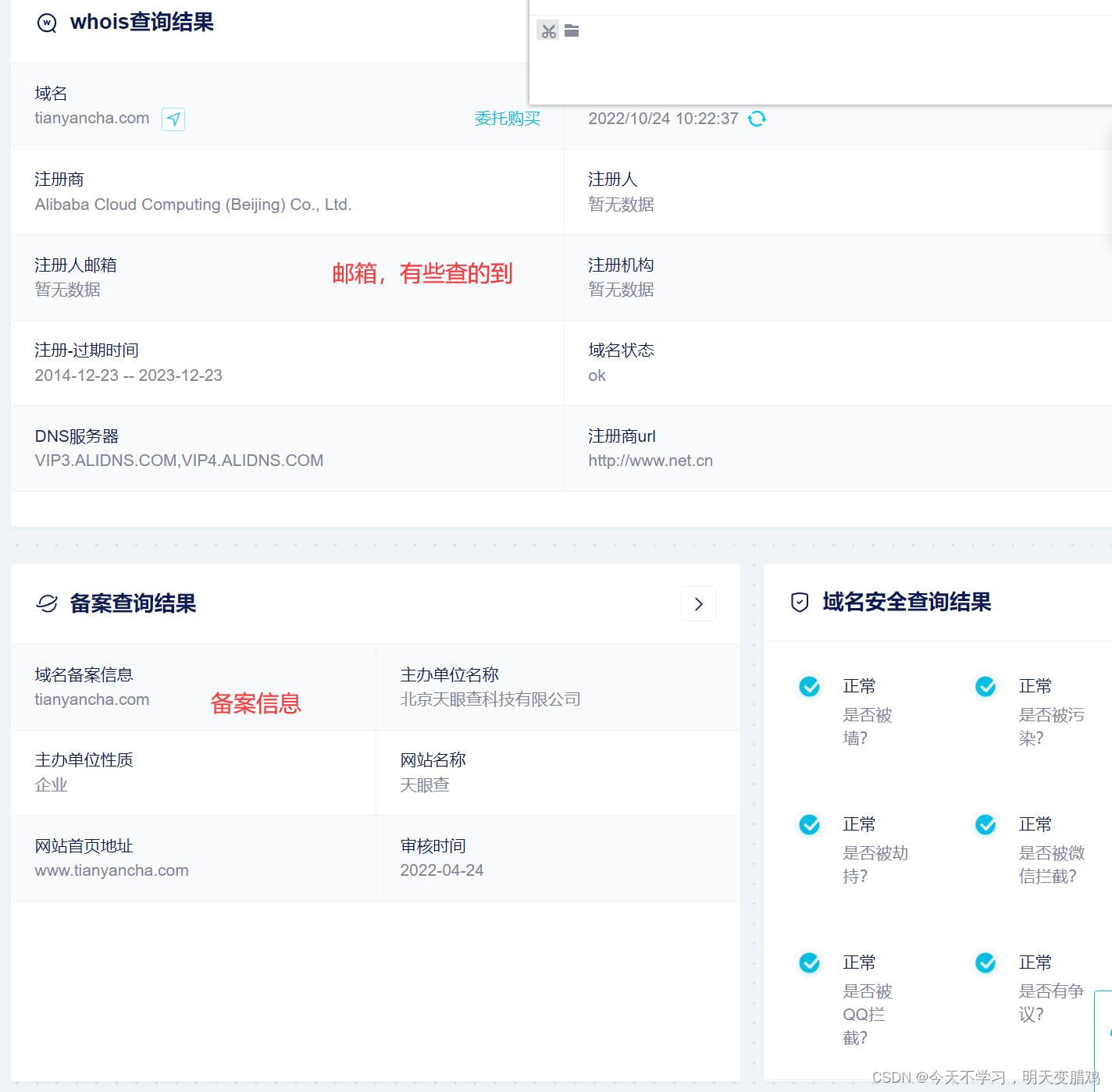
Whois 可以查询域名是否被注册,以及注册域名的详细信息的数据库,其中可能会存在一些有用的信息,例如域名所有人、域名注册商、邮箱等。如下查看京东信息:
京东域名:www.jd.com
2.2搜索引擎搜索
1. 浏览器直接搜索
💎💎搜索引擎通常会记录域名信息,可以通过
site: domain的语法来查询。在浏览器中输入site:jd.com,得到的信息如下:

你会得到非常和京东有关的域名,得到了这些信息后,你可能会发现和目标网站类似的网站,如果类似网站存在某种漏洞的话,你可以对目标站点进行类似漏洞检测方案
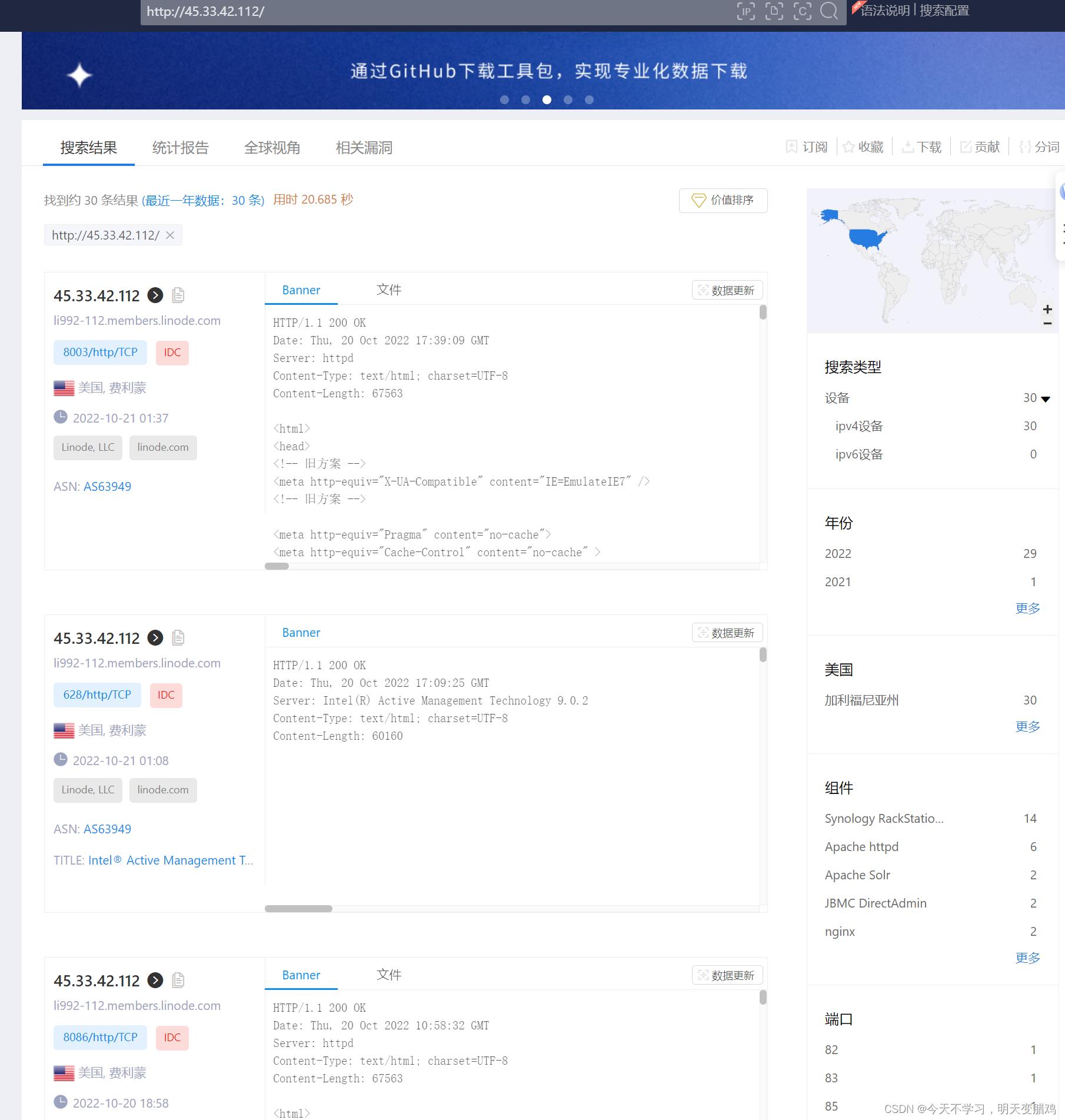
2. 暗黑引擎搜索
💎💎暗黑引擎搜索是特定为渗透测试而生的,你会搜索到目标网站IP类型,开放端口等信息,如下是用
ZooomEYE搜索外国网站:
2.3. 第三方查询
💎💎在这里介绍两种
2.4. ASN信息关联
💎💎 1.
ASN是一个自治系统,在自治系统中,可以自定义网络,比如说1.1.1.1这个IP地址,对应的计算机有非常多个,这是因为自治系统。
⚠️⚠️2. 一个自治系统有时也被称为是一个路由选择域 (
routing domain) 。一个自治系统将会分配一个全局的唯一的16位号码,这个号码被称为自治系统号 (ASN) 。因此可以通过ASN号来查找可能相关的IP
2.5. 域名相关性
同一个企业/个人注册的多个域名通常具有一定的相关性,例如使用了同一个邮箱来注册、使用了同一个备案、同一个负责人来注册等,可以使用这种方式来查找关联的域名。一种操作步骤如下:
- 查询域名注册邮箱
- 通过域名查询备案号
- 通过备案号查询域名
- 反查注册邮箱
- 反查注册人
- 通过注册人查询到的域名在查询邮箱
- 通过上一步邮箱去查询域名
- 查询以上获取出的域名的子域名
其他的自己实验
2.6. 网站信息利用
⚠️⚠️1.网站中有相当多的信息,网站本身、各项安全策略、设置等都可能暴露出一些信息。
⚠️⚠️2. 网站本身的交互通常不囿于单个域名,会和其他子域交互。对于这种情况,可以通过爬取网站,收集站点中的其他子域信息。这些信息通常出现在
javascript文件、资源文件链接等位置。
⚠️⚠️3. 网站的安全策略如跨域策略、
CSP规则等通常也包含相关域名的信息。有时候多个域名为了方便会使用同一个SSL/TLS证书,因此有时可通过证书来获取相关域名信息。
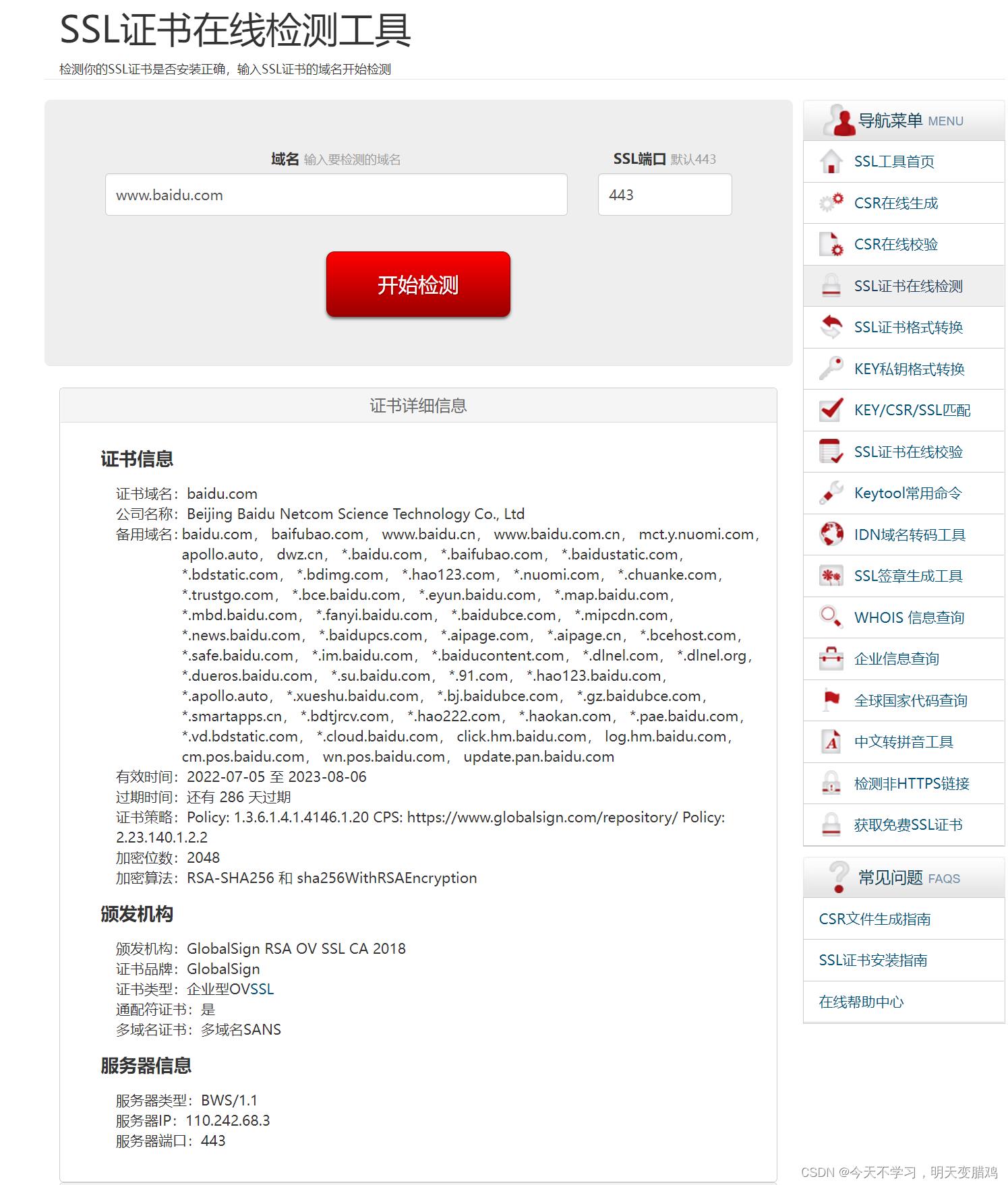
2.7. HTTPS证书
💪💪查询已授权证书的方式来获得相关域名
怎么查看域名证书,查询方式如下:
- 第一种就是在建网站的平台注册会员账号之下来进行查询,大家可以首先访问建立网站的官方网站,这时候证书便会自动弹出来,大家为了方便使用,所以可以用手机将它拍摄下来,也可以直接将网址收藏,这是一种相对便捷的查看方式。
- 第二种方法是登录会员平台,点击“我的产品”,然后依次点击“选中需要打印证书的域名”和“高级服务选项”之下的“查看”按钮,只要按照这个基本流程完成操作,那么同样可以看到自己的域名证书。
- 第三种,查询网站 证书查询网站
2.8. CDN
2.9. 子域爆破
就是使用工具进行爆破,看是否有该域名,也可以直接搜索,子域名爆破工具
3.端口信息
3.1常见端口
FTP (21/TCP)SSH (22/TCP)- Telent (23/TCP)
- SMTP (25/TCP)
DNS (53/UDP & 53/TCP)DHCP 67/68- Kerberos (88/TCP)
POP3 (110/TCP & 995/TCP)- RPC (135/TCP)
- NetBIOS (137/UDP & 138/UDP)
- NetBIOS / Samba (139/TCP)
- IMAP (143/TCP & 993/TCP)
- SNMP (161/TCP & 161/UDP)
- LDAP (389/TCP)
HTTPS (443/TCP)Linux Rexec (512/TCP & 513/TCP & 514/TCP)- Rsync (873/TCP)
- RPC (1025/TCP)
- Java RMI (1090/TCP & 1099/TCP)
MSSQL (1433/TCP)Oracle (1521/TCP)- NFS (2049/TCP)
- ZooKeeper (2171/TCP & 2375/TCP)
- Docker Remote API (2375/TCP)
mysql (3306/TCP)- RDP / Terminal Services (3389/TCP)
- Postgres (5432/TCP)
- VNC (5900/TCP)
- CouchDB (5984/TCP)
- WinRM (5985/TCP)
Redis (6379/TCP)- Kubernetes API Server (6443/TCP && 10250/TCP)
- JDWP (8000/TCP)
- ActiveMQ (8061/TCP)
- Jenkin (8080/TCP)
- Elasticsearch (9200/TCP)
- Memcached (11211/TCP & 11211/UDP)
- RabbitMQ (15672/TCP & 15692/TCP & 25672/TCP)
- MongoDB (27017/TCP)
- Hadoop (50070/TCP & 50075/TCP)
3.2端口扫描
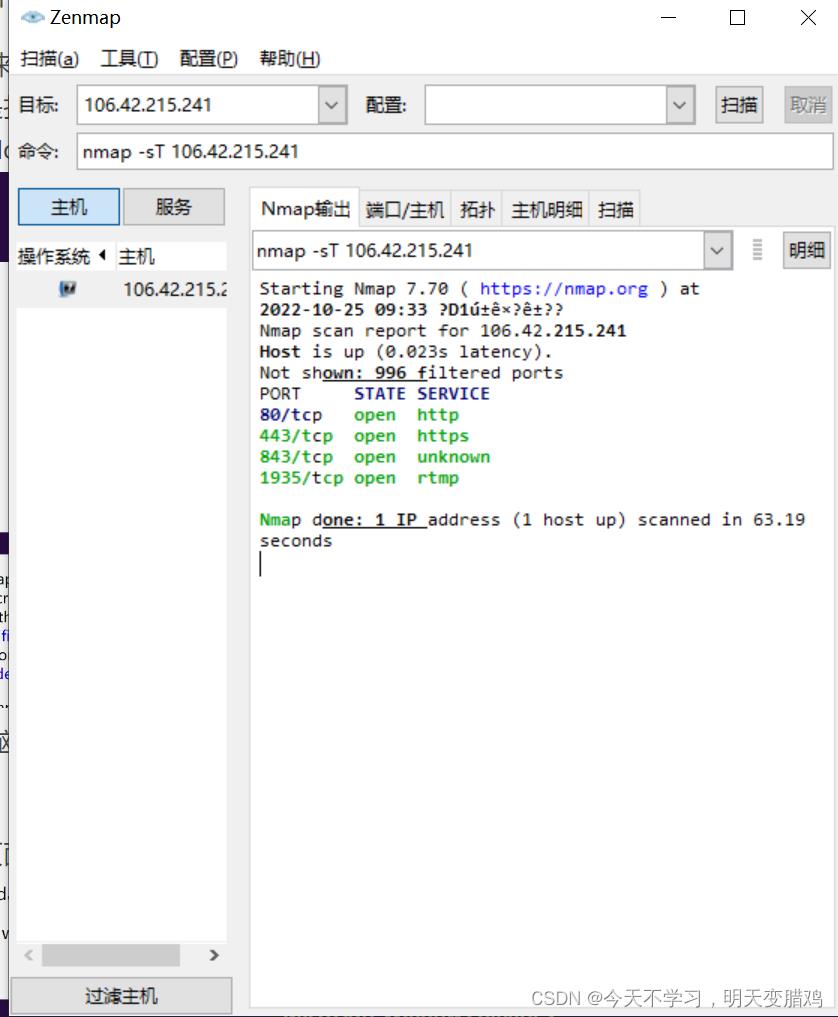
nmap 具备端口扫描的功能,可以使用nmap进行端口扫描,如下所示,扫描
106.42.215.241·nmap下载
nmap -sT 106.42.215.241//TCP连接扫描(全扫描),不安全,慢
-
nmap -sS 106.42.215.241//SYN扫描(半扫描:这种方式需要较高的权限,而且现在的大部分防火墙已经开始对这种扫描方式做处理。),使用最频繁,安全,快,
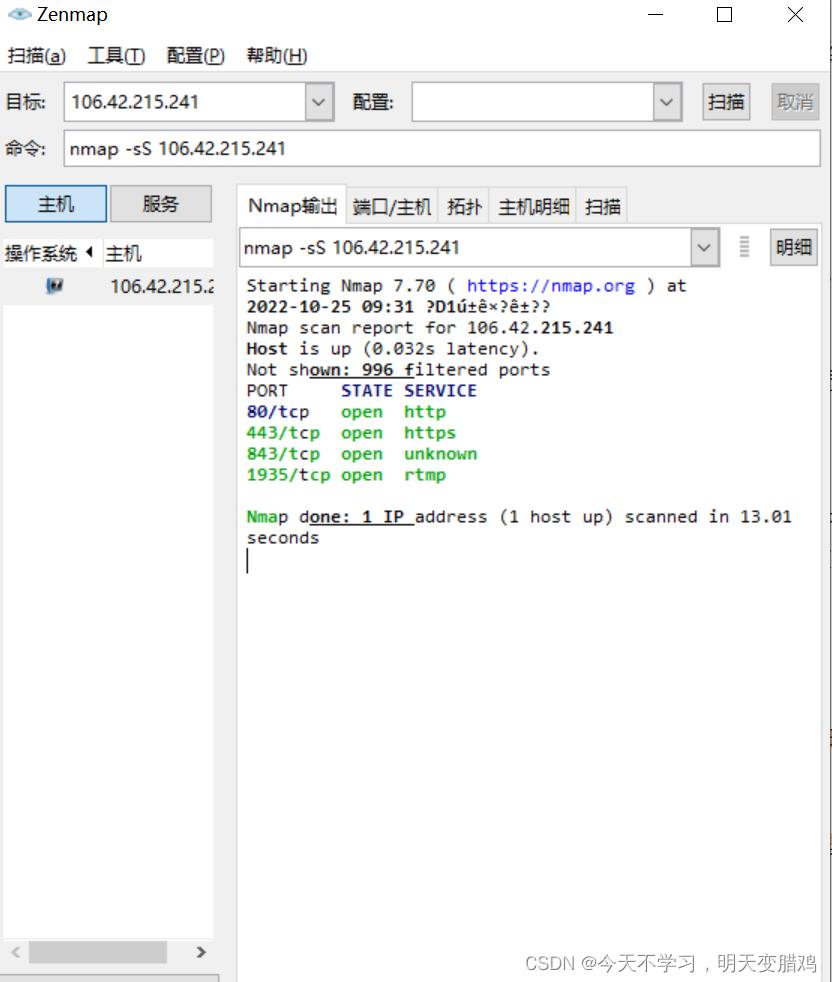
-
nmap -Pn 106.42.215.241//目标机禁用ping,绕过ping扫描 -
nmap -sU 106.42.215.241//UDP扫描,慢,可得到有价值的服务器程序
4.站点信息
4.1 判断网站操作系统
使用三种方法
-
Linux大小写敏感,Windows大小写不敏感 -
通过
ping的TTL值判断,Windows在128左右,LInux在64左右,如下ping 106.42.215.241为linux

-
工具扫描
nmap -0 网址
4.2 扫描敏感文件
robots.txt
1. 搜索引擎通过一种程序robot自动访问互联网上的网页并获取网页信息。
2. 您可以在您的网站中创建一个纯文本文件robots.txt,在这个文件中声明该网站中不想被robot访问的部分
3.robots.txt文件应该放在网站根目录下,一般是目标网址/robots.txt
在robots.txt文件中:
1.User-agent:描述搜索引擎robot的名字(值为*代表所有的搜索引擎)
2.Disallow :描述不希望被访问到的一个URL,一般是目标地址/文件名
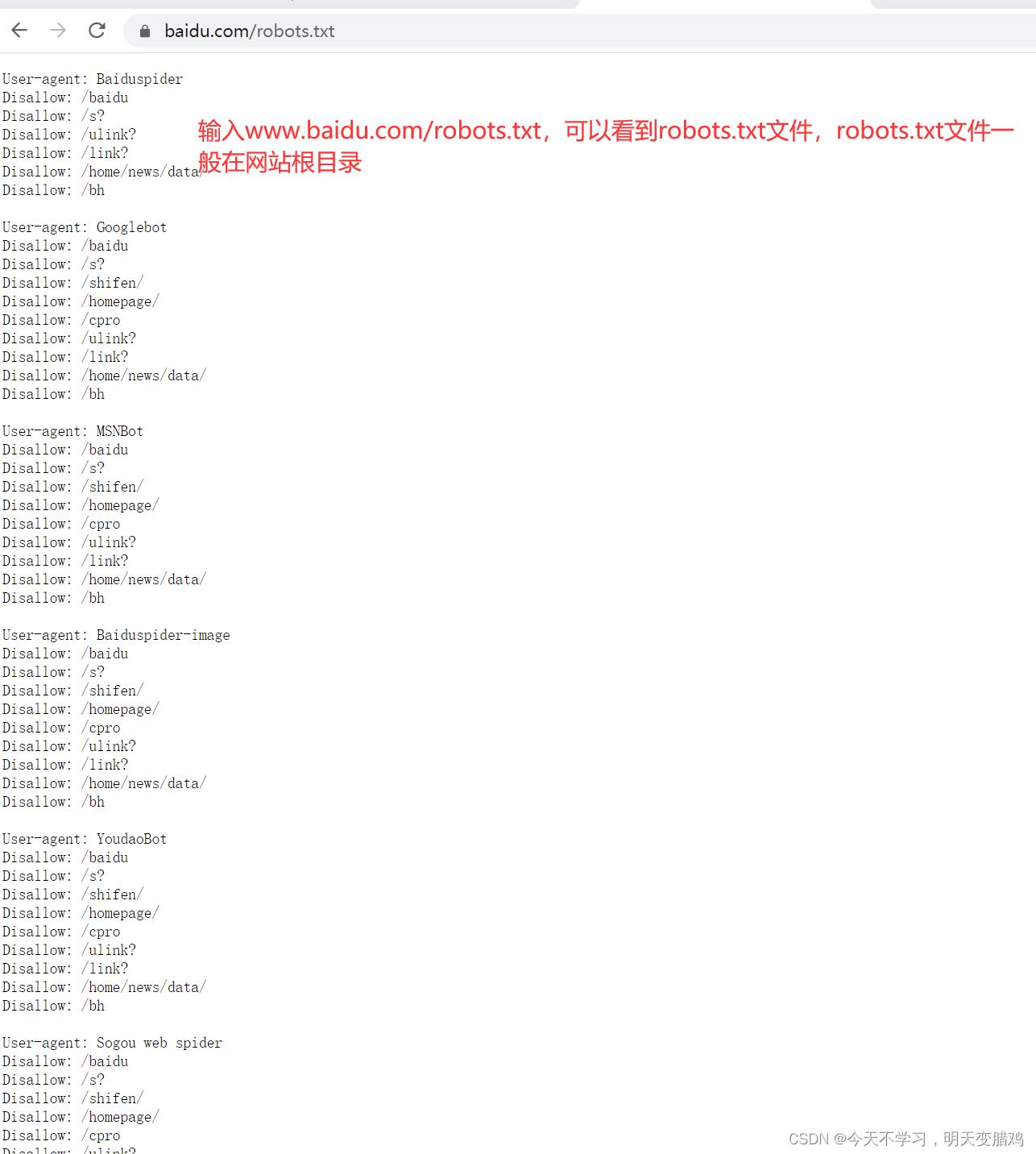
crossdomain.xmlsitemap.xml
如下两种文件一般是备份文件,或者是下载文件
xx.tar.gzxx.bak
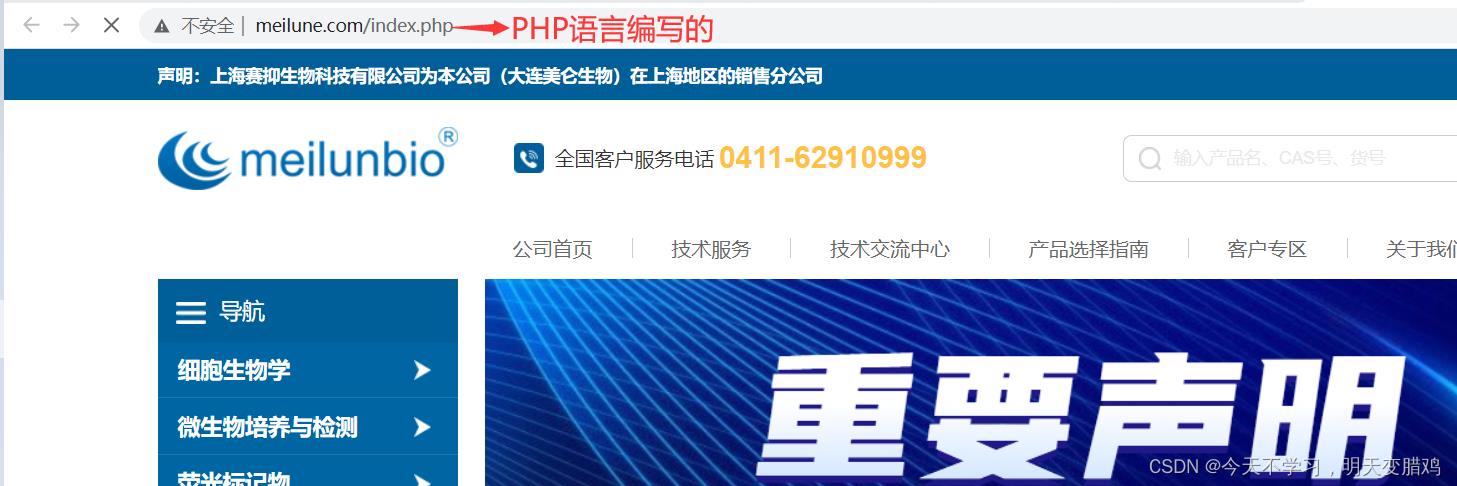
4.3 确定网站采用的语言
⚠️⚠️找文件后缀
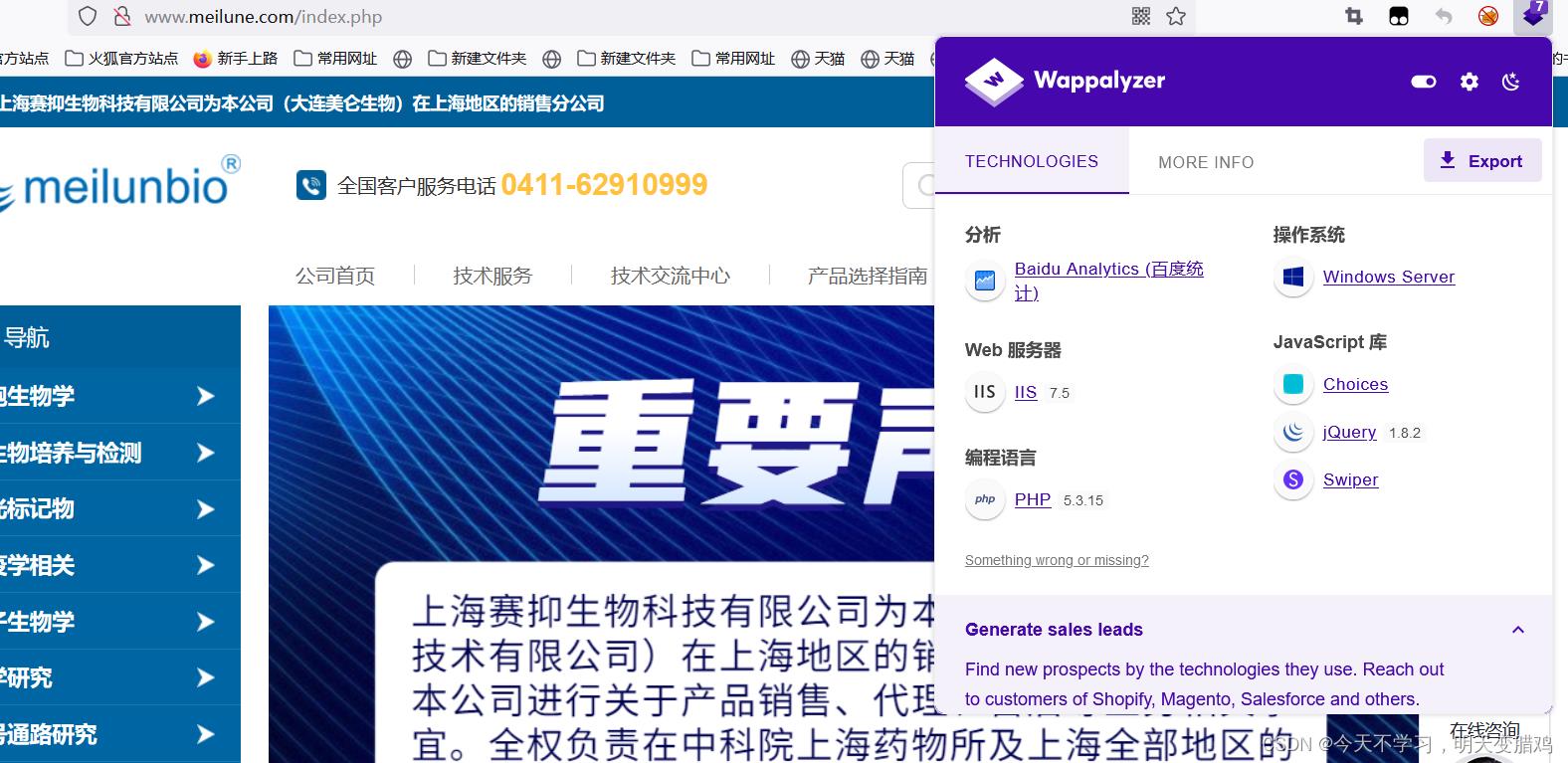
4.4 前端框架
- 普通方法
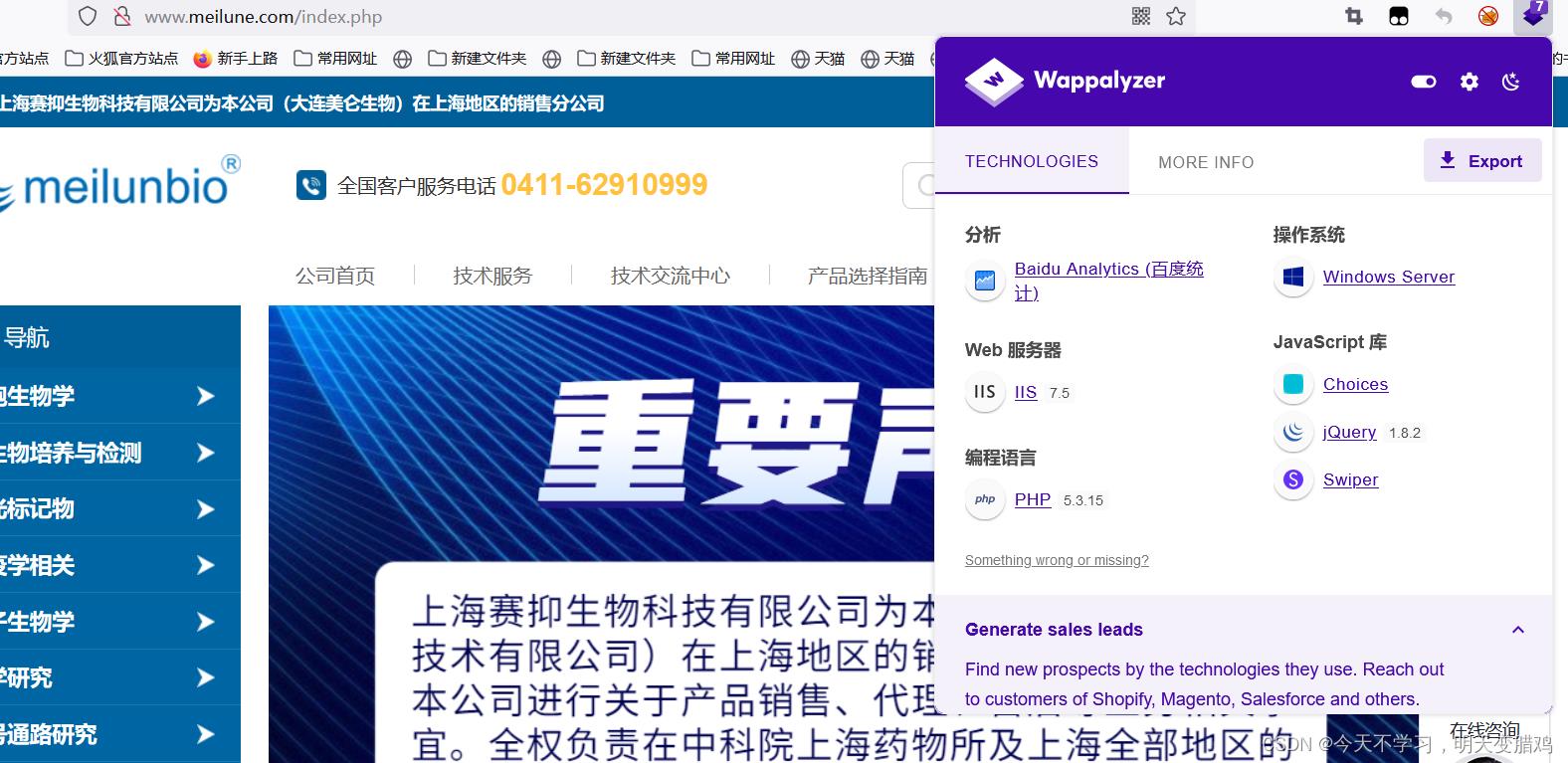
识别前端框架 - 工具识别,在火狐浏览器中安装
Wappalyzer插件(Wappalyzer是一个浏览器扩展,揭示了网站上使用的技术。它可以检测内容管理系统、电子商务平台、web服务器、JavaScript框架、分析工具等。)
4.5 中间服务器
如
Apache / nginx / IIS等,可以通过如下三种方法:
-
查看header中的信息,就是查看
Server
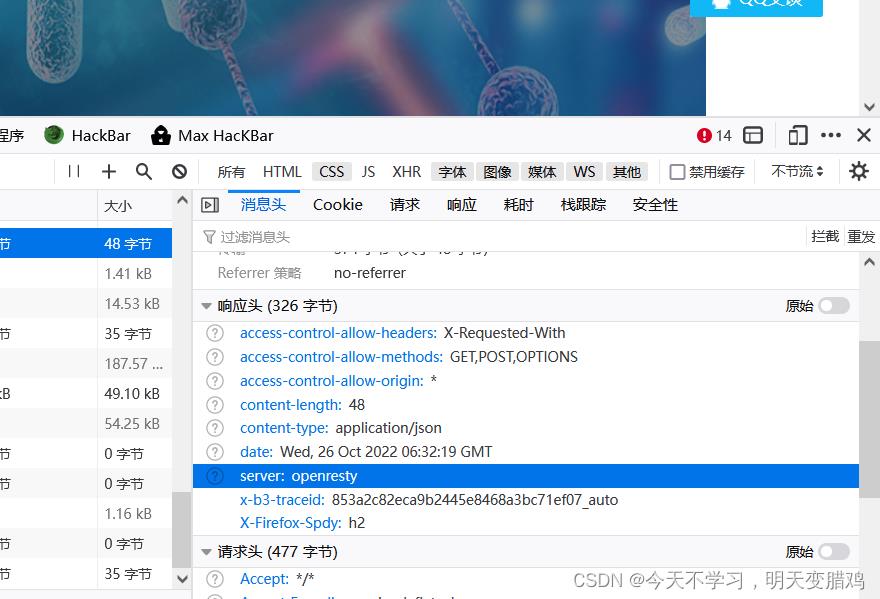
-
根据报错信息判断
-
工具判断
4.6 Web容器服务器
最常见的
Web容器服务器就是tomcat
4.7 后端框架
后端框架难以识别,常见的识别方法如下:
- 根据
Cookie判断 - 根据
CSS/ 图片等资源的hash值判断 - 根据
URL路由判断 - 根据网页中的关键字判断
- 根据响应头中的
X-Powered-By
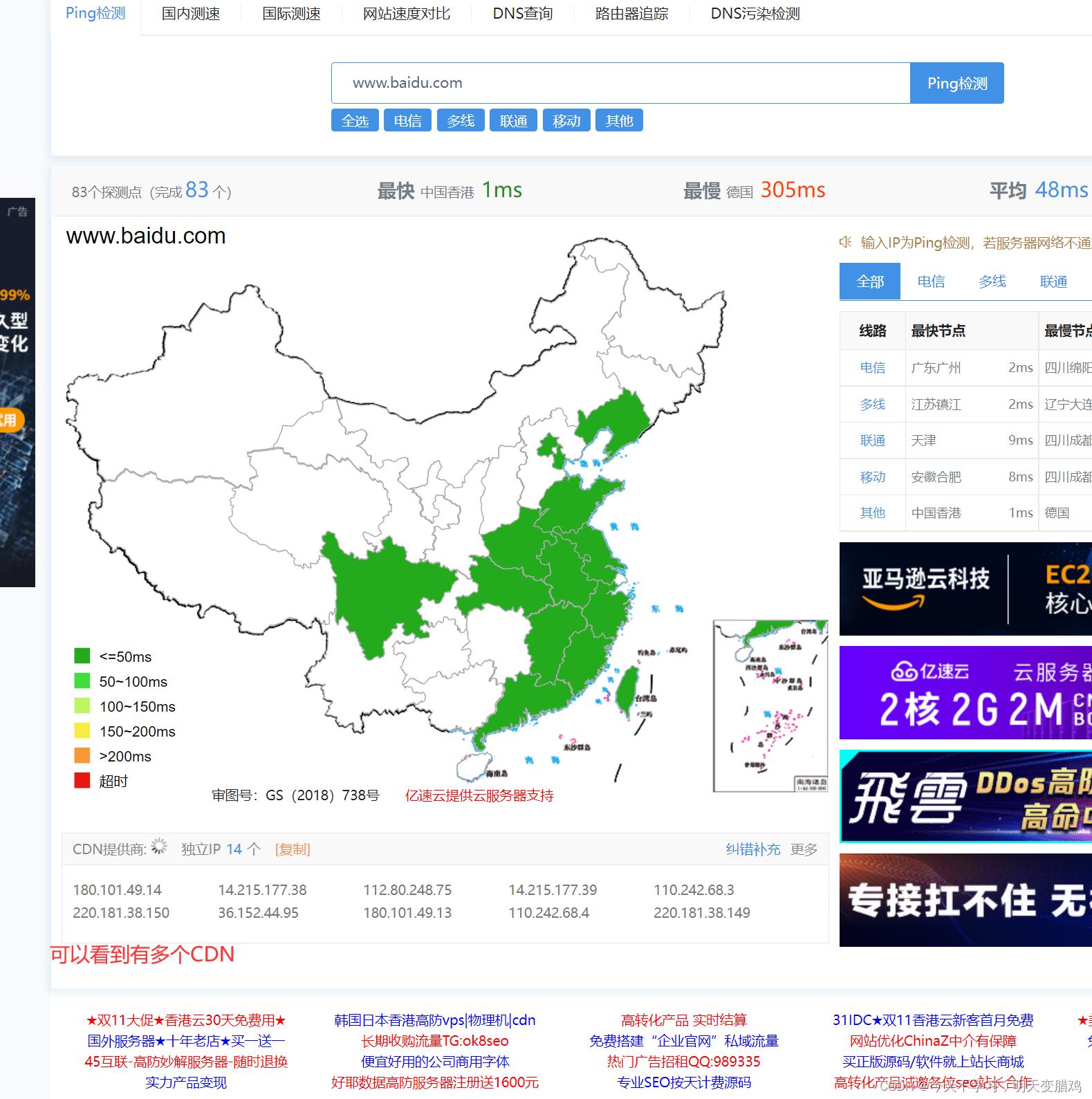
4.8 CDN信息
4.9 探测有没有WAF
直接使用sqlmap,探测有没有WAF连接
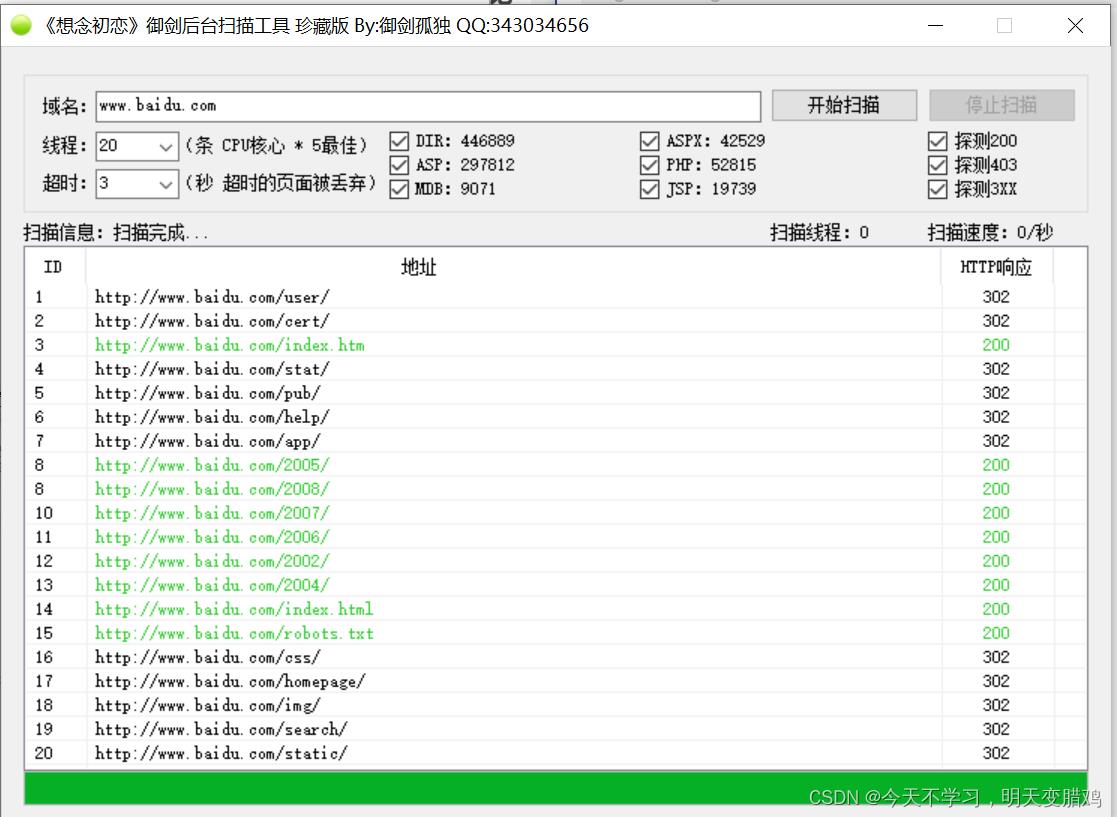
4.10 扫描敏感目录
御剑,和burpsuit等多种工具都可以扫描,扫描百度如下
5.搜索引擎利用
5.1 搜索引擎如何运行
- 数据预处理:
长度截断 => 大小写转化 => 去标点符号 => 简繁转换 => 数字归一化,中文数字、阿拉伯数字、罗马字 => 同义词改写 => 拼音改写
2.
处理:分词 => 关键词抽取 => 非法信息过滤
5.2 搜索技巧
- site:网站 (查找网站的所有信息,及返回此目标站点被搜索引擎抓取收录的所有内容)
- site:网站 keyword (此处可以将关键词设定为网站后台,管理后台,密码修改,密码找回等)
- link:网站
- related:网站 (返回所有与目标站点”相似”的页面,可能会包含一些通用程序的信息等)
- intext:把网页中的正文内容中的某个字符作为搜索条件(只对Goolgle有效)
- intitle:把网页标题中的某个字符作为搜索条件
- cache:搜索搜索引擎关于某些内容的缓存,可能会在过期内容发现敏感信息
- filetype:指定一个格式的文件作为搜索对象
- inurl:搜索包含指定字符的url
以上搜索技巧一般是组合使用,
5.3 快照
快照就是以前的某些东西不能够看了,通过快照可以看到
5.4 Github
在Github中,可能会存在源码泄露、AccessKey泄露、密码、服务器配置泄露等情况,常见的搜索技巧有
- language:语言
- 搜索内容 in:name (在名字中查找要搜索的内容)
- 搜索内容 in:description
- 搜索内容 in:readme
比如搜索vue项目,可以这样搜索 vue in:name或者 vue in:description 或者vue in:name,in:description
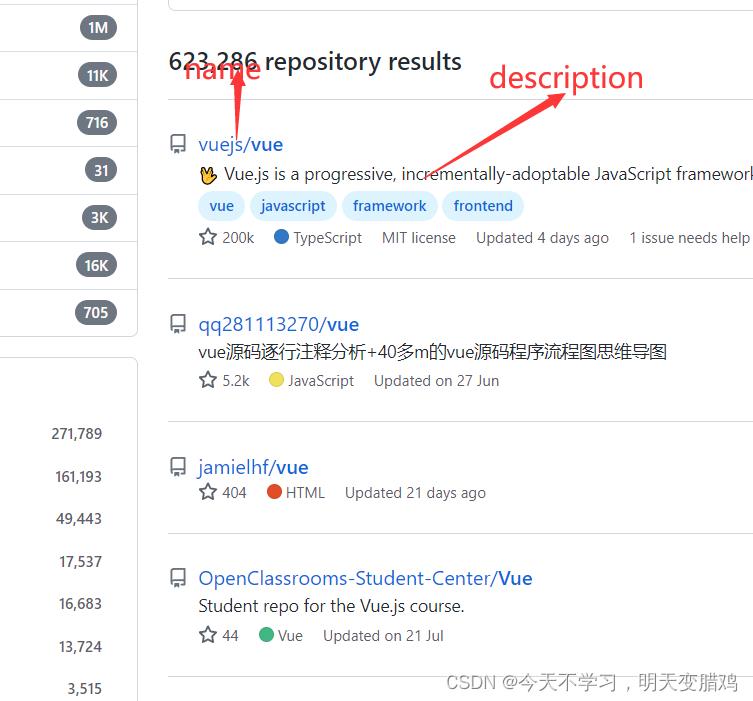
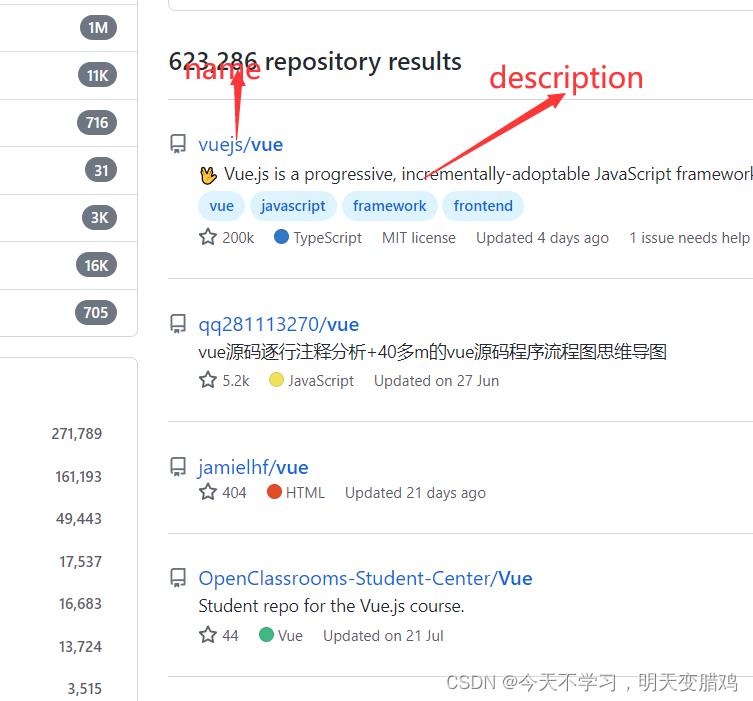
以下通过点赞数和克隆数量来查找
- stars 可以是:>= :<= …
- fork
列如:vue stars:>=100 fork:1000…2000
以上语法都可以组合使用
6.社会工程学
社会工程学总结一句就是打入敌人内部获取情报
6.1企业信息收集
一些网站如天眼查等,可以提供企业关系挖掘、工商信息、商标专利、企业年报等信息查询,可以提供企业的较为细致的信息。
公司主站中会有业务方向、合作单位等信息
6.2人员信息收集
针对人员的信息收集考虑对目标重要人员、组织架构、社会关系的收集和分析。其中重要人员主要指高管、系统管理员、开发、运维、财务、人事、业务人员的个人电脑。
人员信息收集较容易的入口点是网站,网站中可能包含网站的开发、管理维护等人员的信息。从网站联系功能中和代码的注释信息中都可能得到的所有开发及维护人员的姓名和邮件地址及其他联系方式。
在获取这些信息后,可以在Github/Linkedin等社交、招聘网站中进一步查找这些人在互联网上发布的与目标站点有关的一切信息,分析并发现有用的信息。
此外,可以对获取到的邮箱进行密码爆破的操作,获取对应的密码
6.3钓鱼
就是发送一些电子邮件,如果你点击了该电子邮件,就会中毒,这就是钓鱼,发一个鱼饵(邮件)诱使你去点击,你点击了你就上钩了。
以上是关于web安全之信息收集的主要内容,如果未能解决你的问题,请参考以下文章