Python值传递和引用传递(详细分析)
Posted 朝歌晚酒南栀雪
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python值传递和引用传递(详细分析)相关的知识,希望对你有一定的参考价值。
目录
6.1.2 源对象是可变数据类型(对象元素也不可变的情况下)
1. 形参与实参
我们先来重温一组语法:
- 形参:方法被调用时需要传递进来的参数,如:func(int a)中的a,它只有在func被调用期间a才有意义,也就是会被分配内存空间,在方法func执行完成后,a就会被销毁释放空间,也就是不存在了
- 实参:方法被调用时是传入的实际值,它在方法被调用前就已经被初始化并且在方法被调用时传入。
举个栗子:
def func(b):
b = 20
print(b)
if __name__ == '__main__':
a = 10 # 变量
func(a)例子中
a=10 中的 a 在被调用之前就已经创建,在调用func方法时,他被当做参数传入,所以这个a是实参。
而 func(b) 中的 b 只有在 func 被调用时它的生命周期才开始,而在func调用结束之后,它也随之被释放掉,所以这个b是形参。
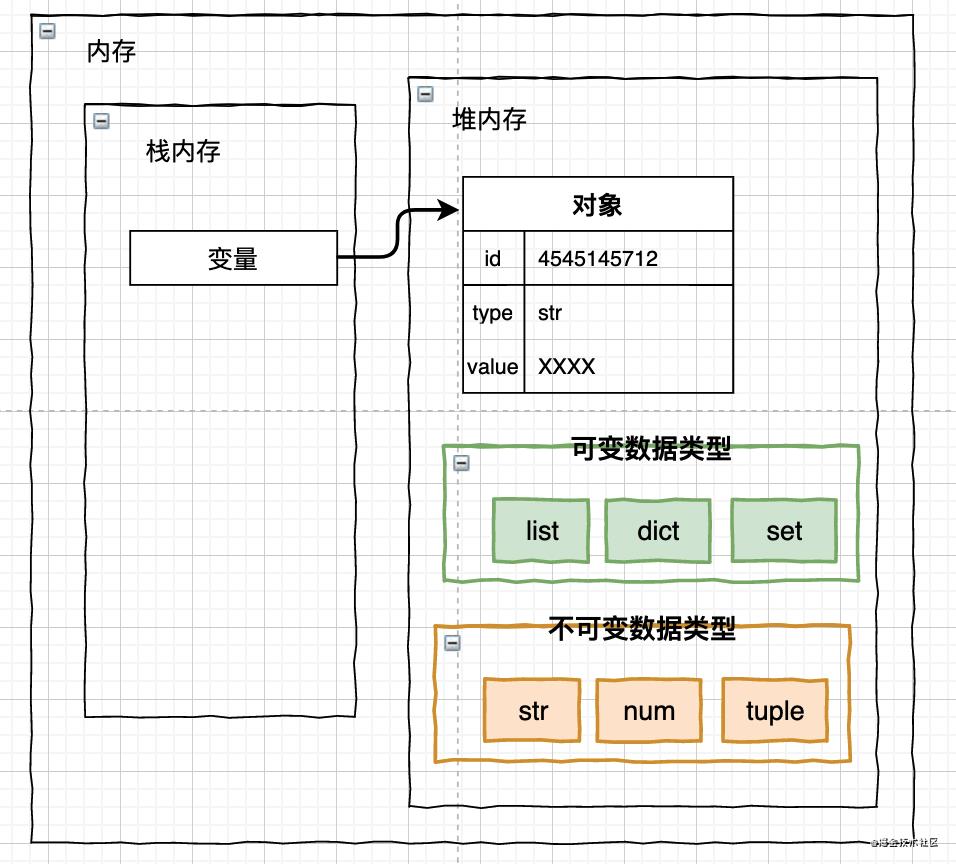
2. Python的数据类型
所谓数据类型,是编程语言中对内存的一种抽象表达方式,我们知道程序是由代码文件和静态资源组成,在程序被运行前,这些代码存在在硬盘里,程序开始运行,这些代码会被转成计算机能识别的内容放到内存中被执行。
因此
数据类型实质上是用来定义编程语言中相同类型的数据的存储形式,也就是决定了如何将代表这些值的位置存储到计算机的内存中。
所以,数据在内存中的存储,是根据数据类型来划定存储形式和存储位置的。
那么
Python的数据类型有哪些?
- 可变数据类型:List(列表)、Dictionary(字典)、Set(集合)
- 不可变数据类型:String(字符串)、Number(数字)、Tuple(元组)
3.Python变量及其赋值
3.1 不可变对象赋值
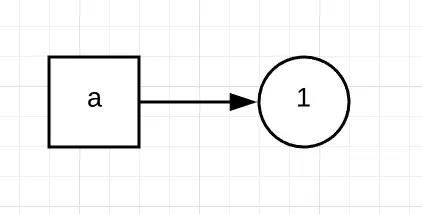
来看下面的一段python代码:
a = 1
b = a
c = (1, 2, 3)
d = c
print(id(a), id(b))
print(id(c), id(d))
a = a + 1
print(id(a), id(b))
4298548768 4298548768
4298548800 4298548768首先将1赋值于a,即a指向了1这个对象,如下面的流程图所示
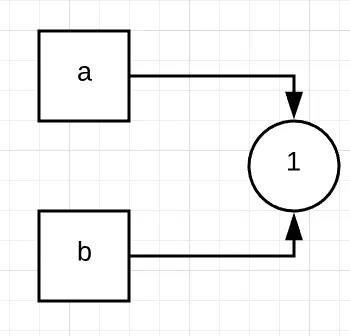
接着b = a则表示,让变量b也同时指向1这个对象
注意:
Python里的对象可以被多个变量所指向或引用
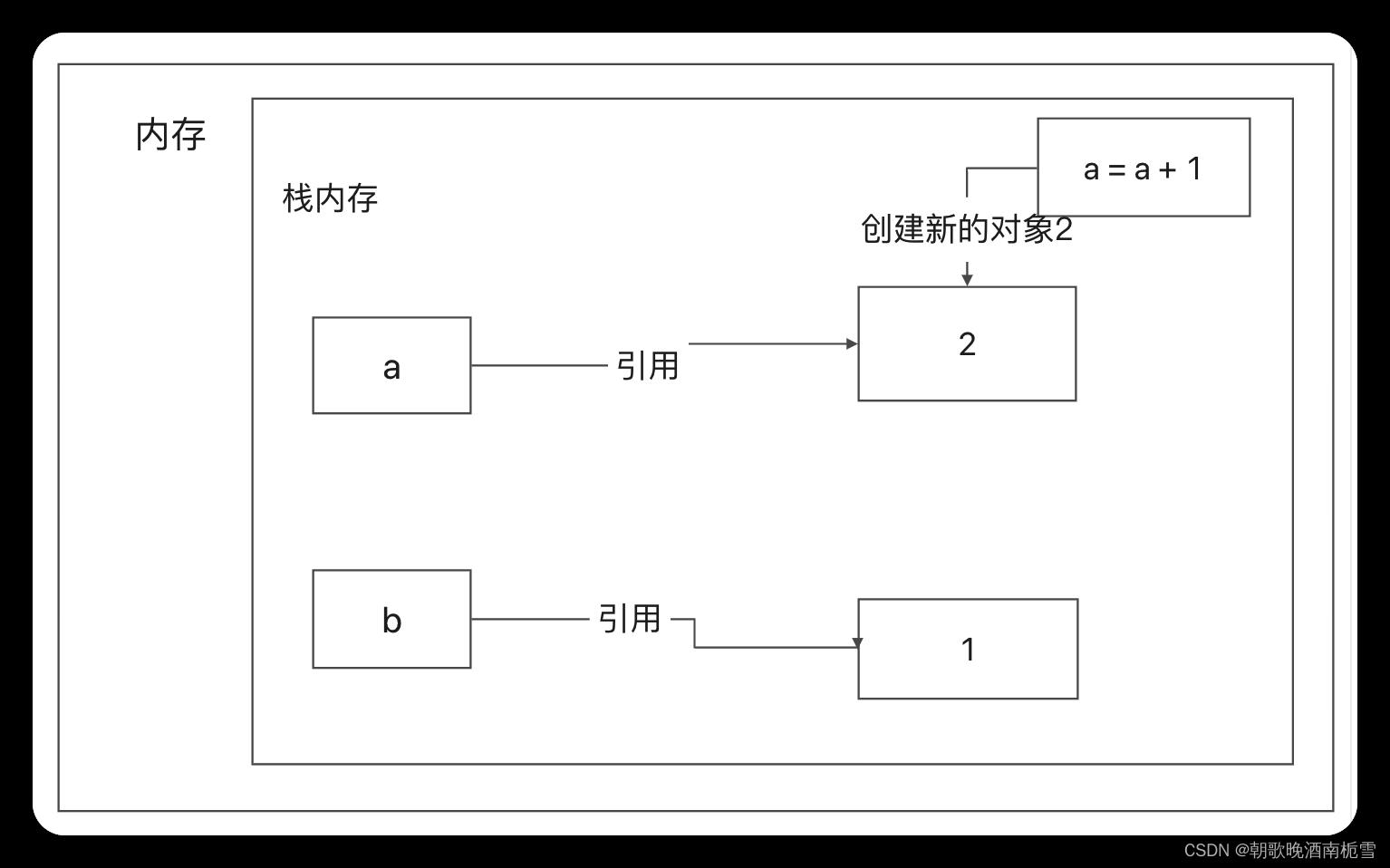
最后执行 a = a + 1
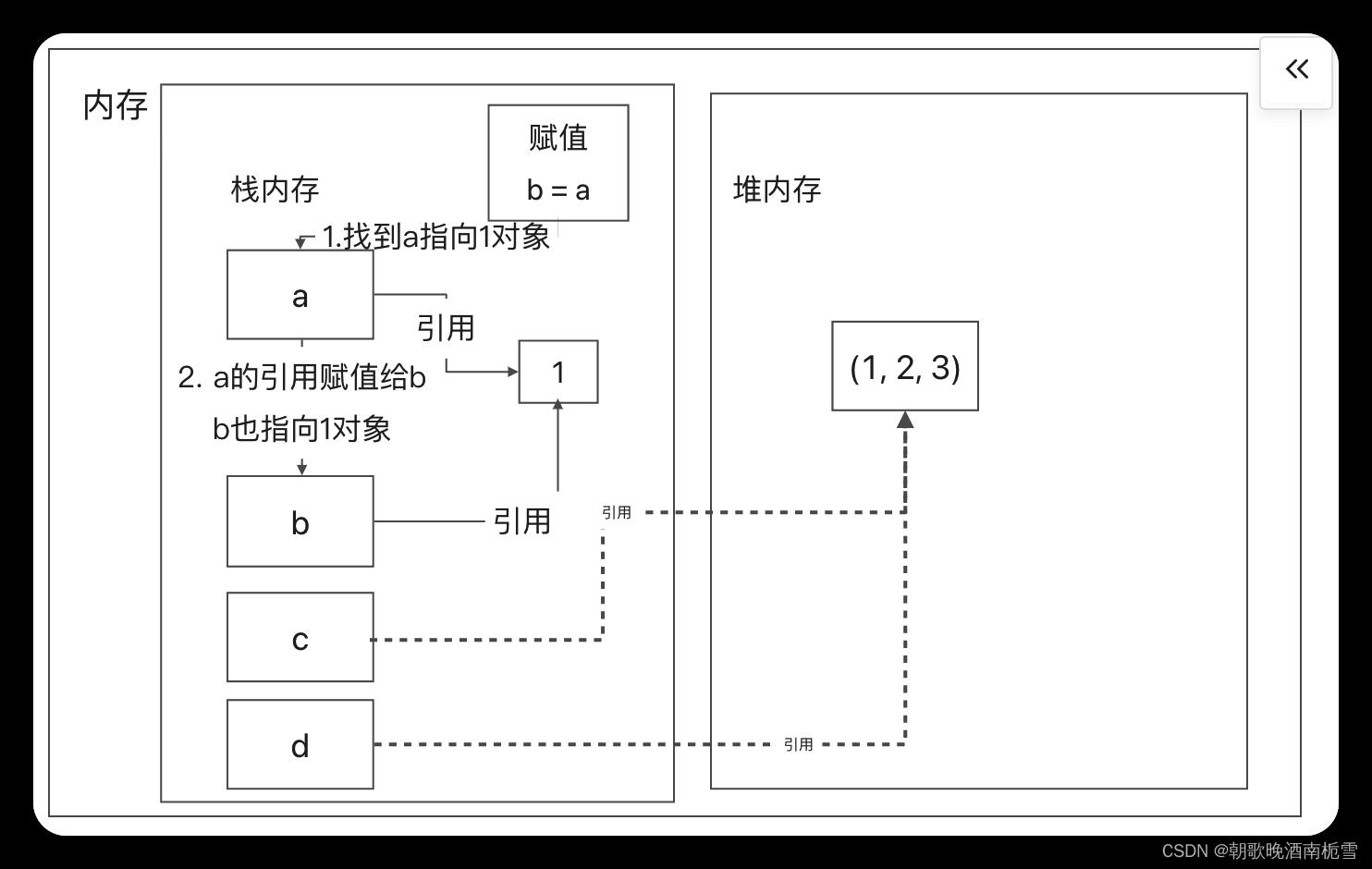
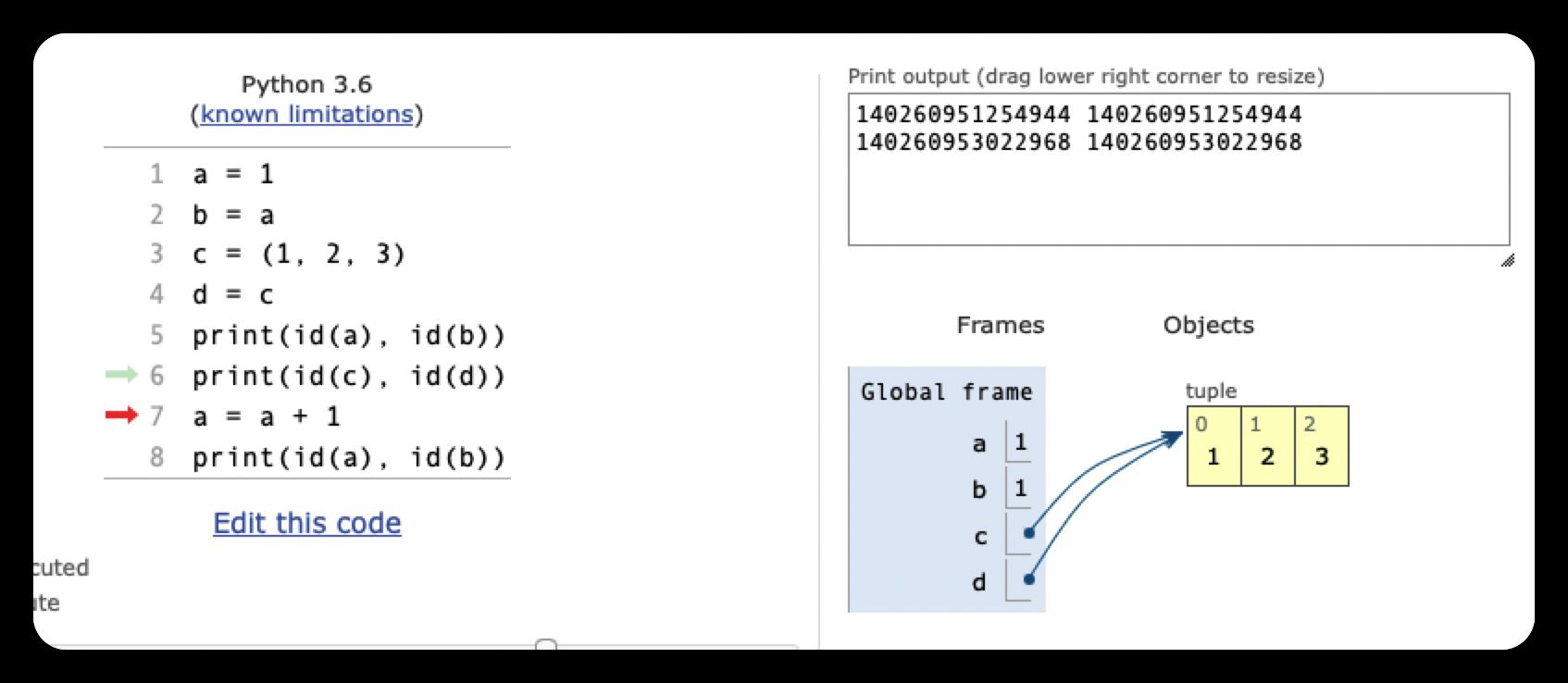
需要注意的是,Python的数据类型,例如整型(int)、字符串(string)等等是不可变的。所以,a = a + 1并不是让a的值增加 1,而是表示重新创建了一个新的值为2的对象,并让a指向它。但是b 仍然不变,仍然指向1这个对象
因此,最后的结果是,a的值变成了2,而b的值不变仍然是1
通过这个例子可以看到,这里的a和b,开始只是两个指向同一个对象的变量而已,或者也可以把它们想象成同一个对象的两个名字。简单的赋值b = a,并不表示重新创建了新对象,只是让同一个对象被多个变量指向或引用
同时,指向同一个对象,也并不意味着两个变量就被绑定到了一起。如果给其中一个变量重新赋值,并不会影响其他变量的值
3.2 可变对象赋值
明白了上面不可变对象赋值这个基本的变量赋值例子,再来看一个列表的例子:
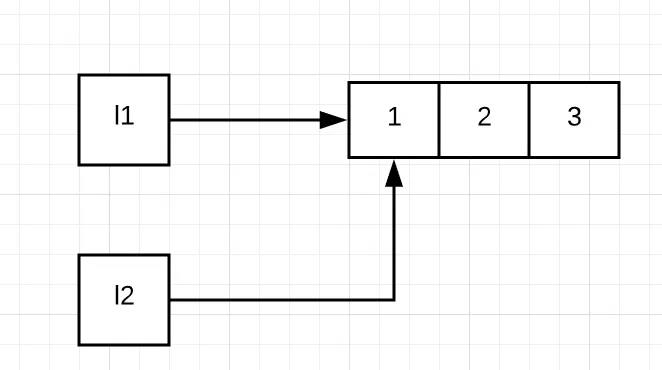
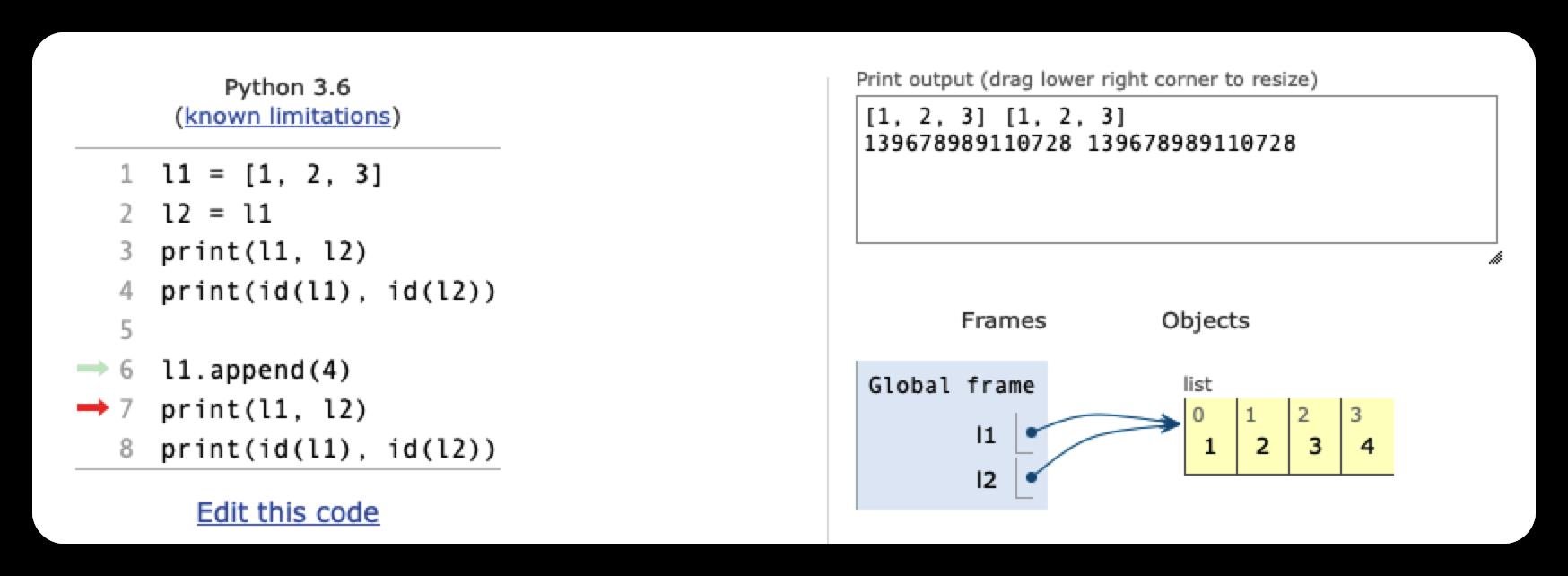
l1 = [1, 2, 3]
l2 = l1
print(l1, l2)
print(id(l1), id(l2))
l1.append(4)
print(l1, l2)
print(id(l1), id(l2))
[1, 2, 3] [1, 2, 3]
4374317312 4374317312
[1, 2, 3, 4] [1, 2, 3, 4]
4374317312 4374317312同样的,首先让列表l1指向了 [1, 2, 3] 这个对象,然后将这个对象的引用传递给l2,这样 l1 和 l2 同时指向 [1, 2, 3] 这个对象
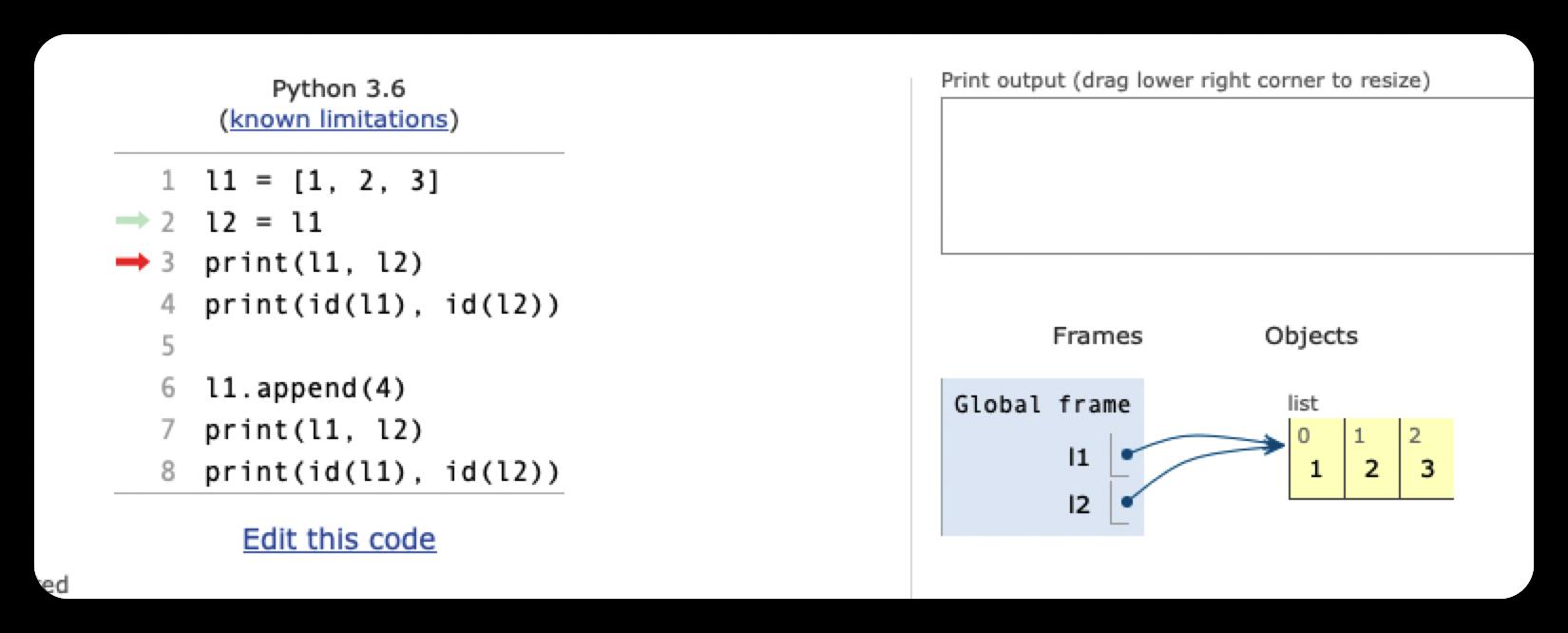
由于列表是可变的,所以 l1.append(4) 不会创建新的列表,只是在原列表的末尾插入了元素4,变成 [1, 2, 3, 4] 。由于l1和l2同时指向这个列表,所以列表的变化会同时反映在l1和l2这两个变量上,那么,l1和l2的值就同时变为了[1, 2, 3, 4]
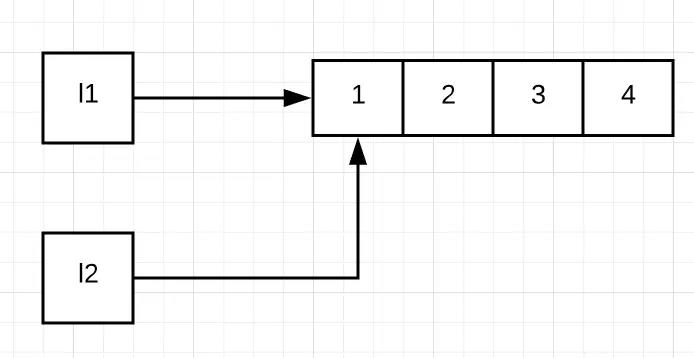
3.3 变量删除
需要注意的是,Python里的变量可以被删除,但是对象无法被删除。比如下面的代码:
l = [1, 2, 3]
del ldel l 删除了l这个变量,之后无法访问l,但是对象[1, 2, 3]仍然存在
Python程序运行时,其自带的垃圾回收系统会跟踪每个对象的引用。如果 [1, 2, 3] 除了l外,还在其他地方被引用,那就不会被回收,反之则会被回收
3.4 变量赋值总结
由此可见,在Python中:
- 变量的赋值,只是表示让变量指向了某个对象,并不表示拷贝对象给变量,而一个对象,可以被多个变量所指向
- 可变对象(列表,字典,集合等等)的改变,会影响所有指向该对象的变量
- 对于不可变对象(字符串、整型、元组等等),所有指向该对象的变量的值总是一样的,也不会改变。但是通过某些操作(+= 等等)更新不可变对象的值时,会返回一个新的对象
- 变量可以被删除,但是对象无法被删除
4.Python函数的参数传递
4.1 参数传递定义
Remember that arguments are passed by assignment in Python. Since assignment just creates references to objects, there’s no alias between an argument name in the caller and callee, and so no call-by-reference per Se.
Python的参数传递是赋值传递(pass by assignment),或者叫作对象的引用传递(pass by object reference)
Python里所有的数据类型都是对象,所以参数传递时,只是让新变量与原变量指向相同的对象而已,并不存在值传递或是引用传递一说
4.2 不可变对象的参数传递
看下面这个例子:
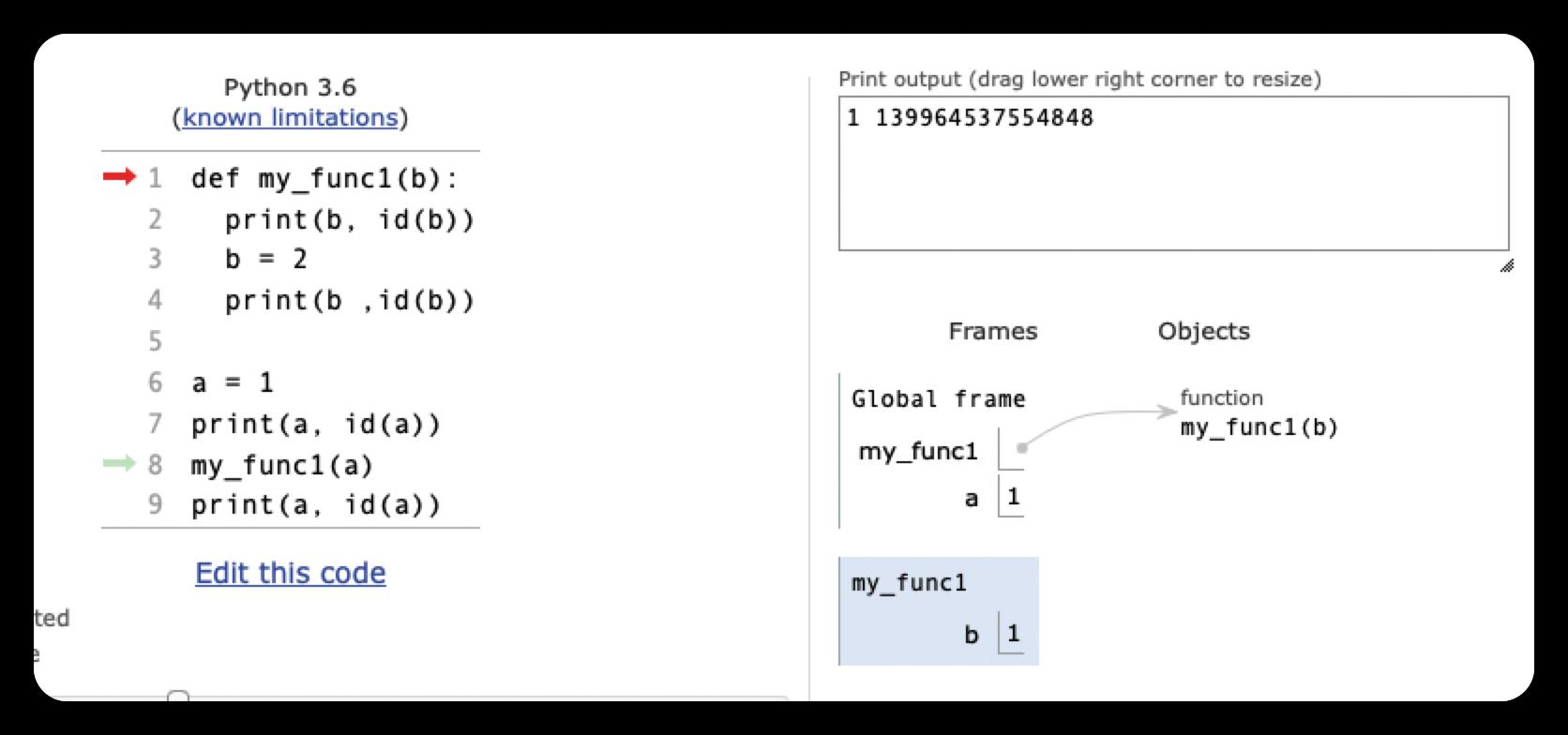
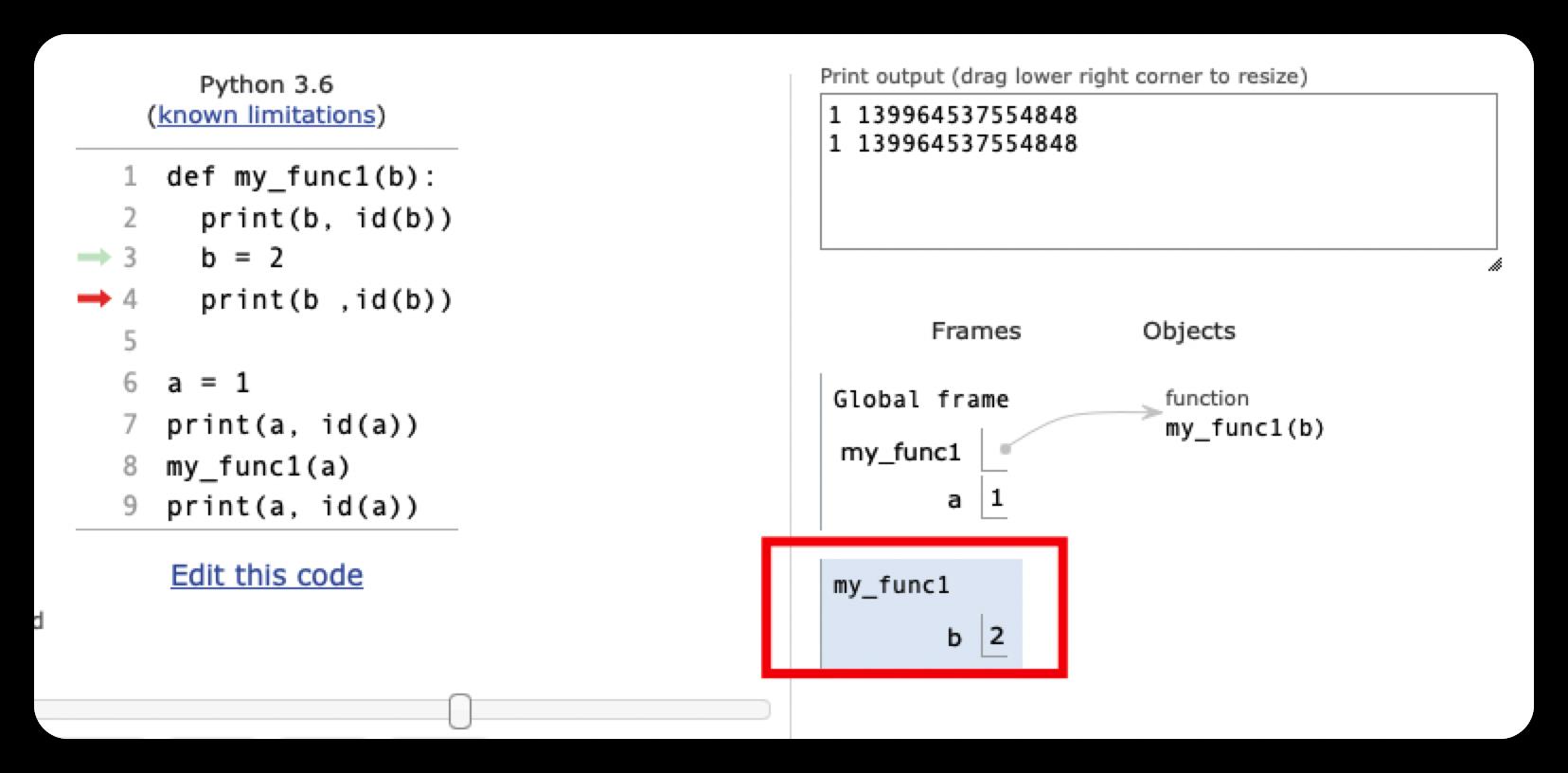
def my_func1(b):
print(b, id(b))
b = 2
print(b ,id(b))
a = 1
print(a, id(a))
my_func1(a)
print(a, id(a))
1 4346537504
1 4346537504
2 4346537536
1 4346537504这里的参数传递,使变量a和b同时指向了1这个对象。但当执行到b = 2时,系统会重新创建一个值为2的新对象并让b指向它,而a仍然指向1这个对象。所以,a的值不变,仍然为1
那么对于上述例子的情况,是不是就没有办法改变a的值了呢?
答案当然是否定的
只需稍作改变,让函数返回新变量赋给 a。这样,a就指向了一个新的值为2的对象,a的值也因此变为2
def my_func2(b):
print(b, id(b))
b = 2
print(b ,id(b))
return b
a = 1
print(a, id(a))
a = my_func2(a)
print(a, id(a))
1 4334462496
1 4334462496
2 4334462528
2 4334462528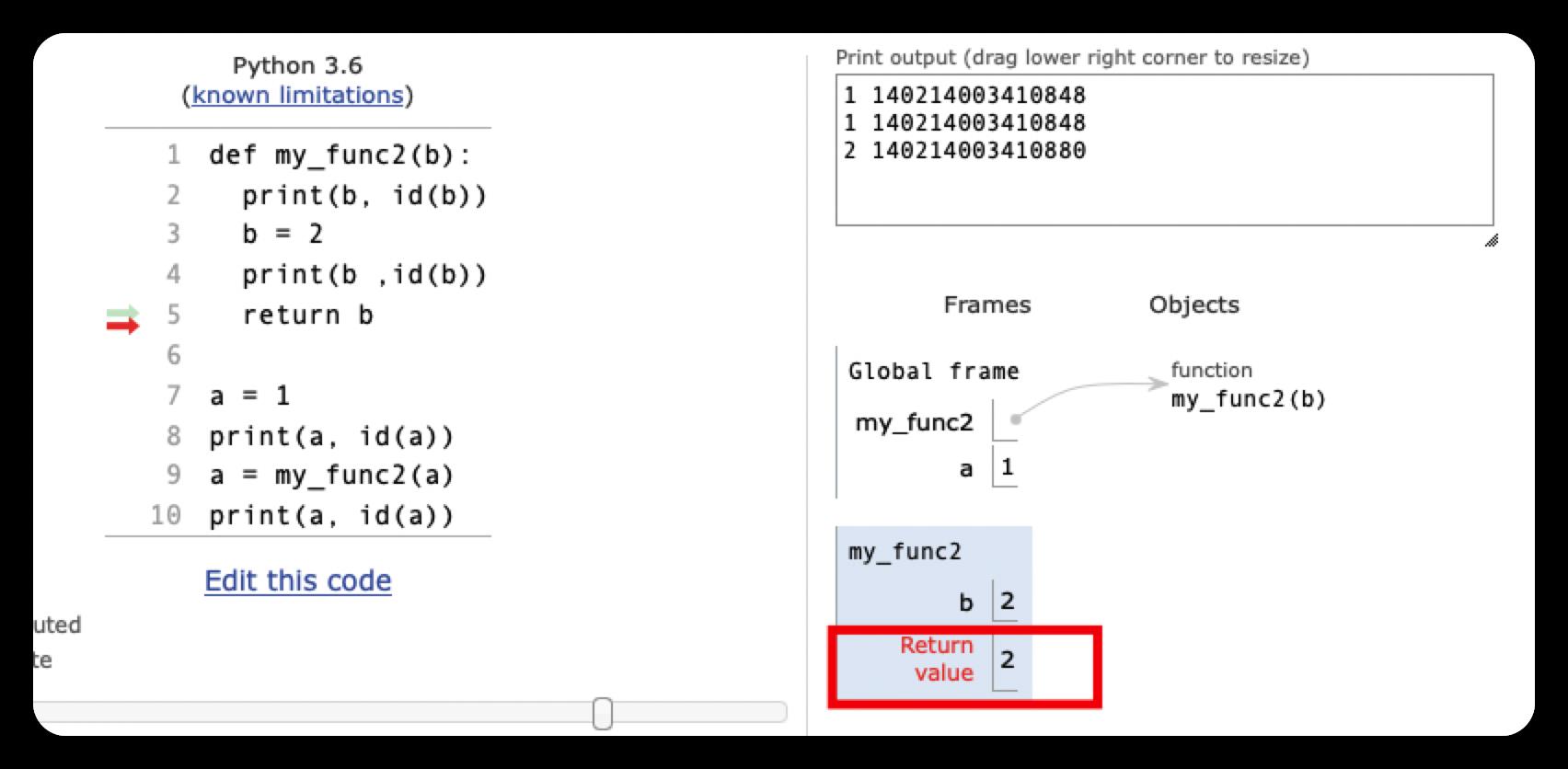
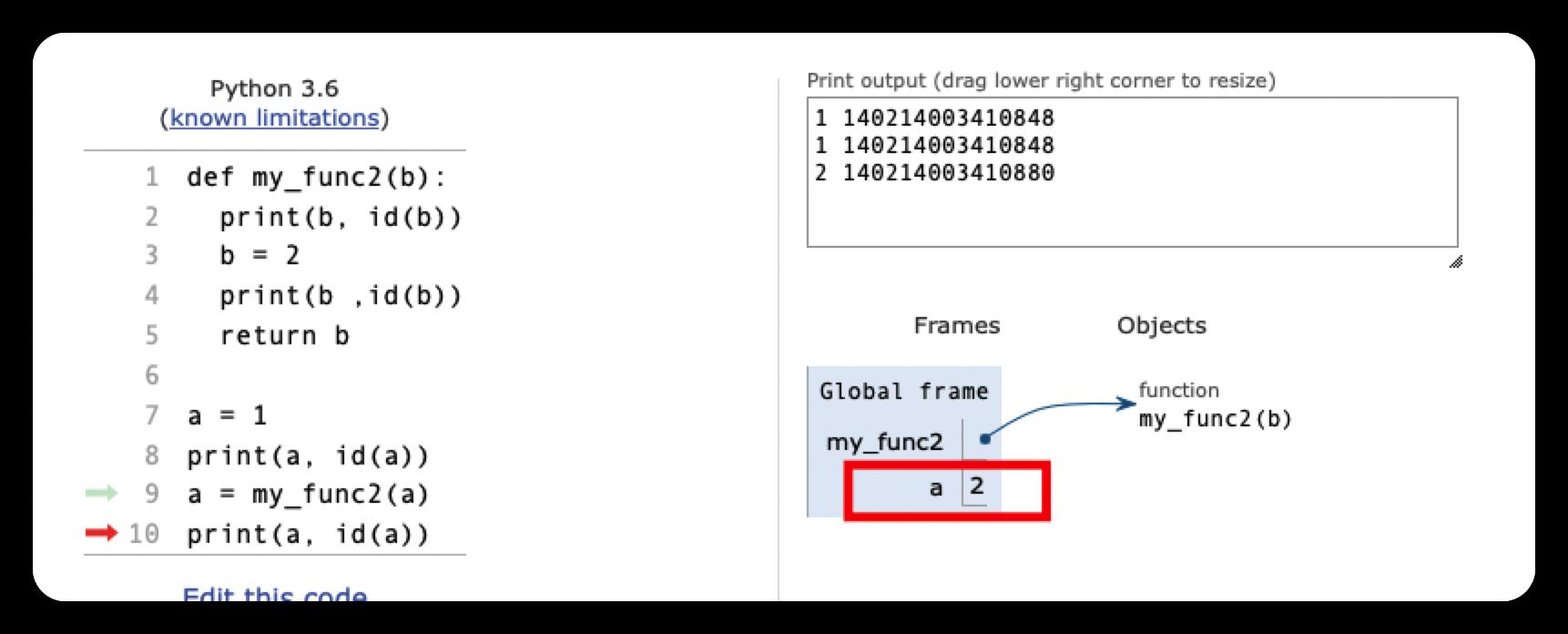
4.3 可变对象的参数传递
不过,当可变对象当作参数传入函数里的时候,改变可变对象的值,就会影响所有指向它的变量。比如下面的例子:
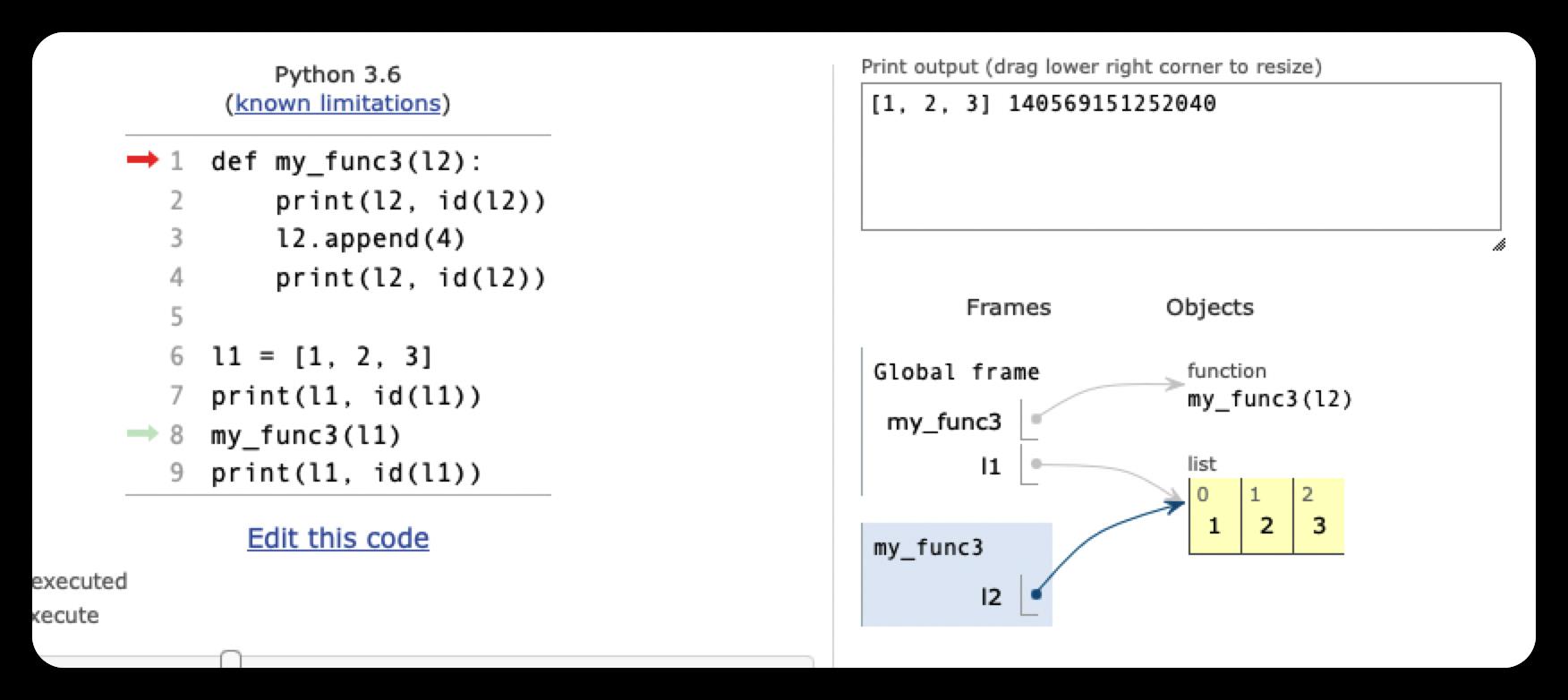
def my_func3(l2):
print(l2, id(l2))
l2.append(4)
print(l2, id(l2))
l1 = [1, 2, 3]
print(l1, id(l1))
my_func3(l1)
print(l1, id(l1))
[1, 2, 3] 4348477696
[1, 2, 3] 4348477696
[1, 2, 3, 4] 4348477696
[1, 2, 3, 4] 4348477696这里l1和l2先是同时指向值为 [1, 2, 3] 的列表。不过,由于列表可变,执行append()函数对其末尾加入新元素4时,变量l1和l2的值也都随之改变,但是自始至终他们指向的对象都没有改变,都是同一个对象
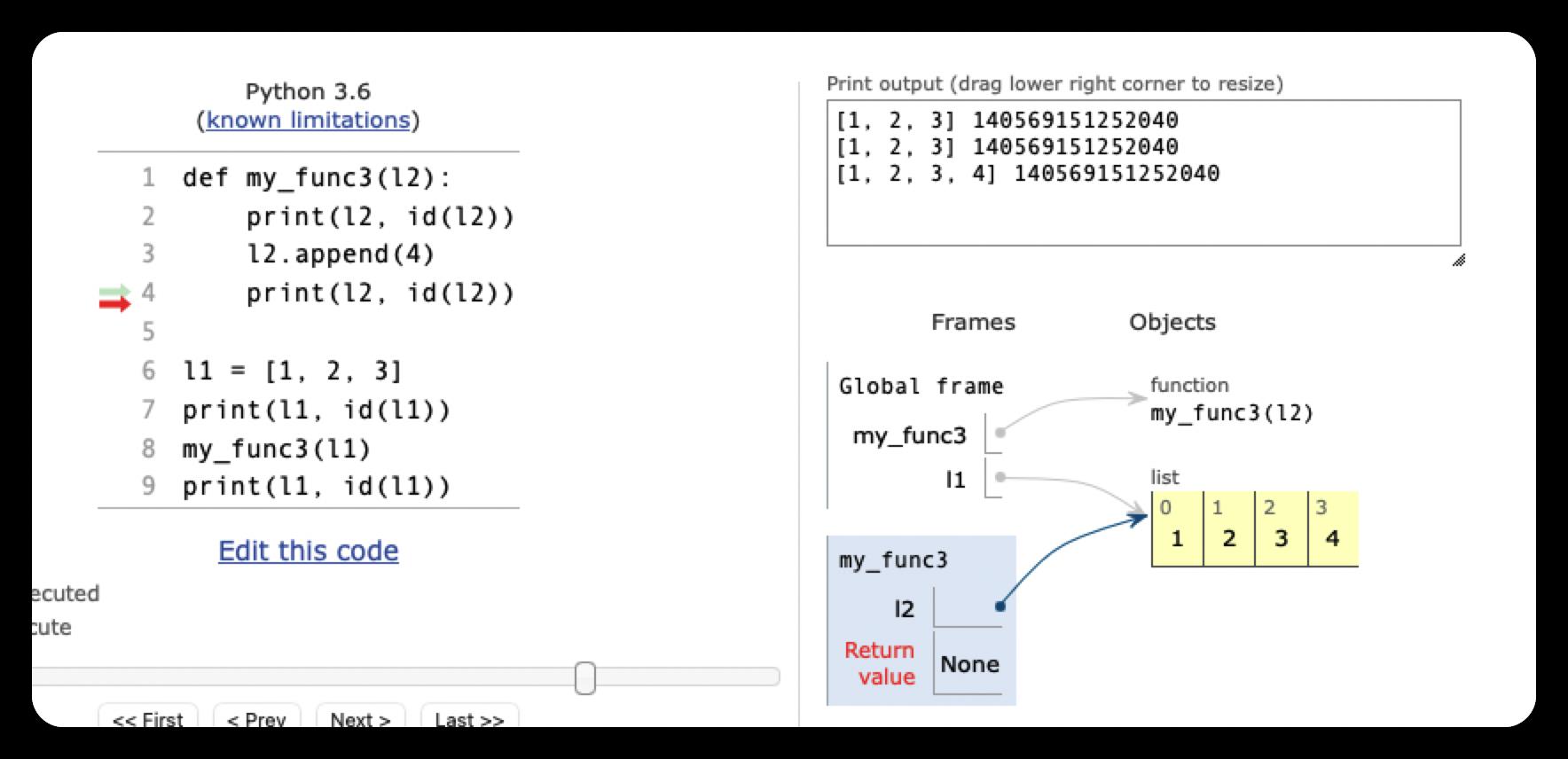
但是,下面这个例子,看似都是给列表增加了一个新元素,却得到了明显不同的结果
def my_func4(l2):
print(l2, id(l2))
l2 = l2 + [4]
print(l2, id(l2))
l1 = [1, 2, 3]
print(l1, id(l1))
my_func4(l1)
print(l1, id(l1))
[1, 2, 3] 4349149440
[1, 2, 3] 4349149440
[1, 2, 3, 4] 4349150400
[1, 2, 3] 4349149440为什么l1仍然是[1, 2, 3],而不是 [1, 2, 3, 4] 呢?
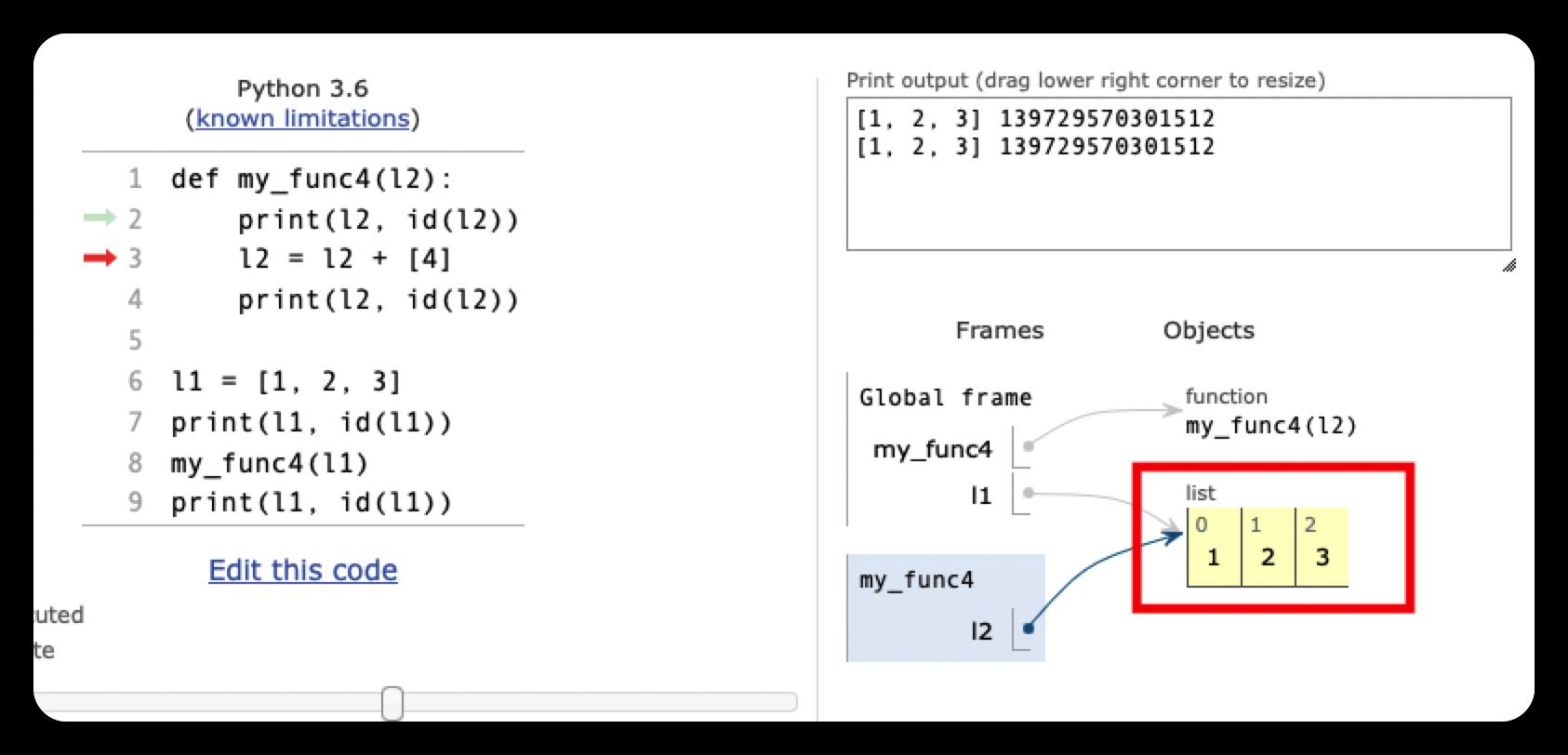
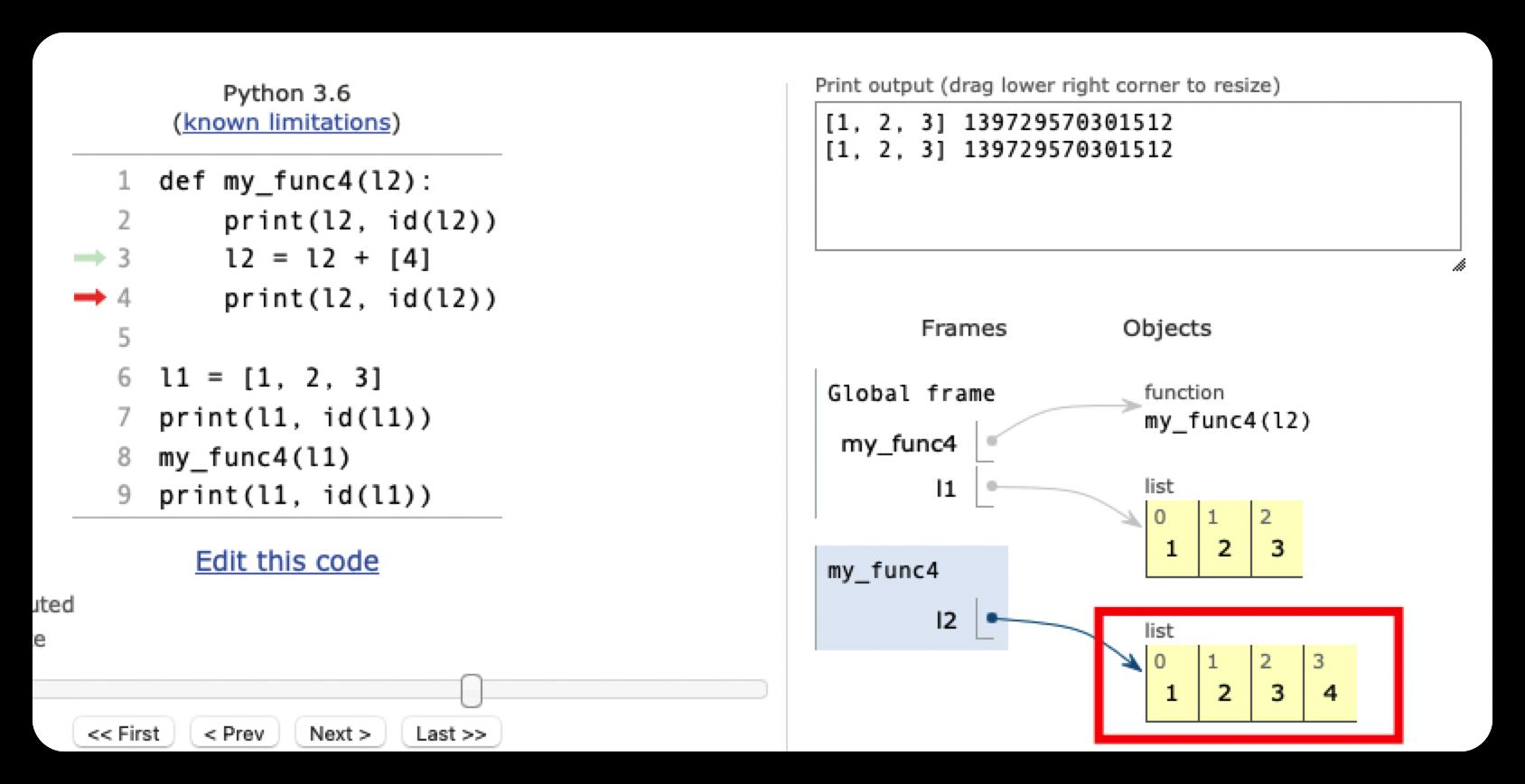
要注意,这里 l2 = l2 + [4] ,表示创建了一个末尾加入元素 4的新列表,并让l2指向这个新的对象。最后,当my_fun4函数执行结束后,对应的l2也被释放掉了,这个过程与l1无关,因此l1的值不变。
当然,同样的,如果要改变l1的值,就得让上述函数返回一个新列表,再赋予l1即可:
def my_func5(l2):
print(l2, id(l2))
l2 = l2 + [4]
print(l2, id(l2))
return l2
l1 = [1, 2, 3]
print(l1, id(l1))
l1 = my_func5(l1)
print(l1, id(l1))
[1, 2, 3] 4341862592
[1, 2, 3] 4341862592
[1, 2, 3, 4] 4341863488
[1, 2, 3, 4] 4341863488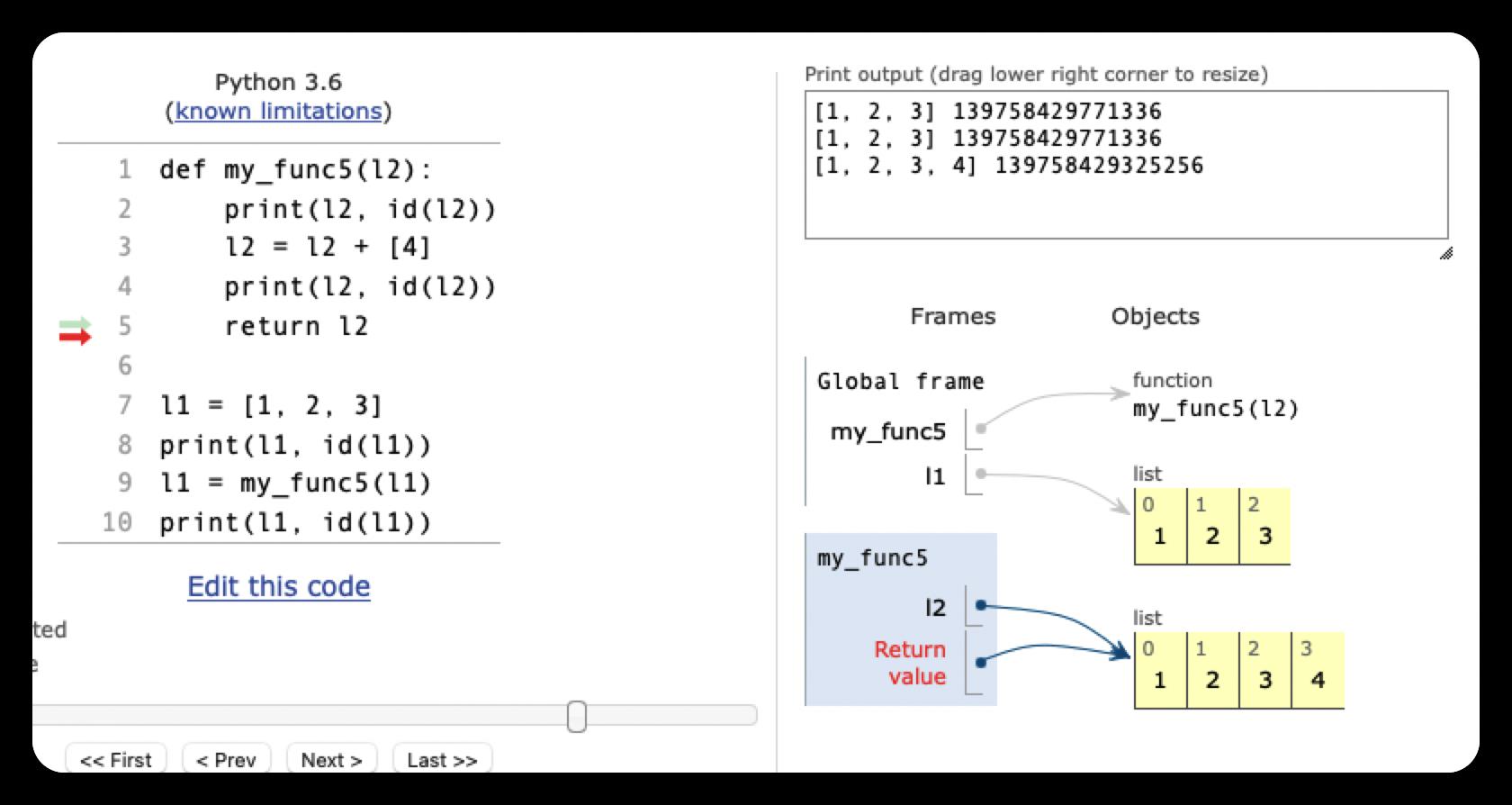

这里尤其要记住的是,改变变量和重新赋值的区别:
- my_func3()中单纯地改变了对象的值,因此函数返回后,所有指向该对象的变量都会被改变
- my_func4()中创建了新的对象,并赋值给一个局部变量,因此原变量仍然不变
至于my_func3()和5的用法,两者虽然写法不同,但实现的功能一致
不过,在实际工作应用中,往往倾向于类似my_func5()的写法,添加返回语句。这样更简洁且不易出错
5.总结
和其他语言不同的是,Python中参数的传递既不是值传递,也不是引用传递,而是赋值传递,或者是叫对象的引用传递
需要注意的是,这里的赋值或对象的引用传递,不是指向一个具体的内存地址,而是指向一个具体的对象
- 如果对象是可变的,当其改变时,所有指向这个对象的变量都会改变
- 如果对象不可变,简单的赋值只能改变其中一个变量的值,其余变量则不受影响
通过一个函数来改变某个变量的值,通常有两种方法:
- 第一种是直接将可变数据类型(比如列表,字典,集合)当作参数传入,直接在其上修改
- 第二种是创建一个新变量来保存修改后的值,然后将其返回给原变量
在实际工作中更倾向于使用后者,因为其表达清晰明了,不易出错
6 不可变与可变对象赋值对比:
6.1 单层源对象
6.1.1 源对象是不可变数据类型(对象元素也不可变)
下面的代码中, l1、l2 和 l3 都指向同一个对象吗?
l1 = 1
l2 = 1
l3 = l2
print(id(l1), id(l2), id(l3))
4380304928 4380304928 4380304928l1 = (1, 2, 3)
l2 = (1, 2, 3)
l3 = l2
print(id(l1), id(l2), id(l3))
4349798848 4349798848 4349798848l1 = "123"
l2 = "123"
l3 = l2
print(id(1), id(2), id(3))
4315664432 4315664432 4315664432可以看到,对于不可变对象(对象元素也不可变情况下),对象本身在堆里被创建,其它变量都指向对应的对象,
由于对于不可变对象,如果我们改变某个变量的值,他会在堆空间找是否存在该对象,如果存在,该变量会指向该对象,如果不存在,则新分配空间,创建对象,然后再指向这个新的对象
6.1.2 源对象是可变数据类型(对象元素也不可变的情况下)
下面的代码中, l1、l2 和 l3 都指向同一个对象吗?
l1 = [1, 2, 3]
l2 = [1, 2, 3]
l3 = l2
print(id(l1), id(l2), id(l3))
print(id(1))
print(id(l1[0]), id(l2[0]), id(l3[0]))
4339722368 4339720768 4339720768
4334331424
4334331424 4334331424 4334331424可以看到,对于这个可变对象(对象元素不可变情况下),l1创建完列表对象 [1, 2, 3] 之后,l2也创建了一个新的对象[1, 2, 3],所以l1和l2指向的是不同的对象,由于赋值操作 l3 = l2,导致l3的引用与l2一致,都指向了同一个对象。
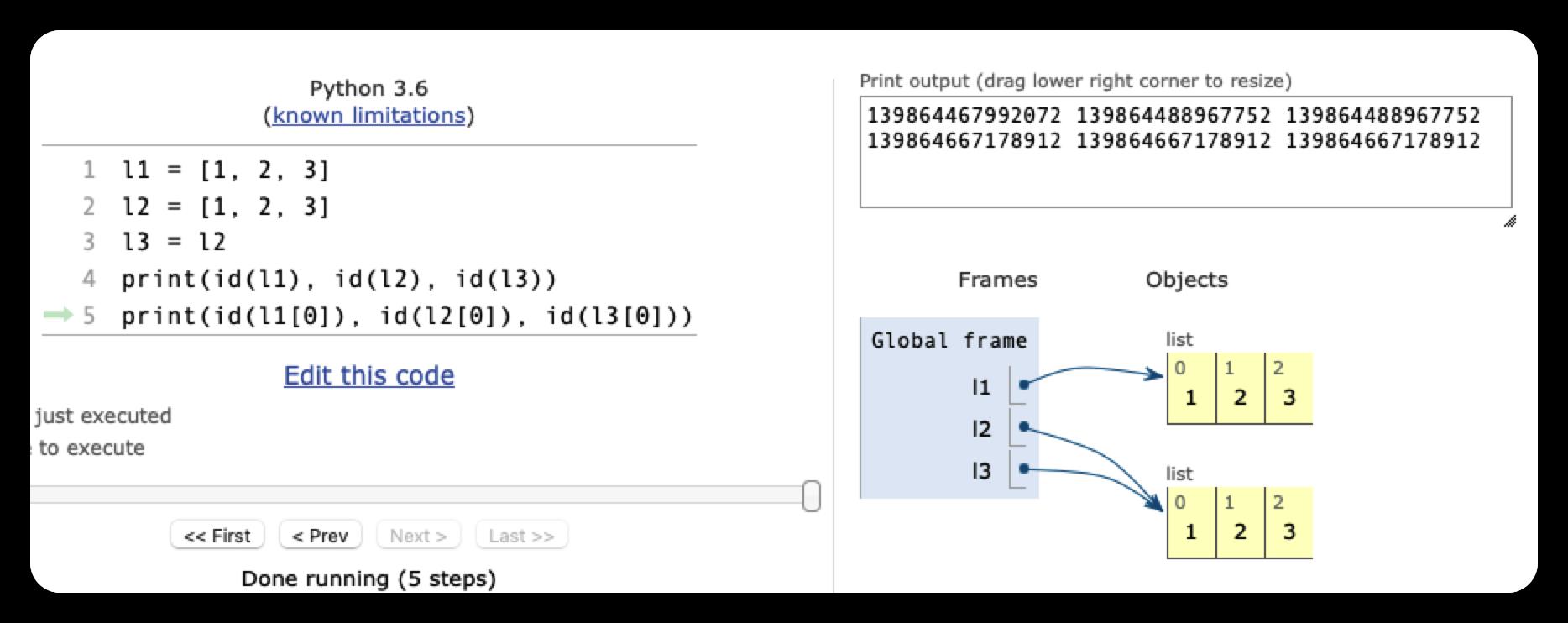
但是我们看到 l1 和 l2 变量各自指向的对象,两个对象里面的元素,确是指向具体的值1,2,3,且指向的是同一个值,所以可以说,l1 和 l2变量各自指向的列表对象,列表对象各位置元素指向了具体的值,最终结果都是不可变的值,其他都是引用
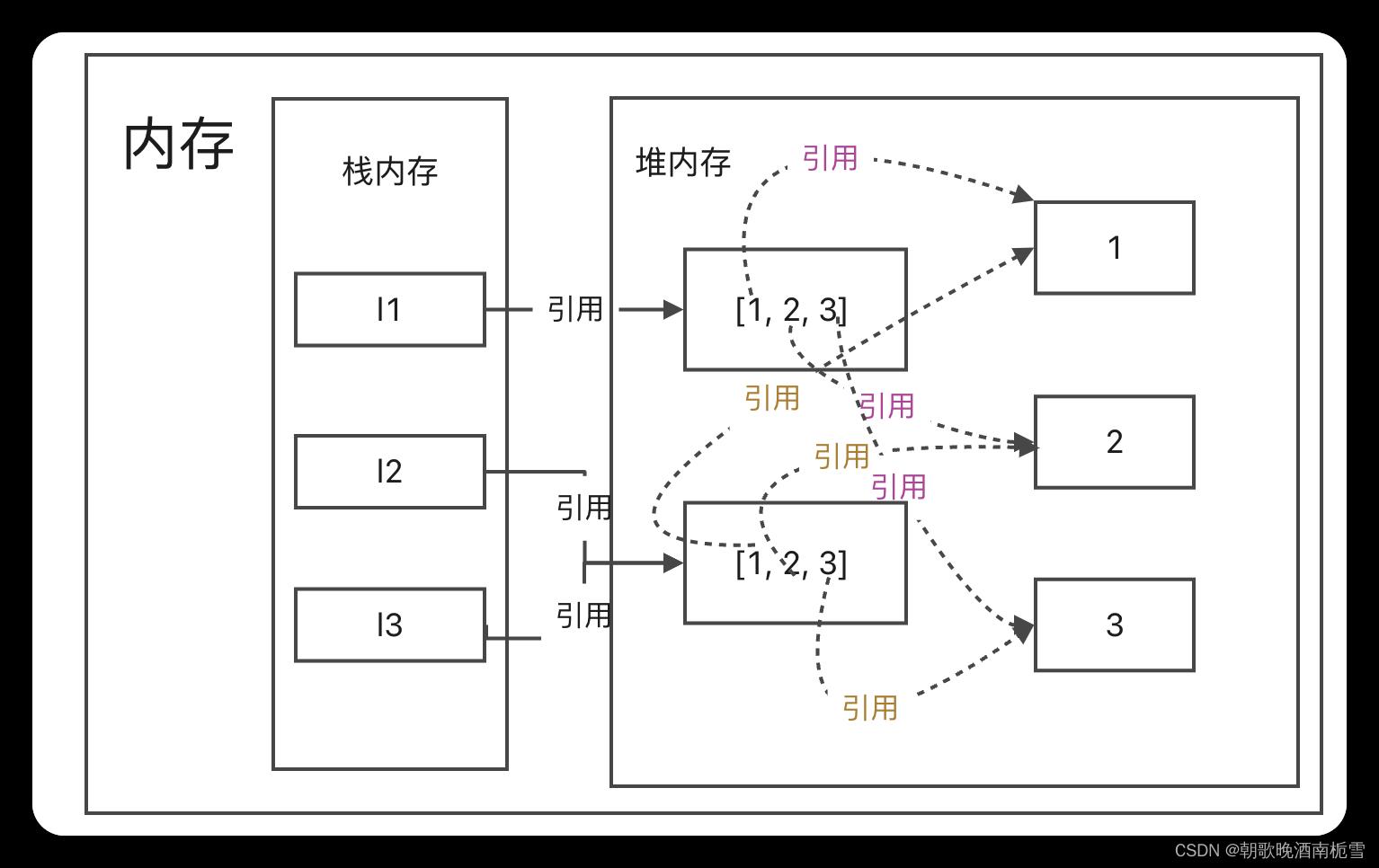
6.2 多层源对象
6.2.1 源对象是不可变数据类型
6.2.1.1 源对象是不可变数据类型(源对象元素可变情况)
l1 = ([1, 2, 3], 2, 3)
l2 = ([1, 2, 3], 2, 3)
l3 = l2
print(id(l1), id(l2), id(l3))
print(id(l1[0]), id(l2[0]), id(l3[0]))
print(id(l1[1]), id(l2[1]), id(l3[1]))
4313229824 4313387840 4313387840
4313303360 4313301760 4313301760
4307920448 4307920448 4307920448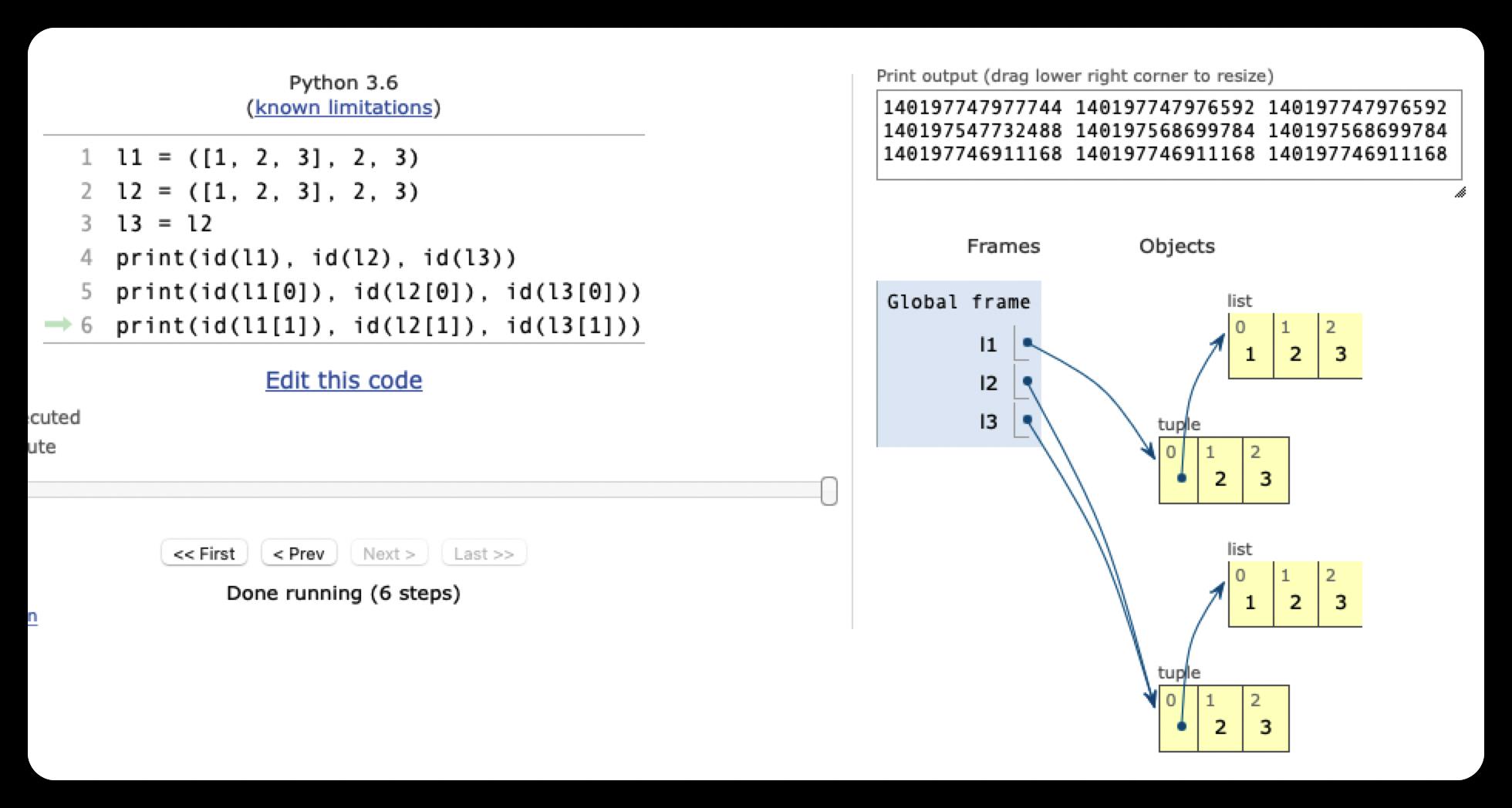
可以看到,当源对象是不可变数据类型时,如果源对象里元素存在可变类型数据时,多层原对象在创建对象的时候,不会直接引用之前的对象地址,而是会重新分配空间,创建一个新的对象,如上面的l1和l2。
但是赋值操作不受这个影响,还是会直接拷贝源对象的地址给新的变量
6.2.1.2 源对象是不可变数据类型(源对象元素不可变情况)
l1 = ((1, 2, 3), (1, 2, 3), 3)
l2 = ((1, 2, 3), (1, 2, 3), 3)
l3 = l2
print(id(l1), id(l2), id(l3))
print(id(l1[0]), id(l2[0]), id(l3[0]))
print(id(l1[1]), id(l2[1]), id(l3[1]))
print(id(3))
print(id(l1[2]), id(l2[2]), id(l3[2]))
4341183808 4341183808 4341183808
4341573952 4341573952 4341573952
4341573952 4341573952 4341573952
4337002080
4337002080 4337002080 4337002080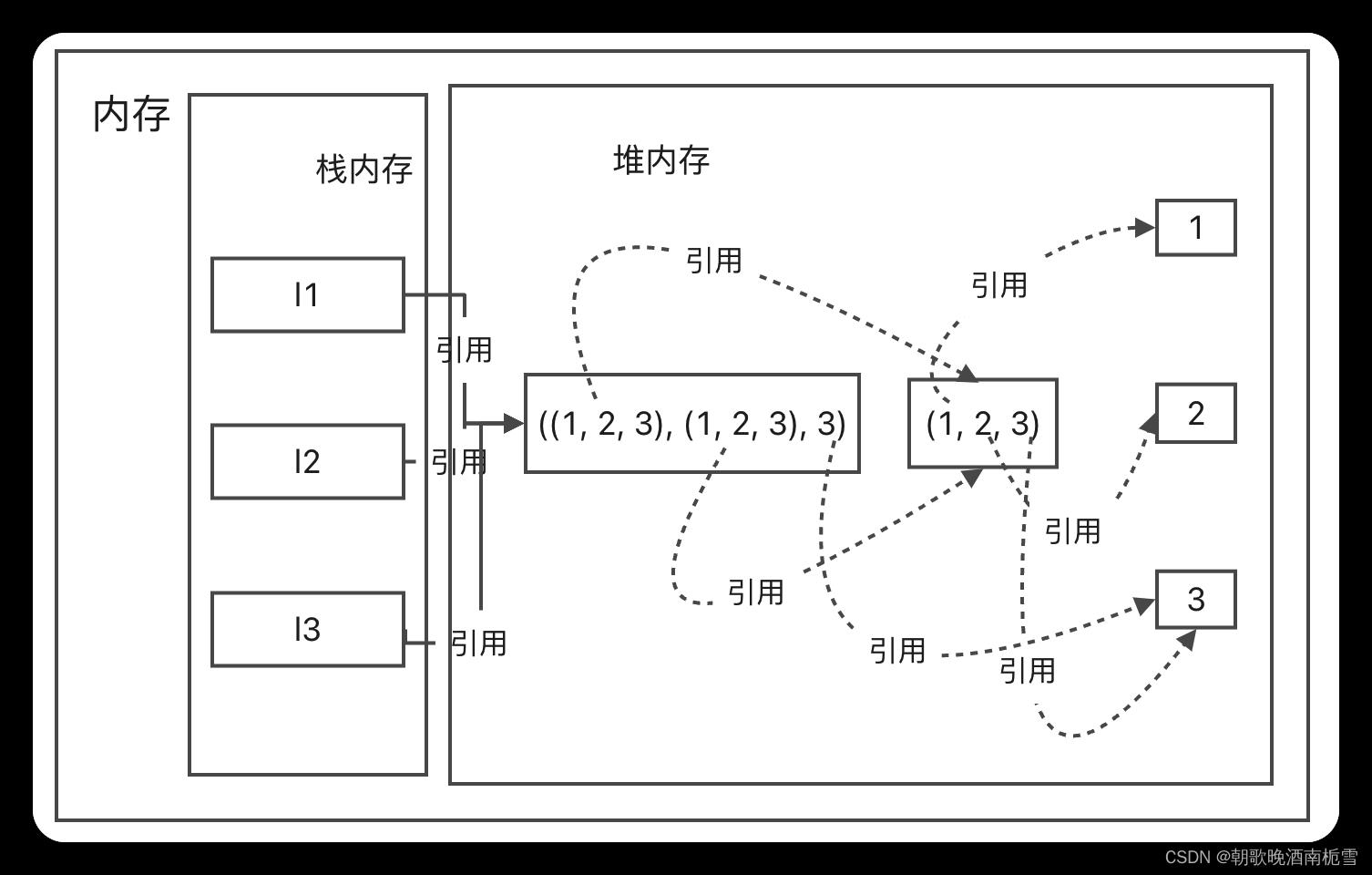
上面可以看到,多层原对象情况下,源对象元素如果也全都是不可变的,则不会分配新的对象,如l1和l2,他们源对象的地址都是相同的,说明他们都指向同一个对象地址,且源对象的元素,比如(1,2,3),也只会创建一个对象,l1、l2、l3的index为0和1位置的地址都指向一个,说明都引用的一个对象
6.2.2 源对象是可变数据类型(源对象元素可变情况)
l1 = [[1, 2, 3], [1, 2, 3], 3]
l2 = [[1, 2, 3], [1, 2, 3], 3]
l3 = l2
print(id(l1), id(l2), id(l3))
print(id(l1[0]), id(l1[1]))
print(id(l1[0]), id(l2[0]), id(l3[0]))
print(id(l1[1]), id(l2[1]), id(l3[1]))
print(id(l1[2]), id(l2[2]), id(l3[2]))
4312373056 4312372800 4312372800
4312287488 4312285888
4312287488 4312372416 4312372416
4312285888 4312373120 4312373120
4306871904 4306871904 4306871904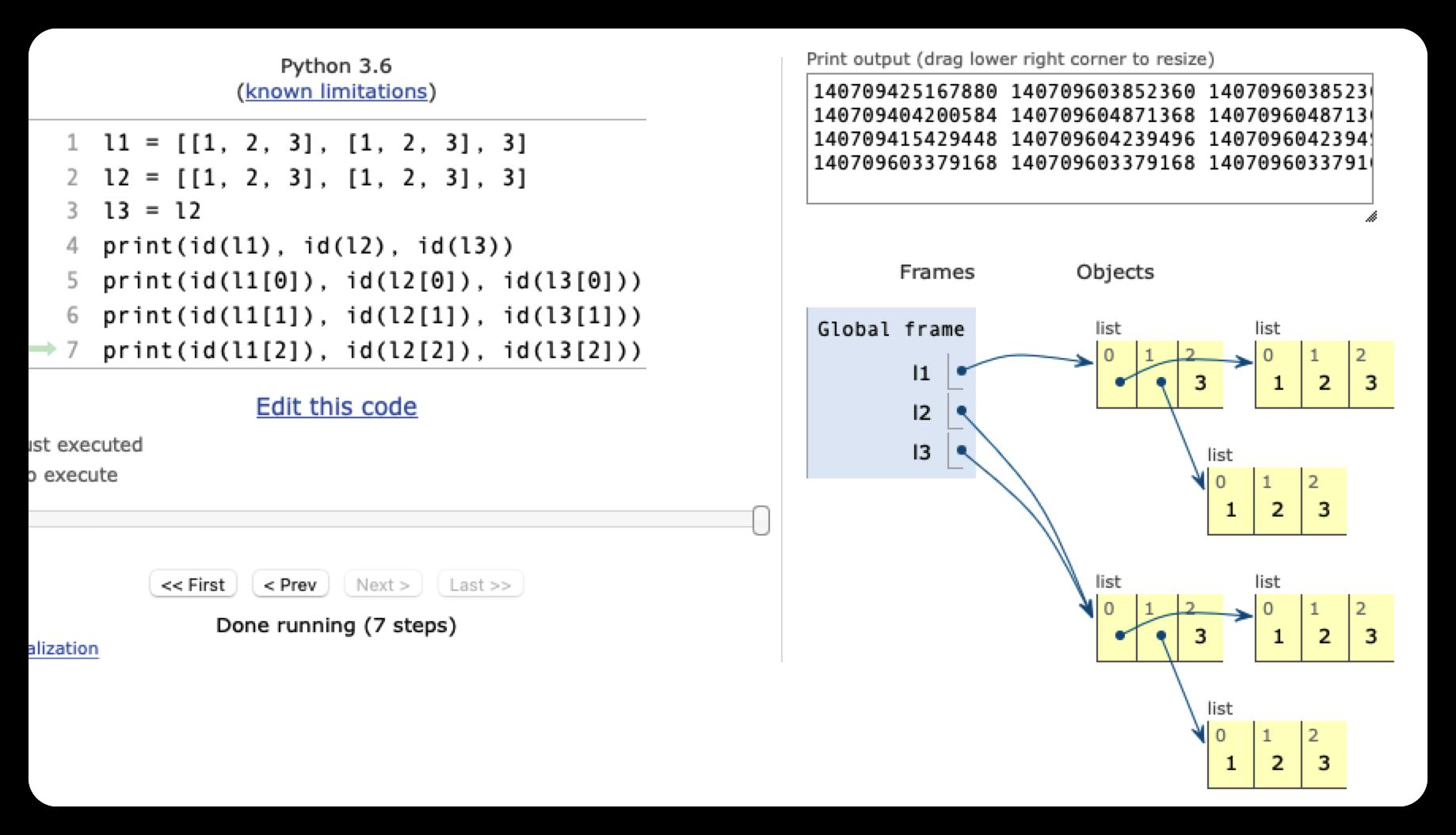 当源对象是可变数据类型,而且源对象元素也都可变情况下,如l1和l2,他们看起来值是一样的,但是他们指向的确是不同的地址,说明他们指向的是不同的对象
当源对象是可变数据类型,而且源对象元素也都可变情况下,如l1和l2,他们看起来值是一样的,但是他们指向的确是不同的地址,说明他们指向的是不同的对象
然后我们看l1自身的index=0 和index=1的元素,虽然都是[1,2,3],但是他们指向的地址也各自都不一样
 https://www.yuque.com/docs/share/2bcc0b83-515f-4c5d-bfbe-e1a075a662fe?#%20%E3%80%8APython%E5%80%BC%E4%BC%A0%E9%80%92%E5%92%8C%E5%BC%95%E7%94%A8%E4%BC%A0%E9%80%92%E3%80%8B
https://www.yuque.com/docs/share/2bcc0b83-515f-4c5d-bfbe-e1a075a662fe?#%20%E3%80%8APython%E5%80%BC%E4%BC%A0%E9%80%92%E5%92%8C%E5%BC%95%E7%94%A8%E4%BC%A0%E9%80%92%E3%80%8B以上是关于Python值传递和引用传递(详细分析)的主要内容,如果未能解决你的问题,请参考以下文章