Java面试总结
Posted 路上阡陌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java面试总结相关的知识,希望对你有一定的参考价值。
说说你对面向对象三大特征的理解
封装:使用抽象数据类型将数据和基于数据的操作封装在一起,数据被保护在抽象数据类型内部,只保留一些对外接口和外界联系,也就是说用户不用关心对象的内部细节,只需要通过对象的对外接口访问对象。
继承:在已经定义的类的基础上建立新的类,子类可以新增自己的数据或者功能,但不能选择性继承父类的数据或功能。通过继承可以实现代码复用,提高靠开发效率。
需要注意的地方:
- 子类拥有父类的所有属性和方法,包括私有属性和方法,但是私有属性和方法不能被访问,只是拥有;
- 子类可以拥有自己的属性和方法,即子类可以对父类进行扩展;
- 子类可以重写父类的方法(重写)。
多态:一个引用变量到底指向哪个类的实例对象,这个引用变量调用的方法到底是哪个类实现的方法,只有在程序运行期间才能知道。
实现多态的三个必要条件:
- 继承:再多态中必须存在有继承关系的子类和父类;
- 重写:子类需要重写父类的方法,这样在调用这些方法时就会调用子类重写的方法;
- 向上转型:在多态中需要将子类的引用赋给父类对象,只有这样该引用才既能调用父类方法,有能调用子类方法。
重载(Overload)和重写(Override)的区别是什么?
重载:在一个类或者子类父类之间,多个同名方法根据不同的传参来执行不同的逻辑处理。
重写:重写就是子类按照自己的需求对继承自父类的方法进行重新实现。
重载的核心就是:方法名相同,参数列表不同(参数个数、参数顺序和参数类型)。
重写的核心就是:子类对父类的方法进行重新实习,外部样子不可以改变,内部逻辑可以改变。
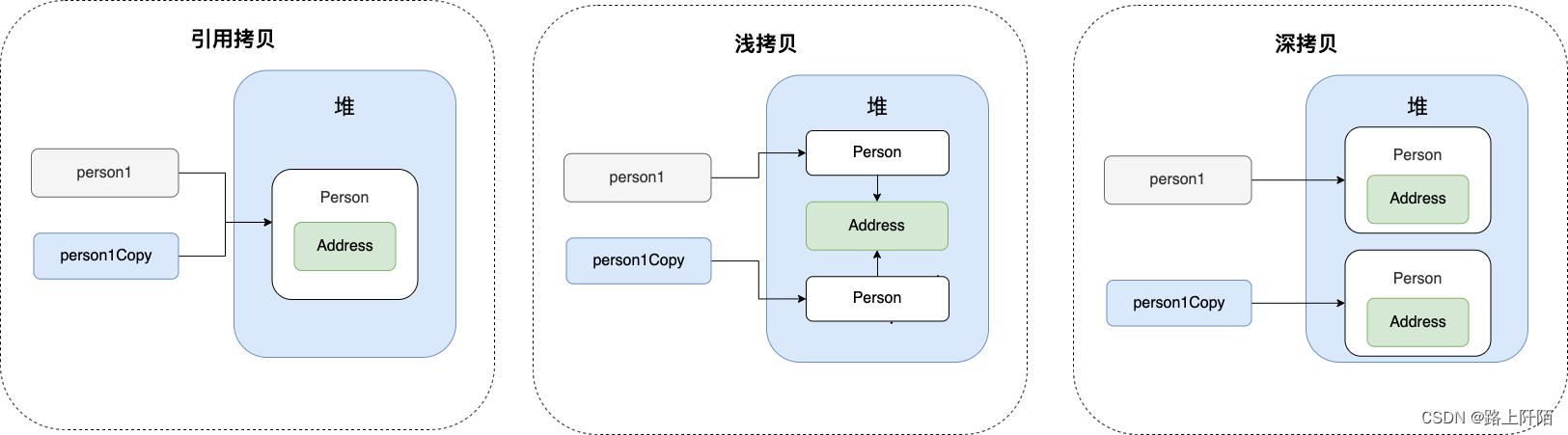
深拷贝和浅拷贝区别了解吗?什么是引用拷贝?
- 浅拷贝: 浅拷贝会在堆上创建一个新的对象(区别于引用拷贝),但如果对象内部有有引用类型的属性,会直接复制内部对象的引用地址,即原对象和拷贝对象共用一个内部对象;
- 深拷贝: 深拷贝会完全复制整个对象,包括这个对象的内部对象。
浅拷贝
浅拷贝的示例代码如下,我们这里实现了 Cloneable 接口,并重写了 clone() 方法。
clone() 方法的实现很简单,直接调用的是父类 Object 的 clone() 方法。
public class School implements Cloneable
private String schoolName;
// 省略构造函数、Getter&Setter方法
@Override
protected Object clone() throws CloneNotSupportedException
try
return (School)super.clone();
catch (CloneNotSupportedException e)
throw new AssertionError();
public class Student implements Cloneable
private School school;
// 省略构造函数、Getter&Setter方法
@Override
protected Object clone() throws CloneNotSupportedException
try
Student student = (Student) super.clone();
return student;
catch (CloneNotSupportedException e)
throw new AssertionError();
测试 :
Student student1 = new Student(new School("第一中学"));
Student student2 = (Student) student1.clone();
//true
System.out.println(student1.getSchool() == student2.getSchool());
从输出结果就可以看出, student1 的克隆对象和 student1 使用的仍然是同一个 School 对象。
深拷贝
这里我们简单对 Student类的 clone() 方法进行修改,连带着要把 Student 对象内部的 School 对象一起复制。
@Override
protected Object clone() throws CloneNotSupportedException
try
Student student = (Student) super.clone();
student.setSchool((School) student.getSchool().clone());
return student;
catch (CloneNotSupportedException e)
throw new AssertionError();
测试 :
Student student1 = new Student(new School("第一中学"));
Student student2 = (Student) student1.clone();
//false
System.out.println(student1.getSchool() == student2.getSchool());
从输出结果就可以看出,student1 的克隆对象和 student1 包含的 School 对象已经是不同的了。
那什么是引用拷贝呢?
简单来说,引用拷贝就是两个不同的引用指向同一个对象。也就是说引用拷贝不会再堆上创建新的对象,而是直接复制原对象的对象引用。
什么是不可变对象?好处是什么?
不可变对象指对象一旦被创建,状态就不能再改变,任何修改都会创建一个新的对象,如 String、Integer及其它包装类。不可变对象最大的好处是线程安全。
能否创建一个包含可变对象的不可变对象?
当然可以,比如final Person[] persons = new Persion[]。persons是不可变对象的引用,但其数组中的Person实例却是可变的。这种情况下需要特别谨慎,不要共享可变对象的引用。这种情况下,如果数据需要变化时,就返回原对象的一个拷贝。
值传递和引用传递的区别的什么?为什么说Java中只有值传递?
值传递(pass by value)是指在调用方法时将实参复制一份传递到方法中,这样当方法对形参进行修改时不会影响到实参。
引用传递(pass by reference)是指在调用方法时将实参的地址直接传递到方法中,那么在方法中对形参所进行的修改,将影响到实参。
值传递和引用传递的关键区别有两点:
-
调用方法时有没有对实参进行复制。
-
方法内对形参的修改会不会影响到实参。
基本类型作为参数被传递时肯定是值传递;引用类型作为参数被传递时也是值传递,只不过“值”为对应的引用。Java 的确是值传递的。只不过,引用类型在调用有参方法的时候,传递的是对象的引用,并不是对象本身。而对象的引用在传递的过程中并没有发生改变,虽然对象本身发生了变化。
== 和 equals 区别是什么?
==常用于相同的基本数据类型之间的比较,也可用于相同类型的对象之间的比较;
如果 == 比较的是基本数据类型,那么比较的是两个基本数据类型的值是否相等;
如果 == 比较的是引用类型数据,那么比较的是两个引用是否指向了同一块内存区域;
equals方法主要用于两个对象之间,检测一个对象是否等于另一个对象;
看一看Object类中equals方法的源码:
public boolean equals(Object obj)
return (this == obj);
它的作用也是判断两个对象是否相等,般有两种使用情况:
-
情况1,类没有覆盖equals()方法。则通过equals()比较该类的两个对象时,等价于通过“==”比较这两个对象。
-
情况2,类覆盖了equals()方法。一般,我们都覆盖equals()方法来两个对象的内容相等;若它们的内容相等,则返回true(即,认为这两个对象相等)。
Java语言规范要求equals方法具有以下特性:
- 自反性。对于任意不为null的引用值x,x.equals(x)一定是true。
- 对称性)。对于任意不为null的引用值x和y,当且仅当x.equals(y)是true时,y.equals(x)也是true。
- 传递性。对于任意不为null的引用值x、y和z,如果x.equals(y)是true,同时y.equals(z)是true,那么x.equals(z)一定是true。
- 一致性。对于任意不为null的引用值x和y,如果用于equals比较的对象信息没有被修改的话,多次调用时x.equals(y)要么一致地返回true要么一致地返回false。
- 对于任意不为null的引用值x,x.equals(null)返回false。
介绍下hashCode()?
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在JDK的Object.java中,这就意味着Java中的任何类都包含有hashCode()函数。
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
为什么要有 hashCode?
以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:
当把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。
但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
equals方法和hashcode的关系?
-
如果两个对象equals相等,那么这两个对象的HashCode一定也相同;
-
如果两个对象的HashCode相同,不代表两个对象就相同,只能说明这两个对象在散列存储结构中,存放于同一个位置。hashCode()只表示对象的哈希码,哈希码相同的对象不一定相等,反之,没有重写equals方法的前提下,两个对象相等,则hashCode一定相同。
-
两个对象相等,对两个对象分别调用equals方法都返回true;
为什么重写 equals 方法必须重写 hashcode 方法 ?
判断的时候先根据hashcode进行的判断,相同的情况下再根据equals()方法进行判断。如果只重写了equals方法,而不重写hashcode的方法,会造成hashcode的值不同,而equals()方法判断出来的结果为true。
在Java中的一些容器中,不允许有两个完全相同的对象,插入的时候,如果判断相同则会进行覆盖。这时候如果只重写了equals()的方法,而不重写hashcode的方法,Object中hashcode是根据对象的存储地址转换而形成的一个哈希值。这时候就有可能因为没有重写hashcode方法,造成相同的对象散列到不同的位置而造成对象的不能覆盖的问题。
以上是关于Java面试总结的主要内容,如果未能解决你的问题,请参考以下文章