Spark架构原理和生态系统
Posted 正则化
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark架构原理和生态系统相关的知识,希望对你有一定的参考价值。
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
Spark vs Hadoop
Hadoop 是大数据处理领域的开创者,用于进行分布式、大规模的数据处理,其中MapReduce 负责进行分布式计算,HDFS 负责存储大量文件。
Apache Spark 是 Hadoop MapReduce的接任者,而且远比Hadoop出色,Spark提供了更高级的编程接口、更高的性能。除此之外,Spark 不仅能进行常规的批处理计算,还提供了流式计算支持,是当今最流行的开源大数据处理框架。
Hadoop
Hadoop在每一次MapReduce 运算之后,会将数据的运算结果从内存写入到HDFS中,第二次 MapReduce 运算时在HDFS中读取数据,如此类推

这种机制的缺点是:
- 多次对磁盘进行读写操作,增加了多余的 IO 时间
- HDFS 的每份数据都需要冗余若干份拷贝,耗费磁盘空间。
- 很多复杂的数据处理工作无法用一次 MapReduce 完成,需要将多非常多的MapReduce 过程连接起来,更加拖慢了速度。
那么为什么Hadoop每次MapReduce运算后都需要将结果写入HDFS,而不是直接存放在内存,通过RPC传递给下一个结点呢?这是因为分布式系统必须有容错性,如果某一个结点宕机了,存放在内存的运算结果就会全部丢失,其他结点无法将数据恢复出来,只能重启整个计算任务,开销非常大。因此Hadoop选择通过将运算结果写入HDFS来防止数据丢失,保证下一个结点能够读取到数据。
Spark
Spark选择将数据一直缓存在内存中,运算时直接从内存读取数据,只有在必要时,才将部分数据写入到磁盘中,因此Spark的运算速度远高于Hadoop。Spark之所以敢将数据存放在内存中,是依赖于一个假设:所有计算过程都是确定性的(deterministic),所以当某个RDD分区(partition)丢失了,另一个计算节点可以从它的前继节点出发、用同样的计算过程重算一次,即可得到完全一样的 RDD 分区。
除此之外,Spark还使用了先进的 DAG(Directed Acyclic Graph,有向无环图)调度程序、查询优化器和物理执行引擎,在处理批量处理以及处理流数据时具有较高的性能。
Spark计算模型
Spark架构的一些基本概念
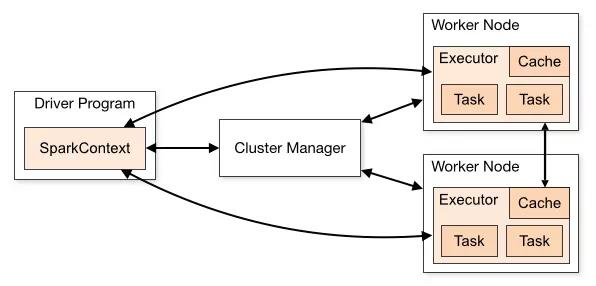
**Application:**由用户编写的调用 Spark API 的应用程序,它由集群上的一个Driver程序和多个Executor程序组成。其中应用程序的入口为用户所定义的 main 方法。
**Driver:**是一个运行Application中main()函数并创建SparkContext的进程。Driver节点也负责提交Job,并将Job转化为Task,在各个Executor进程间协调 Task 的调度。
**SparkContext:**是 Spark 所有功能的主要入口点,它是用户逻辑与 Spark 集群主要的交互接口。通过SparkContext可以与Cluster Manager和Executor交互。
**Cluster Manager:**即集群管理器,它存在于 Master 进程中,主要用来对应用程序申请的资源进行管理。
**Worker Node:**任何能够在集群中运行 Spark 应用程序的节点。
**Executor:**是在一个在Worker Node上为Application启动的进程,它能够运行 Task 并将数据保存在内存或磁盘存储中,也能够将结果数据返回给Driver。
**Task:**由SparkContext发送到Executor节点上执行的一个工作单元。
RDD & Partition
RDD
RDD即弹性分布式数据集(Resilient Distributed Datasets),是一种容错的、可以被并行操作的元素集合。它是Spark中一个最基础的概念,是 Spark 对所有数据处理的一种基本抽象。Spark 中的计算过程可以简单抽象为对 RDD 的创建、转换和返回操作结果的过程:
**makeRDD:**通过读取传统文件(如文本文件)、HDFS、NoSQL 等数据源创建RDD,RDD 被创建后不可被改变,只可以对 RDD 执行 Transformation 及 Action 操作。
**Transformation(转换):**对已有的 RDD 中的数据执行计算进行转换(如map、filter、groupByKey、cache等方法),并产生新的 RDD。Spark 对于Transformation采用惰性计算机制,即在 Transformation 过程并不会立即计算结果,而是在 Action 才会执行计算过程。
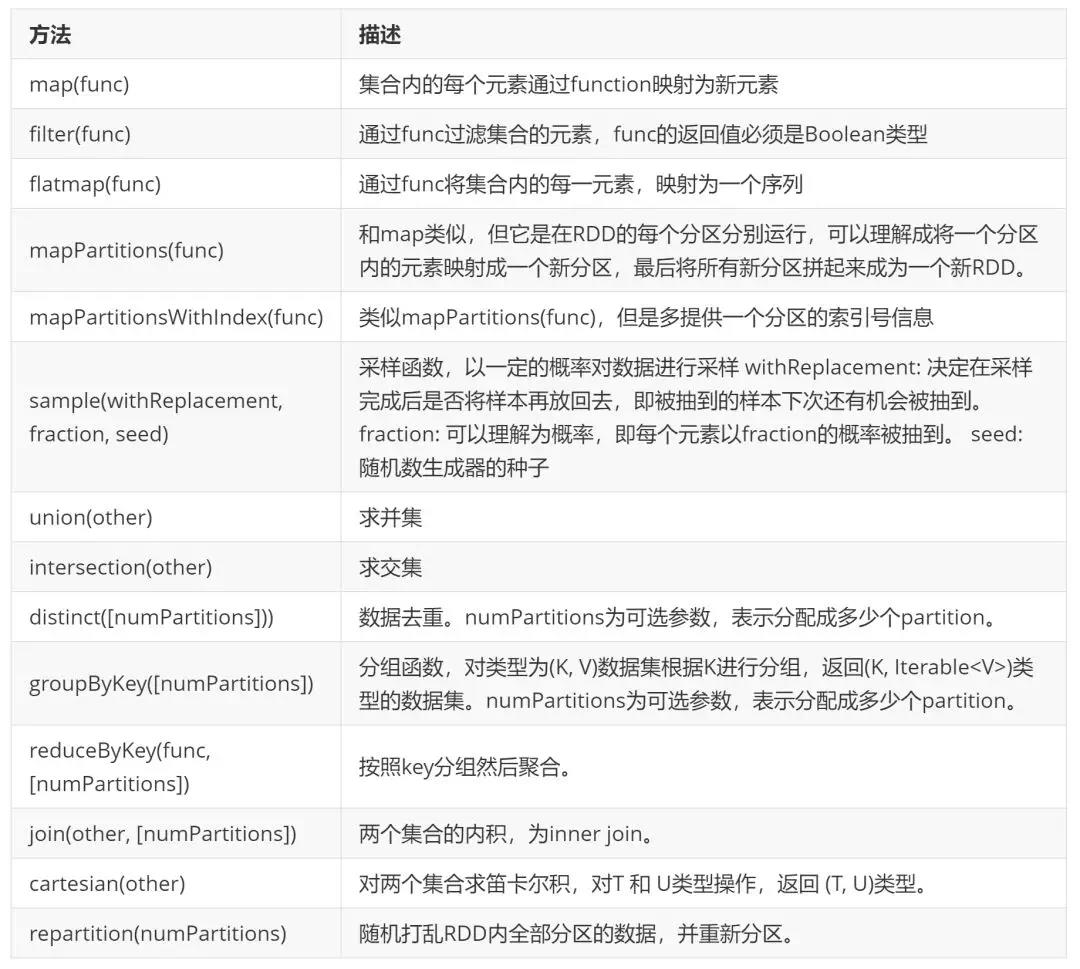
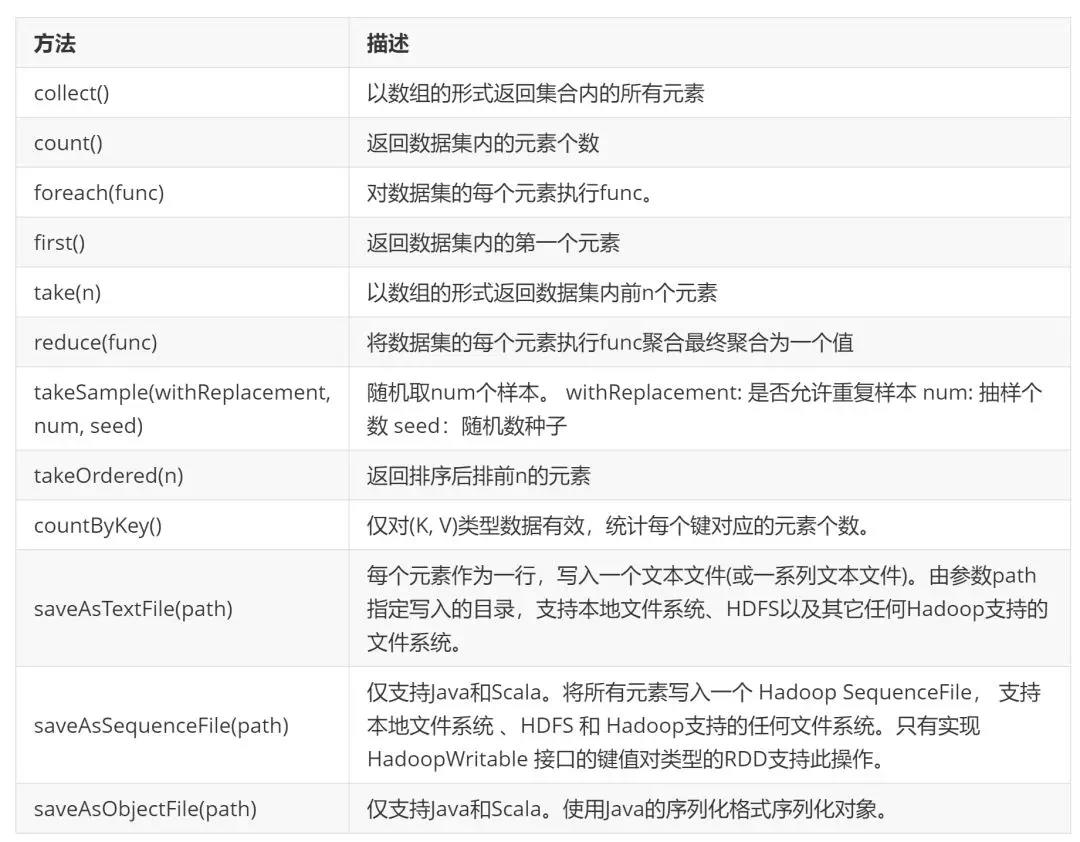
**Action(执行):**对已有的 RDD 中的数据执行计算产生结果(如reduce、collect、count、saveAsTextFile等方法),将结果返回 Driver 程序或写入到外部物理存储(如 HDFS)。
Partition
partition(分区)是RDD的最小单元,一个RDD由分布在各个节点上的partition 组成。例如,使用 Spark 来读取本地文本文件内容,读取完后,这些内容将会被分成多个partition,这些partition就组成了一个RDD,同时这些partition可以分散到不同的机器上执行,这也就是 RDD 中 “distributed” 的含义。
partition的数量也有讲究,Spark中每个task对应着一个partition,因此partition的数量决定了task的数量。如果 partition 数量太少,则计算资源不能被充分利用。例如分配 8 个核,但 partition 数量为 4,则只有4个核被用来并行运行对应的4个task,有一半的核没有被利用到。根据Spark RDD Programming Guide上的建议,集群节点的每个核分配 2-4 个partitions比较合理。
partition的数量可以在创建 RDD 时指定,否则Spark 将使用默认值。
依赖关系 & Stage
宽/窄依赖
Spark 中 RDD 的每一次Transformation都会生成一个新的 RDD,这样 RDD 之间就会形成类似于流水线一样的前后依赖关系,Spark 将依赖关系分为两种类型,分别是窄依赖和宽依赖:
窄依赖:每个父 RDD 的一个分区最多被子 RDD 的一个分区所使用,即 RDD 之间是一对一的关系。例如map、filter、union等算子都会产生窄依赖。
宽依赖:是指一个父 RDD 的分区会被子 RDD 的多个分区所使用,即 RDD 之间是一对多的关系。例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖。
Stage
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分为相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖关系。
切割规则:从后往前,遇到宽依赖就切割stage,遇到窄依赖就将这个RDD加入该stage中
因此每个stage包含一个或多个task任务,然后将这些task以taskSet的形式提交给TaskScheduler运行。
Spark调度
调度过程
上图是Spark 对 RDD 执行调度的过程,可以分成四个步骤
- 创建 RDD 并生成 DAG
- 由 DAGScheduler 分解 DAG 为包含多个 Task(即 TaskSet)的 Stages再将 TaskSet 发送至 TaskScheduler
- TaskScheduler 负责调度每个 Task,并分配到 Worker 节点上
- Worker结点执行Task,得到最后的计算结果
DAGScheduler
当执行 Action 操作时,相应的产生一个 Job,DAGScheduler 主要是把一个 Job 根据 RDD 间的依赖关系,划分为多个 Stage,每个 Stage 由多个 Task 组成(即 TaskSet),每个 Task 处理 RDD 中的一个 Partition。一个 Stage 里面所有分区的任务集合被包装为一个 TaskSet 交给 TaskScheduler 来进行任务调度。
DAGScheduler 对 RDD 的调度过程如下图所示:
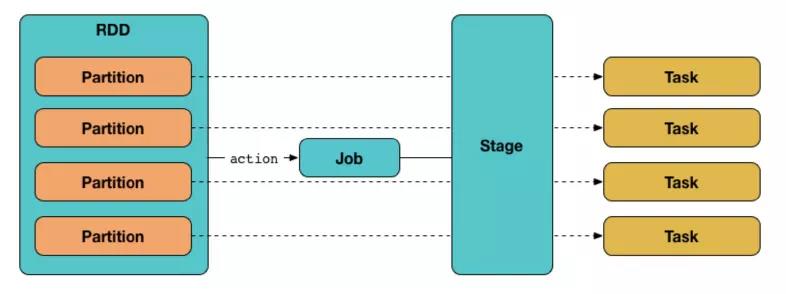
TaskScheduler
DAGScheduler 将一个 TaskSet 交给 TaskScheduler 后,TaskScheduler 会为每个 TaskSet 进行任务调度,Spark 中的任务调度分为两种:FIFO(先进先出)调度和 FAIR(公平调度)调度。
FIFO 调度( Spark 默认的调度模式):经典的调度方法,谁先提交谁先执行。
FAIR 调度:支持将作业分组到池中,并为每个池设置不同的调度权重,任务可以按照权重来决定执行顺序。(有兴趣可以去了解这个算法,这里不展开讲)
Spark 生态
Spark 生态系统以Spark Core为核心,能够
- 读取传统文件(如文本文件)、HDFS、Amazon S3、Alluxio 和NoSQL 等数据源。
- 利用Standalone、YARN 和Mesos 等资源调度管理,完成应用程序分析与处理。
- 不同组件解决不同的场景任务,如Spark Streaming 的实时流处理应用、Spark SQL 的即席查询、MLlib 的机器学习、GraphX 的图处理等等。
如下图所示,正是这个生态系统实现了“One Stack to Rule Them All”的目标,使得Spark成为了最流行的开源大数据处理框架
Spark Core是整个Spark生态系统的核心,是一个分布式的大数据处理框架,其重要特性包括:
- 引入了RDD的抽象概念,它是分布在一组节点中的弹性只读对象集合,如果数据集一部分丢失,则可以根据“血统”对它们进行重建,保证了数据的高容错性。
- 提供有向无环图(DAG)的分布式并行计算框架和内存机制来支持多次迭代计算或者数据共享,极大地减少了迭代计算之间存取数据的开销
- 提供多种运行模式,包括Spark自己提供的本地模式和Standalone,以及第三方资源调度框架如YARN、MESOS 等。
具体的Spark Core计算模型已经在上面章节详细讲解过,下面的章节简单介绍生态组件Spark Streaming和Spark SQL,他们的工作基本都是将对应的场景任务翻译成Spark Core能够理解和执行的任务。
Spark Streaming
Spark Streaming 是一个对实时数据流进行高吞吐、高容错的流式处理系统,可以对多种数据源(如Kafka、Flume、Twitter 和ZeroMQ 等)进行类似Map、Reduce 和Join 等复杂操作,并将结果保存到外部文件系统、数据库或应用到实时仪表盘。
以往,批处理和流计算被看作大数据系统的两个方面。我们常常能看到这样的架构——以 Kafka、Storm 为代表的流计算框架用于实时计算(逐条数据地进行处理),而 Spark 或 MapReduce 则负责每天、每小时的数据批处理。在 ETL 等场合,这样的设计常常导致同样的计算逻辑被实现两次,耗费开发人力和计算资源不说,保证一致性也是个问题。
而Spark Streaming将流处理和批处理结合了起来,提出了DStream(Discretized Streams)方案。具体地说,Spark Streaming 将流式计算分解成一系列短小的批处理作业,也就是把输入数据按照批处理大小(如几秒)分成一段一段的离散数据流(DStream),每一段数据都转换成Spark中的RDD,然后将Spark Streaming 中对DStream 流处理操作变为针对Spark 中对RDD 的批处理操作。
DStream方案虽然牺牲了低延迟特性(一般流计算能做到 100ms 级别,Spark Streaming 延迟一般为 1s 左右),但是开发者只需要维护一套 ETL 逻辑即可同时用于批处理和流计算。
Spark SQL
与命令式(imperative)编程相对的是声明式(declarative)编程,前者需要告诉程序怎样得到我需要的结果,即开发者需要编写执行计划,后者则是告诉程序我需要的结果是什么,然后由程序翻译和生成执行计划即可,可见声明式编程更加简洁,可以极大地降低开发难度、节省开发者的时间。Hadoop的声明式编程接口就是Hive SQL,Hive的作用是把hdfs数据文件映射成数据表,通过Hive SQL操作HDFS中的数据,其中Hive将SQL语句转换成MapReduce任务进行。
Spark的声明式编程接口就是Spark SQL,它是在 Spark Core之上的一层封装,在 RDD 计算模型的基础上,提供了 DataFrame API 以及一个内置的 SQL 执行计划优化器 Catalyst
- DataFrame 就像数据库中的表,保存数据以及数据的schema 信息。DataFrame 的数据是行对象组成的 RDD,对DataFrame 的操作最终会变成对底层 RDD 的操作。
- Catalyst 是一个内置的 SQL 优化器,负责把用户输入的 SQL 转化成执行计划。
下图的黄色部分就是Spark SQL的部分
Spark Structured Streaming
Spark 通过 Spark Streaming 拥有了流计算能力,那 Spark SQL 是否也能具有类似的流处理能力呢?答案是肯定的,只要将数据流建模成一张不断增长、没有边界的表,那么很多 SQL 操作等就能直接应用在流数据上。对此,Spark基于 Spark SQL 实现了Spark Structured Streaming,因此Spark SQL 中的大部分接口、实现都得以在 Spark Structured Streaming 中直接复用。
将用户的 SQL 执行计划转化成流计算执行计划的过程被称为增量化(incrementalize),这一步是由 Spark 框架自动完成的。对于用户来说只要知道:每次计算的输入是某一小段时间的流数据,而输出是对应数据产生的计算结果。
例子:把流式数据当成一张不断增长的 table,也就是图中的 Unbounded table of all input。然后每秒 trigger 一次,在 trigger 的时候将 query 应用到 input table 中新增的数据上,有时候还需要和之前的静态数据一起组合成结果。query 产生的结果成为 Result Table,我们可以选择将 Result Table 输出到外部存储。
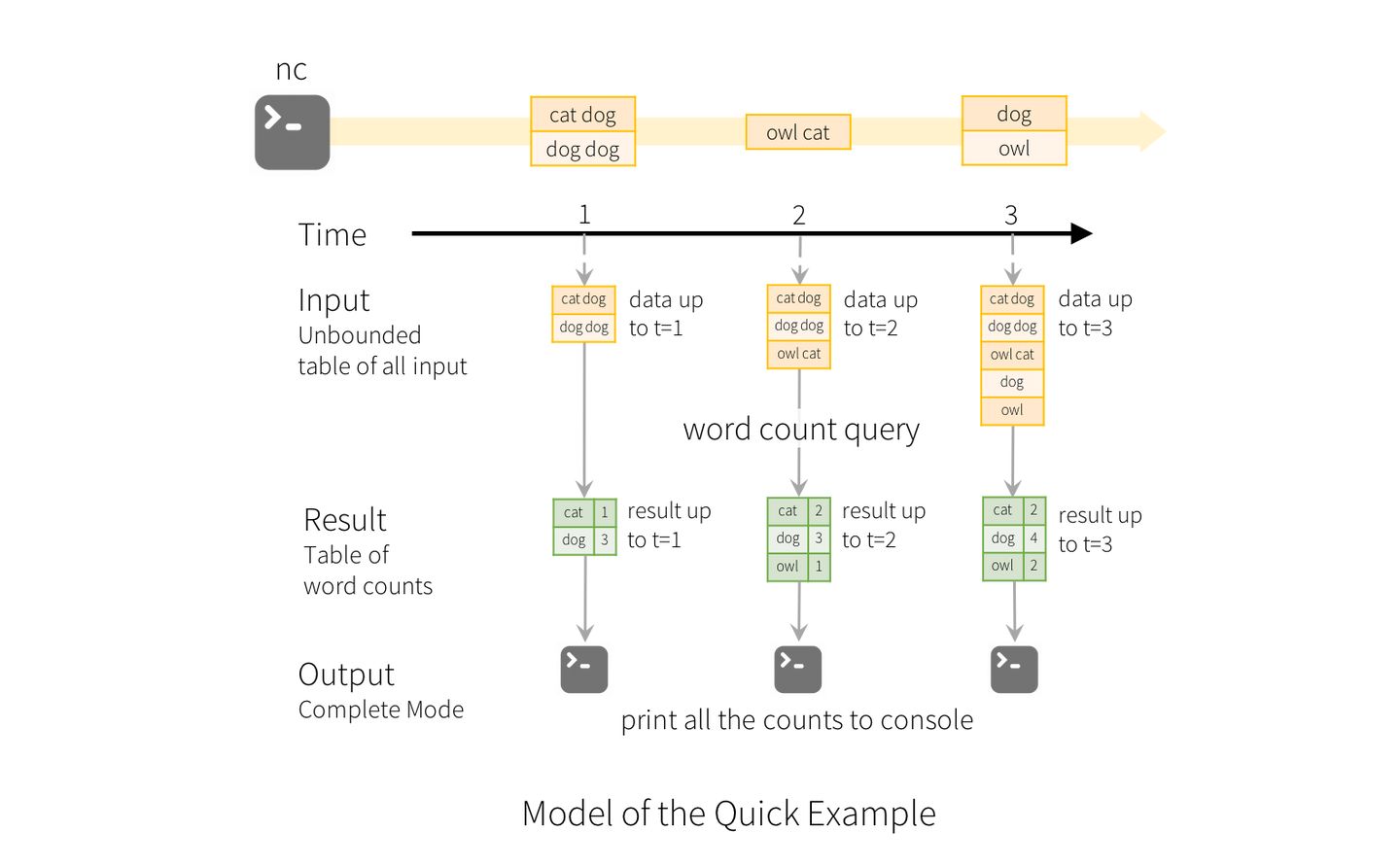
此外,Spark Structured Streaming还有两个额外的特性,分别是窗口(window)和水位(watermark)。因为流数据有Event Time和Processing Time 这两种时间概念, Event Time 是数据自带的属性,一般表示数据产生于数据源的时间,Processing Time 是数据到达 Spark 被处理的时间,在网络故障等情况下,Processing Time可能远远大于Event Time,此时会有数据已过期的情况,需要考虑是否丢弃这一部分数据。
**窗口(window)是对过去某段时间的定义。**批处理中,查询通常是全量的(例如:总用户量是多少);而流计算中,我们通常关心近期一段时间的数据(例如:最近24小时新增的用户量是多少)。用户通过选用合适的窗口来获得自己所需的计算结果,常见的窗口有滑动窗口(Sliding Window)、滚动窗口(Tumbling Window)等。 例子:
import spark.implicits._
val words = ... // streaming DataFrame of schema timestamp: Timestamp, word: String
// Group the data by window and word and compute the count of each group
val windowedCounts = words.groupBy(
window("eventTime", "10 minutes", "5 minutes"),
$"word"
).count()
窗口大小设置为10分钟,每5分钟trigger一次,统计每个10分钟窗口内的结果,即使是late data也会全部更新到对应的时间窗口的统计结果中。
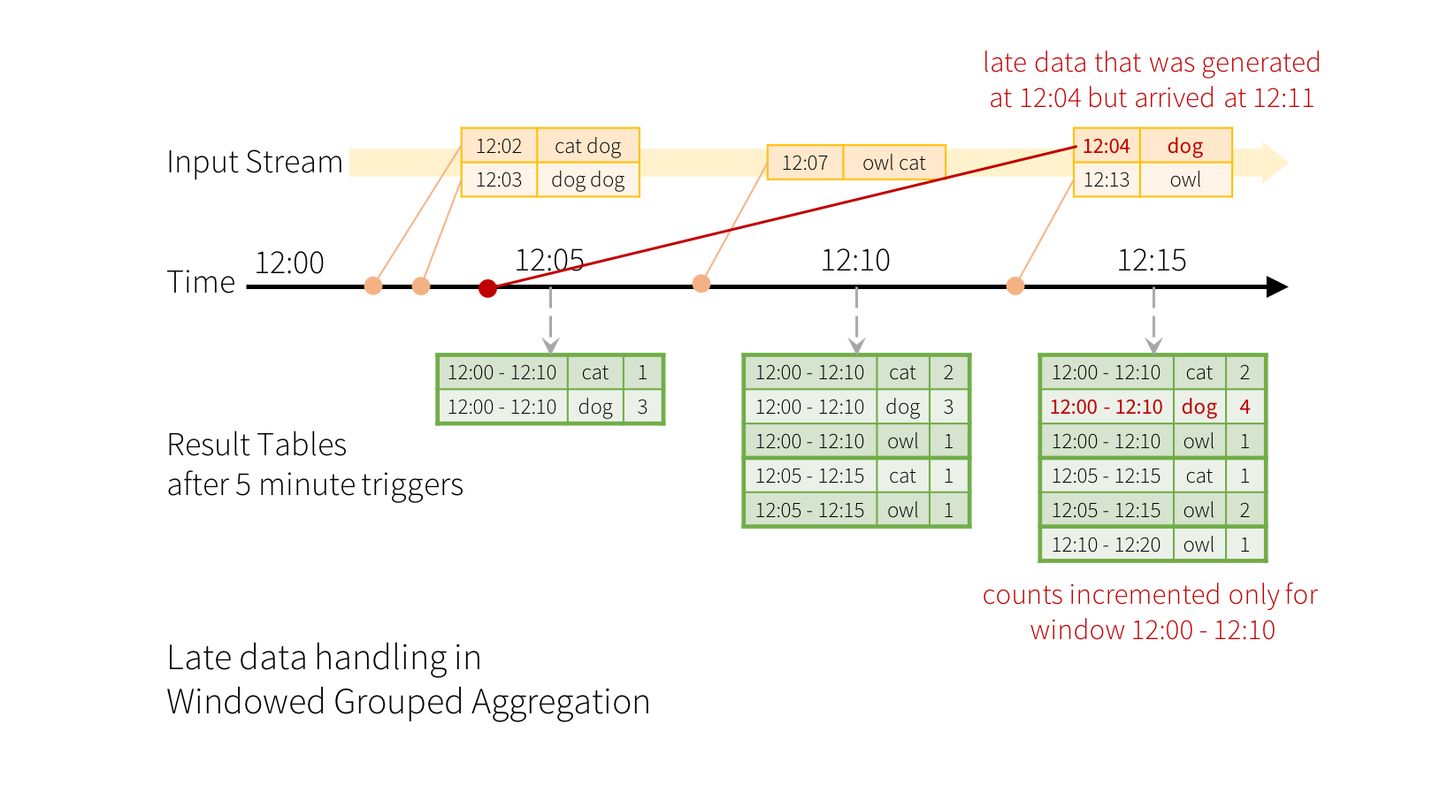
**水位(watermark)用来丢弃过早的数据。**单纯使用window的话,无论late data来的多晚,都需要对其进行计算,但实际上很多过迟的数据已经没有统计的意义了,而且流计算系统的内存是有限的、只能保存有限的状态,一定时间之后必须丢弃历史数据。所以Spark Structured Streaming还有watermark的特性。例子:
import spark.implicits._
val words = ... // streaming DataFrame of schema timestamp: Timestamp, word: String
// Group the data by window and word and compute the count of each group
val windowedCounts = words
.withWatermark("eventTime", "10 minutes")
.groupBy(
window("eventTime", "10 minutes", "5 minutes"),
$"word")
.count()
上述代码watermark设置为10分钟,那么trigger时只有10分钟以内的late data会被统计,再之前的数据就会被抛弃掉。
以上是关于Spark架构原理和生态系统的主要内容,如果未能解决你的问题,请参考以下文章