Redis Stream队列与多线程模型
Posted 胡尚
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis Stream队列与多线程模型相关的知识,希望对你有一定的参考价值。
文章目录
Stream队列与多线程模型
Stream队列
Redis5.0版本新出stream数据结构,是实现消息队列的功能的。
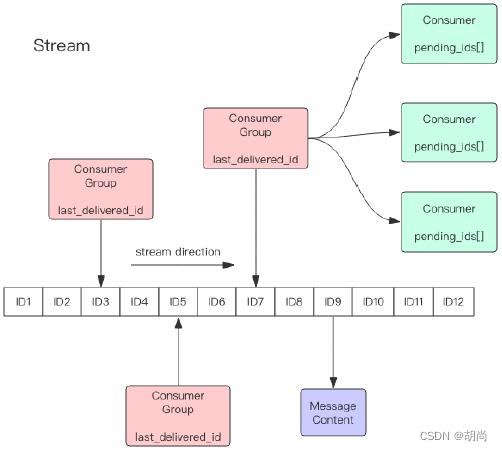
Redis Stream 的结构如上图所示,每一个Stream都有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容。
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用xadd指令追加消息时创建的。
每个 Stream 都可以挂多个消费组,每个消费组会有个游标last_delivered_id在 Stream 数组之上往前移动,表示当前消费组已经消费到哪条消息了。每个消费组都有一个 Stream 内唯一的名称,消费组不会自动创建,它需要单独的指令xgroup create进行创建,需要指定从 Stream 的某个消息 ID 开始消费,这个 ID 用来初始化last_delivered_id变量。
每个消费组 (Consumer Group) 的状态都是独立的,相互不受影响。也就是说同一份 Stream 内部的消息会被每个消费组都消费到。
同一个消费组 (Consumer Group) 可以挂接多个消费者 (Consumer),这些消费者之间是竞争关系,任意一个消费者读取了消息都会使游标last_delivered_id往前移动。每个消费者有一个组内唯一名称。
消费者 (Consumer) 内部会有个状态变量pending_ids,它记录了当前已经被客户端读取,但是还没有 ack的消息。
消息 ID 的形式是timestampInMillis-sequence,时间戳-流水号。消息 ID 可以由服务器自动生成,也可以由客户端自己指定,但是形式必须是整数-整数,而且必须是后面加入的消息的 ID 要大于前面的消息 ID。建议不要自己指定
消息内容就是键值对,形如 hash 结构的键值对
生产端
生产端常用命令如下所示:
# 追加消息
# xadd stream名字 消息id key value [key value ...]
xadd streamtest * name hushang age 23
# 删除消息,这里的删除仅仅是设置了标志位,不会实际删除消息。如果不指定消息id直接执行则是删除整个stream中的消息
# xdel stream名字 消息id
xdel streamtest 165847589548-0
# 获取消息,会过滤掉删除了的消息,也可以用- + 表示获取所有消息,-表示最小值 + 表示最大值
# xrange stream名字 最小消息id 最大消息id
xrange streamtest - +
# 获取stream中消息数量
# xlen stream名字
xlen streamtest
# 删除stream
del stream名字
案例
# 首先新增三条消息
127.0.0.1:6379> xadd streamtest * name hushang age 23
"1679980604367-0"
127.0.0.1:6379> xadd streamtest * name zhangsan age 24
"1679980624235-0"
127.0.0.1:6379> xadd streamtest * name lisi age 18
"1679980635354-0"
# 查询消息
127.0.0.1:6379> xrange streamtest - +
1) 1) "1679980604367-0"
2) 1) "name"
2) "hushang"
3) "age"
4) "23"
2) 1) "1679980624235-0"
2) 1) "name"
2) "zhangsan"
3) "age"
4) "24"
3) 1) "1679980635354-0"
2) 1) "name"
2) "lisi"
3) "age"
4) "18"
127.0.0.1:6379> xrange streamtest - 1679980624235-0
1) 1) "1679980604367-0"
2) 1) "name"
2) "hushang"
3) "age"
4) "23"
2) 1) "1679980624235-0"
2) 1) "name"
2) "zhangsan"
3) "age"
4) "24"
# 获取消息数量与删除消息
127.0.0.1:6379> xlen streamtest
(integer) 3
127.0.0.1:6379> xdel streamtest 1679980604367-0
(integer) 1
127.0.0.1:6379> xlen streamtest
(integer) 2
消费者组
单消费者
stream中一般是以消费者组进行消费,但我们也可以使用单消费者,
Redis 设计了一个单独的消费指令xread,可以将 Stream 当成普通的消息队列 (list) 来使用。使用 xread 时,我们可以完全忽略消费组 (Consumer Group) 的存在,就好比 Stream 就是一个普通的列表 (list)。
# 可以使用0-0表示从头开始读取消息
# 最后一个参数消息id是一个开区间(n,+∞),也就是说不会读取到指定消息id的这条消息
# xread count 读取消息数量 streams stream名字 从哪条消息id开始读
xread count 1 streams streamName 0-0
也可以使用$从尾开始读取,也就是当前时间之前发送的消息都不会读取到
xread count 1 streams streamName $
但是这条命名默认是不返回任何消息的,需要使用阻塞的方式读取
# block后面的数字代表阻塞时间,单位毫秒
xread count 1 block 0 streams streamName $
如下所示
# 直接从尾部读取没有数据返回
127.0.0.1:6379> xread count 1 streams streamtest $
(nil)
# 加上阻塞读取后,重新打开一个会话往steam中新加一条消息,然后这边就有返回了,最后返回的时间是阻塞了多久
127.0.0.1:6379> xread count 1 block 0 streams streamtest $
1) 1) "streamtest"
2) 1) 1) "1679983057656-0"
2) 1) "name"
2) "wangwu"
3) "age"
4) "111"
(40.16s)
127.0.0.1:6379>
# 如果阻塞时间不写0 那么等到指定的阻塞时间一到就结束了
127.0.0.1:6379> xread count 1 block 1000 streams streamtest $
(nil)
(1.07s)
127.0.0.1:6379>
这种单消费者方式不会有消费消息的offset偏移量,想要实现顺序消费消息,那么就需要自己维护消息id,记录当前已经消费到哪一个id了
消费者组group
消费者组中有一个last_delivered_id记录当前消费到那一条消息了,在创建消费者组时就需要传递一个消息id作为last_delivered_id的值
# 创建一个消费者组,0-0表示从头开始消费,
# xgroup create 要消费的stream名 消费者组名 从哪一个消息id开始消费
xgroup create streamtest hs-group 0-0
# 也可以加$表示从尾部开始消费,当前时间之前发送的消息都不会被消费
xgroup create hs-group streamtest $
可以使用xinfo stream stream名字命令来查看stream的情况
# 目前streamtest中有三条消息
127.0.0.1:6379> xrange streamtest - +
1) 1) "1679980624235-0"
2) 1) "name"
2) "zhangsan"
3) "age"
4) "24"
2) 1) "1679980635354-0"
2) 1) "name"
2) "lisi"
3) "age"
4) "18"
3) 1) "1679983057656-0"
2) 1) "name"
2) "wangwu"
3) "age"
4) "111"
127.0.0.1:6379> xinfo stream streamtest
1) "length"
2) (integer) 3 # 消息的数据量
3) "radix-tree-keys"
4) (integer) 1
5) "radix-tree-nodes"
6) (integer) 2
7) "groups"
8) (integer) 1 # 1个消费组
9) "last-generated-id"
10) "1679983057656-0" # 最后一条消息的消息id
11) "first-entry"
12) 1) "1679980624235-0" # 第一条消息与最后一条消息
2) 1) "name"
2) "zhangsan"
3) "age"
4) "24"
13) "last-entry"
14) 1) "1679983057656-0"
2) 1) "name"
2) "wangwu"
3) "age"
4) "111"
也可以使用xinfo groups stream名来查看消费者组情况
127.0.0.1:6379> xinfo groups streamtest
1) 1) "name"
2) "hs-group" # 消费者组名
3) "consumers"
4) (integer) 0 # 消费者组中目前还没有消费者
5) "pending"
6) (integer) 0 # 有多少条消息为ack应答
7) "last-delivered-id" # 从哪条消息开始消费,也就是消费消息的offset
8) "0-0"
消费者
有了消费组,自然还需要消费者,Stream 提供了 xreadgroup 指令可以进行消费组的组内消费,需要提供消费组名称、消费者名称和起始消息 ID。
它同 xread 一样,也可以阻塞等待新消息。读到新消息后,对应的消息 ID 就会进入消费者的PEL(正在处理的消息) 结构里,客户端处理完毕后使用 xack 指令通知服务器,本条消息已经处理完毕,该消息 ID 就会从 PEL 中移除。
# 最后的> 表示从当前消费组的 last_delivered_id 后面开始读,每当消费者读取一条消息,last_delivered_id 变量就会前进
# xreadgroup GROUP 消费者组名 消费者名 count 消费消息数量 streams stream名 >
xreadgroup GROUP hs-group c1 count 1 streams streamtest >
开始读取消息
127.0.0.1:6379> xreadgroup GROUP hs-group c1 count 1 streams streamtest >
1) 1) "streamtest"
2) 1) 1) "1679980624235-0"
2) 1) "name"
2) "zhangsan"
3) "age"
4) "24"
127.0.0.1:6379> xreadgroup GROUP hs-group c1 count 1 streams streamtest >
1) 1) "streamtest"
2) 1) 1) "1679980635354-0"
2) 1) "name"
2) "lisi"
3) "age"
4) "18"
127.0.0.1:6379> xreadgroup GROUP hs-group c1 count 1 streams streamtest >
1) 1) "streamtest"
2) 1) 1) "1679983057656-0"
2) 1) "name"
2) "wangwu"
3) "age"
4) "111"
# 三条消息读完后就没有了
127.0.0.1:6379> xreadgroup GROUP hs-group c1 count 1 streams streamtest >
(nil)
# 接下来加上 block 0 尝试阻塞读取消息,当其他会话执行xadd命令后这边就能读取到数据了
127.0.0.1:6379> xreadgroup GROUP hs-group c1 count 1 streams streamtest >
1) 1) "streamtest"
2) 1) 1) "1679985519302-0"
2) 1) "name"
2) "zhaoliu"
3) "age"
4) "123"
(11.90s)
127.0.0.1:6379>
还可以通过xinfo consumers stream名字 消费者组名来查看消费者组中消费者的信息
127.0.0.1:6379> xinfo consumers streamtest hs-group
1) 1) "name"
2) "c1" # 消费者名
3) "pending"
4) (integer) 4 # 当前有多少条消息未ack应答
5) "idle"
6) (integer) 199097 # 空闲了199097ms没有读取消息
ack应答
# xack streamtest 消费者组名 消息id [消息id...]
127.0.0.1:6379> xack streamtest hs-group 1679980624235-0
(integer) 1
# 现在再查看当前消费者组就只用3条消息未查看应答了
127.0.0.1:6379> xinfo consumers streamtest hs-group
1) 1) "name"
2) "c1"
3) "pending"
4) (integer) 3
5) "idle"
6) (integer) 351981
127.0.0.1:6379> xinfo groups streamtest
1) 1) "name"
2) "hs-group"
3) "consumers"
4) (integer) 1
5) "pending"
6) (integer) 3
7) "last-delivered-id"
8) "1679985519302-0"
Redis队列几种实现
-
基于List的lpush + brpop
需要处理空闲连接的问题,如果线程一直阻塞在那里,Redis客户端的连接就成了闲置连接,闲置过久,服务器一般会主动断开连接,减少闲置资源占用,这个时候blpop和brpop或抛出异常,所以在编写客户端消费者的时候要小心,如果捕获到异常需要重试。
-
基于Sorted-Set的实现
多用来实现延迟队列,当然也可以实现有序的普通的消息队列,但是消费者无法阻塞的获取消息,只能轮询,不允许重复消息。
-
PUB/SUB,订阅/发布模式
优点:
典型的广播模式,一个消息可以发布到多个消费者;多信道订阅,消费者可以同时订阅多个信道,从而接收多类消息;消息即时发送,消息不用等待消费者读取,消费者会自动接收到信道发布的消息。
缺点:
消息一旦发布,不能接收。换句话就是发布时若客户端不在线,则消息丢失,不能寻回;
-
基于Stream类型的实现
基本上已经有了一个消息中间件的雏形
Redis的IO模型
Reactor模型
这里首先介绍一下Reactor模式
具体事件处理程序不调用反应器,而向反应器注册一个事件处理器,表示自己对某些事件感兴趣,有事件来了,具体事件处理程序通过事件处理器对某个指定的事件发生做出反应;
单线程Reactor模式
客户端与服务端通信一般是下面几个步骤:建立连接、服务器读取数据、解码、计算处理、编码、响应给客户端
这种模式下所有的事情都是一个Reactor线程来做
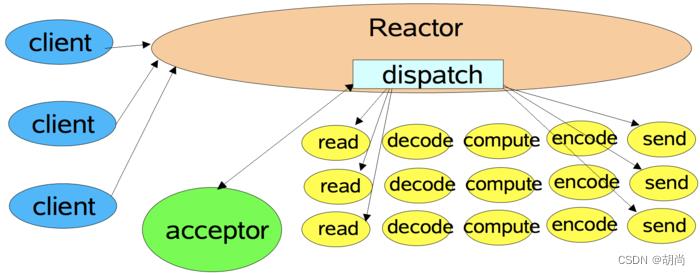
单线程Reactor,工作者线程池
将非I/O操作从Reactor线程中移出转交给工作者线程池来执行,Reactor线程仅仅去处理客户端连接、读取、响应。而具体的处理交给多个工作线程去做
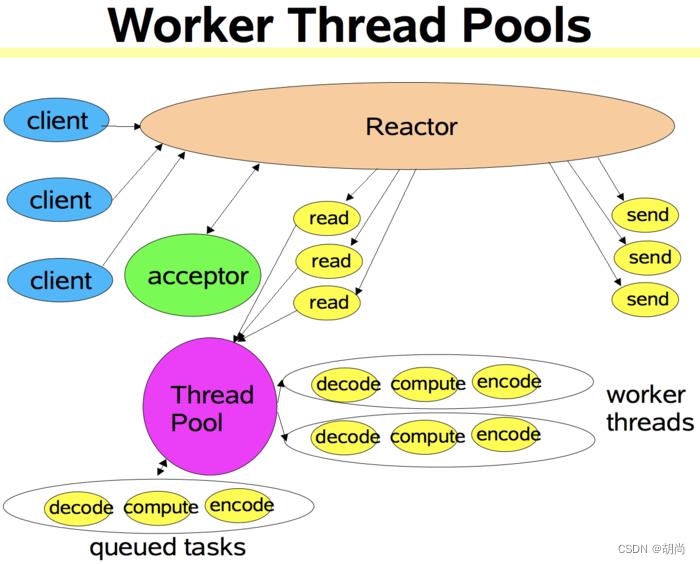
多Reactor线程模式
如果客户端的连接非常多,一个reactor线程也忙不过来时,那么这一块也可以使用多线程,一个主reactor线程去处理客户端的连接,子reactor线程处理读取和响应,工作线程处理业务操作

Redis的IO模型
Redis 基于 Reactor 模式开发了自己的网络事件处理器 - 文件事件处理器(file event handler,后文简称为 FEH),而该处理器又是单线程的,所以redis设计为单线程模型。
多路复用、文件事件分派、文件事件处理都是一个线程。
这里的socket可以理解为就是一个redis客户端
采用I/O多路复用同时监听多个socket,根据socket当前执行的事件来为 socket 选择对应的文件事件处理器。
当被监听的socket准备好执行accept、read、write、close等操作时,和操作对应的文件事件就会产生,这时FEH就会调用socket之前关联好的事件处理器来处理对应事件。
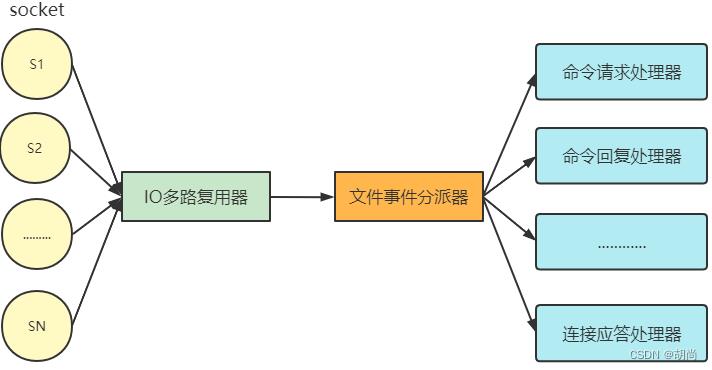
socket
文件事件就是对socket操作的抽象, 每当一个 socket 准备好执行连接accept、read、write、close等操作时, 就会产生一个文件事件。一个服务器通常会连接多个socket, 多个socket可能并发产生不同操作,每个操作对应不同文件事件。
I/O多路复用程序
I/O 多路复用程序会负责监听多个socket。
尽管文件事件可能并发出现, 但 I/O 多路复用程序会将所有产生事件的socket放入队列, 通过该队列以有序、同步且每次一个socket的方式向文件事件分派器传送socket。
当上一个socket产生的事件被对应事件处理器执行完后, I/O 多路复用程序才会向文件事件分派器传送下个socket, 如下:

文件事件分派器
文件事件分派器接收 I/O 多路复用程序传来的socket, 并根据socket产生的事件类型, 调用相应的事件处理器。
文件事件处理器
服务器会为执行不同任务的套接字关联不同的事件处理器, 这些处理器是一个个函数, 它们定义了某个事件发生时, 服务器应该执行的动作。
文件事件的类型
I/O 多路复用程序可以监听多个socket的 ae.h/AE_READABLE 事件和 ae.h/AE_WRITABLE 事件, 这两类事件和套接字操作之间的对应关系如下:
当socket可读(比如客户端对Redis执行write/close操作),或有新的可应答的socket出现时(即客户端对Redis执行connect操作),socket就会产生一个AE_READABLE事件。
当socket可写时(比如客户端对Redis执行read操作),socket会产生一个AE_WRITABLE事件。
I/O多路复用程序可以同时监听AE_REABLE和AE_WRITABLE两种事件,要是一个socket同时产生这两种事件,那么文件事件分派器优先处理AE_REABLE事件。即一个socket又可读又可写时, Redis服务器先读后写socket。
总结
最后,让我们梳理一下客户端和Redis服务器通信的整个过程:
- Redis启动初始化时,将连接应答处理器跟AE_READABLE事件关联。
- 若一个客户端发起连接,会产生一个AE_READABLE事件,然后由连接应答处理器负责和客户端建立连接,创建客户端对应的socket,同时将这个socket的AE_READABLE事件和命令请求处理器关联,使得客户端可以向主服务器发送命令请求。
- 当客户端向Redis发请求时(不管读还是写请求),客户端socket都会产生一个AE_READABLE事件,触发命令请求处理器。处理器读取客户端的命令内容, 然后传给相关程序执行。
- 当Redis服务器准备好给客户端的响应数据后,会将socket的AE_WRITABLE事件和命令回复处理器关联,当客户端准备好读取响应数据时,会在socket产生一个AE_WRITABLE事件,由对应命令回复处理器处理,即将准备好的响应数据写入socket,供客户端读取。
- 命令回复处理器全部写完到 socket 后,就会删除该socket的AE_WRITABLE事件和命令回复处理器的映射。
Redis6中的多线程
-
redis6.0版本之前,一个主线程处理用户的请求,包括读、解析、执行、响应。
但是还有一些后台线程执行其他操作比如:持久化、bigkey删除等等
这个时候cpu不是redis的瓶颈,redis的瓶颈是网络和内存的读写,既然不是cpu瓶颈也就没有必要用多线程了,使用现在的多路复用+FEH事件模型也能达到每秒10w的请求
-
redis6.0版本中,处理用户的请求的操作还是一个主线程来执行的,Redis的多线程部分只是用来处理网络数据的读写和协议解析。
因为用户量越来越大,一些公司的QPS已经超过了每秒10w的请求。执行一次redis命令,大部分的耗时都是在网络数据的读写上面,那么就在这一块用了多线程来进行,而其他操作还是由主线程来做。
Redis6.0多线程的实现机制
流程简述如下:
1、主线程负责接收建立连接请求,获取 socket 放入全局等待读处理队列
2、主线程处理完读事件之后,通过 RR(Round Robin) 将这些连接分配给这些 IO 线程
3、主线程阻塞等待 IO 线程读取 socket 完毕
4、主线程通过单线程的方式执行请求命令,请求数据读取并解析完成,但并不执行回写 socket
5、主线程阻塞等待 IO 线程将数据回写 socket 完毕
6、解除绑定,清空等待队列
该设计有如下特点:
1、IO 线程要么同时在读 socket,要么同时在写,不会同时读或写
2、IO 线程只负责读写 socket 解析命令,不负责命令处理
以上是关于Redis Stream队列与多线程模型的主要内容,如果未能解决你的问题,请参考以下文章